WANdisco, which yesterday suspended trading shares on AIM, has appointed FRP Advisory to lead the independent investigation into the disclosed discovery of “potential” sales irregularities, and independent non-exec directors will help the process.
The company said that significant, sophisticated and “potentially fraudulent” irregularities concerning purchase orders, revenue and bookings had been discovered. A company statement said the irregularities were “represented by one senior sales employee” and “give rise to a potential material mis-statement of the Company’s financial position.”
“The Board now expects that anticipated fy22 revenue could be as low as $9 million and not $24 million as previously reported. In addition, the Company has no confidence in its announced fy22 bookings expectations.”
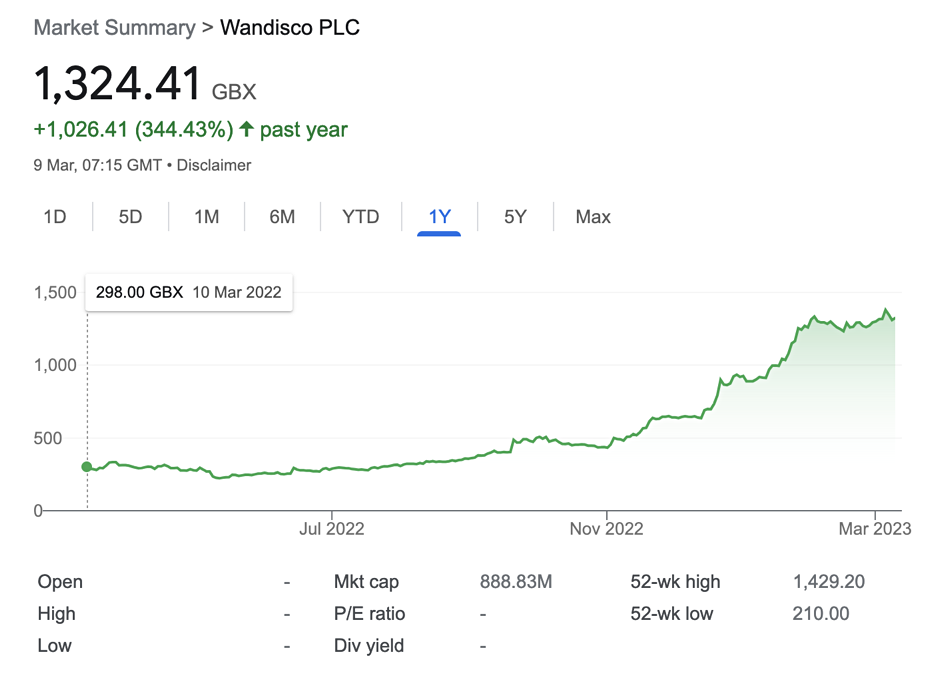
This revelation comes after a period of a strongly rising share prices for WANdisco:
It now appears that the revenue and booking numbers that supported the share price rise this year, and thoughts of a dual US-UK listing, may not bear out.
A $15 million revenue shortfall means WANdisco could conceivably run out of cash. Sales irregularities potentially causing a change in full year revenues from $24 million to $9 million – a $15 million drop – must have involved major accounts.
WANdisco has not named the “senior sales employee.”
The two non-exec directors helping the investigation are global equity expert Peter Lees and corporate financier Karl Monaghan, and they will support and facilitate the investigation process, the company said. Existing WANdisco external legal and professional advisers will also support the process as necessary.
FRP Advisory is a UK-based firm supplying forensic accounting, financial advice, restructuring, corporate finance, and debt advisory services. Its people will now have to ask WANdisco’s fy2022 customers what exactly they ordered and tally that with internal records so that an incoming cash position can be calculated and a basis for moving forward established.
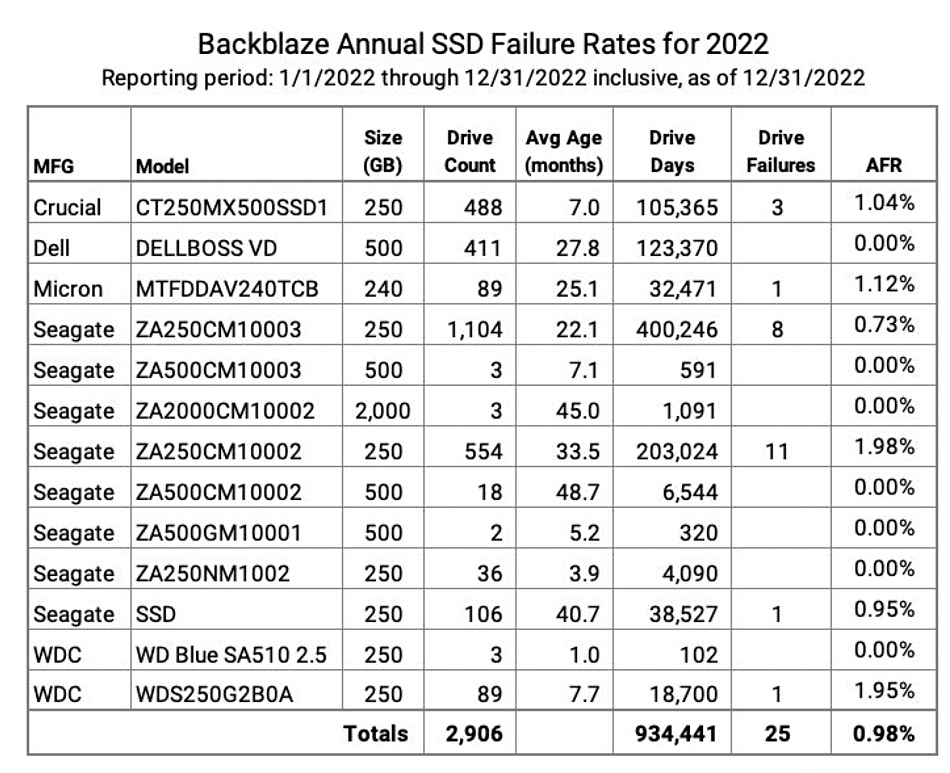
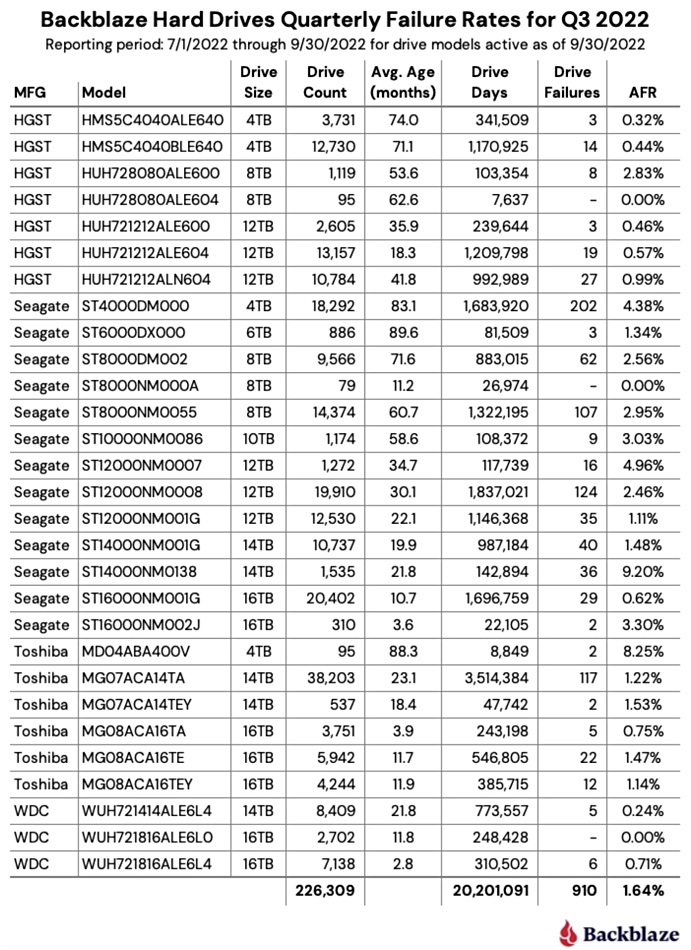
Cloud storage provider Backblaze has found its SSD annual failure rate was 0.98 percent compared to 1.64 percent for disk drives, a difference of 0.66 percentage points. It also noted that SSD manufacturers’ SMART stats were not so smart.
Backblaze stores customers’ backup and general storage data in its cloud datacenters. These are composed of disk drive pods and servers that use SSD boot drives. It has published disk drive annual failure rate statistics for some years and has now accumulated enough SSD data to publish SSD AFR numbers for the first time.
The surprise is that SSDs are not much more reliable than disk drives with their mechanical components – the moving read:write heads and spinning platters. Here is its SSD data table:
An equivalent table of its disk drive statistics provides comparative data:
Based on its SSD and HDD AFR percentages, the difference is 1.64 – 0.98 = 0.66, not even one in 100 drives. In a 1,000-HDD population, we would expect 16.4 to fail while with 1,000 SSDs we expect 9.8 to fail – a difference of 6.6 drives. The reliability difference is much less than we would have expected.
The failure reasons are not known, and why should they be? Only an SSD manufacturer would have the staff and equipment needed to diagnose a failed SSD.
Backblaze’s Andy Klein writes: “There were 13 different models in use, most of which are considered consumer grade SSDs … Six of the seven models had a limited number of drive days – less than 10,000 – meaning that there is not enough data to make a reliable projection about the failure rates of those drive models.”
Not so SMART
Klein notes that the SMART (Self-Monitoring, Analysis, and Reporting Technology) used for drive state reporting is applied inconsistently by manufacturers. “Terms like wear leveling, endurance, lifetime used, life used, LBAs [Logical Block Address] written, LBAs read, and so on are used inconsistently between manufacturers, often using different SMART attributes, and sometimes they are not recorded at all.”
That means you can’t use such SMART statistics to make valid comparisons between the drives. Come on, manufacturers. Standardize your SMART numbers.
He did find the SMART temperature recording was standard enough to permit a heat comparison between the SSDs Backblaze used, and found a bell curve, a normal distribution. He also found that the SSD temperatures were higher than that of Backblaze’s disk drives. “For 2022, the average temperature was 34.9 degrees Celsius. The average temperature of the hard drives in the same storage servers over the same period was 29.1 degrees Celsius.”
This was an odd result. Klein writes: “One possible reason is that, in all of our storage servers, the boot drives are further away from the cool aisle than the data drives. That is, the data drives get the cool air first.”
He looked to see if there was a relationship between SSD temperature and failure, plotting a curve for the failed drives. “We attempted to plot the same curve for the failed SSDs, but with only 25 failures in 2022, the curve was nonsense.” It was simply not statistically valid.
