IBM is adding a server and software to its Diamondback tape library to build an on-premises S3 object storage archive.
The DiamondBack (TS6000), introduced in October last year, is a single-frame tape library with up to 14 TS1170 tape drives and 1,458 tape LTO-9 cartridges, storing 27.8PB of raw data, and 69.6PB with 2.5:1 compression. It transfers data at up to 400MBps with 12 drives active and has a maximum 17.2TB/hour transfer rate.
Diamondback
DiamondBack S3 has an added x86 server, as the image shows, which provides the S3 interface and S3 object-to-tape cartridge/track mapping. Client systems will send Get (read) and Put (write) requests to DiamondBack S3 and it will read S3 objects from, or write the objects to, a tape cartridge mounted in one of the drives.
IBM’s Advanced Technology Group Tape Team is running an early access program for this Diamondback S3 tape library. Julien Demeulenaere, sales leader EMEA – Tape & High-End Storage, says Diamondback S3 will be a low-cost repository target for a secure copy of current or archive data. It will enable any user familiar with S3 to move their data to Diamondback S3. A storage architect can sign up for a 14-day shared trial on a Diamondback S3 managed by IBM, so they can verify the behavior of S3 for tape.
The S3-object-on-tape idea is not new, as seen with Germany’s PoINT Software and Systems and its Point Archival Gateway product. This provides unified object storage with software-defined S3 object storage for disk and tape, presenting their capacity in a single namespace. It is a combined disk plus tape archive product with disk random access speed and tape capacity.
Archiving systems supplier XenData has launched an appliance which makes a local tape copy of a public cloud archive to save on geo-replication and egress fees.
Quantum has an object-storage-on-tape tier added to its ActiveScale object storage system, providing an on-premises Amazon S3 Glacier-like managed service offering. SpectraLogic’s BlackPearl system can also provide an S3 interface to a backend tape library.
DiamondBack S3 does for objects and tape what the LTFS (Linear Tape File System) does for files and tape, with its file:folder interface to tape cartridges and libraries. Storing objects on tape should be lower cost than storing them on disk, once a sufficient amount has been put on the tapes – but at the cost of longer object read and write times compared to disk. IBM suggests it costs four times less than AWS Glacier with, of course, no data egress fees.
Demeulenaere told us: “There is no miracle, we can’t store bucket on tape natively. It’s just a software abstraction layer on the server which will present the data as S3 object to the user. So, from a user point of view, they just see a list of bucket and can only operate it with S3 standard command (get/put). But it is still files that are written by the tape drive. The server will be accessed exclusively through Ethernet; dual 100GB port for the S3 command, one GB Ethernet port for admin.
“The server is exclusively for object storage. It can’t be a file repository target. For that, you will need to buy the library alone (which is possible) and operate it as everybody is doing (FC, backup server).”
Secure Data Recovery (SDR) is offering to rescue files up to 256KB from corrupted SanDisk Extreme SSDs for free. A $79.99 licence fee is required for larger file recoveries.
Some 2TB and 4TB Western Digital SanDisk Extreme Pro, Extreme Portable, Extreme Pro Portable and MyPassport SSDs, released in 2023, have suffered data loss due to a possible firmware bug. This has sparked a lawsuit which hopes to become a class action. Secure Data Recovery thinks it has a way to salvage most if not all of the data from such drives.
SDR reckons the firmware bug messes up allocation metadata which stops the SSD managing data distribution among its flash pages and cells. SDR says its “software detects traces of scrambled metadata and file indexes. Once located, it pieces the information together and retrieves the data.” It is providing a process to recover the lost data with users paying a license fee if files above a certain size are recovered. We haven’t tried this process or verified it and include it here for information purposes only.
SanDisk Extreme Pro SSD.
The sequence of operations a user needs to carry out, after connecting the SSD to a PC or Mac host, is this:
2) Select the location containing lost data. That is C: drive for most users.
3) Select Quick File Search or Full Scan.
4) Choose the relevant file or folder.
5) Continue with the relevant subfolder if applicable.
6) Select the file from the list on the right.
7) Click to select the output folder for recoverable files. That is the E: drive for most users.
8) Click Recover in the bottom-right corner of the window. A status update will appear if successful.
9) Click Finish in the bottom-right corner of the window.
