Privately held ExaGrid claims it had a record-breaking first 2023 quarter, with a customer count that’s now risen past 3,800.
These customers are using ExaGrid’s Tiered Backup Storage, purpose-built and scale-out backup appliances, with backups stored in a fast ingress and restore landing zone until being deduplicated for longer-term retention. ExaGrid competes with Dell’s PowerProtect and similar systems from HPE (StoreOnce), Quantum (DXi) and Veritas (NetBackup Flex) and, latterly, all-flash backup systems such as Pure’s FlashBlade.
President and CEO Bill Andrews said: “ExaGrid prides itself on having a highly differentiated product that just works, does what we say it does, is sized properly, is well supported, and just gets the job done. We can back up these claims with our 95 percent net customer retention, NPS score of +81, and the fact that 92 percent of our customers have our Retention Time-Lock for Ransomware Recovery feature turned on, and 99.2 percent of our customers are on our yearly maintenance and support plan.”
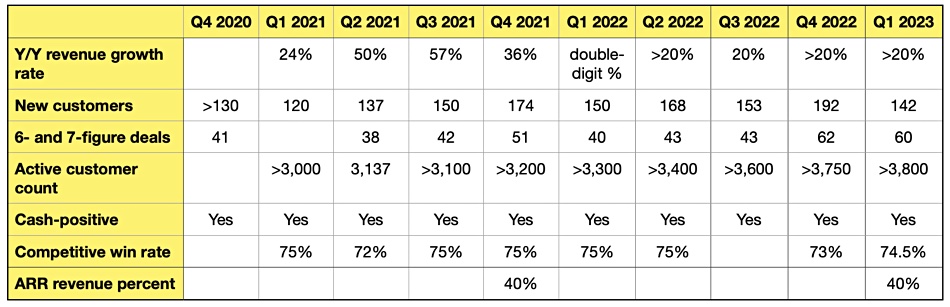
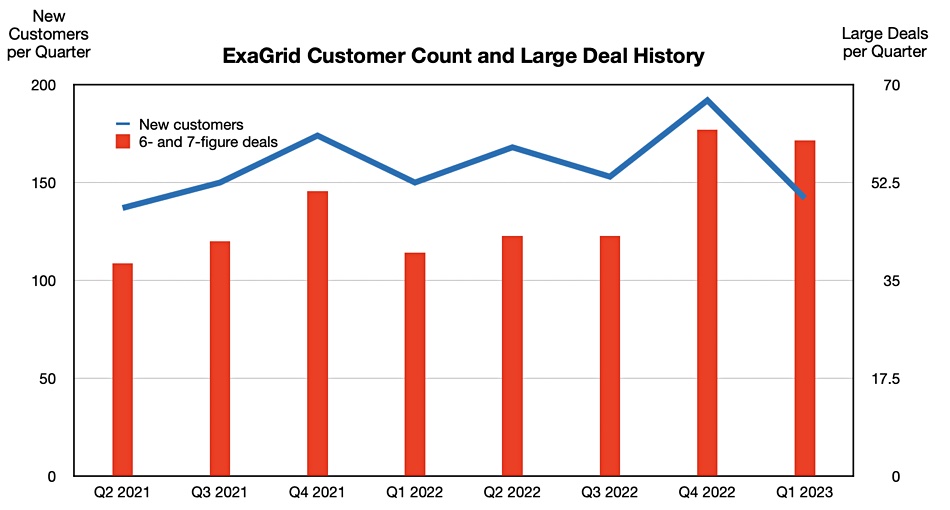
ExaGrid’s growth history
We don’t get to see actual revenue numbers but ExaGrid claimed it experienced:
A 74.5 percent competitive win rate for the quarter
141 new customers taking the customer count past 3,800
Over 60 six-figure new customer deals and three seven-figure new customer deals
Sales and support teams in 30 countries and customer installations in over 80 countries
Company has been cash, EBITDA, and P&L positive over the last 10 quarters
40 percent of revenue is ARR
Andrews said: “ExaGrid is continuing to expand its reach and now has sales teams in over 30 countries worldwide and has customer installations in over 80 countries. We have also added dedicated sales teams for the large enterprise and large IT Outsourcer organizations. Outside of the United States, our business in Canada, Latin America, Europe, the Middle East, Africa, and Asia Pacific is rapidly growing.”
Andrews sent out an internal memo claiming ExaGrid has “the fastest ingest for the fastest backups and the shortest backup window.” It features the “Veeam Data Mover, Landing Zone (no inline dedupe), job concurrency for parallel backup jobs, Veeam SOBR (Scale-Out Backup Repository) for front-end performance load balancing, encryption with self-encrypting drives versus encryption in software, optimized file system for large backup jobs, etc.”
This means backup and restore speed, with Andrews claiming it beat a rival “in side by side testing by 2X,” adding: “They are not optimized for large backup jobs, they don’t use the Veeam Data Mover, they don’t do job concurrency, etc. etc. etc. It is not about the storage, it is about the software before the storage.”
Data protector Cohesity is going to provide its data structures to OpenAI so that generative AI can be applied to threat and anomaly detection, potentially combating the ransomware plague.
Microsoft has invested in OpenAI and this Cohesity involvement is part of a suite of data protection integration activities between Cohesity and Microsoft, aimed at strengthening the appeal of Azure cloud services and Cohesity’s SaaS activities to enterprise customers. Microsoft has said it will invest $1 billion in Open AI and has gained exclusive rights to use OpenAI’s GPT-3 technology in its own products and services. Cohesity and Microsoft have also unveiled three product/service integrations and made two Cohesity services available on Azure.
Sanjay Poonen
Cohesity president and CEO Sanjay Poonen supplied a quote: “Cohesity is integrating with Microsoft’s broad platforms across security, cloud and AI – all in order to help joint customers secure and protect their data against escalating cyberattacks.
“This expanded collaboration will make it simple for thousands of Microsoft customers and ecosystem partners to access Cohesity’s award-winning platform.”
The three integrations are:
Cohesity’s DataProtect backup and recovery on-prem product and backup as a service offering, boh integrate with Microsoft Sentinel, a cloud-native security information and event management (SIEM) platform.
Cohesity integrates the Azure Active Directory and multi-factor authentication (MFA) to manage and access Cohesity products, including Cohesity Data Cloud and Cohesity Cloud Services.
Cohesity data classification is powered by BigID and BigID has integrated with Microsoft Purview to provide data discovery, privacy, security and governance intelligence.
Cohesity’s Fort Knox SaaS cyber vaulting offering is now available on Azure in preview form with general availability due in months. The Cohesity DataProtect Backup-as-a-Service (BaaS) offering supports Microsoft 365 and customers’ M365 data can be backed up to an Azure target destination.
Poonen’s company says it is already using AI to help customers detect anomalies indicative of an operating cyberattack, and believes AI can be used to analyze vast volumes of data at speed. It could enable IT and security operations to detect and respond to a security breach faster, with improved accuracy, and in a more rounded way, the firm claims.
Having an AI tool operate within a Cohesity data structure to better detect and respond to ransomware and other malware attacks could be a large improvement on current approaches.
Phil Goodwin, an IDC research VP, said: “We think integrating with Microsoft Azure will help Cohesity and its customers to stay a step ahead of cyber criminals through more intelligent security now and with other interesting use cases to follow.”
It will also help Cohesity make progress against competition from Rubrik and other cyber-security suppliers. A Cohesity-Microsoft webinar will provide more information about the two’s integration and joint AI activities.
IBM now provides direct, switchless access to a Power server’s flash drives, the aim being to enable more cores to access more drives with higher data access bandwidth.
The Power server products are IBM’s proprietary servers and pretty much the last proprietary server CPU technology holdout against the dominant x86 processors and rising Arm and Risc-V processor designs. The processors are used in Power servers and i systems, the old AS/400 which originated in 1988. IBM is updating both its Power and i product lines.
Steve Sibley
IBM’s VP for Power Product Management, Steve Sibley, writes in a post: “IBM is extending its I/O capabilities with the first known PCIe direct-attached 24-bay NVMe storage drawer in the industry.”
By direct-attach, IBM means there is no PCIe switch or other bump in the wire between the NVMe SSDs and the PCIe lanes leading to the processor cores. The aim is to provide full PCIe lane bandwidth between an NVMe drive and a CPU core that needs to read/write data from/to it. A PCIe switch is often used to aggregate lanes so that each drive only gets a part of the overall bandwidth available.
For example, Supermicro had a 20-drive server with PCIe gen 3 direct attachment in April 2020, the 2029UZ-TN20R25M. This had 80 lanes of PCIe gen 3 bandwidth between the processor and the drives, 4 lanes per drive. IBM is correct in saying it has the first 24-drawer direct-attach PCIe system, but Supermicro did it with 20 drives three years ago.
According to Big Blue, the benefits this brings to Power servers, compared to its current SAS-based Power alternatives, are:
Lowering $/TB for direct-attached IBM storage by 62 percent,
Nearly 10X more I/O bandwidth (GBps) and up to 3.7X more I/O operations/sec (IOPS),
The ability to directly attach up to 1.2 PB of storage (153 TB in a single drawer with support for up to 8 drawers) on a single E1080, and delivering over 85 percent more capacity/Watt,
Extending the capacity of Flash Cache systems required for large critical database applications,
Native boot capability for up to 24 partitions.
The E1080 is the top line model in IBM’s range of shipping five Power 10 products:
It has from 8 to 32 PCIe gen 5 adapter slots (8 per node) and supports up to 4 expansion drawers per node, which use PCIe gen 4 adapters. In detail, a system (processor) node supports 6 x PCIe Gen4 x16 or PCIe Gen5 x8 and 2 x PCIe Gen5 x8 I/O low-profile expansion slots per system node (maximum 32 in a 4-node system.)
