Canadian data protector Asigra is launching a SaaS app backup product with an SDK for developers to write connector modules and marketplace for customers to buy them. HYCU has competition for its third-party SaaS app backup connectors and marketplace.
There are a huge number of SaaS apps and writing connecting code to link backup software to every SaaS app’s APIs is impossible for any single backup supplier. Asigra began working on a scheme to have MSPs and their partners write connectors instead around the end of 2021.
Eric Simmons, Asigra CEO, said in a statement: “IT professionals are coming to understand that the protection of SaaS application data throughout an organization is not only a legal obligation but also vital for protecting reputation and finances. The importance of this cannot be overstated and drives our focus on protecting the entire SaaS application spectrum.”
SaaS adoption is widespread. According to Fortune Business Insights: “The global Software as a Service (SaaS) market size was valued at $215.10 billion in 2021 and is expected to grow from $251.17 in 2022 to $883.34 billion by 2029,” a 19.7 percent CAGR.
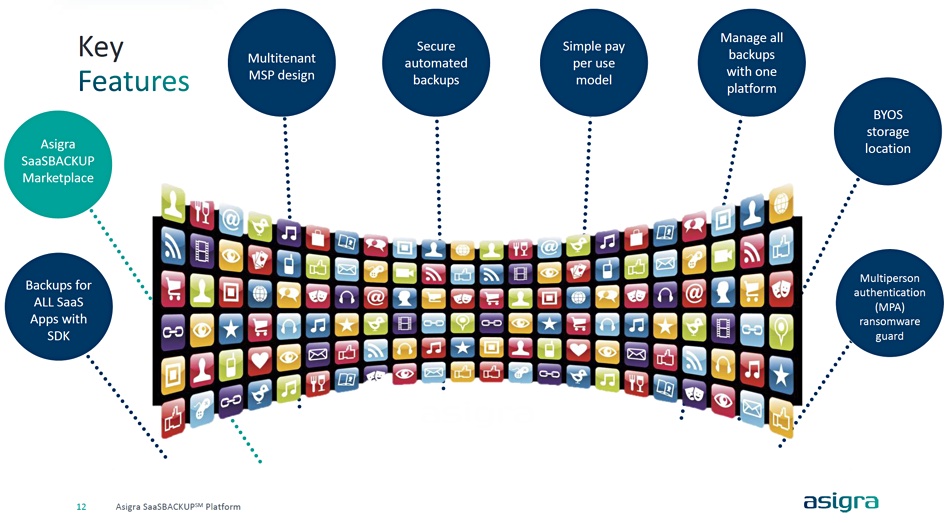
Asigra reckons the average user has nine SaaS apps while the average company uses 137. There should be a single backup facility for SaaS app customer data and Asigra intends its SaaSBACKUP to be exactly that.
Asigra’s software already works with the most popular SaaS apps – M365, Google Workspace and Salesforce. Connectors are needed for the mass of other SaaS apps.
Asigra graphic
The software has an SDK and supports multi-tenancy and AWS, S3-compatible storage, and Wasabi and Backblaze as backup destinations. But it also supports the use of an MSP’s preferred storage backend, either a cloud vault or an on-premises object store, as well. It has a pay-for-use business model and a marketplace for discovering and accessing connectors. Security is helped by having more than one person needed to make backup decisions such as storage vault deletion.
It is partnering with third-party supplier Augmentt so potential customers can discover their SaaS app exposure and manage it.
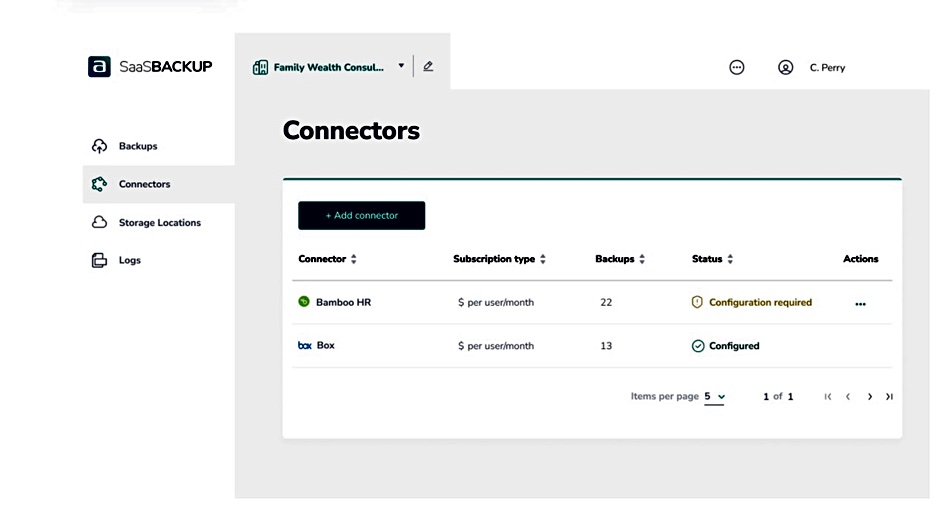
Asigra SaaSBACKUP screenshot
Asigra says SaaSBACKUP software adapts to and protects data in an unlimited number of SaaS environments, and provides mass deployment across hundreds or thousands of SaaS application users simultaneously. New users are automatically detected and included in the backup environment. Users can recover data at any level of granularity, including recovering a single email or a complete email system. When the lost data is identified, restorations are made to a user’s account or alternative location. Data can be protected for as long as required, and encrypted and defended with multi-factor authentication to meet regulatory and compliance mandates.
The SaaSBACKUP beta program will start in May 2023. Managed service providers may register to participate in the program here. Asigra thinks it will announce general availability in North America for MSPs in the third 2023 quarter, and GA for the UK and mainland Europe, VARs and VADs in the fourth quarter. Support for other geographies will come in 2024, along with multi-language facilities and a SaaSBACKUP marketplace for connectors and any other services.
Comment
Both HYCU and Asigra have independently recognized that protection of customer data in the great mass of SaaS apps isn’t always covered by the backup software vendors writing their own connectors. Hence the proposition of having it done by third parties. We think other backup vendors might come to the same conclusion. If they want to enter the general SaaS data protection market, they will have to provide an SDK for their software, motivation for connector writers, a what-SaaS-apps-do-I-use facility, and a marketplace for finding and accessing connectors.
Live data mover WANdisco says that for mass data needing hyperscale compute analysis, users need to move the data to compute in the cloud, and claims normal data gravity rules don’t apply.
WANdisco’s Data Activation Platform technology bridges internet edge environments, datacenters, and multiple public clouds for AI, machine learning and big data analysis. It views its technology as appropriate for constant data movement and not one-off migration products. The company has customers in three main markets: automotive, telco and manufacturing.
Dave Richards
The big trend in the automotive market is connected electric vehicles (EVs) with ADAS (advanced driver assistance systems), which can generate 25GB data an hour when being driven. CEO Dave Richards said in a briefing: “In the edge there isn’t enough compute. You have to go to the cloud and its huge elastic compute.”
Richards blogged: “Edge computing doesn’t allow for the collective analysis of data distributed across many edge datacenters – the type of analysis that could inform product roadmaps or shape new business models.”
An edge datacenter in the automotive market could be one of a hundred datacenters fed with data from ADAS EVs, and local charging networks. You can’t run a machine learning training algorithm across all of them. This data needs analyzing and used for machine learning training globally to get the best results. You have to run ML training across the combined data. That can mean throwing 5,000 or more CPUs at it – and you can’t install them in an edge datacenter.
Richards said the amount of compute you need at the center is so vast that only the hyperscalers can supply it. Only they have this level of burst demand compute capacity available for hire.
The analysis need not be complex, according to Richards: “Basically it’s BigQuery running on an object store.”
What Richards is implying is that, apart from the need to analyze or train using a single massive data set, there is a reversal needed in the bring compute-to-storage argument. This relies on slow data transmission times to say that, in effect, data has gravity, and it is better (easier, faster) to bring compute to the storage rather than the stored data to the compute.
Apart from the situation where real-time decision making is needed at the edge, data can reach such a scale that you can’t bring compute to the edge; too much would be needed. Or it can need aggregating from multiple edge sites for ML training, say, and you can’t analyze at the edge sites in a distributed way; it has to be fed to a single central site.
At a large scale, compute capacity limitations overrule the data gravity argument.
Richards thinks the 200TB/day data level is a rough crossover point. Below that data gravity rules and it’s feasible to process it locally. Above that, then you can find you need hyperscaler-class burst compute for ML training and the data needs to be in the cloud – AWS, Azure or GCP.
WANdisco’s technology can move it up into the cloud constantly, rather than in single massive hits. It can copy the data from an edge site to a cloud, validate that the transfer is complete and then auto-delete the data at the edge, making room for fresh data to come in.
WANdisco marketing VP Chris Pemberton said: “80 percent of the data in automotive is learning data – and it’s sitting at the edge,” where it is of little use.
Charging an EV
Making EV self-driving capabilities more reliable and certain is the big EV ML training activity we all know about. But another ML training application can be used by EV charging network suppliers to calculate how much electricity to supply to an edge charging site. Generate or buy too much and it has to be wasted, while obtaining an insufficient supply means you can’t satisfy the charging demand. In both instances huge amounts of money are involved, either wasted electricity generating capacity or chargers sitting idle because of inadequate electricity supply.
Richards thinks WANdisco will be selling to every power generator in Europe because of factors like this.
In general, he suggests that in the live data movement market WANdisco has no competition: “We have 100 percent market share.”
The analysis and ML environment can vary with vertical markets and WANdisco’s 10-person salesforce is organized by vertical market. It has just hired Thomas Wirtz away from Databricks to be its Director for Automotive and Manufacturing segments.
Richards said: “Ten enterprise sales guys pulled in $127 million in bookings. We think we can get to a billion dollars of bookings with 20 salespeople, and be the most profitable company the world has ever seen.”
