Analysis: ZNS and FDP are two technologies for placing data more precisely on SSDs to lengthen their working life and improve performance. How do they work? Will both be adopted or will one prevail?
ZNS (Zoned Name Space) and FDP (Flexible Data Placement) have the server hosting an SSD tell its controller where to place data so as to reduce the number of writes needed when the controller recovers deleted space for reuse.
The reason this is needed is that there is a mismatch between an SSD’s writing and deleting data processes, which results in the SSD writing more data internally than is actually sent to it. This is called write amplification. If 1MB of data is written to the SSD and it internally writes 2.5MB of data then it has a write amplification factor (WAF) of 2.5. Since NAND cells have a fixed working life – in terms of the number of times that data can be written to them – then reducing the write amplification factor as much as possible is desirable. And greatly so for hyperscalers who can have thousands of SSDs.
Write amplification
An SSD has its cells organized in blocks. Blocks are sub-divided into 4KB to 16KB pages – perhaps 128, 256 or even more of them depending upon the SSD’s capacity.
Data is written at the page level, into empty cells in pages. You cannot overwrite existing or deleted data with fresh data. That deleted data has to be erased first, and an SSD cannot erase at the page level. Data is erased by setting whole blocks, of pages and their cells, to ones. Fresh data (incoming to the SSD) is written into empty pages. When an SSD is brand new and empty then all the blocks and their constituent pages are empty. Once all the pages in an SSD have been written to once, then empty pages can only be created by recovering pages from blocks which have deleted data in them – from which data has been removed, or erased.
When data on an SSD is deleted, a flag for the cells occupied by the data is set to stale or invalid so that subsequent read attempts for that data fail. The data is only actually erased when the block containing those pages is erased.
SSD terminology has it that pages are programmed (written) or erased. NAND cells can only endure so many program/erase or P/E cycles before they wear out. TLC (3bits/cell) NAND can support 3,000 to 5,000 P/E cycles, for example.
Over time, as an SSD is used, some of the data in the SSD is deleted and the pages that contain that data are marked as invalid. They now contain garbage, as it were. The SSD controller wants to recover the invalid pages so that they can be re-used. It does this at the block level by copying all the valid pages in the block to a different block with empty pages, rewriting the data, and marking the source pages as invalid, until the block only contains invalid pages. Then every cell in the block is set to one. This process is called garbage collection and the added write of the data is called write amplification. If it did not happen then the write amplification factor (WAF) would be 1.
Once an entire block is erased, which takes time, it can be used to store fresh, incoming data. SSD responsiveness can be maximized by minimizing the number of times it has to run garbage collection processes.
This process is internal to the SSD and carried out as a background process by the SSD controller. The intention is that it does not interfere with foreground data read/write activity and that there are always fresh pages in which to store incoming data.
Write amplification is an SSD feature that shortens working life.
Individual pages age (wear out) at different rates and an SSD’s working life is maximised by equalizing the wear across all its pages and blocks.
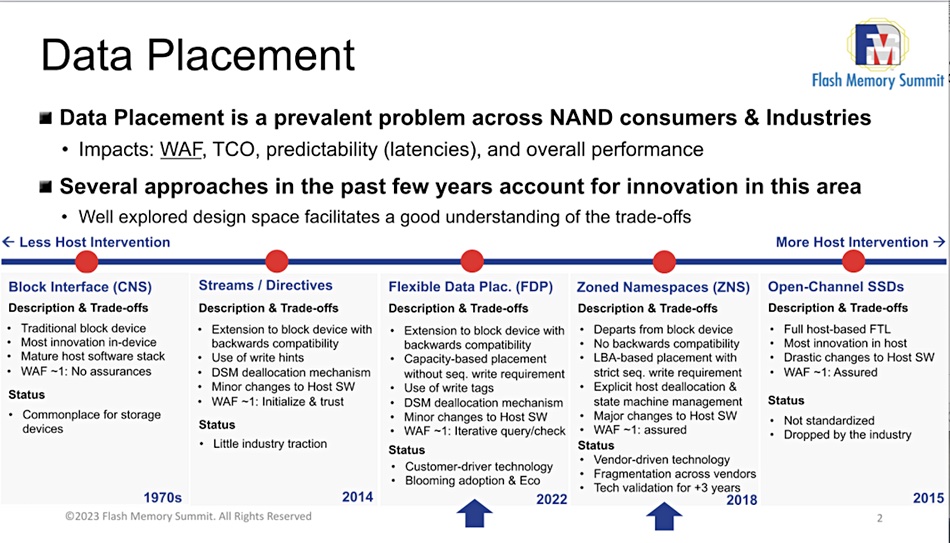
If particular blocks experience a high number of P/E cycles they can wear out and the SSD’s capacity is effectively reduced. ZNS and FDP are both intended to reduce write amplification.
ZNS
Applications using an SSD can be characterized as dealing with short-life data or long-life data and whether they are read- or write-intensive. When an SSD is used by multiple applications then these I/O patterns are mixed up. If the flash controller knew what kind of data it was being given to write then it could manage the writes better to maximize the SSD’s endurance.
One attempt to do this has been the Zoned Name Space (ZNS) concept, which is suited to sequentially-written data with both shingled media disk drives and SSDs. The Flexible Data Placement (FDP) concept does not have this limitation and is for NVMe devices – meaning prediminantly SSDs.
