Model9, the mainframe to cloud object storage data mover, has reorganized its product set, adding cyber-protection and a facility to feed cloud-based AI, machine learning and data warehouses with mainframe data.
Startup Model9, founded in 2016, began life on a mission to replace complex, slow and costly mainframe tape backup storage with Virtual Tape lIbrary (VTL) software sending data to public cloud object storage and S3-supporting on-premises stores. It now has three product lines: Manager to move and store backup/archive data in the cloud; Shield to cyber-protect copies of mainframe data; and Gravity to move mainframe data to the cloud and there transform it and load it into cloud data warehouses and AI/ML pipelines.
Gil Peleg.
Co-founder and CEO Gil Peleg told IT Press Tour attendees in Tel Aviv that Model9 isn’t about replacing mainframes with the public cloud. “It will be a hybrid mainframe cloud world for the next twenty to thirty years.”
The company’s software parallelizes transmission of mainframe data to the public cloud or on-premises object stores, making it both faster and much much cheaper and simpler to use than mainframe tape for backup. For example, it uses IBM’s non-billable zIIP facility to process its data, meaning its mainframe compute is free. Other mainframe backup data movers to tape use the standard mainframe CPUs and their processing cycles cost money.
Model9 opportunity
Model9 has gained credibility in the mainframe world with several public case studies. It is working with mainframe-focussed system houses such as Accenture and Infosys, and has been brought into deals by the newly-formed Kyndryl – IBM’s spun off services business – and also by Cohesity. Its software is available in the three public cloud marketplaces. It thinks it has little effective competition and a large opportunity ahead of it. How large?
That depends upon the number of IBM mainframes in customer datacenters. IBM doesn’t release such numbers. We understand 71 per cent of Fortune 500 companies use mainframes; assume two each and that’s 710. Assume that’s half IBM’s base and we think there will be at least 1,500 IBM mainframes out there. A 2016 Quora thread suggested 10,000 with some estimates reaching up to 40,000.
Let’s say 10,000 and further assume Model9 has penetrated five per cent of IBM’s base; 500 systems. That gives it huge growth potential. Each sales cycle is multi-month in length – possible a year or longer – and requires a direct sale, either to the end user or to a partner. That means Model9 will have to grow its worldwide sales and office presence. It had a $9 million A-round of funding in 2020, with Intel Capital taking part. That’s not a lot of money in the storage startup world.
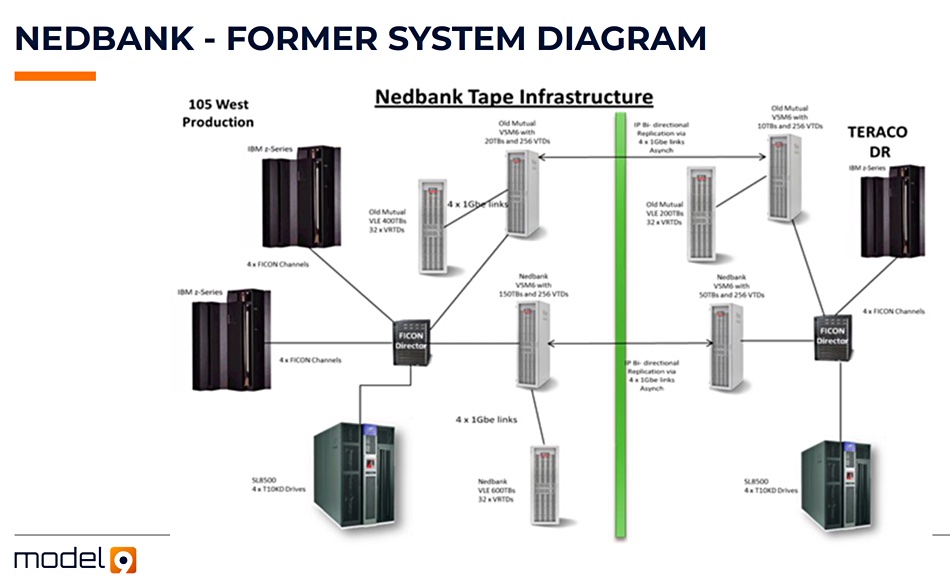
Is it effectively self-funded? Model9 can charge customers a lot of money while saving them even more money. Here is a picture of customer Nebank’s infrastructure for backup before using Model9:
All this infrastructure and associated process complexity adds to and strengthens the gravitational force holding data penned up in the mainframe. Model9 can break that prison. Here is the infrastructure after using Model9’s software:
That’s an awful lot of kit that can be sold off, software that no longer has to be licensed, and datacenter space that can be retired.
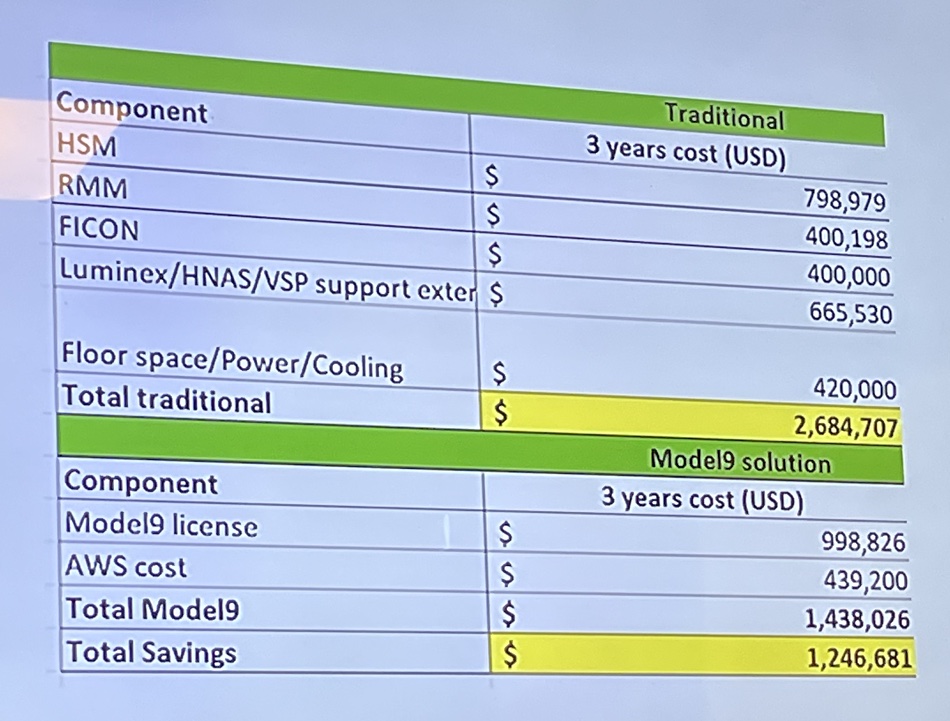
We saw some financial numbers from a Model9 POC which were impressive:
These numbers were from an iPhone photo, this slide was not in the deck distributed to Press Tour attendees.
