Nvidia is building an AI supercomputer called Eos for its own use in climate science, digital biology, and AI workloads. Eos should provide 18.4 exaFLOPS of AI performance and will be built using Nvidia’s SuperPOD technology. How will its data be stored?
Eos will have 576 x DGX systems utilizing 4,608 Hopper H100 GPUs. There are 8 x H100 GPUs per DGX and 32 x DGX systems per Nvidia SuperPOD, hence 18 SuperPODS in Eos. Each DGX provides 32 petaFLOPS. Eos should be four times faster that Fujitsu’s Fugaku supercomputer in terms of AI performance and is expected to provide 275 petaFLOPS of performance for traditional scientific computing.
Nvidia Eos graphic
This will need a vast amount of data storage to feed the GPU processors fast enough to keep them busy. It needs a very wide and swift data pipeline.
Wells Fargo analyst Aaron Rakers writes: “Each of the DGX compute nodes will incorporate two of NVIDIA’s BlueField-3 DPUs for workload offloading, acceleration, and isolation (i.e. advanced networking, storage, and security services).”
We can expect that the storage system will also use BlueField-3 DPUs as front-end NICs and storage processors.
We envisage that Eos will have an all-flash datastore providing direct data feeds to the Hopper processors’ memory. With promised BlueField-3 support, VAST Data’s scale-out Ceres enclosures with NVMe drives and its Universal Storage software would seem a likely candidate for this role.
Nvidia states: “The DGX H100 nodes and H100 GPUs in a DGX SuperPOD are connected by an NVLink Switch System and NVIDIA Quantum-2 InfiniBand providing a total of 70 TB/sec of bandwidth – 11x higher than the previous generation.”
Nvidia SuperPOD graphic
Rakers writes that data will flow to and from Eos across 360 NVLink switches, providing 900GB/sec bandwidth between each GPU within the DGX H100 system. The systems will be connected through ConnectX-7 Quantum-2 InfiniBand networking adapters running at 400Gb/sec.
This is an extraordinarily high level of bandwidth and the storage system will need to have the capacity and speed to support it. Nvidia says: “Storage from Nvidia partners will be tested and certified to meet the demands of DGX SuperPOD AI computing.”
Nvidia storage partners in its GPUDirect host server CPU-bypass scheme include Dell EMC, DDN, HPE, IBM (Spectrum Scale), NetApp, Pavilion Data, and VAST Data. Weka is another supplier but only provides file storage software, not hardware.
Providing storage to Nvidia for its in-house Eos system is going to be a hotly contested sale – think of the customer reference possibilities – and will surely involve hundreds of petabytes of all-flash capacity with, we think, a second-tier capacity store behind it. Candidate storage vendors will pour account-handling and engineering resource into this like there is no tomorrow.
Data storage management software biz Open-E has certified Kioxia’s FL6 NVMe SSD series with its flagship ZFS-based Open-E JovianDSS data storage software. A solution document has details.
…
Kioxia is sampling new Automotive Universal Flash Storage (UFS) Ver. 3.1 embedded flash memory devices with 64GB, 128GB, 256GB, and 512GB capacities. Both the sequential read and write performance of the Automotive UFS Ver. 3.1 devices are significantly improved by approximately 2.2x and 6x respectively over previous generations. These performance gains contribute to faster system startup and over-the-air updates. Kioxia is providing no other details of the device. In January it was sampling a UFS phone memory card using QLC flash. Kioxia fab partner Western Digital announced a Gen 2 UFS 3.1 drive in June last year with 128, 256, and 512GB capacities.
…
Dr James Cuff
FabreX composable systems supplier GigaIO has hired Dr James Cuff as chief of scientific computing and partnerships. He will be tasked with helping design composable architectures that function at scale and will support and extend GigaIO’s technical, scientific computing platforms and services. Cuff took early retirement as the Assistant Dean and Distinguished Engineer for Research Computing from Harvard University in 2017.
“This is a true tipping point in our community and it is hard to fully explain how important and game-changing these current and future architectures we will build for our community at GigaIO will turn out to be. It is a once-in-a-lifetime opportunity to properly disrupt the industry, in a good way,” said Cuff.
…
Research house TrendForce says overall NAND Flash supply has been significantly downgraded in the wake of raw material contamination at a Kioxia and Western Digital fab in early February, becoming the key factor in a predicted 5-10 percent NAND Flash price appreciation in 2Q22.
…
Cloud file data services supplier Nasuni has announced support for the AWS for Games initiative with Nasuni for Game Builds. It uses S3 object storage as the back-end cloud, with file services built on top, and enables game developers and quality assurance testers to share and collaborate with teams around the globe on complex game builds. AWS for Games is an initiative featuring services and solutions from AWS and AWS Partners, built specifically for the video game industry.
…
Pavilion Data Systems announced technology enabling Windows customers to take advantage of NVMe-oF using NVMe/TCP or NVMe/RoCE drivers supported through the Microsoft WHQL program. Pavilion’s NVMe/TCP initiator provides seamless integration with existing Ethernet-based networks with 50 percent lower latency than current iSCSI deployments. Pavilion is also shipping a WHQL-certified NVMe/RoCE v2 initiator in conjunction with partner StarWind Software. NVMe/RoCE allows for a client to directly access an application’s memory bypassing the CPU and avoiding complex network software stacks to further improve application performance.
…
Vcinity, which provides global access to file data, has announced Vcinity Access. It has an S3 API and enables cloud-native applications that use Amazon S3 or S3-compliant object storage to remotely access and instantly operate on that data across hybrid, distributed, or multi-cloud environments, with local-like performance. It claims this eliminates the need to move or copy data to the cloud, between cloud regions, or between S3 buckets.
Samsung and Western Digital are allying to standardize and drive broad adoption of next-generation zoned SSD data placement, processing and fabrics (D2PF) storage technologies.
The pair will initially focus on jointly creating a vigorous ecosystem for zoned storage solutions. They want to encourage a range of collaborations around D2PF technology standardization and software development. The intent is that end users can have confidence that zoned technologies will have support from multiple device vendors and from vertically integrated hardware and software companies.
Robert Soderbery
Rob Soderbery, EVP and GM for Western Digital’s Flash Business Unit, said in a statement: “For years Western Digital has been laying the foundation for the zoned storage ecosystem by contributing to the Linux kernel and open-source software community. We are excited to bring these contributions to this joint initiative with Samsung in facilitating wider adoption of zoned storage for users and application developers.”
