


CXL 2.0 will enable memory pooling, which sounds great, but a bit vague. How big can the memory pools be? There is no firm answer yet, but we can take a stab at it. How does a petabyte sound? Or more?
The potential memory pool capacity depends upon the servers providing it. And that depends upon the server CPUs and their PCIe lane support as well as DRAM DIMM module capacity. We started on the basis of Sapphire Rapids processors, and were helped by MemVerge’s expert Beau Beauchamp in our calculations and also by Jim Handy of Objective Analysis..
CXL 2.0 maintains cache coherency between a server CPU host and three device types. Type 1 devices are I/O accelerators with caches, such as smartNICs, and they use CXL.io protocol and CXL.cache protocol to communicate with the host processor’s DDR memory. Type 2 devices are accelerators fitted with their own DDR or HBM (High Bandwidth) memory and they use the CXL.io, CXL.cache, and CXL.memory protocols to share host memory with the accelerator and accelerator memory with the host. Type 3 devices are just memory expander buffers or pools and use the CXL.io and CXL.memory protocols to communicate with hosts.
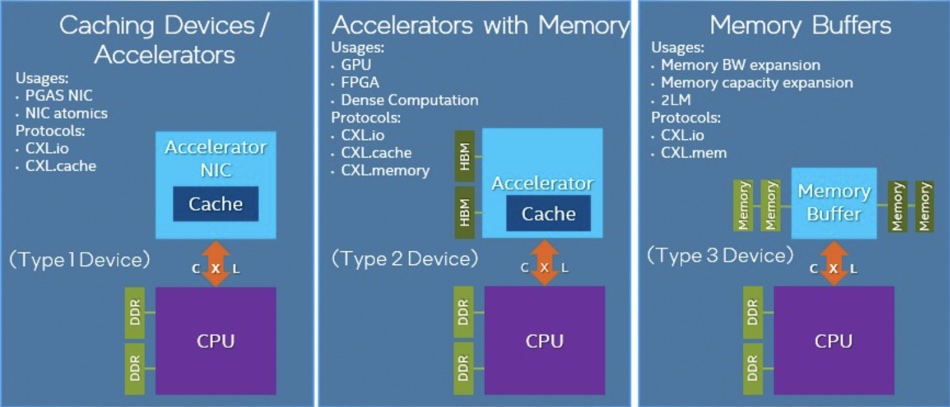
A Type 3 device will link to a server host across the link, which will be PCIe 5.0 initially. Later versions of PCIe – 6 and 7 for example – will be used in subsequent versions. Intel’s coming gen-4 Xeon SP Sapphire Rapids CPU will support CXL 1.1. and then 2.0.
It will have up to 56 cores, 8x DDR5 DRAM sockets, support 64GB of HBM2e with each of its four component tiles supporting 16GB, and up to 128 PCIe 5 lanes, as well as Optane PMem 300 devices.
Beauchamps’s view
Beauchamp told us: “Sapphire Rapids supports 8 DIMM sockets, so 4TB can be configured using 512GB DIMMs (which will exist), but the economics of doing so will make it a rare case.”
CXL 2.0 will support 16 PCIe lanes. Beauchamp added detail: “CXL supports from 1 to 16 lanes per link in powers of 2. Each PCIe 5 lane provides 4GB/sec of bandwidth, so 128 GB/sec for a x16 link. A DDR5 channel has ~38 GB/sec bandwidth, hence a x4 CXL link (32 GB/sec) is a more comparable choice if direct-attaching CXL memory modules. The industry is generally centering on x4 links for CXL memory cards.”
He then worked out how many more DDR channels this meant. “Multiple CXL links are supported. I’m sure Sapphire Rapids has many PCIe lanes (close to 100), and I assume a third to a half of those can be CXL, so let’s say there are three x16 groups (which like PCIe can each be bifurcated into four x4 links) so that is equivalent to about 12 more DDR channels. I don’t know how many slots chassis designs will include.”

Using the maximum DIMM size of 512GB, “12 more DDR channels” would mean a theoretical 6TB of CXL DRAM capacity per Sapphire Rapids CPU, which could be added to its local, direct-attached 4TB max of DRAM to make 10TB in total.
Beauchamp said “CXL 2.0 supports switching, so using a x16 link to a switch-fanout multi-slot (>10 slots) memory box is conceivable. Multiple servers sharing (partitioning) 50–60 slots is also conceivable.”
Building on this
Now let’s add in MemVerge’s memory machine technology. It is system software that clusters many servers’ memory into a single pool. In April 2019, we learned it could support a cluster of 128 server appliances, each with 512GB of DRAM and 6TB of Optane.