IBM i product line updates
Technology refreshes for IBM’s i systems portfolio will ship in May, including improvements in IBM Navigator for i, allowing both end users and system administrators to access, manage, and monitor their IBM i environments better. Customers running complex plan data inquiries can realize performance improvements due to the SQL engine’s ability to exploit the Power10’s capabilities.
IBM is providing tape backup for its Power 10 i environments, with:
New 4-port 12Gbps SAS adapter, at least 2X faster than its current SAS adapters,
Direct connection to 8Gbps fibre channel tape libraries or standalone tape devices,
Support for LTO9 tape technology.
Lastly, IBM has partnered with FalconStor Software to bring enterprise-class data protection, disaster recovery, ransomware protection, and cloud migration to Power workloads through FalconStor’s StorSafe Virtual Tape Library (VTL) offering. This VTL provides backup to the cloud and on-premises so users can migrate, backup and restore Power Systems workloads to Power Virtual Server. It works with backup software to reduce capacity requirements and minimizes replication time by removing redundant copies of data with integrated dedupe technology.
Multi-protocol storage SW supplier DataCore is setting up a Perifery edge division with AI+ services it says provide preprocessing tasks at the edge of media and entertainment company workflows.
DataCore Perifery first surfaced in September last year when DataCore partnered shared storage supplier Symply to place its software in the Symply Perifery media archiving appliance. This has S3-native object storage software using DataCore’s acquired Caringo Swarm technology. The Perifery appliance integrated with workflows used in media production, post-production, studios, sports, and in-house creative teams.
Dave Zabrowski, DataCore’s CEO, said in a statement: “Building on the recent acquisitions of Object Matrix, Caringo, and MayaData, Perifery was created to bring a clear focus and attention to the needs of high-growth, data-driven markets. With the launch of our Perifery division, we’ve invested in extremely talented and experienced individuals in the space, and we look forward to bringing innovation to the edge.”
Abhijit Dey
Perifery division GM and COO Abhijit Dey quoted a Gartner finding that, by 2025, over 50 percent of enterprise-managed data will be created and processed at the edge, and said: “With the Perifery family of workflow solutions, we are addressing the evolving requirements of high-growth edge markets while helping customers avoid unpredictable public cloud service and transfer fees.”
Dey was DataCore’s Chief Product Officer and has spent 24 years of his working life as a backup guy at Veritas, Symantec and Druva. DataCore has set up a Perifery website with a leadership page that looks like DataCore’s leadership page. Perifery almost looks like an independent company or a new face for DataCore.
Perifery AI+
The first Perifery division product is AI+ and it is aimed at providing media workflow processing at the edge, so-called preprocessing, where the media is generated and can, with AI+, be worked on before it’s sent up to the public cloud or to a datacenter. AI+ is a set of application-centric services for content production workflows. It is integrated with the Perifery Transporter on-set media appliance, Swarm software, and Perifery Panel for Adobe Premiere Pro.
The outfit’s Symply Transporter
The Transporter is a content shuttle with a rugged eight bay desktop design and dual 25Gb Ethernet interfaces. This is for physical transfer of large content files from edge locations to datacenters.
Dey said: “Many media production organizations have adopted AI cloud-based apps and services to process their digital assets. But the cloud has an unpredictable cost model and requires significant time and effort to upload, download, and manage processing services coming from various sources.”
The first preprocessing functionalities available on Perifery AI+ will include object recognition and smart archiving. DataCore says AI+ will improve customers’ workflow efficiency, reduce costs, speed up time of delivery, and monetize digital assets faster.
DataCore has moved its Object Matrix Appliance, Cloud and Quattro products as well as its Swarm software and Swarm CSP offerings into the Perifery division. The division also houses the Symply Appliance and Transporter.
There are more than 400 Perifery channel partners worldwide to help distribute DataCore’s Perifery offerings from the get go. Perifery will demonstrate its Transporter running containerized Swarm with Perifery AI+ and third-party object recognition software at the 2023 NAB Show in Las Vegas at booth N1331.
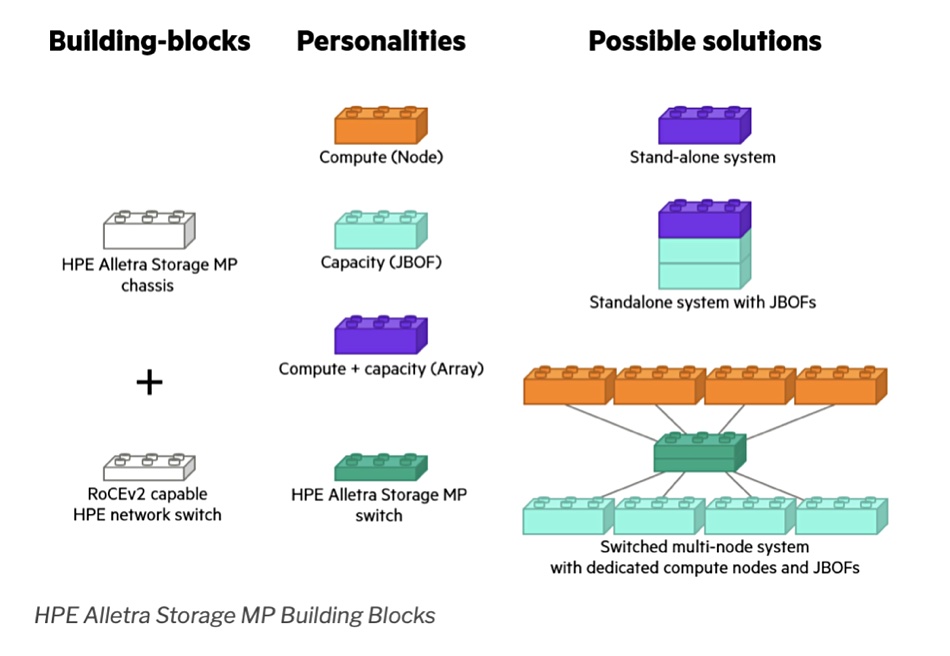
With its Alletra Storage MP tech HPE is standardizing its storage array hardware on scale-out storage nodes; Proliant server chassis with all-flash NVMe-fabric connected local storage, and Aruba switches. Dimitris Krekoukias, writing as Recovery Monkey, has written two informative blogs about what it’s doing.
He writes in the first blog: “At a basic level, there are just two items: a chassis and (optionally) dedicated cluster switches. The chassis can become just compute, or compute with storage in it.” The chassis can also be presented as a JBOF (just a box of flash) supporting NVMe SSDs, storage-class memory, and NVDIMMs. Krekoukias blogs: ”It has storage media and two ‘controllers’, each with an OS, RAM and CPU. It’s just that the expansion slots, CPUs and memory used are minimal, just enough to satisfy JBOF duties.”
“Increase the JBOF compute power and expansion slots, and now you can use that same architecture as a compact storage array with two controllers and storage inside the same MP chassis. For bigger capacity and performance needs, a disaggregated architecture can be used, connecting diskless compute to JBOFs in large clusters.”
Uniform hardware quality was a design criterion. Krekoukias blogs: “The quality of the hardware had to be uniform – the same high-end hardware quality should be used for both the ultra-fast versions of Tier-0 platforms with 100 percent uptime guarantees as well as their entry versions and everything in between.”
He says: “Things like a plethora of PCIe lanes, huge memory throughput and high core density are important for performance: we standardized on AMD CPUs for the new hardware.”
Why use Proliant Servers as the controllers instead of traditional storage controller hardware? Krekoukias says: “HPE sells hundreds of thousands of servers each quarter after all. Storage controllers (even if you add up all storage vendors together) are a tiny fraction of that number. Taking advantage of server economies of scale was a no-brainer.” This brings component pricing and supply chain reliability advantages.
This hardware commonality is quite different from HPE’s other storage products, including the Alletra 9000, 6000, 5000 and 4000, and from other suppliers, such as Pure Storage and Dell. It is implied by Krekoukias’ blog that HPE’s common hardware base approach will be applied to other storage products. In our view that could mean that next generation Alletra 9000, 6000, 5000 and 4000 hardware could transition to Alletra Storage MP base hardware components.
Put another way, Primera, Alletra 9000, Nimble and Alletra 6000 customers can potentially look forward to a migration/upgrade to a common Alletra MP hardware base. We are also confident that object storage access support will be added to Alletra, but who’s object storage? VAST Data, the source of Alletra MP file storage software, supports object storage and so is an obvious candidate. But HPE has existing sales partnerships with object storage suppliers Cloudian and Scality, and could use software technology from one of them.
Perhaps we’ll hear more at HPE’s Discover event in Las Vegas, June 20–22.
Block access personality
In a second blog, looking at Alletra MP block access storage, Krekoukias revealed more information about HPE’s new block storage OS. We already know it has a Primera base with added disaggregated compute and storage box support plus Nimble data reduction but Krekoukias tells us more about this, removing scalability limitations and improved efficiency.
It has Active Peer Persistence, meaning active-active access to sync replicated volumes. With this “migrations from older systems will be easy and non-disruptive (we are initially aiming this system at existing smaller 3PAR customers.”
“Redirect-on write (ROW) snaps were carried over from Nimble. As was always doing full stripe writes and extremely advanced checksums that protect against lost writes, misplaced writes and misdirected reads.”
The software allows single node addition, dissimilar node addition, and simultaneous multiple node loss in a cluster. There is no volatile write cache as a write-through scheme is used; “where dirty write data and associated metadata is hardened to stable storage before an I/O complete is sent to the host. The architecture allows for that storage to be a special part of the drives, or different media altogether. An extra copy is kept in the RAM of the controllers.”
