Panasas is known for shipping PanFS ActiveStor storage systems for high-performance computing shops. Now it’s branching out by partnering with Atempo and its Miria data-moving product.
Panasas started getting a deeper involvement with machine learning this summer, and has now decided to pursue the data movement and analytics market. This is a broadening move to bring in AI and machine learning and also high performance data analytics to its core HPC storage activity.
Panasas’ VP of Marketing and Product at Panasas, Jeff Whitaker, put out a statement saying: “These new offerings are key additions to our PanFS software suite, and they underscore our continued transformation into a multiplatform, software-first company.”
Atempo’s Miria Data Management software has modules for analytics, migration, backup, archiving and synchronization, and can support billions of files. It happens to support Lustre and S3. Panasas has created two new pieces of software from this: PanView Analytics by Atempo and PanMove Advanced by Atempo.
Tom Shea, Panasas CEO and president, provided more context: “Volumes of unstructured data are growing rapidly today, driven by the increasing convergence of traditional HPC and AI workloads. … “The PanView and PanMove suite continues the Panasas new product trajectory and gives our customers the control they need over their data – across platforms and in the cloud.”
PanMove extends Panasas’ reach beyond a cluster. It enables users to move large volumes of data between different ActiveStor systems, locally and across geographic distances. Data can also be moved between PanFS storage environments and S3 object stores, whether in public or private clouds, or on-premises systems.
Panasas customers’ end-users can extend PanMove’s protection, synchronization, and replication functionality even further by pairing it with Atempo’s Miria products. They can then support backup and archive targets such as tape and tape robotics as well as Azure and Google cloud object storage.
PanView is a data management and analytics tool that provides end-users with a simple, consolidated global view of their data across Panasas storage systems. It also delivers comprehensive storage activity reporting from a dashboard.
Atempo has been steadily building out partnership activities, making deals with Quantum and Qumulo. Now it has a third US-based storage partner.
Panasas will be demonstrating its software products at booth #713 at SuperComputing ‘22 in Dallas, Texas on November 14th – 17th, 2022. The PanView and PanMove products will be available to customers in the first 2023 quarter.
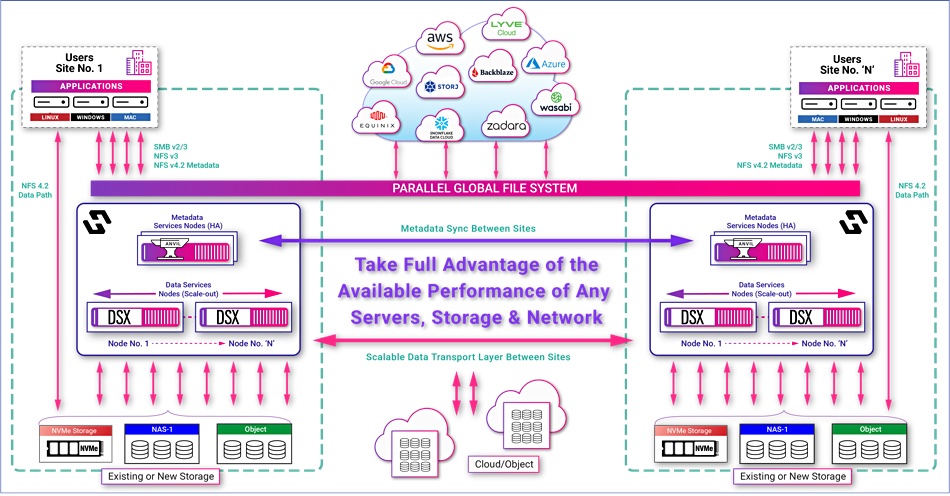
Hammerspace Global Data Environment (GDE) users can access files from servers, across datacenters, and global Internet links, and Hammerspace has upped the speed of all three stages, with parallel NFS, RDMA, and metadata and data path separation.
GDE 5.0 adds higher performance at server level, with near maximum IO subsystem speed, across interconnects in data centers, saturating Ethernet and InfiniBand links, and onwards to to the cloud, saturating links at this level too. The server-local IO acceleration applies to bare metal, virtual machines and containerized applications. It says this allows organizations to take full advantage of the performance capabilities of any server, storage system and network anywhere in the world.
David Flynn
Hammerspace CEO and founder David Flynn said in a supplied quote: “Technology typically follows a continuum of incremental advancements over previous generations. But every once in a while, a quantum leap forward is taken with innovation that changes paradigms. … Another paradigm shift is upon us to create high-performance global data architectures incorporating instruments and sensors, edge sites, data centers, and diverse cloud regions.”
The company claims GDE 5.0 changes previously held notions of how unstructured data architectures can work, delivering the performance needed to free workloads from data silos, eliminate copy proliferation, and provide direct data access to applications and users, no matter where the data is stored.
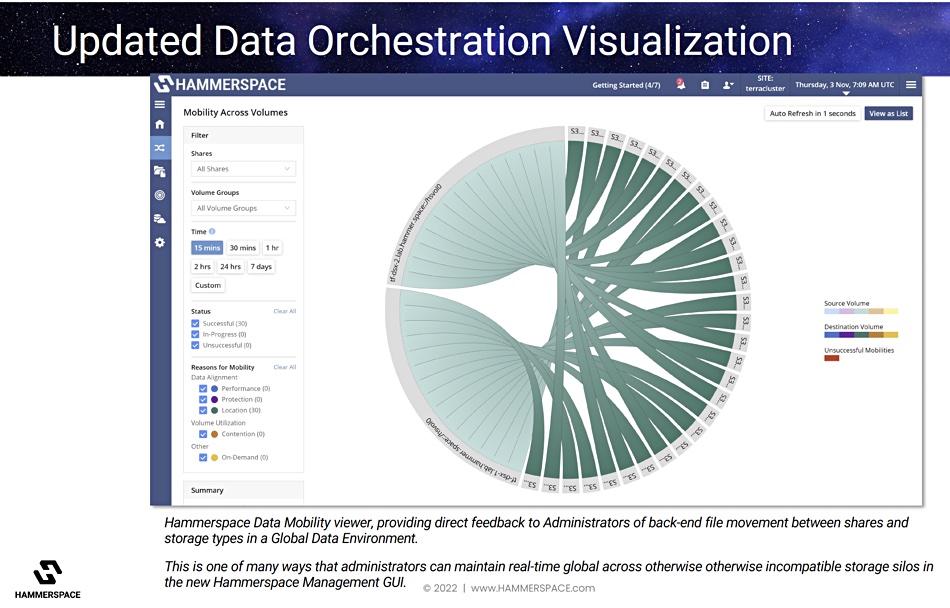
Hammerspace GDE v5 data orchestration visualization.
Server level
Hammerspace CTO Trond Myklebust, maintainer for the Linux Kernel NFS Client, said: “Hammerspace helped drive the IETF process and wrote enterprise quality code based on the standard, making NFS4.2 enterprise-grade parallel performance NAS a reality.”
The company’s Parallel Global File System architecture separates the file metadata control plane from the data path and can use embedded parallel file system clients with NFS v4.2 in Linux, resulting in minimal overhead in the data path. It takes full advantage of the underlying infrastructure, delivering 73.12 Gbits/sec performance from a single NVMe-based server, providing nearly the same performance through the file system that would be achieved on the same server hardware with direct-to-kernel access.
When servers are running at the edge they can become disconnected. With GDE, file metadata is global across all sites, and on disconnect local read/write continues until the site reconnects, at which time the metadata re-synchronizes with the rest of the global data environment.
Data center level
File system parallelism and separation of metadata traffic applies at this level as well. GDE 5.0 can saturate the fastest storage and network infrastructures, orchestrating direct I/O and scaling linearly across different platforms to maximize aggregate throughput and IOPS. Hammerspace supports a wide range of high-performance storage platforms that organizations have in place today.