SDR says that “sometimes, the parent folder structure is lost in the process. However, the files inside them are unaffected. Most subfolders remain intact. Recovered files from missing directories are assigned to a Lost and Found folder.”
The company is a SanDisk platinum partner for its recovery services under a no-data-no-recovery-fee deal. WD’s data recovery webpage lists four US-based recovery operators: Ontrack Data Recovery, Drive SaversDataRecovery, Datarecovery.com and Secure Data Recovery.
Ascend.io’s CEO/founder Sean Knapp says he believes that the data ingestion market won’t exist within a decade, because cloud data players will provide free connectors and different ways to connect to external sources without moving data. He thinks consolidation in the data stack industry is reaching new heights as standalone capabilities are getting absorbed into the major clouds.
…
SaaS app and backup provider AvePoint reported Q2 revenue of $64.9 million, up 16 percent year on year. SaaS revenue was $38.3 million, up 39 percent year on year, and its total ARR was $236.2 million, up 26 percent. There was a loss of $7.1 million, better than the year-ago $11.1 million loss. It expects Q3 revenues to be $67.6 to $69.6 million, up 9 percent year on year at the mid-point.
…
Backblaze, which supplies cloud backup and general storage services, has hired Chris Opat as SVP for cloud operations. Backblaze has more than 500,000 customers and three billion gigabytes of data under management. Opat will oversee cloud strategy, platform engineering, and technology infrastructure, enabling Backblaze to scale capacity and improve performance and provide for the growing pool of larger-sized customers’ needs. Previously, he was SVP at StackPath, a specialized provider in edge technology and content delivery. He also spent time at CyrusOne, CompuCom, Cloudreach, and Bear Stearns/JPMorgan.
…
An IBM Research paper and presentation [PDF] proposes to decouple a file system client from its backend implementation by virtualizing it with an off-the-shelf DPU using the Linux virtio-fs/FUSE framework. The decoupling allows the offloading of the file system client execution to an ARM Linux DPU, which is managed and optimized by the cloud provider, while freeing the host CPU cycles. The proposed framework – DPFS, or DPU-powered File System Virtualization – claims to be 4.4× more CPU efficient per I/O, delivers comparable performance to a tenant with zero-configuration or modification to their host software stack, while allowing workload-specific backend optimizations. This is currently only available with the limited technical preview program of Nvidia BlueField.
…
MongoDB has launched Queryable Encryption with which data can be kept encrypted while it’s being searched. Customers select the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use. With this the content of the query and the data in the reference field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption and is open source.
MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys.
…
Nexsan – the StorCentric brand survivor after its Chapter 11 bankruptcy and February 2023 purchase by Serene Investment Management – has had a second good quarter after its successful Q1. It said it accelerated growth in Q2 by delivering on a backlog of orders that accumulated during restructuring after it was acquired. Nexsan had positive operational cash flow and saw growth, particularly in APAC. It had a 96 percent customer satisfaction rating in a recent independent survey.
CEO Dan Shimmerman said: “Looking ahead, we’re recruiting in many areas of the company, including key executive roles, and expanding our sales and go-to-market teams. Additionally, we’re working on roadmaps for all our product lines and expect to roll these out in the coming months.”
…
Nyriad, which supplies UltraIO storage arrays with GPU-based controllers, is partnering with RackTop to combine its BrickStor SP cyber storage product with Nyriad’s array. The intent is to safeguard data from modern cyber attacks, offering a secure enterprise file location accessible via SMB and NFS protocols and enabling secure unstructured data services. The BrickStor Security Platform continually evaluates trust at the file level, while Nyriad’s UltraIO storage system ensures data integrity at the erasure coded block level. BrickStor SP grants or denies access to data in real time without any agents, detecting and mitigating cyberattacks to minimize their impact and reduce the blast radius. Simultaneously, the UltraIO storage system verifies block data integrity and dynamically recreates any failed blocks seamlessly, ensuring uninterrupted operations. More info here.
…
Cloud file services supplier Panzura has been ranked at 2,075 on the 2023 Inc. 5000 annual list of fastest-growing private companies in America, with a 271 percent increase year on year in its ARR. Last year Panzura was ranked 1,343 with 485 percent ARR growth. This year the Inc. 5000 list also mentions OwnBackup at 944 with 625 percent revenue growth, VAST Data at 2,190 with 254 percent growth, and Komprise at 2,571 with 212 percent growth. SingleStore and OpenDrives were both on the list last year but don’t appear this year.