With much of its sales activity taking place in the USA, it’s been rumored that WANdisco could be considering adding a US listing alongside its UK AIM market listing. The company has just put out a statement saying: “As a dual UK and US headquartered technology company, WANdisco has long stated its intention to consider an additional listing of its ordinary shares in the United States. The company can confirm that it is in the early stages of proactively exploring this option.”
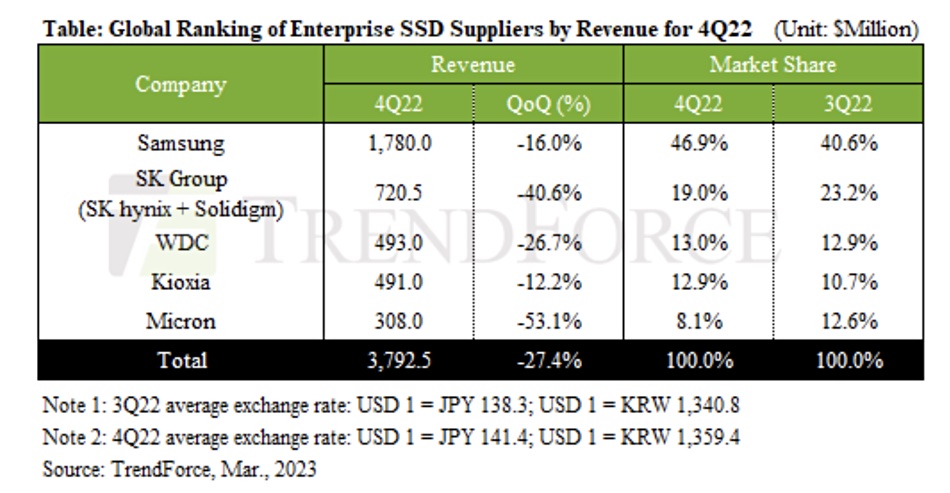
Research house TrendForce has laid bare the SSD market decline in the last 2022 quarter and changes in suppliers’ market shares, with Samsung gaining and SK hynix and Micron losing.
Taiwan-based TrendForce says server OEMs, including ones from China, bought fewer SSDs in the second half of 2022. Despite a need for more SSDs for notebook computers and smartphones, this caused a market contraction in Q4. There was a 25 percent enterprise SSD price decline from Q3 to Q4 2022, and total enterprise SSD revenues in Q4 were $3.79 billion, 27.4 percent lower than in Q3.
TrendForce expects another decline to take place in the current quarter, Q1 2023.
The analyst believes Micron was the worst affected by the market contraction, with a 53.1 percent revenue drop to $308 million and a market share change from 12.6 percent in Q3 to 8.1 percent in Q4, making it the smallest supplier by revenue in the enterprise SSD market. The reason for this, apart from general market conditions, is that Micron makes more SATA enterprise SSDs than the other suppliers and shipments of its 176-layer, PCIe 4.0 product have been weaker than expected, but should rise this quarter.
Number two player SK hynix was the next worse affected, with a 40.6 percent revenue drop from Q3 to its Q4 total of $720.5 million, helping it to lose three points of market share, with a 19 percent portion. It was particularly affected by Chinese buyers purchasing less and a delay in launching new products by Solidigm, say the researchers.
Market leader Samsung saw a 16 percent revenue decline to $1.78 billion but a six-point gain in market share to 46.9 percent. TrendForce says Samsung has a technological need and a rounded product set. It is well placed for the coming PCIe 5.0 SSD market as it has already sent samples of its PCIe 5.0 products to customers for qualification.
Like Micron, it has a high bandwidth memory (HBM) product line so is well positioned for AI and HPC workloads needing faster and more memory bandwidth. The researchers think Samsung is in a stronger position compared with its competitors.
The analyst also pointed out a limitation it sees with Western Digital: “On account of its limited resources for R&D, WDC lags behind its competitors in the launching of PCIe 4.0 enterprise SSDs. Hence, there are some concerns about its ability to expand market share in the future.” Also PCIe 5.0 is coming but “WDC appears to be slightly less prepared for the arrival of PCIe 5.0. In sum, WDC will likely experience more difficulties in maintaining its market share during 2023.”
Kioxia saw the smallest loss of revenue from Q3 to Q4 2022 – 12.2 percent to $491 million. It’s the main supplier of SAS SSDs and “because SAS products have a higher unit price compared with PCIe products, Kioxia was able to somewhat limit the QoQ decline in its revenue despite the lower-than-expected order volume.” Its PCIe 4.0 SSD shipments should rise this quarter and it is marketing PCIe 5.0 product to server ODMs. We’re also told “Kioxia aims to catch up to other suppliers in the race to attain the 23X-L technology by 2024.”
With TrendForce expecting a further enterprise SSD market decline in the current quarter, it is to be hoped that the second and third quarters will see a market recovery.
Huawei made a slew of storage announcements at Mobile World Congress 2023 in Barcelona, including Blu-ray archival storage, the diskless OceanDisk for carriers’ cloud datacenters, ransomware protection and a multi-cloud storage system.
More than 400 telecommunications carriers are on Huawei’s customer list. It says carriers face major challenges as they move to new services such as video, big data, and cloud: mass unstructured data storage, malware attacks and system failures, and using multiple cloud platforms. The four MWC 2023 announcements are being made in response to these three problem areas.
Dr. Peter Zhou, President of Huawei’s IT Product Line, said in his presentation at the event: “We are entering an era of yottabyte data. Data apps are booming. Huawei data storage will fully embrace new cloud-native applications to help carriers build leading data infrastructure in the multi-cloud era.”
The products
Huawei says it is announcing a Blu-ray-based optical disk archiving product as more than 70 percent of carriers’ unstructured data is cold and relatively inactive. This is the OceanStor Pacific 930x series, a software+hardware product with a single cabinet capacity of more than 5PB. There is no datasheet available for this system.
The OceanDisk product is a rebrand of an existing OceanStor Micro line which stores data on NVMe SSD; so it is diskless, despite its name, having no hard disk drive storage. This product decouples storage and compute. It comes in two variants: a 25 x NVMe SSD 1300 and a 36 x NVMe SSD 1500. Both are 2 RU enclosures and have on-board controllers. The palm-sized SSD capacity options are 3.84TB, 7.68TB, and 15.36TB.
OceanStor Micro 1300.
Huawei told us it “uses OceanDisk storage to ensure reliability through large-scale EC and two copies to improve storage space utilization. In addition, the lossless data reduction capability (with a reduction ratio of more than 1.5 times) further improves storage efficiency, helps customers reduce the use of storage servers, and uses OceanDisk as an efficient and shared storage resource pool to obtain on-demand resources, reducing cabinet space and power consumption by 40 percent.
To combat malware, particularly ransomware, Huawei announced an all-domain end-to-end ransomware protection storage offering, delivering double protection for production and backup storage. This storage provides 4-layer data protection policies, ransomware detection, data anti-tamper, an isolation zone through air-gap technology, and end-to-end data breach prevention. Huawei wants to ensure that storage is the last line of defense for data security.
The multi-cloud storage offering supports intelligent cross-cloud data tiering and a unified cross-cloud data view, enabling the free flow of data across clouds. This supports both AWS and the Huawei Cloud. There are settable tiering policies based on hot, warm, and cold data. This system moves cold data to the cloud, but metadata is still stored locally. Data can flow between local storage and the cloud on demand.
This product is so new that, and although there is detailed introduction about multi-cloud storage on Huawei’s website, it is currently only written in Chinese. An English version will be ready in a few months.
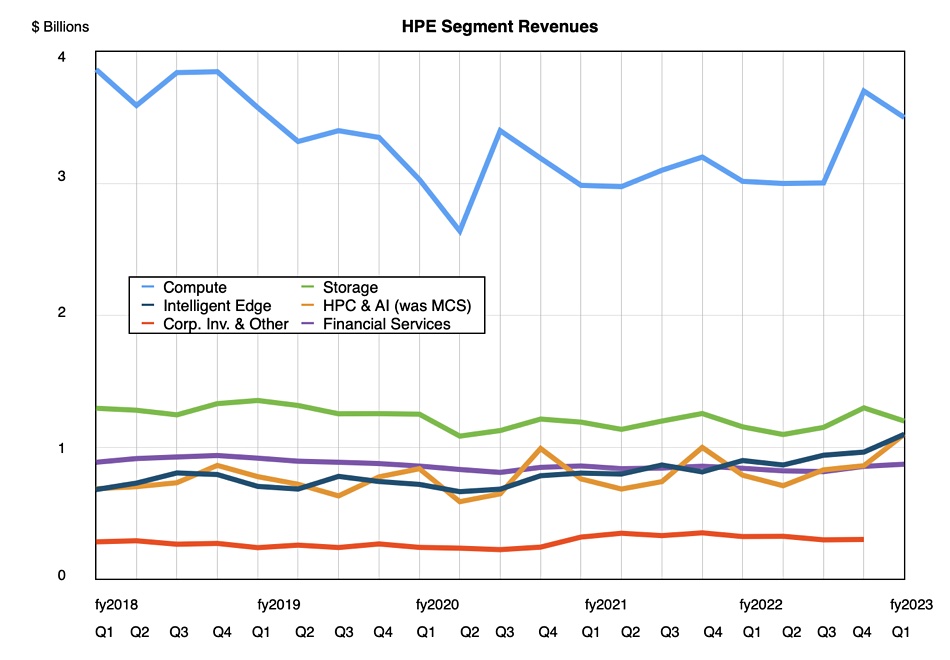
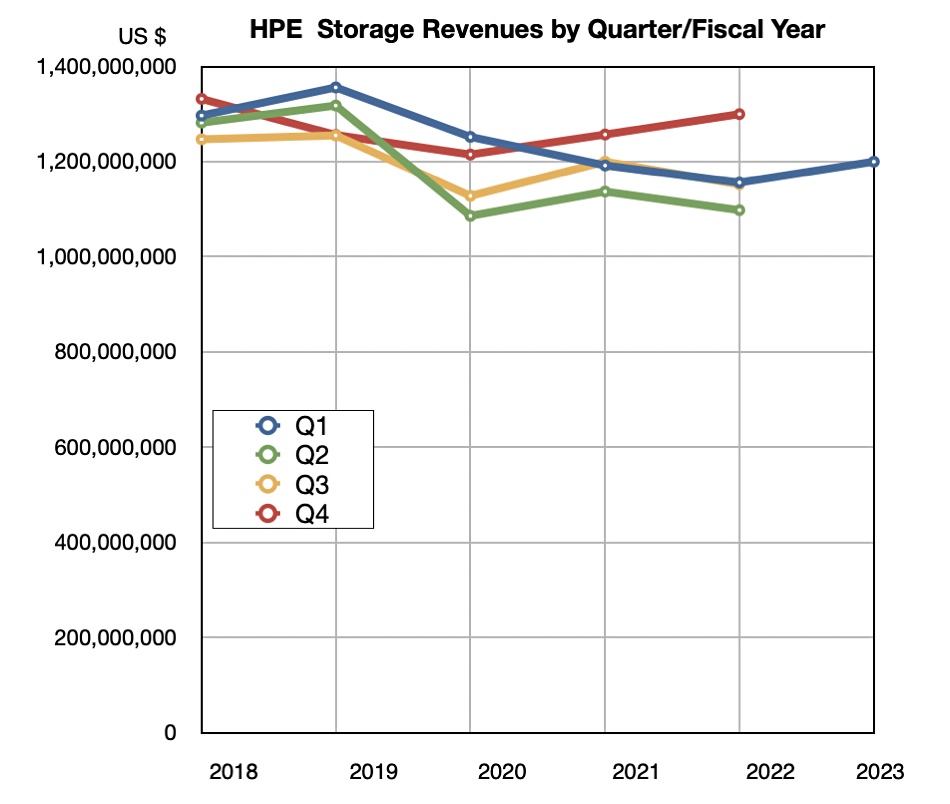
HPE storage contributed to strong first fiscal 2023 quarter results as all business units grew and collectively drove revenues, leading the company to raise its outlook.