GDE 5.0 adds a 20 percent increase in metadata performance to accelerate file creation in primary storage use cases, and accelerated collaboration on shared files in high client count environments. It also adds RDMA (Remote Direct Memory Access) support for global data over NFS v4.2, providing high-performance access to all data in the global data environment, no matter where it is located.
Hammerspace GDE architecture graphic.
There are data services nodes, called DSX (Data Service eXtensions) In the GDE. These provide the ability for Hammerspace to parallelize front-side and store-side I/O across the network. DSX nodes handle all I/O operations, replication, data movement, etc., and are designed to scale out to over 60 nodes in a cluster to accommodate any level of performance requirements.
A test showed that with a cluster of 16 DSX servers, the Hammerspace file system hit 1.17 Tbits/second; the maximum throughput the NVMe storage could handle. It did this with 32Kb file sizes and low CPU utilization. Performance scaled linearly and to even higher levels when more storage and networking were added.
Metro, continental and global level
GDE supports AWS, Azure, GCP and Seagate’s Lyve Cloud. V5.0 adds:
Continual system-wide optimization to increase scalability, improve back-end performance, and improve resilience in very large, distributed environments
New management GUI, with user-customizable tiles, better administrator experience, and increased observability of activity within shares
Increased scale, increasing the number of Hammerspace clusters supported in a single global data environment from 8 to 16 locations.
Hammerspace says its Parallel Global File System orchestrates data automatically and by policy in advance to make data present locally without users wasting time waiting for data placement. The GDE can send data across dual 100GbitE networks at up to 22.5GB/sec.
It says this level of performance enables workflow automation to orchestrate data in the background on a file-granular basis directly, by policy. This makes it possible to start working with the data as soon as the first file is transferred and without needing to wait for the entire data set to be moved locally. It means data can flow to on-premises servers or in and into the public clouds.
Hammerspace claims it can saturate the network within the cloud when needed to connect the compute environment with applications. An EDA (Electronic Design Automation) test in Azure showed GDE performance scales linearly, making it suitable for compute-intensive use cases. For example, processing genomics data, rendering visual effects, training machine learning models and general high-performance computing.
Download a Hammerspace Technology white paper here to find out more.
It may seem counter-intuitive – startups want to have as much cash on hand as possible in order to grow quickly, right? – but startups with an over-capitalization problem can kill their hopes of a good exit. How do you detect it, deal with it or prevent it?
Venture capitalists invest to grow their money over a relatively small number of years – five to ten, say, depending on the time window for their funds. They want a return within that window, preferably one gained by an IPO or an acquisition so that the equity they own is bought by somebody for far more than it cost the VC to buy it in the first place.
This means they need the startup in which they have invested to grow fast. They do not want their money locked up in a startup that doesn’t grow fast enough – or worse, doesn’t grow at all. But you can’t accelerate a company faster than its market will bear. VC impatience can’t beat market forces.
VCs throwing in a lot of cash can seem like a very good idea. Having more money than needed, particularly in straitened times, provides a longer runway for a startup. It’s a cushion – a safety measure. Perhaps the idea is to have a mega-round, after which no more money will be needed – ever – because the company will become self-funding. That’s a major bet on the future.
There is a company marketing aspect to VC fundraising as well. The more money investors put in, and the more rounds there are, the more valuable the company can appear to prospective customers. VAST Data has used this marketing tack.
In May 2021 VAST co-founder and CMO Jeff Denworth said after an $83 million round: “Today’s announcement is intended to raise visibility to our mission and to elevate our profile in the hearts and minds of the strategic customer prospects who are looking to make massive bets on our technology in the years to come. At $3.7 billion, we’re now worth more than many of the household name brand storage and cloud infrastructure products that VAST competes with.”
But having more money than needed can produce wasteful spending habits. “We don’t need positive cash flow just yet. We can fund the growth from cash in the bank.” An over-funded startup stops thinking in lean-and-mean, money-is-scarce terms and starts splashing cash about – hiring costly consultants, making the offices look top class, moving mountains of cash to advertising and marketing, over-spending on customer acquisition, and relying on support to fix problems rather than engineering to build a better product.
The excess of money is used as a crutch to shore up poor business practices. A more cash-efficient company would put money aside for a rainy day while it learns to stand, walk, and run on its own feet.
How can you tell if a startup which has raised boatloads of cash is not spending it in a gluttonous way? A good sign is cash flow positivity. A second is a consistently high and/or accelerating customer revenue growth rate. Beyond that it is more subjective.
We asked ex-Datera CEO Guy Churchward questions to find out more.
Guy Churchward.
Blocks & Files: Can you identify any over-capitalized storage startups?
Guy Churchward: Tintri, Datrium, Datera, and Violin were all over-capitalized for different reasons … Tesla was but look at it now. Commvault was, but seems to have turned the corner.
Then there are the handful of $200+ million [VC]-invested companies. How do they create success for the investors as it’s not just about growth and spending but creating a return!
Blocks & Files: How does over-capitalization come about?
Guy Churchward: Over-capitalized companies can happen through dreaming, drifting, lack of real accountability and large gravitational market shifts that just pull the rug and send a company into a spiral that changes a company’s fortunes from fantastic to frenetic.
Blocks & Files: What kinds of over-capitalized companies are there?
Guy Churchward: It’s a super tricky topic. Over-capitalized is basically a company that’s taken in more money than it is perceived to be worth from assets – the ‘valuation’ – and that’s subjective based on who’s doing the valuation, and its market phase.
Blocks & Files: Market phase?
Guy Churchward: There is the ‘dream’ phase, the ‘what if’ phase, and the ‘reality’ phase. The ‘dream’ phase is a company’s ‘worth’ when it just finished MVP (minimum viable product), has perhaps a few customers in beta or ‘paid production’, and looks like it can change the world. The perceived value from the board is an enormous multiplier and buyers buy on the dream!
The ‘what if’ phase is when a startup deploys a solid set of productions and can show it can replicate, but has no scale … so a large company would look at it and assume ‘if we had that product and amplified what it did into our base through our channels, can you just imagine how big we can make it’. The multiplier is high on forward-looking revenue but not as high as dream – it’s more pragmatic, but still buying on future promise.
The ‘reality’ phase is a business that’s already professionally run, has a client base and an acquirer would have a 360-degree view on the business and buy on the balance sheet – growth, retention, market size, competitive pressures etc. So this is a low forward multiple or sometimes a multiple on trailing revenues.
On top of that, if an company has been capitalized but the terms of each round have got more aggressive as the money is harder to find, there is a possibility the capitalization table and preference load means the company will find it hard to make any money for anyone except the owners of the senior round. So for the investors in that round they are OK, but for the employees and early investors the company is over-capitalized. They have been diluted to irrelevancy.
Blocks & Files: How do you detect over-capitalization?
Guy Churchward: This means you basically subjectively look at companies that have taken in a load of money, over a long period of time, have had great promise but have not had an event. VCs love selling in the ‘dream’ stage but if this doesn’t happen they like to get out in the ‘what if’ stage. But they will hold and invest if they think they can create a massive return – a multi-billion-dollar acquisition or an IPO.
Who was buffing their feathers a few years ago and has gone quiet? What companies took in a load of money? You thought they were going to IPO and now you wonder who on Earth would bother buying them.
If they get too big, and their client base is identical to their competitors, and it’s ‘just another mousetrap’ – then what’s the exit strategy?
This means you have a zombie company. On paper it might look good but likely the investment is written off – they missed their window!
On the other end of the spectrum, if you look at small companies that change their CEO, by some degree you can say they were over-capitalized. That means the board has concluded that the investment they have put in versus the results the exec team has afforded them are not conducive to future investments. They have to make adjustments as their assets that they paid for are not in the right math. That stops them wanting to invest more, and stops any new investors. The thing you hear here is ‘it doesn’t look like the current investors have got a good return’. So that’s when you have a startup that drifts around …
Blocks & Files: Are there types of over-capitalized companies?
