


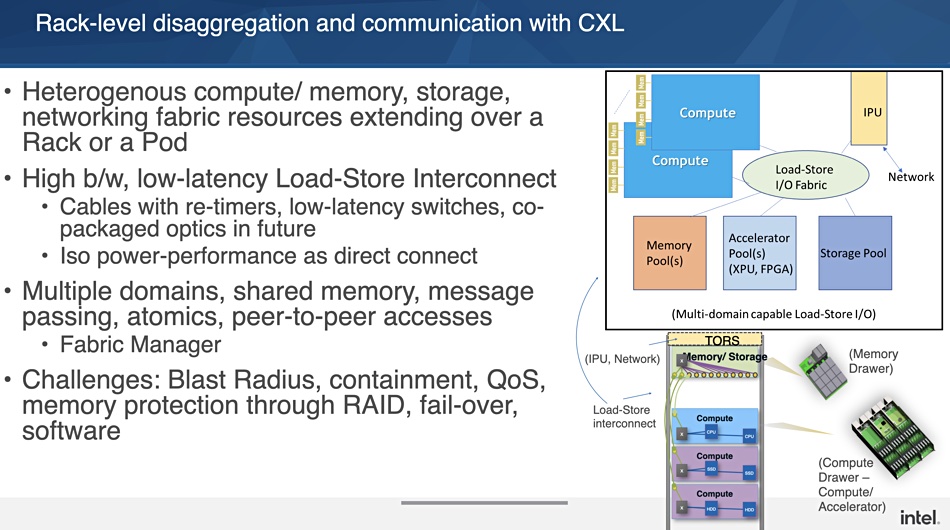
Intel foresees the CXL bus enabling rack-level disaggregation of compute, memory, accelerators storage and network processors, with persistent memory on the CXL bus as well.
This was revealed when Intel presented a keynote pitch on the Compute Express Link (CXL) at the IEEE Hot Interconnects event.
CXL is based on the coming PCIe Gen-5.0 bus standard to interconnect processors and fast, low-latency peripheral devices.
Intel’s presenter was its Fellow and Director of I/O Technology and Standards, Dr Debendra Das Sharma and he started his session looking at Load-Store IO. This form of IO — loading and storing data into memory locations — is relevant because server memory capacity needs are rising due to the basic requirement to compute more data faster in AI, machine learning and other data-intensive applications such as genomics and big data analytics.
Load-Store IO is faster — much faster — than network IO, which transfers packets or frames of data, and is typically limited to taking place inside a server using CPU-level interconnect. Das Sharma said Load-Store IO physical layer (PHY) latencies are less than 10ns, whereas fast networking PHY latencies are in a >20 to >100ns range.
The aim is to extend Load-Store IO out of the server, and the way to do that is to use the PCIe Gen-5 bus as a base. The memory in connected devices can then be treated as cached, write-back memory by the server processor, and not need a DMA data transfer to move data between devices and the physical server CPU-attached memory. An Intel slide shows this:

Das Sharma mentioned three usage models for such CXL bus systems:
- Type 1 — Caching Devices and Accelerators accessed via network interface cards (NIC);
- Type 2 — Accelerators (GPU, FPGA) with their own memory, such as HBM;
- Type 3 — Memory buffers for memory bandwidth and capacity expansion.
PCIe Gen-5 is fast enough to support server access to a pool of DDR5 DRAM across the CXL interconnect, and have it treated as usable DRAM by a server CPU. This, Sharma said, is poised to be an industry game-changer. It decouples compute from the traditional DIMM memory bandwidth and capacity limitations.
In the future NVDIMM (non-volatile DIMMs or persistent memory) could move to CXL, with DRAM backed up by storage-class memory (SCM) or NAND.
There could be computational storage devices — storage drives with on-board processors and memory and caching. They would do do on-drive compression, encryption, RAID, key:value store compaction, search or vector processing for AI/ML applications. They would have a DMA engine for moving data and use PCIe services such as NVM-Express.
Das Sharma says CXL enables systems to scale with heterogeneous processing and memory, with a shared cacheable memory space accessible to all using the same mechanisms.
In fact there could be a cluster-wide memory tier — a byte-addressable data store, scalable to petabytes:
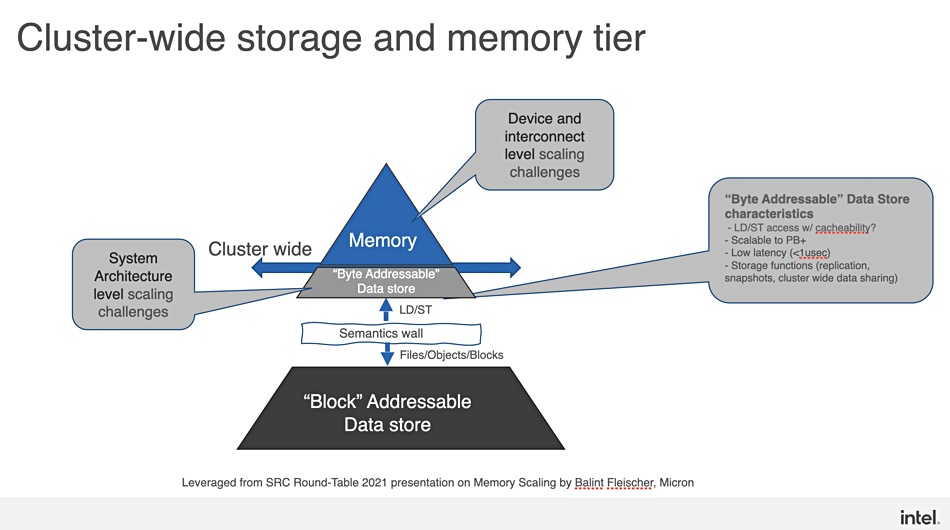
CXL would provide a Load-Store IO fabric at rack-level, disaggregating compute, memory pools, accelerator pools (GPU, FPGA), storage pool and network processing units across racks.
A June 2021 version of Das Sharma’s presentation given at the EMEA Storage Developer Conference can be seen on YouTube.
Comment
The only SCM made by Intel is Optane. Das Sharma is talking about having Optane NVDIMMs hooked up to the CXL interconnect and have that capacity accessed by servers across the CXL link. He says persistent memory would then be cacheable, multi-headed for failover, and hot-pluggable.
As there is a 150+-member CXL consortium, we might expect other vendors’ SCM products to play nice in this space as well — such as potential ones from Micron, Samsung and others.
We think Das Sharma’s eventual rack-level disaggregation with CXL has a composability angle with sets of compute, memory, accelerator, storage and network processors dynamically composed to run specific application workloads.