Revenues in the quarter ended January 31 were $7.8 billion, a 12 percent increase, beating guidance, with a $501 million profit, slightly less than last year’s $513 million. Compute revenues provided the bulk at $3.5 billion, up 14 percent, with storage bringing in $1.2 billion, 5 percent higher, and the Intelligent Edge (Aruba networking) contributing $1.13 billion, up 25 percent. HPC and AI provided $1.1 billion, a 34 percent rise, helped by a large contract associated with Frontier, the world’s first exascale system.
Antonio Neri
President and CEO Antonio Neri said: “HPE delivered exceptional results in Q1, posting our highest first quarter revenue since 2016 and best-ever non-GAAP operating profit margin. Powered by our market-leading hybrid cloud platform HPE GreenLake, we unlocked an impressive run rate of $1 billion in annualized revenue for the first time. These results, combined with a winning strategy and proven execution, position us well for FY23, and give us confidence to raise our financial outlook for the full year.”
EVP and CFO Tarek Robbiati said: “In Q1 we continued to out-execute our competition, despite uneven market demand, and produced more revenues in every one of our key segments, with our Edge business Aruba being a standout.”
Financial summary
Annual Recurring Revenue: >$1 billion and up 31 percent year/year
Diluted EPS: $0.38 down $0.01 from last year
Operating cash flow: -$800 million
Free cash flow: -$1.3 billion reflecting seasonal working capital needs
Robbiati said in the earnings call: “We expect to generate significant free cash flow in the remainder of fiscal year ’23 and reiterate our guidance of $1.9 billion to $2.1 billion in free cash flow for the full year.”
HPE’s Alletra storage array revenue growth increased well above triple digits from the prior-year, helped by stabilizing supply. That means at least 100 percent; doubled revenue at a minimum. HPE is altering its storage business to focus on higher margin, software-intensive as-a-service revenue. It is continuing to invest in R&D for its own IP.
Neri teased earnings call listeners by saying: “Alletra … is the fastest [growing] product in the history of the company. It has grown triple digits on a consistent basis and you will see more announcements about this platform going forward … It was conceived to be a SaaS-led offer. And that’s why it’s fueling also the recurring revenue as we go forward.
“Our order book at the start of Q1 was larger than it was a year ago. And as we exit that quarter, it is more than twice the size of normalized historical levels.”
The macroeconomic background is having an effect: “Demand for our solutions continue though it is uneven across our portfolio. We also see more elongated sales cycles, specifically in Compute that we have seen in recent quarters.”
Robbiati said: “Deal velocity for Compute has slowed as customers digest the investments of the past two years though demand for our Storage and HPC & AI solutions is holding and demand for our Edge solutions remains healthy.
AI and megatrends
The AI area with Large Language Model (LLM) technology is seen by HPE as an inflexion point it can use to its advantage. Neri said HPE is ”assessing what is the type of business model we can deploy as a part of our as-a-service model by offering what I call a cloud supercomputing IS layer with a platform as-a-service that ultimately developers can develop, train, and deploy these large models at scale.
“We will talk more about that in the subsequent quarters, but we are very well-positioned and we have a very large pipeline of customers.”
An analyst asked why HPE was doing well, mentioning “the contrast in your outlook on storage and compute versus some of your peers.”
Neri said this was due to HPE having a diversified portfolio unlike competitors who “don’t have the breadth and depth of our portfolio. Some of them are just playing compute and storage. Some of them play just in storage. Some of them only play in the networking … We have a unique portfolio, which is incredibly relevant in the megatrends we see in the market.”
The megatrends are around edge, cloud, and AI. They are reshaping the IT industry and HPE offers its portfolio through the GreenLake subscription business: “GreenLake is a winning strategy for us because it’s very hard to do.”
Also, unlike Dell, HPE now has no exposure to the downturned PC market.
The company’s director declared a regular cash dividend of $0.12 per share on the company’s common stock, payable on April 14.
The outlook for the next quarter is for revenue to be in the range of $7.1 billion to $7.5 billion. At the $7.3 billion midpoint that is an 8.7 percent increase on the year-ago Q2. Robbiati commented: “While many tech companies are playing defense with layoffs, we see fiscal year ’23 as an opportunity to accelerate the execution of our strategy.”
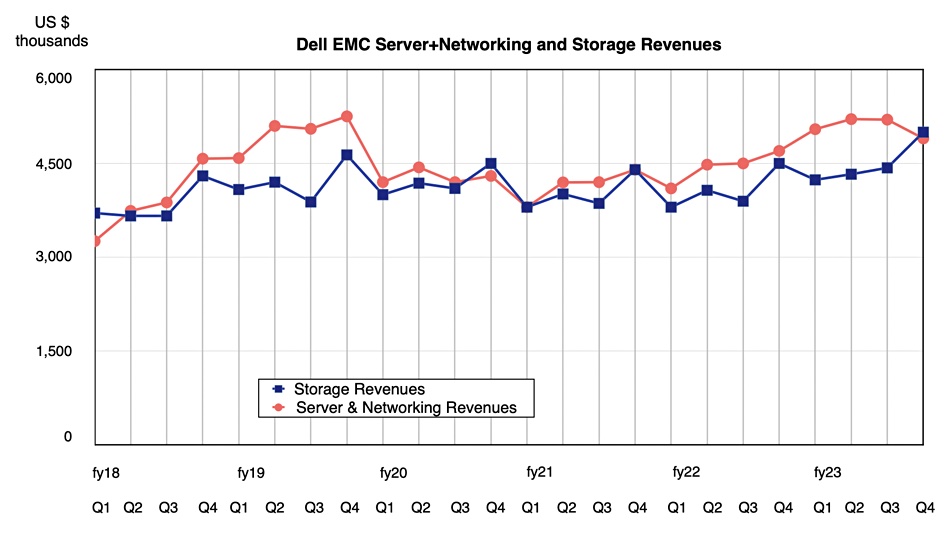
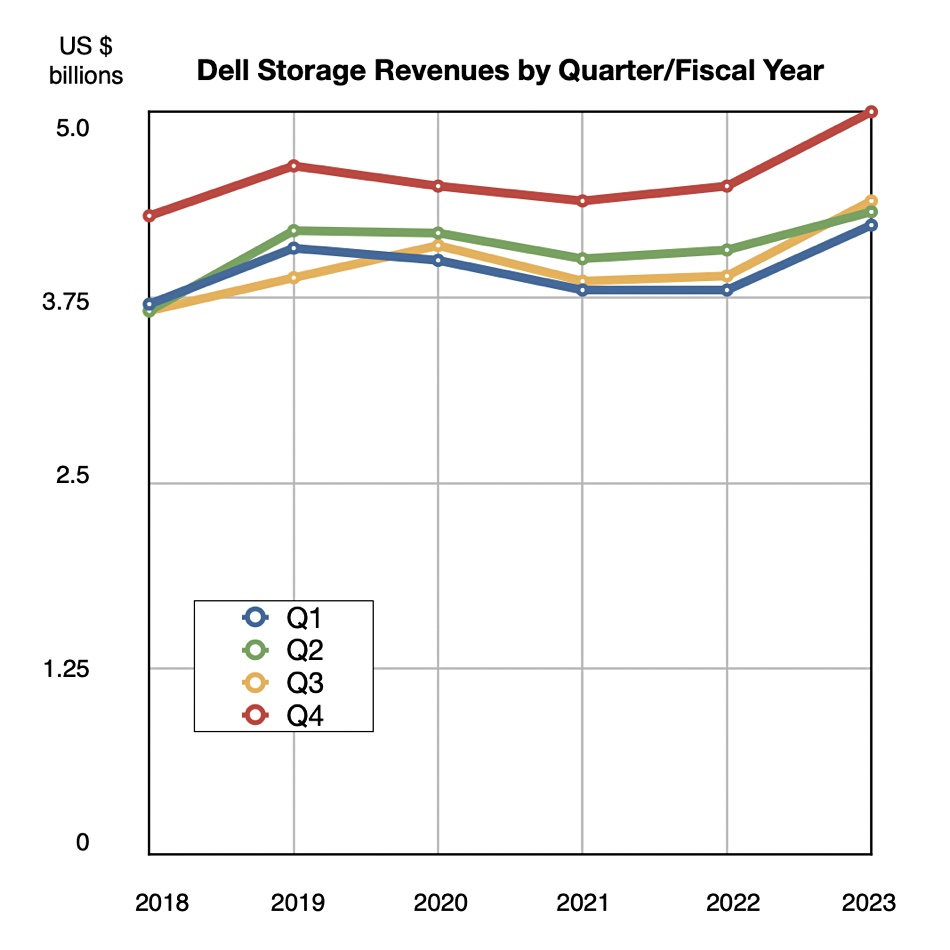
The fourth quarter is always a belter for Dell and its latest results show a record $5 billion in storage revenues.
