


Israeli startup UnifabriX is demonstrating a CXL 3.0-connected Smart Memory device for data center and HPC memory pooling
The demo is taking place at SC22 and UnifabriX said it will involve both memory pooling and sharing, as well as performance measures. The aim is to provide multi-core CPUs with the memory and memory bandwidth needed to run compute/memory-intensive AI and machine learning workloads in data centers. Existing CPUs have socket-connected DRAM and this limits the memory capacity and bandwidth. Such limits can be bypassed with CXL memory expansion and pooling.
Ronen Hyatt, CEO and co-founder of UnifabriX, said: “We are setting out to showcase significant improvements and the immediate potential that CXL solutions have to upend HPC performance and close the gap between the evolution of processors and memory”
The company reckons its CXL-based products achieve exceptional performance and elasticity in bare-metal and virtualized environments over a wide range of applications, including the most demanding tasks.
UnifabriX was started in January 2020 by Hyatt and CTO Danny Volkind. Seed funding was provided by VCS and angel investors. Hyatt is an ex-platform architect in Intel’s Data Center Group who joined Huawei as a Smart Platforms CTO in 2018. He left to launch UnifabriX. Volkind was a system architect at Intel and was employed by Huawei as a Chief Architect. Both were at PMC Sierra before Intel and attended Israel’s Technion Institute of Technology.
CXL background
A UnifabriX white paper looks at CXL 1.1 and 2.0 differences, with CXL 1.1 supporting direct-attached memory devices to facilitate memory expansion, and CXL 2.0 adding remote memory device support via CXL switching. The switch allows multiple hosts to connect to a memory device and see their own virtual CXL memory resources. The memory device can be sub-divided into logical domains, each of which, or groups of which, can be assigned to a separate host. An external Fabric Manager controls the CXL switch or switches. This all supports dynamic memory expansion for servers by allocating them cache-coherent remote memory from the CXL pool.
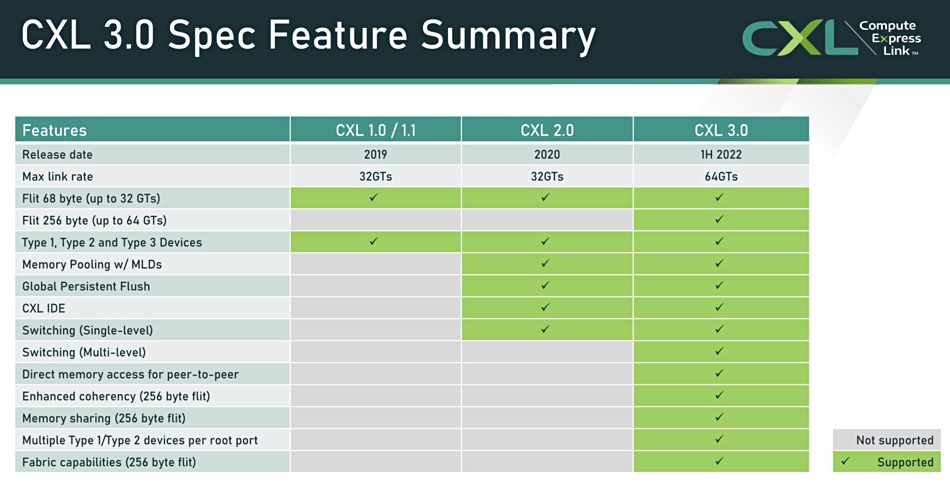
The memory devices may be pure memory or intelligent processors with their own memory, such as GPUs or other accelerator hardware. The CXL 3.0 standard uses PCIe gen 6.0 and doubles per-lane bandwidth to 64 gigatransfers/sec (GT/sec). It enables more memory access modes – sharing flexibility and complicated memory sharing topologies – than CXL 2.0.
In effect, CXL-connected memory becomes a composable resource. According to Wells Fargo analyst Aaron Rakers, Micron has calculated that CXL-based memory could grow into a $2 billion total addressable market (TAM) by 2025 and more than $20 billion by 2030.
Demo product

The SC200 demo is of a Smart Memory device powered by UnifabriX’ RPU (Resource Processing Unit) built from the silicon up with UnifabriX hardware and software. The RPU is described as an evolution of the DPU (Data Processing Unit) and is used to improve host CPU utilization, memory capacity and system-wide bandwidth. UnifabriX will demo enhanced performance related to all three items using a “recognized HPC framework.”
This Smart Memory Node is a 2 or 4 rack unit box with E-EDSFF E3 media bays and up to 128TB of memory capacity. The memory can be DDR5 or DDR4 DRAM, or NVMe-connected media.
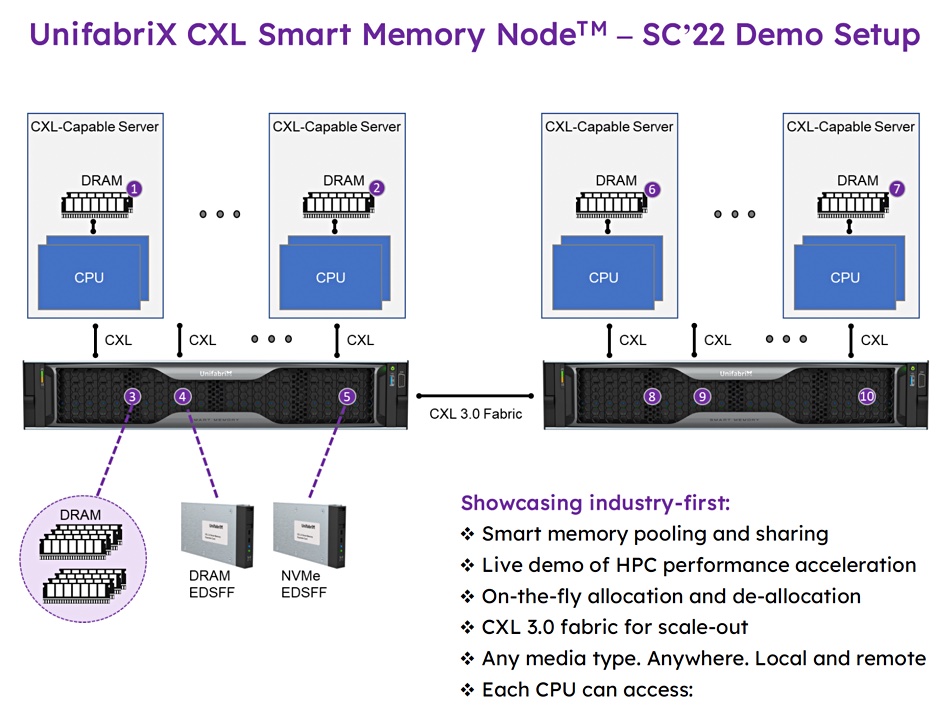
Access is via NVMe-oM (NVMe over Memory) and there can be up to 20 CXL FE/BE ports with node stacking via a BE Fabric. The box is compliant with CXL 1.1, CXL 2.0, PCIe Gen 5 and is CXL 3.0-ready. It has enterprise RAS (Reliability, Availability and Scalability) and multi-layer security.
Two such units will be connected across a CXL 3.0 fabric to several servers. This is said to be the first ever CXL 3.0 fabric. Hyatt said: “Setting out to achieve and document CXL-enabled performance in a real environment according to industry standard HPC benchmarking is a difficult task that we are excited to demonstrate live at SC22.”





