


Analysis: Netflix uses an open-source Druid analytics database to understand and quantify how users’ devices are handling browsing and playback. Other Druid users include Airbnb, Alibaba, Cisco, eBay, Lyft, Paypal, Pinterest, Reddit, Salesforce, Shopify, Slack, Splunk, Tencent, Trustpilot, Walmart, Wikipedia, Yahoo, Xiaomi and many more.
The streaming platform uses it to get real-time answers from queries to a database with billions of items to filter and scan. It’s not a relational database, a NoSQL database nor a data warehouse or lakehouse and, although it’s specialised, it is in wide use. Articles about Ocient and Firebolt have touched on this topic of real-time querying of vast datasets, so it’s becoming important in our storage arena. Let’s try to understand the Druid magic to get a better handle on things.
Origin
An adtech firm called Metamarkets originally devised Druid as a distributed and real-time data store in 2011 to provide SaaS analytics. Metamarkets provided interactive analytic dashboard facilities for advertisers to find out how programmatic ad campaigns were performing. It was acquired by Snap in 2017. Druid was moved to an Apache license in 2015.
A Metamarkets blog describes its original needs: “Our requirements were driven by our online advertising customers who have data volumes often upwards of hundreds of billions of events per month, and need highly interactive queries on the latest data as well as an ability to arbitrarily filter across any dimension – with data sets that contain 30 dimensions or more. For example, a typical query might be ‘find me how many advertisements were seen by female executives, aged 35 to 44, from the US, UK, and Canada, reading sports blogs on weekends’.”
It needed real-time access to a store containing billions of time-series events. Data warehouses were ruled out because their scan rates were too slow and caching speed up was defeated because Metamarkets needed to make arbitrary drilldowns. Relational databases were also unsuitable: “RDBMS data updates are inherently batch, updates made via inserts lead to locking of rows for queries.”
A NoSQL approach was no good as “pre-aggregations required hours of processing time for just millions of records (on a ~10-node Hadoop cluster). … as the number of dimensions increased, the aggregation and processing time increased exponentially, exceeding 24 hours.”
That meant no real-time queries.
So Metamarkets decided to build its own data store and make it hugely scalable by parallelising processes within it. It featured a distributed architecture, real-time data ingestion, the ability to query both real-time and historical data, and a column orientation with data compression for scan speed. Speed was also facilitated by using bitmap indices with so-called Concise Compression.
Druid can be scaled out to perform scans of 26 billion rows per second or more and it can ingest up to 10,000 records per second per node. The servers in a Druid cluster can be scaled up or out, which provides more scaling capacity than scaling up.
Druid structure
A Druid deployment uses commercially available servers and these are called nodes. There are three basic types: master node, data node and query node. Old data is stored in so-called deep storage which is pluggable storage outside Druid such as Ceph, NFS, Hadoop (HDFS) or S3. The nodes run processes and these could run in dedicated servers and be called nodes – or servers:
- Master Node – Overlord, Coordinator, Zookeeper, Metadata Store processes;
- Data Node – Middle Manager/Indexer, Historical processes;
- Query Node – Broker processes and web console.
We have seen several different diagrams showing how these nodes and processes are related to each other as data is ingested, indexed, sent to (deep) storage, and queried. We’ll show four and then attempt an explanation.