Total revenues in the quarter ended February 3 were $25.04 billion, 11 per cent down annually due to lower PC sales, but beating Wall Street estimates and Dell’s own guidance. There was a profit of $606 million, an increase on the year-ago $1 million, which was far lower than usual due to VMware dividend and debt repayment issues. Full fiscal 2023 revenues were $102.3 billion, up just 1 percent, with a profit of $2.422 billion, down 56 percent.
Storage is in Dell’s ISG business unit, which recorded Q4 revenues 7 percent higher than last year at $9.9 billion, its eighth consecutive growth quarter. The PC-dominated CSG unit reported in with $13.4 billion revenues, a 26 percent drop on a year ago, as the PC market slowed in June and then fell precipitously in the fourth quarter. Storage revenues, which rose 10 percent annually, pipped the $4.9 billion of server revenues in ISG, 5 percent up year-on-year.
Co-COO Chuck Whitten said in prepared remarks: “We are pleased with our FY23 execution and financial results given the macroeconomic backdrop. FY23 was ultimately a tale of two halves with 12 percent growth in the first half and revenue down 9 percent in the second half as the demand environment weakened over the course of the year.”
He added: “We delivered record FY23 revenue of $102.3B, up 1 percent on the back of 17 percent growth in FY22 … ISG in particular had a strong year with record revenue of $38.4B, including record revenue in both servers and networking and storage, and record operating income of over $5 billion … We expect to gain over a point of share in mainstream server and storage revenue when the IDC calendar results come out later this month. ”
Storage revenues in Dell’s Q4 are consistently higher than in the other quarters
Q4 financial summary
Gross margin: 23 percent
Operating cash flow: $2.7 billion
Diluted EPS: $1.80
Remaining performance obligations: $40 billion
Recurring revenue: c$5.6 billion, up 12 percent year-over-year
Cash and investments: $10.2 billion
The company more than doubled the number of active APEX subscribers over the course of the year.
Dell’s storage results, together with those of Pure Storage, up 14 percent, contrast markedly with NetApp, which has just reported a 5 percent decline in revenues.
Whitten said that in storage, Dell has “gained four points of share in the key midrange portion of the market over the last five years … [There was] demand growth in PowerFlex, VxRail, Data Protection and PowerStore. We are pleased with our momentum in storage – the investments we’ve made over the years strengthening our portfolio are paying off and have allowed us to drive growth and share gain in what was a resilient storage market in 2022.”
The ISG performance looks impressive considering that Dell reacted to the PC market downturn in Q4 with cost controls, an external hiring pause, travel restrictions, lower external spend and layoffs.
Outlook
Whitten said: “Though Q4 was a very good storage demand quarter, we saw lengthening sales cycles and more cautious storage spending with strength in very large customers offset by declines in medium and small business. Given that backdrop, we expect at least the early part of fy24 to remain challenging. In other words PC sales aren’t going to rebound soon and business is cautious about buying IT gear.”
CFO Tom Sweet added: “We expect Q1 revenue to be seasonally lower than average, down sequentially between 17 percent and 21 percent, 19 percent at the mid-point.” That would be $20.3 billion, a 27.5 percent drop on fiscal 2022’s Q1. He expects growth from that low point throughout the rest of fy24.
The full fy24 revenue amount is being guided down between 12 and 18 percent, 15 percent at the midpoint, meaning $86.96 billion.
Reuters reports this tepid outlook sent Dell shares down 3 percent in trading after the results statement was issued.
CFO Tom Sweet is retiring at the end of Q2 2024. Dell says Yvonne McGill, currently corporate controller, will be its new CFO effective the start of Q3 fiscal 2024.
Content delivery player Akamai has agreed to buy Kubernetes storage startup Ondat.
Akamai Technologies has a massively distributed Connected Cloud offering for cloud computing, security, and content delivery. It provides services for developers to build, run, and secure high performance workloads close to where its business users connect online. Akamai is adding core and distributed sites on top of the underlying backbone that powers its existing edge network. This spans more than 4,100 locations across 134 countries. The network megalith aims to place compute, storage, database, and other services close to large population, industry, and IT centers.
Adam Karon, Akamai’s COO and cloud technology group GM, said: “Storage is a key component of cloud computing and Ondat’s technology will enhance Akamai’s storage capabilities, allowing us to offer a fundamentally different approach to cloud that integrates core and distributed computing sites with a massively scaled edge network.”
Ondat’s employees, including founder and CTO Alex Chircop, will join Akamai’s cloud computing business. No acquisition price information was provided.
Ondat recently partnered with CloudCasa, which provides containerized application backup. Sathya Sankaran, founder and GM of CloudCasa, said: “The acquisition of Ondat by Akamai is another indication that Kubernetes is entering the mainstream for enterprises deploying stateful business applications on Kubernetes environments in public clouds.”
In his view: “Ondat fills the distributed storage management gap in the Linode Kubernetes Environment (LKE) for the Akamai Connected Cloud. The best-of-breed CloudCasa and Ondat offering provides Akamai customers with a unified solution to run their stateful applications on Kubernetes without worrying about availability, performance, protection, or data management and recovery. Akamai Connected Cloud customers will now be able to migrate their Kubernetes applications and data from on-premises environments and alternative public clouds to LKE.”
Alex Chircop.
Ondat was founded as StorageOS in 2015 by original CEO Chris Brandon in New York, along with CTO and one-time CEO Alex Chircop and VP Engineering Simon Croome in the UK. It raised $2 million seed funding and then went through an $8 million A-round in 2018 and a $10 million B-round in 2021 – $20 million in total. Brandon resigned to join Amazon in 2019.
The Ondat name was adopted in October 2021. Croome left in November 2021 and later joined the Microsoft Azure storage team. Richard Olver, who joined Ondat as COO in May 2021, became the CEO in September last year, after Ondat went through a layoff exercise in July, under tough business conditions.
Robin.io, another Kubernetes storage startup, was acquired by Japan’s Rakuten Symphony in March 2022. Pure Storage acquired Portworx, a third Kubernetes storage startup, in September 2020.
IBM reckons its customers face three pressing data challenges and is realigning its storage product portfolio to measure up to them.
Update. SVC and Storage Virtualize note added at end of story. 5 March 2023.
The three challengers are adoption of AI/ML and HPC workloads; hybrid cloud app transformation and data movement from edge-to-core-to-cloud; and ensuring data resiliency in the face of malware. The Spectrum brand prefix is being dropped as part of this following a IBM Storage process involving market research, talking to industry heads, and working with customers.
Denis Kennelly
Ahead of publication, IBM gave us sight of a blog written by Denis Kennelly, GM of IBM’s storage division, in which he talks about the effect of this exercise: ”The result was to simplify our offerings by reducing the number of products we promote to a more manageable number with a bias on solution-led conversations that is software-defined, open and consumable as a service. Also, it was important to make it plainly obvious that IBM is very much in the storage business – leading to a decision to drop ‘Spectrum’”’ in favor of what we do incredibly well: ‘Storage’.”
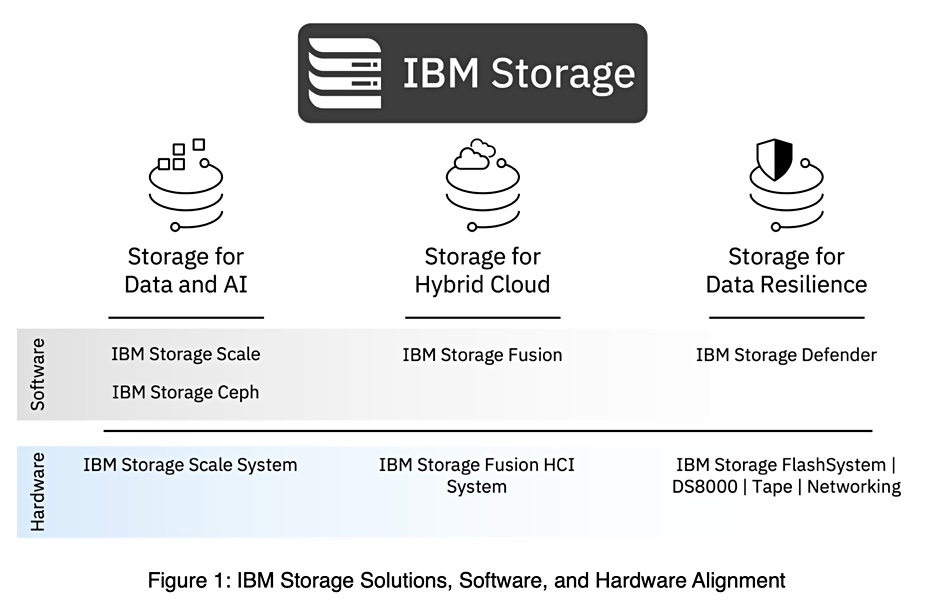
His blog includes a diagram depicting this realignment:
The AI/ML/HPC (Data and AI) market will be presented with IBM Storage Scale (Spectrum Scale as was) and also Storage Ceph, the software that came with IBM’s Red Hat acquisition. Kennelly said: “We are investing in industry-leading open source based Ceph as the foundation for our software defined storage platform.“ Ceph provides block, file and object access protocol support and will be used for general-purpose workloads in this market.
