Meta (Facebook as was) has announced its AI Research SuperCluster (RSC) which it claims is among the fastest AI supercomputers running today and will be the fastest in the world once fully built out in mid-2022.
Pure Storage is providing both FlashArray and FlashBlade storage for the RSC and says “RSC will have unparalleled performance to rapidly analyse both structured and unstructured data.” Pure says it helped to design the first generation of Meta’s AI research infrastructure in 2017. That version had 22,000 Nvidia V100 Tensor Core GPUs in a single cluster and performed 35,000 training jobs a day.
Rob Lee, CTO, Pure Storage, issued a statement. “The technologies powering the metaverse will require massively powerful computing solutions capable of instantly analysing ever increasing amounts of data. Meta’s RSC is a breakthrough in supercomputing that will lead to new technologies and customer experiences enabled by AI. We are thrilled to be a part of this project and look forward to seeing the progress Meta’s AI researchers will make.”
Nvidia RSC AI supercomputer.
RSC is powered by 760 Nvidia DGX A100 systems linked with Nvidia Quantum 200Gbit/sec InfiniBand fabric, delivering 1,896 petaflops of TF32 performance. The system is expected to be the largest customer installation of Nvidia DGX A100 systems to date once fully deployed later this year. An Nvidia blog has much more detail.
RSC will help Meta’s AI researchers build better AI models that can learn from trillions of examples; work across hundreds of different languages; seamlessly analyse text, images and video together; develop new augmented reality tools and more; build for the metaverse, in other words.
Its storage tier has 175 petabytes of Pure Storage FlashArray//C, 46 petabytes of cache storage in Penguin Computing Altus systems, and 10 petabytes of Pure Storage FlashBlade.
The Meta blog reads “Through 2022, we’ll work to increase the number of GPUs from 6,080 to 16,000, which will increase AI training performance by more than 2.5x. The InfiniBand fabric will expand to support 16,000 ports in a two-layer topology with no oversubscription. The storage system will have a target delivery bandwidth of 16TB/sec and exabyte-scale capacity to meet increased demand.” Good news for Pure.
This system is expected to deliver, according to Wells Fargo analyst Aaron Rakers, “~5 exaflops of mixed-precision AI performance (~220 Linpack petaflops).”
Rakers told subscribers “Today’s announcement serves as a significant additional validation of Pure’s positioning as an all-flash array platform provider into a large hyperscale cloud customer (Meta was the cloud customer contributing to Pure F3Q22). … Pure had announced that it was deploying its AFAs at a hyperscale cloud customer impacting their F3Q22 (Oct ’21) quarter – now confirmed to be Meta; we estimate ~$30 million revenue contribution.”
Meta says its researchers have already started using RSC to train large models in natural language processing (NLP) and computer vision for research, with the aim of one day training models with trillions of parameters. Its blog goes into ore detail. “We hope RSC will help us build entirely new AI systems that can, for example, power real-time voice translations to large groups of people, each speaking a different language, so they can seamlessly collaborate on a research project or play an AR game together.”
It wanted to design a new generation RSC because “We wanted this infrastructure to be able to train models with more than a trillion parameters on data sets as large as an exabyte – which, to provide a sense of scale, is the equivalent of 36,000 years of high-quality video.”
Meta expects RSC to provide “a step function change in compute capability to enable us not only to create more accurate AI models for our existing services, but also to enable completely new user experiences, especially in the metaverse.”
Source Massive X-Class Solar Flare uploaded by PD Tillman; Author - NASA Goddard Space Flight Center
NVMe/TCP pioneer Lightbits Labs grew its business on multiple fronts in 2021 and ended the year with a 2.3X increase in pipeline growth, positioning it for an even better 2022.
On the back of VMware certification in 2021 for its software, which sends NVMe storage accesses across TCP and provides flash management, the company doubled its installed base and increased its average deal size by 60 per cent compared to 2020.
Eran Kirzner, Lightbits CEO, provided a statement: “We attribute the growth to our unique capabilities in terms of delivering a highly performant, cost-efficient data platform with enterprise rich data services in a shared storage environment that is easy to consume. More companies are adopting NVMe/TCP, and we invented it, it’s native to our storage software and our announcement last year with VMware is evidence that we are on a trajectory towards delivering an end-to-end NVMe solution.”
Lightbits publicised other growth aspects of its 2021 experience:
Increasing revenue on a tailwind of IT organisations looking for simplicity, agility, and cost-efficiency;
A significant number of new partners join the “GoPurple program”;
Added offices;
Added 27 per cent more employees.
Kirzner said “In 2022, watch for more product innovations with our strategic alliances.”
The general move to provide NVMe/TCP as an upgrade to existing iSCSI deployments is widespread, with support from Dell EMC (PowerStore), Fungible, NetApp, Pavilion Data, StorONE, and VMware in 2021.
Toshiba added NVMe/TCP support to its Kumoscale product in 2019. HPE and Pure Storage have yet to add support.
Acronis has improved its CyberFit partner program with more emphasis on supporting partner development, particularly for cloud-based services, increasing its marketing and social media visibility with pre-packaged automated content, and offering competitive professional and financial assistance to partners willing to migrate to Acronis.
A focus on service providers and cloud distribution partners, with no revenue threshold for service providers, straightforward program requirements, and a dedicated partner account manager;
Joint business planning, with business plans available on the Partner Portal, financial benefits for Gold and Platinum partners, and joint sales and marketing efforts;
Competitive migration program, with financial and professional services assistance available to partners ready to migrate to Acronis;
Unique #TeamUp programme, offering partnerships with sports teams and unique sports benefits;
Sales and marketing automation tools and pre-packaged content, with e-mail drip campaigns and social media campaigns available to automate via Partner Program;
On-demand demo lab for partners, an upcoming cloud-based virtual lab environment with Acronis Cyber Cloud components pre-installed and available for training and demo purposes;
NFR programme, providing Acronis Software licenses to partners’ internal usage;
…
Codenotary, which supplies end-to-end cryptographically verifiable tracking and provenance for all software artefacts, actions, and dependencies and can instantly identify untrusted components in software, has raised $12.5 million in series B funding by new and existing investors Bluwat, Elaia and others. It is the primary contributor to Immudb, the open source enterprise-class database with data immutability that can scale to billions of transactions per day. Codenotary uses immudb to underpin its notarization and verification product. There have been more than 12 million downloads of immudb so far.