Krekoukias says: “This way of protecting the writes also allows more predictable performance on a node failure, simpler and easier recovery, completely stateless nodes, the ability to recover from a multi-node failure, plus easy access to the same data by way more than 2 nodes…”
“Eventually, the writes are coalesced, deduped and compressed, and laid down in always full stripes (no overwrites means no read-modify-write RAID operations) to parity-protected stable storage.
The redirect-on write snapshot method avoids a write performance penalty which persists in write-intensive environments. The ROW method treats snapshots as a list of pointers. When blocks in a volume are going to be overwritten the snapshot system is updated with the pointers to the about-to-be-overwritten blocks and then the new data is written to a fresh area of the drive.
The existing old data blocks are added to the snapshot system without having to be read and copied in separate IO operations. There is only one I/O operation; a write, plus the snapshot pointer updating. Consequently ROW snapshots are faster than the alternative Copy-on-Write (COW) snapshots.
At first, Alletra MP block storage will use compute nodes with drives inside the chassis. A near-future release will introduce “the larger, switched, fully disaggregated, shared-everything architecture for much larger and more flexible implementations.” Scale-out block in other words.
We’ll hear more details on Alletra MP file storage before the end of the month.
Interview StorPool CEO Boyan Ivanov and his team see their block storage access software, running on multiple controllers, as an example of the “post-SAN” storage that’s needed in an environment that they believe has moved on from the invention.
SANs (Storage Area Networks) were developed from the mid-nineties onwards as a way of giving server-based applications a way to access more storage than an individual server could usefully manage and as a way to provide a shared pool of block storage for many servers. It was and still is a popular and widely used on-premises IT technology, but newer ways of providing block-level storage are claimed to solve problems which limit SANs.
Boyan Ivanov.
We asked Storpool CEO Boyan Ivanov a set of emailed questions about the problems he thinks beset SANs and what alternatives exist for SAN users.
Blocks & Files: How is it that the SAN concept, developed in the ’90s, is not working now?
Boyan Ivanov: The SAN concept was developed as a way to provide shared storage capabilities to applications, so it abstracts the data from a single physical device or host/server. This was a way to provide reliability and data longevity, regardless of hardware failures, and to consolidate data silos.
This was a good approach, but the design dates back to a time when business demands from applications and the size of IT were rather small. You may say minuscule by the workloads and business needs of today. There used to be tens of servers connected to a single SAN storage array. There are still many cases where the SAN approach makes sense and is very good. Typically this is the case when the size of the IT systems is small, or less complex and demanding.
However, most applications of today require a very different approach. One is they operate on a much, much larger scale, which makes using specialized, single-purpose storage arrays (i.e. SANs or all-flash arrays, AFA) unfit. Today’s data centers have tens of thousands of servers, all needing extremely fast access to the storage system. So we need a new way of thinking about data storage.
Also end users today want always-on, blazingly fast applications. Businesses need to deliver these at lower and lower budgets and in increasingly more complex and unpredictable environments. The demands for agility, performance, uptime, operational efficiency, and cost optimizations simply cannot be met by the storage array architecture.
We need a new approach and a storage architecture designed for the demands of this century going forward, not for the last one.
Blocks & Files: Can you summarize the problems?
Boyan Ivanov: The old approach to storage has so many issues.
The traditional SAN, which is a dual-controller, shared disk system is just too inflexible. What happens if six months after you install your building block, you realize you need lower latency or higher capacity? How do you do that without breaking up your building blocks?
Modern businesses operate in the always-on operating model. There are no maintenance windows. Applications work 24×7. Provisioning, scaling, etc. need to happen within that model. This is not how traditional/legacy SANs and flash arrays operate.
Controllers often become performance bottlenecks, which are difficult to address. Adding to the rigidity of the solution.
Large-scale (multi-rack) availability is difficult to manage in traditional arrays. For example, taking several racks down to address a power issue would be a major project requiring synchronous replication with a SAN solution.
There are high-cost system lifecycles and misaligned lifecycles between storage and servers.
Traditional storage arrays generally have slow adoption of innovation compared to industry-standard servers. The latest networking and CPU and high-speed DRAM and media always appear first on commodity servers.
Traditional SAN arrays are difficult to manage at scale. You always end up with multiple silos to take care of.
SAN/AFA (All-Flash Array) storage systems were built with the idea of being managed by a graphical interface (GUI) by hand, by highly-trained storage administrators. And users of today need a self-service, API-driven storage that they do not log into. It’s integrated into their IT software stack. Customers don’t want to be buried in service tickets for every minor provisioning change – they need self-service and dynamic provisioning so there’s no service interruption.
Blocks & Files: Can the SAN concept be improved?
Boyan Ivanov: The short answer is no, and we’ve written about why a while ago.
To give it an analogy – it is impossible to turn a ship into an airplane when you need cargo transported from one place on Earth to another. They are both storage and transportation appliances, yet the architecture and utility are very different. They intersect on a small area of cases and are fit for different purposes, use cases, and ways of running a business.
In more practical terms – while the now legacy storage paradigm gets improved – faster drives, bigger controllers and interconnects – it is still handicapped by its architecture, developed in the 1990s. We need a radical departure from this approach.
Blocks & Files: If the SAN concept has run out of road where do we go from here?
We are moving away from a hardware-centric approach to a software-centric one. The value is (and has always been in the software). Standard hardware, managed by smart software is so much more flexible, agile, faster, and cost-efficient.
It is a fluid, multi-controller system, based on standard servers, running applications as well as storage. It’s programmable, flexible, integrated, and always on. It is scalable online, both in terms of capacity and performance. It makes hardware lifecycle management, forklift upgrades, maintenance windows, and downtime a thing of the past.
It is the way of the future for most modern IT workloads and teams and increasingly so for traditional workloads like databases and core applications, which now operate at a much larger scale.
And much of the component innovation that everyone focuses on is just a building block for a software-centric architecture. NVMe devices. Checked. NVMeOF/TCP. Checked. CXL. Checked. DNA storage – likely so, too. Quantum storage anyone?
Blocks & Files: Do you think that we need a new approach to data storage?
Boyan Ivanov: It is not that we do. It is the current state of the world that imposes one on us.
The requirements for speed, flexibility, and cost efficiency that each IT infrastructure team is facing are not being addressed with the architecture of the last century.
As a result, there is a lot of extra work and workarounds that IT teams now do and take for granted, while end users just struggle.
Without going down the rabbit hole, just a few examples:
Performance does not scale, separately from capacity – if you do not get the needed performance – get one more box. Now you have data silos and more boxes to manage
Waiting for months or years, to get the latest technologies, at a humongous price
Downtime on upgrades, refresh cycles, scheduling maintenance windows
Performance degradation of the solution, as you fill it up
Applications choking for performance, leading to application & database splitting & sharding. And so complexity and cost explode.
Vendor lock-in and price hikes or dead-end streets, when a SAN line gets discontinued.
All these are not sustainable anymore and create missed opportunities, cost millions of dollars, and squander human potential. This is why we need a new approach to running mission-critical applications and managing their most important primary data.
Blocks & Files: Dell, NetApp, IBM, Infinidat and others would say the SAN concept is healthy. How are they mistaken?
Boyan Ivanov: You cannot get a radically different outcome by doing incremental improvements to the existing technology.
The SSD was not an improved HDD. It was a new concept, made possible at a certain stage of technical progress. It was a quantum leap.
Note that these technologies co-exist today. Companies are deploying more HDD capacity compared to 10 years back when we barely had SSDs. However, now every core application is using NVMes.
So there is nothing wrong with SANs and AFAs. They are here to stay and will be used for certain use cases. But the bulk of the workloads, the important things, are switching to software-centric storage.
For example, how many SANs are Amazon or Google using for their EBS and persistent disk services? Zero right? It’s an insane question to ask. At their scale they have figured out this is not done by a hardware appliance, it’s software.
And out of all rudimentary implementations of storage software, StorPool is the most advanced, yet proven block-storage data platform on the market. It is giving the missing building block to customers, running diverse and demanding workloads at scale. We built this because we saw how the world is changing and what users need, not what is still the thing that is sold the most, but on the slide.
Blocks & Files: What do you recommend and why?
Boyan Ivanov: We recommend that people reevaluate how they think about storage. It is not a hardware appliance anymore. It is fluid, it’s software-driven.
Further data storage is not a single component anymore. To start with, current IT environments are very interconnected – compute, networking, and storage are becoming one integral system, more tightly coupled.
The impact of a next-generation storage platform is unlocking value across the board.
From more obvious things, like reduced datacenter footprint, less energy consumption, and fewer man-years spent on repetitive manual tasks. To unexpected gains – much faster applications, faster time to value, new high-value services, less employee time wasted on unproductive work, and more done by the team for the same amount of time. Then you have reductions in TCO as faster storage can optimize compute and networking costs, as our customer Namecheap found it can get up to 60 percent savings on compute resources. So a next-gen storage solution can ease staffing shortages and improve employee happiness while optimizing the cost structure and profit margins of the entire business.
In practice: we recommend that people start their datacenter design with their storage requirements. Making the wrong decision around storage is so expensive in the long run. It’s not just the cost and hassle of upgrading or replacing a mistake. It’s living with the mistake. Living with poor application performance harms all phases of your business. Lost customers because of slow transactions. Lost productivity due to slow queries. Lost business opportunities because your team is fussing with their storage solution instead of investing in growing their business.
When we talk with prospects, they are aware of the points and limitations of traditional SAN architecture. They just don’t know that they have better choices. So my advice to them is to demand better.