He says his SSD population size limits statistical validity. “We acknowledge that 2,906 SSDs is a relatively small number of drives on which to perform our analysis, and while this number does lead to wider than desired confidence intervals, it’s a start.”
Indeed, and it’s data we have not seen before. Keep it coming, Backblaze.
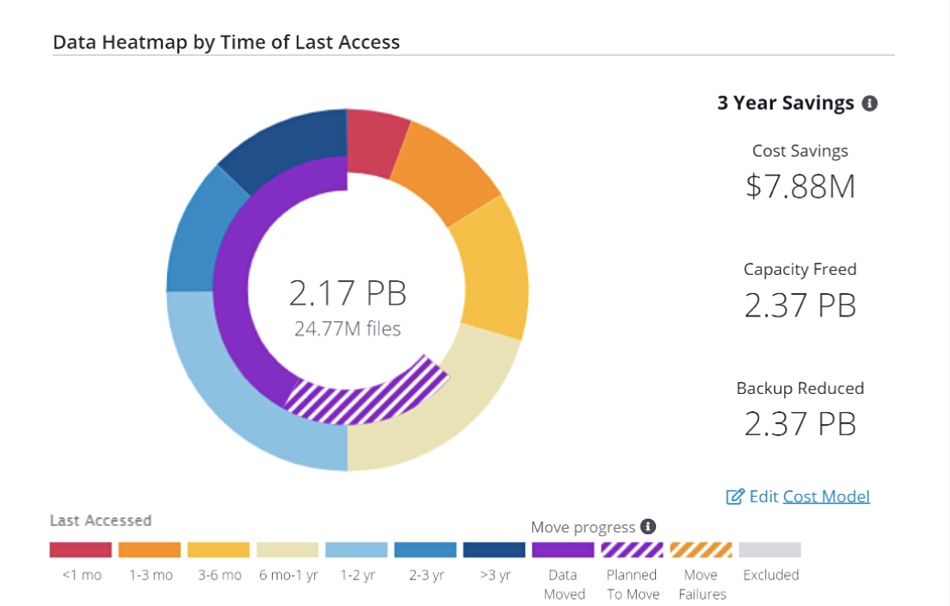
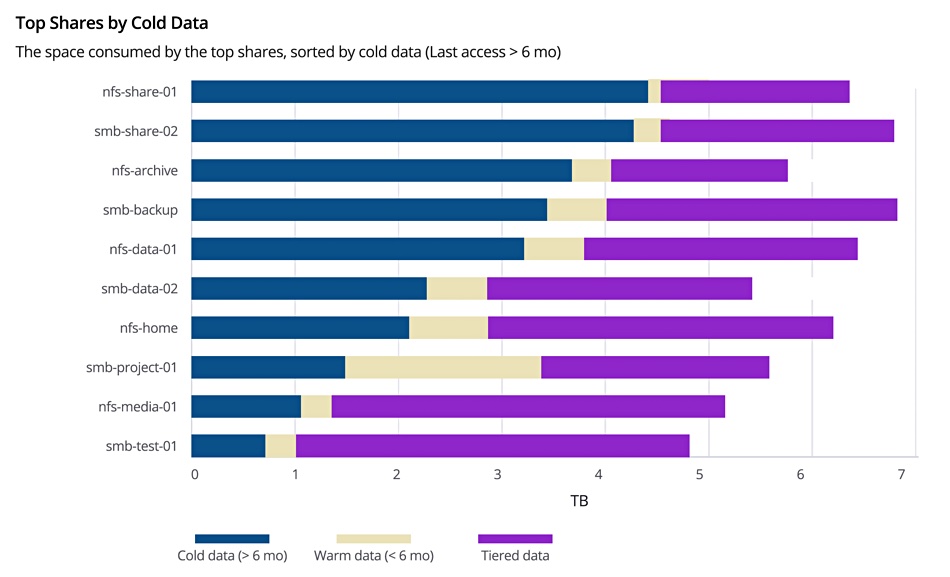
A Komprise Analysis dashboard can show customers the cost savings from moving little-accessed files to less expensive storage.
The Komprise Analysis feature is available as-a-service, with a set of pre-built reports and dynamic interactive analysis. Users can point Komprise at all file and object storage – including NetApp, Dell, HPE, Qumulo, Nutanix, Pure Storage, Windows Server, Azure, AWS and Google – to see a unified analysis in a few minutes showing how data is being used, how fast it’s growing, who is using it, and what data is hot and cold.
Paul Chen, senior director of product management at Komprise, said: “Komprise Analysis gives enterprise IT teams the visibility and information they need to cut costs with smart data tiering, data management and cloud data migration initiatives.”
Komprise Analysis report
Users can set different data management policies and their own customized cost models to interactively visualize expected savings. The beauty of this is that you can pretty much immediately see if it’s going to be worthwhile buying Komprise’s software for hierarchical storage management functionality.
Komprise Analysis file access heatmap
Komprise says that its Analysis offering scales across hundreds of petabytes with no performance impact to storage. Users can help to address data retention, data segregation and reporting for compliance and security use cases. They can also find out about file system and network topology performance bottlenecks before they impact data movement.
The built-in reports include:
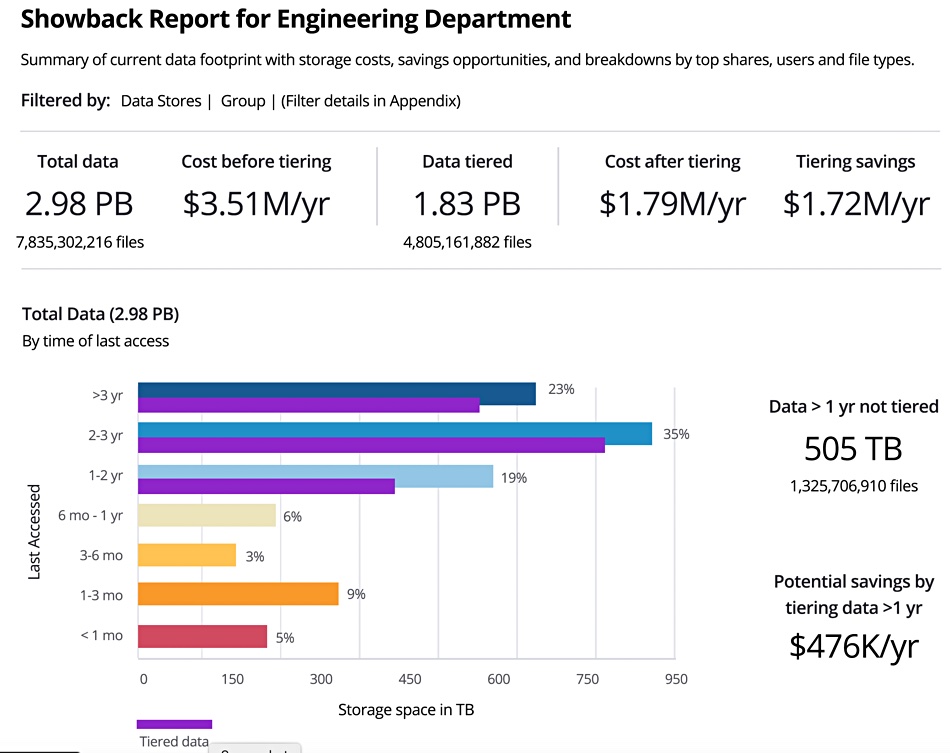
Showback –See storage costs, potential savings and a breakdown by top shares, users and file types to foster better departmental collaboration and buy-in.
Cost Savings – Understand projected cost savings and three-year projections for data growth of each data management plan.
Data Stores – See all data stores across locations, vendors and clouds to easily sort across metrics like fastest growth, newest data, coldest shares.
Orphaned Data – See obsolete, orphaned data and potential savings from its deletion.
Duplicates – Identify potential duplicates across storage vendors, silos, sites and clouds.
User Audit – Monitor user access and usage for auditing purposes.
Previously quiet data migrator Interlock has decided to raise its profile and tell the world it’s a better migration supplier than Datadobi and other players such as Data Dynamics and Atempo with its Miria offering. Datadobi disagrees.
Noemi Greyzdorf
Interlock tells us it has been migrating data over the past 14 years, with more than a thousand migrations – from a few terabytes to petabytes – without any data loss. Noemi Greyzdorf, Interlock’s strategic marketing consultant, said: “The challenge with data (file/object) migrations is that there are many hidden complexities that, when not addressed properly, result in longer migration times and costs.” Greyzdorf supplied examples:
Unlike competitors, Interlock can migrate data from disparate vendors as well as across protocols (NAS to S3). It is able to perform data transformation necessary to translate data formats and structures of one vendor/protocol to another.
Interlock can extract data from application if given access to storage. This allows Interlock to migrate data at the storage layer which is faster, than through the application.
Typically, when migrating data across different storage systems, built-in data protections like snapshots, are lost, but with Interlock, snapshots, labels, as examples, may be migrated with data.
Migrations are complicated by lack of resources such as bandwidth and CPU/memory due to production state of the system. Interlock is able to track utilization (when the system is busy etc.) and adjust number of threads accordingly. This also helps reduce required cutover time.
Most other vendors are pretty good at migrating like systems or like protocols. Datadobi migrates CAS data from Centera to CAS on ECS, but is not able to migrate CAS data to NAS or S3. Others can migrate data if environments are mirrored, but don’t take into consideration unique aspects of each system and its implementation of protocols, structures, application or metadata etc.
We asked Datadobi about this and a spokesperson replied:
Datadobi can do this too.
Datadobi can do this too on selected applications.
When migrating across disparate platforms from different vendors data protection constructs such as snapshots are incompatible. But Datadaobi can be used to execute migrations involving snapshots by employing a specific method to reconstruct the snapshots that are to be retained across systems. With regard to “labels” we assume that is referring to tags (metadata extensions) applied to content as an organization mechanism. Datadobi provides tagging (labeling) and can transfer these tags/labels when migrations are executed.
As can Datadobi. Datadobi can also manage network bandwidth consumption and even combine network throttling with thread level throttling.
This isn’t right. Datadobi has been migrating CAS-to-NAS for 12 years and CAS-to-S3 for seven years. We still do a fair number of CAS-to-NAS/S3 migrations, mostly with the very large enterprises who still have substantial Centera and ECS estates.
For Interlock, migration between different vendors and across protocols is complex. Greyzfdorf said: “Datadobi’s claim is that ‘DobiMigrate enterprise-class software would enable them to migrate file or object data between any storage platform, on-premises or in the cloud – safely, quickly, easily, and cost effectively.’ The devil is in the details. A tool can do like-to-like migrations or some very basic ones, but as soon as you add scale, applications, permissions, or data protection into the equation, a canned tool will require customization. As the quote implies, copying data is only part of the solution.”