The storage hardware product associated with these two software products is the Storage Scale System, previously called the Elastic Storage System or ESS line.
The hybrid cloud market will have data-orchestrating Storage Fusion software focused on Red Hat OpenShift environments. This enables customers to discover data across the organization, and store, protect, manage, govern, and mobilize it. The software was previously called Spectrum Fusion and combined Spectrum Scale functionality with Spectrum Protect Plus data protection software.
The Storage Fusion HCI System is purpose-built hyperconverged infrastructure for OpenShift with container-native data orchestration and storage services.
Storage Defender
Storage for data resilience relies on new Storage Defender software; a combination of IBM Storage Protect (Spectrum Protect as was), FlashSystem, Storage Fusion and Cohesity’s DataProtect product. This will run with IBM Storage’s DS8000 arrays, tape and networking products.
Storage Defender is designed to use AI and event monitoring across multiple storage platforms through a single pane of glass to help protect organizations’ data layers from risks like ransomware, human error, and sabotage. It has SaaS-based cyber vault and clean room features with automated recovery functions to help companies restore their most recent clean copy of data in, so IBM tells us, in hours or minutes from what used to take days.
The FlashSystem product contributes its Safeguarded Copy for logical air gap facilities.
IBM says Storage Defender is its first offering to bring together multiple IBM and third-party products unifying primary, secondary replication, and backup management. Cohesity provides, IBM says, world-class virtual machine protection managed in the hybrid cloud though a cloud-based control plane supporting a multi-vendor strategy optimized for data recovery.
Storage Defender will, according to IBM’s sales pitch, allow companies to take advantage of their existing IBM investments while significantly simplifying operations and reducing operating expenses. IBM says this is the first of such ecosystem integrations.
Kennelly writes “When we looked at the overall market, we were impressed by the Cohesity platform and team’s differentiated focus on scalability, simplicity, and security. By integrating our leading software-defined technologies, I am excited to bring essential cyber resiliency capabilities to IBM clients. Cyberattacks are on the rise, but data can be protected and restored when you are prepared.”
IBM plans to make the Storage Defender offering available in the second quarter of calendar 2023 beginning with Storage Protect and Cohesity DataProtect. Storage Defender will be sold and supported by IBM as well as through authorized IBM Business Partners.
Comment
With this resell deal, Cohesity now has the advantage of IBM’s sales force and channel working in its favor.
The IBM Storage rebranding and realignment exercise apparently means some Spectrum-branded products have been left behind. Spectrum Connect, Spectrum Discover, Spectrum Virtualize (the old SAN Volume Controller or SVC) and Spectrum Virtualize for Public Cloud are examples. But not so. IBM’r Barry Whyte, Principal Storage Technical Specialist and IBM Master Inventor, tells us: “SVC stays SVC, and Virtualize becomes Storage Virtualize but with more of a focus on the FlashSystem branding itself. SVC turns 20 this year and is still going strong at some major accounts.”
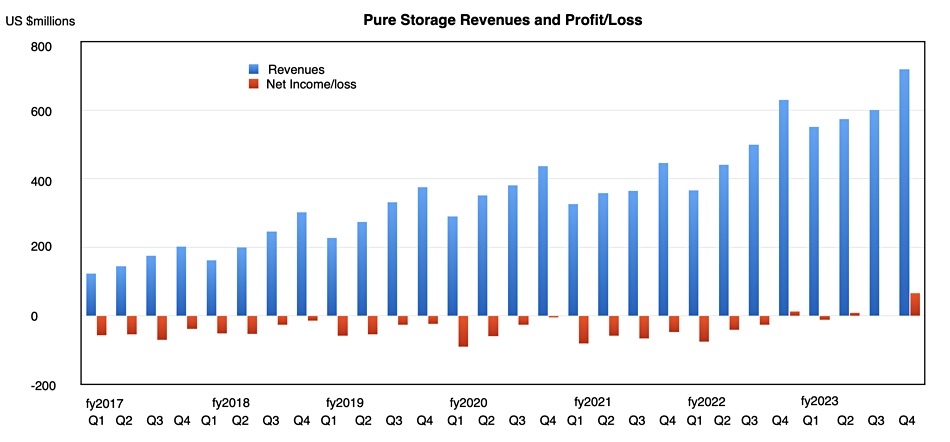
Pure Storage grew Q4 revenues by 14 percent year-on-year, reported its biggest ever profit, and overtook NetApp for all-flash array run rates. Yet Wall Street analysts expected higher revenues and a stronger outlook, so the stock price sank more than 10 percent in trading after the results were posted.
Revenues in the quarter ended February 5 were $810.2 million and net profit was $74.5 million, up from $15 million a year ago. Q4 subscription revenues of $1.1 billion were 30 percent higher.
Full year revenues totaled $2.75 billion, a 26 percent jump, with a profit of $73 million, Pure’s first ever annual profit recorded.
CEO Charlie Giancarlo said in his prepared remarks: “We were pleased with our Q4 year-over-year revenue growth of 14 percent and were very pleased with our annual revenue growth of 26 percent, and annual subscription ARR growth of 30 percent – especially considering the challenges of the steadily increasing global economic slowdown.”
Note the great profits jump in Pure’s latest quarter
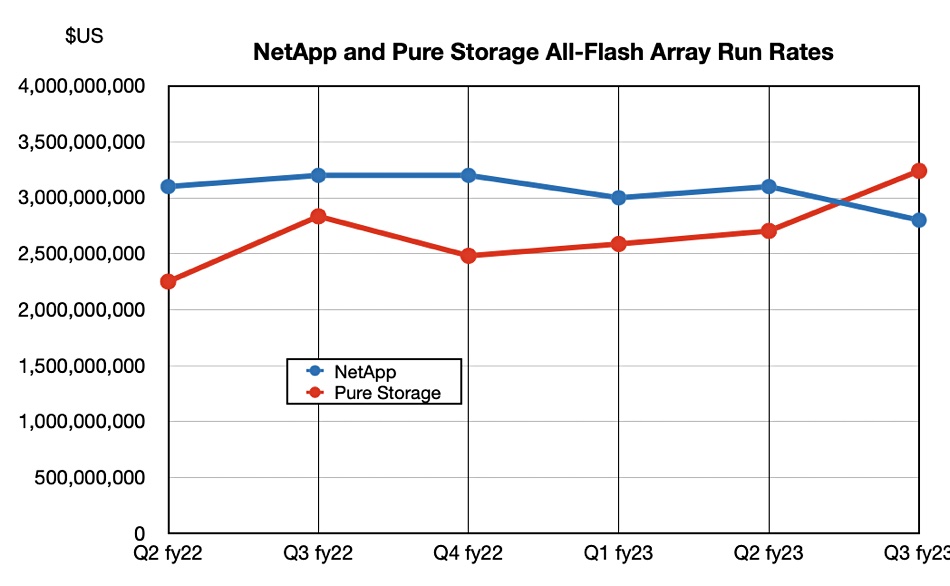
Pure’s revenues grew faster than the market and it also outpaced NetApp in all-flash array revenue run rate, with a 14 percent year-on-year increase to $3.24 billion versus NetApp’s $2.8 billion, down 12 percent annually:
The Pure AFA run rate number includes service revenues, as does NetApp’s. Strict product revenues were $545 million, a $2.2 billion annual run rate.
Pure gained more than 490 new customers in the quarter, taking its total past 11,000. International market revenues grew 39 percent to $258 million while the US could only manage 6 percent growth to $552 million, reflecting customer caution. There was no new business from Meta, which is about halfway through a 1EB Pure system deployment.
Q4 financial summary
Gross margin: 69.3 percent
Operating cash flow: $233 million; up 85 percent
Free cash flow: $172.8 million
Total cash, equivalents and marketable securities: $1.6 billion
Headcount: 5,100
The general economic situation is affecting Pure and Giancarlo said: “We are … well aware of the challenges of the current economic environment and the strains that it places on our customers.”
Pure – like others – is seeing longer sales cycles and customers, particularly enterprise customers, being cautious about large purchases. These, described as near-term headwinds, have affected its growth outlook for the year, which also served to disappoint Wall Street.
To counter this, Giancarlo said: “We have already taken actions to reduce spending across the company and have reduced our spending and budgetary growth plans for FY 24 until we see improvements in the environment.”
Pure is emphasizing electricity and operational savings in its sales messages and suggesting customers could save cost by moving from disk or hybrid arrays to Pure’s flash gear. Giancarlo referred to this: “We’re … changing the way our sales teams go about working with the customer on evaluating our products [with] a much greater focus on near-term operational costs as a justification for making the choice to proceed forward with a project versus maybe other projects that they have in their consideration.
“Pure’s Flash-optimized systems generally use between two and five times less power than competitive SSD-based systems, and between five to ten times less power than the hard disk systems we replace. Simple math then shows that replacing that 80 percent of hard disk storage in data centers with Pure’s flash-based storage can reduce total data center power utilization by approximately 20 percent. ”
Step forward the new FlashBlade//E as Pure’s disk array-killing standard bearer, released this week. Giancarlo said: “While our development of FlashBlade//E was not done in anticipation of a recession, it couldn’t come at a better time. It’s operating costs [are] well below the operating cost of a hard disk environment that it will be replacing … FlashBlade//E, I think, is going to be a barn burner.”