…
Meredyth Jensen.
HPC and enterprise storage array provider DDN has appointed Meredyth Jensen as its CMO. She comes from being SVP marketing at RGP, a human capital firm – a non-storage tech background. DDN has an SVP for marketing: Kurt Kuckein.
A DDN spokesperson said: “DDN continues to experience impressive YOY growth and has brought on a new CMO who will be focused on building DDN’s brand eminence, awareness and expanding our footprint in key verticals/markets as well as generating demand for our portfolio to support enterprise customers, government and higher ed in their digital transformation journeys. This is especially relevant now with commercial customer requirements driven by the growing complexity of AI data management. These customers are looking for solution providers with domain expertise in both advanced computing and Enterprise workloads.
“Yes, Kurt is reporting to Meredyth and will bring his deep subject matter expertise to our product marketing engine to accelerate growth.”
…
Research outfit TrendForce expects NAND flash prices for 1Q22 to decline by 8–13 per cent quarter on quarter, compared to TrendForce’s previous forecast of 10–15 per cent, primarily due to PC OEMs’ increased orders for PCIe 3.0 products and the impact of the lockdown in Xi’an on PC OEMs’ price negotiation approaches. The daily number of new COVID-19 cases in Xi’an has recently undergone a noticeable drop, and the local government has also announced that the emergency level has been downgraded. As such, Samsung’s and Micron’s local production facilities are returning to normal with respect to workforce and operational capacity. Samsung’s local production base manufactures NAND flash products, whereas Micron’s local production base is responsible for the testing and packaging of DRAM chips as well as the assembly of DRAM modules. The impacts of the lockdown mainly relate to delays in the deliveries of memory products to customers.
…
Veritas has confirmed that Gartner analyst Santhosh Rao is joining Veritas in the role of senior director, product and strategy. He will be reporting to Doug Matthews, Veritas VP of product management.
…
William Blair financial analyst Jason Ader told subscribers his December quarter survey of 118 VARs capped off a strong IT spending year, with VARs seeing customers put ample budgets to work and address urgent application and infrastructure needs. That said, he observed a sequential downtick in overall sentiment, which was attributed to project pushouts, severity of supply constraints, macro concerns on Omicron and inflation, and the likelihood of more moderate spending growth in 2022 (due to tougher comps).
…
Weebit Nano, together with its development partner CEA-Leti, has demonstrated its first operational ReRAM crossbar arrays. It says this is a key milestone on the company’s path to creating discrete (stand-alone) non-volatile memory (NVM) chips. Weebit says its crossbar arrays were developed using a 1S1R (one selector one resistor) architecture that enables the high density needed for discrete chips. Such an architecture also allows Weebit’s arrays to be stacked in 3D layers so they can deliver even higher densities. CEO Coby Hanoch said Weebit Nano continues to make significant technical and commercial progress within the embedded sector – recently “successfully scaling our ReRAM technology down to 28nm. Now, with the creation of our first kilobit crossbar arrays, we’re continuing our progress toward discrete memory solutions.”
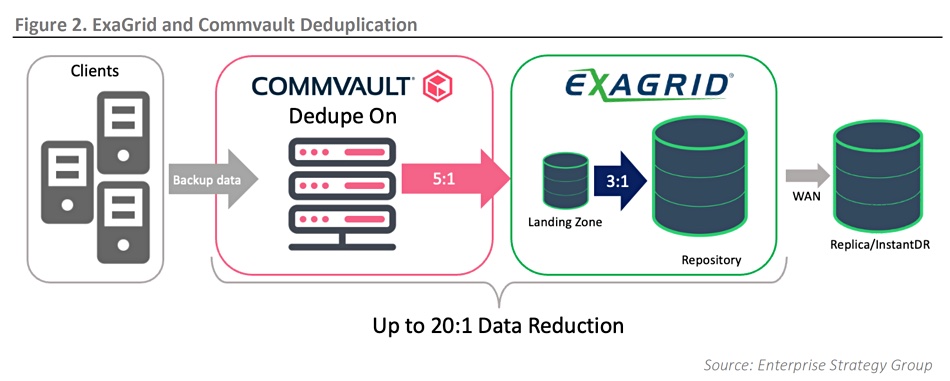
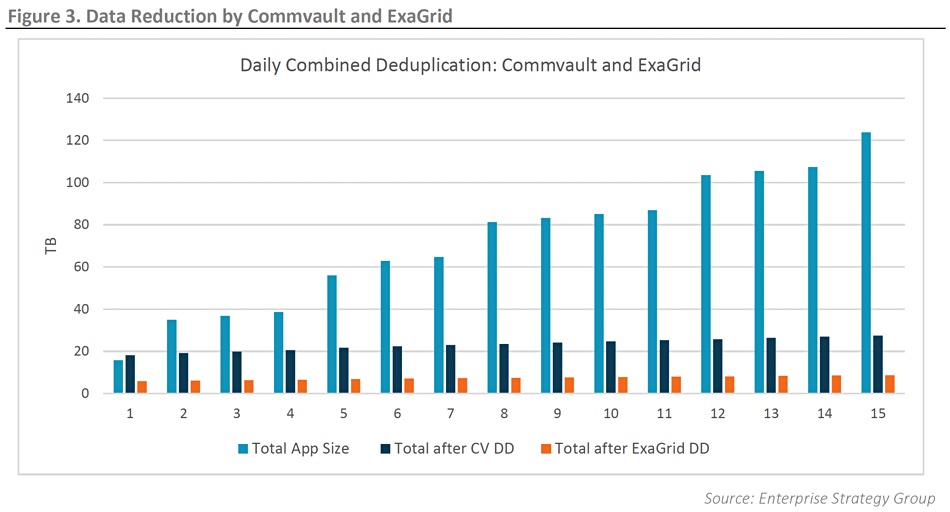
Analysis house ESG says users can get a fifteenfold reduction in backup size by using an ExaGrid array as a backup target for Commvault.