…
Real-time database supplier Redis has upgraded its open source and enterprise product to Redis v7.2, adding enhanced store vector embeddings and a high-performance index and query search engine. It is previewing a scalable search feature which enables a higher query throughput, including VSS and full-text search, exclusively as part of its commercial offerings. It blends sharding for seamless data expansion with efficient vertical scaling. This ensures optimal distributed processing across the cluster and improves query throughput by up to 16x compared to what was previously possible.
The latest version of the Redis Serialization Protocol (RESP3) is now supported across source-available, Redis Enterprise cloud and software products for the first time. Developers can now program, store, and execute Triggers and Functions within Redis using Javascript. With Auto Tiering, operators can keep heavily used data in memory and move less frequently needed data to SSD. Auto Tiering offers more than twice the throughput of the previous version while reducing the infrastructure costs of managing large datasets in DRAM by up to 70 percent.
The preview mode Redis Data Integration (RDI) transforms any dataset into real-time accessibility by seamlessly and incrementally bringing data from multiple sources to Redis. Customers can integrate with popular data sources such as Oracle Database, Postgres, MySQL, and Cassandra.
…
Silicon Motion has confirmed the termination of the merger agreement with MaxLinearand intends to pursue substantial damages in excess of the agreement’s termination fee due to MaxLinear’s willful and material breaches of the merger agreement. A July 26 MaxLinear statement said:”MaxLinear terminated the Merger Agreement on multiple grounds, including that Silicon Motion has experienced a material adverse effect and multiple additional contractual failures, all of which is clearly supported by the indisputable factual record. MaxLinear remains entirely confident in its decision to terminate the Agreement.” A July 26 8-K SEC filing contains a little more information.
…
HA and DR supplier SIOS has signd with ACP IT Solutions GmbH Dresden top disribute its products in Germany, Switzerland, and Austria.
…
SK hynix is mass-producing its 24GB LPDDR5X DRAM, the industry’s largest capacity.
Robert Scoble
…
Decentralized storage provider Storj has a partnership with Artificial Intelligence-driven mental health tech company MoodConnect. The two intend to unveil a state-of-the-art mental health tracker designed to help individuals and corporations capture, store, and share sentiment data securely. MoodConnect empowers users to track, store and share their own emotion data from conversations and to securely possess this data for personal introspection, to share with healthcare professionals, with friends and family, or to gauge organizational sentiment within a company. It will use Storj distributed storage. MoodConnect has appointed Robert Scoble as its AI advisor.
Broadcom has unveiled its updated 256-port and 512-port Fibre Channel Director switches, operating at 64Gbps. This represents the seventh generation of Fibre Channel storage networking technology, accompanied by a higher-capacity extension switch.
Fibre Channel (FC) is a lossless networking scheme used in Storage Area Networks (SANs). The seventh-generation FC succeeds the 32Gbps Gen 6 version. Systems, including servers and storage arrays, employ FC host bus adapters for switch connections and subsequent access to host systems. The larger switches with the most network ports are termed Directors, while devices designed for long-distance links are known as Extension Switches. Almost three years after launching its first 64Gbps Fibre Channel (FC) switch gear, Broadcom is updating its products with more 64Gbps ports.
Broadcom’s Dennis Makishima, VP and GM for its Brocade Storage Networking division, said: “High density and global network extension technology enables Broadcom customers to build datacenter infrastructure that is scalable, secure, and reliable.”
Broadcom Brocade X7-8 and X7-4 Directors in their 14RU and 8RU chassis
In 2020, Broadcom announced the first-generation Brocade brand X7 Directors with up to 384 64Gbps line rate ports, using 8 x 48-ports or 512 x 32Gbps ports, G720 switches with 56 x 64Gbps line rate ports in a 1RU design, and 7810/7840 extension switches. Now it has been able to work up to providing 512 x 64Gbps ports in the X7 Director by using a new 64-port blade with SFP-DP transceivers, which is 33 percent faster, it says, than the prior transceivers.
Broadcom has also added the 64Gbps Brocade 7850 Extension Switch to the product set, enabling faster worldwide scale and delivering up to 100Gbps over long distances. It manages the longer latency and packet losses that occur with such extended distances. The new switch complements the existing 7810 switch, with its 12 x 32Gbps FC and 6 x 1/10Gbps Ethernet ports, and also the 7840 with its 24 x 16Gbps FC/FICON and 16 x 1/10Gbps Ethernet ports. FICON is the Fibre Channel IBM mainframe link.