The three-year cost for the Model9 subscription licences, charged by capacity, was $998,826 – near enough a million dollars – yet the customer was saving $1.25 million. These are seriously large sales and Model9 would be self-sustaining if there were enough of them – but there aren’t. Yet.
Peleg told me that all Model9 customers renewed their subscription licenses – not a single customer has walked. Also second and subsequent sales can be charged at a higher per/TB capacity rate. He said mainframe customers are used to price increases.
Even so, he said, Model9 will probably seek a second funding round and money would clearly be needed to grow and deepen the company’s presence in various regions worldwide. It should be easier to attract VC interest this time around. Mainframes are not sexy, but AI/ML training and big data warehouse analytics are hugely glamorous, with Model9 able to feed mainframe data to SnowFlake, Yellowbricks and other cloud warehouse businesses. Without Model9 these cloud ML training and analytics facilities are a closed book to mainframe customers.
Peleg said IBM had created a ML Inference processor which will be in the coming z16 mainframe. An inference processor, not a training processor. With Model9, mainframe customers can send their training datasets to the cloud in a Model9-mediated extract, load and transform (ELT) process with all chargeable computing done in the cloud at a much lower cost than mainframe cycles. Once trained, the data model can be shipped back to the mainframe and ML inference runs done there for instant results.
Big blue is reselling the combined transactional and analytic SingleStoreDB database as a service.
The SingleStoreDB universal database is based on the distributed, relational MemSQL SQL database. It has been developed to provide both transaction and analytic workload functionality and is available on-premises and in the public cloud. The company asserts that its customers no longer require separate operational and analytical database systems.
IBM’s Michael Gilfix, VP product management for data & AI, provided an announcement statement: “Businesses need a data strategy that is designed to support mission-critical applications and fuel advanced analytics and AI. The launch of SingleStore Database with IBM is the latest step we’re taking to help clients adopt a data fabric strategy and architecture … making data management simpler and smarter.”
SingleStore CEO Raj Verma is bullish on the combined transaction+analytic database idea, saying: “We believe we will witness a massive re-platforming of existing applications in the near future. Our relationship with IBM can help organizations have a solution designed to accelerate their time-to-value and drive improved performance in a frictionless, hybrid, multi-cloud architecture enabled by SingleStore.”
SingleStore says customers can simplify and unify data tiers with SingleStore and IBM. The SingleStore software can be deployed on-premises, in private clouds or in public clouds, and is subscription-based. The primary customer benefits are said to be lower legacy database and hardware costs, accelerated query results with a single database, and the ability to run data-intensive reports quickly.
IBM will offer the purchasing, licensing and support of the SingleStore Database. Its customers – clients in IBM-speak – can work with IBM Expert Labs or IBM Consulting for global deployment support. This can include consulting on individual database technologies and overall data management architectures, including a data fabric.
This agreement is an expansion of the existing IBM and SingleStore relationship, including SingleStore’s certification on Red Hat OpenShift and its availability with the Red Hat Marketplace.
SingleStore was founded in 2011 and has taken in $264 million in funding, with $80 million rounds in both 2020 and 2021. IBM likes SingleStore’s technology so much it participated in its F-series funding round in November 2021. Before SingleStore, Verma was co-CEO at MemSQL in 2019 and became the sole CEO in September 2020.
He’s driving the company hard, and this latest IBM deal will help raise SingleStore’s profile and bring in more business. Combining relational and analytical database functions in a single product will suit companies who don’t want to set up a separate analytical database with extract, transform and load functions to move transactional and other data to it.
Dell is adding SmartSync file synchronization to object storage for PowerScale and Isilon systems with a OneFS v9.4 update.
OneFS is the operating system for Dell’s PowerScale and Isilon scale-out filers. It already has a SyncIQ feature which provides parallelized replication between Isilon clusters for disaster recovery. It can send and receive data on every node in a PowerScale/Isilon cluster. An administrator can choose to sync every six hours for customer data, every two days for HR data, and so on.
The SmartSync data mover complements SyncIQ, providing off-cluster data moving, such as to object storage targets like ECS, AWS and Azure. It enables flexible data movement and copying, incremental resyncs, push and pull data transfer, and one-time file to object copy.
Competitor Qumulo has its Shift feature to move files to S3-supporting target systems.
Version 9.4 also adds more features. There is non-disruptive rolling Infiniband to Ethernet back-end network migration for legacy Gen-6 clusters. In-line deduplication will be enabled by default on new OneFS 9.4 clusters, but clusters upgraded to OneFS 9.4 will maintain their current dedupe configuration.
Secure boot support is extended to include the F900, F600, F200, H700/7000, and A700/7000 platforms. The SmartConnect feature now identifies non-resolvable nodes and provides their detailed status, allowing the root cause to be pinpointed.
There is automatic monitoring, download, and installation of new healthcheck packages as they are released. A new CloudIQ protocol statistic has count keys added, allowing performance to be measured over a specified time window and providing point-in-time protocol information
Automated statistics are gathered on CloudPools accounts and there are policies providing insights for planning and troubleshooting CloudPools-related activities.
The OneFS 9.4 code is available for download on the Dell Online Support site, in both upgrade and reimage file formats. Dell says that for upgrading existing clusters, the recommendation is to open a service request with Dell Support to schedule an upgrade. To provide a consistent and positive upgrade experience, Dell is offering assisted upgrades to OneFS 9.4 at no cost to customers with a valid support contract.
Comment
Slowly but surely file and object systems are getting integrated. Object suppliers have added file interfaces and filer suppliers are supporting S3 access and data movement. Over in the SAN world we have seen unified block and file systems like Dell EMC’s Unity/PowerStore and NetApps ONTAP.
Are we going to see a grand reunification with combined block, file and object systems? Ceph supporters would say they already enjoy the benefits of such a tripartite storage system.
Israeli startup Pliops wants to replace the existing block interface to SSDs, based on disk drive-era thinking, with key:value store technology that enables vastly more efficient SSD operation. It claims this will accelerate data access and prolong an SSD’s working life.
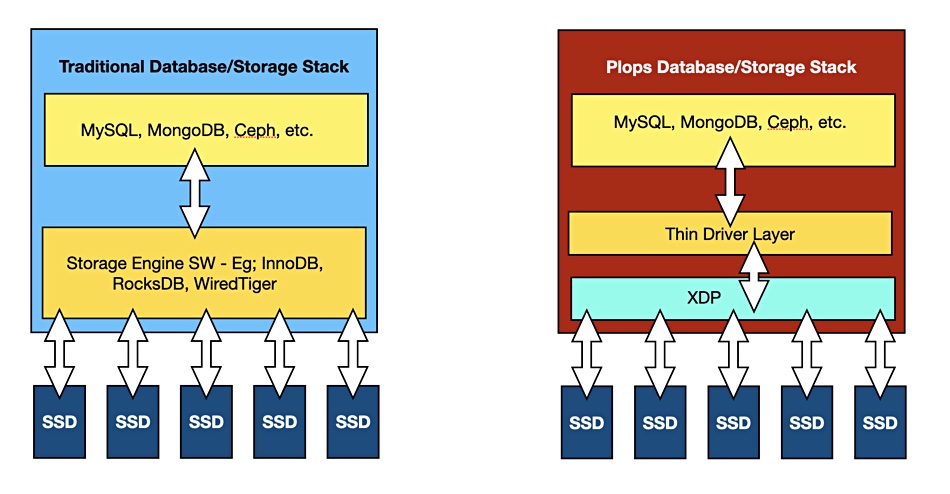
Pliops’s founders realised that a server’s low-level storage functions could be pushed down the stack to a reinvented SSD controller – one that replaced the existing FTL (Flash Translation Layer). The company was started up in 2017 to develop this storage offload technology for x86 servers comprising a PCI bus-attached card called an eXtreme Data Processor (XDP). It is built with FPGA chips, NVDIMMS and DRAM, and carries out the processing performed by storage engine software used by Ceph, Relational, and NoSQL databases such as MongoDB.