Commvault’s backup software delivers a 5:1 dedupe ratio, using a local-to-the-system deduplication scheme. The backup data set is shrunk to a fifth of its ordinal size. When Commvault sends this to an ExaGrid system, using CIFS/SMB, it – with its global dedupe scheme – provides a further 3:1 dedupe ratio, reducing the set’s size again to one fifteenth of its original size.
This was validated by analysts at ESG, substantiating ExaGrid’s marketing claims. ESG’s report states: “Individually, Commvault and ExaGrid each offer data deduplication, but together they offer a highly efficient backup solution that can reduce the storage footprint by up to 300 per cent, saving storage capacity and cost.”
If the backup is sent to a remote site for extra resiliency then the greater deduplication saves network bandwidth cost.
In fact the ESGites recorded an up to 20:1 total dedupe ratio in some cases. “A combined ExaGrid and Commvault solution can achieve even greater deduplication: up to 20:1 in many cases. A 20x reduction in backup storage costs can be a significant boost to any budget.”
No operational changes are needed to the Commvault configuration. The ESG testers noted “Adding ExaGrid to an existing Commvault environment is as simple as adding a new Commvault Library and Storage Policy for ExaGrid and selecting them for use. This is a quick and easy task with which Commvault administrators are familiar.”
ESG’s testers set up both sides of the setup and said it was a simple task overall. “ESG validated how easy and fast it was to set up an initial ExaGrid/Commvault deployment to securely back up data, replicate it, and make it available for instant restore. The ExaGrid tasks were simple to complete using the intuitive GUI, and the Commvault tasks are familiar to Commvault administrators.”
You might wonder about how this Commvault/ExaGrid combo compares to Commvault with other deduping backup targets, such as Data Domain/PowerProtect? We had a look to see if Commvault users might get even greater benefits with a different backup target.
It appears not. In fact it seems from a Commvault user Community website that using Data Domain may require Commvault dedupe to be turned off. The full thread is quite informative about the background. The topic is complex and a Dell Technologies community website contains notes about virtual PowerProtect DD Virtual Edition with Commvault and metadata wrinkles which adds further complexity.
All in all we weren’t able to discover the combined Commvault/PowerProtect dedupe ratio and discovered things might be more complex than setting up a Commvault/ExaGrid combination.
ExaGrid CEO Bill Andrews told us “No one else that we know of can further deduplicate Commvault deduplicated data.” There you have it.
MRM – Managed-Retention Memory (MRM). A January 2025 Microsoft research paper said that MRM is different from volatile DRAM as it can retain data without power and does not waste energy in frequent cell refreshes, but unlike SCM (Storage-Class Memory), is not aimed at long-term retention times. As most of the inference data does not need to be persisted, retention can be relaxed to days or hours. In return, MRM has better endurance and aims to outperform DRAM (and HBM) on the key metrics such as read throughput, energy efficiency and capacity.
The paper authors conclude: “By relaxing retention time requirements, MRM can potentially enable existing proposed SCM technologies to offer better read throughput, energy efficiency, and density. We hope this paper really opens new thinking about innovation in memory cell technologies and memory chip design, tailored specifically to the needs of AI inference clusters.”
Solidigm is not an SSD design and manufacturing weakling cast off by parent Intel because it was failing. It went because Intel needed the capital invested in it to develop its more important core manufacturing fab and processor technology capabilities. Solidigm, which was partially acquired by SK hynix, is a multi-billion dollar revenue company, an SSD design and manufacturing powerhouse with a reputation for rock-solid SSD quality.
Blocks and Files was briefed by two Solidigm executives on the company’s situation, scope and aspects of its technology plans. They were Greg Matson, VP for strategic planning and marketing – the datacentre guy – and Avi Shetty, senior director, strategic planning and marketing for client SSDs. We found it had a wide-ranging roadmap, both for enterprise and client drives.
Greg Matson.
Greg Matson: “We’re a new company, obviously, but we have the backing of a multi-billion-dollar SK group. And so we’re a kind of a billion dollar startup.” There is: “A great [Intel/Solidigm] revenue base that I think over time we’ll be publicly talking about [with] many billions of dollars of existing SSD revenue.”
He spoke of Solidigm having the: “deep technical expertise of coming from the [Intel] platform company. … We haven’t lost that. We’re the same people that grew up, in the platform-based company, both in a client and datacentre [way], and we are not going to lose that array, we’re building that capability out.”
“We are going to be headquartered in the US in San Jose, [with a] very strong presence … across the globe, with 20 global locations, and over 2,000 SSD-focused employees, purely focused on developing solid state drives for client and datacentre [markets]. And then countless thousands more in the factories.”
Parent, manufacturing and customers
Solidigm and SK hynix complement each other. “We have killer client products in the enthusiast and performance segment coming from SK. We have killer mainstream products and value products coming from the historic Intel roadmap. … We have great SSDs in compute, coming from SK and great SSDs in the compute and storage space coming from the Intel perspective.”
The two manufacturing networks are another strength. “We have our SK base factory network. It’s really big in scale. We have our Fab 68 coming from China, again, really big in scale.”
“We’re investing in expanding both of those networks. We have really deep customer understanding, coming from both sides, both the SK as well as the Intel side, and have presence in almost every customer in the world from an SSD perspective, whether it’s top 10 in cloud service providers, whether it’s the the storage OEMs, the traditional enterprise, server OEMs, the enterprise and business and enthusiast client, and we have very strong presence there, across our SSD base.”
“We’re building on kind of the reputation of having kind of world-class quality, reliability, as well as customer support. … [We] aren’t going to lose that history of having rock solid products in the market.”
Charge Trap vs Floating Gate
Solidigm and SK hynix have different NAND technologies, with SK hynix using Charge Trap technology but Intel being a Floating Gate hold-out.
Most of the NAND industry, except Intel/Solidigm, has adopted Charge Trap. For example, Micron used Floating Gate technology up until its 4th generation 3D NAND which went to Charge Trap and 128 layers in 2019.
Greg Matson said SK has been shipping Charge Trap “to mobile client datacentre markets for quite a while. … We’re [Solidigm] unique from a supplier perspective that we have both of these technologies to bring to market to allow us to optimise our product portfolio for all the different segments in both cloud and datacentre.”