Jinman Han, Head of Memory Sales & Marketing at Samsung Electronics, added: “Our collaborative efforts will embrace hardware and software ecosystems to ensure that as many customers as possible can reap the benefits of this highly important technology.” He said the collaboration “will actively grow into a larger basis of engagement for zoned storage standardization.”
Zoning diagram with traditional SSD data placement on the left and zoned placement on the right. This instance uses drive-managed zoning as the SSD firmware layer indicates
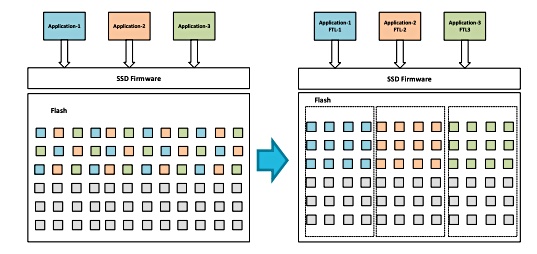
A zoned SSD has its capacity divided into separate areas or zones which are used for data with different IO types and characteristics – read-intensive, write-intensive, mixed, JPEGs, video, etc. The traditional Flash Translation Layer (FTL), which normally manages data placement on the drive, is not used. Data can only be appended to existing data in a zone, being written sequentially. Typically small writes are aggregated together (batched up) by the zone management software into a 4KB chunk and written in a single operation to the drive. A zone must be erased for its cells to be rewritten.
The zone management and data placement software can be located in a host server and acts as the SSD front-end software instead of a drive-resident FTL. A WD zoned storage website contains more information.
Samsung PM1731a zoned SSD
Samsung announced its PM1731a zoned namespace SSD in June last year, its first such device. Western Digital was earlier into the zoned SSD game with its ZN540 in November 2020.
WD sees zoned namespaces applying to its shingled magnetic recording (SMR) disk drives as well as SSDs, a technology sector in which Samsung does not participate.
Samsung and Western Digital say they will define high-level models and frameworks for next-generation zoned storage technologies through organizations such as the Storage Networking Industry Association (SNIA) and the Linux Foundation. Inside the SNIA they have already founded the zoned storage Technical Work Group, which was approved in December 2021. This group, which also has NetApp and Microsoft as members, is defining and specifying common use cases for zoned storage devices, as well as host/device architecture and programming models.
Samsung and WD want to expand zone-based (e.g. ZNS, SMR) device interfaces to future-generation, high-capacity storage devices with enhanced data placement and processing technologies. They also see expansion possibilities to computational storage and storage fabrics including NVMe over Fabrics (NVMe-oF), which they call emerging D2PF technologies.
Comment
Samsung has no product interest in having D2PF apply to SMR disk drives; it doesn’t make HDDs. That part of the Samsung-WD initiative will need Seagate and Toshiba co-operation for D2PF (host-managed) SMR disk drives to have a standardized interface across vendors.
In order for the Samsung-WD D2PF initiative to be used across the SSD industry, it will need other SSD suppliers and controller suppliers, such as Phison, to join in. That basically means getting Kioxia – which could be likely as it is a WD NAND fab partner – Micron and SK hynix on board as well. If these join the SNIA zoned storage work group, zoning could become an SSD industry standard. Having a hyperscaler vendor or two join in would help as well since they buy thousands of SSDs annually and would need to alter their software to use zoned SSDs.
Mobile devices was the one weak spot in Micron‘s second quarter of fiscal 2022 ended 3 March – datacenter, automotive, and storage DRAM and NAND all grew briskly otherwise
Revenues for the quarter jumped 25 percent year-on-year to $7.79 billion, and Micron reported a profit of $2.26 billion compared to a loss $603 million a year earlier. DRAM contributed the bulk of revenue, at $5.72 billion, 29 percent up on the year, with NAND at $1.84 billion and growing at 19 percent.
In his prepared remarks, president and CEO Sanjay Mehrotra opined: “Micron delivered an excellent performance in fiscal Q2 with results above the high end of our guidance.” He added: “We saw broad-based demand for our products, with our SSD products achieving record revenue, and our auto market revenue also reaching an all-time high.”
Of course there were supply chain issues, due to COVID-19 and Russia’s invasion of Ukraine, but Micron sees no impact from these it can’t handle. “We currently do not expect any negative impact to our near-term production volumes because of the Russia-Ukraine war,” the CEO said.
Mehrotra said Micron is well placed in the market. “Demand for memory and storage is broad, extending from the datacenter to the intelligent edge and to a growing diversity of user devices. Memory and storage revenue has outpaced the rest of the semiconductor industry over the last two decades, and we expect this trend to continue over the next decade, thanks to ongoing advancement of AI, 5G and EV adoption” – EV meaning electric vehicles.
He said the AI trend is also a positive for the company. “Memory and storage share of server BOM costs already exceeds 40 percent and this number is even higher for servers optimized for AI/ML workloads.”
Micron has four business units. The largest is compute and networking, which pulled in $3.46 billion, up 31 percent year-over-year, as servers needed more DRAM and NAND. Micron says its 1z and 1α DRAM represented the majority of its DRAM bit shipments, while 176-layer NAND accounted for the majority of its flash. It also leads the industry, it claims, with DDR5 memory.
The next largest BU is mobile and this looked stagnant in comparison – $1.875 billion in revenue, up just 4 percent annually. Weaker results in China and some increased phone vendor inventories were mentioned as contributing to this.
The embedded unit, mostly automotive sales, rose 37 percent to $1.277 billion, while the storage unit’s revenues rose 38 percent to $1.71 billion. In the storage unit Micron is making good progress in its qualifications of 7450 NVMe SSD with datacenter customers, “which has contributed to a doubling of our fiscal Q2 data center SSD revenues year over year.”
Micron forecast a boom in the automotive and industrial embedded market, with Mehrotra saying: “The automotive and industrial segments are expected to be the fastest-growing memory and storage markets over the next decade.” Automotive sales of both DRAM and NAND set a new record for Micron in the quarter.
“We expect over 100 new EV models to launch worldwide in this calendar year alone. These new EVs include advanced ADAS and in-vehicle infotainment features that have significantly higher memory and storage requirements. In fact, some of these level-3 autonomous EVs have about $750 in memory and storage content, which is 15 times higher than the average car.”
There was 60 per cent year-over-year growth in industrial IoT with demand for factory automation and security systems.