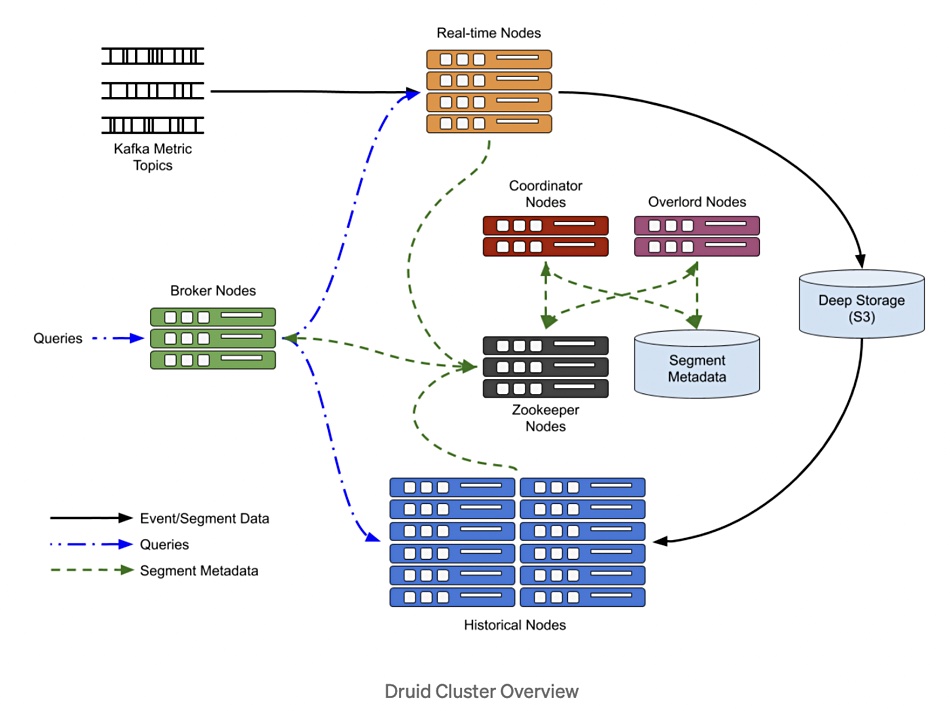
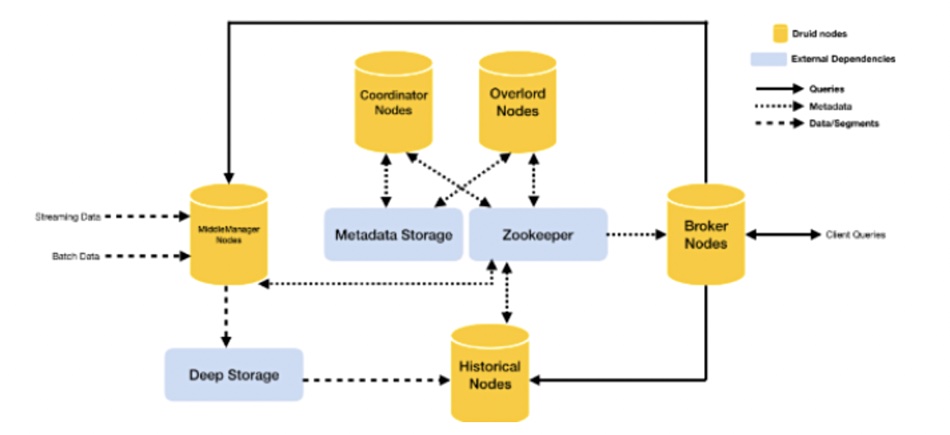
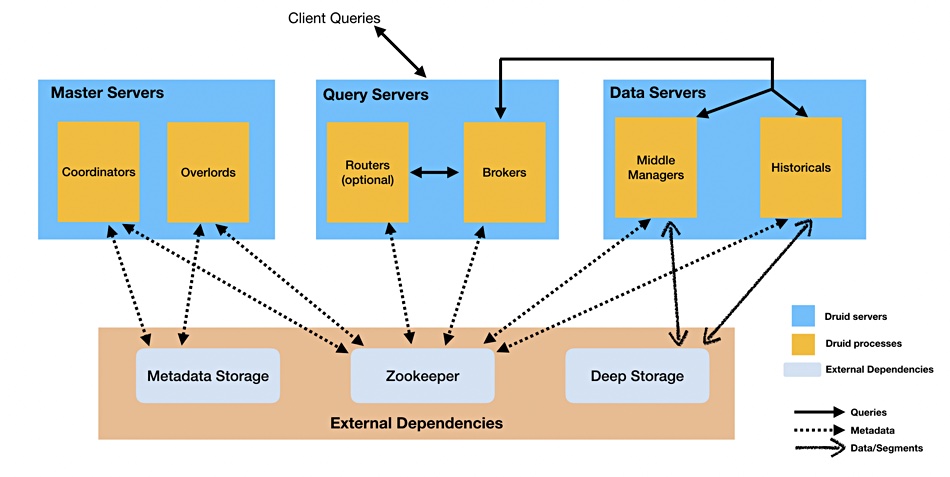
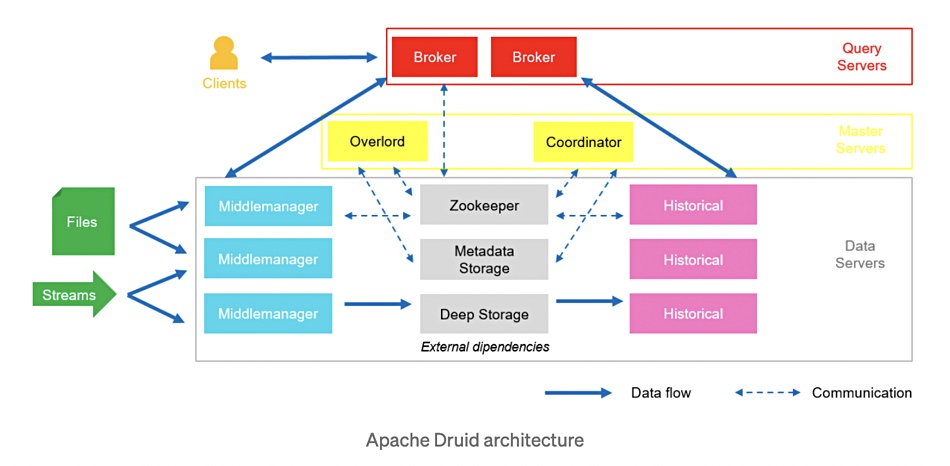
As you see, though the diagrams share terms like Overlord and Zookeeper, they are all different.
