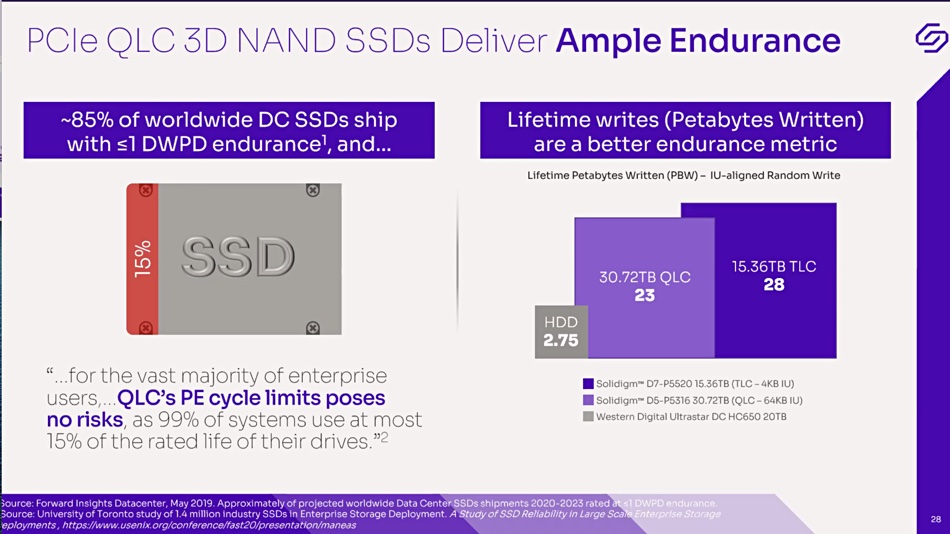
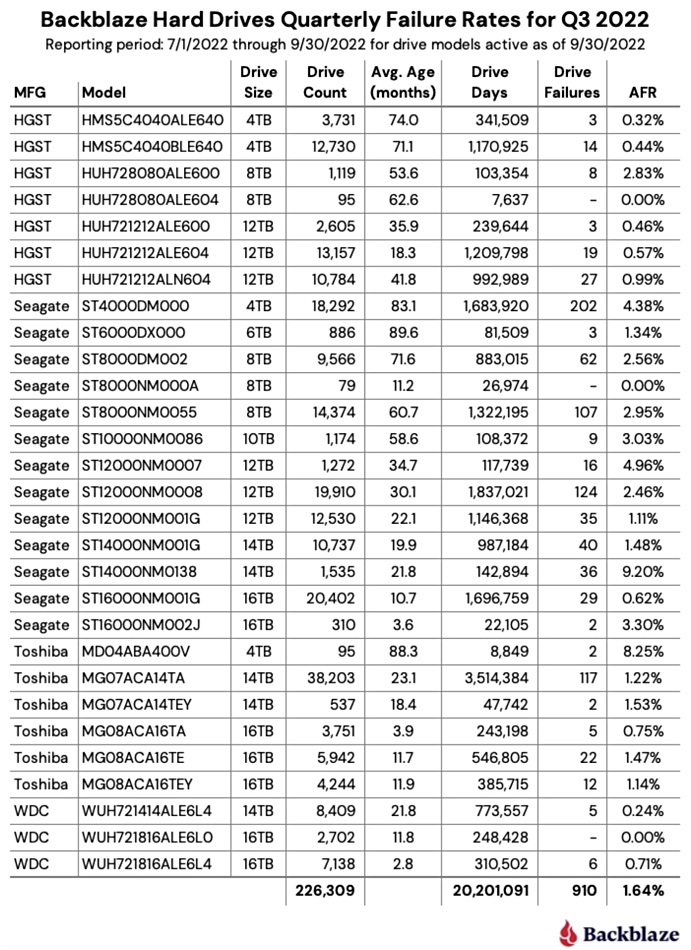
Google is introducing a SAN-like Cloud Hyperdisk persistent storage instance to its Cloud Platform, with separately tunable capacity and compute so compute-intensive VMs don’t have to be provisioned to get storage IOPS and throughput.
It says SAP HANA, SQL Server, data lake, modeling and simulation applications need a single storage entity providing object storage flexibility with file manageability and block access performance. The coming Google Cloud Hyperdisk block storage offering meets these requirements and will offer 80 percent higher IOPS per vCPU for high-end database management system (DBMS) workloads when compared to other hyperscalers.
Hyperdisk was previewed in September by Google, and is a next generation Persistent Disk type for use with Google Compute Engine (GCE) and Google Kubernetes Engine (GKE). In the preview Hyperdisk was mentioned along with the C3 machine series using Gen 4 Xeon SP processors and an Intel IPU customised for Google. The C3 virtual machines VMs with Hyperdisk will deliver four times more throughput and deliver a tenfold improvement in IOPS compared to the previous C2 instances.