Brocade 7850 Extension Switch
The 7850 is significantly faster than the 7810 and 7840, with 24 x 64Gbps FC and FICON ports, and 16 x 1/10/25Gbps and 2 x 100Gbps Ethernet ports. It supports in-flight encryption and can be used to hook up a disaster recovery site to the main site, with lossless failover between WAN links.
Cisco’s MDS 9700 Fibre Channel Director uses a 48-Port 64Gbps Fibre Channel Switching Module (blade). Its MDS 9000 24/10-Port Extension Module provides 24 x 2/4/8/10/16Gbps FC ports and 8 x 1/10 Gbps Ethernet Fibre Channel over IP (FCIP) ports. Broadcom’s new gear is faster.
There is backwards compatibility for 8, 16, and 32Gbps Fibre Channel with the new Broadcom products. The Brocade X7 Director and 7850 Extension Switch are available now. Get an X-7 Director product brief here and 7850 Extension Switch details here.
Supermicro has launched a PCIe gen 5 storage server line with E3.S flash drives and CXL memory expansion support aimed squarely at the HPC and ChatGPT-led AI/ML markets.
The EDSFF’s E3.S form factor updates and replaces the U.2 2.5-inch drive format, inherited from the 2.5-inch disk drive days. Supermicro is supporting single AMD and dual Intel CPU configurations in either 1RU or 2RU chassis, with up to four CXL memory modules (CMM) in the 1RU chassis, and NVMe SSDs filling the E3.S slots. Given that they use the latest AMD and Intel processors, these are likely the fastest raw spec storage servers on the market and are aimed at the AI inferencing and training markets.
Supermicro president and CEO Charles Liang said: “Our broad range of high-performance AI solutions has been enhanced with NVMe based Petabyte scale storage to deliver maximum performance and capacities for our customers training large AI models and HPC environments.”
The systems support up to 256TB/RU of capacity, meaning a full rack could hold 10.56PB of raw storage.
There are four separate products or SKUs and a table lists their characteristics:
The 1RU models can accommodate up to 16 hot-swap E3.S drives, or eight E3.S drives, plus four E3.S 2T 16.8mm bays for CMM and other emerging modular devices. The 2RU servers support up to 32 hot-swap E3.S drives. Maximum drive capacity is 15.36TB in the E3.S format currently, but 30TB E3.S drives are coming later this year, and that will double the maximum capacity at 512TB/RU, meaning 1PB in 2U and 20PB in a full rack. The data density and raw access speed will seem incredible to users with arrays of 7 or 15TB PCIe gen 3 or 4 drives.
Both Kioxia and Solidigm are working with Supermicro to get their coming higher-capacity SSDs supported by these new storage servers.
It’s likely that the other main storage server suppliers – Dell, HPE, and NetApp – will use similar designs for their scale-out storage hardware in the near future. A lids-off picture shows the basic Supermicro design: drives at the front, then fans, logic, memory and processors in the middle, with power supplies and network ports at the back.
Clockwise from top left: single AMD 2U, dual-Intel 2U, dual-Intel 1U, single AMD 1U
UK startup BlueShift Memory has won an FMS 2023 Most Innovative Memory Technology award for its memory accelerating FPGA that it claims offers up to 1,000 times speed up for structured data set access.
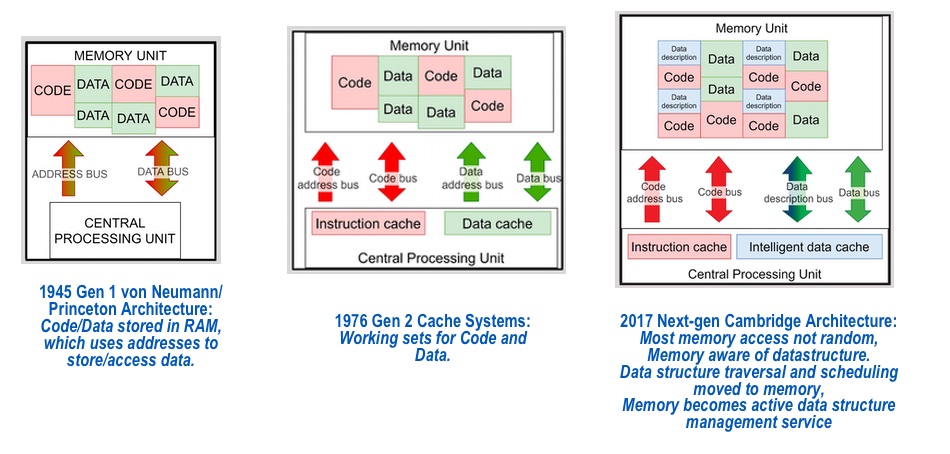
Fabless semiconductor company BlueShift was founded in 2016 in Cambridge, England, by CTO and ex-CEO Peter Marosan, a mathematician with experience in cloud and grid computing. He said he realized that a memory wall was developing between processors and memory with cores sitting idle between memory accesses because there was not enough CPU-memory bandwidth, with caching being rendered less useful as data set sizes increase.