Wall Street analyst Aaron Rakers reckons that AMD’sPensando DPU adoption will be mostly driven by hyperscale cloud deployments and there is a $5-6 billion total addressable market for such DPUs in the datacenter over the next five years. The market is driven by next-gen workloads featuring parallel processing and heterogeneous compute architectures, datacenter disaggregation and composability, and workload isolation through zero-trust architectures. AMD noted that revenue has “ramped significantly” during its 3Q22 and 4Q22 earnings calls, driven by positive cloud adoption and a building enterprise pipeline.
…
Dell has been improving its data protection products: PowerProtect DD Operating System (PPDDOS), PowerProtect Data Manager (PPDM), PowerProtect Data Manager Appliance (PPDMA), and PowerProtect Cyber Recovery (PPCR). PPDM gets auto discovery of Oracle Data Guard Federated, providing better management of Oracle backups and restores in a high-availability Data Guard environment. PPDM is now integrated with Oracle Incremental Merge (OIM), enabling users to create synthesized full backups at the cost of an incremental backup, meaning quicker Oracle backups with better dedupe ratios and faster recoveries.
PPDMA gets multi-factor authentication and Active Directory integration for single user login management. Multiple virtual local area network (VLAN) uplink management provides faster input/output data rates. Users can view and download all audit logs from a single location in the UI.
PPDDOS extends Smart Scale for PowerProtect appliances support to on-premises instances of PowerProtect DD Virtual Edition. PPDDOS’s Management Center supports RSA for multi-factor authentication.
PPCR for AWS allows automated recovery with PPDM within the AWS vault. Multiple vaults can be configured in the same AWS cloud region, meaning a more scalable recovery strategy. PowerProtect CyberSense has multi-link connections for load balancing, dynamic licensing to remove stale hosts from CyberSense capacity meters for accurate licensing. Analytics can run on Hyper-V workloads protected with Avamar and PowerProtect DP appliances.
…
Dremio has announced that the first chapter of its book, Apache Iceberg: The Definitive Guide | Data Lakehouse Functionality, Performance, and Scalability on the Data Lake, is available for free. The complete book will include lessons on achieving interactive, batch, machine learning and streaming analytics, without duplicating data into many different systems and formats. Readers will learn the architecture of Apache Iceberg tables, how to structure and optimize them for maximum performance, and how to use Apache Iceberg with data engines such as Apache Spark, Apache Flink, and Dremio Sonar.
…
Gartner has published its storage market revenue numbers for Q4 calendar 2022. Total revenue was $6.39 billion, up 7.5 percent on the year. All-flash storage accounted for 50.8 percent of that, $3.25 billion. Total external capacity shipped was up 13 percent year on year (primary +18 percent, secondary +5 percent, backup +7 percent). All-flash capacity was 18.2 percent, down fro 18.4 percent a year ago. Dell earned most revenues, $1.5 billion, up 2.5 percent annually. HPE had $659 million, up 7 percent year over year, and Pure $507 million, giving it a 15.6 percent AFA revenue share; it was 17.7 percent in the year-ago quarter.
…
Sino-American distributed OLAP startup Kyligence has released Kyligence Zen, a metrics platform that centralizes all types of metrics into a unified catalog system, providing unified and intelligent metrics management and services across an entire organization. Users can define, compute, organize, tag and categorizing them, and share metrics with other relevant teams. A Zen Metrics Language (ZenML) simplifies onboarding metrics data from different systems e.g. uses existing digital assets from Business Intelligence (BI) systems or data warehouse query histories. Kyligence Excel Connector enables users to access metrics from their BI tool of choice, without any IT involvement.
…
Connor McCarthy
MariaDB has appointed Conor McCarthy as CFO, effective April 10. McCarthy, who has over 30 years leading finance organizations at high-growth companies, brings significant experience scaling software-as-a-service (SaaS) businesses. Previously, McCarthy was CFO at Ideanomics, a NASDAQ-listed cleantech company, where he developed the revenue models for vehicle-as-a-service and charging-as-a-service products. Prior to Ideanomics, McCarthy was CFO at OS33, leading due diligence for a successful equity raise, and CFO at Intent Media Inc., closing two committed loan facilities resulting in $20 million in reduced capital committed.
…
Samsung has capitulated to market reality and is cutting memory chip production due to a massive drop in operating profits from the oversupplied market. First 2023 quarter operating profits of ₩0.6 trillion ($455 million) were 96 percent lower than the ₩14.12 trillion reported a year ago, the lowest profit for any quarter in 14 years, according to Reuters. It says it is cutting chip production meaningfully but not by how much. Samsung will release detailed earnings, including divisional breakdowns (DRAM vs NAND), later this month. Micron and SK hynix have already announced memory chip production cuts.
Nasuni aims to become a data intelligence company, using software to analyze and locate automatically indexed and tagged file data.
Jim Liddle.
Jim Liddle, VP for Nasuni’s Access Anywhere Product, told us the business – which currently supplies cloud-based file services, in contrast to on-premises filers – has exceeded a $100 million annual revenue run rate, and stepped over the 750 customer mark. Many of its clients are large and geo-distributed enterprises, he added. It has some 500 staff, runs in the three big public clouds, has a CEO with experience of running listed companies, and a new CRO. What’s next?
Company-wise it looks like an IPO may be on the cards, and in terms of technology Nasuni wants to build on its file metadata base, both penetrating file data and broadening its overall scope.
“We index all of a customer’s data today. We’re working on expanding this to include the content.” That means reading files and indexing the content. How? “Our indexer integrates Apache solr and we use Apache Tika as the metadata extractor.”
Apache solr is an open-source full text search software platform using Apache Lucene. Liddle said Lucene and Tika need to be integrated with a data source file, and given rules to tell them what to detect and extract. The rules can define semantic terms and also words to ignore.
“We use graph technology to build our content index.” Storage admins can create their own rules and Nasuni adds tagging on top of these.
All files that are content-indexed have to be fully read, but subsequent updates are read on their own with any fresh content index entries added to the existing file’s content index.
A search on the content index returns a path to the file. Users instituting such searches can only access files they are allowed to see, with an Active Directory or similar permissions facility used. A user could search for files with content related to a particular project name and have them tagged with a group identifier. This has obvious applicability to legal activities and grouping files which mention a product, a department, a subsidiary, a person, a customer, etc.
The next stage would be to use this content indexing to automate the discovery of sensitive and/or personal identification information (PII). This PII detection could work in background mode and result in an automatic quarantining of discovered files.
The third stage, influenced by Large Language Model AI/ML software, would augment the content indexing on a vertical basis using what Liddle called “Big AI.”
For example a user could ingest a video into their file system. Previously they have set up video content rules. The video is passed to Google Vision AI which can classify images and videos and their content. It returns metadata which could include a scene-by-scene description, an audio transcription, a copyright yes:no indicator, and individuals in an image or video. This is passed back to Nasuni which adds it to the file’s existing metadata and so it becomes part of Nasuni’s file metadata search space.
We have a 3-part roadmap here that includes Nasuni adding full text file indexing, search and actions based on the indexed content, and finally media file content indexing. It will no longer just be providing data access but helping management activity based on file content.
Liddle said: “Nasuni is a data management company moving into data intelligence.” Data governance, CTERA’s focus, is part of this, but data intelligence means much more than governance. Automated content indexing and searching open doorways into an organisation’s filed content memories and enable it to discover and respond to much, much more than database records and website form box input.
Sorin Faibish has resigned from his director of product solutions role at block storage migrator Cirrus Data Solutions. He is now a performance engineer at NAS supplier OpenDrives.
…
ALTR, an automated data governance policy enforcement and data security supplier, has appointed Jonathan Sander, Snowflake’s first Security Field CTO, to its board.
…
Ascend.io announced a new product to manage data mesh architectures end-to-end from multiple cloud platforms such as Snowflake, Databricks and BigQuery, among others. The Ascend Data Pipeline Automation Platform is a single platform with, we’re told, intelligence to detect and propagate change across a company’s ecosystem, ensure data accuracy, and quantify the cost of its data products. The new Data Mesh capabilities allow teams to package data into products that can be easily consumed and reused across the organization, while assuring the lineage of that data to ensure that information is current and accurate, Ascend.io said. More information here.
Enrico Signoretti
…
GigaOm analyst Enrico Signoretti, of GigaOm Radar and Sonar diagram fame, has joined Cubbit as its VP for Product and Partnerships. Cubbit supplies geo-distributed object storage that’s S3-compatible and immutable.
…
Data lake company Databricks announced its Databricks Lakehouse for Manufacturing, an open, enterprise-scale lakehouse platform tailored to manufacturers that unifies data and AI and, so we’re told delivers record-breaking performance for any analytics use case. Available today, Databricks’ Lakehouse for Manufacturing breaks down silos and is designed for manufacturers to access all of their data and make decisions in real-time, the vendor said. Databricks’ Lakehouse for Manufacturing has been adopted by DuPont, Honeywell, Rolls-Royce, Shell and Tata Steel.
…
File migrator and mapper DataDobi reckons orphaned data left behind by departed personnel can be located with its StorageMAP product. Such orphaned data presents, it said, compliance, security, operational and reputational risks. StorageMAP can help you derisk it, it added: “Bottom line, ignoring the risks of orphaned data is not an option. If you don’t take steps to manage your data effectively, your business’s safety, reputation, and financial stability may be at stake. Don’t wait until it’s too late – act now with StorageMAP.”
…
Fivetran, which supplies automated data movement software, announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format. Iceberg, Fivetran said, offers atomic, consistent, isolated and durable (ACID) transactions for data lakes. Tomer Shiran, co-founder and CPO at Dremio, said: “Fivetran’s support for Amazon S3 and its standardization on Iceberg format makes it easier than ever for organizations to get their data into a lakehouse. With Fivetran, AWS and Dremio, organizations can build their open data lakehouse architecture for users to quickly access and query data and provide critical data-driven business insights.”
