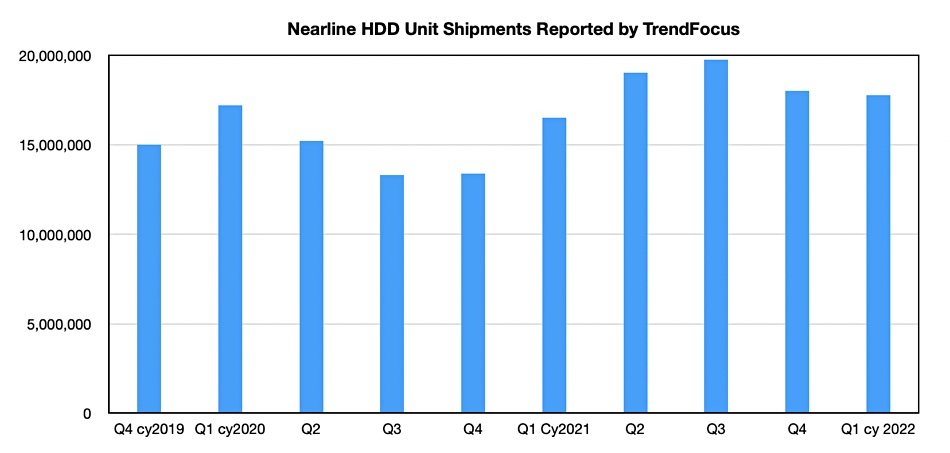
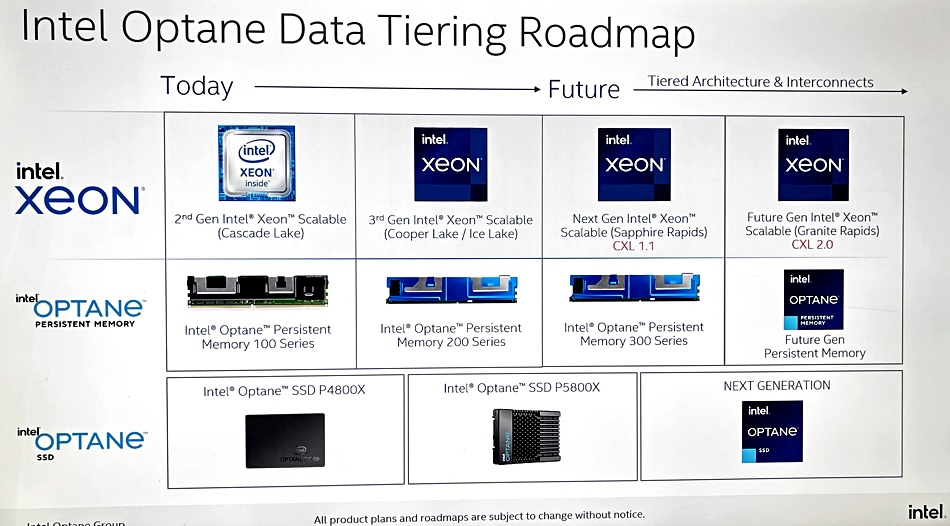
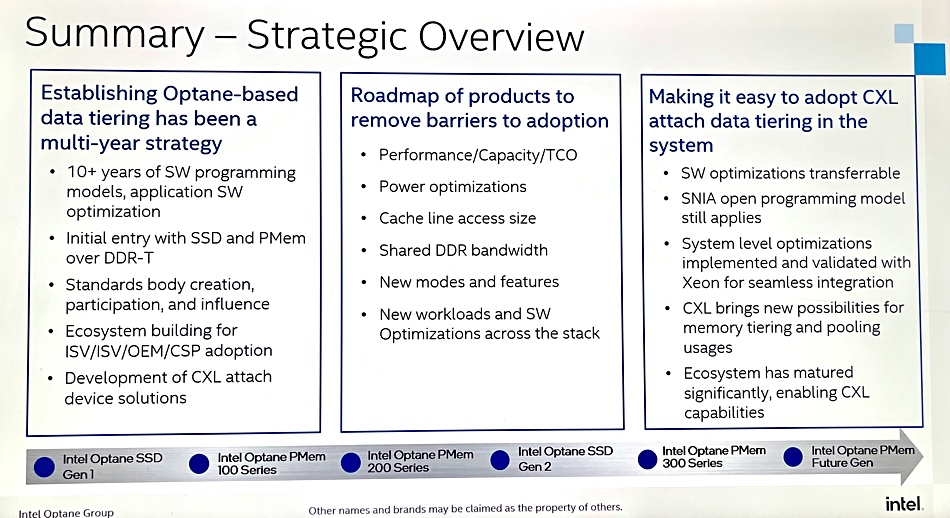
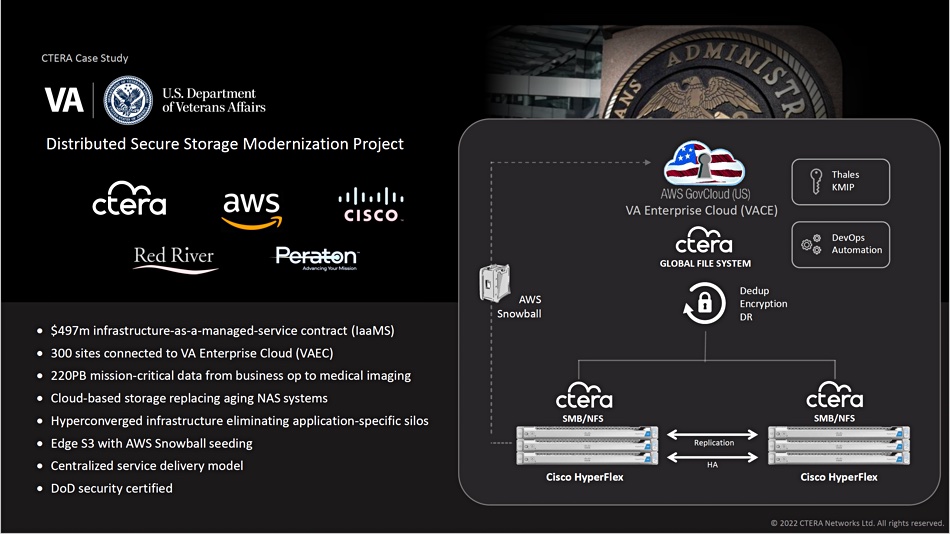
….
In-cloud Saas data protector Clumio announced news of its Clumio Protect for Amazon DynamoDB, with granular recovery, improved audit readiness and reduced TCO for long-term backups. Clumio said it delivers cloud customers a fast setup process, turnkey ransomware protection, one-click recovery of their databases, centralized compliance reporting, and actionable insights to reduce data risks. Clumio Protect for Amazon DynamoDB can backup Amazon DynamoDB tables and items in less than 15 minutes with no upfront sizing, planning, or additional resources needed to setup in AWS accounts, Clumio added. The service will be generally available April 21, 2022.
…
Druva has gained Nutanix Ready certification for its SaaS data protection offering (DataResiliency Cloud) for Nutanix AHV HCI hybrid cloud. It covers protection for Nutanix workloads across data centers, remote offices, and Nutanix Clusters on AWS through a secure, automated, and simplified platform that requires no additional hardware or software. It works across platforms, applications, and geographies. Druva claimed it’s the only SaaS-based offering with support for Nutanix, and includes image-based backups, support for Prism Central and Prism Element, application-consistent snapshots of Nutanix AHV VMs, reduced cost with long-term retention and a CloudCache secondary storage to retain optional local backup copies for up to 30 days for stricter RTO/RPO or industry-specific compliance.