Plops database/storage stack (right) vs traditional storage stack (left.)
Co-founder and CEO Uri Beitler said Pliops wants to become the Nvidia of storage, by increasing infrastructure scaling for databases, analytics, AI and other data-intensive applications. So it’s built a specialised processing engine to do it.
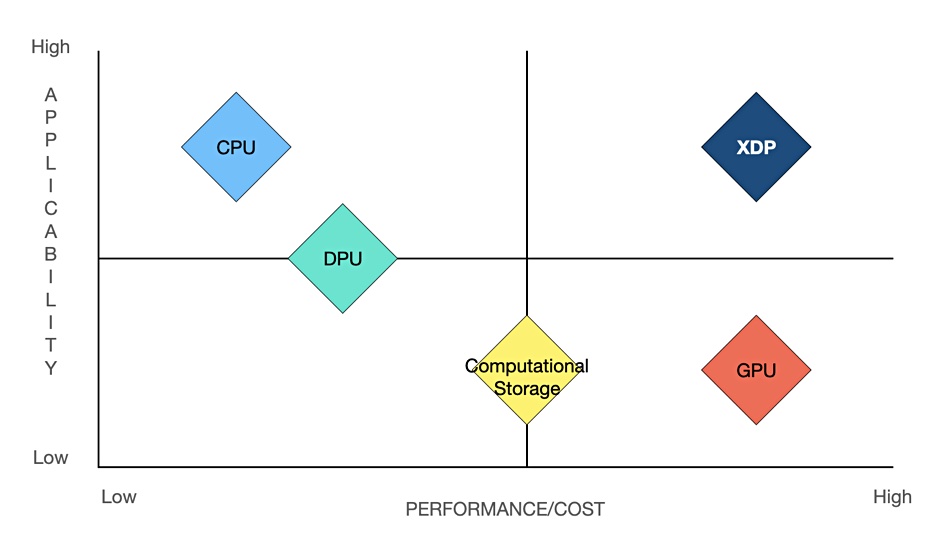
In an IT world getting flooded with SmartNIC, IPU (Intel), DPU (Fungible, Nvidia and others) and computational storage announcements, how do we place its XDP in the market? A Pliops slide showed a positioning diagram which we have reproduced:
Blocks & Files version of Plops XDP market positioning diagram
Beitler presented a session at an IT Press Tour event in Tel Aviv covering Pliops’s situation and progress. He said: “We complement both DPUs and computational storage.” How so?
Computational storage drives, like ones from ScaleFlux, operate at the per-drive level. Pliops’s XDP effectively replaces a storage array controller, operating across a set of drives with up to 64TB of total raw capacity. It improves their overall I/O performance, extends individual drive endurance, increases effective capacity through compression, and provides RAID-like protection against drive failure.
Pliops XDP card with four supercaps on the right and FPGA on the left.
Rear of Pliops XDP card.
DPUs like Fungible’s chips include networking functions – Fungible’s TrueFabric. Beitler said: “We have no networking capabilities [and] we are working with DPU developers today.”
On launch in July 2021, the XDP delivered up to 3.2 million random read and 1.2 million random write IOPS and could store up to 128TB of data on 64TB of SSD capacity through compression. It supports QLC (4bits/cell) flash drives, also Optane SSDs, and has block and key:value store interfaces to its server host applications. Block is basically treated as an overlay on the underlying key:value technology and is still faster, Beitler said, than other suppliers’ block-interface SSDs.
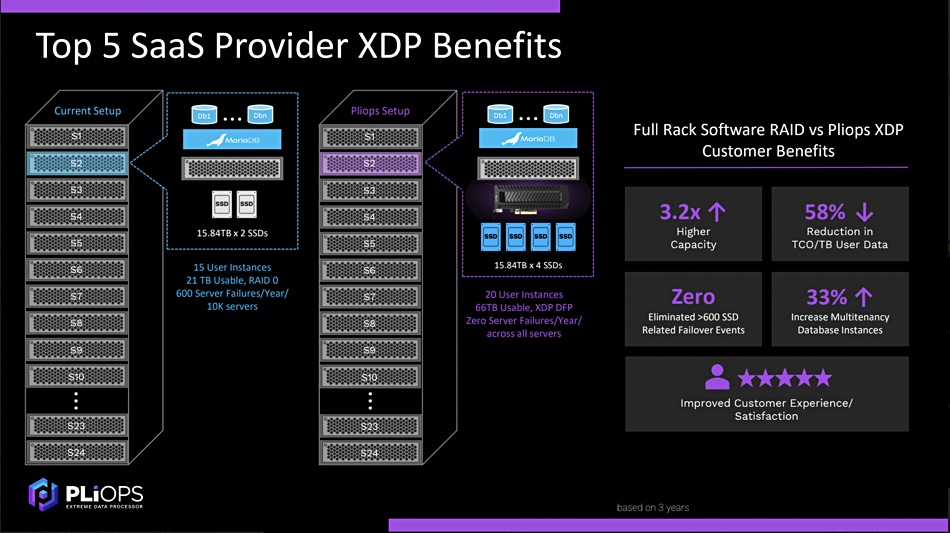
It sells its product to hyperscaler businesses and large enterprises who find their x86 servers bogged down with getting masses of data to their processors, limited in data access speed, suffering short SSD endurance and high cost. Pliops says it has gained early traction – counting a global top five SaaS provider in China as a customer and a top five hyperscaler with an IaaS offering. There is also a Top500 HPC customer. None of these can be named yet.
They all get, Pliops said, significant TCO savings. Steve Fingerhut, Pliops’s chief business officer, said the top five SaaS provider used to have RAID-protected racks of servers and storage – 2x 15.84TB SSDs per server with 21TB usable. Now it has servers fitted with the XDP and 4x 15.84TB SSDs with 64TB usable. It suffers zero server stoppages due to SSD failures – the XDP has RAID functions – which was a fairly frequent occurrence before with the hundreds if not thousands of servers in its estate. There has been a 58 per cent reduction in TCO/TB of user data and a 33 per cent increase in the multi-tenancy of its database instances.