…
IBM Spectrum Scale is now available in Google Cloud courtesy of Sycomp. The Sycomp Storage Fueled by IBM Spectrum Scale product is said to optimize performance for the cloud, deploy in minutes, support auto-tiering to reduce costs, and allow customers to concurrently access data from thousands of VMs, with data access via NFS and the native Spectrum Scale client. The solution is available in the Google Cloud Marketplace, as a VM-based offering that deploys within a customer’s project, and is supported and maintained by Sycomp.
…
IDC has published its first-ever forecast for the performance intensive computing as a service (PICaaS) market. It projects that the total worldwide PICaaS market will grow from $22.3 billion in 2021 to $103.1 billion in 2027 with a compound annual growth rate (CAGR) of 27.9 percent over the 2022-2027 forecast period.
…
Think your filesystem is large? InsideHPC reports on the Orion file system at the Oak Ridge National Laboratory’s Frontier supercomputer. It occupies 50 racks with up to 700 PB capacity across SSDs and HDDs using open-source Lustre and ZFS. There is 11.5 PB of NVMe SSDs using 5,400 drives with a 10 TB/sec peak write speed, 679PB of HDD capacity using 47,700 drives with peak read speed of 4.6 TB/sec and peak write speed of 5.5 TB/sec, and a 10 TB NVMe SSD metadata tier based on 480 drives.
…
MASV, which offers a fast, large-file transfer for video professionals, announced ‘Send from Amazon S3,’ which enables users to select files from their storage and share them via a MASV link or email. ‘Send from Amazon S3’ combines with MASV’s existing ‘Deliver to Amazon S3’ to enable complete cloud-to-cloud workflows within the Amazon Web Services (AWS) ecosystem.
…
The Cyberspace Administration of China has initiated a security review of Micron’s products sold in China. Its announcement cites the reasons as ensuring “the security of the key information infrastructure supply chain, prevent network security risks caused by hidden product problems, and maintain national security.” Micron, we understand, sells DRAM and NAND SSDs in China and said it stands by its products. This could be much-delayed retaliatory action for the US restrictions on Huawei and the wider chip industry in China. It also signals that China has the capability of sourcing Micron-class DRAM and NAND products elsewhere, perhaps from Chinese manufacturers. Some 14 percent of Micron’s business is in China and it has offices in Shenzhen and Shanghai and a chip packaging facility in Xian. Some non-Chinese companies buy its products for manufacturing operations in China.
…
Martin Cooper
Nebulon’s VP Solutions Architecture and Customer Support, Martin Cooper, has resigned after three and a half years. He’s joining Continuous Data Protection technology supplier JetStream as VP for EMEA.
…
NetApp has replaced departed CloudOps boss Anthony Lye (he went to Palentir in July last year) by hiring Haiyan Song as the new EVP and GM of its Cloud Operations Business. Song was previously EVP and GM of Security and Distributed Cloud at F5. She has held senior leadership positions at Splunk and HPE, as well as various engineering leadership roles at database management and ecommerce companies.
…
Data protector and cybersecurity pusher Rubrik is setting up a CISO Advisory Board. The board is chaired by Chris Krebs, the first Director of the US Cybersecurity and Infrastructure Security Agency (CISA) and founding partner of the Krebs Stamos Group. The new members include:
Aaron Hughes, Senior Vice President and CISO, Albertsons
Marnie Wilking, CISO, Booking.com
Marene Allison, former CISO, Johnson & Johnson
Amit Aggarwal, Head of Cybersecurity, Moderna
Christophe Blassiau, SVP, Cybersecurity & Product Security, Global CISO & CPSO, Schneider Electric
The board’s mission as a cybersecurity coalition is to lead on strategies for collaboration across private and public sector organizations to address the unprecedented growth of cyberattacks.
…
NAND fabber and SSD supplier SK hynix says it has no plans to make additional production cuts, according to The Korea Times. It had previously said it would reduce investments by 50 percent y/y in 2023. Vice Chairman Park Jung-ho said: “We will change our management plans following the US-China conflict while buying as much time as possible.”
…
Sternum has revealed two new vulnerabilities in several QNAP storage operating systems. The vulnerabilities were found by Amit Serper, the director of security research for Sternum, who was prominent in the disarmament of NotPetya ransomware. The vulns impacts QTS, QuTS hero, QuTScloud and QVP (QVR Pro appliances). QNAP acknowledged the problem and issued the following CVEs: CVE-2022-27597 and CVE-2022-27598.
…
In a YouTube video, VAST Data CMO and co-founder Jeff Denworth told interviewer Steve McDowell of NAND Research: “We’re working on essentially building a thinking machine. In June we’ll explain all the parts that go into that… It very much starts from the ground up and our realization is that people that have kind of outsourced their software to the cloud have also kind of outsourced the thinking around how to get the most value out of infrastructure. So we wanted to start from a clean sheet of paper. We wanted to build from the ground up on a superior architecture and then make it more and more capable over time, and that’s all I’m going to say before June.”
…
Virtana, which supplies AI-driven solutions for hybrid cloud management and monitoring, has released an independent research report, The State of Multi-Cloud Management 2023. It says 83 percent of IT leaders are using more than one cloud service provider (CSP), and 44 percent are using more than three CSPs. The survey results demonstrate growing management and data complexities that come from the high number of cross-provider interactions. Virtana said it’s SW can help with the problem.
…
Zadara is partnering with Japan-based Internet services and cloud solutions provider BroadBand Tower to provide the Zadara Edge Cloud Services for BroadBand Tower’s launch of its c9 Flex-N Infrastructure-as-a-Service Platform – a cloud-based full stack solution including storage, compute, and networking. BroadBand Tower supports a large portion of Japan’s internet: sites including top portals, ecommerce, video distribution, and social media organizations that generate massive volumes of data everyday. Zadara provides compute (EC2-compatible), storage (block, file, object), and networking facilities as managed services located on-premises, in hybrid and multi-cloud, and at the edge.
…
Zilliz reckons the latest version of Zilliz Cloud, which scales to billions of vectors, aims to cure AI “hallucinations.” Zilliz Cloud is the managed service from Zilliz, the inventors of Milvus, the open source vector database used by more than 1,000 enterprises around the world, and is billed as an ideal data source for LLMs like ChatGPT. LLM hallucination can be minimized by supplying LLMs with external sources of domain-specific data, the vendor said. By using OpenAI plugins to connect to ChatGPT, it provides the basis for the emerging CVP (ChatGPT/Vector DB/Prompts-as-Code) technology stack.
Researchers at the UK’s Lancaster University say they have devised a new ULTRARAM non-volatile memory combining DRAM speed and flash endurance. A spinout company is being setup to try to commercialize it.
Professor Manus Hayne
Physics professor Manus Hayne led the team that invented ULTRARAM, a charge-based memory where the logic state is determined by the presence or absence of electrons in a floating gate. This technology depends upon quantum resonant tunneling in compound semiconductors. Each cell has a floating gate accessed through a triple-barrier resonant tunneling heterostructure.
The Lancaster Uni team says compound semiconductors are commonly used in photonic devices such as LEDs, laser diodes and infrared detectors, but not in digital electronics, which uses silicon semiconductors. But ULTRARAM can be built on a silicon substrate. A research paper says: “Sample growth using molecular beam epitaxy commences with deposition of an AlSb nucleation layer to seed the growth of a GaSb buffer layer, followed by the III–V memory epilayers.”
III-V refers to a compound semiconductor alloy, containing elements from groups III and V in the periodic table, such as Gallium Arsenide.
The paper’s abstract says: “Fabricated single-cell memories show clear 0/1 logic-state contrast after ≤10 ms duration program/erase pulses of ≈2.5 V, a remarkably fast switching speed for 10 and 20 µm devices. Furthermore, the combination of low voltage and small device capacitance per unit area results in a switching energy that is orders of magnitude lower than dynamic random access memory and flash, for a given cell size. Extended testing of devices reveals retention in excess of 1000 years and degradation-free endurance of over 107 program/erase cycles, surpassing very recent results for similar devices on GaAs substrates.”
The researchers contrast DRAM and NAND: “A fast, high-endurance memory seemingly necessitates a frail logic state that is easily lost, even requiring constant refreshing, for example … DRAM. In contrast, a robust, nonvolatile logic state ostensibly requires large amounts of energy to switch, which (gradually) damages the memory structure, reducing endurance; for example, flash.”
Resistive RAM, magnetoresitive RAM, and phase-change memory technologies are subject areas of R&D trying to bridge these two states. They say: “ULTRARAM breaks this paradigm via the exploitation of InAs (Indium arsenide) quantum wells (QWs) and AlSb (Aluminium antimonide) barriers to create a triple-barrier resonant-tunneling (TBRT) structure … By using the TBRT heterostructure as the barrier between FG and channel, rather than the usual monolithic material, a charge-based memory with extraordinary properties can be achieved.”
A quantum well is a region in a three-dimensional structure in which particles are forced to occupy a two-dimensional region in which they have discrete energy values. Quantum well devices operate very quickly, need little electricity, and are used in photonic devices. AISb is a semiconductor.