Ruwen Hess, Product Management, Storage, at Google, presented Cloud Hyperdisk at an October 2022 Cloud Field Day event, and said: “We really thought about what does block storage for the cloud really, ideally, look like?”
“The feedback coming from customers was a lot around having it dynamically provisioned both performance wise and capacity wise, decoupled from instance, type and size. And with the ability to be dynamically adjusted over time, covering the full spectrum, all core workloads, and with each workload being able to change scale and other parameters, without suddenly getting efficiency or TCO checks.”
Because of this dynamic provisioning and instance decoupling, Google says, users don’t have to choose, aka over-provision, large compute instances to get the storage performance needed for Hadoop and Microsoft SQL Server data workloads.
There are three Hyperdisk types: Throughput, Balanced and Extreme, as a slide showed:

The Throughput variant is designed to deliver up to 3GBps bandwidth for scale-out analytics workloads and be cost-efficient. The Extreme offering provides more than 4.8GBps of throughput with 300,000+ IOPS and will have performance and latency SLAs. It is for high-end SQL Server, Oracle and SAP HANA-class workloads, as Hess said: “Where you just need the utmost performance and less price sensitivity, more of a focus on the performance facilities.”
The Hyperdisk Balanced scheme fits between these bandwidth and IOPS-optimized variants, with around 150,000 IOPS and 2.4 GB/sec throughput. Hess said: “We expect the the bulk of workloads will find that Hyperdisk Balanced is well covered in terms of the price/performance profiles, and so forth.”
Hyperdisk pooling
In time Hyperdisk pools will be provided, one per Hyperdisk variant, with the ability for management at scale, thin-provisioning, data reduction and policy-based management. That means customers won’t have to directly manage every Hyperdisk.
Hess said: “Hyperdisk will exist both as fully provisioned as persistent disk as today. And then later in 2023, we will also offer storage pools where customers can optionally put these volumes into the pools, where the pools will benefit from thin provisioning, data reduction, and management by policies, where you have possibly hundreds of instances with hundreds of 1,000s of disks.” Customers will have both options.