The outlook for the next quarter is revenues of $8.7 billion, plus or minus $200 million, a Micron record for quarterly revenues, and a 17.3 percent year-over-year increase. Mehrotra said: ”We are on track to deliver record revenue and robust profitability in fiscal 2022 and remain well positioned to create significant shareholder value in fiscal 2022 and beyond.”
One thing to note: Wells Fargo analyst Aaron Rakers told subscribers Micron thinks it can meet the bit capacity demands out to 2025 for DRAM and NAND with DRAM node and NAND layer count transitions, at which point new fab capacity could be needed.
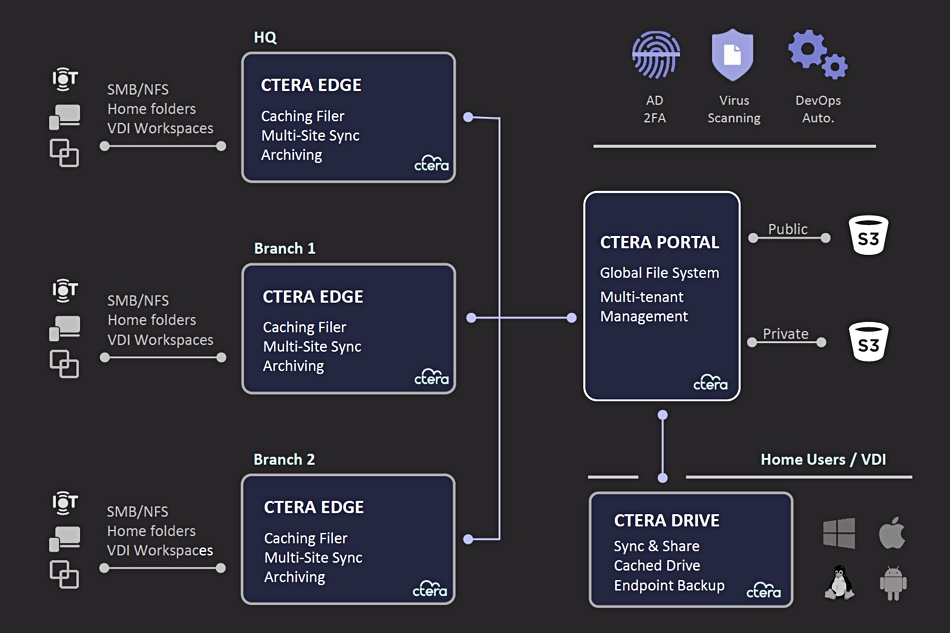
CTERA is hooking its edge filers up to Backblaze’s object store in the cloud to give users file access and collaboration services, claiming it makes NAS filers redundant.
CTERA provides distributed file-based unstructured data management services using local cache systems or edge filers, connected to a central object store. IBM COS File Access is a rebranded version of the CTERA file system using IBM’s Cloud Object Storage as its central repository. HPE makes CTERA services available via GreenLake, building on CTERA’s integration with the Nimble dHCI and SimpliVity HCI products. Now CTERA is repeating these kind of deals with Backblaze, using its B2 S3-based cloud object storage.
Oded Nagel, chief strategy officer at CTERA, said: “We’re seeing a massive shift from traditional NAS to cloud NAS, from edge to core access, as organizations evolve and expand.” He added that the Backblaze-CTERA partnership is a new cost-effective storage option for companies wanting to tier their data to the cloud for redundancy and collaboration.
CTERA graphic
Nilay Patel, VP of sales at Backblaze, was punchier: “You’ll never have to – or want to – upgrade your NAS again.”
Why? “If you’re tired of buying new equipment every three years, replacing hard drives, paying for maintenance or power or space in a datacenter, and all of the headaches of managing remote user access, then the CTERA and Backblaze partnership is perfect for you. The setup is incredibly easy and the immediate budget and staffing relief will give you resources to tackle new opportunities.”
The CTERA-Backblaze combination provides a global filesystem that can:
Expand the capacity of existing on-premises infrastructure
Retire legacy file servers and NAS devices altogether
Provide multi-site collaboration
Establish disaster recovery and business continuity plans
Back up data distributed globally in one centralized store, while maintaining instant (via CTERA’s Edge Filers) and reliable access (via Backblaze’s 99.9 percent uptime SLA)
Deliver pay-as-you-go cloud storage pricing for a quarter of the price of equivalent offerings (like AWS S3)
The CTERA-Backblaze combo is roughly equivalent to Nasuni’s cloud-based file services offering, and also to similar cloud-based distributed file access and collaboration services from Egnyte and Panzura.
However CTERA relies more on partners, like IBM, HPE, and now Backblaze, to provide a central storage repository around which it can cluster its edge filers. Effectively, CTERA’s edge filer/cloud services gateway provides a ring of edge filers around some kind of central core, which is supplied by a third party.
This limits the amount of integration possible between the edge systems and the partner cloud core systems because they come from different design centers, have different code bases, and were not architected together. But it means CTERA can sell in partnership with third parties like IBM, Backblaze, and HPE, whereas Nasuni, Egnyte, and Panzura are more limited in that regard.
In March last year CTERA said it was re-architecting its software to be cloud-native, and turning it into microservices.
Comments by VAST Data co-founders CEO Renen Hallak and CMO Jeff Denworth suggest the company is going to develop data infrastructure software that can help fulfill the vision of long-defunct supercomputing outfit Thinking Machines.
This is a long way on from just storing bits of data in the clever way that VAST’s Universal Storage accomplishes.
Hallak’s thinking
Renen Hallak
In May last year Hallak told a writer from Protocol Enterprise that VAST wants to run its own data science platform, with a trajectory he says will pit it against vendors including Databricks.
“We think that five years from now… that infrastructure stack needs to be very different. It needs to enable AI supercomputers rather than the applications that we have in the past… Vertical integration adds to simplicity. But more than that, it allows you to take full advantage of the underlying technology.”
Hallak implied that VAST Data would seek to build most of the platform itself: “It would not be possible for us to just buy someone else… and strap it on top of our system. We always lean towards doing the critical parts ourselves. And if there are any peripherals that aren’t as important… then maybe there would be room for acquisitions.”
“There is a massive opportunity to compile different data services into one product suite,” he added.
Denworth’s prognostications
Denworth told Computer Weekly in November last year: “In the next 20 years we’ll see a new class of application. It won’t be about transactional data, it won’t be about digital transformation. What we’ll see is computing coming to humans; seeing, hearing, and analyzing that natural data.
