HPE has added block and file storage services to its GreenLake subscription program, based on new Alletra Storage MP hardware, with the file service itself based on VAST Data software.
Alletra Storage MP is a multi-protocol system, meaning block or file, and joins the Alletra 6000 (Nimble-based) and 9000 (Primera-based) block storage arrays. HPE also provides the Alletra 5000 hybrid SSD+HDD arrays aimed at cost-efficient performance for a mix of primary workloads and secondary backup and recovery. Also in the family is the Alletra 4000 line, rebranded Apollo servers for performance-centric workloads. HPE’s announcement additionally includes backup and recovery and Zerto-based disaster recovery as GreenLake services.
Tom Black, HPE’s EVP and GM of storage, said: “The rapid increase in the volume and complexity of data has forced organizations to manage it all with a costly combination of siloed storage solutions. The new HPE GreenLake data services and expanded HPE Alletra innovations make it easier and more economical to manage multiple types of data, storage protocols, and workloads.”
The big event in this STaaS (Storage-as-a-Service) announcement is the addition of VAST Data-based file services to GreenLake and the use of Alletra MP hardware for both scale-out file and block services so that customers can converge file and block services on a single hardware platform. But the file storage and block storage are two separate software environments. It is not possible to have a unified file+block Alletra MP system.
Block storage was first added to GreenLake in June last year, as was backup and recovery, and also Zerto-based disaster recovery in HPE’s GreenLake for Private Cloud Enterprise announcement.
The existing GreenLake block storage services continue and we now have:
- GreenLake mission-critical block storage – Alletra 9000
- GreenLake business-critical block storage – Alletra 6000
- GreenLake general purpose block storage – (Alletra 5000)
- GreenLake scale-out block storage – Alletra MP – mission-critical storage with mid-range economics