Avi Shetty.
Shetty told us: “The client world has segmented and you need unique technologies to address your segments which you’re going after. Floating Gate with its ability to scale and offer high densities allows us to go aggressively after the value, cost-focused, high density required segments, which allows us to offer 1TB, 2TB, and maybe on a 3TB to 4TB basis, at a very attractive price point.
“Charge Trap with its fundamental performance benefits allows us to focus on the high-end workstation, enthusiast-related product markets. So this is a complementary business, complementary technologies with the two coming together to give us the ability to address the full portfolio on both the datacentre and client, which individually we’ve been maybe missing but collectively we now are a much stronger force.”
Matson agreed. “Some of the compute applications … in cloud hosting, for example, require very high amounts of IOPS, like high-capacity and … small capacity drives to get the most bandwidth and the highest most IOPS out of the system. … Charge Trap excels at that. … that’s an area of focus [where] the historic Intel hasn’t excelled.
“Where we’ve [Intel] excelled is kind of that mid-capacity and high-capacity range in … more moderate performance compute usages, and then the very high-capacity storage use cases.
“We have … what we think now is the best of best of breed, to be able to serve all your classes, cloud compute, and storage, focused enterprise storage, focused workloads on the enterprise side.”
It’s not a case of going all-in on Charge Trap or Floating gate, according to Matson. “We dive deep with our top service providers, for example, to understand their exact workloads. And we’ve been able to tune our drives to perform better than competitors’ drives. In those workloads where they actually use the drive in some cases, you know, our datasheet doesn’t look as good as our competition. And in the four corners type, random read performance, for example, there you might see a competitor having higher random read IOPS and kind of corner case workload.
“But you get down into an elastic block store workload at the biggest cloud service providers in the world and we offer better quality of service and better … read latency profiles. And we’ve been able to do that in Floating Gate.
“We’re going to work on Charge Trap solutions and get those things tuned for the … best killer performance and compute workloads as well. And so I think there’s advantages for both.”
Solidigm product portfolio.
Shetty said Floating Gate has a role on the client front too. But products using it have to meet two goals. “There are essentially two vectors in which we define our product. … One[ is] cost-focus, we have to get into PCs, where we have to fit into system price points, with an affordability index within our OEM PCs, anywhere from $399 all the way up [to] $22,000.”
The other vector, as we understand it, is optimally balancing performance, endurance, and reliability, as well as cost.
Shetty explained: “It’s not just about speeds and feeds all the time. Yes, there is a market where speeds and feeds are really important. But it’s all about … having a drive, which is optimally balancing performance, endurance, reliability, as well as cost. Because in the end … you don’t want to have provided an SSD, which gives you the best performance, but it sucks in battery life, maybe one hour battery life, right?”
Matson has this view of Floating gate advantages: “That kind of discreet charge storage node on Floating Gate we think gives us the best in class both voltage threshold window and strong cell isolation really allowing us to have the highest P/E cycles with a densest flash memory. It easily enables us to scale to three, four and even five layers per cell … while still meeting industry standard data retention and reliability metrics. That’s different than we’ve seen in competitors’ QLC flash for example.”
PLC NAND
Five bits per cell is penta-level cell (PLC) NAND, with a 25 per cent per-cell capacity advantage over QLC (4 bits/cell) NAND. It is inherently slower than QLC NAND because of the additional voltage levels, and also has lower native endurance than QLC.
Matson said “This technology we think is best for high-capacity storage-focused drives that gives us the the best bit density you know, meaning technology cost and as well as overall capacity scaling.”
PLC development at Solidigm “is going really well. In fact, we’re already demonstrating silicon in the labs, and are working on the best intercept for PLC SSDs and the enterprise side. I can’t comment on timing for that. I can tell you that we’re very bullish on the technology, and do not see any deviation from our ability to deliver the kind of industry standard JEDEC, standard daily [use] type specs that deviate at all from TLC or QLC.
“We have strong customer interest in that. It’s going to come with compromises on performance, like QLC does as well. But it will definitely have its place in the market. We think that plays a big role over over time. It’s a very promising kind of long term technology.”
We mentioned that suppliers such as VAST Data might be interested in enterprise-class PLC SSDs and Matson replied “You can imagine that companies like that are extremely interested.”
3D NAND Layer counts
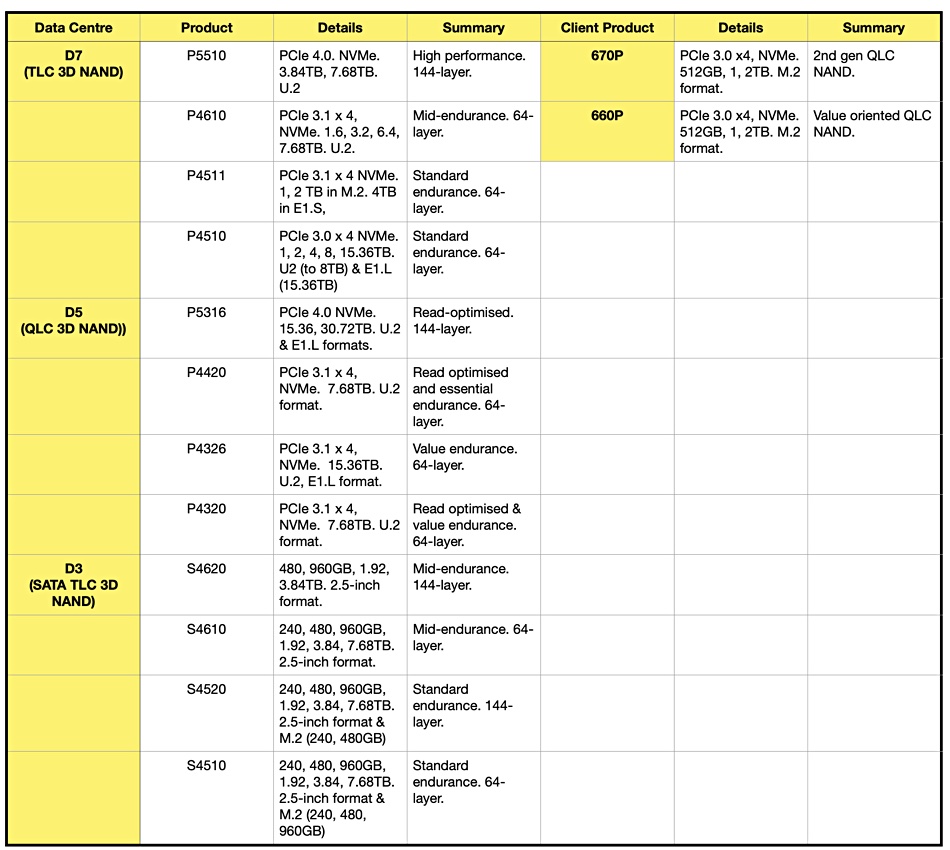
Intel is currently introducing its 144-layer 3D NAND technology. Matson said “We’ll be expanding that 144 layer to essentially all of our products by the end of calendar 2022.”