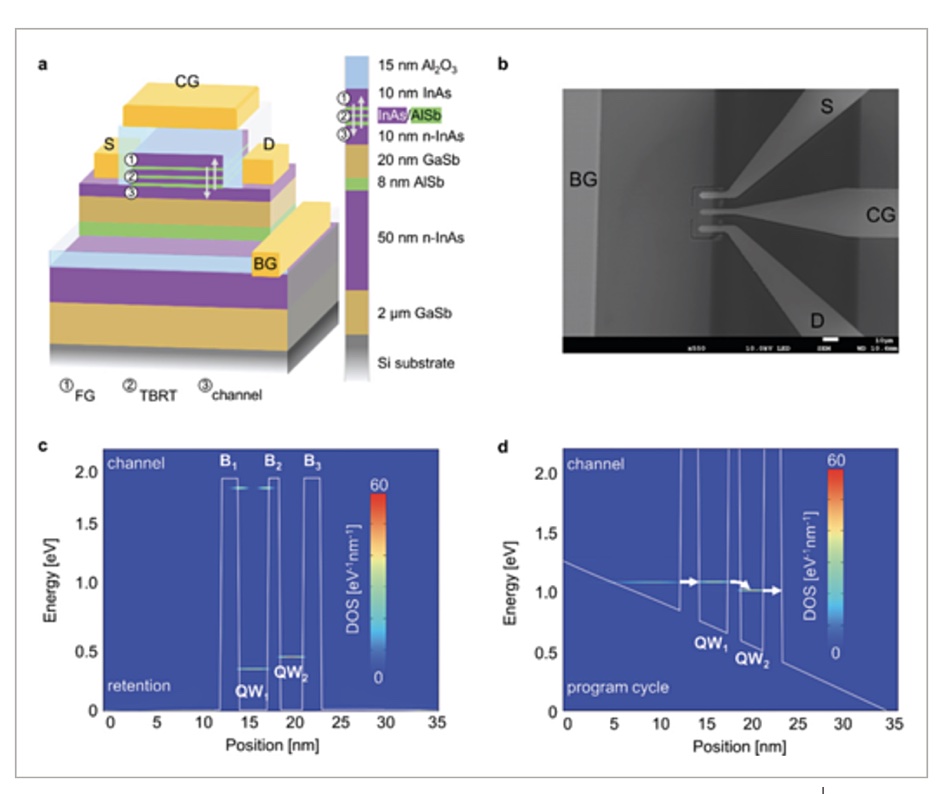
ULTRARAM device concept. a) Schematic cross-section of a device with corresponding material layers. The floating gate (FG), triple-barrier resonant-tunneling structure (TBRT), and readout channel are highlighted. Arrows indicate the direction of electron flow during program/erase operations. b) Scanning electron micrograph of a fabricated device of 10 µm gate length. c, d) Nonequilibrium Green’s functions (NEGF) calculations of density of states alongside conduction band diagrams for no applied bias (i.e., retention) and program-cycle bias respectively. B1, B2, and B3 are the AlSb barrier layers. QW1 and QW2 are the InAs quantum wells in the TBRT.
The abstract says: “The 2.1 eV conduction band offset of AlSb with respect to the InAs that forms the floating gate (FG) and channel, provides a barrier to the passage of electrons that is comparable to the SiO2 dielectric used in flash. However, inclusion of two InAs quantum wells (of different thicknesses) within the TBRT structure … allows it to become transparent to electrons when a low voltage (≈2.5 V) is applied, due to resonant tunneling.” SiO2 is Silicon Dioxide.
The charge state of the floating and, therefore, the logic state of the memory, is read non-destructively by measuring the current through the channel when a voltage is applied between the source (S) and drain (D) contacts.
Here’s the kicker: “Due to the low voltages required and the low capacitance per unit area of the device compared to DRAM, ultralow logic state switching energies of 10−17 J are predicted for 20 nm feature size ULTRARAM memories, which is two and three orders of magnitude lower than DRAM and flash respectively.”
They conclude: “Testing of the fabricated single cell memory devices shows strong potential, with devices demonstrating a clear memory window during ≤10 ms program/erase operations, which is remarkably fast for 10 and 20 µm gate-length devices. The ≈2.5 V program/erase voltage and low device-areal-capacitance results in a switching energy per unit area that is 100 and 1000 times lower than DRAM and flash respectively. Extrapolated retention times in excess of 1000 years and degradation-free endurance tests of over 107 program-erase cycles prove that these memories are nonvolatile and have high endurance.”
If this can be commercialized and fabricated at an attractive cost then we have a new storage-class memory. The technology has already been patented in the US and spinout discussions are taking place with potential investors.
HPE has added block and file storage services to its GreenLake subscription program, based on new Alletra Storage MP hardware, with the file service itself based on VAST Data software.
Alletra Storage MP is a multi-protocol system, meaning block or file, and joins the Alletra 6000 (Nimble-based) and 9000 (Primera-based) block storage arrays. HPE also provides the Alletra 5000 hybrid SSD+HDD arrays aimed at cost-efficient performance for a mix of primary workloads and secondary backup and recovery. Also in the family is the Alletra 4000 line, rebranded Apollo servers for performance-centric workloads. HPE’s announcement additionally includes backup and recovery and Zerto-based disaster recovery as GreenLake services.
Tom Black, HPE’s EVP and GM of storage, said: “The rapid increase in the volume and complexity of data has forced organizations to manage it all with a costly combination of siloed storage solutions. The new HPE GreenLake data services and expanded HPE Alletra innovations make it easier and more economical to manage multiple types of data, storage protocols, and workloads.”
The big event in this STaaS (Storage-as-a-Service) announcement is the addition of VAST Data-based file services to GreenLake and the use of Alletra MP hardware for both scale-out file and block services so that customers can converge file and block services on a single hardware platform. But the file storage and block storage are two separate software environments. It is not possible to have a unified file+block Alletra MP system.
Block storage was first added to GreenLake in June last year, as was backup and recovery, and also Zerto-based disaster recovery in HPE’s GreenLake for Private Cloud Enterprise announcement.
The existing GreenLake block storage services continue and we now have:
Before today, GreenLake file services were supplied through a partnership deal with Qumulo. Now we have the VAST Data-powered GreenLake file services as well, running on Alletra Storage MP systems, which are also used for the scale-out block services.
File personaAlletra MP
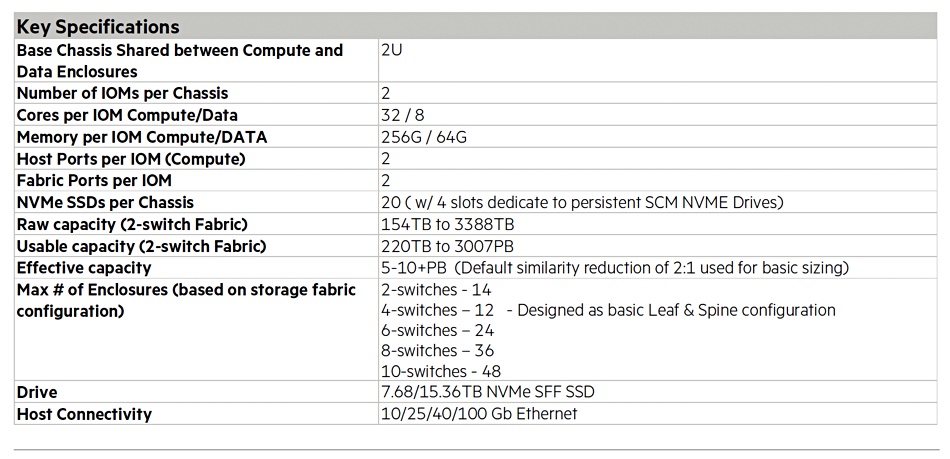
Alletra MP, formerly known as Alletra Storage MP, for file services uses VAST Data’s disaggregated shared everything (DASE) architecture and software, with one or more 2RU controller chassis (2 CPU nodes per chassis) talking across a 100GbitE NVMe fabric to one or more 2RU capacity (JBOF) nodes. These come with up to 20 x NVMe SSDs (7.58TB, 15.35TB) and four storage-class memory drives (800GB, 1.6TB encrypted), which we understand are Kioxia XL Flash drives. They provide fast metadata operations.
Controller nodes and capacity nodes can be scaled independently, providing separate performance and capacity scaling. Aruba switches interconnect the two classes of hardware.
HPE image showing Alletra Storage MP Compute, 2 x Aruba 8325 switches and Alletra Storage MP JBOF
Shilpi Srivastava, VP Storage and Data Services Marketing at HPE, told us: “HPE’s GreenLake for File Storage uses a version of VAST Data’s software that’s built for HPE GreenLake cloud platform. While we leverage VAST Data software as a key component of our solution, the product runs on HPE’s differentiated HPE Alletra Storage MP hardware and is managed through HPE GreenLake cloud platform.
“For HPE GreenLake for File Storage, the compute controller nodes do not store metadata. The metadata is stored in SCM layer on JBOFs. That is possible with the Disaggregated Shared Everything architecture of the software that VAST provides for HPE GreenLake for File Storage.”
This software provides inline similarity data reduction (deduplication and compression) even for previously compacted data.
Alletra Storage MP file mode spec table
HPE suggests GreenLake for File Storage can be applied to cloud-native workloads (Kubernetes, OpenShift, Anthos), BI and ML frameworks (TensorFlow, PyTorch, H20.ai and Caffe2) and petabyte-scale data lakes (Spark, Spark streaming, Hadoop, and Python).
Block persona Alletra MP
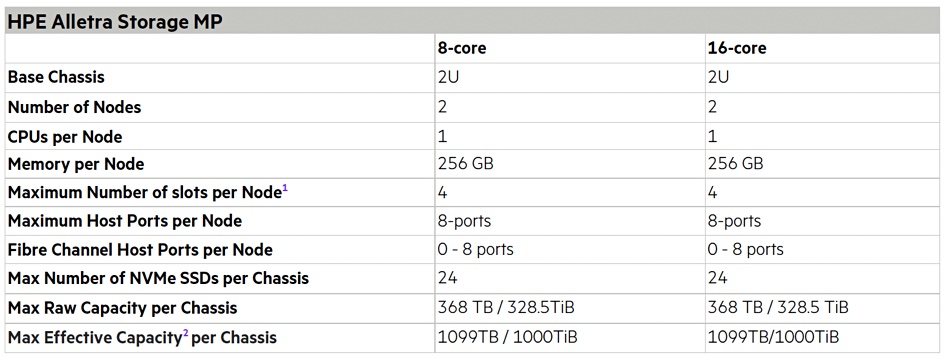
Block persona Alletra MP uses the same basic 2RU storage chassis, which hosts two 8 or 16-core CPU controllers [nodes] and 8, 12 or 24 small form factor TLC-encrypted NVMe drives (1.92TB, 3.84TB, 7.68TB, or 15.36TB). It features a massively parallel, multi-node, and all-active platform design with a minimum of two nodes. There is a new block mode OS.
