


Xinnor says its software RAID with ScaleFlux compressing SSDs mitigates RAID rebuild impact, meaning less node-level redundancy with distributed data apps.
RAID is used to guard against drive failures when using multiple drives to provide the storage needed by applications. A distributed application, like a database, runs across multiple server nodes and these can need to be over-provisioned to cope with the extra internal traffic and degraded performance that come with failed device rebuild operations in RAID arrays. Xinnor provides xiRAID software with tunable IO parameters and SCakeFlux has computational SSDs with built-in compression technology to reduce device write amounts.
A Xinnor/ScaleFlux doc says: ”A key feature provided by xiRAID is the ability to control the rate of array reconstruction, enabling a predictable reconstruction workload sized to ameliorate contention with host IO. The The ScaleFlux CSD 3310 NVMe SSDs feature transparent inline compression that also lowers the impact of intra-RAID reconstruction IO.”
The two companies said they ran a test to see how a device failure and subsequent rebuild affected the IO rates of an Aerospike database accessing 38.5TB of storage capacity from 5 x 7.68TB ScaleFlux CSD 3310 PCIe gen 4 NVMe SSDs. The host server had a dual-socket Xeon Gold 6342 CPU with 48 cores and 512GB of DRAM. It ran Ubuntu 22.
In the setup Xinnor set its RAID 5 reconstruction priority to 10 percent of throughput to minimize the overall IO latency impact on the host. An Aerospike certification tool (ACT) was downloaded from GitHub and it generated a workload for the test and monitored the tail latency. The essential latency goal was that at most 5 percent of transactions exceed 1 millisecond.
The test involved four phases: normal operation, an SSD removal, degraded operation, rebuild when device returned to array, and normal operation again. A chart shows what happened to the IO patterns:
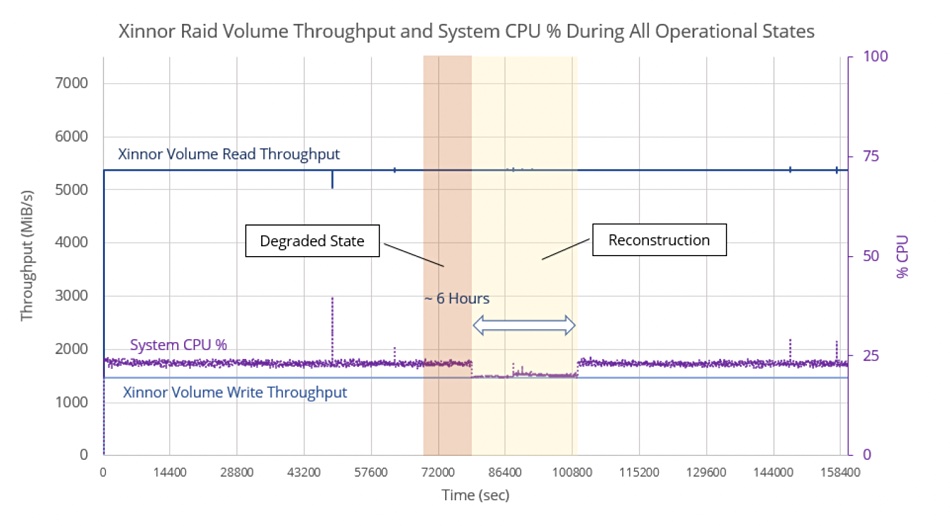
There was no appreciable database IO impact at all, neither on reads nor on writes. The total read and write throughput are constant;at 5.4GBps and 1.7GBps, respectively. There is a slight decline in CPU utilization while the array reconstructs. The drive rebuild took about six hours, going by the chart.
The tail latency was similarly unaffected:
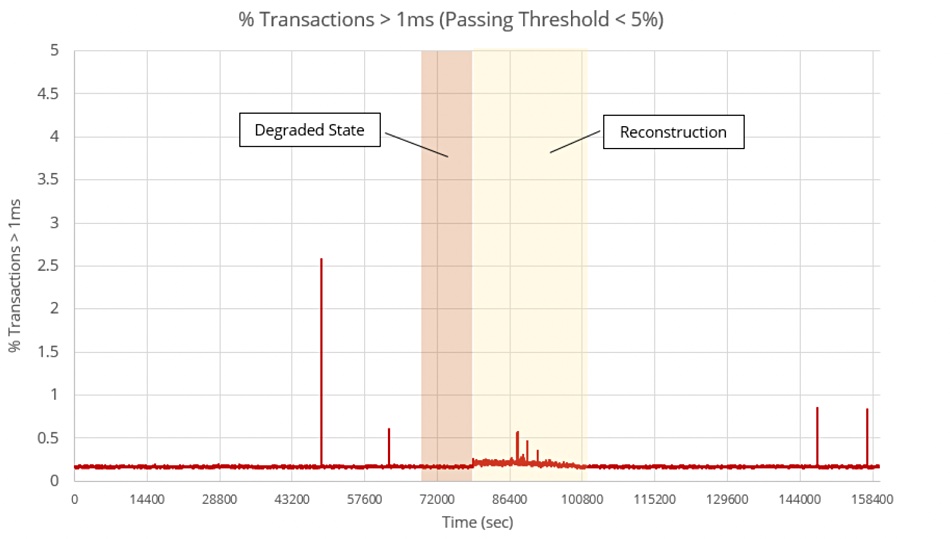
This all looks remarkable. RAID rebuilds normally are lengthy affairs, particularly with disk drives and particularly with high-capacity devices. ScaleFlux CSD 3000 series SSDs run the capacity gamut from 3,2TB through 3.84TB, 6.4TB, 7.68TB to 15.36TB. It would be interesting to see the test repeated with the 15.36TB drives, with the rebuild taking 12 hours assuming a linear progression. You could rebuild faster by setting the Xinnor Reconstruction priority differently.
The test shows that a Xinnor/ScaleFlux configuration can be used for low-latency applications. The two suppliers suggest there is an extension to distributed low-latency application scenarios.
They say that “the increased node data reliability may make it feasible to reduce the amount of node-level redundancy. For example, deploying double replication in place of triple replication. Such an implementation would reduce server count and rack space, lower network utilization, and decrease the quantity of any required node-level licenses.”