A zoned SSD has its capacity divided into separate namespace areas or zones which are used for data with different IO types and characteristics – read-intensive, write-intensive, mixed, JPEGs, video, etc. Data can only be appended to existing data in a zone, being written sequentially.
A zone must be erased for its cells to be rewritten. Unchanging data can be put into zones and left undisturbed with no need for garbage collection to be applied to these blocks.
A host application needs to tell the SSD which zones to use for data placement. In fact all the host applications that use the SSD need to give the controller zoning information.
FDP
The NVM Express organization is working on adding FDP to the NVMe command set. It is being encouraged by Meta’s Open Compute Project and also by Google, because hyperscalers with thousands of SSDs would like then to have longer working lives and retain their responsiveness as they age.
An OCP Global Summit FDP presentation (download slides here) by Google Software architect Chris Sabol and Meta’s Ross Stenfort, a storage hardware systems engineer, revealed that Google and Meta were each developing their own flexible data placement approaches and combined them to be more effective. As with ZNS, a host system tells the SSD where to place data. (See the Sabol-Stenfort pitch video here.)
The two showed an FDP diagram:
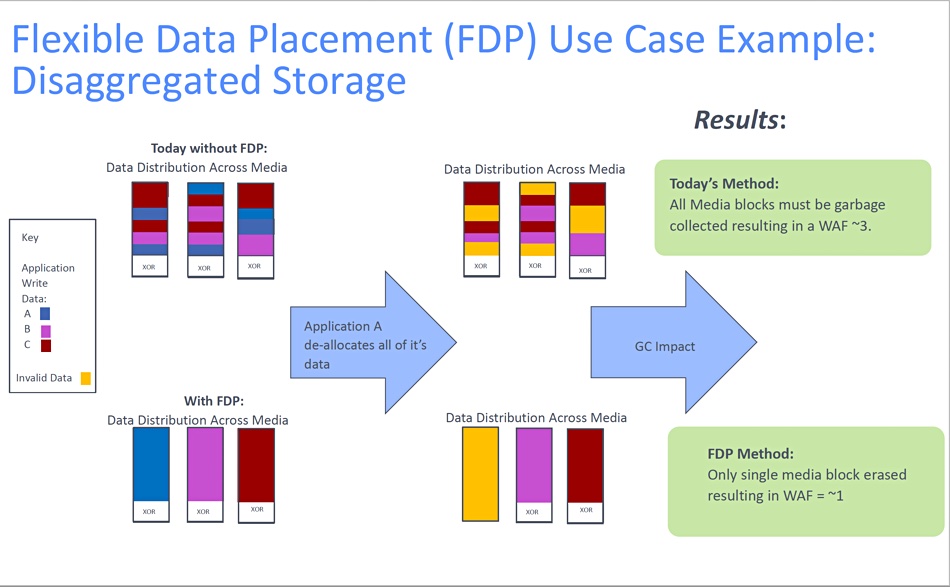

In effect, data from an application is written to an application-specific area of the SSD, to a so-called reclaim unit or block/blocks. Without FDP, data from a mix of applications is written across all the blocks. When one app deallocated (deletes) its data then all the blocks must undergo garbage collection to reclaim the deleted space and the resulting WAF in this example is about 3.
With FDP in place then only one block is erased and the WAF is closer to 1. This reduces the amount of garbage collection, lengthens the drive’s endurance and helps maximize its responsiveness. An additional benefit is that there is a lower need for over-provisioning flash on the drive, and thus a lower cost.
Javier González of Samsung presented on FDP at the FMS 2023 event in Santa Clara this month and his slide deck can be seen at the bottom of a LinkedIn article – here.
He said FDP and ZNS are the latest in a series of moves attempting to lower SSD write amplification, as a slide showed:
In Samsing testing, ZNS applied to a RocksDB workload achieved a slightly better WAF reduction than FDP.
He said that both ZNS and FDP have potential roles to play. For ZNS: “If you are building an application from the ground up and can guarantee (i) sequential writes, (ii) fixed size objects, (iii) write error handling, and (iv) a robust I/O completion path to handle anonymous writes if you are using Append Command (which is mandatory in Linux), then ZNS is probably the way to go. You will achieve an end-to-end WAF of 1, and get the extra TCO benefits that ZNS devices provide.”
However, “ZNS is an explicit, strict interface. You either get all the benefits – which are plenty – or none.”
FDP is different: “If you are retrofitting an existing application where (i) writes are not always sequential, (ii) objects may be of different sizes, and (iii) the I/O path relies in existing, robust software, then FDP is probably your best bet.”
He writes: “Our experience building support for RocksDB, Cachelib, and lately XFS (still ongoing after four weeks) tells us that reaching the first 80 percent of the benefit is realistic without major application changes” for FDP.
He thinks both technologies could co-exist but believes that one will prevail and expand to cover different use-cases.

More engineering effort in the SSD hardware and software supplier and user ecosystem is needed for ZNS while FDP needs less engineering support from an application-oriented ecosystem.
Gonzalez thinks only one of these technologies will gain mainstream adoption, but doesn’t know which one. ZNS is best suited for applications designed around fully sequential writes, while FDP is a better fit for users starting to deploy data placement in their software ecosystem.
An NVM Express TP4146 – TP standing for Technical Proposal – deals with FDP and has been ratified.