“We are conscious of not computing in one datacenter, and using unstructured and structured data. We are also conscious that data has gravity, but so also does compute when you get to the high end.”
This will mean a new computing framework with “very ambitious products” to be announced by VAST.
In January, Denworth told The Next Platform: “Thinking Machines was a very bespoke supercomputing company that endeavored to make some really interesting systems and over time. That’s ultimately what we’re going to aim to make: a system that can ultimately think for itself.”
He added: ”We realized that we could take that far beyond the classic definitions of a file system, but the realization was that the architecture that has the most intimate understanding of data can make the best decisions about what to do with that data. First by determining what’s inside of it. Second of all, by either moving the data to where the compute is or the compute to where the data is, depending upon what the most optimized decision is at any given time.”
The Beeler video podcast
Denworth told Brian Beeler on a Storage Review video podcast: “The next 20 years could [see] something that we call the natural transformation, or computers start to adapt to people… Our realization is if you rethink everything at the infrastructure level, there are gains that can be realized higher up the stack that we will take the world to over the next couple years.”
“Computers are definitely at a point where they can now do the sensory part of what humans could do before; they can see, they can hear, they can probably not smell so much, but understand natural information closer and closer to the way that humans understand it. And I think the leap again, from that to having thinking machines, may be a big one, maybe a smaller one. But once you get to a thinking machine, it’s game over, you don’t need anything beyond that.
“And so I think it’s justified, that we’re putting all of our resources at building infrastructure that is enabling that next wave. And I think we will be surprised at how far we can take this in terms of what’s possible.”
He talked about organizations working in different parts of the stack: “We have, obviously the hardware vendors working on GPUs, we have vendors like us working on that middle of the sandwich infrastructure part and software, we have the application vendors working on life science, genomics, medical imaging, we have financial institutions, taking advantage of all types of information coming into their systems, it’s really exciting.”
Data arrival is going to be driving activity: “I think things are getting flipped on their head if before you had an application, and it was reading data, either from memory or from storage, in order to manipulate it, and then it was writing the result that it understood to be the case, I think the more and more we’re going to see data driven applications, the data itself as it flows into the system will trigger functions that need to be run on it based on different characteristics of that information.
“And then you’ll have recursion of more and more functions that need to be run as a result of what we understand on this specific piece of information as we compare it to the rest of the data that we already have stored specifically with respect to GPUs,” said Denworth.
“I think the fact that we’re called VAST data is a big clue. We are trying to build that next generation of data infrastructure.
“People will see us expand in the storage space and get closer and closer to realizing the true vision of universal storage of our customers not needing to think about where they placed their data and how much access they have to it, and what can be done with it.
“And in parallel, you’ll see more and more not necessarily storage parts coming from us as well, based on feedback that we get from customers.“
VAST will “essentially work to help customers solve the whole of their data processing, machine learning deep learning problem in a hybrid cloud world, in a way, where we just take not just the complexity of tiering and things like that as considerations and take them off the table… And this seems to [be] becoming more and more popular, as people start to understand some of these natural language processing models, some of these new computer vision, or computer audio models. And so that’s, that’s pretty exciting. We’ve got a lot that we’re doing with Nvidia.”
Thinking Machines and Databricks
Thinking Machines was a supercomputing company started in 1983 to build highly parallel systems using that era’s artificial intelligence technology. The aim was to chew through masses of data much more quickly than serial computing and so arrive at decisions in seconds or minutes instead of days or weeks.
The company over-reached itself and crashed in 1994, with parts being bought by Sun Microsystems. Its architecture typically required a front-end server, and back-end Sparc CPUs and vector processors
In February last year Blocks & Files wrote: “Databricks enables fast SQL querying and analysis of data lakes without having to first extract, transform and load data into data warehouses. The company claims its ‘Data Lakehouse’ technology delivers 9X better price performance than traditional data warehouses. Databricks supports AWS and Azure clouds and is typically seen as a competitor to Snowflake, which completed a huge IPO in September 2020… Databricks’ open source Delta Lake software is built atop Apache Spark.”
The VAST future
VAST Data is going to build a data infrastructure layer vertically integrated with its existing storage platform to form what today would be called an AI supercomputer. This layer will provide data lake capabilities and be able to initiate analytics processing itself; the data as it flows into the system will trigger functions that need to be run on it.
VAST CTO Sven Breuner previously confirmed this, saying VAST will link customer’s separate VAST systems together: “It’s now time to start moving up the stack by integrating more layers around database-like features and around seamlessly connecting geo-distributed datacenters.”
We think that VAST will use a lot of Apache open-source software, such as Spark like Databricks, Druid like Imply, and Kafka like Confluent.
VAST is looking at hearing, speech, and vision applications and will use Nvidia hardware, such as the Grace and Hopper chip systems. We are sure that penta-level cell flash and the CXL bus will play a part in VAST’s storage and infrastructure roadmap.
It will present its IT infrastructure systems, both on-premises and in the public cloud – in a bid to help customers solve all of their data processing and deep learning problems in a hybrid cloud world. We think VAST will not port its Universal Storage software to the public cloud. The Cnode software could be ported easily but the Dnode structure (storage-class memory drive front end with NVMe QLC SSD backend drives) could be hard to replicate with the appropriate storage instances in the public cloud.
B&F thinks it’s likelier there will be a VAST system in a public cloud available to the CSP’s customers directly or indirectly.
Our understanding is that VAST will announce its 10-year roadmap direction at an event later this year.
Cisco’s HyperFlex hyperconverged system is embracing disaggregated storage. A HyperFlex iSCSI feature can provide storage outside of the HyperFlex cluster. This makes it equivalent to HPE Nimble’s DHCI design. It’s said to be suitable for Windows failover clustering, Oracle database and Oracle RAC, and Microsoft Exchange. The HyperFlex iSCSI feature is available from Cisco HyperFlex HX Data Platform Release 4.5 and higher.
…
The Aerospike Real-time Data Platform is now certified with Red Hat OpenShift for Aerospike Kubernetes Operator 2.0 and enables OpenShift customers to deploy Aerospike in a familiar and standardized environment. Google Cloud Platform customers will have access to the Aerospike Cloud Managed Service to manage and maintain their Aerospike Real-time Data Platform.
