StorCentric’s Retrospect has announced its own Storage Cloud and integrated it as a backup target into Retrospect Backup v19. It has also updated its VMware and Hyper-V virtual machine backup and restore facility to Retrospect Virtual 2022.
There are several cloud storage offerings used as backup targets, such as Amazon’s S3, Azure Blob, Backblaze B2, and Wasabi. Several backup-as-a-service suppliers sell their own cloud and examples include Clumio (AWS), Datto, and Druva (based on AWS). Generally speaking, backup industry practice is not to have a tightly coupled cloud storage target.
General manager JG Heithcock said: “Retrospect Cloud delivers a seamless one-click cloud backup and ransomware protection experience to our customers with a global footprint to minimize latency and adhere to local data regulations.” He said Retrospect’s SMB customers will appreciate having a single subscription covering both the backup software and the cloud storage (perpetual licensing is still available as an option).
Retrospect has not actually built its own cloud infrastructure and is relying on the Wasabi S3-compatible cloud, with 13 datacenters around the globe. Each one will be certified. Wasabi positions its cloud as a high-availability offering significantly less expensive than AWS. This contract with Retrospect probably helps explain why Wasabi has been able to raise extra funding for its cloud development.
In effect, Retrospect is reselling the Wasabi cloud as an integral part of Retrospect Backup 19 and Virtual 2022. We may see similar arrangements from other backup suppliers, or even more such deals with backup suppliers by Wasabi.
Retrospect says its cloud has a major focus on combatting ransomware and has security-focused features like immutable backups, anomaly detection, multi-factor authentication, and AES-256 at-rest encryption. Sensitive data can be backed up to Retrospect Cloud Storage but guaranteed to remain private from the underlying infrastructure providers.
Heithcock told us: “We say, hey, you’ve been doing backups for a month. And normally, you backup 5, 10 percent of your files. Today, you’re wanting to backup 80 percent. Something’s weird about that, right? That’s not normal, probably ransomware. And so we will flag that backup and send out alerts and emails.”
v19 also supports on-premises NAS devices, including the latest Nexsan EZ-NAS unit, with Retrospect built-in, and tape libraries offering LTO-9 support. Heithcock said: “You can also set this up as a file server and actually backup files on it. In fact, you don’t have to just do backups, you can use Retrospect as a data migration tool.”
Retrospect 19 also includes:
- Backup Comparison to check what’s changed between backups. Using this with anomaly detection, administrators can identify exactly which files changed to signal an anomaly and evaluate their contents to isolate valid ransomware infections.
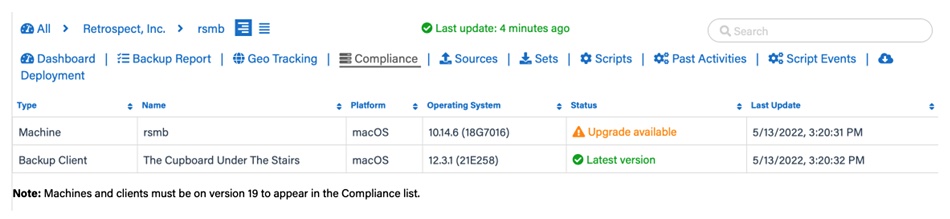
- OS Compliance Checks to identify systems that are out of compliance with the latest version of each operating system.
- One certified Wasabi cloud storage location.
The backup comparison feature can be used if anomaly detection detects ransomware to identify infected files and avoid using them, going to previous versions instead.
A subsequent v19.1 update release will add:
- Flexible immutable retention periods to extend the period on past backups instead of including that data in new backups.
- Certification of each of Wasabi’s data centers around the world, meaning an additional 12 locations for Retrospect Cloud Storage.
- Microsoft Azure for Government: blob storage on Azure for Government for state and local agencies looking for data protection in a US-based high-security data center.
Retrospect Management Console, the hosted backup analytics service, is updated to support multi-factor authentication, has a redesigned dashboard to better aggregate information for larger environments, separate user roles such as Administrators and Viewers, and a user action audit log.
Retrospect Virtual 2022 gets significantly faster backups, up to three times faster, and restores, data deduplication to reduce storage capacity occupancy, and certified Hyper-V 2022 support.
All-in-all, it has significantly upgraded and strengthened its backup software, with dedupe, cloud storage, anti-ransomware features, and much faster virtual machine backup.
Retrospect availability and pricing
Retrospect Backup 19.0 and Virtual 2022 will be generally available on July 12, and Backup 19.1 and Management Console updates will be generally available on August 30. Capacity-based pricing includes 500GB at $12/month and 1TB at $20/month. There is a separate add-on for existing perpetual licenses.