Before today, GreenLake file services were supplied through a partnership deal with Qumulo. Now we have the VAST Data-powered GreenLake file services as well, running on Alletra Storage MP systems, which are also used for the scale-out block services.
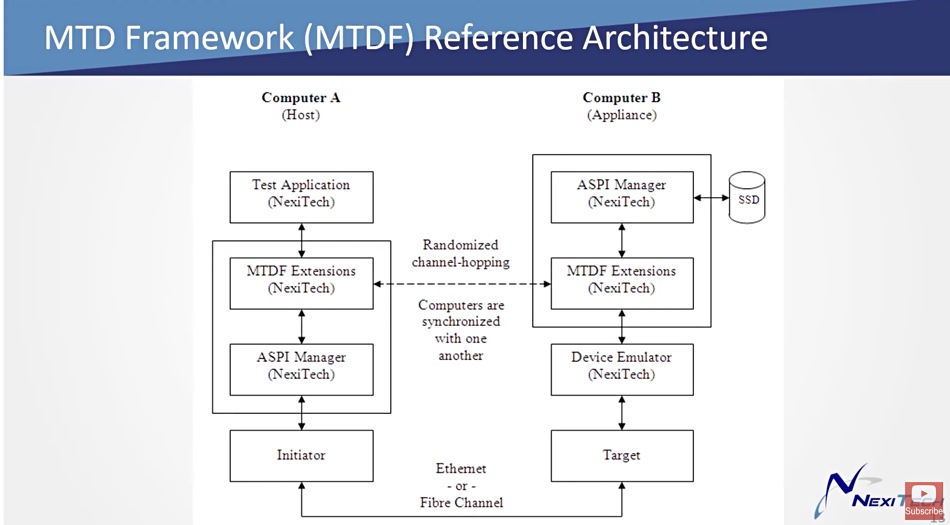
File persona Alletra MP
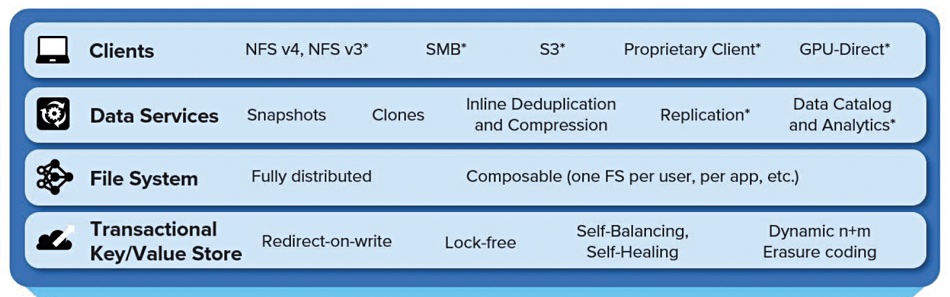
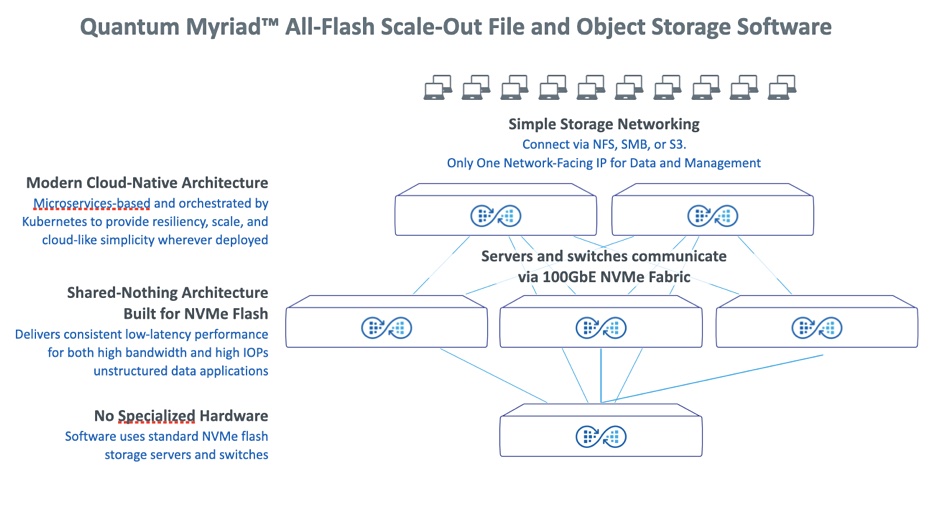
Alletra MP, formerly known as Alletra Storage MP, for file services uses VAST Data’s disaggregated shared everything (DASE) architecture and software, with one or more 2RU controller chassis (2 CPU nodes per chassis) talking across a 100GbitE NVMe fabric to one or more 2RU capacity (JBOF) nodes. These come with up to 20 x NVMe SSDs (7.58TB, 15.35TB) and four storage-class memory drives (800GB, 1.6TB encrypted), which we understand are Kioxia XL Flash drives. They provide fast metadata operations.
Controller nodes and capacity nodes can be scaled independently, providing separate performance and capacity scaling. Aruba switches interconnect the two classes of hardware.

Shilpi Srivastava, VP Storage and Data Services Marketing at HPE, told us: “HPE’s GreenLake for File Storage uses a version of VAST Data’s software that’s built for HPE GreenLake cloud platform. While we leverage VAST Data software as a key component of our solution, the product runs on HPE’s differentiated HPE Alletra Storage MP hardware and is managed through HPE GreenLake cloud platform.
“For HPE GreenLake for File Storage, the compute controller nodes do not store metadata. The metadata is stored in SCM layer on JBOFs. That is possible with the Disaggregated Shared Everything architecture of the software that VAST provides for HPE GreenLake for File Storage.”
This software provides inline similarity data reduction (deduplication and compression) even for previously compacted data.
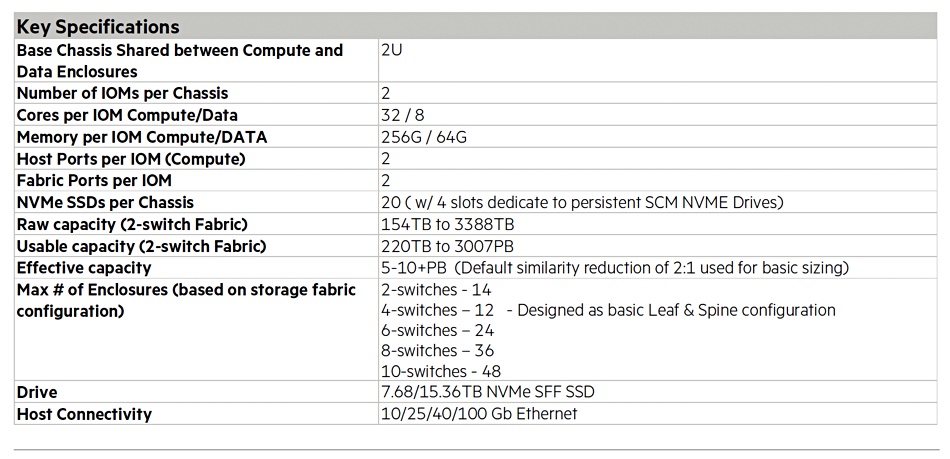
HPE suggests GreenLake for File Storage can be applied to cloud-native workloads (Kubernetes, OpenShift, Anthos), BI and ML frameworks (TensorFlow, PyTorch, H20.ai and Caffe2) and petabyte-scale data lakes (Spark, Spark streaming, Hadoop, and Python).