…
MLOps provider Iguazio says Latin America airlines group LATAM has selected its MLOps platform for a large scale, cross-company AI project. The use cases include optimizing and safeguarding the company’s frequent flyer program from fraud, improving pilot training through better understanding of the factors that create un-stabilized approaches to landing, and intelligent route planning to reduce CO2 emissions. LATAM works extensively with GCP, utilizing tools like Google Big Query, Google Cloud Storage and Google Workload Identity. Iguazio is fully compatible with GCP and has a strong partnership with Google. LATAM is planning to deploy its AI products on GCP using Iguazio.
…
Hyperscale data analytics storage provider Ocient has announced a partnership with Basis Technologies for its next-generation campaign forecasting, inventory analysis, and bid shading solution. With the implementation of Ocient, Basis Technologies says it was able to consolidate 10 workloads on a single cluster, decreasing time to query from 24 hours to minutes or less, and reduce system costs by 30 percent. Basis has 30 billion auction records, over 100 billion rows in the system, and over 5 trillion data points in some columns in its NoSQL database.
…
Kubernetes-native data platform provider Ondat is teaming up with SUSE to deliver management of digital authentication credentials (secrets management) in Kubernetes to protect access to sensitive data for SunnyVision, a data center infrastructure service provider. With SUSE Rancher and built-in Trousseau, SunnyVision can now use the native Kubernetes way to store and access secrets by plugging into Hashicorp Vault using the Kubernetes KMS provider framework. No additional changes or new skills are required.
…
Pure Storage has published its inaugural Environmental, Social, and Governance (ESG) report, which provides visibility into the company’s current metrics and sets commitments for the future. As part of this ESG report, Pure conducted a product life cycle assessment (LCA) of its portfolio, specifically the FlashArray products, which found that Pure customers achieve up to 80 percent reduction in direct carbon usage by data systems compared to competitive products. Pure said it is committing to several goals to reduce its own carbon footprint, making progress against Scope 1, 2, and 3 emissions, focused both on company operations and the use phase of Pure products:
50 percent intensity reduction in market-based Scope 1 and 2 greenhouse gas (GHG) emissions per employee from FY20 to FY30
Achieve net zero market-based Scope 1 and 2 emissions by FY40
66 percent intensity reduction in use of sold products from Scope 3 emissions per effective petabyte shipped from FY20 to FY30
In-memory computing supplier ScaleOut Software has announced support for Redis clients in ScaleOut StateServer Version 5.11 as a community preview. Redis users can use the company’s flagship distributed caching product to connect to a cluster of ScaleOut servers and execute Redis commands. Unlike open-source Redis, ScaleOut StateServer implements fully consistent updates to stored data. In addition, ScaleOut StateServer’s native APIs run alongside Redis commands and incorporate advanced features, such as data-parallel computing, streaming analytics, and coherent, wide-area data replication that are not available on open source Redis clusters.
…
SingleStore has hired Shireesh Thota as senior veep for engineering. Thota will lead the company’s engineering efforts and oversee the design and development of the SingleStore DB product. Yatharth Gupta will head up product management and design as veep of products and growth. Both Thota and Gupta will report directly to CEO Raj Verma. Thota previously ran the engineering ops for Cosmos DB and Postgres Hyperscale (Citus) services at Microsoft, where he worked in multiple roles for more than 15 years.
…
Snowflake today revealed an extension of its relationship with Amazon Web Services intended to improve demand forecasting and delivery for the retail and consumer packaged goods (CPG) industries. The partnership means that retail brands and CPGs can process, analyse and syndicate data from a multitude of sources through Snowflake’s integrated platform, without the delays of traditional methods which require copying and moving data, Snowflake says. Customers will also have access to new data from third-party data providers within Snowflake’s Retail Data Cloud.
…
ELITE SO-DIMM DDR5 rolls out
Taipei-based TEAMGROUP has released its ELITE SO-DIMM DDR5 Standard Memory, which runs at the all-new ultra-high clock speed of 4,800MHz – is up to 50 percent higher than DDR4’s maximum of 3,200MHz. It comes in both single and dual-channel kits. The ELITE SO-DIMM DDR5 Standard Memory is a good choice for laptop users looking for a large performance upgrade without hassle, or so TEAMGROUP says.
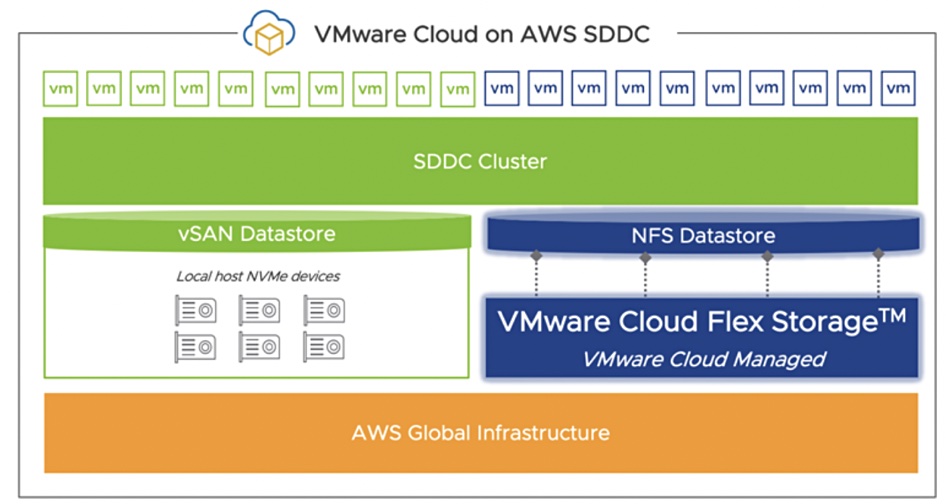
VMware is previewing a managed Cloud Flex Storage file service for VMware Cloud on AWS, based on its Datrium acquisition.
Cloud Flex Storage is a pay-as-you-go, elastic and scalable storage and data management service with cloud-native abstractions. It is set up and operated by customers through the VMware Cloud Services Console. A preview early access program will allow customers to independently provision and scale storage capacity external to the VMware Cloud on AWS SDDC hosts.