Front and rear views of block mode Alletra MP chassis with/without bezel and showing 24 x 3.84TB NVMe SSDs in three groups of eight
Srivastava said: “For the new block storage offering, the software OS is an enhanced version of the OS from Alletra 9000 (Primera) that blends the data reduction tech previously in the Nimble Storage OS. The combination of the two software capabilities backed by Alletra Storage MP enables GreenLake for Block Storage to offer the availability, performance and scalability of mission-critical storage with mid-range economics.”
Block mode Alletra Storage MP feature table. Effective capacity assumes 4:1 data compaction ratio (thin provisioning, deduplication, compression, and copy technologies) in a RAID 6 (10+2) configuration. Max raw capacity uses 15.36TB drives
HPE says GreenLake for Block Storage is the industry’s first disaggregated, scale-out block storage with a 100 percent data availability guarantee. The company claims it offers better price/performance than GreenLake mission-critical block storage but with the same always-on, always-fast architecture.
HPE’s Patrick Osbourne, SVP and GM for Cloud and Data Infrastructure Platforms, was asked about a GreenLake for Object Storage service in a briefing. He said this “is an opportunity for tomorrow.” VAST data supports S3.
Capex and opex options
Srivastava tells us: “With this launch, HPE is for the first time adding the flexibility of capex purchasing, in addition to the opex buying options to HPE GreenLake… To get the new HPE Alletra Storage MP, customers must first purchase the new HPE GreenLake for Block Storage or HPE GreenLake for File Storage. With that, they get HPE Alletra Storage MP today that they own along with HPE GreenLake for Block Storage or HPE GreenLake for File Storage subscription services. HPE GreenLake for Block Storage based on HPE Alletra Storage MP and HPE GreenLake for File Storage will be available via opex options in the near future.”
She emphasized: “It’s important to recognize that HPE GreenLake is first and foremost a cloud platform that offers a cloud operational experience for customers to orchestrate and manage all of their data services.”
Competition
The competition for the Alletra MP is twofold. On the one hand there are file storage systems and on the other block storage systems. HPE has not released any performance data for Alletra MP in either file or block mode, contenting itself so far by saying it has low latency and high performance. Describing Alletra MP as suitable for mission-critical storage with mid-range economicssuggests that it will need careful positioning against the Alletra 4000, 6000 and 9000 block storage systems if it is not going to cannibalize their sales. Having it be a scale-out block storage system will help with differentiation but performance and price/performance stats will be needed as well.
A quick list of block mode competition will include Dell (PowerStore, PowerMax), Hitachi Vantara, IBM (FlashSystem), NetApp (ONTAP), and Pure Storage, along with StorONE. File mode competition will involve Dell (PowerScale), IBM (Spectrum Scale), NetApp, and Qumulo. It may also include Weka.
Pure Storage’s Prakash Darji, GM of the Digital Experience business unit, said: “The market for scale-out block wasn’t growing or all that large,” and Pure hasn’t optimized its products for that.
He observed: “If you’re dependent on third party IP to go ahead and get changes to deliver your service, I don’t know any SaaS company on the planet that’s been successful with that strategy.” Pure introduced a unified file and block FlashArray after it bought Compuverde in 2019. It had file access protocols added with the v6.0 Purity operating system release in June 2020 after having initial NFS and SMB support arrive with v5.0 Purity in 2017. It can say it has a single block+file silo, like NetApp with ONTAP and Dell with PowerStore, but unlike HPE.
Effect on VAST
This endorsement of VAST Data by HPE is a huge win. In effect HPE is saying VAST Data is a major enterprise-class supplier of file services. HPE itself suddenly becomes a more serious filesystem storage player with VAST a first-party supplier to GreenLake, unlike Qumulo. This catapults VAST from being a new startup, albeit a fast-growing one, into a supplier in the same enterprise class as HPE, and therefore worthy to compete for enterprise, mission-critical, file-based workloads against Dell, IBM, NetApp, Pure Storage, and Qumulo.
We think VAST could see a significant upsurge in its revenue with this HPE GreenLake deal.
Bootnote
The phrase “File persona” is no relation to the File Persona offering on HPE’s 3PAR arrays.
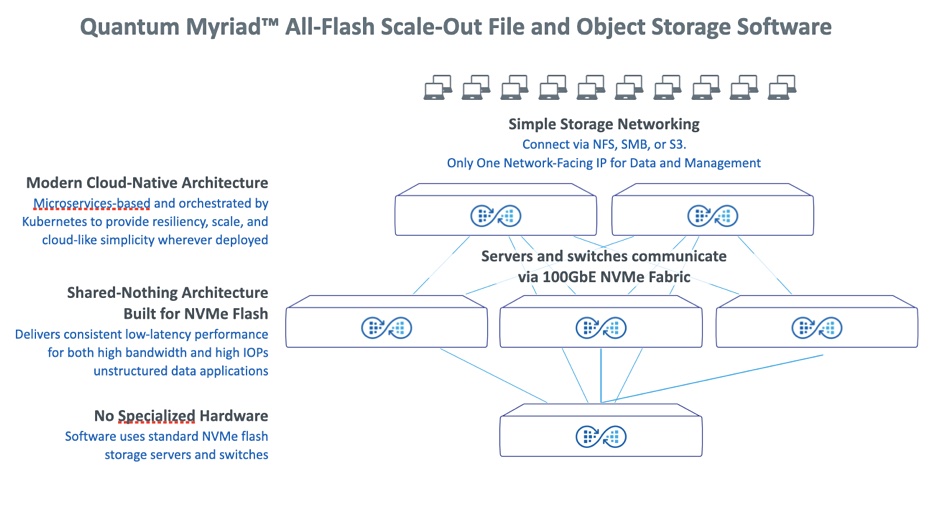
Quantum has written a unified and scaleout file and object storage software stack called Myriad, designing it for flash drives and using Kubernetes-orchestrated microservices to lower latency and increase parallelism.
The data protector and file and object workflow provider says Myriad is hardware-agnostic and built to handle trillions of files and objects as enterprises massively increase their unstructured data workloads over the next decades. Quantum joins Pure Storage, StorONE and VAST Data in having developed flash-focused storage software with no legacy HDD-based underpinnings.
Brian Pawlowski
Brian “Beepy” Pawlowski, Quantum’s chief development officer, said : “To keep pace with data growth, the industry has ‘thrown hardware’ at the problem… We took a totally different approach with Myriad, and the result is the architecture I’ve wanted to build for 20 years. Myriad is incredibly simple, incredibly adaptable storage software for an unpredictable future.”
Myriad is suited for emerging workloads that require more performance and more scale than before, we’re told. A Quantum technical paper says that “for decades the bottleneck in every system design has been the HDD-based storage. Software didn’t have to be highly optimized, it just had to run faster than the [disk] storage. NVMe and RDMA changed that. To fully take advantage of NVMe flash requires software designed for parallelism and low latency end-to-end. Simply bolting some NVMe flash into an architecture designed for spinning disks is a waste of time.”
Software
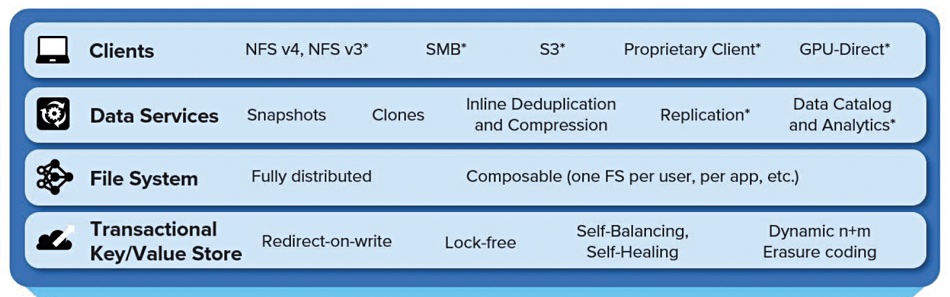
The Myriad has four software stack layers:
Myriad software layers. Items with an asterisk are roadmap items
Using NFS v4, incoming clients access a data services layer providing file and object access, snapshots, clones, always-on deduplication and compression and, in the future, replication, a data catalog and analytics. These services use a POSIX-compliant filesystem layer which is fully distributed and can be composed (instantiated) per user, and per application.
Linux’s kernel VFS (Virtual File System) layer enables new filesystems to be “plugged in” to the operating system in a standard way and enables multiple filesystems to co-exist in a unified namespace. Applications talk to VFS, which issues open, read and write commands to the appropriate filesystem.
Underlying this is a key/value (KV) store using redirect-on-write technology, not overwriting, which enables the snapshot and clone features. The KV store is lock-free, saving computational overhead and accessing client process time, as well as being self-balancing and self-healing. Files are stored as whole objects or, if large, split into smaller separate objects. This KV store uses dynamic erasure coding (EC) to protect against drive failures.
Metadata is stored in the KV store as well. Generally metadata objects will not be deduplicated or compressed but users’ files will be reduced in size through dedupe and compression. The KV store provides transaction support needed for the POSIX-compliant filesystem.
