


With its Alletra Storage MP tech HPE is standardizing its storage array hardware on scale-out storage nodes; Proliant server chassis with all-flash NVMe-fabric connected local storage, and Aruba switches. Dimitris Krekoukias, writing as Recovery Monkey, has written two informative blogs about what it’s doing.
He writes in the first blog: “At a basic level, there are just two items: a chassis and (optionally) dedicated cluster switches. The chassis can become just compute, or compute with storage in it.” The chassis can also be presented as a JBOF (just a box of flash) supporting NVMe SSDs, storage-class memory, and NVDIMMs. Krekoukias blogs: ”It has storage media and two ‘controllers’, each with an OS, RAM and CPU. It’s just that the expansion slots, CPUs and memory used are minimal, just enough to satisfy JBOF duties.”
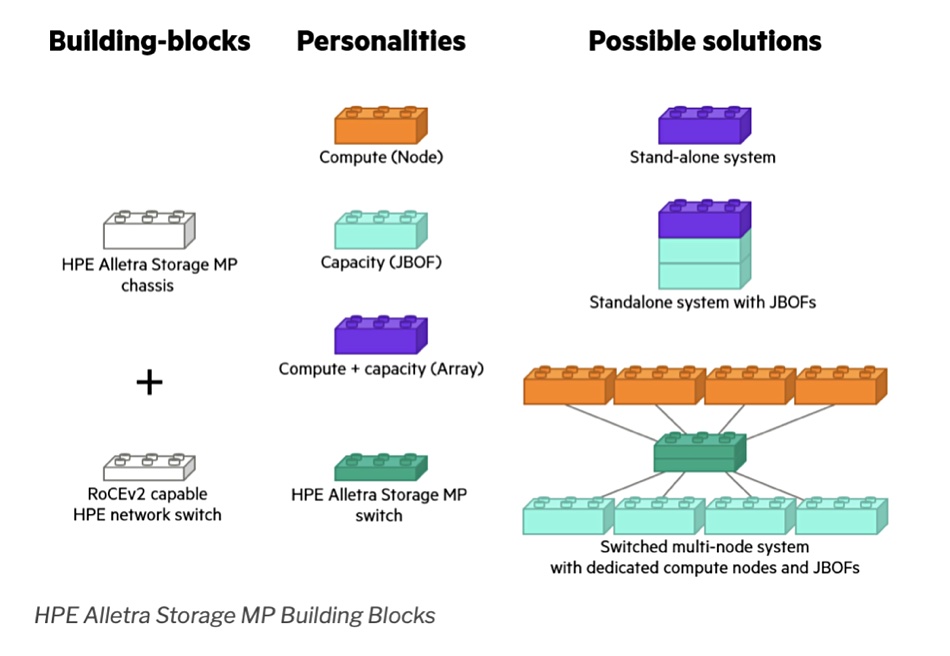
“Increase the JBOF compute power and expansion slots, and now you can use that same architecture as a compact storage array with two controllers and storage inside the same MP chassis. For bigger capacity and performance needs, a disaggregated architecture can be used, connecting diskless compute to JBOFs in large clusters.”
Uniform hardware quality was a design criterion. Krekoukias blogs: “The quality of the hardware had to be uniform – the same high-end hardware quality should be used for both the ultra-fast versions of Tier-0 platforms with 100 percent uptime guarantees as well as their entry versions and everything in between.”
He says: “Things like a plethora of PCIe lanes, huge memory throughput and high core density are important for performance: we standardized on AMD CPUs for the new hardware.”
Why use Proliant Servers as the controllers instead of traditional storage controller hardware? Krekoukias says: “HPE sells hundreds of thousands of servers each quarter after all. Storage controllers (even if you add up all storage vendors together) are a tiny fraction of that number. Taking advantage of server economies of scale was a no-brainer.” This brings component pricing and supply chain reliability advantages.
This hardware commonality is quite different from HPE’s other storage products, including the Alletra 9000, 6000, 5000 and 4000, and from other suppliers, such as Pure Storage and Dell. It is implied by Krekoukias’ blog that HPE’s common hardware base approach will be applied to other storage products. In our view that could mean that next generation Alletra 9000, 6000, 5000 and 4000 hardware could transition to Alletra Storage MP base hardware components.
Put another way, Primera, Alletra 9000, Nimble and Alletra 6000 customers can potentially look forward to a migration/upgrade to a common Alletra MP hardware base. We are also confident that object storage access support will be added to Alletra, but who’s object storage? VAST Data, the source of Alletra MP file storage software, supports object storage and so is an obvious candidate. But HPE has existing sales partnerships with object storage suppliers Cloudian and Scality, and could use software technology from one of them.
Perhaps we’ll hear more at HPE’s Discover event in Las Vegas, June 20–22.
Block access personality
In a second blog, looking at Alletra MP block access storage, Krekoukias revealed more information about HPE’s new block storage OS. We already know it has a Primera base with added disaggregated compute and storage box support plus Nimble data reduction but Krekoukias tells us more about this, removing scalability limitations and improved efficiency.
It has Active Peer Persistence, meaning active-active access to sync replicated volumes. With this “migrations from older systems will be easy and non-disruptive (we are initially aiming this system at existing smaller 3PAR customers.”
“Redirect-on write (ROW) snaps were carried over from Nimble. As was always doing full stripe writes and extremely advanced checksums that protect against lost writes, misplaced writes and misdirected reads.”
The software allows single node addition, dissimilar node addition, and simultaneous multiple node loss in a cluster. There is no volatile write cache as a write-through scheme is used; “where dirty write data and associated metadata is hardened to stable storage before an I/O complete is sent to the host. The architecture allows for that storage to be a special part of the drives, or different media altogether. An extra copy is kept in the RAM of the controllers.”
Krekoukias says: “This way of protecting the writes also allows more predictable performance on a node failure, simpler and easier recovery, completely stateless nodes, the ability to recover from a multi-node failure, plus easy access to the same data by way more than 2 nodes…”
“Eventually, the writes are coalesced, deduped and compressed, and laid down in always full stripes (no overwrites means no read-modify-write RAID operations) to parity-protected stable storage.
The redirect-on write snapshot method avoids a write performance penalty which persists in write-intensive environments. The ROW method treats snapshots as a list of pointers. When blocks in a volume are going to be overwritten the snapshot system is updated with the pointers to the about-to-be-overwritten blocks and then the new data is written to a fresh area of the drive.
The existing old data blocks are added to the snapshot system without having to be read and copied in separate IO operations. There is only one I/O operation; a write, plus the snapshot pointer updating. Consequently ROW snapshots are faster than the alternative Copy-on-Write (COW) snapshots.
At first, Alletra MP block storage will use compute nodes with drives inside the chassis. A near-future release will introduce “the larger, switched, fully disaggregated, shared-everything architecture for much larger and more flexible implementations.” Scale-out block in other words.
We’ll hear more details on Alletra MP file storage before the end of the month.