CTO Marc Fleischmann says in a blog that customers need consistent cross-cloud consumption and management of data across the entire data life cycle and “that’s where Cloud Flex Storage comes in.“
VMware Cloud Flex Storage diagram
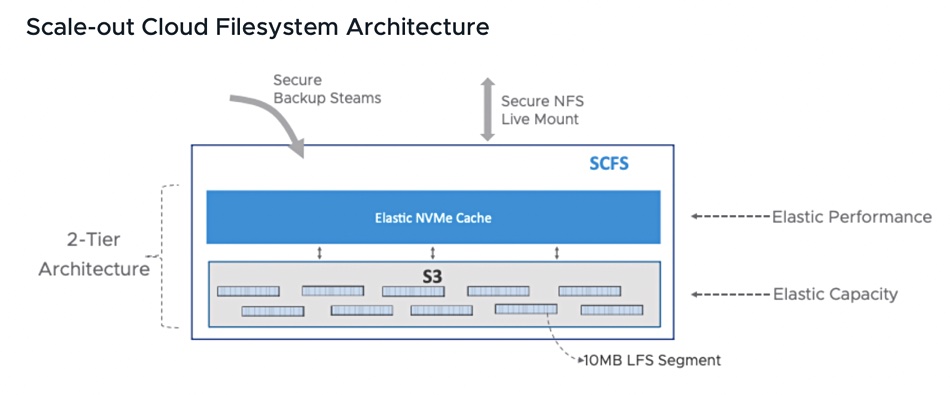
It is based on Datrium’s Distributed HyperConverged Infrastructure technology in which hyperconverged nodes running storage controller software are linked to an external shared storage pool. This has a Scale-out Cloud File System (SCFS) with a two-tier design that allows for independent scaling of storage performance and capacity, using a Log-Structure Filesystem (LFS) design.
A blog by VMware chief technologist Sazzala Reddy, co-founder of Datrium, says SCFS uses AWS EC2 with local NVMe drives for IO performance as a cache tier, and S3 to store all data in an object-based capacity tier. It features snapshots and immutability.
Sazzala Reddy’s SCFS diagram
VMware’s SCFS use cases up to now have been backup, disaster recovery, and ransomware protection. It is used in VMware’s DRaaS with VMware Cloud on AWS product. Now SCFS is being extended to the primary storage situation, with Cloud Flex Storage, providing file-based storage complementing the vSAN block storage.
There are three additional use cases: cloud migration, data center extension, and storage-intensive workload scaling. Customers running certain workloads on VMware Cloud on AWS using local instance storage with VMware vSAN may have other workloads that are storage bound. They can now have disaggregated Cloud Flex Storage for them.
In a migration scenario VMware says Cloud Flex Storage supports the lift and shift of virtual machines without any need to rework the data layer or re-architect the storage design. The datacenter extension example includes short-term burst capacity, on-demand scaling for data analytics, or long-term storage of data repositories in the cloud.
VMware says the Cloud Flex Storage roadmap includes making it available on multiple clouds, with cost-effective multi-AZ and regional availability. It also wants to enable multi-dimensional scaling of compute, performance, and storage capacity, and add enterprise-grade data management and data reduction capabilities.
Wasabi has announced the opening of its new storage region in Toronto to provide closer proximity to customers and partners in North America. The Toronto location is Wasabi’s 11th overall following recent expansions into Frankfurt, Paris, and London. It is housed in an Equinix Toronto datacenter.
…
Data protection supplier Acronis has become West Ham United Football Club’s official cyber protection partner, providing integrated data protection and cybersecurity. Global distributor Ingram Micro will support the partnership as Acronis’s #CyberFit Partner. Nathan Thompson, Commercial Director at West Ham United, trilled: “Protecting our data, which includes that of our supporters, is of the highest priority for us and Acronis is the perfect partner to help us do so.” We would have thought winning football matches was West Ham’s highest priority but what do we know?
…
Marketeers at the Svalbard coal mine-based Arctic World Archive have come up with a PR stunt – “Digital art and NFTs deposited for eternity in the Arctic World Archive.” They say some NFTs are at risk of being lost in the digital ether. By securing the digital art on a physical media in a sustainable vault in the Arctic, the information is secured from being lost or stolen. Top Dog Studios established the Non-Fungible Vault to offer artists and collectors a secure way of storing their valuable digital assets and keeping it accessible for future generations. Over 70,000 unique pieces of art will be stored, having traded for over $5.9bn on the Ethereum blockchain.
Top Dog NFT deposit ceremony at the AWA
…
Tokyo University researchers have identified a fix for an MRAM issue. They say Spin-Orbit Torque RAM (SOT-RAM) can use even less power than Spin Transfer Torque RAM (STT-RAM) but the read path in SOT-RAM shares part of the write path, which can can unintentionally flip the stored bit’s value. The researchers created a bi-directional read path to fix the problem. A video describes what they did and an IEEE Xplore paper explains their research.
…
Samsung has released a Scalable Memory Development Kit (SMDK) v1.0, which consists of a basic SMDK allocator, kernel, and a guide providing an example workload test. It was developed for Samsung’s CXL (Compute Express Link) Memory Expander to enable a full-stack software-defined memory system and is a collection of software tools and APIs that sit between applications and the hardware. A host server’s main memory and the CXL Memory Expander can be adjusted for priority, usage, bandwidth, and security, or simply used as is. More data on GitHub.
Samsung CXL Memory Expander
…
US private healthcare software provider Epic is supporting Microsoft Azure partner Silk(database acceleration software) to migrate Electronic Health Records (EHR) to Azure. Matt Douglas, Chief Architect at Sentara Health, which runs 12 hospitals in Virginia and North Carolina, said: “The performance of Silk on Azure could not be met by any other cloud solution for our most intense workloads, including our EHR.” A Microsoft blog says more.
…
Cloud data warehouse provider Snowflake has announced the launch of the Retail Data Cloud, providing a bespoke data-sharing platform to suit the needs of customers in the retail space. The Retail Data Cloud empowers retailers, manufacturers, distributors, consumer packaged goods (CPG) vendors, and industry technology providers, to leverage their own data, access new data, and collaborate across the retail industry. It follows the recent debut of Snowflake’s health services cloud.
NetApp grew all-flash array sales faster than Pure Storage and to a higher revenue share in 2021’s fourth calendar quarter, according to Gartner research. The all-flash array market grew more rapidly than the primary and secondary storage markets, as well as the backup and recovery market.