Avi Shetty said “We went from 128 to 144 and we are going to go scale up in future. That also coincides with die size – basically the NAND die is growing.” That causes him potential problems in space-limited client systems.
PCIe 4 and 5 and CXL
Solidigm will roll out PCIe 4 to all of its enterprise SDS this year, probably by the mid-point. Avi Shetty said “We have products from the SK side addressing the Gen 4 market today, which is coming top to bottom … going into performance segment, then into mainstream, and then eventually into full value.”
Avi Shetty said that moving to PCIe 4 on the client side would mean a cost increase – “A non-media BOM (Bill of Materials) increase.”
“But we expect innovations in other areas, to introduce Gen 4 to the majority of the customers. For example, to effectively produce a Gen 4 SSD at equivalent or pretty close pricing as Gen 3 … we need to invest in DRAM-less. You will see innovation on our end to effectively give more performance to the end user at the same system price points. So you’ll see all of those showing up in our roadmaps in future.”
Avi Shetty said that on the client side it wasn’t just a case of adding PCIe 4 connectivity to the drives. The overall platform adoption of PCIe 4 drives, such as M.2 form factor drives, has to be considered. That means being DRAM-less, connectivity bandwidth and thermal management, where desktops have more scope for cooling than notebooks, and so tend to get things like PCIe 4 before notebook products.
Greg Matson: “Absolutely. And we’re aligning our Gen 5 timing with when we see a broad adoption of Gen 5. Just to give you a little bit of flavour, a lot of our top 10 cloud service providers are just getting to Gen 4 this year, and some not even until 2023. And we see the bulk of the market [and] it’s in that transition from Gen 3 to Gen 4. And then we think that the Gen 5 timeframe will start in 2023 and ramp even more heavily in 2024 from a customer adoption perspective. Our products are right in line with that timeframe.”
Solidigm is investigating client PCIe 5 use but wide industry ecosystem co-operation will be needed to cope with things like PCIe 5 drive thermal, power and bandwidth management. PCIe 5 could be used to halve the equivalent PCIe 4 system’s lane count, from four to two, say, offer the same performance and also free up PCIe slots for other peripherals.
Greg Matson: “From a Solidigm perspective, we are not developing any CXL products right now … the SK Hynix side of the DRAM side of the house … probably have some plans but [we’re] not up to speed on those plans.”
EDSFF
Any plans for EDSFF, the new ruler-format drive form factors?
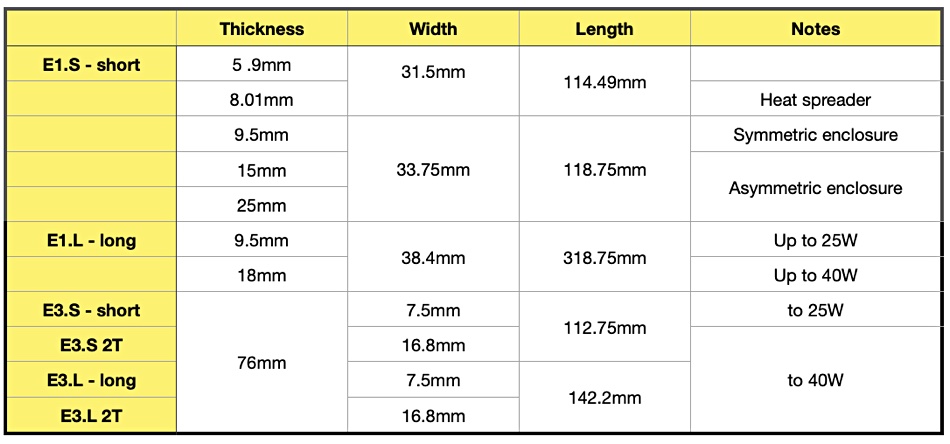
EDSFF form factors.
Matson is sentimental. “My team actually invented EDSFF and launched the first one in 2017. So we love EDSFF, because it’s our little baby. … We see pretty broad adoption happening. It’s been a slow to come out. E1.Ss are coming out as the emerging agenda, especially at the US cloud service providers. There we see the E3.S starting to come out in the PCIe 5 timeframe, very late this year and 2023. We’re very committed to that form factor.”
Matson thinks it will become “the state of the art for datacentre.”
Shetty’s attitude was quite different. The M.2 form factor is a fact of life in client systems. The E1 form factors are too thick, in Z-height sense, for laptops. ”If you’re asking EDSFF form factor and notebook, no way.
“My honest recommendation [is it] will be very limited to a very niche – maybe a workstation – kind of segment, which wants that form factor for a certain use case.”
Storage Class Memory
B&F: “Will Solidigm develop its own storage class memory technology?”
Matson: “We’ve been looking at it.” Optane (3D XPoint) “is still the only true storage class memory that’s ever been launched. Everyone else is doing NAND-based products. Yes, we are. We are strongly and carefully looking at the NAND-based versions of those products.”
We got specific. “Would you be looking at introducing specific product to compete with Samsung’s Z-SSD or the Kioxia equivalent?”
Matson did not get more specific. “I can say we’re looking at it and I can’t comment on product with future product plans. But of course, we’re looking at external customers. Our customers want us to serve all the [market] segments.”
No immediate plans then. But Solidigm products to compete with the Samsung and Kioxia Z-SDD-type technology could be coming in the future.