Application data extraction is an Interlock specialty: “The extraction’s purpose is to make data available independent of the application, especially when the application is only retained and licensed to access older or archived data. Interlock can extract data regardless of application as long as there is access to storage system. Interlock can extract data and make it searchable on file or object protocols.”
Interlock’s way of dealing with snapshots “is not to reconstruct snapshots, which is taking each snapshot and recreating the file in a separate file system, which can exponentially increase the required capacity on the target system to store all the snapshots. Interlock captures the actual delta that is represented by the snapshot and appends it to an object or creates it on the target system. This may increase incrementally required storage capacity but by a very small factor in comparison to reconstructing data. Interlock supports this when migrating data off or on NetApp and Isilon.”
The company ducks the network bandwidth and throttling issue, and says it has a helpful way of handling cutover: “Every migration tool has developed some methodology to manage thread counts and network consumption; the challenge here is more about the cutover. The cutover requires some interruption to operations and minimizing the cutover window is critical. Interlock has developed an observability capability that enables the cutover to be minimized.”
This leaves us in the position of suggesting that users needing migration capability should consider proof-of-concept trial runs before selecting a vendor.
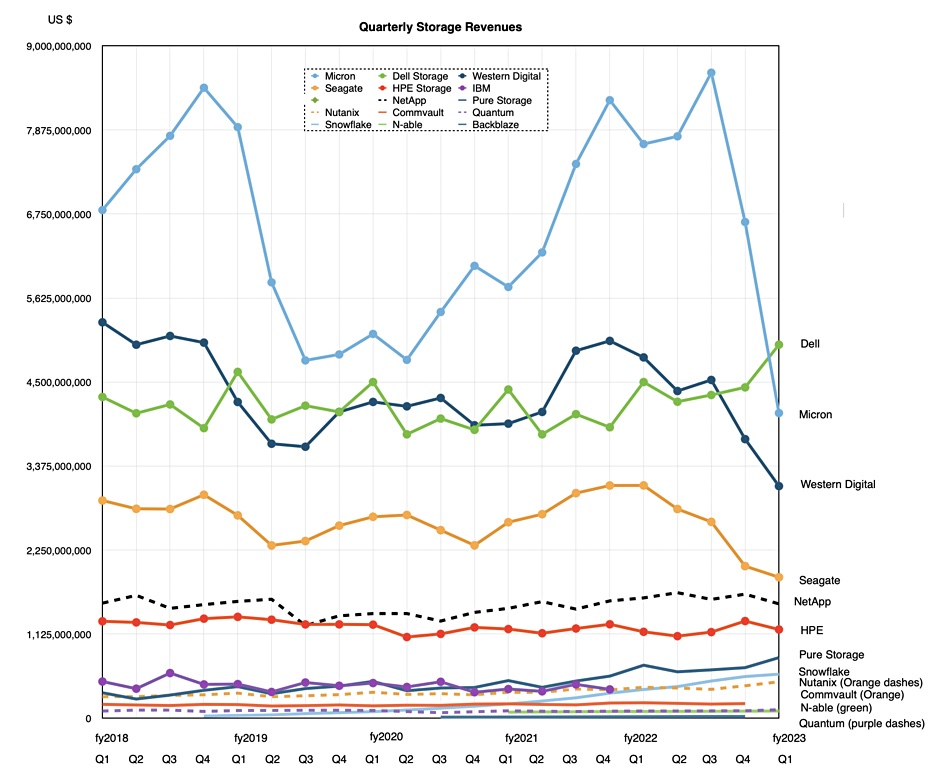
The latest look at storage supplier revenue trends show the flash and disk media companies taking a dive and systems suppliers like Dell, Pure Storage, and Snowflake enjoying a rise.
We track the revenues of publicly owned storage suppliers over time and every so often compare them all in a chart with the most recent one showing this pattern:
All the suppliers’ quarterly revenue reports are normalized to HPE’s financial year. We are looking at just the storage revenues from systems suppliers such as Dell and HPE.
We last reviewed storage supplier revenue trends in September 2022 and the media suppliers were riding high. The NAND supply glut and general economic situation have brought this low, with Micron revenues falling below those of Dell’s storage business, and both Western Digital and Seagate revenues tumbling below Dell as well. Dell has been on a rising trend since mid-2021.
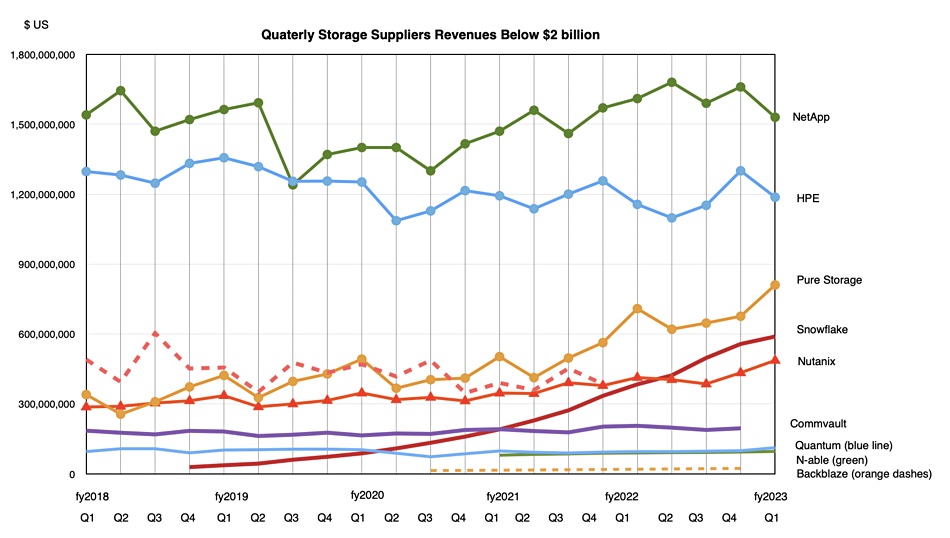
If we redraw the chart to exclude all suppliers with revenues greater than NetApp we get a clearer picture of what’s happening to suppliers in this area of the market:
NetApp is slowly distancing itself from HPE in storage revenue terms, though both rise above the rest. Three suppliers are edging towards HPE – Pure, followed by Snowflake and Nutanix, which has been overtaken by Snowflake.
Four suppliers form the bottom level of our chart: Commvault, Quantum, N-able and Backblaze.
We think it likely that Rubrik may IPO later this year or in 2024, perhaps followed by other privately-owned business including Cohesity, Databricks and even Veeam perhaps, and then their numbers would then appear on this chart as well.
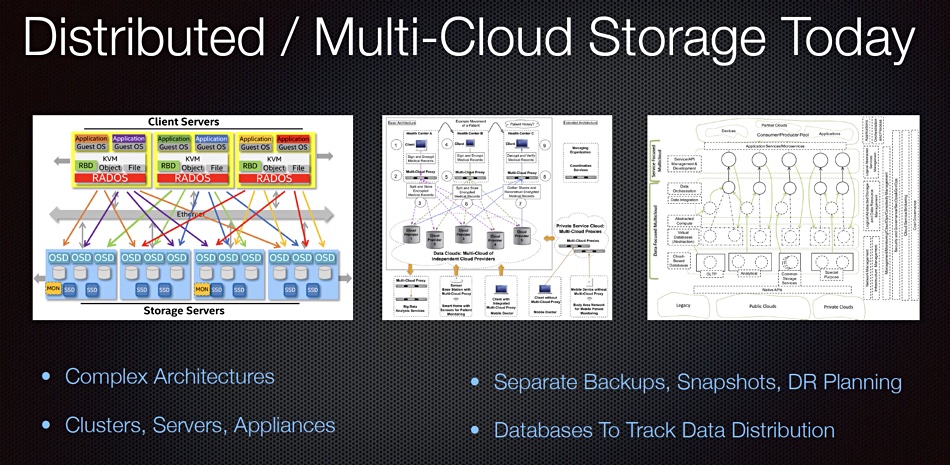
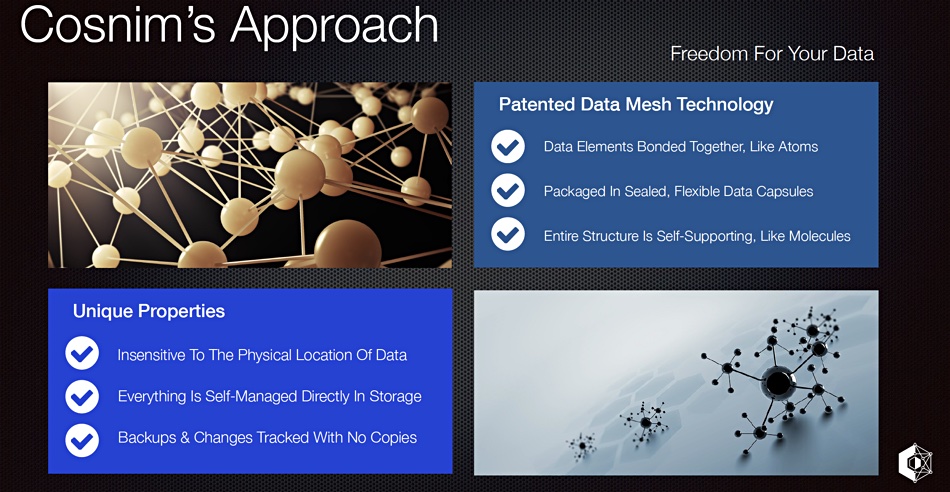
Data elements should be stored like atoms and molecules, self-bonding into data structures like files and objects, and held in capsules forming a universal storage entity accessible from anywhere. That’s the concept of Cosnim, a Canadian startup that claims to have a new approach to storage with a universal and distributed data storage engine offering file, object and database access using data elements bonded together like atoms and molecules.
Update. The Nebula term has been replaced by Continuum in Cosnim documentation. 14 March 2023.
COO Leon Parsaud told B&F: “We have developed a patented solution that can store data across multiple clouds while providing additional features such as time travel (infinite resolution of your data at any point in time), ransomware protection and enhanced cost savings.”
Cosnim diagram of today’s distributed multi-cloud storage
Cosnim’s features include:
Ransomware and outages protection – continuously shields data everywhere from common threats using robust and fully immutable storage.
Store anywhere, no servers or appliances – store and distribute your data on any combination of cloud, datacenter and local storage, no vendor lock-in. Everything is managed in software running directly on client devices and services.
Absolute cloud confidentiality – everything about your data is encrypted directly on your own devices, metadata included, before it’s sent anywhere. Since there are no servers, your data and encryption keys always stay 100 percent private.
Time-travel – access any past data instantly. Examine any of your past data at any point in time, instantly, at any resolution. It’s as if you had sub-second backups, archives and snapshots at every possible moment. No delays, no restores.
Fast integration – all your files are accessible directly through your OS as if it was local storage, wherever your data is actually stored, in the cloud, your datacenter or elsewhere. All transparently, greatly reducing the complexity of migrating and accessing data in the cloud.