Outlook
CFO Kevan Krysler said: “We expect that Q1 revenue this year will be flat at $560 million when compared to Q1 of last year.“ This bleak outlook surprised analysts and investors who had been expecting $681.4 million, according to Wells Fargo’s Aaron Rakers.
Giancarlo answered a question about this in the earnings call, saying there “was a slowing down of progression of the pipeline of the staged opportunities, meaning the progression that we had typically seen in earlier quarters of movement from early stage to later stage… That has slowed down since the beginning of the year. And we have to assume that, that will be true for at least a couple of quarters going forward. And so that’s changed the outlook … for the year as we go forward.”
Krysler expects things to improve later in the year and full FY 24 guidance is for mid to high single digit year-on-year percentage growth, with no Meta sales included. Wall Street analysts had expected 13-14 percent growth, hence the 10 percent stock price drop.
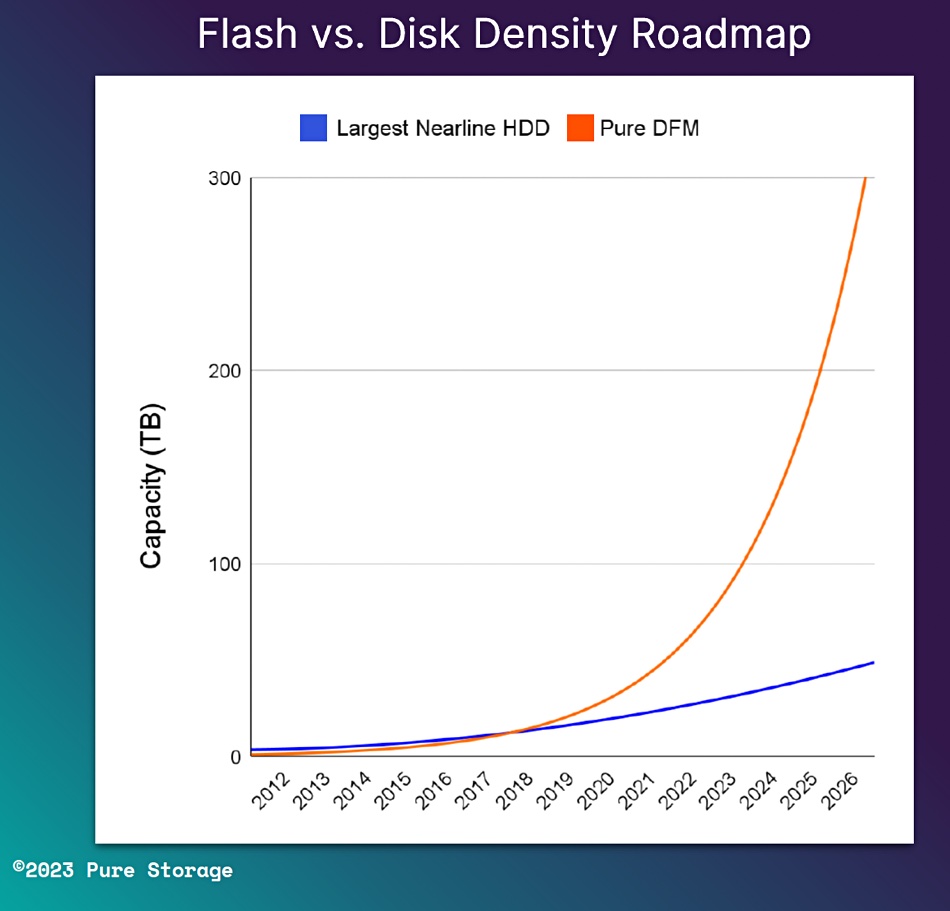
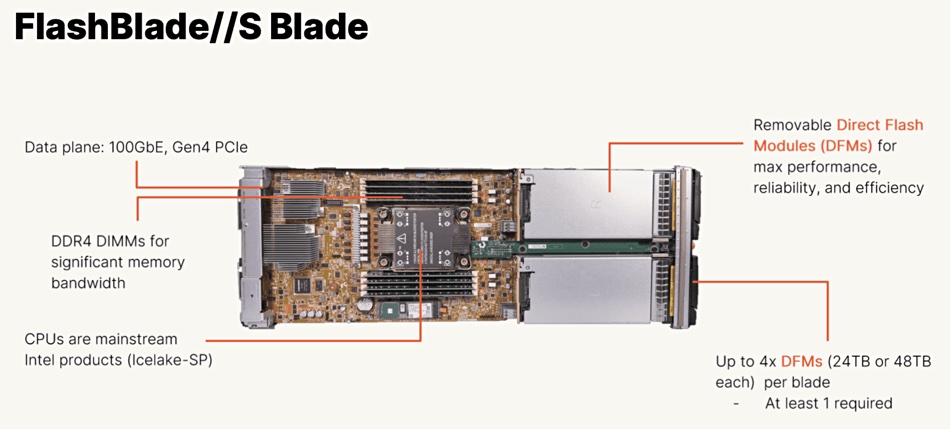
Pure Storage says it will build a 300TB flash drive by 2026. The company manufactures its own SSDs, called Direct Flash Modules (DFMs), which are basically a collection of NAND chips with Pure’s FlashArray and FlashBlade operating system, Purity, providing system-wide flash controller functions. The FlashBlade//S and //E systems use either 24 or 48TB DFMs.
Pure CTO Alex McMullan briefed Blocks & Files and presented a chart showing Pure’s DFM capacity expansion roadmap out to a 300TB module:
He said: “The plan for us over the next couple of years is to take our hard drive competitive posture into a whole new space. Today we’re shipping 24 and 48TB drives. You can expect … a number of announcements from us at our Accelerate conference around larger and larger drive sizes with our stated ambition here to have 300TB drive capabilities, by or before 2026.”
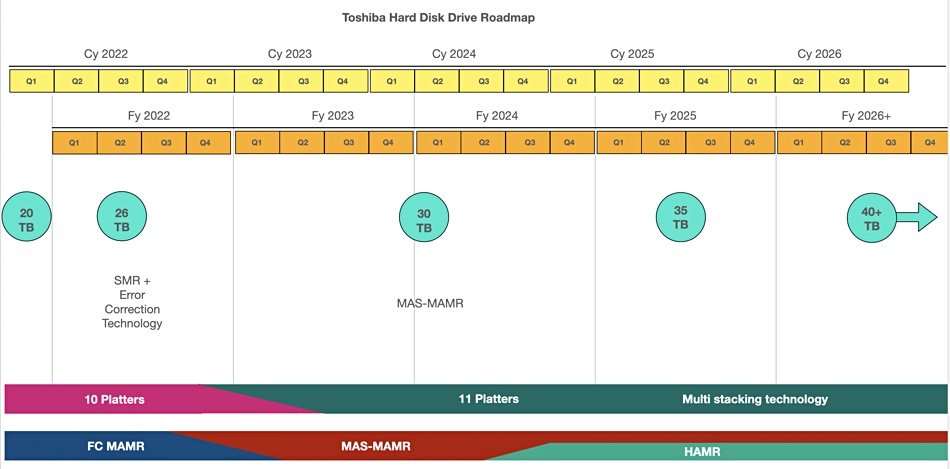
This far outstrips other disk drive capacity roadmaps. For example, Toshiba sees its MAS-MAMR and HAMR technology taking it to 40TB in 2026:
Seagate has said its HAMR tech should enable a 50TB HAMR drive in its fiscal 2025 and a 100TB drive “at least by 2030.” Pure Storage will have a 5 to 6x capacity per drive advantage by then if its engineers can deliver the DFM goods.
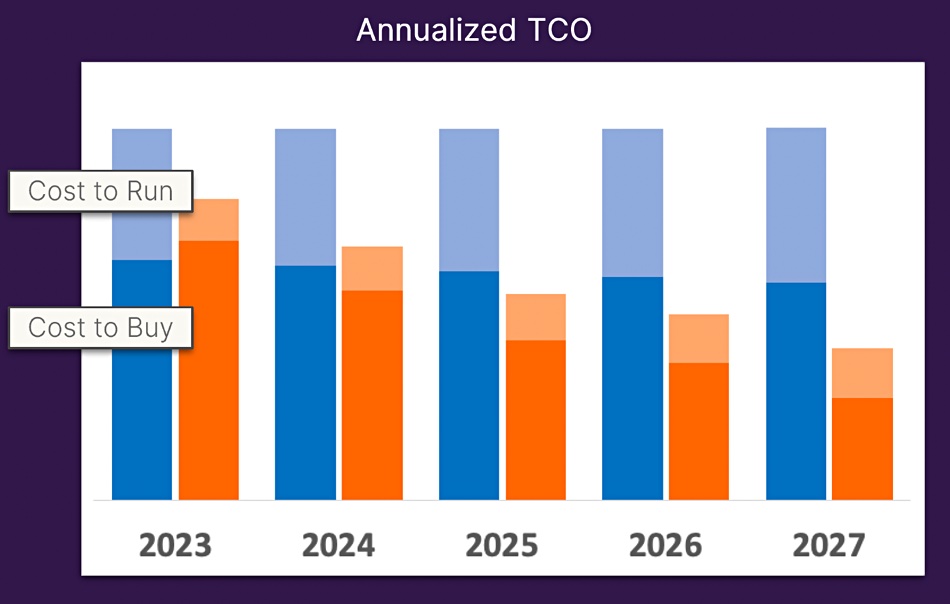
McMullan also showed a chart depicting better and steadily declining TCO vs HDD systems between now and 2026:
A FlashBlade chassis can hold 10 blades. Each blade can be fitted with up to four DFMs. A 10-blade x 4 x 300TB DFM FlashBlade//E chassis would have 12PB of raw capacity, compared to today’s FlashBlade//E’s 1.92PB. McMullan said: “For customers … this opens up a whole new suite of capabilities. So we admire the persistence of hard drive vendors, but I don’t realistically think that they have a plan or a strategic goal [that matches this].”