We are told Pliops is making good progress in talking to US-based hyperscalers – CSPs and enterprises both. The early progress in China has yielded Inspur becoming an OEM.
Roadmap
The company is developing its second generation XDP and this will feature PCIe 5 support, and higher raw capacity – possibly 128TB. There will also be support for SDXI and TP-4091.
SDXI (Smart Data Accelerator Interface) support is an SNIA proposed standard for a memory to memory Data Mover interface. The SNIA says software memcpy is the current data movement standard for software implementation due to stable CPU ISA (Instruction Set Architecture). However, this takes away from application performance and incurs software overhead to provide context isolation. Offload DMA engines and their interfaces are vendor-specific, and not standardized for user-level software.
A Plops slide showed SDXI and TP-4091 linked to Arm servers, which have a non-x86 ISA.
ScaleFlux chief scientist Tong Zhang said: “In order to off-load certain computational tasks into computational storage drives, host applications must be able to adequately communicate with computational storage drives. This demands the standardised programming model and interface protocol, which are being actively developed by the industry (e.g., NVMe TP 4091, and SNIA Computational Storage working group).”
Pliops says it is also moving from FPGA to ASIC technology
Investors and partners
Pliops has taken in $115 million in funding with the latest round being for $65 million last year. Its investors include AMD, Intel Capital, Nvidia, SoftBank and Western Digital, which also uses Pliops in-house for a Redis application.
Beitler said Pliops is partnering with all the main SSD vendors and also working with Nvidia in two ways. One is to have an XDP-fronted NVMe drive shelf using BluefIeld smartNICs to talk to host systems. The second is to have the XDP NVMe drive shelf link directly to an Nvidia GPU server, in much the same way as a VAST Data array might.
Aryeh Mergi.
He said Pliops is also working with DPU developers today as well as SSD vendors. It doesn’t work at the moment with file system suppliers. Pliops chairman Aryeh Mergi said: “At a low level they use key:value stores and we are applicable. We just don’t work with them today.” WEKA and Google-acquired Elastifile were cited as key:value store technology users. Mergi said Pliops is focussing more on open source software, like Ceph and “most file systems are proprietary.”
Pliops also works with WD on the zoned name space initiative. The XDP batches up random writes and sends them to the SSD as sequential blocks, reducing write amplification and treating the SSD as a single zone. Theoretically it would be easy to divide an SSD up into logical zones and manage them separately.
It seems to Blocks & Files that Pliops has been operating in a quiet mode – under the radar so to speak – but it hinted that named customer case studies were coming. We expect to hear much more from Pliops as the year progresses.
A March update for HYCU’s Protégé backup offering adds support for Dell EMC Isilon and PowerScale systems, plus additional features such as Azure Government Cloud support.
Update. Additional HYCU views added. 5 April 2022.
HYCU presented its update to a March IT Press Tour in Tel Aviv, reminding attendees it began its life providing Nutanix-focussed backup, then added VMware, and subsequently added the Google, Azure and AWS public clouds in that order, with an agentless backup-as-a-service offering. Office 365 was supported in February last year, and Kubernetes-orchestrated cloud-native workloads in April.
Subbiah Sundaram.
Subbiah Sundaram, VP of product for HYCU, told attendees: “We integrate with Isilon’s native API, not using NDMP, whose use impacts production systems. Ours does not.”
That’s because NDMP uses host server CPU and memory resources whereas HYCU’s agentless backup does not. HYCU’s Protégé software can backup Isilon and PowerScale systems to on-premises Data Domain and ECS targets but also to the three top public clouds. In this way it can aid a customer’s migration to the cloud.
When it was mentioned that Druva can also backup source systems to the public cloud, and Dell has a tie-up with Druva, HYCU SBP sales Justin Endres said that Druva was AWS-specific and customers would prefer multi-cloud support. He also suggested that Dell-Druva deal was done in haste and Dell might be looking to widen its SaaS backup supplier relationship so as to gain multi-cloud target support.
Endres also said that Isilon/PowerScale customers moved to HYCU because relying on replica copy-based rather than backup-based protection didn’t scale well or extend easily to the public cloud. HYCU fulfils both requirements. Also Isilon customers came to HYCU because extending their legacy backup to the cloud was hard and HYCU made it easier. Commvault and Veritas were singled out in this regard, with Sundaram saying Commvault’s Metallic does not protect Isilon.
Other features in the March update were:
Expanded WORM (Write Once Read Many) support including S3 object lock and its equivalent for Azure Blob and Google Cloud Object Storage;
Zero trust security with partners offering services after education by HYCU;
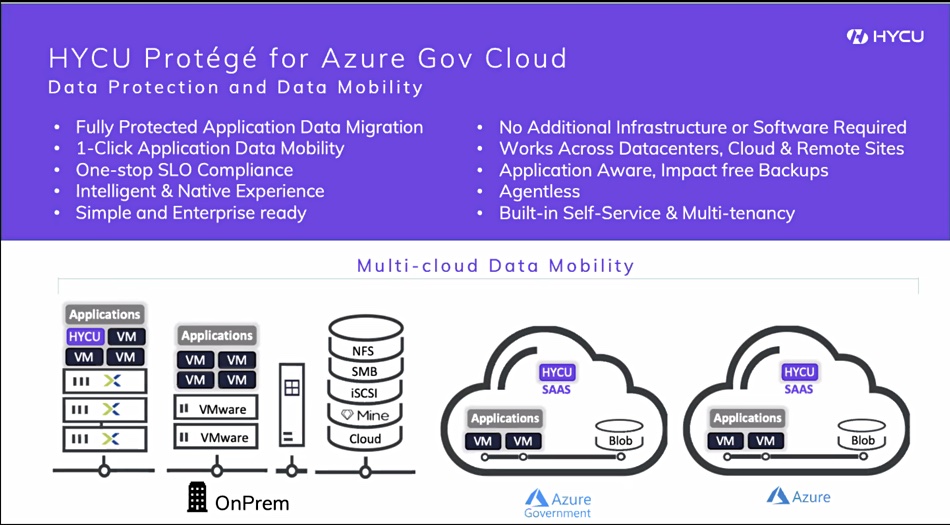
Migration from on-premises backups to the to Azure Government Cloud.
HYCU Azure Government Cloud slide.
Asked if HYCU offered dedupe in the cloud, Sundaram said: “We don’t do dedupe in the cloud. It requires compute there and compute is expensive while storage and networking are cheaper. We only ship unique blocks to the cloud with a first fill backup and only unique blocks from incremental changes.” This is marketed as Cloud Smart with savings in backup storage capacity and faster recovery than restoration from a deduplicated backup store in the cloud. In effect HYCU gets dedupe done on the source system.
In the future HYCU could introduce data protection plus security with integration of its software with the native security management of the source platform so it could work with the identity management features there.
HYCU has an R-Score ransomware attack readiness score with a 0 to 1,000 rating and offers it as a free service to customers. It was created with help from Mandiant and, so far, it has been used more than 50,000 times.
HYCU presentation slide.