Unified storage – live storage, backups, snapshots, archives and versions are all integrated and maintained in a single unified storage system distributed across the cloud and datacenters, simplifying data and storage management.
Cost reduction – Cosnim claims its design consumes significantly less raw storage and network egress charges compared to other technologies.
Leon Parsaud
We were given a Cosnim Technology Primer document explaining these concepts. It talks about distributing data in the cloud and claims: “The primary reason why decentralized storage management is so complex and difficult is that we’re still basically managing data as if they were pieces of paper.”
For example: “Backups are essentially the electronic equivalent of taking photocopies of pages and then putting them in archival boxes; replication is the equivalent of sending photocopies to a remote office, tracking and re-sending copies if the original is altered; servers are the equivalent of comptrollers, which carefully coordinate and centralize the view of the data; even journaled filesystems and blockchain are based on basic ledger concepts, albeit with a few twists.”
Data atoms and molecules
Cosnim believes we need to move away from this paper-based origin and think of data as “self-governing elements, forming free bonds between each other to build a self-supporting structure, much the same way atoms bind themselves together to form large, complex molecules.” Cosnim treats all fundamental pieces of data in this way.
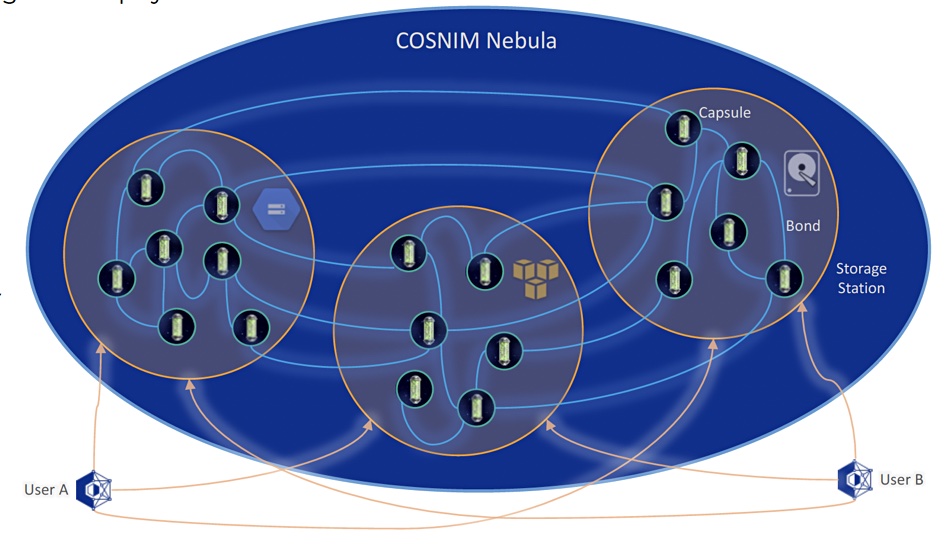
When storing files, “Cosnim breaks up the file’s contents into fragments and binds them all together with metadata and control information, which are also elements. Elements are then packaged into one or more capsules (which may contain other unrelated elements) and bonded in turn with other capsules in the Nebula.”
A Nebula is a mesh of inter-related elements and capsules, similar to large molecules built from smaller molecules and atoms. Cosnim has patented processes and proprietary algorithms to manage these bonds, which enables “capsules and their data to be freely stored and distributed anywhere in the cloud or on local devices, on any number and type of storage, without any tracking of their physical location.”
Capsules are physically stored on storage stations through which users connect to the system (Nebula). “There are no central servers, clusters, or peer-to-peer communication. Everything is held together and managed entirely through capsules and the bonds that form the Nebula.”
Cosnim Nebula concept
“When data is updated, instead of physically replacing or updating actual storage units such as blocks or files, Cosnim creates small new elements and ever so slightly alters the mesh to integrate this new data, leaving all other components intact. There is no fixed location for any of the data; any storage station and capsule are fully capable of carrying everything.”
Deeper dive
We asked Cosnim a question about metadata storage: “With Cosnim’s distributed data elements making up, for example, a file, there has to be metadata describing how the file elements are to be combined in a file. Where is this metadata stored please? In a central place? How does a local storage engine know how to build the file when access to it is requested – if the elements making up the file are distributed?”
Guy Sabourin
Guy Sabourin, CEO, CTO and co-founder, told us: “In Cosnim, data, data fragments, metadata and control information are all part of our mesh, which we call a ‘continuum’, and everything is stored in general-purpose capsules. Capsules are stored themselves in a universal format about anywhere, as cloud objects, files, database records or raw storage. The actual storage location is irrelevant to Cosnim, all we care is to have a place where the capsules can be stored and retrieved.
“We don’t have very specific locations for metadata; everything in Cosnim is internally bonded together through a variation of our patented technology, and in order to reach a file for example, we use these bonds between data elements, which could be considered a loose equivalent of filesystem root, directories, file metadata and data fragments, to reach the data. But there are no central servers, repositories, catalogs or indices to manage this; the bonds themselves hold the entire continuum together, which is how we work serverless.
“So to answer your question, I’m guessing where your mind is, there’s no ‘official’ server or location where this metadata is held or organized, nor do we know in advance where it’s going to be. It can be physically anywhere, in any capsule in any storage system. We figure out the data distribution layout very quickly when we first connect to storage systems, but even then, the metadata remains fully mobile afterwards and can freely change location, as long as the customer’s configuration allows that to happen of course.
“Critical data is also replicated, so we have more than one place to go to during outages. Finally, we don’t reconstruct files on local storage, we implement our own filesystem and we stream the data directly from the continuum (which can have pieces cached on local storage) to the OS or application, on demand. We do this both for reading and writing.
“Unfortunately, there’s no external technical documentation that explains the core technology beyond [the tech primer], most of our outreaches think we already go too deep on the tech side!
“If you’re interested in the underlying technology though, we do have a great demo with a very visual console that shows graphically how this is organized and behaves in real life. We use that to help our audience understand multi-cloud data distribution and resiliency better, so this might answer your questions better. We do have some trade secrets in how we make the core technology work smoothly in real life though.”
Contact Cosnim if you are interested in seeing the demo.
Background
The company has two officers according to its website: CEO, CTO and co-founder Guy Sabourin, and COO and co-founder Leon Parsaud. There are various advisors as well. Sabourin describes himself as the inventor, founder and CEO of Cosnim Cloud Technologies and is a ex-IT consultant and software engineer. He spent several years at Morgan Stanley as an IaaS virtualization software engineer. Parsaud is an ex-private equity person with his Sipher business offering clients strategy and branding help.
AWS engineer Andy Warfield has a FAST’23 technical session entitled “Building and Operating a Pretty Big Storage System (My Adventures in Amazon S3)” which is viewable on Youtube.
…
Data protector Arcserve ran a research study in the UK which found that 27 percent of IT decision-makers (ITDMs) falsely believe that cloud providers are responsible for protecting and recovering data in the public cloud. It’s getting better. In 2019, 47 percent of ITDMs believed it was the cloud provider’s responsibility. The misconception persisted in 2020, with 40 percent believing the same, and now stands at 27 percent in the latest research.
…
British cybersecurity company Censornet has announced Total Protection, a new product package to prevent data loss and breaches. Targeted at companies in the mid-market, Total Protection is designed to defend email, web, and cloud apps, and provides advanced enterprise-grade data loss prevention. It says its package will enable organizations to protect their entire digital attack surface – web, email, cloud – via a single, consolidated solution. Complete with advanced Data Loss Prevention (DLP), it removes the need for multiple point products, giving organizations enterprise-grade security with instant data protection and rapid time-to-value, we’re told.
…
Managed infrastructure solutions provider 11:11 Systems has launched 11:11 Managed Backup for Cohesity. This managed service brings together Cohesity’s DataProtect platform and cluster-based architecture with 11:11 Systems’ workload integration and backup management to create an on-prem data protection bundle. By combining Cohesity’s software deployed on-site with 11:11’s onboarding, configuration, and ongoing management, customers get comprehensive protection from a secure, scalable backup offering in a single, seamless system. In the event of a ransomware attack, customers can quickly recover at scale.
…
Cohesity has been named a Leader in the Omdia Universe: Protecting and Recovering Data in the Cloud Era, 2022–23 report. It was recognized for its modernized data protection approach and capabilities in core backup and recovery, and monitoring and reporting. Cohesity earned the top capability score due to its high ratings in solution breadth, roadmap and strategy, and solution capability
…
Leveraging Cyxtera’s global footprint of colocation facilities and Digital Exchange network fabric, Cyxtera and Dell will provide global enterprises of all sizes – as well as federal, state, and local government organizations – with full stack infrastructure as a service. This includes compute infrastructure, network connectivity, and colocation space and power at the individual server and rack unit levels. These capabilities enable a cloud-like experience for the deployment of workloads that require the control, performance, and security of dedicated infrastructure and colocation, the companies claimed.
…
Data lakehouse supplier Databricks has launched Databricks Model Serving to provide production machine learning (ML) natively within the Databricks Lakehouse Platform. Model Serving, so said Databricks, removes the complexity of building and maintaining infrastructure for intelligent applications. Customers can use Databricks’ Lakehouse Platform to integrate real-time machine learning systems across their business, from personalized recommendations to customer service chatbots, without the need to configure and manage the underlying infrastructure. Deep integration within the Lakehouse Platform offers data and model lineage, governance, and monitoring throughout the ML lifecycle, from experimentation to training to production. Databricks Model Serving is now generally available on AWS and Azure.
…
Cryptographically verifiable immutable enterprise-scale database supplier immudb has announced new connectors that it said make it possible for data kept in any other data store, for example a PostgreSQL database, to be made tamper-proof for forensic, judicial or auditing purposes. With immudb connectors, data can be extended to and stored inside immudb with guarantees against tampering while providing high performance and full query capabilities. immudb is pitcheed as being capable of protecting sensitive data for workloads that require the utmost in data security. Codenotary uses immudb to underpin its software supply chain security product. There have been more than 15 million downloads of immudb so far.
…
Intel Data Center Manager 5.1 helps monitor, calculate, predict, and control the operational carbon emissions and footprint by collecting the telemetry from the IT devices in the datacenter. It is one component for organizations focused on achieving sustainability goals and lower power costs. Take a look here.