…

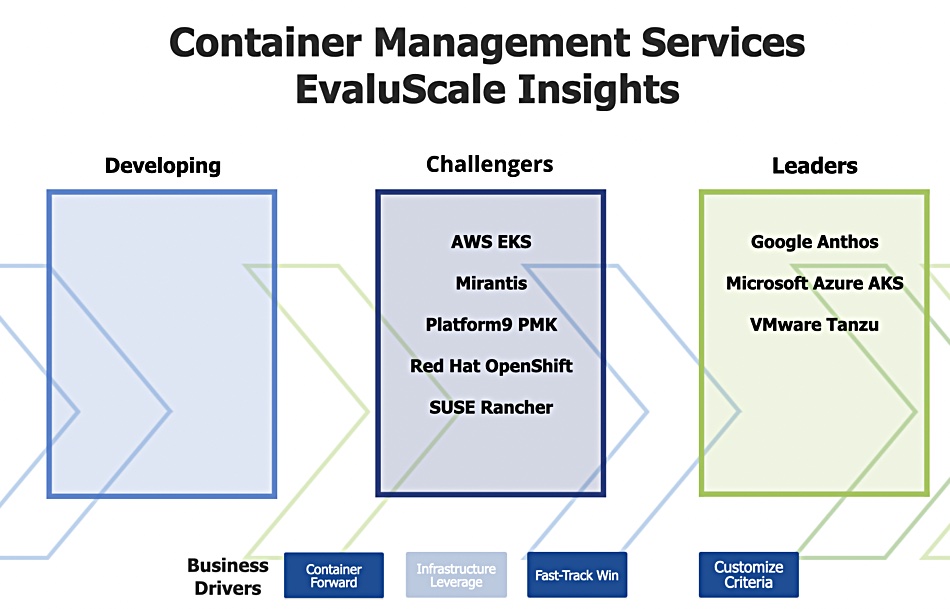
The Evaluator Group has announced its 2022 EvaluScale Insights for Container Management Systems for Platforms and Services. The EvaluScale Insights is based on deep research published by Evaluator Group with technology comparison and selection criteria known as EvaluScale Comparison Matrices. The EvaluScale Insights examines and ranks the vendors as Leaders, Challengers and Developing with a weighting based on the EvaluScale selection criteria and business drivers. The 2022 EvaluScale Insights Leaders: Container Management Platforms Leaders (see diagram above;)
- Container Forward: Red Hat Open Shift, SUSE Rancher and D2IQ
- Infrastructure Leverage: VMware Tanzu
- Fast Track Win: Red Hat Open Shift, Azure Stack and D2IQ
Container Management Service Leaders (see diagram below);
- Container Forward: Google GKE/Anthos Azure AKS, SUSE Rancher, VMware Tanzu
- Infrastructure Leverage: Google GKE/Anthos, Azure AKS, Mirantis, VMware Tanzu
- Fast Track Win: AWS EKS, Google GKE/Anthos, Azure AKS, Red Hat OpenShift, VMware Tanzu
…
An Intel VMD driver for vSphere can be used to create NVMe RAID1 setups. Intel Volume Management Device (VMD) works with the Xeon family of processors to enable additional control and management of NVMe devices. Intel VMD is similar to an HBA controller but for NVMe SSDs. Hot Plug, LED management, and error handling are some of the features available. The Intel-enabled NVMe driver for vSphere now supports RAID 1 volumes for boot and data. There’s more data here.
…
Kioxia KumoScale Software v2.0 is built around the NVM Express over Fabrics (NVMe-oF) protocol and delivers high performance NVMe flash storage as a disaggregated networked service. It includes additional bare metal deployment options, seamless support for OpenID Connect 1.0, and support for NVIDIA Magnum IO GPUDirect Storage (GDS). GDS enables a direct data path for direct memory access (DMA) transfers between GPU memory and storage, which avoids a bounce buffer through the CPU. KumoScale software behaves as a storage adapter to GDS.
OpenID Connect is an identity layer on top of the OAuth 2.0 protocol that allows Clients to verify the identity of users and session based on the authentication performed by an Authorization Server for service account permissions. V2.0 also includes CSI raw block support, and an embedded Grafana storage analytics dashboard.