Guy Churchward: I look at three different types.
1. The early startups that got massive funding from tech titans are blowing cash like water on marketing but there isn’t a lot of substance – aka companies that shout louder than serve. Generally they get rolled up or tucked in.
2. The companies that got unicorn funding, have an impressive growth, shouty marketing but they are just another mousetrap in a market space [in which they] can’t IPO and they hope for a purchase. But they just have nothing unique, they are a second source and therefore the board will be wondering what happened when the year-on-year growth slows and they are burning too hard. For example, four-plus years of 40 percent growth, then a tail-off on a company that is burning more than it’s making.
3. The company that’s been around a long time. It’s taken the innovation death spiral already, is totally catering to its existing base, has cut costs to try and survive, and now is like an ocean liner without propulsion. It needs the model to change somehow.
Ugly, but these are called zombie companies. They look alive, but they just are not. The employees are exhausted and just waiting for someone to buy them so they can move on.
Blocks & Files: Who is to blame for over-capitalization?
Guy Churchward: In storage, in all these situations, it’s never the fault of an individual but the collective responsibility of the board and the management and the market dynamics.
If a CEO is a tech founder and given too much rope then they can drift. But if they are jumped on, then the entrepreneurial side is quashed and you never get to bet.
If a CEO is left too long is that his/her fault, or the board’s? Should they change them, help them or install someone to coach them? If a company refuses to take an exit because a board member is greedy and misses their prime, then the blame drops on the management – but perhaps it’s not them.
Comment
It’s far easier to detect over-capitalization after the fact. No VC will publicly admit a company in which they have invested – and for which they have acquisition or IPO hopes – is over-capitalized. And neither will the board or CEO.
Denial is the name of this game – until reality bites.
Datacenter virtualizer Verge.io has appointed storage and tech industry veteran Mike Wall as its board chairperson, shortly after releasing some numbers for its second quarter.
Mike Wall.
Wall was the chairman and CEO at Kubernetes data-moving startup Ionir and took over its CEO spot from incumbent and co-founder Jacob Cherian in July 2021. This followed Ionir’s $11 million A-round in September 2020. No follow-on funding has been announced.
He exited the Ionir Chairman and CEO roles in March this year, giving Cherian his second stint at running the company.
Wall said in a statement: “Coming off of a record-breaking quarter makes this is an exciting time to be a part of the Verge.io team and I look forward to helping continue the sales velocity that we’ve achieved.”
Privately-owned Verge.io said it had 3x annual recurring revenue (ARR) growth to a record level in the third quarter of 2022 compared to the second quarter. It said the second quarter was also a record. The growth came from existing customers subscribing to more Verge.io software and from new customers. It did not provide financial figures.
Verge.io said its sales cycle was shortening, with new customers making orders in a matter of weeks from first contact, and it reckons the sales pipeline has more potential customers in it than ever. The company is looking at expanding its sales channels to capitalize on this customer interest.
The customers are subscribing to software which uses hyperconverged infrastructure to build a nested, multi-tenant, software-defined datacenter (SDDC) for enterprises and MSPs.
An SDDC is built from compute, storage, and network servers in resource pools. The storage can be a vSAN (block) or a NAS (files) and uses blockchain technology. The storage supports encryption, global deduplication, long-distance sync, snapshotting, recovery and auto-failover. SDDCs can be moved via dashboard button clicks from one platform to another, cloned for another set of tenants or department in an existing customer, or set up for a new customer.
This helps scale an MSP’s business. They and other customers get a single license which replaces multiple hypervisor, network, storage, data protection, and management tools to simplify technology stacks.
Verge.io CEO Yann Ness said: “Such strong quarter-over-quarter success shows that our efforts to provide a single piece of software that simplifies the data center process and offers a secure multi-tenancy for clouds is resonating in the marketplace. We are very pleased with the results of Q3 2022 given that we launched our website only 7 months ago and most of our sales team has only been in place for 6 months.”
Ness said: “Verge.io is poised to continue its pattern of growth as we provide a better alternative to traditional legacy cloud architectures that are too complex and require too much management.”
If Verge.io can continue its growth despite the worsening economic situation then Wall and Ness will really have something to crow about.
MSPs will be able to manage more and bigger clients with fewer staff, claims Acronis, talking up its new machine learning-boosted management product, which also includes more automation for its backup and cyber-protection product.
The new features add to the Acronis data protection and security product set for its MSP (Managed Service Provider) channel partners. Acronis hired a new CEO, Patrick Pulvermueller, last year to help it increase sales through channel, particularly MSPs.
Yves Meier, executive board member at Acronis customer GMG, said: “Acronis Advanced Management allowed us to offer more proactive, preventative protection for our clients – which improves their satisfaction with our services, and saves my team a ton of time responding to problems.”
The Acronis Cyber Protect Cloud (CPC) for service providers combines backup and security, meaning anti-malware, antivirus, and endpoint protection management. CPC has a number of extra protection packs, all branded “Advanced” as in Advanced Security, with others including Backup, Disaster Recovery, Email Security, Disaster Loss Prevention, File Sync and Share, and Management.
CPC is a major product, being used by used by over more than 20,000 managed service providers in over 150 countries with 26 languages, and there are more than 750,000 business customers of these MSPs.
Acronis announced a Cyber Scripting feature for Advanced Management in July, providing a verified set of 40-plus scripts to automate common tasks. Customers could create or fine-tune existing scripts and add them to a script repository.
Advanced Management takes this further and automates an MSP’s routine tasks via scripting and patch management. It provides daily tracking visibility into clients’ software assets and data protection, and monitors disk drive health. The facility now gets machine learning-based automated remote monitoring for continuous anomaly detection as a general malware defense. This is adaptive and doesn’t require manual threshold setting, claims the company.
The patch management provides for rollback from automated backups in the event a patch fails. There is also better security protection on remote desktop and Cyber Scripting with two-factor authentication (2FA) and a new protocol using 2-way AES to prevent management tools from opening new vulnerabilities.
The Advanced Automation feature will help Acronis’ MSP partners integrate Acronis MSP customer’ back-office functions with Acronis service delivery, such as endpoint management. It has:
Billing automation with support for consumption-based services
SLA tracking, reporting and technician performance
Support ticketing system
Automatic, granular per-tenant tracking of billable and non-billable time
Operational and profitability reporting and dashboards
Support for multiple languages
Centralized control and visibility from the Acronis console
This plan is to tempt channel partners with the idea they’d be better able to scale services to clients, integrate support ticketing , show clients which services were delivered, review SLAs, review staff utilization rates and performance, as well as do revenue forecasting.
Acronis will be releasing the Advanced Management update of Remote Desktop in December, and both the machine intelligence monitoring and new Advanced Automation product will arrive in the first quarter of 2023.
Storj briefed B&F on its decentralized storage offering, revealing why Web3 storage decentralizers use cryptocurrency and blockchain, and how Storj makes decentralized storage fast.
Decentralized storage (dStorage) takes the virtual equivalent of an object storage system and stores data fragments on globally distributed nodes owned by independent operators who are paid using cryptocurrency, with storage I/O transactions recorded using blockchain. You realise how odd this is when you notice that the nodes in an on-premises object storage system don’t use blockchain to record their transactions and don’t require any cryptocurrency payments. But it’s Web3, so, cool?
John Gleeson.
Storj offers decentralized cloud object storage (DCS) software, previously known as Tardigrade, which uses MinIO and is S3-compatible. John Gleeson is Storj’s COO and he answered the cryptocurrency query: “It is all about cross-border payments. The cryptocurrency allows us to pay what is currently about 9,000 operators, operating 16,000 storage nodes in 100 different countries in a way that I can’t think of any other way that we would do that. Really, the cryptocurrency component isn’t innovation.”
If Storj paid its storage node providers – its operators – in fiat currency then it would have to manage foreign exchange rates and transactions. Using cryptocurrency lets Storj avoid foreign exchange complications – the operator gets paid within the cryptocurrency regime and each one deals with conversion to their local real money.