McMullan said there could be intermediate drive sizes in between todays’ 48TB and 2026’s 300TB DFMs.
How will Pure get to a 300TB DFM? McMullan again: “All the chip fabs are shipping us somewhere between 112 and 160 layers. All the fab vendors have a plan and a path to get to 400-500 layers over the next five years. And the whole point of that will help us of course, on its own.”
Comment
That’s well and good but five years takes us to 2028, two years after McMullan’s 2026 and 300TB DFMs. That means 3D NAND layer count increases won’t get Pure to a 300TB DFM by 2026 on their own.
A 300-layer 3D NAND chip, double today’s 150 or so layers, might make a 100TB DFM possible but in our thinking there needs to be some other capacity booster, such as increasing the physical size of the DFMs so they can hold more chips.
You could fit physically larger DFMs on a FlashBlade if the compute and DRAM components were removed, as is the case with FlashBlade//S storage-only EX blades:
A longer DFM with 2.5x more capacity would be 120TB using today’s QLC 150-160 layer chips. Double that to a 300-plus layer chip and we’d be looking at a 240TB DFM, still 60TB short.
PLC (5bits/cell) NAND would add another 20 percent – 288TB, 12TB short – but, at this point, we are in the right area. Our best estimate is that Pure is relying on increased NAND chip count in physically larger DFMs, with chips built from more layers, and using PLC formatting to get to the 300TB level.
Rajiev Rajavasireddy, Pure’s FlashBlade VP Product Management, said: “PLC is a work in progress. This is why we have R&D on our hardware platforms. Yes, we have more than one way to skin that cat.”
Pure Storage says it has a new FlashBlade//E product optimized for capacity, designed to replace mainstream disk-based file and object stores with an acquisition price comparable to disk-based systems, and lower long-term cost of ownership, costing less than 20 cents per GB with three years’ support.
Amy Fowler
The FlashBlade//E has evolved from the existing FlashBlade//S and adds storage-only blades to the existing compute+storage blades, thus expanding capacity and lowering cost. Pure says it uses up to 5x less power than the disk arrays it is meant to replace and has 10-20x more reliability.
Amy Fowler, FlashBlade VP and GM, said: “With FlashBlade//E, we’re realizing our founders’ original vision of the all-flash datacenter. For workloads where flash was once price-prohibitive, we are thrilled to provide customers the major benefits Pure delivers at a TCO lower than disk.”
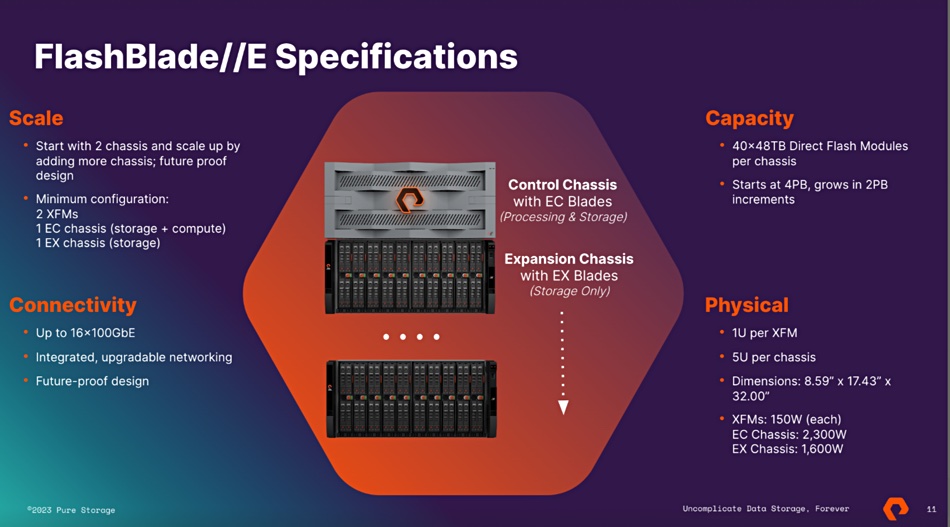
FlashBlade//E
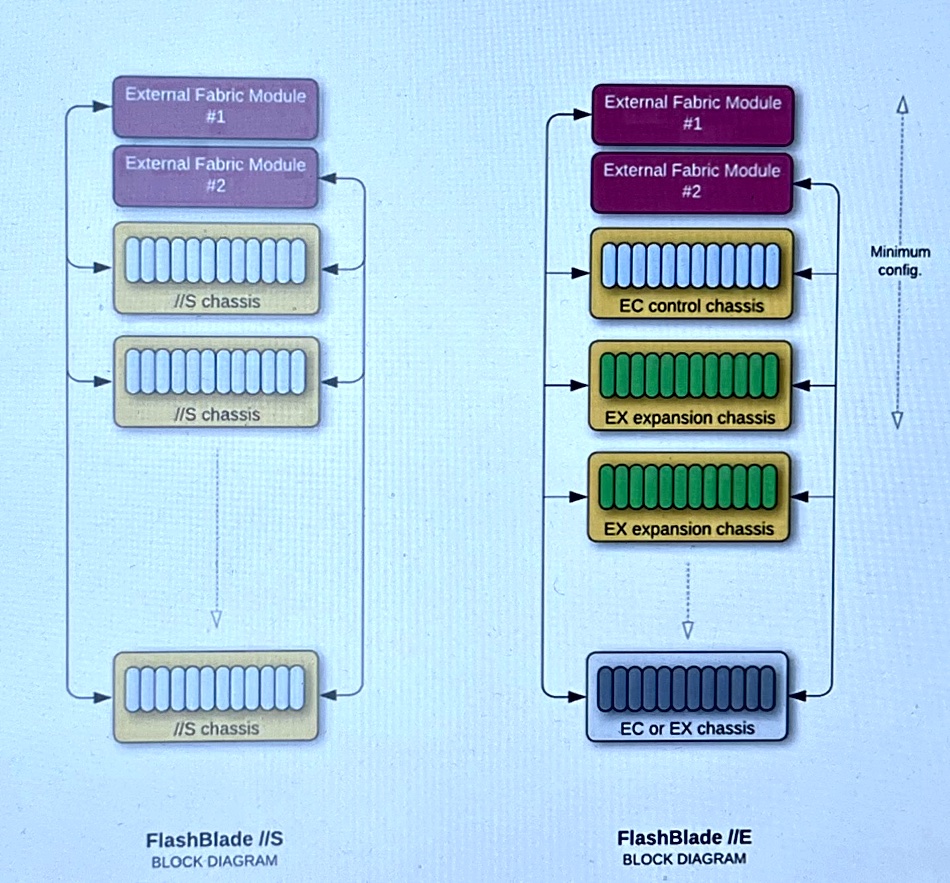
FlashBlade//E starts with 4PB of capacity, using Pure’s 48TB Direct Flash Modules (DFM) and scales up in 2PB increments. For context, note that FlashBlade//S is for high-performance access to file+object data, with the S500 providing the fastest access and S200 providing slower access. Both can scale out to 10 chassis, meaning a max capacity of 19.2PB (10 chassis x 10 blade x 4 x 48TB DFM.)
The system starts with a head node, a 5RU EC control chassis with 10 compute+storage blades. Each holds a CPU with DDR4 DRAM DIMMs plus two or four 48TB QLC (4bits/cell) DFMs accessed via NVMe across a PCIe gen 4 bus. The Purity//FB OS runs the system. There will be two 1RU external fabric modules (XFM) to network blade chassis together.
FlashBlade//E with EC head node on top and EX storage node below
There can be one or more EX expansion chassis, each with 10 storage blades, again fitted with two or four DFMs. There can be a maximum of 10 chassis in a cluster but this will contain more than 1 head node.
FlashBlade//E storage chassis showing blades
Customers tell a sizing tool how much capacity they need and it returns a configuration with an appropriate head-node/expansion storage chassis ratio. Pure’s Rajiev Rajavasireddy, VP Product Management, told B&F: “We give them a configuration that says, for this capacity, here’s the combination [of CPU and storage] that you’re going to need … We determine what that ratio is going to be for optimal performance as well as the capacity.”
Pure FlashBlade expansion differences between //S and //E models
He added: “What we’re effectively doing with E is we are actually increasing the amount of the storage each compute node actually manages, relative to the FlashBlade that somebody had … But there are limits beyond which it becomes counterproductive. The architecture is such that we can actually add more compute nodes as needed.”
FlashBlade//E DFMs cannot be used in //S systems.
Here’s the power draw picture;
The Control Chassis with EC Blades consumes 2,300W
The Expansion Chassis with EX Blades consumes 1,600W
The two XFMs: 150W each
For a starting configuration of FlashBlade//E it’s about 1.06 W/TB, and for every expansion node with EX blades, 0.83 W/TB.
Performance
Rajavasireddy said: “Our performance is going to be just as good or even better than disk and disk hybrid system that we’re targeting. If you think about performance you have sequential throughput, you have random IO, you have large files, small files, and metadata.
“For sequential data, so for large files and sequential throughput, these disk-based systems are reasonably good because the heads are not seeking too much, they’re just running with the head in one position, for the most part. Our sequential throughput is going to be just as good or better.”
He said FlashBlade//E will do better than disk-based arrays with small files, random IO and metadata.
IO performance
IO access to these systems will be across faster versions of Ethernet, with 100 gigE today moving to 200 and then 400 gigE. PCie 4 can be expected to advance to PCIe 5. CTO Alex McMullan said: “We have no concerns on that side of things. We already have the engineering plan laid out in terms of network, in terms of PCIe links, to make sure that that is not a concern for us.”
These systems will have to be more reliable than today’s. McMullan said: “If you’re effectively collapsing five or 10 physical systems into one FlashBlade, it also has to drive up reliability in exactly the same way. And a big part of this for us has been about observability. It’s been about exporting a lot more metrics into things like [Pure analytics application] Prometheus for customers to be able to see, but also for us to monitor.”