The access protocols will be expanded to NFS v3, SMB, S3, GPU-Direct and a proprietary Quantum client in the future.
These four software layers run on the Myriad data store, which itself is built from three types of intelligent nodes interconnected by a fabric.
Hardware
The Myriad architecture has four components, as shown in the diagram above and starting from the top:
Load Balancers to connect the Myriad data store to a customer’s network. These balance traffic inbound to the cluster, as well as traffic within the cluster.
100GbitE network fabric to interconnect the Myriad HW/SW component systems to each other and provide client access.
NVMe storage nodes with shared-nothing architecture; processors and NVMe drives. These nodes run Myriad software and services. Every storage node has access to all NVMe drives across the system essentially as if they were local, thanks to RDMA. Incoming writes are load balanced across the storage nodes. Every node can write to all the NVMe drives, distributing EC chunks across the cluster for high resiliency.
Deployment node which looks after cluster deployment and maintenance, including initial installation, capacity expansion, and software upgrades. Think of it as the admin box.
The servers and switches involved used COTS (Commercial Off The Shelf) hardware, x86-based in the case of the servers.
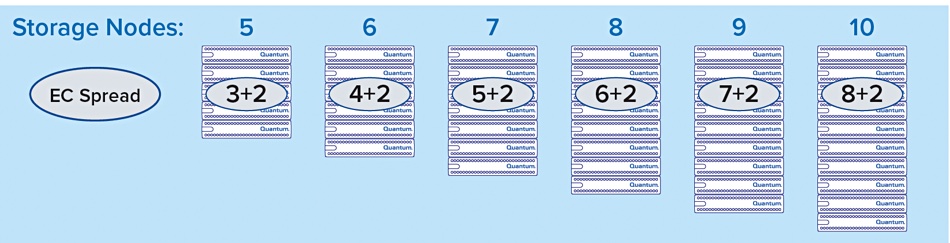
Drive and node failure
The dynamic erasure coding provides protection against two drives or node failures; a +2 safety level. The “EC Spread” equals the number of drives plus 2. Data is written into zones, parts of a flash drive, and zones across multiple drives and nodes are grouped into zone sets. In a five-node system there will be a 3+2 EC spread scheme while in, say, a nine-node system there will be a 7+2 EC spread.
Myriad +2 EC safety level scheme
As the number of nodes increase, say, from 9 to 11, new zone sets are written using the new 9+2 scheme. All incoming data is stored in the new 9+2 zone sets. In the background, and as a low-priority task, all the existing 7+2 zone sets are converted to 9+2. The reverse happens if the node count decreases. If a drive or node fails then its data contents are rebuilt using the surviving zone sets.
In the future the EC safety level will be selectable.
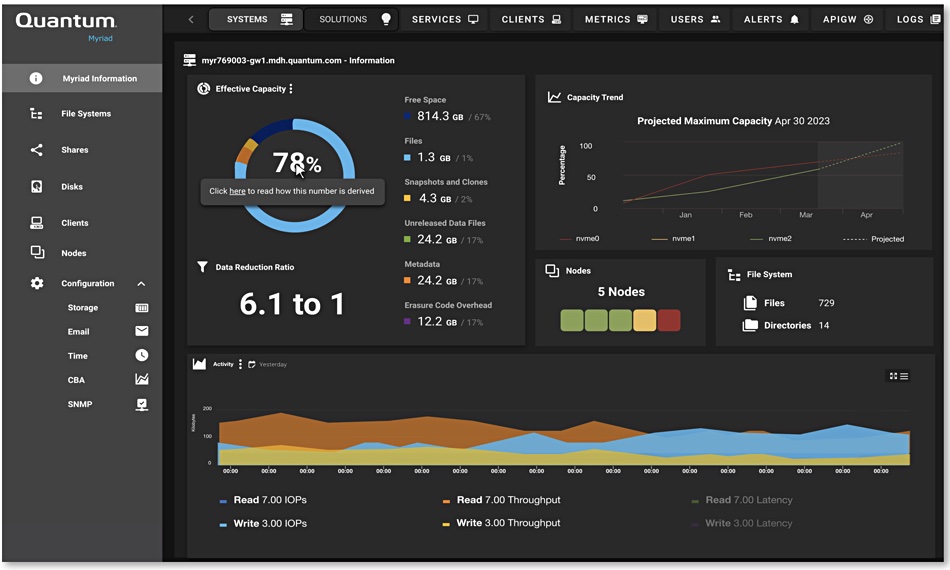
Myriad management
Myriad is managed through a GUI and a cloud-delivered portal featuring AIOps capabilities. A Myriad cluster of any size can be accessed and managed via a single IP address.
Myriad GUI
The Myriad software has several management capabilities:
Self-healing, self-balancing software for in-service upgrades that automatically rebuilds and repairs data in the background while rebalancing data as the storage cluster expands, shrinks and changes.
Automated detection, deployment and configuration of storage nodes within a cluster so it can be scaled, modified or shrunk non-disruptively, without user intervention.
Automated networking management of the internal RDMA fabric so managing a Myriad cluster requires no networking expertise.
Inline data deduplication and compression to reduce the cost of flash storage and improve data efficiencies.
Data security and ransomware recovery with built-in snapshots, clones, snapshot recovery tools and “rollback” capabilities.
Inline metadata tagging to accelerate AI/ML data processing, provide real-time data analytics, enable creation of data lakes based on tags, and automate data pipelines and workflows.
Real-Time monitoring of system health, performance, capacity trending, and more from a secure online portal by connecting to Quantum cloud-based AI Operations software
Traditional monitoring via SNMP is available, as well as sFlow. API support is coming and this will enable custom automation.
Myriad workload positioning
Quantum positions Myriad for use with workloads such as AI and machine learning, data lakes, VFX and animation, and other high-bandwidth and high-IOPS applications. These applications are driving growth in the market for scale-out file and object storage, which is expected to grow to be a $15.7 billion market by 2025, according to IDC.
We understand that, over time, existing Quantum services, such as StorNext, will be ported to run on Myriad.
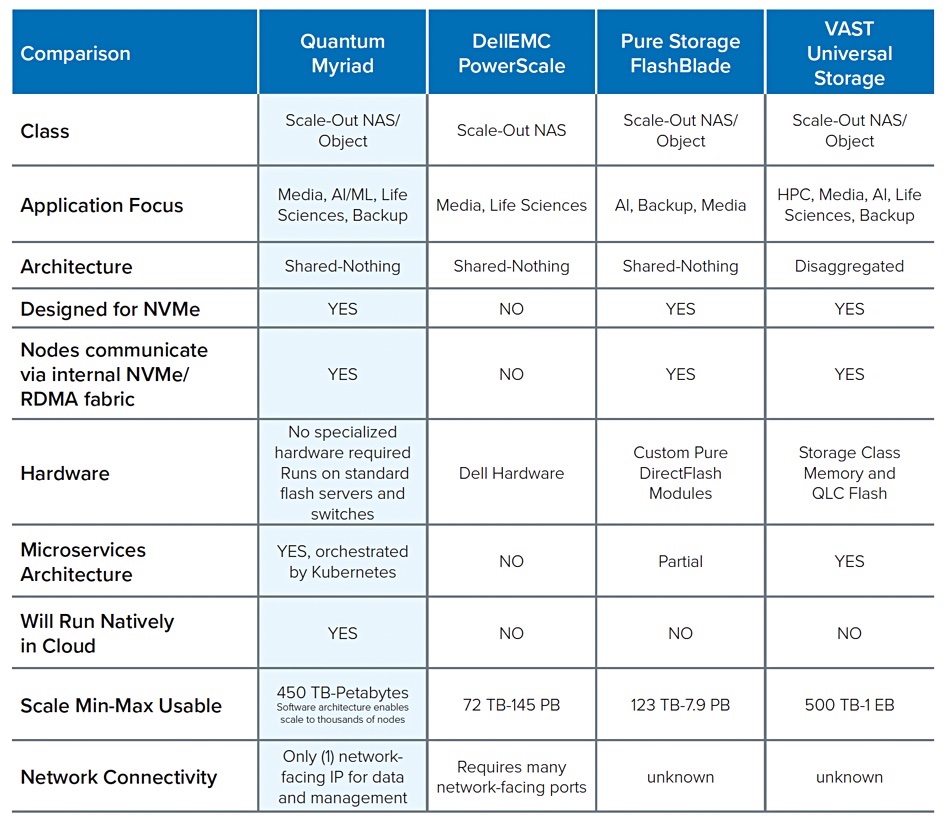
We have not seen performance numbers for Myriad or pricing. Our understanding is that Myriad will be generally competitive with all-flash systems from Dell (PowerStore), Hitachi Vantara, HPE, NetApp, Pure Storage, StorOne and VAST Data. A Quantum competitive positioning table confirms this general idea:
As the Myriad software runs on commodity hardware and is containerized, it can, in theory, run on public clouds and so give Quantum a hybrid on-prem/public cloud capability.
Myriad is available now for early access customers and is planned for general availability in the third quarter of this year. Get an architectural white paper here, a competitive positioning paper here, and a product datasheet here.
Bootnote
Quantum appointed Brian “Beepy” Pawlowski as chief development officer in December 2020. He came from a near three-year stint as CTO at composable systems startup DriveScale, bought by Twitter. Before that he spent three years at Pure Storage, initially as a VP and chief architect and then as an advisor. Before that he ran the FlashRay all-flash array project at NetApp. FlashRay was canned in favor of the SolidFire acquisition. Now NetApp has pulled back from SolidFire and Beepy’s Myriad will compete with NetApp’s ONTAP all-flash arrays. What goes around comes around.
Beepy joined NetApp as employee number 18 in a CTO role and was at Sun before NetApp.