…
Satori, which provides a Universal Data Access Service for cloud-based data stores and infrastructure, is adding support for three relational databases – MySQL, CockroachDB and MariaDB. Users can now control access to data stored in these databases in a streamlined, secure and non-disruptive way. Yoav Cohen, CTO at Satori, said. “As new choices like CockroachDB and MariaDB see rapid adoption within the enterprise, we also saw the need to meet the growing demand for managing access to sensitive data in these databases while realizing the vision of universal data access. Now Satori customers can hook into these popular services, alongside other leading data platforms including Amazon Redshift and Snowflake, without having to build such capabilities themselves.”
…
Vehera LTD, trading as Storage Made Easy today announced a record year of bookings, growing over 100 per cent year-on-year. This included its highest quarterly bookings ever in the fourth quarter and its largest seven figure sale. Company CEO Jim Liddle said: “During the pandemic we have seen companies shift to use on-cloud object storage in combination with on-cloud or on-site file storage. This shift has meant that companies required a flexible global namespace to enable employees to easily and transparently work with their hybrid file and object data sets wherever they reside.” SME’s File Fabric product meets that need “without any lock-in enabling companies to continue to directly access their data assets and take direct advantage of low cost analytics and other applications offered by large cloud vendors such as Amazon, Microsoft and Google.” The business is owned by Moore Strategic Ventures and did not make public it’s actual financial results.
…
StorPool Storage was listed as the 413th fastest-growing company in Europe as part of Financial Times’ in-depth special report focused on organizations that achieved the highest compound annual growth rate in revenue between 2017 and 2020. StorPool achieved a CAGR during the queried timeframe of 69.29 percent. This was nearly double the minimum average growth rate – 36.5 percent – required to be included in this year’s ranking. StorPool Storage is a primary storage platform designed for large-scale cloud infrastructure. It converts sets of standard servers into primary or secondary storage systems and provides thin-provisioned volumes to the workloads and applications running in on-premise clouds with multi-site, multi-cluster and BC/DR capabilities .
…
VMware said it has worked closely with other tech firms, including Pensando Systems, to deliver a single infrastructure platform across silicon and OEM vendors in the DPU space under the auspices of Project Monterey. AMD’s purchase of Pensando seemingly validates VMware’s belief in the future of the data center as a distributed and heterogeneous architecture – which will continue to evolve by embracing newer types of devices and accelerators. VMware sdaid it is actively engaged with Pensando Systems to jointly work on a distributed data center architecture.
…
VMware announced VMware Cloud Flex Storage, a natively integrated, elastic and scalable disaggregated cloud storage that mitigates the scalability issues faced by users on VMware Cloud on AWS. With VMware Cloud on AWS, cost economics were less than ideal and there were challenges associated with scaling its default vSAN storage. The only way to scale is to add or remove hosts, which means the addition or removal of CPU and memory in chunks, regardless of whether it was needed or not. VMware Cloud Flex Storage adds on-demand capacity and easy cost-effective scalability that requires no more than just a few clicks. Read a Gestalt IT blog for more info.
…
Replicator WANdisco said it saw strong trading in Q122 following significant contract wins for its LiveData Migrator (LDM) solution, both directly and via key cloud channel partners including Azure, AWS and IBM, and analytics partners Databricks and Snowflake. Eg; see Canadian National Railway. Its unaudited Q122 bookings are $5.8 million: up from $1.1 million a year ago. Ending RPO (Remaining Performance Obligations) is expected to be approximately $14 million for Q122: up significantly from $4.2m a year ago. Continued high visibility of it’s near-term business pipeline underpins confidence in strong 2022 trading.
…
HPE’s data protector Zerto has published a ransomware report about an ESG study revealing that gaps in readiness are seriously impacting the ability of many organizations to manage and recover from attacks. While organizations recognize that one of the best protections against a ransomware attack is the ability to recover from it, many are still struggling to counteract ransomware when prevention has failed. So, natch, buy Zerto’s services to help. Find out more in its downloadable e-book, “The Long Road Ahead to Ransomware Preparedness.”
…