Marosan said: “We have worked extremely hard over the past couple of years to prove the concept of our disruptive non-Von Neumann architecture and to develop our self-optimizing memory solution, and it is very rewarding to have our efforts acknowledged by the Flash Memory Summit Awards Program.”
He has devised the ‘Cambridge’ architecture to follow on from current cached CPU-memory systems developed from researchers at Harvard/Von Neumann/Princetonm who created architectures specifying CPU-memory interactions.
BlueShift diagrams
The Cambridge architecture way to provide more bandwidth is for the memory system to understand some data structures and stream data as it’s needed to the CPU cores instead of waiting for them to finish an instruction, move on to the one in cache, rinse and repeat, coping with cache misses and going to DRAM, etc.
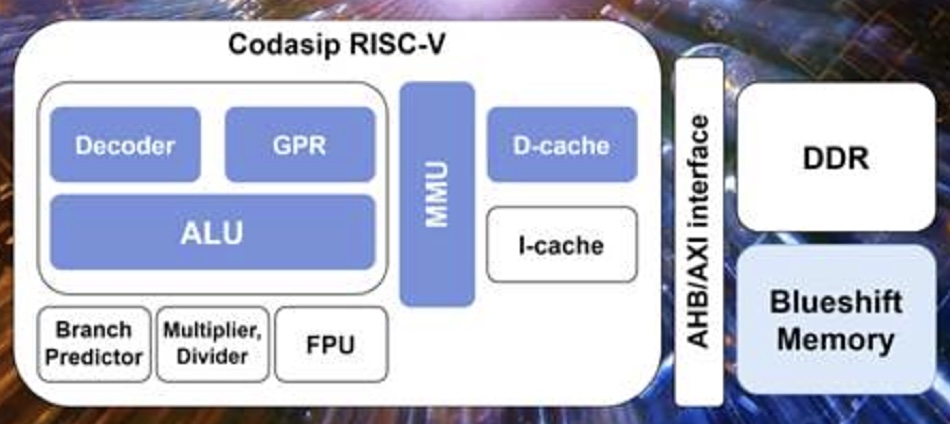
BlueShift has developed an FPGA featuring an integrated RISC-V Processor with a modified Codasip core to maximise memory bandwidth, and accelerate CPU core-DRAM access. It does this for HPC, AI, augmented and virtual reality machine vision, 5G Edge and IoT applications where large datasets have to be processed in as short a time as possible.