It’s possible that Solidigm, in its Intel NAND and SSD business unit period, was held back by its parent. Could we be seeing the start of a rejuvenation, with this billion dollar startup, freed of intel shackles, finding its wings and starting to fly? It’s a nice idea. Let’s hope it has substance.
Dell has release version 2.1 of its PowerStore software with performance improvements, NVMe/TCP functionality, automated IP SAN setup and management improvements. It’s also released XtremIO v6.4 software, and there’s more coming.
PowerStore is Dell’s core mid-range unified file and block access array, and converged the prior Unity, VNX and XtremIO product lines. PowerStore OS 2.0 was announced in April last year so v2.1 comes along nine months later with, Dell blogger VP technologists Itzik Reich writes, “performance improvements and additional functionality to support current and future workloads.”
His blog indicates that the release includes:
Portfolio-wide performance boost compared with the PowerStore 2.0 release;
More IOPS for every PowerStore model – up to 34 per cent at comparable response times (transactional latency);
Support for NVMe over Ethernet fabrics with NVMe/TCP and SmartFabric Storage Software (SFSS);
Provides advanced manageability and automation with infrastructure costs almost 25 per cent lower than Fibre Channel;
Performance up to 45 per cent higher than iSCSI;
Supported with SFSS in Dell and non-Dell switch environments;
Utilises existing 25Gbit and 10Gbit embedded and IO module ethernet ports;
Support for VMware vSphere 7.0U3 (as soon as re-released by VMware) and SUSE Linux Enterprise Server (SLES);
Additional new features with PowerStoreOS 2.1;
Improved AI for performance load balancing;
Windows 2022 support for agentless import;
Volume application tags;
Customisable login banner;
SSL Certificate import for management.
Itzik Reich.
The entry-level PowerStore 500 also gets DC power support. Reich notes: “Either AC or DC power is selected at the time of ordering and a PowerStore 500 system cannot be converted from using AC to DC or from DC to AC PSUs.”
NVMe/TCP
The NVMe/TCP support was actually announced last September along with the SmartFabric Storage Software (SFSS) feature, an end-to-end NVMe IP SAN system created in partnership with VMware.
There is a lot of information about these two items. Reich blogs: “Starting in PowerStoreOS 2.1, Ethernet interfaces can be used for iSCSI or NVMe/TCP host connectivity on PowerStore T model appliances. Ethernet interface creation is deployed in mirrored pairs to both PowerStore nodes since these interfaces do not fail over. This configuration ensures that the host has continuous access to block-level storage resources if one node becomes unavailable.”
Also: “NVMe/TCP is supported on 25GbitE (4-port) I/O module for front end host access 25GbitE speeds.” Note that: “When a Volume is created, all the unique identifiers for SCSI and NVMe are created with it. Once the Volume is mapped to a host, then it is defined as an NVMe-attached Volume or a SCSI-attached Volume. Hosts can only be attached to NVMe OR to SCSI at the same time. You cannot have a Volume mapped to NVMe and SCSI hosts at the same time.”
About SFSS, he writes: “In this initial release, SFSS is a standalone software solution packaged as a containerised application enabling an end-to-end automated and integrated NVMe-oF solution running TCP over an Ethernet fabric.”
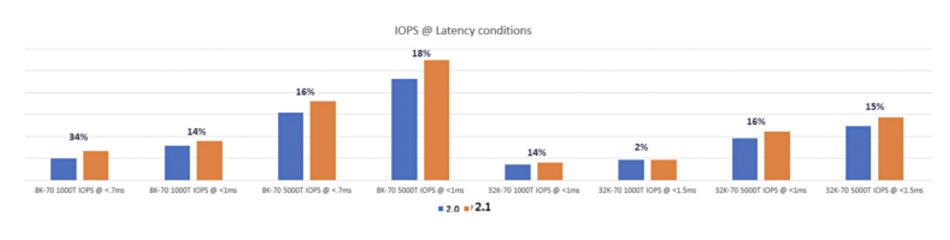
Performance boost
Reich exhibits a chart showing percentage IOPS improvements from v2 to v2.1 at various latency levels. The actual IOPS numbers are not shown, and the percentage range is 2 per cent to 34 per cent.
PowerStore performance improvements.
There are no charts showing improvements per PowerStore model.
The other new features are less of a headline nature. With Volume Application tags “Users can then use application-centric management to view and sort through their volumes by application type by adding the new ‘Application’ column in the list view.” It will help with volume management.
V2.1 PowerStore OS release notes can be found here.
XtremIO v6.4
For XtremIO system users, version 6.4 provides:
SNMPv3 support
cluster performance metrics over SNMPv3 in agent mode (server to client);
SNMPv3 differs from previous versions of SNMP in user authentication functionality with user keys to encrypt the data being transferred;
Replication
intermixing optical and copper ports simultaneously for native replication IP links;
raises an alert if two links in a cluster are not active;
adjustable bookmark retention times;
option to use fully qualified domain name (FQDN) instead of IP for Peer-XMS to better align with industry best practices;
integration with RecoverPoint now supports the Snapshot creation type/username being displayed at showing-protection-copies for remote-protection sessions;
Syslog support – sending logs to a central Syslog server;
Emulex-related enhancements – address several potential Emulex kernel and chip issues;
Changes to the supported configurations of the XMS Remote Support Feature – with XMS version 6.4.0-22 (or later) the email and legacy SRS-GW XMS remote support configurations are not supported.
CEO and co-founder of Filebase, Joshua Noble, told attendees at a virtual IT press tour about items on the Filebase roadmap.
We first learnt about Filebase in April last year, with its ability to store S3-compliant objects on back end decentralised storage networks such as SIA, Storj and Skynet. These are blockchain-based, but Filebase abstracts that away – using API-based front ends – and hides associated crypto-currency billing behind dollars and cents pricing for customers.
Joshua Noble.
Boston-based Noble told attendees “We started building the technology for this around 2017. We founded the company in early 2019. And we launched the products or service offering in May of 2019. Since then, we have acquired a little over 8,000 registered users on the platform.”
He said “On any given day, we’re processing … tens of millions of API calls per day. And we’re actually about to hit one billion objects processed in total. … That means we’ve stored a total of are about to have stored a total of one billion objects on two different decentralised storage networks in totality.” That would be the SIA and Storj networks.