Data ingest
Let’s try to make sense of what’s going on, and start with data ingest which happens in the data node or server layer.
Streaming data from Kafka, Kinesis, Tranquility or other sources can be ingested as can batched data from Hadoop, S3, an RDBMS and, again, other sources. The Middle Manager nodes, sometimes called Ingestors or Real-Time nodes, handle this and segment or partition the data by time (configurable duration) into an immutable compressed columnar file which is written to deep storage.
There are three possible column types: timestamp, dimension (field name) or metric (numeric data derived from other fields). The Middle Managers also index and pre-aggregate the data before creating segments. All incoming data within a specified time interval is written to the same segment in sequential fashion. Druid uses a flat data model, and not a nested data model.
Once the data is in deep storage then Historical nodes (Historicals) are responsible for fetching it in response to queries.
Master nodes
The master nodes form a Druid cluster control plane. The Overlords do data load balancing over the Middle Managers. The Coordinators do data load balancing across the Historical processes or nodes, informing them when data segments need to be loaded from deep storage, evicting segments when no longer needed and getting segments replicated.
Metadata storage contains all the metadata created by the Middle Managers in a relational database such as MySQL or PostgreSQL. The Zookeeper process is an Apache project used for current cluster state management, internal service discovery, coordination and cluster leader election.
We need to understand that Coordinators are told by Metadata Storage when new data segments have been created by a Middle Manager. It then gives it to a Historical so it can be written to the underlying filesystem. At that point it is evicted from the Middle Manager. The Middle Managers keep their pre-aggregated segment data in memory while the Historicals write the new segments to deep storage. Once there, segments are read-only.
If a Middle Manager node fails them the Zookeeper gets its dataset reconstituted by the remaining Middle Manager nodes.
Query nodes and query process
There is a single type of query node, called a Broker, and a web console is also located in this layer of Druid. Brokers can be scaled out to increase real-time query processing capability.
Brokers receive incoming queries, in a JSON query language or via Druid SQL, from client applications and assign them to relevant Middle Managers and Historicals – the ones which contain (can serve) these data segments. The Broker splits the incoming query up into sub-queries and sends them to the identified Middle Managers and Historicals for execution.
The Historicals fetch the requested data from deep storage while the Middle Managers fetch any real-time data segments.
When the results are returned they are merged and output to the client.
The net result of this is that Druid can enable querying of enormously large data sets which can include real-time as well as historical data. It began life as an adtech real-time query/analytics database facility but is finding use in applications needing a similar ability to query massive datasets constantly ingesting streamed data from event logs in real time. For example, clickstream analysis, APM (Application Performance Management), supply chain, network telemetry, digital marketing, and risk/fraud analysis.
As Metamarkets states, “Queries over billions of rows, that previously took minutes or hours to run, can now be investigated directly with sub-second response times.” Druid can cope with trillions of rows of data in multi-petabyte data stores.
I feel Druid and Druid-type applications are going to become more widely used as streams of digital event data are analysed to optimise processes and so fine-tune enterprise processes involving billions, if not trillions of events over time.
Druid is available for download on GitHub, and more information can be found on the Druid project website.