He said: “A storage admin will manage the storage pool and much like the managing a SAN today, where you have total capacity, you have buffer capacity, you have thin provisioning, [and] over time, we will also expose, not only capacity pooling, but also performance pooling. So, if you have a lot of instances, and most of them are idle, but sometimes they spike a bit, you’ll be able to stick them into a pool and benefit further down the road.”
Provisioning example
Hess provided a comparison between provisioning GCP persistent storage today and how it will look in the future with Hyperdisk:
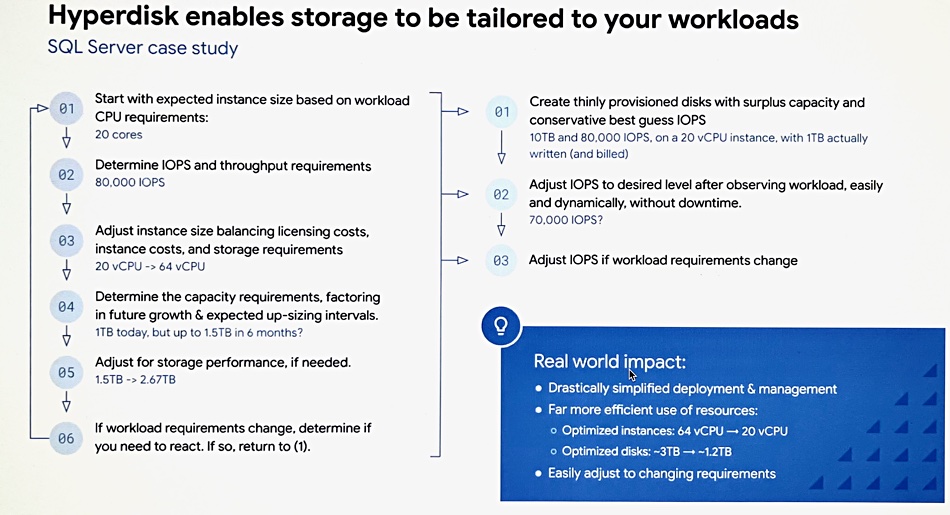
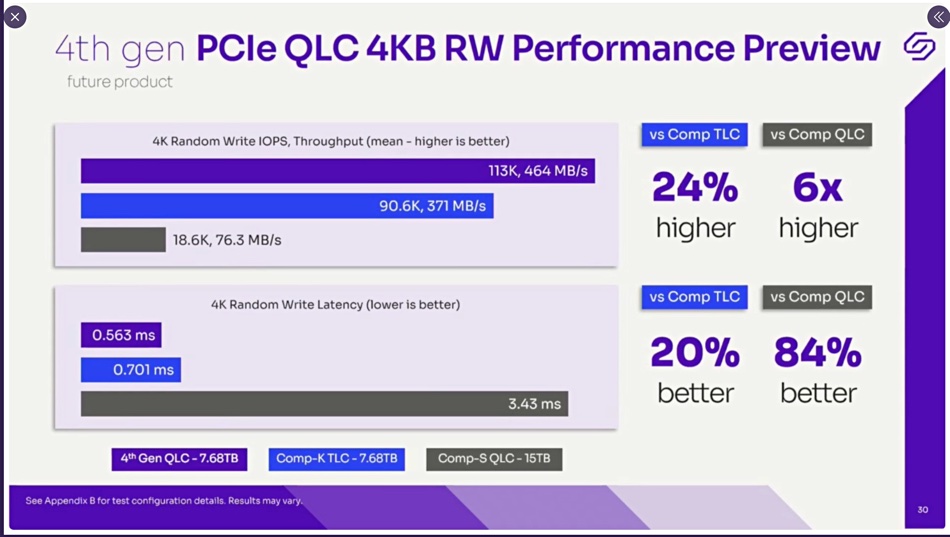
He outlined 6 steps needed to provision persistent storage for SQL Server today, wth manual resetting when changes occur, and contrasted that with 3 steps needed when Hyperdisk arrives. Today’s SQL Server set up requires, for example, a 64 vCPU instance whereas Hyperdisk will only need a 20 vCPU instance because it has decoupled storage performance from the VM instance type.

In more detail he said today’s scheme needed an 64-core N2 VM and 3.3TB of PD-SSD storage delivering 1.2GBps to provide 100,000 IOPS and 2TiB of capacity. Hess said: “You’re buying 3.3 terabytes to get to the 100,000 IOPS.” Switch over to Hyperdisk when it arrives and that changes to a 32-core N2 VM with 2TB of Hyperdisk Balanced capacity.
Because Hyperdisk can be dynamically tuned then it can be set up to provide 100,000 IOPS and 1.8GB/sec in office hours and 50,000 IOPS and 1GBps outside that period.
Hess said Hyperdisk will be developed so that: “over time, extending it into into workload-aware storage, where customers can set business level metrics that the system understands the workload level, say for SAP HANA rehydration plans and things like that.”
He specifically said more user-visible metrics were coming: “We are actually working on exposing more metrics, especially around latency, for block storage in general.”
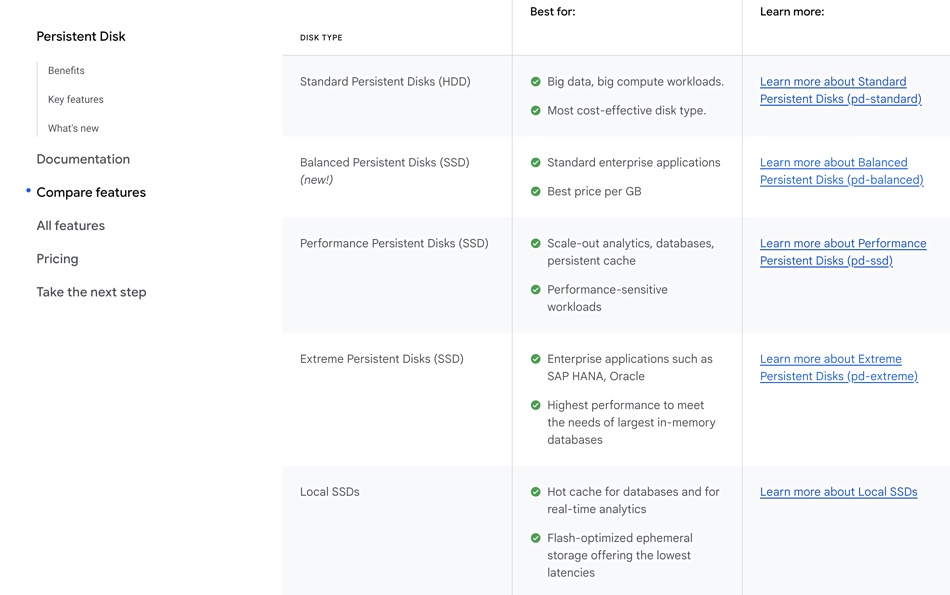
Hyperdisk is not yet listed in Google Cloud’s Persistent Disk webpage, and should be available early next year.
Azure has an Elasticated SAN offering for large scale, IO-intensive workloads and top tier databases such as SQL Server and MariaDB. Amazon has a Virtual Storage Array (VSA) construct in its cloud in which compute is presented as VSA controllers and capacity expressed as volumes which can use NVMe drives. As a source on the industry said: “It’s a tacit admission by the hyperscalers that there is a gap in their storage portfolios in this space; specifically, high-performance sharable block.”