The roadmap items are:
Additional back end networks throughout 2022 – IPFS, Filecoin and Arweave;
Back end network selection to optimise performance, cost, etc.;
Geo-fencing;
Object-copying between networks with multiple erasure-coded replicas across networks;
Add CDN (Content Distribution Network) use case – “We want to launch and offer CDN feature sets … more custom setting of cache control headers, and things like that.”
Support for custom domains so that “you can have a fully static website powered by Firebase and the decentralised networks that we’re built on top of.”
S3 Object Lock – “This is a big one, of course, in the ransomware world of being able to have a objects in the bucket locked for a certain duration of time”;
Offline mode so you can access your data without going through the Filebase platform.
What about archiving capability? “We don’t have a formal roadmap item for it at the moment but it’s absolutely something that we are exploring.”
Noble said “IPFS is heavily used in the crypto blockchain NFC worlds. IPFS is a data transmission protocol. … We have figured out a way to pin data onto the IPFS network, make it accessible, but have it be backed by these decentralised storage networks and have the whole thing decentralised so you can access data. Filebase, heaven forbid, can go down entirely, [and] all the data is still accessible.”
He is keen on Filecoin too. “[The] Filecoin network has about 13 to 14 exabytes of capacity, the last time I checked. And so this will be a huge boost for us in terms of capacity that we can offer to our customers.” It also has large sector sizes (write blocks) but Filebase’s packing technology can fill those sectors up.
Geo-fencing is “basically placing data within a specific geographic region for compliance and regulatory purposes, things of that nature.”
Filebase is a small startup, literally, in headcount terms. It has about a dozen employees and they all work remotely; it’s distributed, just like its file storage architecture.
Managed infrastructure network systems provider 11:11 Systems has completed the acquisition of iland, a global cloud service provider of secure and compliant hosting for infrastructure (IaaS), disaster recovery (DRaaS), and backup as a service (BaaS). 11:11 Systems also recently acquired Green Cloud Defense, a channel-only, cloud Infrastructure-as-a-Service (IaaS) provider. 11:11 reckons that, with these two acquisitions, “a hyper growth pathway has been created.”
…
Cyber security/data protector Acronis has found another sporting thing to sponsor. It will be the Official Cyber Protection Partner of the round-the-world sailing competition, The Ocean Race. The partnership will be supported by Ingram Micro, distributor of technology products and services, as the Official #CyberFit Partner, inline with the Acronis #TeamUp Program.
…
Arcserve announced an update to ShadowXafe and OneXafe Solo, its data recovery and backup products. They get simplified management at scale, support for immutable storage on the cloud, and improved data recovery. Customers can stagger backup jobs to ensure prioritisation, and partners can assign NFR licenses to multiple sites for better control. There is expanded support for Wasabi cloud object lock for cloud immutability and WAN-optimised replication. Arcserve says ShadowXafe’s patented VirtualBoot technology allows partners to perform a virtual machine recovery in milliseconds and restore an entire infrastructure in minutes. OneXafe Solo is a plug-and-play data protection appliance for business continuity that streams data directly to Arcserve Cloud Services.
…
Kalray, which provides processors and acceleration cards from cloud to edge, has entered into exclusive negotiations for the acquisition of 100 per cent of the shares of Arcapix Holdings Ltd, a provider of software-defined storage and data management products for data-intensive applications. Arcapix Holdings is the parent company of pixitmedia and arcastream. The intent is to strengthen Kalray’s position in the growing storage and intelligent data processing market, and accelerate the market penetration of Kalray’s acceleration cards and storage products.
Shridar Subramanian.
…
Pavilion Data has appointed Shridar Subramanian, ex-Arcserve CMO, as its chief product and marketing officer (CPMO). He will “spearhead the company’s initiatives to further innovate in the big data storage and analytics marketplace.” He assumed his position at Arcserve after serving as CMO and VP of product management at StorageCraft Technology, which merged with Arcserve in 2021. Previously he was chief revenue and marketing officer at storage systems company Exablox, a company acquired by StorageCraft in 2017. Pavilion CEO Dario Zamarian said “His skills will be invaluable to Pavilion as we continue to expand our offerings for the enterprise analytics market.”
…
SmartX has added a Network and Security component to its hyper-converged infrastructure (HCI). It uses micro-segmentation to help customers secure east-west traffic in various virtualization scenarios, enhance network security inside datacentres, and build “zero trust” enterprise cloud infrastructure. Customers can isolate infected virtual machines in time, blocking malicious attacks from spreading inside the datacentre, and set virtual machines into “diagnostic isolation” mode for debugging. More info here.
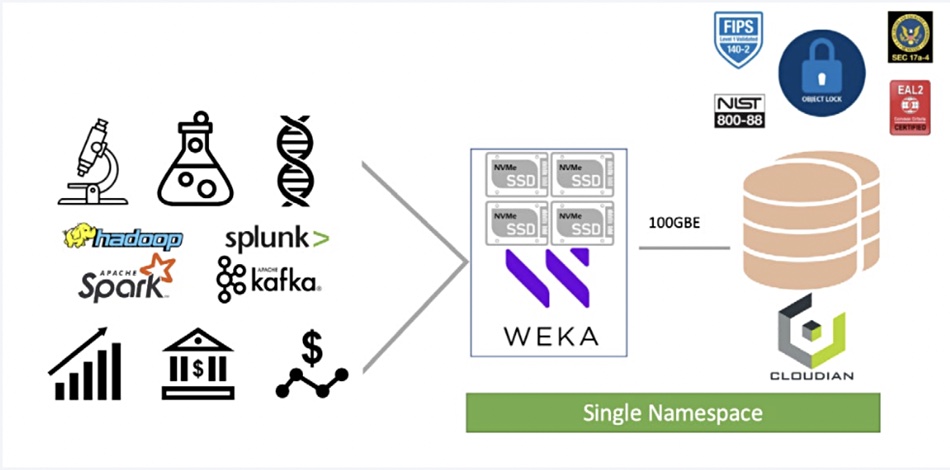
Cloudian and WEKA have partnered to add exabyte-scalable backend HyperStore object storage to WEKA’s scale-out, parallel Data Platform for AI filesystem software.