Green flashand gunning for disk
The //E is more power-efficient than //S FlashBlade systems, drawing <1W/TB. McMullan told us: “We’re holding to the same power budget for drives as they get bigger and bigger, which nobody else can claim at this point in time … We’ll be getting below one watt per terabyte very quickly in the next few months. And our plan is to get into a discussion where it’s milliwatts per terabyte over the next two years.” In general, Pure says it’s delivering green flash at the price of disk.
It’s also better in e-waste terms as organizations tend to shred and send disk drives to landfill when they are replaced. DFMs don’t produce such e-waste as they can be recycled, Pure says.
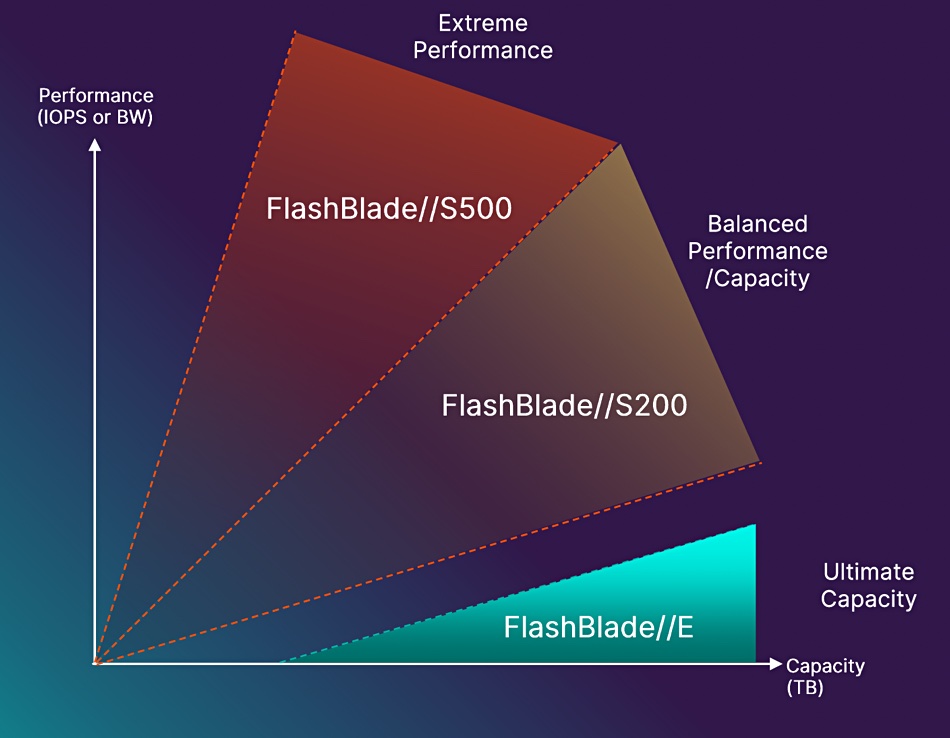
Rajavasireddy told us: “With this FlashBlade//E we are targeting that volume of data that is currently running on disk and disk hybrid systems … We feel we finally have something that can go straight at the disk-based high capacity storage market.” A positioning diagram shows it in a 2D space defined by performance and capacity axes relative to FlashBlade//S:
Pure’s diagram deliberately shows no overlap between the FlashBlade//S200 and the FlashBlade//E systems
Pure sums this up by claiming that, compared to HDD alternative systems, FlashBlade//E needs a fifth of the power, a fifth of the space, is 10-20x more reliable, has 60 percent lower operational cost and generates 85 percent less e-waste.
It is basically saying it’s going to invade the hybrid disk array market for mainstream bulk unstructured data that requires reasonably fast access and high capacity for workloads like data lakes, image repository, and video surveillance records – everyday file and object workloads. And it’s going to be doing it with drives that are larger than disk, require less energy than disk, and are more reliable than disk. And that when you throw them away, you don’t need a landfill site to hold the disk drive shreds.
Pure really does believe it can blow disk drive unstructured data arrays out of the water with FlashBlade//E. The system will be generally available by the end of April 2023 and can be supplied as a new service tier in Pure’s Evergreen//One Storage as-a-tier (STaaS) subscription.
The Standards Council of Canada has approved an IT-related standard which would eliminate new data silos and copies when organizations adopt or build new applications, thus apparently preventing any data copies being made with new applications. However, last-time integration could bring in legacy data via copies.
It states: “The organization shall avoid creation of application-specific data silos when adding new applications and application functionality. The organization shall adopt a shared data architecture enabling multiple applications to collaborate on a single shared copy of data. The organization should continue to support the use of application-specific data schema without the need to generate application-specific data copies.”
The DCG told us: “The CIO Strategy Council Technical Committee 1 on Data Governance comprises policy makers, regulators, business executives, academics, civil society representatives and experts in data management, privacy and related subjects from coast-to-coast-to-coast.”
Keith Jansa, Digital Governance Council CEO, issued a statement saying: “By eliminating silos and copies from new digital solutions, Zero-Copy Integration offers great potential in public health, social research, open banking, and sustainability. These are among the many areas in which essential collaboration has been constrained by the lack of meaningful control associated with traditional approaches to data sharing.”
The problems the standard is meant to fix center on data ownership and control, and compliance with data protection regulations such as California’s Consumer Privacy Act and the EU’s General Data Protection Regulation (GDPR). The creation of data copies, supporters of the standard say, transfers data control away from the original owners of the data.
Dan DeMers, CEO of dataware company Cinchy and Technical Committee member for the standard, said: “With Zero-Copy Integration, organizations can achieve a powerful combination of digital outcomes that have always been elusive: meaningful control for data owners, accelerated delivery times for developers, and simplified data compliance for organizations. And, of course, this is just the beginning – we believe this opens the door to far greater innovation in many other areas.”
DGC says viable projects for Zero-Copy Integration include the development of new applications, predictive analytics, digital twins, customer 360 views, AI/ML operationalization, and workflow automations as well as legacy system modernization and SaaS application enrichment. It is developing plans for the advancement of Zero-Copy Integration within international standards organizations.
Implications
We talked to several suppliers, whose products and services currently involve making data copies, about the implications for them.
WANdisco’s CTO Paul Scott Murphy told us: “At first glance, the standard may appear to push against data movement, but in fact, it supports our core technology architecture. Our data activation platform works to move data that would otherwise be siloed in distributed environments, like the edge, and aggregates it in the cloud to prevent application-specific copies from proliferating.
“Our technology eliminates the need for application-specific data management and ensures it can be held as a single physical copy, regardless of scale.”
He added: “Notably, there’s a particularly important aspect of the new guidance on preventing data fragmentation by building access and collaboration into the underlying data architecture. Again, our technology supports this approach, dealing directly with data in a single, physical destination (typically a cloud storage service). Our technology does not rely on, require, or provide application-level interfaces.
“In response to the standard, Canadian organizations will need to adopt solutions and architectures that do not require copies of data in distributed locations – even when datasets are massive and generated from dispersed sensor networks, mobile environments, or other complex systems.”
A product and service such as Seagate’s Lyve Mobile depends upon making data copies and physically transporting the copied data to an AWS datacenter or customer’s central site. Both would be impacted for new apps if the Canadian Zero-Copy Initiative was adopted.
A Seagate spokesperson told us: “Seagate is monitoring the development and review of Zero-Copy Integration Standard for Canada by technical committee and does not speculate on potential adoption or outcome at this time.”
What does the standard mean for backup-as-a-service suppliers Clumio or Druva, makers of backup data copies stored in a public cloud’s object store.
W Curtis Preston, Chief Technical Evangelist at Druva, told us: “This is the first I’ve heard of the standard. However, I believe it’s focusing on a different part of IT, meaning the apps themselves. They’re saying if you’re developing a new app you should share the same data, rather than making another copy of the data. The more copies of personal data you have the harder it is to preserve privacy of personal data in that data set. I don’t have any problem with that idea as a concept/standard.
“I don’t see how anyone familiar with basic concepts of IT could object to creating a separate copy of data for backup purposes. That’s an entirely different concept.”
Poojan Kumar, co-founder and CEO of Clumio, told us: “This is an important development; companies are being encouraged to use a single source of truth – such as a data lake – to feed data into apps, analytics platforms, and machine learning models, rather than creating multiple copies and using bespoke copy-data platforms and warehouses.”
He added: “Backup and DR strategies will evolve to focus on protecting the shared data repository (the data lake), rather than individual apps and their copies of data. We have maintained that backups should be designed not as ‘application-specific’ copies, but in a way that powers the overall resilience of the business against ransomware and operational disruptions. This validates our position of backups being a layer of business resilience, and not simply copies.”
DGC view
We have asked the DGC how it would cope with examples above and what it would recommend to the organizations wanting to develop their IT infrastructure in these ways. Dan DeMers told us: “One of the most important concepts within the Zero-Copy Integration framework is the emphasis on data sharing via granting access for engagement on uncopied datasets (collaboration) rather than data sharing via the exchange of copies of those datasets (cooperation).
“But as you point out, many IT ecosystems are entirely reliant upon the exchange of copies, and that is why Zero-Copy Integration focuses on how organizations build and support new digital solutions.”
Legacy apps can contribute, he said. “One capability that is not defined in the standard (but we are seeing in new data management technologies such as dataware) is the ability to connect legacy data sources into a shared, zero-copy data architecture. These connections are bi-directional, enabling the new architecture to be fueled by legacy apps and systems on a ‘last time integration’ (final copy) basis.
“It’s like building the plane while it’s taking off in that sense – you’re using a Zero-Copy data architecture to build new solutions without silos or data integration, but it’s being supplied with some of its data from your existing data ecosystem.
“It’s all about making a transition, not destroying what’s working today, so the scenarios you outlined would not be an issue in its adoption.”