Blockchain
The use of blockchain is inherent in cryptocurrencies but is also generally used in dStorage to confirm and verify that data I/O has taken place and that storage capacity is present and available in the dStorage network.
A blockchain is a decentralized ledger of transactions across a peer-to-peer network and is only needed because the peers in the network cannot natively be trusted to be present and performing as they should. In an on-premises multi-node storage system the nodes can be physically seen and the system controllers know of their presence and activity. Indeed, if a node goes down systems can detect this, via a missing heartbeat signal say, and fail-over to a working node.
That is not the case in a general peer-to-peer network, where there are no controllers. A node in Guatemala can go down with no other peer system realizing it. Blockchain technology is used to verify that operating nodes are active and performing correctly. For example, in the Filecoin storage network, blockchain verification is based on operators providing proof of replication and proof of space-time (PoSt).
Storj only uses blockchain for its internal cryptocurrency transactions, as Gleeson said: “We use blockchain only for the payment. Our token is an ERC-20-compatible token built on the Ethereum blockchain. And that is the extent of the blockchain technology in our in our product.”
Technology versus philosophy
Several dStorage providers believe that the world wide web has become too centralized in the hands of massive corporations, such as Amazon, Google and Microsoft. They believe in the wisdom of crowds, the computation-supported ability of providers and users to interact with and operate an internet that is not dominated by large corporations. For them blockchain is the technology – the golden doorway – opening the internet to freedom, with self-policed users and operators working within a cryptocurrency environment safeguarded by the technological magic that is blockchain.
But businesses want to store data – safely and cost-effectively. They have no philosophical desire to overturn Amazon because Amazon’s existence is somehow just wrong. Indeed, most would like to be Amazon. For them the storage of data has to be fast – I/O performance matters, and dStorage is generally only fast enough for storing archival data. It’s slow, in other words.
For example, in the Filecoin network, it can take five to ten minutes for a 1MiB (1.1MB) file from the start (deal acceptance) to the end of the upload process (deal block chain registration, aka appearance on-chain).
Storj characteristics
Gleeson said Storj is different and does not use blockchain for storage I/O transactions – the deals in which operators make storage capacity available to clients, accept and store and then retrieve the clients’ data.
He said: “Blockchain requires high computation, it tends to have very high latency. And if you have a storage business and you have an hour and a half to save a file and retrieve a file synchronously, that’s not a thing that that many people can use well. But if you’ve got sub-second latency, and you’ve got high throughput, then you have a product that addresses a broad range of use cases,” and not just archiving.
Storj asked itself, Gleeson said: “Could you actually use some of the primitives of decentralized systems but without a distributed ledger, without a true blockchain, without a high energy consuming proof of work component? Just tap into what is ultimately a system of thousands and millions of hard drives all around the planet that are 10 or 20 percent full, and aggregate that under-utilized capacity in a way that you can take advantage of some of the benefits of proven distributed systems like Gluster, and Ceph?”
You would need to create a an incentivized system of participation with zero trust architecture and layers of strong encryption, and have easy to use, but powerful access management capabilities to deliver such cloud storage product.
And that is what Gleeson says Storj did. “You just you take a fundamentally different approach, which is the Airbnb approach. Right? You can and try and build hotels or, or you can aggregate the excess capacity of people’s rooms all around the world.”
He said: “We’re delivering an enterprise grade service. We offer we’re the only decentralized project offering an SLA: 11 nines of durability, 99.97 percent availability.”
Cost
The storage cost is $0.004/GB/month and bandwidth (egress) costs $0.007/GB. Multi-region capability is included at no charge. This is cheaper than AWS, by far, and also Wasabi and Backblaze.
Gleeson said: “Because we’re not building buildings and stuffing them full of servers and hard drives, we’re able to to really capitalize on the unit economics here, and offer a product that is 1/5 to 1/40th of the price of Amazon depending on your use case.”
Storj is “tapping into any datacenter, any computer anywhere that has excess hard drive capacity. And when you can share that with the network, we’re able to aggregate all of that capacity as one logical object store and present that to applications to store data. It allows individuals to monetize their unused capacity. … And it gives us the the edge in terms of security, pricing and performance.”
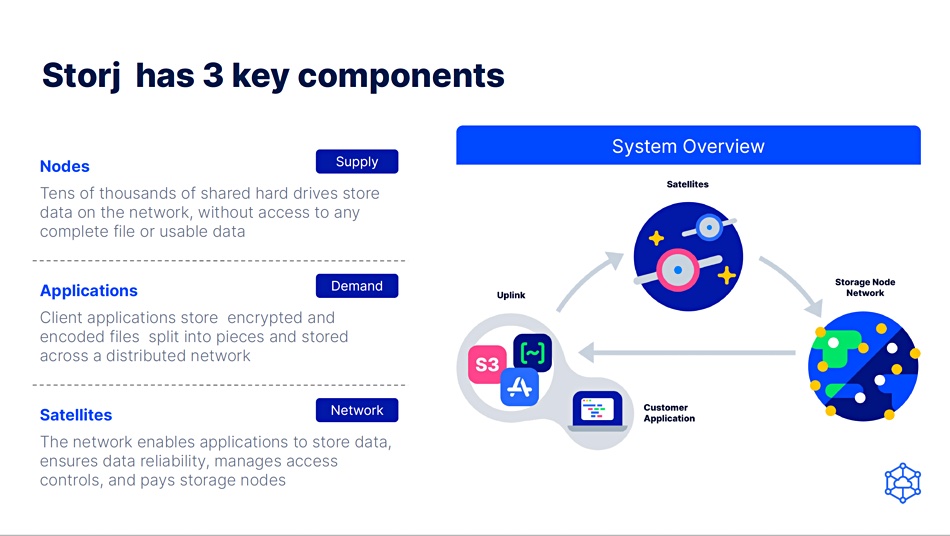
Customer applications talk via an uplink to do-called satellite nodes which, in turn, link to the storage capacity-providing nodes. Storage node operators are paid for storage and egress. We could think of a node as a virtual storage drive and a satellite as the rough equivalent of a filer (metadata) controller, which knows which drives (nodes) store which data shards.
Incoming data files or objects are split into >80 sections (shards), encrypted, erasure-coded and spread across a subset of the available nodes. Any 29 shards can be used to reconstruct lost data.
Performance and test
Storj offers performance better than S3 for many workloads, measured in milliseconds, and says it is content delivery network class. It writes data from and presents data to clients (read I/O) using parallel fetches to/from the shard-storing nodes and claims a typical laptop can achieve 1Gbit/sec transfer speed with a supporting internet connection while more powerful servers can exceed 5Gbit/sec downloading (reads) and in excess of 5Gbit/sec uploading (writes). Extremely powerful servers on strong networks can achieve transfer speeds of large datasets in excess of 10Gbit/sec.
A University of Edinburgh academic, Professor Antonin Portelli, has written a paper about Storj performance when storing HPC data. A simulated 128GB HPC file filled with random data was uploaded to Storj’s decentralized cloud storage (DCS) from the DiRAC Tursa supercomputer at the University of Edinburgh. The server used had a dual-socket AMD EPYC 7H12 processor with 128 cores and 1TB of DRAM.
The files were then downloaded from a number of supercomputing centers in the USA and the download speed measured. All the upload and download sites had multi GB/sec access to the internet. Here are the results:
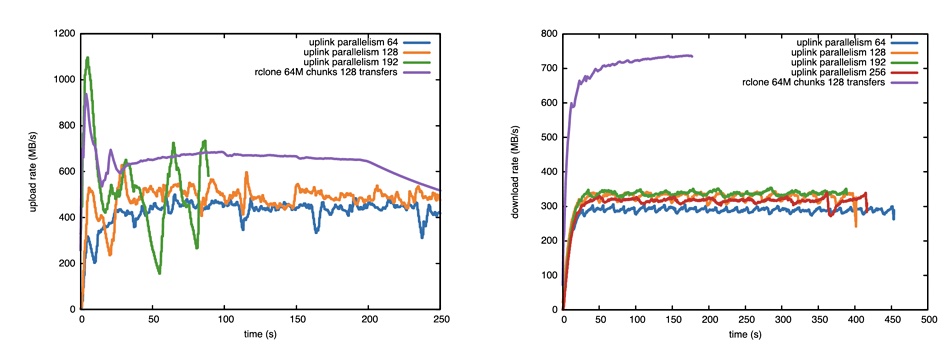
Storj Ediniburgh Uni test results. Upload on left and download on the right.