…
Kasten by Veeam, which supplies Kubernetes backup and recovery, announced near triple-digit Annual Recurring Revenue (ARR) growth in fiscal 2022. Kasten has expanded its footprint by doubling the size of its staff and extending its presence in the enterprise space and vertical markets such as finance, wireless telecom, and the public sector. According to recent ESG research commissioned by Kasten, “83 percent of organizations will be using containers in the next 12 months,” said Christophe Bertrand, Practice Director at ESG. “The container backup market will continue at a fast pace, considering 93 percent of organizations think it is important to have a container backup and recovery management solutions that works across multiple public cloud infrastructure.“
…
NAND foundry operator Kioxia is increasing the usage of renewable energy by installing large-scale solar power generation systems at its Kitakami and Yokkaichi plants. Installed on the rooftop of flash memory fabrication facilities, the new solar power systems will be the largest of their kind at any semiconductor plant in Japan. With a total generating capacity of about 7.5MW, the new solar power systems are forecast to generate about 7,600MWh of electricity annually for Kioxia and reduce carbon dioxide emissions by about 3,200 tons per year.
Kioxia NAND fab roof solar panels
…
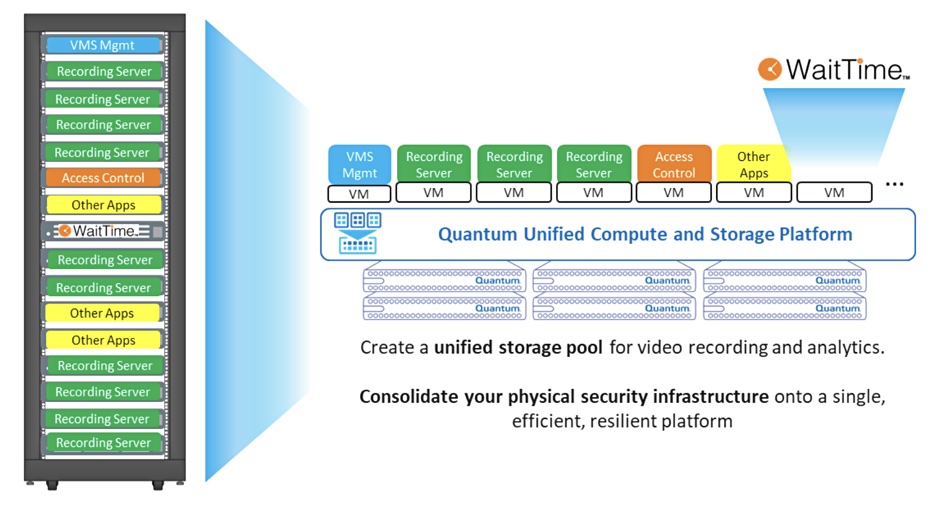
Quantum has partnered with WaitTime, a supplier of crowd intelligence analytics, to deliver a certified system built for real-time crowd intelligence using video surveillance data captured and stored by Quantum’s Unified Surveillance Platform (USP). This is a unified compute and storage platform that is designed to retain data even if hardware fails. It is capable of scaling to handle tens of thousands of cameras. USP is able to manage and run multiple physical security applications on a single infrastructure, including analytics applications like WaitTime. The combined USP and WaitTime system uses data produced by video surveillance cameras to analyze queues in venues such as stadiums, malls, airports, and more.
Quantum WaitTime diagram
WaitTime’s AI software provides real-time data and historical analytics on crowd behavior, we’re told. Its patented AI gives operations personnel live information on crowd movement and density, while providing guests all they need to navigate a venue and information on things like queue times at concession stands.
…
Rockset has introduced compute-compute separation in the public cloud for real-time analytics that isolates streaming ingest compute, query compute, and compute for multiple applications. It says that, until now, there has been a fundamental limitation in every database architecture designed for real-time analytics. A single component performs two competing functions: real-time data ingestion and query serving. These two functions compete for the same pool of compute resources, threatening the reliability and scalability of real-time analytics. Rockset has separated them, and so provides:
Isolation of streaming ingest and queries: Predictable streaming performance even in the face of high-volume writes or reads. Avoid contention and over-provisioning compute.
Multiple applications on shared real-time data: Maintain a single real-time dataset and spin up compute instances to serve multiple applications. Achieve workload isolation without creating replicas.
Fast concurrency scaling: Scale out across multiple clusters to support high concurrency
…
SK hynix is developing 300+ layer 3D NAND, a record layer count. Apparently it presented a session at the 70th IEEE International Solid State Circuits Conference (ISSCC), held in San Francisco in late February, and discussed a 1Terabit chip with 300+ layers, a TLC (3bits/cell) format and a 194 megabytes per second write speed, also a record. SK hynix is currently sampling 238-layer 3D NAND with 512 Gbit chips organized in TLC format.
…
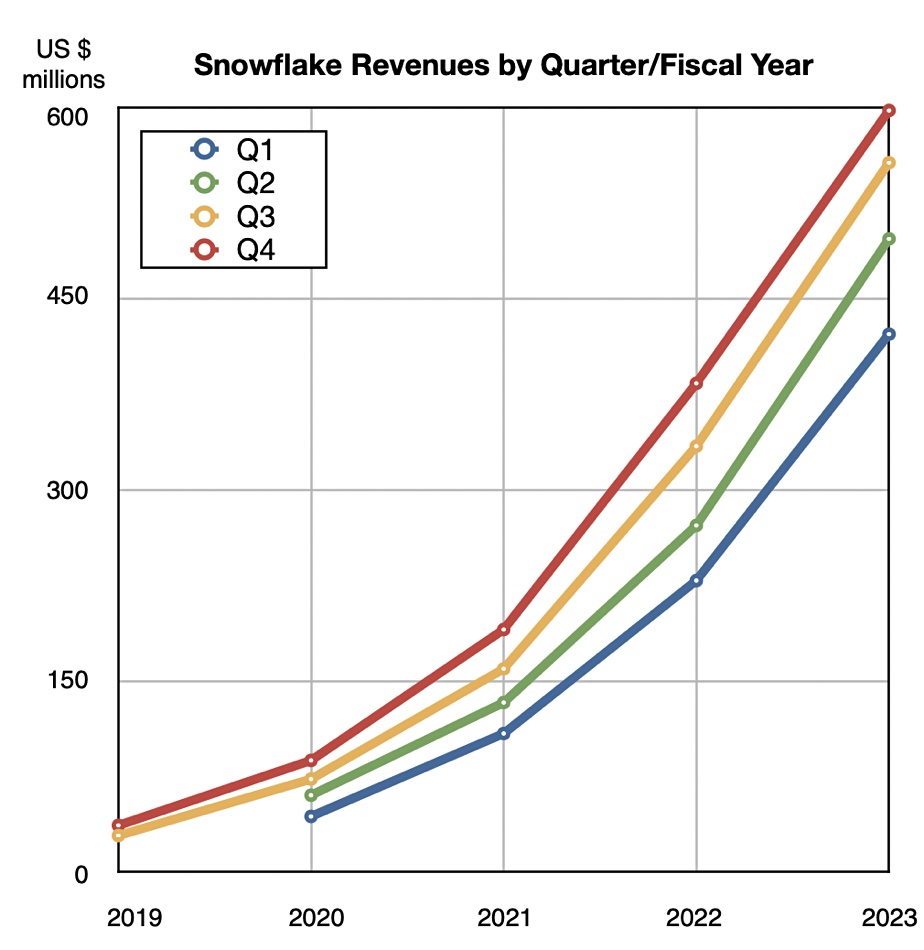
Snowflake’s relentless revenue growth
Cloud data warehouse biz Snowflake announced its Q4 and full 2023 results. Q4 revenues were $598 million, up 53 percent. Product revenue for the quarter was $555.3 million, representing 54 percent growth. There was a loss of $207.2 million, deeper than the year-ago $132.2 million loss. Net revenue retention rate was 158 percent as of January 31. The company now has 7,828 total customers and 330 customers with trailing 12-month product revenue greater than $1 million. Full year revenues were $2.07 billion with a loss of $796.7 million. It’s going for massive growth over profitability.
…
SpectraLogic has sold an 18-frame TFinity exascale tape library to the SLAC National Accelerator Laboratory at Menlo Park, California, using LTO-9 tape media. SLAC is operated by Stanford University for the US Department of Energy. It supports an array of scientific projects focused on cosmology and astrophysics, materials and energy science, catalysis, ultrafast science, and cryogenic electron microscopy. SLAC supports the Rubin Observatory’s 10-year Legacy Survey of Space and Time (LSST) which will scan the entire visible southern sky every few days for a decade. SLAC expects its total storage needs to reach upwards of two exabytes by 2033. Download and read a case study here.
…
STMicroelectronics’ new automotive SoCs enable real-time zonal or domain control in electric and hybrid vehicles. Targeting ASIL-D drivetrain systems, the Stellar P-series engages directly with local sensors and actuators. It features a non-volatile phase-change memory (PCM) duplicated for reliable over-the-air (OTA) updates. PCM has superior read time as well as byte and bit-level write capability compared to embedded NAND; it can also be manufactured in 28nm and finer processes. Just announced is the SR6P6x (P6) line, which is a subset of the earlier SR6P7x (P7) SoC.
…
Archiver StrongLink has announced new Cloud Storage features:
S3 IBR: Immutable Feature allows StrongLink to protect against data deletion by safeguarding data written to S3 Cloud Storage providers.
Hard Delete: Ensures that data written to an S3 target is hard written by performing 2-step verification.
Containers: Allows for multiple S3 buckets to be created.
Black Pearl Store Support: Enables enterprises to write using the S3 Protocol directly to SpectraLogic storage systems.
Export Versioning: Provides the ability to identify the differences between various versions without accessing the S3 bucket and comparing.
Glacier Support: Enables enterprises to present the Glacier Tier of AWS on virtually any storage target.
Azure Support: Enables enterprises to extend StrongLink’s global file system across Microsoft Azure Cloud Storage, allowing ubiquitous data access.
…
Synology has launched two new NAS systems: the DiskStation DS1823xs+, and RackStation RS2423+/RS2423RP+. The DS1823xs+ is an eight-bay desktop NAS built for offices and studios where a dedicated server rack is not available, while the RS2423+/RS2423RP+ is a 12-bay rackmount solution designed to provide SMBs power and flexibility as storage demands grow. Highlights for DS1823xs+ and RS2423(RP)+ include built-in 10GbE connectivity on both units, upgradable to 25GbitE, up to 324TB and 432TB of raw storage capacity after expansion, and over 3,100/2,600 MBps and 3,500/1,700 MBps sequential read/write.
…
ReRAM developer Weebit Nano’s ReRAM IP is now available from SkyWater Technology. Demo chips produced by SkyWater integrating Weebit’s ReRAM module were recently received from manufacturing and proven fully functional. These chips are currently under qualification, and are being used for customer demonstrations, testing and prototyping. SkyWater customers can now integrate Weebit’s ReRAM non-volatile memory (NVM) in their system-on-chip (SoC) designs. Weebit’s ReRAM has up to 100K write cycle endurance, supports 10 years’ data retention at high temperatures, and has ultra-low power consumption, including down to zero standby power. Weebit is partnering with the University of Florida’s Nino Research Group to examine the effects of radiation on its ReRAM, and initial studies confirm the technology is tolerant to high levels. There is a whitepaper about this.