Block persona Alletra MP
Block persona Alletra MP uses the same basic 2RU storage chassis, which hosts two 8 or 16-core CPU controllers [nodes] and 8, 12 or 24 small form factor TLC-encrypted NVMe drives (1.92TB, 3.84TB, 7.68TB, or 15.36TB). It features a massively parallel, multi-node, and all-active platform design with a minimum of two nodes. There is a new block mode OS.

Srivastava said: “For the new block storage offering, the software OS is an enhanced version of the OS from Alletra 9000 (Primera) that blends the data reduction tech previously in the Nimble Storage OS. The combination of the two software capabilities backed by Alletra Storage MP enables GreenLake for Block Storage to offer the availability, performance and scalability of mission-critical storage with mid-range economics.”
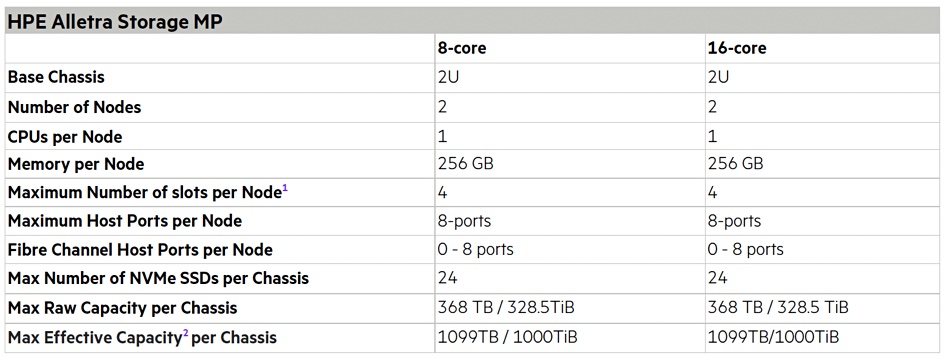
HPE says GreenLake for Block Storage is the industry’s first disaggregated, scale-out block storage with a 100 percent data availability guarantee. The company claims it offers better price/performance than GreenLake mission-critical block storage but with the same always-on, always-fast architecture.
HPE’s Patrick Osbourne, SVP and GM for Cloud and Data Infrastructure Platforms, was asked about a GreenLake for Object Storage service in a briefing. He said this “is an opportunity for tomorrow.” VAST data supports S3.
Capex and opex options
Srivastava tells us: “With this launch, HPE is for the first time adding the flexibility of capex purchasing, in addition to the opex buying options to HPE GreenLake… To get the new HPE Alletra Storage MP, customers must first purchase the new HPE GreenLake for Block Storage or HPE GreenLake for File Storage. With that, they get HPE Alletra Storage MP today that they own along with HPE GreenLake for Block Storage or HPE GreenLake for File Storage subscription services. HPE GreenLake for Block Storage based on HPE Alletra Storage MP and HPE GreenLake for File Storage will be available via opex options in the near future.”
She emphasized: “It’s important to recognize that HPE GreenLake is first and foremost a cloud platform that offers a cloud operational experience for customers to orchestrate and manage all of their data services.”
Competition
The competition for the Alletra MP is twofold. On the one hand there are file storage systems and on the other block storage systems. HPE has not released any performance data for Alletra MP in either file or block mode, contenting itself so far by saying it has low latency and high performance. Describing Alletra MP as suitable for mission-critical storage with mid-range economics suggests that it will need careful positioning against the Alletra 4000, 6000 and 9000 block storage systems if it is not going to cannibalize their sales. Having it be a scale-out block storage system will help with differentiation but performance and price/performance stats will be needed as well.