It’s enabling its partners to offer this as a service with partners billing customers for its use. HYCU says this gives its partners something to compete against Google with its acquired Mandiant offering.
A HYCU spokesperson told us: “These new services for us are just a small but hopefully meaningful way in which our partners can add ransomware assessment to their ongoing practice areas – especially for those in that have security service and practice areas. I honestly don’t think any of us would ever think those capabilities for midsize enterprise-focused MSPs/MSSPs and CSPs would ever run up against the breadth and depth of what Mandiant currently offers and may offer now that they’re a part of Google. We still work with the Mandiant execs and engineers to fine tune R-Score that we introduced with them last August as well.”
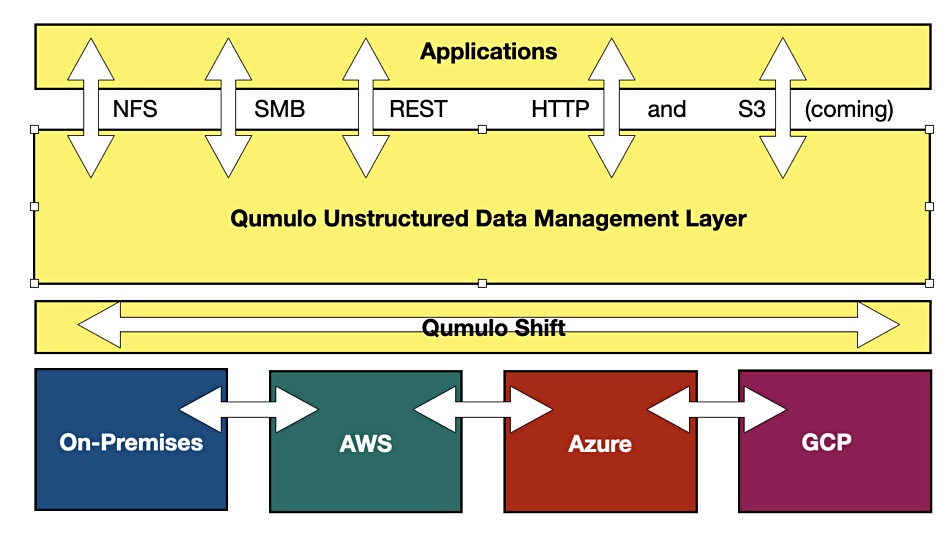
Interview. Ten years after it was founded, as an on-premises scale-out filer supplier, Qumulo is becoming an unstructured data lake services company in a hybrid multi-cloud world, with its own management layer providing a consistent experience across the platforms it supports. Qumulo says it wants to make the infrastructure invisible.
Bill Richter.
Blocks & Files talked to Qumulo CEO Bill Richter about where the company is now and where it is going.
Blocks & Files: Other companies have started just disassociating themselves from their proprietary hardware, or even from hardware all together. They’ll certify suppliers, say, and design hardware with certified builders. But the hardware that users buy is never on the supplier’s books. Would Qumulo be thinking of doing the same thing?
Bill Richter: We did that. When we built the software, that was the design feature. [It] would always run on standard hardware. Four years ago, we started enabling other OEMs to run our software like HPE; on their hardware. And last year, we completely got out of the hardware business altogether. So today, from a business model perspective, all Qumulo sells is its software and the HCl, the hardware compatibility list, is very large. And it spans the most dense, economical form factors all the way up to screaming fast, all-NVMe form factors.
Where is Qumulo today?
Right now, customers run Qumulo on in their datacentres on standard hardware. And in all three major hyperscale clouds as code.
Absolutely not. We never have. So we run directly natively on cloud infrastructure. And the magic for customers is that they they get the GUI, the enterprise features and capabilities, all the things that they use and rely on … are exactly identical. … So that kind of a universal unstructured data management layer for the multi-cloud world is exactly how you should think of us.
Blocks & Files diagram.
You have your business model so that you’re no longer dependent on on-premises hardware sales. And you support both on-premises and the three main public clouds with a consistent user experience across those four environments. Where next are you going with this platform, with the on-premises datacentre and the four public clouds below it. Are you thinking of erecting some kind of software superstructure on top of that platform? And expanding upwards?
One of the things that customers were most excited about Qumulo in the early days was already analytics stuff. And if you extend that notion into a multi-cloud world, the next set of questions they ask us is, hey, what does multi-environment or multi-cloud management look like? I love that I can run Qumulo, on AWS, and in my datacentre, and scale from one environment to another. Help me manage those environments more elegantly. And that is absolutely a direction that we’re going. There’s no question about it, it’s customer-led.
What will the future be like from Qumulo’s viewpoint?
If you believe as we do that the future is in multi-cloud world, customers will use at least one but perhaps more than one hyperscaler. For these datasets that we serve as they’re very large, they’re at scale, very often customers will have on premises environments; on prem clouds. … What we believe customers want is a multi-cloud platform for their unstructured data. And that’s what we built. It’s very, very different from the legacy box sellers, or even some of the new emergent folks out there that have completely different points of view of what the future should be like.
Can you say more about the sorts of high level functions that you may be thinking of adding to the product?
The direction of the product has three major pillars to it. The first is to allow customers to get out of the business, not just of managing hardware, but out of the business of managing software altogether … and just consume capabilities. So the first major step in that direction is our deployment on Microsoft Azure. That’s very different. That is a service on Azure. So customers go to a UI, they choose … their requirements and then they simply deploy or consume. There’s no notion of upgrades; there’s no notion of managing software. They just consume.
The second one … customers want more and more management features out of us, they want a single pane of glass, to be able to look at these various environments. And then they want to be able to action, they want to be able to click a button and say this application or workload where this pattern of IO is going to move from on-premises to my AWS environment, or vice versa, or from AWS to Azure, or if there’s been a corporate decision at my company.
I don’t want to have to change my data structures, or the way that my information workers do business. I want them to have a like for like experience with Qumulo. … You can set up a simple replication relationship between an AWS environment and Azure or any one of these clouds, and press a button and … inside of a few hours, that data set will be replicated over using our tools. And then the customer is up and running. They can even failover from one environment to another.
The third one, building management for a multi-cloud world. [Adding] powerful features to allow customers to do interesting things with their data. We introduced a product called Qumulo Shift last year, that allows customers to write files and then read them as objects. And be able to shift those concepts or blend those concepts between file and object together.
And the reason that we did that is because we want customers to get max value out of their data. So a specific example there is, let’s say, I’m running a toll bridge. And I’m imaging, car plates or licence plates. And that system is built on file. We might want to take that data set, send it to AWS, transform those files into objects, and use AWS machine imaging software [like] Recognition to register those images and let machines reason over them. And then I might want to send the results of that workflow back into a file workflow. And so instead of having a point of view that this world of file an object has to be separate, forever, our point of view is, hey, how do you allow customers to blend these concepts?
Are you doing anything with Nvidia? You’ve got this great file platform and Nvidia needs data for its GPUs.
We are increasingly the unstructured data lake that sits behind Nvidia GPU farms.