Upload rates were in the 400 to 600MB/sec range with download rates in the 280 to 320MB/sec area. Splitting the files manually achieved a 700MB/sec download rate (purple line) and >600MB/sec upload rate. Portelli comments: “It is safe to state that these rates are overall quite impressive, especially considering that thanks to the decentralized nature of the network, there is no need for researching an optimal network path between the source and destination.”
This is a level of performance greater than Filecoin or other blockchain-centric dStorage networks can achieve.
Storj says its performance is fast enough for it to be used for video storage and streaming, cloud-native applications, software and large file distribution, and as a backup target. Gleeson said performance should improve further in 2023 due to better geographic placement and seeking algorithms, and Reed Solomon (erasure coding) adjustments.
Iaso, the Greek goddess of recuperation from illness.
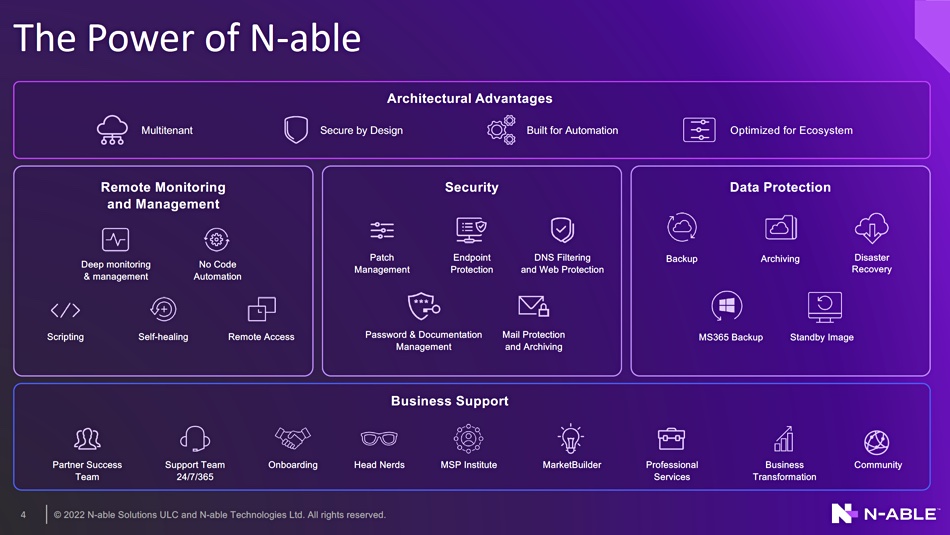
N-able revealed details of its Cove SaaS backup offering at an IT Press Tour briefing, saying it competes with Veeam and Datto and offers equivalent services through its MSP partners.
The company is a Solarwinds spinout, with more than 12,700 MSP partners signed up and 1,400 employees. It has three product pillars: remote monitoring and maintenance (RMM), security and data protection, where the Cove product exists.
N-able takes in 80 percent of its revenues from RMM and 20 percent from Cove. Approximate annual revenues for its last fiscal year were $360 million, meaning, we calculate, backup brought in about $72 million.
Chris Groot, GM of N-able’s data protection business, said Cove is offered through MSPs to their small and medium enterprise customers and also to mid-market in-house IT shops. Cove backs up physical and virtual machines, Windows, Mac and Linux systems, workstations and Microsoft 365. It recommends backing up from within a hypervisor guest to reduce the amount of data backed up. There is a small agent in each source system, such as a virtual machine guest OS.
The agents backup changed blocks only, not whole changed files. Groot said: “We reject stuff you don’t need to restore. There is real-time tracking of changes. We ignore changed folders and only back up changed blocks within a file.”
He cited an example of a 500GB VM with image-level backup needing to backup 30GB of incrementally changed file-level data whereas Cove only needs to backup up 0.5GB of changed blocks. That difference increases with, say, 60 days of retention; 1,800GB vs 30GB. With Cove less data needs to be sent to the cloud, its backup target, and so the backup window is shortened. Also less data needs to be stored in the cloud, lowering the storage cost.
Cove’s cloud
The backups are stored in Cove’s cloud, which has 30 datacenters worldwide, and with a local storage option – Speed Vault – for faster restores. Groot wouldn’t reveal any details of Cove’s datacenters, which we understand to be rented facilities in co-location centers.
Cove’s cloud currently stores around 150PB of data.
Cove can create a standby image, a bootable image alongside encrypted, non-bootable format. This bootable image makes recovery time shorter. Restore has a built-in integrated recovery testing option.
Groot talked about recovery to a local Hyper-V server or to shared local NAS storage, and “the next target will be Azure (2H 2022) with a bootable image into a customer’s tenant in Azure.” Teams support is coming next year.
What about Nutanix? “We can back up VMs in Nutanix; we operate in the guest, but we can’t restore to Nutanix. It’s 90 percent Windows in our space, 10 percent Linux. We don’t see Nutanix in our environment.”
And containers? “We don’t backup Kubernetes. There’s no demand yet.”
Cove competes with Veeam, Datto, Commvault’s Metallic offering and others.
Bootnote
The Cove backup offering has a convoluted history. It was originally developed in the Netherlands as IASO in 2004, Iaso being the Greek goddess of recuperation from illness. GFI Software bought IASO in 2013 and put it into a LOGICNow business unit in 2014. Solarwinds had bought N-able in 2013. It then bought LOGICNow in 2016, put that in the N-able stable, and offloaded it into the N-able spinout in 2021.
N-able realized that IASO had little brand recognition and a name change was needed. The rebrand to Cove took place earlier this year.
The SNIA has set up a Blockchain Storage Committee to address the needs of the technical community’s desire to engage in alliance-building and marketplace-driven activities, whereby all interested parties can participate without concern for Intellectual Property boundaries. The committee will be publishing a Blockchain Concept white paper, creating SNIA alliance agreements for cross-industry collaboration, and developing plans for a one-day Blockchain Technology Summit in Q2 2023. BSC membership is open to all SNIA members. … At SC22 in Dallas Astera Labs will showcase the Leo Smart Memory Controller on real CXL silicon running real workloads and performance benchmarks on customer platforms. … Data protector Acronis has promoted Katya Ivanova to the Chief Sales Officer position from a four-month stint as SVP Sales Operations and Inside Sales, following a 3.5 year period as VP Inside Sales.
Katya Ivanova
…
An open-source AWS S3 Secrets Scanner is available in GitHub. It is a Lambda function to scan objects uploaded/modified in S3 buckets for secrets. Objects are scanned as they are uploaded, in near real-time against a set of secrets definitions, driven by regular expression pattern matching. It excludes objects larger than a certain size and certain object paths, both configurable.
…
Object storage supplier Cloudian has integrated of its HyperStore object storage with Teradata Vantage’s on-premises deployment variants; the IntelliFlex and VMware Editions. This provides a public cloud-like data lakehouse system for supporting analytics workloads in on-premises and hybrid cloud environments. Teradata customers can now take advantage of HyperStore’s native S3 compatibility, exabyte-level scalability and military-grade security to analyze large volumes of data more easily and cost effectively. More info here.