…
Subscription-based datacenter kit supplier VergeIO has devised a VMware Exit Strategy in response to ongoing frustration with VMware’s pricing policies and concerns over the impending Broadcom acquisition. The program includes a competitive trade-in to VergeOS and a migration service powered by a new feature, IOmigrate. Customers can use existing hardware and reduce VMware costs by more than 50 percent, VergeIO claims. IOmigrate uses VMware’s change block tracking (CBT) technology to synchronize virtual machines with VergeOS VMs in near real-time. IOmigrate can be used as a backup and disaster recovery system while testing converted VMs.
Embracing diversity means being open to human talent wherever it occurs. AWS VP of Technology Mai-Lan Tomsen Bukovec chatted to us about women in senior levels in the IT field. She is an ex-general manager of AWS S3, Amazon CloudWatch, EC2 Auto Scaling, Amazon monitoring, and Amazon Simple Workflow before that.
Blocks & Files: With International Women’s Day today, what can be done to attract more women to the IT supplier field?
Mai-Lan Tomsen Bukovec: We must attract and retain more people from under-represented groups so we are bringing diversity to our work force and our ideas. That starts first with creating an inclusive and supportive environment where team members can brainstorm and iterate on the great news ideas of today and tomorrow. It can be daunting if you don’t feel supported, heard, or have the ability to bounce ideas off of someone and gain their advice or perspective. It’s why it’s so important to me as a leader to create and build a work community that cultivates these learning opportunities that support our careers. Additionally, we must encourage and support other people on the team (allies) who can really help invite diverse perspectives and transform a challenging environment. Change starts locally – in our own teams, with actions that we as individuals take.
In addition to owning change in their own organizations, leaders need to mentor and sponsor the next generation of diverse leaders across their companies. Human potential is everywhere. The first step is identifying and growing that talent. Then leaders have to make sure that there are opportunities for growth, channels to be heard, and a safe place to practice skills. It’s one of the reasons that I’ve been here in AWS for almost 13 years and look forward to many more – I think it’s a great place to learn and grow as a working mom/technical leader.
I will also say that change starts with each of us. Changing the diverse talent experience on your team isn’t just owned by the diversity or human resources team. Those organizations are invaluable for helping teams understand what inclusion and diversity means and how to get there. But real, sustained change requires organizational leaders and influencers to personally own and drive the change they want to see, starting first by understanding what the actual, on-the-ground experience is for their diverse talent and then changing it for the better. It’s up to us as leaders to find that talent, even if it’s in unexpected places, and develop it as mentors, sponsors, and human beings.
Blocks & Files: You are an executive sponsor for Asians@Amazon affinity group. What are you hearing on support for the community in the workplace?
Mai-Lan Tomsen Bukovec: Our Asians at Amazon affinity group focuses on sharing and celebrating our different Asian cultures, creating communities and events for Asian Amazonians all over the world, and helping leadership develop skills. We have an amazing volunteer community among the Asians@Amazon community who operate as a “board of directors” both locally and globally to support the larger Asian community in the company.
We take the same approach of listening to our customers as we do when we build products and services – which means we ask our individual local and global communities how we can support them and build programming and activities to do so.
Two key focus areas we heard were 1) bringing the community together through events to help strengthen bonds and provide networking opportunities; and 2) providing mentorship and guidance for leadership growth. For example, I am partnering with another Asian VP, Tony Chor, to lead monthly leadership training sessions for members of our Asians@Amazon community. The board of directors for Asians@Amazon also organizes celebrations for important holidays like the Lunar New Year, Diwali, and runs community building activities like a talent show, mindfulness/meditation classes, and a Ping Pong tournament.
You have to celebrate difference at the core of everything you do as a builder of products and services in order to innovate. At Amazon, our Amazon Leadership Principles guides how we operate as builders of product and services. The Amazon Leadership Principle “Right a Lot” explicitly calls out that leaders “seek diverse perspectives and work to disconfirm their beliefs.”
That is a very important concept. Not only does the Leadership Principle specifically call out that we need to look for different perspectives, but it says that we need to actively try to find a viewpoint that contradicts a strongly held belief or approach. So, in order to be Right a Lot, you have to start by assuming that your starting conviction or belief might not in fact be correct and use the perspectives of those around you to confirm the right approach for what you are building.
I’ve seen firsthand how that works and can attest that it makes for a better product and service for our customers everywhere.
I also think that there’s a personal accountability for every leader to create a work environment that embraces diversity. If you make that personal accountability a shared tenet, then everyone knows that it’s part of the expectations of the organization. For example, the Amazon Leadership Principle “Strive to be Earth’s Best Employer” says “leaders work every day to create a safer, more productive, higher performing, more diverse, and more just work environment.” At Amazon, you are a leader as well as a manager, and that means it’s on everyone to work every day for that environment.
Blocks & Files: You have written this about balcony-hopping: “We take our operational promise to our customers very seriously. I carry a pager and if I get paged, I am [on] that balcony for my service – on the operational call, throughout the event and in the details for the follow-up. I didn’t straddle balconies. When I am at work, I am 100 percent present. When I am with my kids or my husband, I am 100 percent present.” Can you elaborate?
Mai-Lan Tomsen Bukovec: Before the week starts, I take a look at each day in the work week ahead. For a given meeting at work, I make sure that I understand my role so I can be 100 percent focused in the moments ahead – both feet on that balcony, whether it is as a mentor, manager, engineering manager, or product decision maker. My weekends are less structured but the same rule applies. If I am spending time with my husband or my kids, I’m fully present in those moments and my phone and other distractions tucked away.
I roughly calculate the percentage of time that I spend on each balcony during an average week. I make time for the balconies that are important to me and for the people who are on the balconies with me. I also track which important balconies that I didn’t spend time on in a given week so I can prioritize them for upcoming weeks.
When someone gets started with balcony hopping, it can be helpful to think about the impact on the person that shares your balcony, whether it is at home or at work. I know that my time is not inherently more valuable than anyone else’s time, no matter what role I have. If I am distracted or not focused in this moment, I am wasting the hard work of the team or the rare attention of my teenagers and basically sending them the message that my time is more important than theirs – which is not true and not OK. Being aware of my impact on that balcony helps me be present in my moment.
There are only so many hours in a day. The most important thing is that in the course of a given month, you are spending time on the balconies that are the most important to you. It is equally important to make sure that when you are on that balcony, you are 100 percent on it. You have both feet down, your weight is centered, and you are deeply in that moment.
Blocks & Files: What advice would you give your younger self if you were starting out in Microsoft back in 2001 from today’s standpoint?
Mai-Lan Tomsen Bukovec: I would tell my younger self and other women who are early in career to be bolder. Early on in my own career, one of my biggest challenges was overcoming my own perception that asking for new opportunities would be considered too much – too much of a stretch, too unexpected, too “insert something.” When I was younger, I sometimes held off on that bold ask and then saw others stepping into that gap instead of me. Once I realized that I had been overthinking the situation, I started to express what I wanted and as a result, I developed my skills much faster. It was a turning point for me. I had the work ethic and drive but once I realized how to grab an opportunity, it sped up how fast I was able to grow.
As we celebrate International Women’s Day, it’s important to reflect on the progress women have made in the hi-tech industry, while also acknowledging the challenges that still exist. As a woman in tech, I’d like to believe that our daughters and their peers will not have to face the same obstacles that I and my generation have experienced. However, the numbers suggest that, unless there’s a radical change, this will not be the case. While more women are entering the industry, they still face significant barriers – including gender bias, lack of representation in leadership positions, and wage disparities.
What are the challenges facing women and what needs to be done to ensure a brighter future for women in hi-tech?
Highlighting women’s successes
Celebrating women who have broken the glass ceiling is an important way to acknowledge and appreciate their achievements. Some notable examples of women leaders in the high-tech industry include:
Ginni Rometti.
Ginni Rometty Former chairman, president, and CEO of IBM, became the first woman to head the company.
Mira Murati Chief technology officer at OpenAI.
Ursula Burns The first African-American woman to head a Fortune 500 company and was previously the CEO of Xerox.
Diane Bryant A top executive at Intel for more than 30 years and led the company’s datacenter business.
Orna Berry Director of technology at Google CTO office, and former chief scientist at Israel’s Ministry of Industry and Trade.
These women have not only shattered the glass ceiling in their respective industries, but they have also paved the way for other women to follow in their footsteps. Despite these successes, women still face significant barriers in hi-tech.
The numbers tell a different story
While the proportion of women graduating with core STEM degrees is increasing steadily, the gender split remains at 26 percent, since the number of men graduating with core STEM degrees is increasing at a faster rate. This trend is also reflected in the STEM workforce, with women accounting for just 24 percent.
Using the data trends from the last ten years, 2009–2019, WISE has estimated that by 2030, they expect to reach over 29 percent of women in the STEM workforce.
Less than 45 percent of the workforce of the major technology companies in Silicon Valley – namely Google, Apple, Facebook, Amazon, and Microsoft – comprised women (ranging from 28 percent to 42 percent in 2020).
What is causing women to quit the hi-tech industry despite the substantial effort they have made to become accepted in this field?
Women are often driven out of a promising career in tech by a number of factors including institutional barriers, the COVID pandemic, gender bias, and more.
Navigating the boys’ club: the unspoken challenges
The hi-tech industry is often referred to as a boys’ club where conversations revolve around sports, table games, and complaints about wives. Unfortunately, these topics don’t always resonate with women. While these clubs can be enjoyable and sometimes offer lighthearted conversations, they also create a barrier for women to feel included. Imagine being the only man at a table. It makes you wonder what hi-tech offices would look like if women were in the majority.
This topic of the “boys’ club” in the tech industry is complicated as it contradicts the push for equal rights and behaviors between men and women. It’s challenging because, on the one hand, women advocate for equal rights and behavior, eliminating the boundaries between what is considered “masculine” and what is considered “feminine” –making the discussion about a boys’ club somewhat contradictory. On the other hand, it’s still a part of women’s daily challenges. How do we talk about the unspoken?
Tokenism vs empowerment: a delicate balancing act
A further challenge that women encounter as they pursue their careers in the tech industry is the lack of female role models with whom they can identify. As a recent addition to the high-tech industry, I attended a motivational session led by Orna Berry, the former chief scientist at the Ministry of Industry and Trade, and director of technology at the Google CTO’s office. This session was part of a women empowerment initiative held on International Women’s Day.
Witnessing a successful woman in a leadership role within the industry was undoubtedly inspiring, yet it also left me feeling intimidated by her remarkable accomplishments. While such examples serve as a source of inspiration, they may also create unrealistic expectations that discourage women, resembling a ladder with missing rungs, where one can either ascend to the top or remain at the bottom.