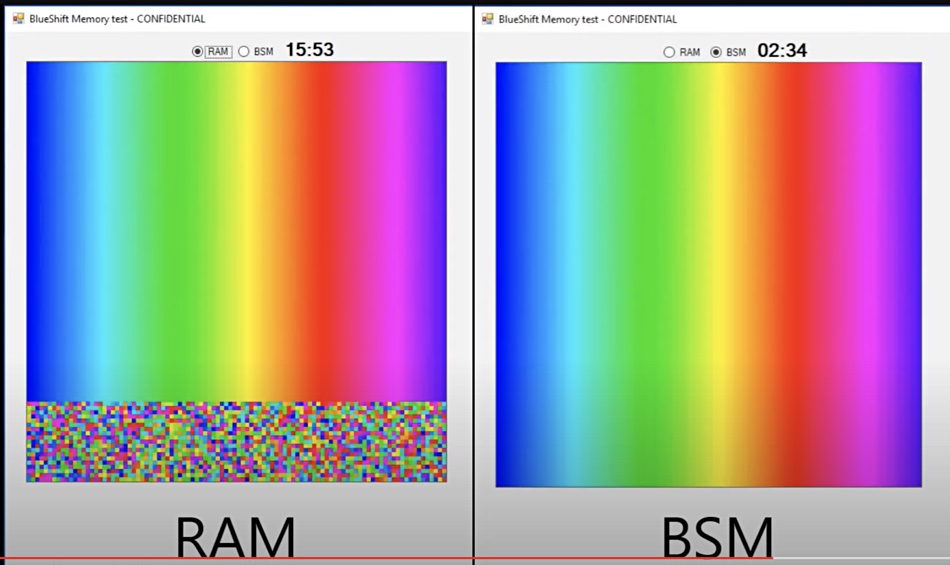
The sort job compared two systems sorting an array of random coloured squares into a spectrum. One was a 100 MHz CPU/DRAM system doing the job along with a 100MHz BlueShift Memory (BSM) system shipping data to its CPU. The BSM system completed the job in 2 minutes 34 secs while the unaided CPU system took 19 minutes and 34 secs, 8.3x longer.
Data sort demo with BSM system completed in 2 mons and 34 seconds.
BlueShift presented a paper, titled “Novel memory-efficient computer architecture integration in RISC-V with CXL” at FMS 2023. It reported that its demonstration BSM device had achieved an acceleration factor of 16 to 128 times for processing image data, along with ultra-low power consumption.
The BlueShift Memory IP can be integrated into either memory chips or processors, or can be used in a stand-alone memory controller. The company says it can cut memory energy access costs in half, and provide zero-latency memory accesses.
Nutanix has launched a turnkey GPT-in-a-box for customers to run large language model AI workloads on its hyperconverged software platform.
Update: Nutanix does not support Nvidia’s GPU Direct protocol. 5 Sep 2023.
GPT (Generative Pre-trained Transformer) is a type of machine learning large language model (LLM) which can interpret text requests and questions, search through multiple source files and respond with text, image, video or even software code output. Sparked by the ChatGPT model, organizations worldwide are considering how adopting LLMs could improve marketing content creation, make chatbot interactions with customers better, provide data scientist capabilities to ordinary researchers, and save costs while doing so.
Greg Macatee, an IDC Senior Research Analyst, Infrastructure Systems, Platforms and Technologies Group, said: “With GPT-in-a-box, Nutanix offers customers a turnkey, easy-to-use solution for their AI use cases, offering enterprises struggling with generative AI adoption an easier on-ramp to deployment.”
Nutanix wants to make it easier for customers to trial and use LLMs by crafting a software stack including its Nutanix Cloud Infrastructure, Nutanix Files and Objects storage, and Nutanix AHV hypervisor and Kubernetes (K8S) software with Nvidia GPU acceleration. Its Cloud Infrastructure base is a software stack in its own right, including compute, storage and network, hypervisors and containers, in public or private clouds. GPT-in-a-box is scalable from edge to core datacenter deployments, we’re told.
The GPU acceleration involves Nutanix’s Karbon Kubernetes environment supporting GPU passthrough mode on top of Kubernetes.
Thomas Cornely, SVP, Product Management at Nutanix, said: “Nutanix GPT-in-a-Box is an opinionated AI-ready stack that aims to solve the key challenges with generative AI adoption and help jump-start AI innovation.”
We’ve asked what the “opinionated AI-ready stack” term means and Nutanix’answer is: “The AI stack is “opinionated” as it includes what we believe are the best in class components for the model runtimes, Kubeflow, PyTorch, Torchserve, etc. The open source ecosystem is fast moving and detailed knowledge of these projects allows us to ensure the right subset of components are deployed in the best manner.’’
Nutanix is also providing services to help customers size their cluster and deploy its software with open source deep learning and MLOps frameworks, inference server, and a select set of LLMs such as Llama2, Falcon GPT, and MosaicML.
Data scientists and ML administrators can consume these models with their choice of applications, enhanced terminal UI, or standard CLI. The GPT-in-a-box system can run other GPT models and fine tune them by using internal data, accessed from Nutanix Files or Objects stores.
Gratifyingly for Nutanix, a recent survey found 78 percent of its customers were likely to run their AI/ML workloads on the Nutanix Cloud Infrastructure. As if by magic, that bears out what IDC’s supporting quote said above.