…
Meet Decodable. It is a stream processing platform providing a simple way to move data from sources to analytics environments with real-time speed, transformed to match the needs of its destination. It’s a fully managed, -aaS offering with pre-built connectors to popular databases and uses SQL so ordinary data scientists can use it. Decodable is Series-A backed by Venrock and Bain, and has a product in production with users. The product features Change Data Capture, capturing changes made to data in a database and then delivering those change records in real time to a downstream analytics process, autonomously. Decodable provides a service, based on open-source Debezium, for CDC processing. Users can connect to source databases and process CDC records in real-time without managing the underlying infrastructure.
…
Dell has updated its Dell Integrated System for Azure Stack HCI offering to include single node configurations, support of Nvidia A2 or A30 GPUs, and deeper integration with Microsoft Azure Arc for better security. It also supports the latest release of Microsoft Azure Stack HCI.
…
Meet DoubleCloud, an analytics platform that helps to store, analyse and transfer data. It helps any business build an end-to-end data stack with sub-second data analytics and fully managed open-source technologies, like ClickHouse and Apache Kafka in less than five minutes. ClickHouse offers performance it claims is 100 to 1,000X faster than traditional DBMS. DoubleCloud aggregates, stores, transfers and visualizes data. Users can ingest data from external sources (eg, Facebook or Google ad platforms), and a free BI tool helps to create dashboards in just one click. DoubleCloud is used all over the world, from the USA to Germany and France. It has a global team of over 50 employees, who work across the UK, France, Israel and USA.
…
Equalum, a provider of data integration and ingestion software, announced its CDC (Change Data Capture) Connect Partner Program. This OEM/integration program is open to batch-oriented data integration vendors, application integration companies, and others requiring a more flexible, high-performance CDC technology to identify and track downstream data. Partners have the opportunity to strengthen their competitive advantage by deploying high-throughput, low-latency CDC without the need for code modifications in source applications.
…
Decentralized compute and storage provide Flux announced the launch of Jetpack 2.0, a system update that enables easier and cheaper deployment of decentralized applications (Dapps) onto the Flux decentralized cloud. Jetpack 2.0 brings an improved Dapp registration and management process as well as direct fiat (government-issued currency) payment and settlement services, and Flux Drive. This allows for data to be retained beyond the life of individual containers through the recently released Flux Interplanetary File System (Flux IPFS). By integrating fiat payment ramps, businesses using Flux don’t need to speculate on crypto prices. Users do not need a proficiency in blockchain to operate within the Web3 space.
…
Gigabyte Technology announced a PCIe 4.0 M.2 2280 format SSD using TLC NAND; the AORUS Gen 4 5000E in two capacities of 500GB and 1000GB, with 5000 MBps read speed and 30 percent lower overall power consumption compared to previous generation PCIe 4.0 SSDs. It uses host memory buffer technology, supports TRIM and SMART functions, and will be available soon. More info here.
…
The University of North Texas System has selected Hammerspace running with Pure Storage Flashblade to provide its file storage environment. When the UNT System’s growing general file and overall data storage needs outgrew the capacity of the existing Isilon NAS storage, it decided to migrate to FlashBlade but didn’t have the resources for a long migration and couldn’t afford any downtime. The UNT selected Hammerspace to provide the data interface layer which enabled, no downtime, fast data-in-place assimilation to make the migration to new technology simple. In the future, the UNT System plans to use Hammerspace software to help provide seamless data access across its data centers and cloud providers.
…
IBM Spectrum Fusion is a container-native hybrid cloud data platform for Kubernetes applications on Red Hat OpenShift Container Platform. It is designed to meet the data services requirements of modern, stateful Kubernetes applications. New capabilities in Fusion version 2.3 include Metro Synchronous Disaster Recovery, Enhanced storage efficiency and resiliency, Data exploration with Spectrum Discover, and more. Read a technical presentation here.
…
InfluxData, creator of the time series platform InfluxDB, announced product enhancements at InfluxDays 2022, its annual developer and community event. New features, including InfluxDB Script Editor, Telegraf Custom Builder, and Flux 1.0, support developers working with time series data, allowing them to do more with less code.
…
Lenovo’s Q3 2022 earnings report showed a significant PC sales decline but ISG (Infrastructure Solutions Group) revenues were up 33 percent Y/Y to $2.61 billion. Within ISG Lenovo reported storage revenues up 115% Y/Y, and Edge revenues quadrupled. Storage revenue growth was driven by buoyant demand from Cloud Service Provider (CSP) customers. Profitability of the CSP segment continued to improve on greater efficiency and better product mix. Lenovo OEMs NetApp storage systems and resells IBM tape drives and libraries.
…
Momento emerged from stealth with its Serverless Cache, the first instantly elastic, highly available cache that can serve millions of transactions per second. Momento is already being used by CBS, NTT Docomo and Wyze Labs. Momento’s CEO Khawaja Shams led Amazon DynamoDB, and together with his co-founder, Daniela Miao, scaled it to become a large fully managed database services. Momento’s Serverless Cache lets developers add a cache to their modern cloud stacks with 5 lines of code, and a cache is ready in under a second via a single API call. It automatically manages hot-keys, maintains high cache hit rates, keeps tail latencies low and provides instantly scalable capacity.
Momento has received $15 million in seed funding led by Bain Capital Ventures and with participation from The General Partnership and angels Marianna Tessel (CTO at Intuit), Neha Narkhede (co-founder and former CTO at Confluent), Tom Killalea (first CISO at Amazon), Don MacAskill (CEO of Flickr/Smugmug) and John Lilly (former CEO of Mozilla). Momento plans to use the funding to expand its engineering team, to build a full cycle GTM team, to expand the Momento platform and to add support for additional clouds.
…
Data protector NAKIVO released version 10.7.2 of NAKIVO Backup & Replication, its enterprise backup and disaster recovery offering, so becoming one of the first data protection vendors to provide compatibility with VMware vSphere 8 IA. VMware announced the initial availability (IA) of vSphere 8, the latest version of the leading virtualisation platform, in October. NAKIVO grew its revenue by 24 percent worldwide in Q3 2022 over Q3 2021. Of the total revenue, 43 percent came from the EMEA region, 37percent from the Americas, and 20% from the Asia-Pacific region. The countries delivering the highest revenue growth in Q3 2022 were Canada, Belgium, and Turkey.
…
NetApp has opened new international headquarters in Cork, Ireland, which is expected to create 500 jobs by 2025 to support NetApp’s international commercial, sales, and technology operations. It has already hired over 100 employees in Cork and will recruit a further 200 more staff by the end of June 2023, to reach 500 employees by 2025. The available positions range from early career to senior level, spanning engineering and technology roles to finance, sales, recruitment, and product management, including multilingual roles.
…
Parsec Labs has a Free Discovery Tool that can scan tens of thousands of files per second and build a detailed report on the total number of files, total number of directories, number of files in directories, average file size, the median file size, as well as the total size of all mounts in a network filer. This tool will export reports in json, xml, csv, and html. Other license packs offered by Parsec Labs include Fail-Safe Data Protection (S3 mobility + full restore for enterprise filers), S3 Mobility (includes file to cloud, cloud to file, cloud to cloud replication, and validated migrations to S3), Enterprise Data Mobility (includes validated migration, fast copy, replication, and third party data verification), Parsec Complete (total data independence), and Insight to Data (Consolidated view of one or more filers. Total data, age of data, type of data). License packs are delivered to virtual or physical appliances.
…
Protocol Labs, the open-source R&D lab, announced the launch of Filecoin Saturn, a data delivery network that will help scale the Filecoin network and make it more accessible to the general public. The Filecoin network has more than 18.9 exabytes of available storage. Up until now, the only way to contribute to the Filecoin network has been to become a Storage Provider (SP) which can be expensive. The release of Filecoin Saturn now means that anyone will be able to download Saturn’s open source software, run it on their server, contribute bandwidth to the network, and earn Filecoin. Saturn is a Web3 Content Delivery Network (CDN) in Filecoin’s retrieval market.
