


Single QLC flash tier storage upstart VAST Data is making a song and dance about its biggest software release ever, saying it will aid VAST’s larger data platform agenda.
A VAST blog by CMO Jeff Denworth introduces and reviews combined v4.6 and v4.7 VAST software releases and promises more instalments over the next five weeks. The starting point is the development of a data catalog.
Denworth says: “The IT industry has been accustomed to the idea that structured, unstructured and semi-structured data stores should all be distinct only because no single system has been designed to achieve true data synthesis, until now.”
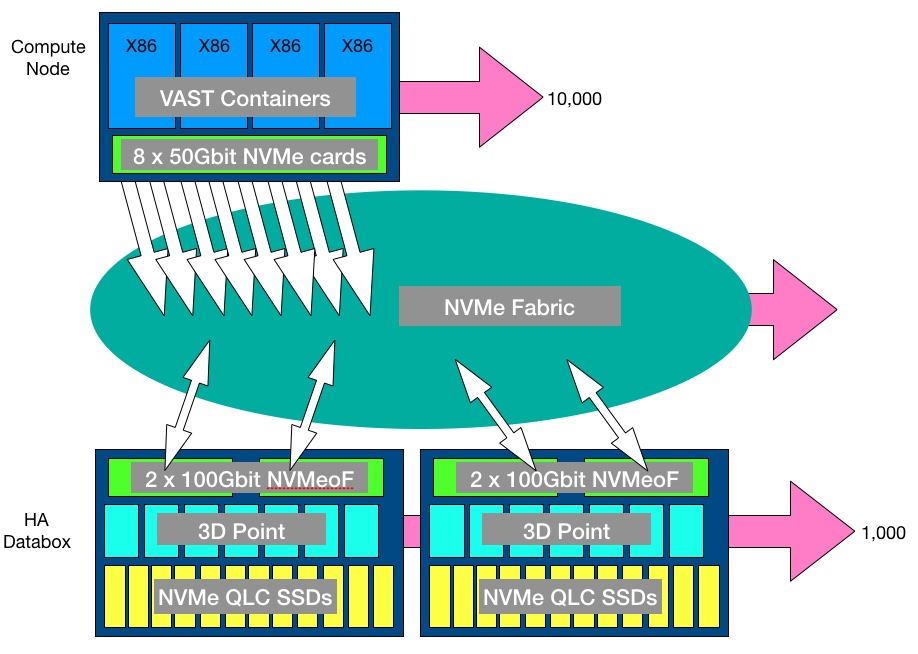
VAST stores its data in its scale-out and global namespace Element Store, a single tier of QLC SSDs accessed across an NVMe fabric by stateless controllers which can see all the drives and refer to metadata held in Optane storage class memory, but now SLC-class fast SSD equivalents.
The new releases add this data catalog plus virtual tiering, key management, remote cluster snapshots, capacity usage predictions, zero-trust features and Kubernetes storage classes.
VAST Catalog
It’s now adding a catalog of the data it holds, detailing “each and every file and object written into an extensible tabular format.” This “enables data users to … query upon massive datasets at any level of scale,” and “is never out of sync with your datastore.” There are aspects of Hammerspace’s Global Data Environment here. How much the two approaches overlap will become clearer as VAST’s software details are released.
We can envisage a VAST cluster as a datalake or lakehouse, with the queryable catalog a means of finding and selecting data according to some criteria. But then what can we do with the selection?
We can make a step forward and imagine running an analysis process on it. Were VAST to set up integrations with providers of analytics software, machine learning training or general AI software, then this catalog capability becomes a data extract process. It could also transform the data but there would be no need to load it into anything, as the processing routine could then use it directly on the VAST storage system – ETL without the L.
Denworth says the catalog will be used for capacity management and chargeback and provide a faster way for backup and archiving processes to run. He also claims that, with the catalog, “Applications can replace POSIX functions with SQL statements to see rapid accelerations for mundane POSIX operations… why find when you can select 1,000 times faster?”
The Posix find function looks through the hierarchically organised nodes in a directory tree to locate files. A SQL select statement retrieves records (rows) from tables in a SQL database
Tiering and clustering
The virtual tiering concept sets up quality of service (bandwidth and IOPS minima and maxima) plans per user or per share, export or bucket. Thus there could be low, medium and high QoS plans, with each representing a tier of service applied to the underlying single tier element store.
The expanded clustering features start with a remote snapshot idea: “VAST clusters now also support the ability to share and extend snapshots to multiple remote clusters. Each remote site can mount another site’s snapshots and even make clones of this data to turn a snapshot into a read/write View. This capability lays the foundation for other work we will unveil, relating to building a global namespace from edge to cloud.”
If “cloud” means public cloud, then that means the VAST OS will be ported there and customers will operate their VAST storage and associated applications in a VAST data universe that extends from globally-distributed on-premises edge sites through data centres to the public cloud.
Comment
Our understanding is that VAST Data’s capabilities and growth progress are being paid close attention by established and mainstream enterprise storage providers, meaning Dell, Hitachi Vantara, HPE, Huawei, IBM, NetApp, and Pure Storage, ambitious newcomers such as Qumulo and WekaIO, and cloud file services providers (CTERA, Egnyte, Nasuni, Panzura, and Lucid Link).
Disruption is afoot in the storage world and it is centered on how best to provide global access and orchestration to petabyte-exabyte scale file, object and block data across a hybrid on-premises and multi-cloud IT environment. The innovation technology flags are being flown highest here by Hammerspace and VAST Data, and maybe WekaIO, with every other player we can see operating in wait-and-see or catch-up mode.