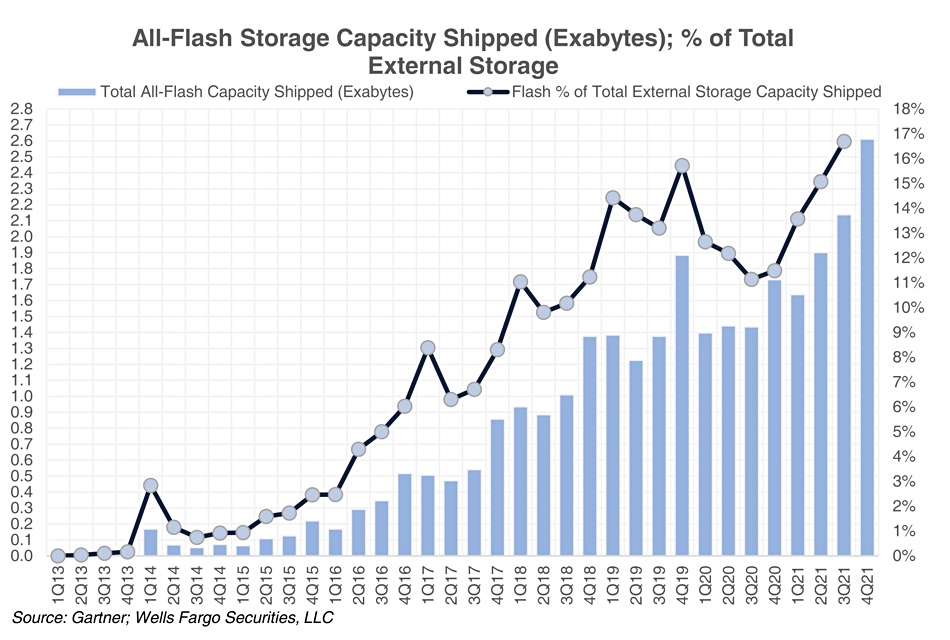
Gartner has issued a report to subscribers about the external storage market in the final three months of last year, and we caught a partial glimpse courtesy of Aaron Rakers, Wells Fargo analyst – meaning hardly any actual revenue numbers and mostly percentages.
Supply chain disruptions, according to Gartner, shrank the total external storage market by 2 per cent year-on-year. Within the total market, all-flash arrays (AFAs) grew 14 percent, compared to hard disk drive (HDD) and hybrid flash/disk arrays falling 14 percent. The primary storage market declined 3 percent, secondary storage saw no change, but the backup and recovery market grew 2 percent.
AFAs represented 64 percent of all primary arrays sold and 14 percent of secondary arrays.
Capacity shipped in the total external array market declined by 6 percent year-on-year and the AFA capacity percentage of the total storage market grew from 11.5 percent in Q4 2020 to 18.4 percent in the latest Q4.
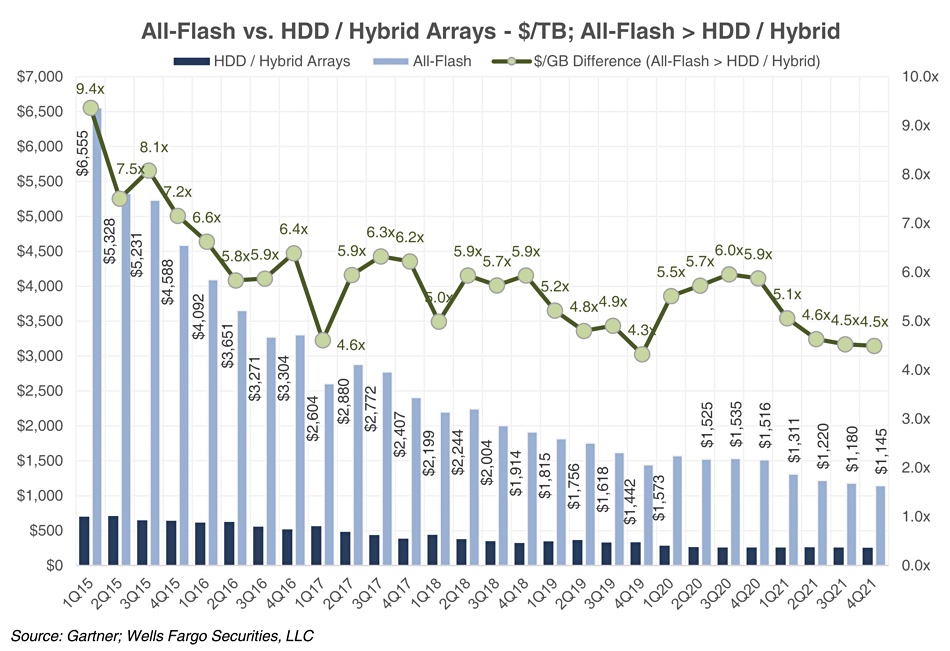
The cost differential in $/GB terms between AFAs and HDD/hybrid arrays was around 4.5x, down from 5.9x a year ago:
Dell EMC led the AFA market in the quarter, with a 23.7 percent market share at $708m. This was lower than its year-ago 26.7 percent share. Dell EMC also saw its leading total external storage market revenue share decline to 24.8 percent in 4Q 2021 from 27.3 percent a year earlier.
NetApp, on the other hand, increased its total storage revenue share from 11.5 percent to 11.8 percent year-on-year. Its AFA market revenue share rose to 17.1 percent or $511m, up 15.6 percent. In fact, AFA revenue represented 73 percent of NetApp’s storage revenues, higher than the 59 percent from a year ago.
Pure Storage, which only sells flash-based systems, increased its AFA market revenue to $453m, taking its share to 15.2 percent versus 14.2 per cent in Q4 2020. Rakers wrote: “Pure saw by far the largest storage capacity growth y/y in percentage terms at +60 percent vs. the overall market declining 6 percent y/y.”
Huawei had the next largest revenue share of the AFA market at 13 percent or $349m, unchanged from a year ago. This was followed by IBM with an 11 percent share, taking its haul to $339m, down from last year’s 12 per cent. HPE ingested $249m in sales, giving it an 8.3 percent AFA market share, down from 9.3 per cent last year. HPE’s overall storage revenues went down 4 percent on the year with its share moving from 10.8 percent to 10.3 percent.
The last identified supplier is Hitachi Vantara with a 3 percent revenue share of the AFA market, equating to $80m in turnover and unchanged from a year ago. The Others category’s share rose from 8 percent in 4Q 2020 to 9 percent in the last 2021 quarter.
Seagate has added a 10th platter to its SkyHawk product line, resulting in a 20TB video surveillance drive.
Update: Exos and IronWorld Pro 20TB drives are 10-platter designs. 30 March 2022.
The prior SkyHawk generation, announced in October 2020, maxed out at 18TB and had a nine-platter configuration inside their helium-filled enclosures, using conventional (perpendicular) magnetic recording (CMR). Now Seagate has squeezed an extra platter in to reach 20TB without recourse to any energy-assisted magnetic recording such as HAMR.