…
The US government held a second International Counter Ransomware (CRI) Summit with 36 nations, the EU and many private sector businesses attending. The attendees said they would take joint steps to stop ransomware actors from being able to use the cryptocurrency ecosystem to garner payment. This will include sharing information about cryptocurrency “wallets” used for laundering extorted funds and the development and implementation of the international anti-money laundering/combating the financing of terrorism (AML/CFT)standards for cryptocurrency and related service providers, including “know your customer” rules to mitigate their misuse by cyber criminals.
…
…
Electronic components supplier TDK announced second quarter fy2023 results on Nov 1, saying HDD read/write head sales decreased due to a substantial decline in demand related to PCs and tablets on top of slowing demand related to data centers. Its Magnetic Applications business segment saw sales down 10.7% Y/Y to ¥54.7 million as a result. TDK aims to expand its sales of MAMR heads and continue developing HAMR heads as a MAMR follow-on.
TDK graphic.
…
Touchdown PR which has many storage company clients, has been acquired by RuderFinn, after discussions with several prospective buyers. It will operate as a RuderFinn business unit with CEO James Carter and the existing staff staying in place.
…
Veeam‘s Cloud Protection Trends Report for 2023 covers four “as a Service” scenarios: IaaS, PaaS, SaaS, and Backup and Disaster Recovery as a Service (BaaS/DRaaS). It found – unsurprisingly – that companies are recognizing the increasing need to protect their SaaS environments. Get a copy of the report here.
Jeffrey Giannetti.
…
Scale-out paralel filesystem supplier WekaIO has appointed Jeffrey Giannetti as Chief Revenue Officer (CRO), reporting to President Jonathsan Martin. He comes from being CRO at Deep Instinct and was a Veeam SVP back in 2017-2018 as well as a stint at Cleversafe. Andrew Perry was WekaIO’s Global VP of Sales up until May this year. His fate is unknown. Giannetti said: “It’s an honor to join the company at this critical point in its trajectory to help build an elite global salesforce that will take this rocket ship to new heights.”
…
Managed compute and storage supplier Zadara is partnering internet infrastructure service company KINX to provide its zStorage, storage-as-a-service, to the Korean market through KINX’s CloudHub. CloudHub is the largest cloud platform in Korea, connecting nine of the leading cloud service providers., and configured as a private network. Zadara zStorage will support storage services for KINX’s multi-cloud and hybrid cloud environments. It upports any data type, block, file, object, on any protocol, on-premises, across clouds or in a hybrid environment.
…
Vector database supplier Zilliz says its Zilliz Cloud is generally available and ready for enterprise production workloads. The fully-managed service makes it easy for companies to deploy and run their image retrieval, video analysis, recommendation engines, targeted ads, customized search, smart chatbots, fraud detection, network security, new drug discovery, and many other AI applications at scale.
The Zilliz Cloud is based on Milvus, the world’s first purpose-built database to store, index, search, and analyze high-dimensional, dense embedding vectors which represent the semantics of unstructured data. Milvus is the fastest growing open-source project in AI data infrastructure, with 14,000 GitHub stars, over two million downloads and installations, and a community of thousands of enterprise users globally, including eBay, Shopee, SmartNews, Line, Kuaishou, Nvidia, Baidu, and Tencent.
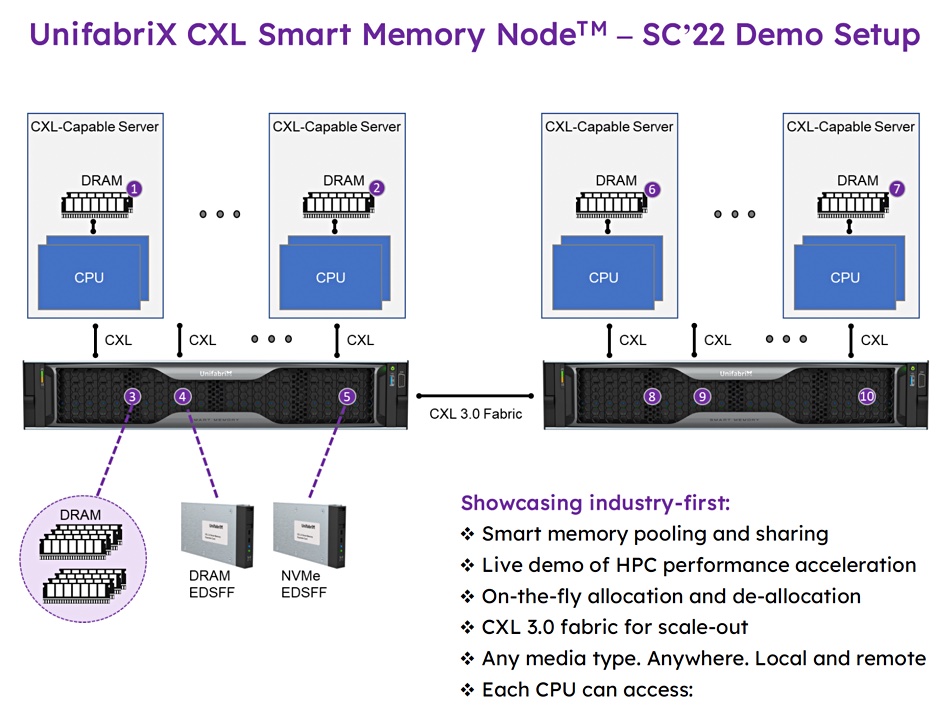
Israeli startup UnifabriX is demonstrating a CXL 3.0-connected Smart Memory device for data center and HPC memory pooling
The demo is taking place at SC22 and UnifabriX said it will involve both memory pooling and sharing, as well as performance measures. The aim is to provide multi-core CPUs with the memory and memory bandwidth needed to run compute/memory-intensive AI and machine learning workloads in data centers. Existing CPUs have socket-connected DRAM and this limits the memory capacity and bandwidth. Such limits can be bypassed with CXL memory expansion and pooling.
Ronen Hyatt, CEO and co-founder of UnifabriX, said: “We are setting out to showcase significant improvements and the immediate potential that CXL solutions have to upend HPC performance and close the gap between the evolution of processors and memory”
The company reckons its CXL-based products achieve exceptional performance and elasticity in bare-metal and virtualized environments over a wide range of applications, including the most demanding tasks.
UnifabriX was started in January 2020 by Hyatt and CTO Danny Volkind. Seed funding was provided by VCS and angel investors. Hyatt is an ex-platform architect in Intel’s Data Center Group who joined Huawei as a Smart Platforms CTO in 2018. He left to launch UnifabriX. Volkind was a system architect at Intel and was employed by Huawei as a Chief Architect. Both were at PMC Sierra before Intel and attended Israel’s Technion Institute of Technology.
CXL background
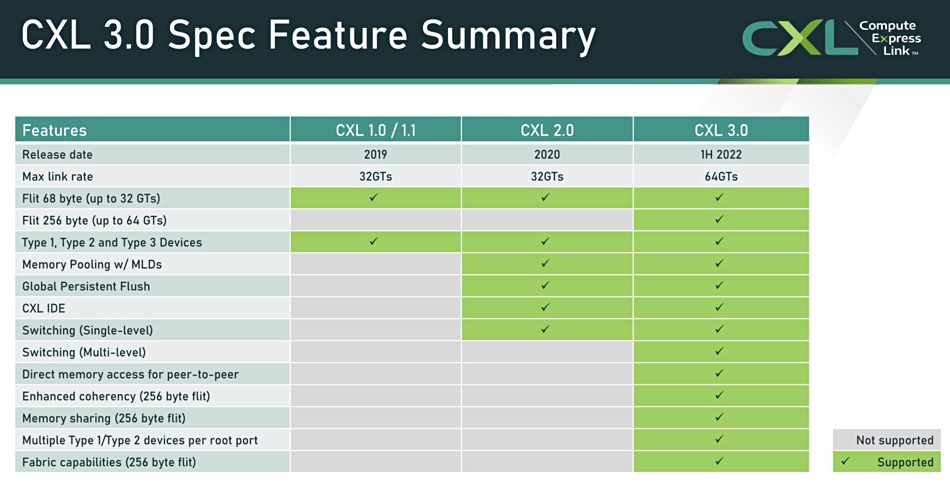
A UnifabriX white paper looks at CXL 1.1 and 2.0 differences, with CXL 1.1 supporting direct-attached memory devices to facilitate memory expansion, and CXL 2.0 adding remote memory device support via CXL switching. The switch allows multiple hosts to connect to a memory device and see their own virtual CXL memory resources. The memory device can be sub-divided into logical domains, each of which, or groups of which, can be assigned to a separate host. An external Fabric Manager controls the CXL switch or switches. This all supports dynamic memory expansion for servers by allocating them cache-coherent remote memory from the CXL pool.