Nutanix wants us to realize it has AI and open source AI community credibility through its:
Participation in the MLCommons (AI standards) advisory board
Co-founding and technical leadership in defining the ML Storage Benchmarks and Medicine Benchmarks
Serving as a co-chair of the Kubeflow (MLOps) Training and AutoML working groups at the Cloud Native Computing Foundation (CNCF)
Get more details about this ChatGPT-in-a-box software stack from Nutanix’s website.
Bootnote. Nutanix’ Acropolis software supports Nvidia’s vGPU feature, in which a single GPU is shared amongst accessing client systems, each seeing their own virtual GPU. It does not support Nvidia’s GPUDirect protocol for direct access to NVMe storage, bypassing a host CPU and its memory (bounce buffer).
Coughlin Associates’ recent forecast on disk, SSD, and tape shipments extending to 2028 suggests that the rise in SSD sales will have minimal impact on disk drive shipments, contrary to some predictions of a complete phase-out of disk drives
Pure Storage is vigorously asserting that no new disk drives will be sold after 2028. CEO Charlie Giancarlo said in June: “The days of hard disks are coming to an end – we predict that there will be no new hard disks sold in 5 years.”
This is based on Pure’s belief that flash drives, especially the high-capacity QLC (4bits/cell) drives, are reducing the total cost of ownership for all-flash arrays to a point lower than that of disk arrays.
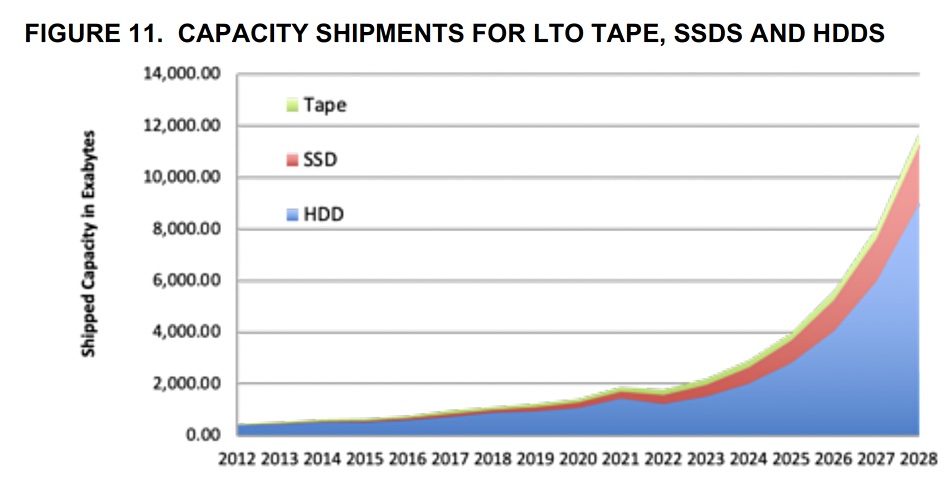
Yet this forecast is not shared by Thomas Coughlin in his August 2023 Digital Storage Technology newsletter. Page 151 of the newsletter has a chart forecasting tape, SSD and HDD capacity shipment out to 2028, which shows no decline in HDD capacity growth at all:
The report text states: ”The chart [above] is the latest Coughlin Associates history and projections for hard disk drive, solid state drive and tape capacity shipments out to 2028. Barring a significant economic downturn, we expect demand for digital storage to support AI, IoT, media and entertainment as well as genomic and other medical applications to drive increased storage demand. This should bring growth back to HDDs, SSDs and magnetic tape capacity shipments as all of these storage media increase in their per-device storage capacities.”