Now, that’s an interesting thing to say. I see Nvidia having two requirements in storage very, very simplistically. One is, if I’m an Nvidia GPU server, I need a frighteningly fast, high bandwidth data server to keep my GPUs busy. But this primary store, isn’t where I keep everything because there’s too much to keep. So I need something behind it and you’re the first person I’ve come across that said, we do that.
Yes, that’s that’s really where we operate today. There are lots of products to keep GPUs maximally computing. And I completely agree with you. One hour later, that data needs moving. And the scale is massive. And the complexity of that data is significant. And so when you look at Qumulo, unstructured data lake, it has all four major file protocols NFS, SMB, Rest and HTTP. And very soon we’ll have S3. And so if you think about the five, that makes the five, inclusively, the five major unstructured data, protocols, being able to write and read and transcribe in a single, unified multi-cloud, unstructured data lake; that completes the grand plan for customers around their data analytics environments, and we’re pulled into that very often.
Okay, does that mean that you’ve made a conscious decision that you’re not going to go and partner Nvidia with things like GPUDirect?
We might, we might. That’s not off the table for us. It’s just that we’re doing so well in the at scale, unstructured data lake. That’s such a pronounced need for customers and it’s unfulfilled, if not for Qumulo. That’s keeping us quite busy today.
I can understand that because I think the primary storage for GPU servers might be in the tens of petabytes. The secondary storage is probably going to be in the hundreds of petabytes; maybe extend out to exabytes. You’re going to want to move the darn stuff off primary storage.
Yes. Then the other part of that equation is this multi-cloud point. You might have a GPU farm that’s training a model. And, of course, that’s important. But then what? And now that you’ve produced that dataset, how are you going to manage it across clouds? And that’s very much where Qumulo comes in. I know some vendors say no, no, it just will be on me in this datacentre in this rack forever. That’s just not how it is.
Because it’s not going to happen. Because racks have finite sizes and datacentres have finite sizes. And components have finite limitations. It’s not going to happen.
Yes. You know, something like storage class memory (SCM), for example, is kind of an interesting concept for one very specific thing. But going to a CIO, which I do often, they don’t want to talk about that. They want to talk about at-scale data management across clouds. Yes. Now somebody does [SCM-type stuff], and we, of course, get that, but that’s just not our market.
Suppose I say that my mental landscape round files is three sided, roughly speaking. On one side, there’s NetApp. On another side there’s Isilon and PowerScale. And the third side of this triangle is WekaIO and very fast scale out parallel storage. Spectrum Scale might be another one. Where in that space would you position Qumulo? Would it be in one place? Or would it be in several places?
I like to do it slightly differently, but I’ll use your three. Now we all think NetApp created the market back in the 90s. But the file system was created for Office document consolidation, fundamentally, which was a great innovation. And people had to get PowerPoint off their desktop and into a shared central storage environment.
PowerScale, Isilon, you know – that’s my old company. The notion there was that people were going to do more with file then than Office documents and so large file formats for the media and entertainment industry, and kind of digitising content was the core use case, but very much still with a proprietary hardware and systems approach. Dell might say Isilon is software-defined, except you can only buy it on this piece of Dell hardware period. I don’t think that that passes the sniff test for anybody.
This other group, like the one you mentioned, like any sort of parallel file system has its place. They’ve been around for a long time, like GPFS. There are science experiments, though. They require client-side drivers, they require an enormous amount of complexity. And it’s all about the infrastructure. If you have a very specific need, and you’re willing to invest the people, the significant amount of money, and the time to go make that work for very narrow need, you’ll do it. We have a completely different point of view, which is, instead of making it all about the infrastructure, we don’t want customers to even think about the infrastructure.
I understand that that plays back into the the invisible infrastructure part of Qumulo’s message.
You got it. And and the truth is in the history of time, you’ve never seen a parallel file system become standard in an enterprise because it’s very complicated for labs, for very specific use cases. For hardcore and sometimes ageing storage administrator, folks, it does have a good use case, but the broad enterprise that’s trying to scale and meet business requirements, and bring down costs and get onto the value of the data, not just the sort of production of it; that’s really our market.
To maybe round that out, we take share from NetApp. We take share from all the legacy folks as you can imagine – Dell PowerScale, IBM. And there are some of the emergent vendors that have made specific hardware optimizations. We see them sometimes, but actually less than you might think,
That will be like, for example, possibly StorOne and VAST Data to name a somewhat louder voiced competitor?
We see them. We actually are very happy with our win rates against them. But we see them less than you might think.
How’s the business doing? Can you provide any numbers without betraying any commercial secrets, run rates or customer numbers or deployed units or something like that?
We just crossed over $100 million of pure software sales [run rate]; now we just simply only measure software. We have nearly 700 independent customers and well over 1,000 deployments. There’s multiple exabytes of data out there in the world that’s being managed on Qumulo.
You can’t have 700 customers, and 1,000 deployments without having something that’s becoming quickly the standard for the enterprise. And the big question that I get get asked – not so much from folks like you, but from customers – is what’s the experience? We measure NPS every single quarter and it lands somewhere between 85 and 90.
That’s a very high score.
It’s high, particularly when the basis of customers is high. Because it’s easy to make three customers happy. If you have 700, that relies on the fit and finish of the product and technology, and then the at-scale way that we’ve designed the business to service those customers.
MCP – Model Context Protocol, recently (March 2025) announced by Anthropic, is a standard model for how applications and services can be discovered and interacted with in a universal way. MCP leverages language models to summarize the rich output of these services and can present information in a human-readable form. MCP is analogous to USB-C, which is a standard for connecting devices and operating systems, connecting agents to software applications and services. Until now, every agentic developer has had to write their own custom plumbing, glue code, etc., to do this. Without a standard like MCP, building real-world agentic workflows is essentially impossible.
Can an object storage system function as primary storage? The general assumption is that primary storage is the fastest storage you can get to support important applications such as online transaction systems where response time is critical, and object storage is too slow.
Object storage supplier MinIO takes a different view: that MinIO is primary storage.
CMO Jonathan Symonds made the case for this extraordinary assertion in a blog post. He started out by widening the definition of primary storage. “It seems that for some, primary storage equals workloads that are run on SAN or NAS. Needless to say, that is a ridiculous definition. … The fact of the matter is that the definition of primary storage is the data store on which your application runs. That means your database, your AI/ML pipeline, your advanced analytics application. It also means your video streaming platform or your website.”
He asserts that “In the public cloud, object storage is almost always primary storage. AWS EMR, Redshift, Databricks, Snowflake, BigQuery all run on object storage and have since Day 1. That makes object storage primary storage for those workloads (and thousands more).”
But Symonds conveniently forgets that AWS also has its Elastic Block Store (EBS) “for data that must be quickly accessible … EBS volumes are particularly well-suited for use as the primary storage for file systems, databases, or for any applications that require fine granular updates and access to raw, unformatted, block-level storage.” AWS also supports primary file steerage with cloud-native FSx for ONTAP.