This experience prompted me to question the efficacy of using accomplished women as tokens, and whether it serves to close or widen the gender gap. Instead, a more realistic model of successful women in the hi-tech industry should be presented, showcasing women in various leadership positions, as well as those who are experts in their own fields. By doing so, we can provide a more comprehensive picture of success and inspire more women to pursue a career in this field.
The Imposter syndrome
Not all the challenges faced by women in the tech industry are external. As a woman working in this field, I have experienced firsthand what it’s like to feel like a misfit. I remember doubting my abilities and feeling like I was not as capable as the men beside me, and feared I’d be exposed as a fraud. This feeling is so common that it even has a name: the imposter syndrome – which 75 percent of female executives across industries have experienced. An interesting fact is that when asked which dynamics within the workplace were most valuable to help reduce feelings of imposter syndrome, 47 percent said having a supportive performance manager and 29 percent said feeling valued and being rewarded fairly.
Transforming the status quo: the vital role of men in advancing women in tech
Men have a significant role to play in promoting more opportunities for women in the industry, starting with guaranteeing early access to education and opportunities and continuing with creating more inclusive workplaces.
In fact, there are men out there who are making a difference, and who are actively working to make the workplace more inclusive and supportive of women. I’ve been lucky enough to have had a few of these men in my own career. Shai Harmelin from Dell EMC saw my potential as a product manager and encouraged me to make the switch from software engineering. Amit Liberman from Grid Services challenged me to embrace my emotions when I was upset (well he was actually so sarcastic about it, that he made me laugh immediately), and Aron Brand, CTERA’s CTO, simply told me: “Don’t worry, you’ve got this” just before I started writing this article. These men are proof that allyship is essential in creating a workplace where everyone can thrive.
Bootnote
Ravit Sadeh.
Ravit Sadeh, senior director of product management, CTERA, has more than 15 years of experience in product management and development in storage and cloud solutions. She is currently the senior director of product management at CTERA. Previously she held product management and development roles at Dell EMC and Amdocs. She has earned two Bachelor of Science degrees, one in Computer Science and one in Biology from the Hebrew University of Jerusalem. Ravit is a single mother of two children.
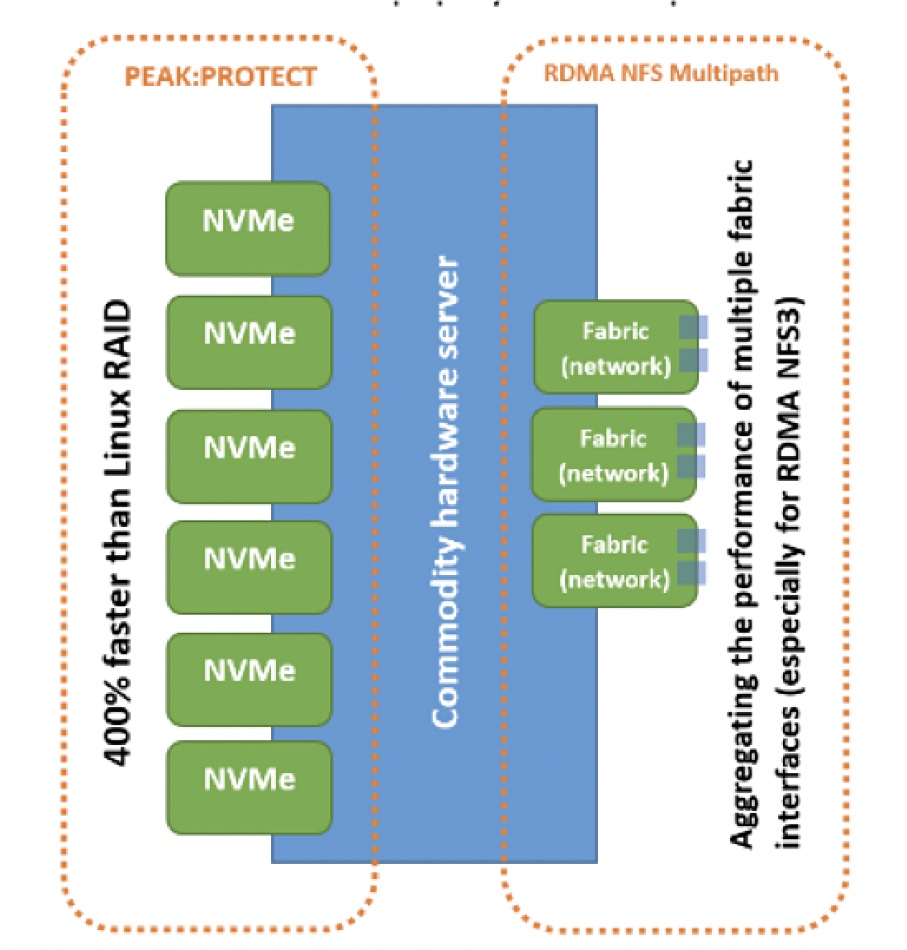
UK startup PEAK:AIO has rewrittten some of the NFS stack and LInux RAID code to get a small 1RU server with a PCIe 5 bus sending 80GB/sec of data to a single GPU client server for AI processing.
Three cheap servers doing this would send 240GB/sec to the GPU server, faster than high-end storage arrays using GPUDirect which pump data to an Nvidia DGX-A100 GPU server at 152 to 191GB/sec. PEAK:AIO provides storage to the AI market and has a user base ranging from startups to world status projects including the UK NHS AI deployment trials. It supports server vendors such as Dell EMC, Supermicro, Gigabyte, and will be distributed by PNY Technologies.
Mark Klarzynski.
PEAK:AIO co-founder and CEO Mark Klarzynski told us: “Storage vendors are not understanding the AI market and its particular use of data.”
He said many high-end GPUDirect-using arrays were not selling – they were too expensive. And he said some suppliers’ case study systems had discounted their kit by more than 90 percent for the case study.
He said AI customers want historical data fed fast and affordably to GPU servers. High-end storage has speed, features and very high prices. Klarzynski said GPU servers could cost $200,000, with storage array suppliers proposing arrays costing a million bucks. That storage is disproportionate in price.
These AI-using customers dont need high-end storage array services like deduplication, snapshots, Fibre Channel and iSCSI. CTO Eyal Lemberger said: “You don’t need snapshots for versioning in this field.”
Stripping these services out of the arrays wouldn’t make them go that much faster, because their software is inefficient.
You could equip a COTS server with 2x 8-core CPUs, putting out say 4GB/sec, with the same GPUDirect support, RDMA for NFS, a PCIe 5 bus and rewrite parts of the basic NFS and Linux RAID software to turn a 2RU server into a near HPC-class data pump. That’s what PEAK:AIO has done.
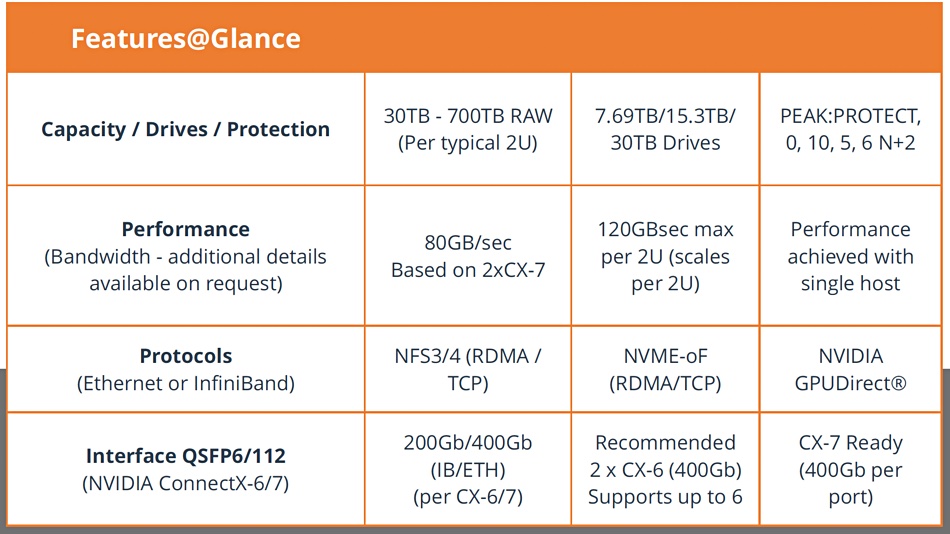
2U Software Defined Storage appliance powered by PeakIO and providing up to 367TB of NVMe over Fabric storage, with the entry-level configuration of 4 SSDs providing over 2 million IOPS, 12GBps random read with less than 90 microseconds latency. The system is scalable up to 24 SSDs, providing more than 23GBps from a single enclosure, and can be extended with additional units.
Most AI-using customers are not storage admins. They don’t want anything complicated and they don’t scale that much. “Ninety percent of GPU servers are in clusters of less than five GPUs. Nvidia SuperPod sales are very low.”
Klarzynski said: “You can start from 50TB and scale to a few hundred terabytes. … We’re not trying to enter the SuperPod world. … AI is less about big data and more about good data. It’s less about super-large CPU clusters and more about smaller clusters of GPU supercomputers. Why would we expect storage designed for the world of big data, HPC or enterprise workloads to work perfectly for the new world of AI?”
The customers don’t want block IO, such as is delivered by NVMeoF, and they are not used to complicated parallel file systems. They need a straightforward file system, basic NFS, as is used by VAST Data. “In fairness, VAST,” Klarzinski said, “got it right.”
PEAK:AIO is a software company. Klarzinski explained: “We’ve rewritten parts of the NFS storage stack and the way it interoperates with GPUDirect. We rewrote Linux’s internal RAID for more performance,” and achieved a 400 percent speed improvement for RAID6 writes and 200 percent for reads.
PEAK:AIO diagram.
The power of PEAK:AIO’s software development is impressive. The latest software release doubled data output speed from 40GB/sec to 80GB/sec.
It developed RDMA Multipath tools for NFS v4, with a kernel focus, and for NFS v3 – its preferred performing version for AI. A test in Dell’s labs confirmed its v1 software’s 40GB/sec number – full wire speed through aggregating multiple links.
PEAK:AIO developed its v1 product last year. Klarzynski is proud of that: “It took off. We sold a fair portion.” He said PEAK:AIO was pretty much self-funded – there is no multi-million dollar VC funding. Now it has v2 software, making it an AI Data Server, and wants to raise its profile.
PEAK:AIO AI Data Server feature list.
A Dell Validated Designs for AI – built in collaboration with PEAK:AIO and Nvidia – delivers an AI Data Server designed for mainstream AI projects, providing realistic capacity levels and ultra-fast performance. It uses Dell PowerEdge servers and Nvidia GPUDirect to create a central pool of shared low-latency NVMe storage.
The latest version of PEAK:AIO’s AI Data Server will be publicly available in Q2. PEAK:AIO systems start at under $8,000 and scale from 50TB to 700TB of NVMe flash per single node. They are currently available to resellers for beta testing.