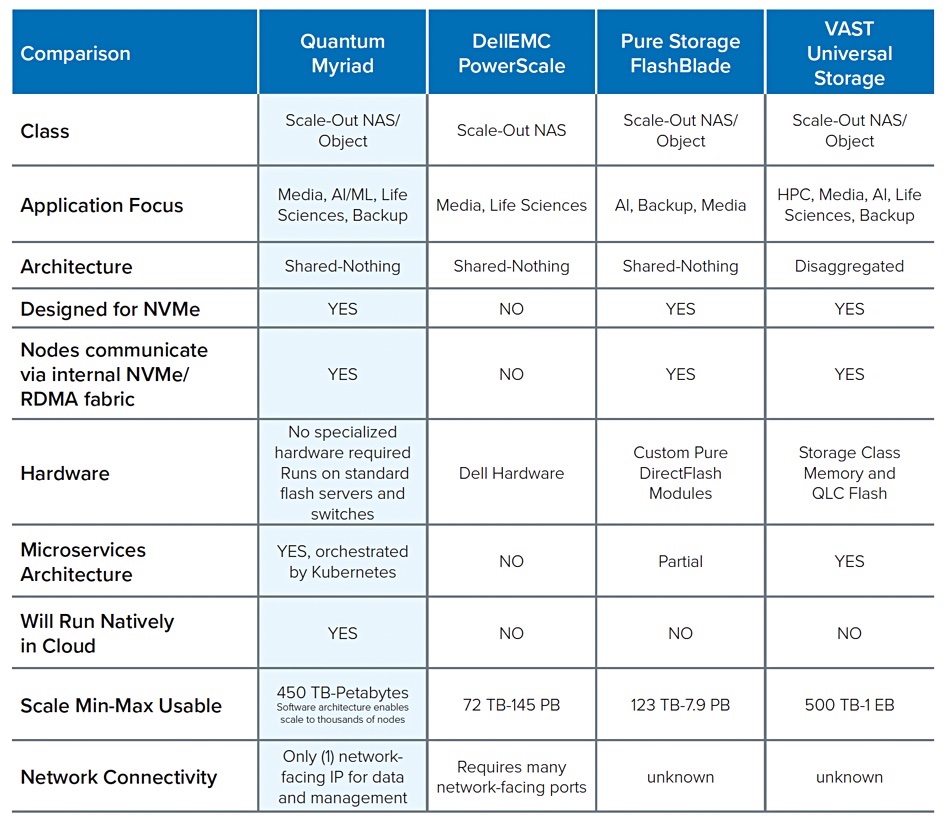
A quick list of block mode competition will include Dell (PowerStore, PowerMax), Hitachi Vantara, IBM (FlashSystem), NetApp (ONTAP), and Pure Storage, along with StorONE. File mode competition will involve Dell (PowerScale), IBM (Spectrum Scale), NetApp, and Qumulo. It may also include Weka.
Pure Storage’s Prakash Darji, GM of the Digital Experience business unit, said: “The market for scale-out block wasn’t growing or all that large,” and Pure hasn’t optimized its products for that.
He observed: “If you’re dependent on third party IP to go ahead and get changes to deliver your service, I don’t know any SaaS company on the planet that’s been successful with that strategy.” Pure introduced a unified file and block FlashArray after it bought Compuverde in 2019. It had file access protocols added with the v6.0 Purity operating system release in June 2020 after having initial NFS and SMB support arrive with v5.0 Purity in 2017. It can say it has a single block+file silo, like NetApp with ONTAP and Dell with PowerStore, but unlike HPE.
Effect on VAST
This endorsement of VAST Data by HPE is a huge win. In effect HPE is saying VAST Data is a major enterprise-class supplier of file services. HPE itself suddenly becomes a more serious filesystem storage player with VAST a first-party supplier to GreenLake, unlike Qumulo. This catapults VAST from being a new startup, albeit a fast-growing one, into a supplier in the same enterprise class as HPE, and therefore worthy to compete for enterprise, mission-critical, file-based workloads against Dell, IBM, NetApp, Pure Storage, and Qumulo.
We think VAST could see a significant upsurge in its revenue with this HPE GreenLake deal.
Bootnote
The phrase “File persona” is no relation to the File Persona offering on HPE’s 3PAR arrays.