The two say their combined products, integrated through WEKA’s tiering function, unifies and simplifies the data pipeline for performance-intensive workloads and accelerated DataOps. It’s managed under a single namespace and – they claim – reduces the total cost of ownership of massive data sets used in AI and machine learning activities. They say it offers the simplicity of NAS, the performance of SAN or DAS, and the scale of object storage. It accelerates every stage of the data pipeline from data ingestion to cleansing to modelled results, according to Cloudian and WEKA.
Cloudian CMO Jon Toor played the “no need to compromise” card said in his announcement statement. “When it comes to supporting advanced analytics applications, users shouldn’t have to make tradeoffs between storage performance and capacity. By eliminating any need to compromise, the integration of our HyperStore software with the WEKA Data Platform gives customers a storage foundation that enables them to fully leverage these applications so they can gain new insights from their data and drive greater business and operational success.”
Petabyte to exabyte scale disk storage in the Cloudian object back end can feed fast NVMe SSD storage in the file-munching WEKA front end. Cloudian says its back end costs under $.01 per GB per month, including support. It has policy-based tiering to AWS, Google Cloud Platform, and Microsoft Azure, and is FIPS, CFTC 4511, SEC 17 a-4, Common Criteria compliant and certified at the capacity tier.
It’s a great deal for Cloudian, giving it a selling opportunity in WEKA’s customer base and market, while filling a gap nicely in WEKA’s offer. And WEKA gets a doorway into Cloudian’s customer base – win/win, I think.
The new combined offering is available now and you can get more information here.
Datto intends to acquire Infocyte, a threat detection and response company, for an undisclosed amount. Datto will thus add endpoint detection and response (EDR) technologies and managed detection and response (MDR) services into its security portfolio. The acquisition is intended to help its MSPs better address their customers’ security needs.
…
Cloud-scale security analytics platform supplier Panther Labs announced a new offering: Panther for Snowflake, developed in partnership with Snowflake to provide purpose-built security monitoring and threat detection. It is available immediately and contains out-of-the-box detections to help security teams monitor activity and validate security configurations in their Snowflake Data Cloud. Security teams can collect and analyse Snowflake logs in real time to detect tampering or unwanted changes to security settings and monitor for incidents or security risks. Snowflake event logs are aggregated, normalised and analysed along with security events from other systems so security teams have greater visibility into potential threats across their entire IT infrastructure from cloud to on-premises.
…
RAIDIX has a new version of its ERA software RAID, v3.4.1, which includes Linux kernel Ubuntu 20.04 HWE, and RHEL/CentOS 8.5 operating system support. The developers say they have significantly improved the DKMS functioning and made the XFS support and the initial starting of the scanner functionality more efficient.
…
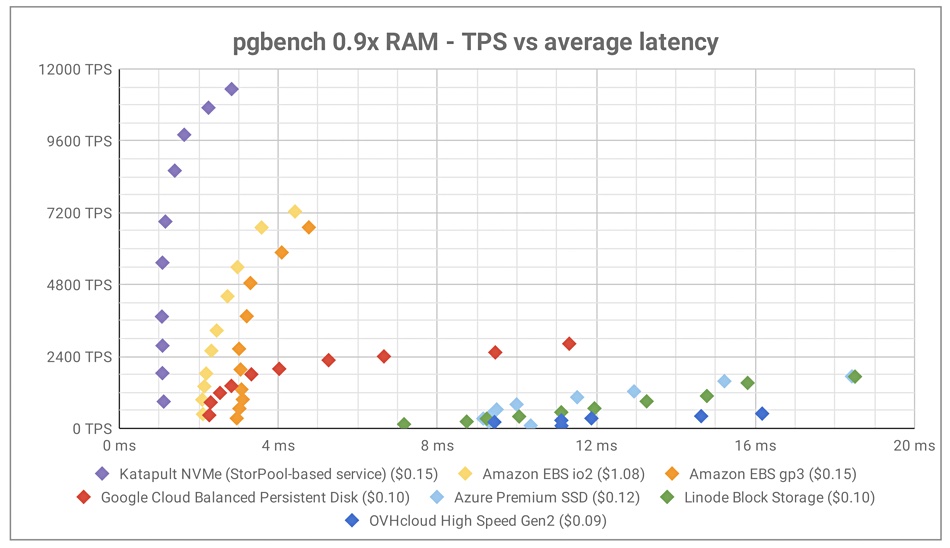
StorPool Storage has published its latest update on the Public Cloud Performance Measurement Report, showing up to 2.5 times better performance for StorPool’s clusters compared to the second-best public cloud offering, Amazon EBS. The report compares the performance of the block storage offerings of Amazon AWS, Google Cloud, Microsoſt Azure, Linode and OVHcloud and pits them against StorPool’s Katapult public cloud. Katapult is a virtual Infrastructure-as-a-Service platform developed by independent UK web hosting Krystal. See the report and testing results here.
Chart from StorPool’s Public Cloud Performance Measurement Report.
…
Industry research outfit TRENDFOCUS has announced a Tape & Archive Storage Service alongside its existing disk and SSD services. Mark Geenen, TRENDFOCUS founder and president, said “We’re expecting a complete re-definition of the technology roadmap for tape, and we’re thrilled by the response we’re receiving from our long-standing clients. Just as hyperscale has already impacted the direction of both HDD and NAND flash storage design and usage, we’re expecting similar movement from tape as enterprise management starts to shift to seeking lower cost options.”
The TRENDFOCUS Tape and Archive Storage Service will initially establish baseline trends on how tape is solving for major providers’ needs, then the service will evolve to include how both HDD and flash solutions could contribute to archive storage in the future. Coverage of other exciting new technologies such as DNA storage will also enlighten the long-term directions for archival storage over the coming decades.
…
Veeam co-founder Ratmir Timashev has contributed to a $1.5 million seed round for Latvia-based Monq Lab, which develops a self-hosted, topology-based, AIOps incident control and automation platform for enterprises. The investment will be used for the expansion of marketing and sales operations in North America and EMEA. Monq’s free, fully featured community edition is already available for download from its web page.