Seagate’s existing 20TB drives, the Exos X20 and the IronWolf Pro, were announced in December. They also have ten CMR platters, meaning a 2.0TB platter density, with an areal density of 1,146 GB/sq in.
SkyHawk drives spin at 7,200rpm and have a 6Gbit/s SATA interface. Their capacity range is 8, 10, 12, 16, 18, and 20TB, with a pair of 8 and 10TB versions in air-filled cases. They have a 256MB cache and their maximum sustained data transfer rate is 260MB/sec, falling to 245MB/sec for the 8 and 10TB air-filled drives.
The 20TB Exos X20 and IronWolf Pro have sustained data transfer rates of 285MB/sec and come with either 6Gbit/sec SATA (IronWolf Pro, Exos X20) or 12Gbit/sec SAS (Exos X20) interfaces.
These SkyHawk drives support support multi-bay NetWork Video Recorders (NVR) and AI-enabled NVR, with up to 64 HD video streams and 32 AI streams running concurrently. Seagate says they can operate up to 120 real-time capture events/sec and 96 real-time compare events/sec. They can endure a workload of 550TB/year workload, have a 2 million hours MTBF rating and a five-year limited warranty. The previous generation had a three-year limited warranty.
Western Digital’s Purple Pro range of video surveillance drives tops out at 18TB. We expect WD to up its capacity to 20TB in the next few weeks and months as it already has 20TB Gold and Red Pro disk drives, using OptiNAND technology and nine 2.2TB platters.
Cloud backup and storage supplier Backblaze has made its existing private Bugcrowd Bug Bounty Program available to all security researchers. Mark Potter, Backblaze CISO, said: “We’re excited to broaden our security profile with Bugcrowd – they make it easy to engage and reward security researchers who can identify issues before they become bigger problems.” Bugcrowd encourages ethical hackers to attack businesses, find vulnerabilities in their software and processes, and aid in guiding the remediation of those vulnerabilities before they can be exploited by anyone else. You can find out more here.
…
DataStax, which supplies a scale-out, cloud-native Cassandra NoSQL database, has unveiled “change data capture” (CDC) for Astra DB, powered by advanced streaming technology built on Apache Pulsar. This enables any organization to create smarter and more reactive applications fueled by connected, real-time data. Today only a fraction of real-time data is being used due to the failure of legacy architectures to meet the performance and scale requirements of real-time data processing. As a result, data is often uploaded in batches, creating chronically stale data. DataStax reckons it can now fix this problem.
…
An ionir report, “The Future of Stateful Applications on Kubernetes,” has found that 60 percent of respondents are running stateful applications on Kubernetes, and of those who aren’t already, 50 percent plan to do so in the next 12 months. Get the report here. Sxity-one percent of respondents ranked data persistence as the top data service for Kubernetes, and 43 percent said data mobility. Some 60 percent of said the top benefit of adopting Kubernetes is an increase in agility, portability, and flexibility.
…
Lightbits, which builds NVMe/TCP block storage software, was this week selected as winner of the “Data Storage Innovation of the Year” award in the third annual Data Breakthrough Awards program conducted by Data Breakthrough, an independent market intelligence organization. Eran Kirzner, CEO of Lightbits Labs, said: “Our data platform is used by Fortune 500 companies today and gaining massive customer traction because it increases ROI with high performance, it reduces TCO with disaggregation, maximizes the utility of flash, and it’s easy to consume.” The gaining of “massive customer transaction” must surely be reflected in Lightbits’ business performance and we look forward to hearing about it.
…
Pure Storage announced continued growth and customer adoption of its SaaS subscription service. In fiscal 2022, Pure’s subscription services made up 33 percent of total revenue, exceeding $738m and representing 37 percent year-over-year growth. Customers can now take advantage of an extended version of Pure’s Cost Calculator, which has been built directly in Pure1, Pure’s AI-driven data-services platform for storage management. They can conduct advanced workload modeling, request a quote, and make purchases directly through the platform.
…
Real-time database platform Redis has announced the launch of Redis Stack, which consolidates the capabilities of the leading Redis modules into a single product, making it easier for developers to build Redis applications. Redis Stack is a suite of three components:
Redis Stack Server combines open source Redis with RediSearch, RedisJSON, RedisGraph, RedisTimeSeries and RedisBloom
RedisInsight is a powerful tool for visualizing and optimizing Redis data, making real-time application development easier and more fun than ever before
The Redis Stack Client SDK includes the leading official Redis clients in Java, JavaScript, and Python. These clients also include our new suite of object mapping libraries which offer developer-friendly abstractions that get you productive with just a few lines of code. Known as Redis OM for .NET, Node.js, Java, and Python, these libraries also make it easier than ever to integrate with major application frameworks such as Spring, ASP.NET Core, FastAPI, and Express.
Redis Stack is now generally available for Redis 6.2, and there is a release candidate for Redis 7.0.
…
As part of a strategy to penetrate vertical markets to maintain its growth, Snowflake has unveiled a new data cloud service targeting the healthcare and life sciences space. The new Healthcare & Life Sciences Data Cloud will provide healthcare and life sciences services for Snowflake partners and enable them to develop their own offerings.
…
Talend, a data integration and data governance supplier, has announced the availability of Talend Data Catalog 8, an automated data catalog providing proactive data governance capabilities that enable organisations to discover, organize, and share trusted data with a single, secure point of control. The update includes tailored business modeling and machine learning-powered data classification and documentation.
…
Weebit Nano is scaling its RERAM semiconductor process technology down to 22nm. It is working with CEA-Leti to design a full IP memory module that integrates a multi-megabit ReRAM block targeting an advanced 22nm FD-SOI process. Weebit’s first embedded ReRAM silicon wafers were produced at at 130nm and have shown positive early test results. It has successfully demonstrated production level parameters at 28nm. It wants to accelerate its development plans to scale its technology to process nodes where existing embedded flash technology is no longer viable.
….
Open-source distributed SQL database company Yugabyte has announced GA of YugabyteDB 2.13. It delivers better control over where data is stored and accessed in geo-distributed deployments. It extends the geo-distribution capabilities of the database with new features that enhance performance, increase control over backups, and intelligently utilize local data for reads. Improved database performance comes from Materialized views (stored, pre-computed datasets), faster region-local transactions with eliminated cross-network latency, and backups within regions to reduce cloud storage data transfer costs and help organizations comply with complex data regulations such as GDPR.