That means we can, in theory, take a single Sapphire Rapids server’s maximum 6TB of DRAM and cluster 128 of them together to produce a 768TB pool of memory along with the 128 x 4TB = 512TB of clustered local memory in the servers – 1.28PB in total.
Beauchamp said there are a few technical issues that may impede this pooling vision in the near term. First: “Previous Xeon processors have a max memory limit they can ‘own’ per socket (ie, be the ‘home’ coherence agent). Cascade Lake had multiple SKUs for this (1, 2, and 4TB). Ice Lake had only one SKU, 4TB. I don’t know what Sapphire Rapids will do in this regard, but I expect it to increase, maybe double to 8TB? That limit may clip your 10TB per socket result.”
Second: “CXL 2.0 switch configuration is limited, so fully flexible sharing between 128 servers may not be practical. (CXL 3.0 is targeting more capable and simplified switching).”
Handy’s view
In answer to the question “how much CXL memory might there be?” Handy said “I think that the answer will come from a different direction.”
“The system’s memory space will be limited by a number of factors – not simply the ones you mention. Near Memory (the stuff that actually touches the CPU) is limited by capacitive loading and how many chips a CPU pin can drive, or even how many chips a DRAM pin can drive. The memory density of a particular chip is important here, and that will increase over time.
“For Far Memory (memory that communicates with the CPU through a controller, ie CXL or OpenCAPI) the number of memory chips that can be attached is almost limitless, so other factors determine how much memory can be attached. (To my understanding, an overabundance of memory addresses is available in CXL, although I have been having some trouble finding an exact answer. I did some looking into the 628-page CXL 2.0 spec, and made a couple of calls, but don’t yet have a solid answer.)
“What ‘other factors’ would determine the maximum memory? The two that I can think of are the physical address length supported by the CPU and the cache controller. These are usually the same. CXL uses asymmetric coherency, which means that a single CPU manages the coherency of the whole system. Any limit on the CPU determines the maximum memory size that can be managed. If Sapphire Rapids is like its predecessors, it will be offered in a variety of flavors with an assortment of addressing capabilities.
“… so you don’t get a concrete answer!”
Handy then made a number of detailed points:
- The maximum DDR DRAM that can be attached to a Sapphire Rapids chip is determined by the CPU chip’s address pins, not by the DRAM chips it uses. Samsung capitalizes off of that by making mega-DIMMs (128, 256, & 512GB) with stacked DRAM chips, using TSV technology developed for HBM, and charging high prices for them, so your calculation (1.28PB) would necessarily be off. As denser DRAMs come along, that would throw it off as well. Samsung may choose to double the number of DRAM chips in its stacks, too, so that would also throw things off.
- HBM support would also be determined by addressing. I would expect for Intel to set the number of address bits a little high to allow future designers to use whatever DRAM makers can ship them five years from now.
- Each CXL channel is a single lane. That lane can either speak PCIe or CXL. This is determined at boot-up. I believe that the number of PCIe lanes on a CPU chip can go from zero to infinity, with 16 being a practical number today.
- The amount of DRAM on a single CXL lane should be many orders of magnitude larger than your 512GB estimate. This means that the amount of memory is limited by the CPU’s address range.
“This isn’t a tidy answer, but CXL has been designed to lead a long life, and that involves providing an over-abundant (for now, at least) address range.”
The net effect of this is that our 1.28PB calculated Near Memory plus Far Memory total could be too small – but no one knows. It depends upon CPU DRAM capacity, CPU PCIe lanes, CXL switch capacity and CXL memory module capacity – that’s four areas of uncertainty, and there may be more.
Eideticom CTO Stephen Bates suggested: “You might have issues powering and cooling all that memory, but that’s just a physics problem ;-).”
Hyperscaler CSPs and massive memory
Our calculated 1.28PB memory amount is a theoretical number and, as Beauchamp has intimated, the economics of this will make it unlikely. But imagine a hyperscale public cloud supplier doing this – providing a massive pool of memory to a set of Sapphire Rapids servers, and so enabling, through composability software, the provisioning of 100TB to 1,000TB memory instances for hyperscale in-memory database/data warehouse applications that would run at currently unimaginable speeds. A pool of Optane storage-class memory could be added in for persistent storage – checkpointing, for example.
Customers could use this facility for burst processing in the AI, machine learning, and analytics application space.
We’re dealing with possibilities here but, with Sapphire Rapids and CXL 2 building blocks, they are tantalizingly close. They represent a potentially huge increase in the deployment of of in-memory data sets and the execution speed of applications using them.
Boot note
The Xeon Ice Lake processor has a 46-bit physical address space: 64TB.