AWS does not specifically define S3 object storage as primary storage, but it does say “Amazon S3 offers a range of storage classes designed for different use cases. For example, you can store mission-critical production data in S3 Standard for frequent access” – which supports Symonds’s point of view.
However he then confuses things even more, asserting that AWS S3 is priced as primary storage. “Object has ALWAYS been primary storage on the public cloud and remains so today. The cloud providers ensure this by pricing file at 13x and block at 4.6x the cost of object.” But that means primary storage is the primary choice because it is low cost – not because it is more performant than block or file storage.
Then Symonds says VMware sees object storage as primary storage. “When VMware announced Tanzu, did they have any SAN/NAS vendors in the announcement? No. It was all object storage. Did they expect that Tanzu would only deal with ‘secondary’ storage? Of course not. Do they understand the enterprise better than anyone else? You can make a strong argument for that case. VMware sees object storage as primary storage.”
Let’s just remind ourselves that Tanzu also contains vSAN – VMware’s block storage – and that Tanzu’s object storage is MinIO. Symonds is hardly a disinterested observer here.
He sums his argument up by claiming “The same goes for RedHat OpenShift, HPE Ezmeral, SUSE Rancher. Every one of them sees object storage as primary storage. That is not to say they don’t also think of SAN/NAS as primary storage – they do, they just recognize that those technologies are legacy when it comes to the cloud. They all recognize that the future is … wait for it … primarily object storage.”
So SAN and NAS are dead and objects are the future, says an object storage supplier with speedy software who ignores AWS block (EBS) and file (FSX for ONTAP) as well. Until AWS stops supporting EBS and FSx for ONTAP, or promotes S3 over them, we can’t say object storage is AWS’s primary storage. Not in the way database and other applications using block as well as file storage define primary storage.
Apple may buy NAND chips from China’s Yangtze Memory Technologies Corporation following the loss of production at the Kioxia/Western Digital joint venture foundries due to chemical contamination.
Bloomberg reports that Apple is testing NAND chips from Tsinghua Unigroup-owned Yangtze (YMTC) and has been locked in negotiations over a potential supply agreement for several months, indicating those talks with Yangtze started before the contamination accident at the Kioxia/WD fab in February.
Kioxia/WD chips are used in Apple’s iPhone and other devices. The iGiant made up for the lost production with orders from Samsung and SK hynix and is now looking to lessen its dependency on Kioxia and WD in order to maintain supply chain consistency and dependability. It has also had NAND supply deals with Micron and Samsung.
A volume deal with Apple would enormously improve YMTC’s standing in the world as a NAND supplier. It makes string-stacked 128-layer NAND (2x 64 layer die design) using Xtacking technology with separate controller logic chips and NAND chips. According to TrendForce research, YMTC accounted for about one per cent of total NAND capacity in 2020 and circa four per cent in 2021.
YMTC is behind the curve with regard to 3D NAND layer count where, basically, the more layers you have the lower the cost/bit of your die. The 128 layers in YMTC’s technology is an earlier generation than the 144 used by Solidigm, the 162 used by Kioxia and WD, and the 176 by Micron, Samsung and SK hynix. Another negative factor could be parent Tsinghua Unigroup’s bankruptcy process, potentially compromising YMTC’s financial stability.
DigiTimes, quoting industry sources, reports that YMTC NAND has passed Apple validation tests with small volume shipments to start in May.
However, Apple setting up a supply deal with a Chinese NAND manufacturer would run counter to US trade policy and the nation’s ambition to become less dependent on Chinese-sourced technology.
Blocks & Files thinks that a major Apple-YMTC supply agreement is unlikely due to Tsinghua Unigroup’s financial status and YMTC’s old technology – although talk of an agreement may help Apple’s negotiations with other NAND suppliers. A supply agreement with Solidigm, now that it is no longer part of Intel, would give Apple a US NAND supplier with more modern technology.
Neither Apple nor YMTC responded to media inquiries.
Danish cloud backup supplier Keepit announced the opening of its first two datacenters in Canada. Keepit is partnering with Equinix, enabling Keepit to provide a data storage offering that follows Canadian laws and regulations for businesses operating inside and outside of Canada. It says the datacenters will increase the company’s ability to offer low-latency data backup and recovery services across platforms such as Microsoft 365, Google Workspace, and Salesforce.
…
Backup-as-a-Service supplier Druva says its Data Resiliency Cloud has surpassed an average of 11 million daily users and it has over 220PB of data under management in the cloud. Its customer base is on track to complete more than 4 billion backups annually. More than one-third of all Druva customers now protect multiple workloads with the Druva Data Resiliency Cloud, while daily backup activity has surged by more than 60 percent over the last 12 months, it said.
…
Informatica has announced its Intelligent Data Management Cloud for Retail, which increases supply chain and inventory management efficiencies and unifies customer data. It is helping retail customers like Hershey, Unilever, Ulta Beauty, and Yum! brands to:
Boost productivity and cut costs by reducing business overhead and manual work for managing supplier information
Shrink supplier onboarding and qualification time from weeks to days
Improve collaboration, assess compliance and risk
Negotiate pricing and payment terms spending across the business
…
Krishna Subramanian
File life cycle manager Komprise has seen “rampant market uptake” of its value proposition for unstructured data management. It’s not releasing any numbers, though. Co-founder, president, and COO Krishna Subramanian told VMblog.com: “We doubled the rate of new customer acquisition last year, and our existing customers are also expanding their footprint: both of these contributed to our strong growth.”
…
NVMe/TCP storage supplier Lightbits will be supported as part of OpenStack Yoga, the latest release of the OpenStack open-standard cloud computing platform. OpenStack clusters will have access to software-defined block storage that delivers cloud-native, high-performance, scale-out, and highly available NVMe/TCP storage. Lightbits has committed to ensure interoperability with and availability through all OpenStack future releases.
…
Cloud file services supplier Nasuni is opening an Innovation Centre in Cork, Ireland, and will create up to 55 new senior engineering jobs over the next three years. The company is also expanding its presence in Germany, Benelux, and England as part of its global expansion. It has hired Derek Murphy as VP of Engineering EMEA, and he comes with experience from Forcepoint, McAfee, Intel, and Apple. Nasuni has a hybrid working arrangement in place across all its offices as it transitions out of COVID-19 measures. As Nasuni Ireland scales and hires people, the company intends to open a physical facility in the near future.
…
Researchers at the University of Vienna, the National Research Council (CNR), and the Polytechnic University of Milan have built a quantum memresistor device using a photonic quantum processor operating on single photons guided on a superposition of paths through waveguides laser-written on a glass substrate. One path measured the photon flow through the device and, using a feedback system, controlled coherent quantum information. A paper published in Nature explains the concept and proposes that it could be used in neuromorphic computing.
…
Cloud data backup startup Rewind is launching Backups for Jira, an automated backup and on-demand data recovery tool that protects a Jira Cloud Instance and all associated data. Rewind’s suite of cloud backup and recovery solutions support platforms like GitHub, Microsoft 365, and Trello. Rewind has also launched a game – Cover Your SaaS – that brings a touch of fun while building awareness of all the different threats that businesses face regarding SaaS data loss.