CXL table of standards and facilities.
The memory devices may be pure memory or intelligent processors with their own memory, such as GPUs or other accelerator hardware. The CXL 3.0 standard uses PCIe gen 6.0 and doubles per-lane bandwidth to 64 gigatransfers/sec (GT/sec). It enables more memory access modes – sharing flexibility and complicated memory sharing topologies – than CXL 2.0.
In effect, CXL-connected memory becomes a composable resource. According to Wells Fargo analyst Aaron Rakers, Micron has calculated that CXL-based memory could grow into a $2 billion total addressable market (TAM) by 2025 and more than $20 billion by 2030.
Demo product
UnifabriX CXL 3.0 fabric memory pooling device.
The SC200 demo is of a Smart Memory device powered by UnifabriX’ RPU (Resource Processing Unit) built from the silicon up with UnifabriX hardware and software. The RPU is described as an evolution of the DPU (Data Processing Unit) and is used to improve host CPU utilization, memory capacity and system-wide bandwidth. UnifabriX will demo enhanced performance related to all three items using a “recognized HPC framework.”
This Smart Memory Node is a 2 or 4 rack unit box with E-EDSFF E3 media bays and up to 128TB of memory capacity. The memory can be DDR5 or DDR4 DRAM, or NVMe-connected media.
Access is via NVMe-oM (NVMe over Memory) and there can be up to 20 CXL FE/BE ports with node stacking via a BE Fabric. The box is compliant with CXL 1.1, CXL 2.0, PCIe Gen 5 and is CXL 3.0-ready. It has enterprise RAS (Reliability, Availability and Scalability) and multi-layer security.
Two such units will be connected across a CXL 3.0 fabric to several servers. This is said to be the first ever CXL 3.0 fabric. Hyatt said: “Setting out to achieve and document CXL-enabled performance in a real environment according to industry standard HPC benchmarking is a difficult task that we are excited to demonstrate live at SC22.”
Samsung is mass producing a 1 terabit 3D NAND chip with the highest bit density in the industry meaning more flash memory for smartphones, smart cars, SSDs and servers.
Update: 20 percent bit density increase statement removed; 10 November 2023.
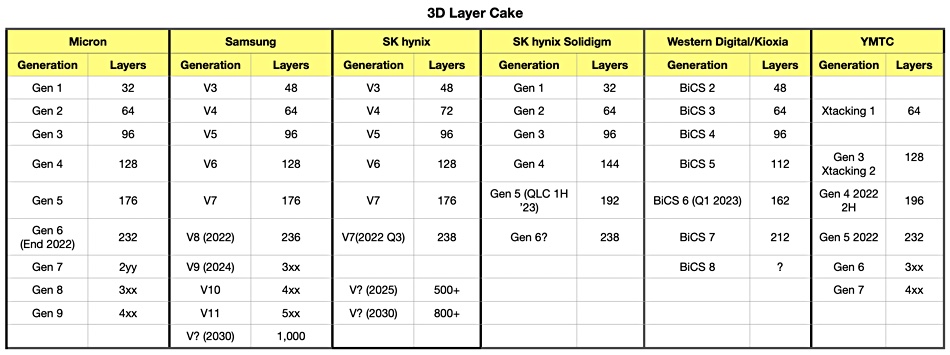
The K90VGK8J8B chip uses Sammy’s gen 8 V-NAND (Vertical-NAND) technology with, we understand, 236 layers and cells organised into TLC (3 bits/cell format). It uses a Toggle DDR5 interface, transferring data at 2,400Mbps.
SungHoi Hur, Flash Product & Technology EVP at Samsung Electronics, said: “Samsung has adopted its advanced 3D scaling technology to reduce surface area and height, while avoiding the cell-to-cell interference that normally occurs with scaling down.”
Samsung 1Tbit Gen 8 V-NAND chip
Samsung said it was able to attain the industry’s highest bit density by significantly enhancing the bit productivity per wafer. It’s latest chip is a good fit for SSDs using the PCIe gen 4 interface and doubled speed PCIe gen 5.
The 236-layer count is 34 per cent more than its 7th generation 3D NAND with a 176-layer count. This combined two 88-layer sections rather than building a single 176-layer device; a technology termed string stacking. Samsung has not revealed whether the 236-layer chip is string-stacked. A major problem with 150-plus layer chips is that the etching of holes through the layers becomes progressively more difficult as the layer count increases, with the hole geometry becoming irregular.
SK hynix is sample shipping a 238-layer count 512Gbit chip, half the capacity of Sammy’s latest NAND chip. It is due to enter mass production in the first half of 2023.
NAND fab partners Kioxia and Western Digital are at the 212-layer point. Micron has 232-layer technology in development as does China’s YMTC. Micron is delaying a production ramp of the 232-layer chip due to the deteriorating economic situation which has adversely affected its earnings. YMTC’s development is expected to be slowed by US Technology export restrictions.
Samsung has not announced any SSD products that use its 1Tb chips. Its FMS 2022 booth and presentations mentioned several SSDs that could use it.
Were Samsung to produce a QLC (4bits/cell) version of its latest chip, the capacity would be a third higher at 1.33Tbit.
VAAI – vStorage APIs for Array Integration (VAAI) is a set of features thatenables a VMWare ESXi host to offload virtual machine (VM) and storage management operations to a storage array. VAAI is a set of storage array operations aimed at reducing host CPU load and storage network bandwidth. VAAI consists of three components that VMware refers to as primitives. A primitive is the underlying technology that a higher-level feature or use case can call. In turn, the primitive can perform a function or request that the function be performed on the storage device on behalf of the primitive. These primitives are as follows:
Atomic Test & Set (ATS), which is used during creation and locking of files on the VMFS volume
Clone Blocks/Full Copy/XCOPY, which is used to copy or migrate data within the same physical array
Zero Blocks/Write Same, which is used to zero-out disk regions
Thin Provisioning in ESXi 5.x and later hosts, which allows the ESXi host to tell the array when the space previously occupied by a virtual machine (whether it is deleted or migrated to another datastore) can be reclaimed on thin provisioned LUNs.
Block Delete in ESXi 5.x and later hosts, which allows for space to be reclaimed using the SCSI UNMAP feature.
vVols – Virtual Volumes – vVols is a VMware vSphere SAN/NAS management and integration framework that exposes virtual disks as native storage objects and enables array-based operations at the virtual disk level. vVols virtualizes SAN/NAS arrays, enabling a more efficient operational model optimized for virtualized environments and centered on the application instead of the infrastructure. vVols virtualizes SAN and NAS devices by abstracting physical hardware resources into logical pools of capacity (vVols datastores) that can be more flexibly consumed and configured to span a portion of, one or several storage arrays. A vVols datastore is a logical construct that can be configured on the fly, without disruption, and does not need to be formatted with a file system.
vVols defines a new virtual disk container (Virtual Volume) that is independent of the underlying physical storage representation. This virtual disk becomes the primary unit of data management, eliminating pre-allocated LUNs/Volumes. vVols enables storage operations with VM granularity, leveraging native array-based data services and software-based data services.