Bootnote.
PEAK:AIO was founded in 2019 by Mark Klarzynski. He led the evolution of software defined storage (SDS), pioneering the development of an iSCSI, Fibre Channel, and InfiniBand SDS framework (SCST) still used and licensed today by leading storage vendors. He went on to develop the initial all flash storage arrays in partnership with vendors such as FusionIO. For example, he worked on FusionIO’s ION Data Accelerator product.
Pure Storage has built a compressing FPGA to speed deep data reduction in its FlashArrays and so increase their effective capacity.
An FPGA (field programmable gate array) is a semiconductor device built from logic blocks and designed to carry out a set of functions. It is programmed to focus on a particular function, such as compression, and carry it out faster than having the same function performed by software running in a general-purpose CPU. Pure Storage’s all-flash FlashArray storage products use data compression to increase the effective capacity of the array with the idea being they’ll lower the total cost of ownership.
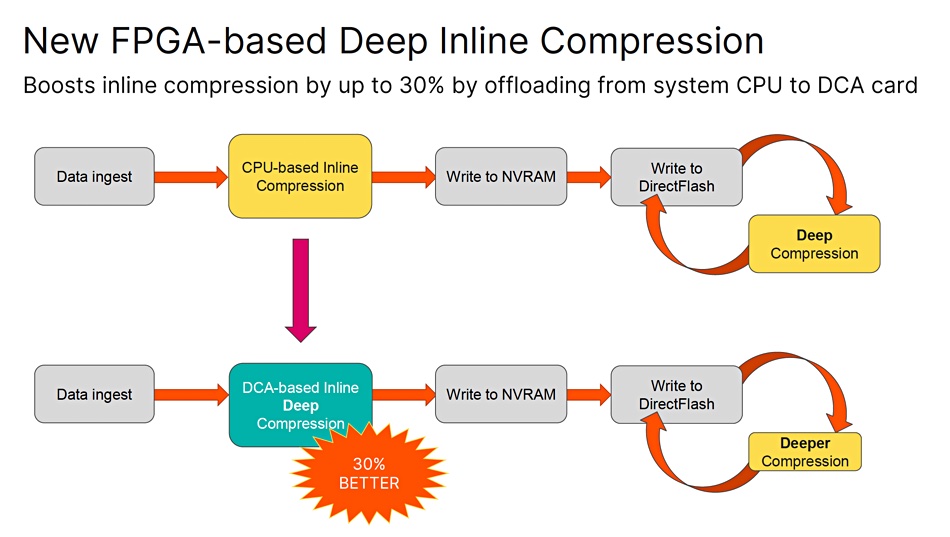
Dan Kogan, VP for FlashArray product management at Pure, said in a briefing that there is a 2-stage compression process: an initial inline run when data is first loaded into the array and before it is written to the flash media, followed by a background deep compression run when the array controllers have idle capacity.
The deep compression routine is run post-data ingress so as not to slow the array controller CPUs down with the deep compression compute load.
Pure DCA compressing FPGA card
By instituting an inline compressing FPGA, called a DCA card, Pure can relieve the array controller processors of the deep compression workload and provide deep compression when data is first loaded with no data ingress rate slowdown. Kogan said that the DCA card improves the inline step of the compression by 30 percent.
Pure’s compression algorithms use variable block sizes with machine learning techniques based on customer data. They auto-detect the data type and use specific routines tailored to the data type.
There will still be a 2-stage compression process, with the initial inline run using the FPGA and a second deeper compression run reducing the data still further when the array controllers have the opportunity to do so.
Pure Storage compression stage diagram before the DCA FPGA and using the FPGA.
The FlashArray//XL will get the new DCA FPGA and customers will not be charged extra for the feature. There is no upgrade capability for existing arrays; this needs to be a green field deployment and all new data that is written is compressed, and then decompressed when read.
All shipping FlashArray//XL systems will be fitted with the new compressing FPGA. The technology may be extensible to Pure’s FlashBlade systems but there are no plans to do this.
Nutanix is investigating the impact of incorrectly using third-party software for customer proof of concepts and more, saying that working out the cost implications of this prevented it from filing audited profit and loss accounts for Q2 of its fiscal 2023.
“Company management discovered that certain evaluation software from one of its third-party providers was instead used for interoperability testing, validation and customer proofs of concept over a multi-year period,” Nutyanix said. “The Audit Committee commenced an investigation into this matter, which is still ongoing, with the assistance of outside counsel. The Company does not believe that this will have a significant impact on the fundamentals of its business and overall prospects.”
The organization is “assessing the financial reporting impact of this matter and it is likely that additional costs would be incurred to address the additional use of the software,” it added.
This perhaps took some of the shine off the 18 percent year-on-year revenue growth to $486.5 million that Nutanix recorded for the quarter ended January 31, beating guidance of $460 – $470 million. This revenue growth outpaced that of NetApp (-5 percent), HPE (12 percent), Pure Storage (14 percent) and Dell’s storage business (7 percent).
Nutanix CEO Rajiv Ramaswami said: ”Against an uncertain macro backdrop, we delivered a solid second quarter, with results that came in ahead of our guidance and saw continued strong performance in our renewables business. The value proposition of our platform is resonating with customers as they look to tightly manage their IT and cloud costs while modernizing their data centers and adopting hybrid multicloud operating models.”
Some customers are repatriating some workloads from the public clouds to their own data centers because the total cost of ownership of these workloads is lower on-premises, the company hinted.
Annual Contract Value (ACV) billings rose 23 percent year-on-year top $267.6 million and annual recurring revenue grew 32 percent to $1.38 billion. Nutanix gained 480 new customers in the quarter, taking its total customer count to 23,620.
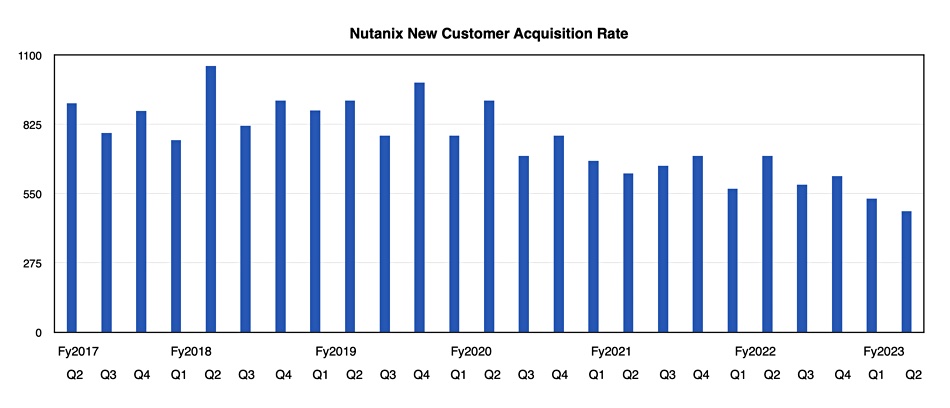
Although the new customer acquisition rate is trending lower (see chart above) customers are spending more money with Nutanix.
Life time bookings:
125 customers with >$10million – up 24 percent
196 customers with $5 – $10 million – up 21 percent
281 customers with $3 – $5 million – up 15 percent
1,411 customers with $1 – $3 million – up 22 percent
Ramaswami said: “We are focusing on higher quality, higher ASP new logos [customers],” more so than picking up as many new customers as possible.
The percentage of customers using Nutanix’ own AHV hypervisor rose to 63 percent, up from 55 percent a year ago and 61 percent in the previous quarter.
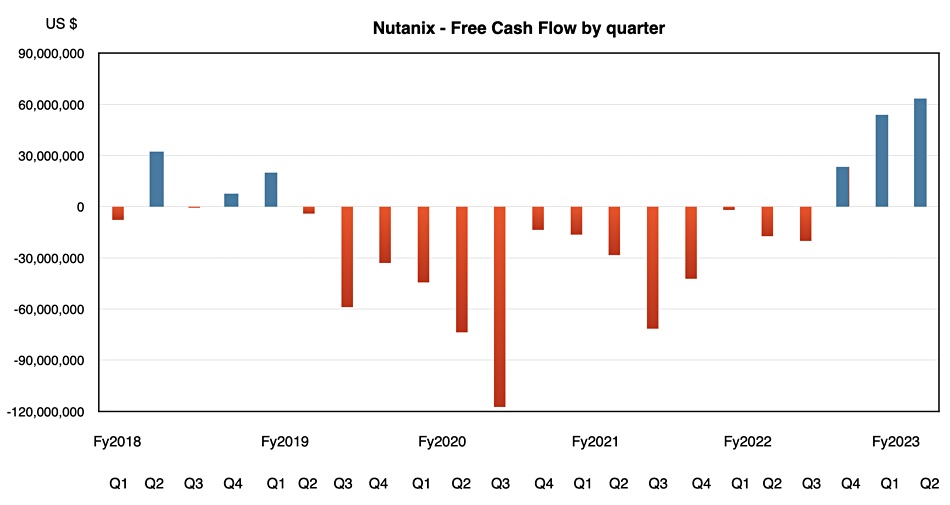
Operating cash flow went up 187 percent to $74.1 million, with $63.0 million of free cash flow equating to a rise of 266 percent. This, Ramaswami said, was due to good expense management. The company’s financial health is improving rapidly.
Nutanix is heading towards profitability.
Ramaswami spoke about priorities in the earnings call: “Our overarching priority remains delivering sustainable profitable growth, through judicious investment in the business, execution on our growing base of renewables and diligent expense management. Our strong free cash flow along with solid top line growth in the second quarter reflects the progress we’ve made to date towards this objective.”
Supply chain constraints with several suppliers improved compared to the prior quarter, and the new worry coming into view is the general economic situation, with Ramaswami saying: “With respect to the macro backdrop, in the second quarter, we continue to see businesses prioritizing their digital transformations and datacenter modernization initiative, enabled by our platform.”
“However, we have seen some increased inspection of deals by customers, which we believe is likely related to the more uncertain macro backdrop. And this is driving a modest elongation in sales cycles.”
These have affected Nutanix’s outlook for the remainder of the fiscal year.
Outlook
Because of the ongoing evaluation software probe, Nutanix will file its formal SEC 10Q quarterly report late. It is possible that expenses will go up and profits will fall in the affected reporting years.
Nutanix said it is expecting between $430 million and $440 million in revenues for the next quarter; $435 million at the mid-point and 7.7 percent year-on-year growth. Full fy2023 guidance is for revenues between $1.80 billion to $1.81 billion, with year-on-year growth of 14 percent at the midpoint.
Broadcom’s VMware acquisition has prompted some VMware customers to look at Nutanix as an alternative but such deals, particularly with larger customers, can take a year to complete. These potential migrations have not been factored into the outlook.