…
SMART Modular Technologies has announced the next generation of its DuraFlash ME2 family of SATA SSD products, which includes industry-standard M.2 2242, M.2 2280, mSATA, Slim SATA and 2.5” form factors. They are available in both industrial and commercial temperature grades and have versions that implement SMART’s SafeDATA power-loss, data-protection technology for graceful handling of power fluctuations and sudden power loss events. They use greater than 96-layer 3D NAND, are available in industrial and commercial temperature grades, and have a lower cost/bit than prior models.
…
StorONE is announcing a Backup-Infrastructure-as-a-Service (BIaaS) using its on-premises S1:Backup arrays in an opex consumption model. There is an introductory price of $5,450 per month for 1.2PB capacity. StorONE says it will revolutionize the economics of backup storage. A webinar has more details.
…
Replicator WANdisco has signed a follow-on agreement worth $1.2 million with a top 10 global communications company on top of an initial $1.5 million commit-to-consume agreement. The initial opportunity covered the migration of 8PB of data from Hadoop to the cloud. The extension covers more data to be migrated.
…
It’s World Backup Day today and many suppliers are saying organisations should back up their data and protect it from ransomware. The best way of doing this is, naturally, to use that supplier’s products and services.
Nvidia is building an AI supercomputer called Eos for its own use in climate science, digital biology, and AI workloads. Eos should provide 18.4 exaFLOPS of AI performance and will be built using Nvidia’s SuperPOD technology. How will its data be stored?
Eos will have 576 x DGX systems utilizing 4,608 Hopper H100 GPUs. There are 8 x H100 GPUs per DGX and 32 x DGX systems per Nvidia SuperPOD, hence 18 SuperPODS in Eos. Each DGX provides 32 petaFLOPS. Eos should be four times faster that Fujitsu’s Fugaku supercomputer in terms of AI performance and is expected to provide 275 petaFLOPS of performance for traditional scientific computing.
Nvidia Eos graphic
This will need a vast amount of data storage to feed the GPU processors fast enough to keep them busy. It needs a very wide and swift data pipeline.
Wells Fargo analyst Aaron Rakers writes: “Each of the DGX compute nodes will incorporate two of NVIDIA’s BlueField-3 DPUs for workload offloading, acceleration, and isolation (i.e. advanced networking, storage, and security services).”
We can expect that the storage system will also use BlueField-3 DPUs as front-end NICs and storage processors.
We envisage that Eos will have an all-flash datastore providing direct data feeds to the Hopper processors’ memory. With promised BlueField-3 support, VAST Data’s scale-out Ceres enclosures with NVMe drives and its Universal Storage software would seem a likely candidate for this role.
Nvidia states: “The DGX H100 nodes and H100 GPUs in a DGX SuperPOD are connected by an NVLink Switch System and NVIDIA Quantum-2 InfiniBand providing a total of 70 TB/sec of bandwidth – 11x higher than the previous generation.”
Nvidia SuperPOD graphic
Rakers writes that data will flow to and from Eos across 360 NVLink switches, providing 900GB/sec bandwidth between each GPU within the DGX H100 system. The systems will be connected through ConnectX-7 Quantum-2 InfiniBand networking adapters running at 400Gb/sec.
This is an extraordinarily high level of bandwidth and the storage system will need to have the capacity and speed to support it. Nvidia says: “Storage from Nvidia partners will be tested and certified to meet the demands of DGX SuperPOD AI computing.”
Nvidia storage partners in its GPUDirect host server CPU-bypass scheme include Dell EMC, DDN, HPE, IBM (Spectrum Scale), NetApp, Pavilion Data, and VAST Data. Weka is another supplier but only provides file storage software, not hardware.
Providing storage to Nvidia for its in-house Eos system is going to be a hotly contested sale – think of the customer reference possibilities – and will surely involve hundreds of petabytes of all-flash capacity with, we think, a second-tier capacity store behind it. Candidate storage vendors will pour account-handling and engineering resource into this like there is no tomorrow.
Data storage management software biz Open-E has certified Kioxia’s FL6 NVMe SSD series with its flagship ZFS-based Open-E JovianDSS data storage software. A solution document has details.
…
Kioxia is sampling new Automotive Universal Flash Storage (UFS) Ver. 3.1 embedded flash memory devices with 64GB, 128GB, 256GB, and 512GB capacities. Both the sequential read and write performance of the Automotive UFS Ver. 3.1 devices are significantly improved by approximately 2.2x and 6x respectively over previous generations. These performance gains contribute to faster system startup and over-the-air updates. Kioxia is providing no other details of the device. In January it was sampling a UFS phone memory card using QLC flash. Kioxia fab partner Western Digital announced a Gen 2 UFS 3.1 drive in June last year with 128, 256, and 512GB capacities.
…
Dr James Cuff
FabreX composable systems supplier GigaIO has hired Dr James Cuff as chief of scientific computing and partnerships. He will be tasked with helping design composable architectures that function at scale and will support and extend GigaIO’s technical, scientific computing platforms and services. Cuff took early retirement as the Assistant Dean and Distinguished Engineer for Research Computing from Harvard University in 2017.
“This is a true tipping point in our community and it is hard to fully explain how important and game-changing these current and future architectures we will build for our community at GigaIO will turn out to be. It is a once-in-a-lifetime opportunity to properly disrupt the industry, in a good way,” said Cuff.
…
Research house TrendForce says overall NAND Flash supply has been significantly downgraded in the wake of raw material contamination at a Kioxia and Western Digital fab in early February, becoming the key factor in a predicted 5-10 percent NAND Flash price appreciation in 2Q22.
…
Cloud file data services supplier Nasuni has announced support for the AWS for Games initiative with Nasuni for Game Builds. It uses S3 object storage as the back-end cloud, with file services built on top, and enables game developers and quality assurance testers to share and collaborate with teams around the globe on complex game builds. AWS for Games is an initiative featuring services and solutions from AWS and AWS Partners, built specifically for the video game industry.
…
Pavilion Data Systems announced technology enabling Windows customers to take advantage of NVMe-oF using NVMe/TCP or NVMe/RoCE drivers supported through the Microsoft WHQL program. Pavilion’s NVMe/TCP initiator provides seamless integration with existing Ethernet-based networks with 50 percent lower latency than current iSCSI deployments. Pavilion is also shipping a WHQL-certified NVMe/RoCE v2 initiator in conjunction with partner StarWind Software. NVMe/RoCE allows for a client to directly access an application’s memory bypassing the CPU and avoiding complex network software stacks to further improve application performance.
…
Vcinity, which provides global access to file data, has announced Vcinity Access. It has an S3 API and enables cloud-native applications that use Amazon S3 or S3-compliant object storage to remotely access and instantly operate on that data across hybrid, distributed, or multi-cloud environments, with local-like performance. It claims this eliminates the need to move or copy data to the cloud, between cloud regions, or between S3 buckets.