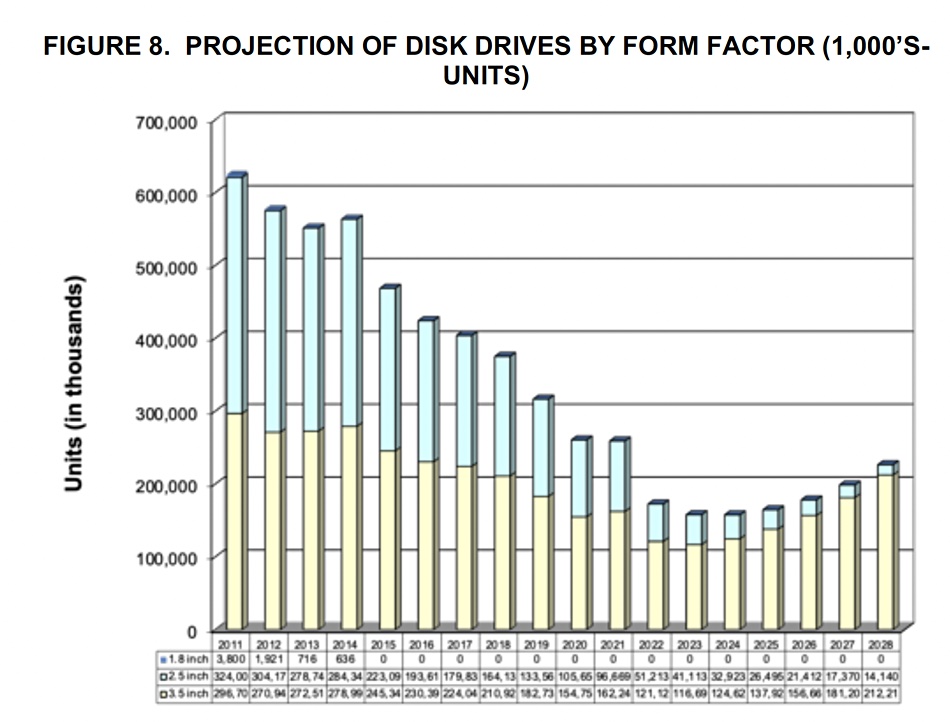
A separate chart looks at disk drive form factor unit shipments out to 2028, and shows a recent decline reversing:
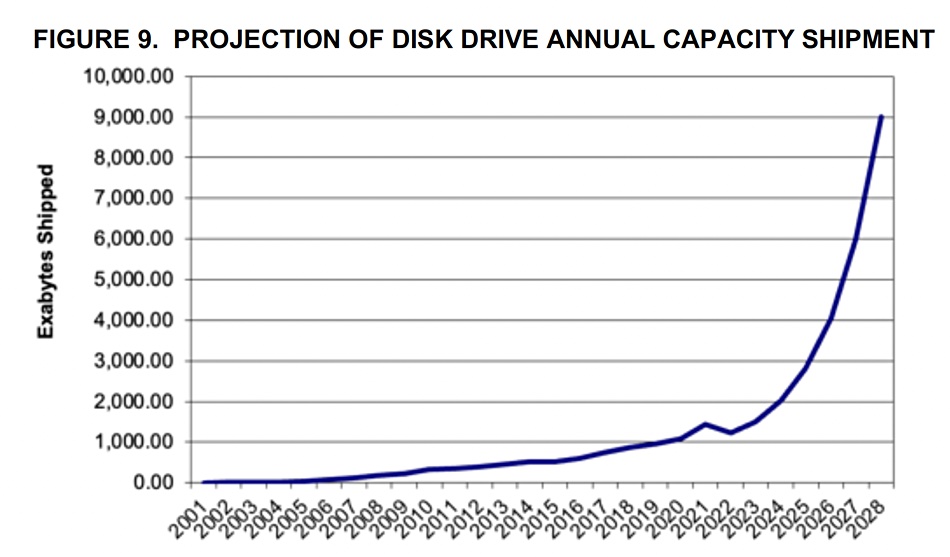
The yellow bars are 3.5-inch drives with the blue bars being 2.5-inch units. A disk drive capacity ship forecast also shows a steep rise to 2028:
The report says: “We project a doubling of head and media demand by 2028, assuming a recovery in the nearline market starting in later 2023 or early 2024. The growth of capacity-oriented Nearline drives for enterprise and hyperscale applications will result in more components per drive out to 2028 and provides the biggest driver for heads and media.”
The industry seems to be divided on this matter. While Thomas Coughlin believes in the continued growth of disk drives, Charlie Giancarlo predicts a dominant future for flash drives. The outcome by 2028 will determine which perspective holds true.
IBM claims it has the fastest storage node data delivery to Nvidia GPU servers with its ESS 3500 hardware and Storage Scale parallel file system.
Nvidia GPU servers are fed data through its GDS (Magnum GPU Direct) protocol which bypasses source data system CPUs by setting up a direct link to the storage subsystem. We had previously placed IBM in second place behind a DDN AI400X2/Lustre system, with that ranking based on IBM’s ESS 3200 hardware.
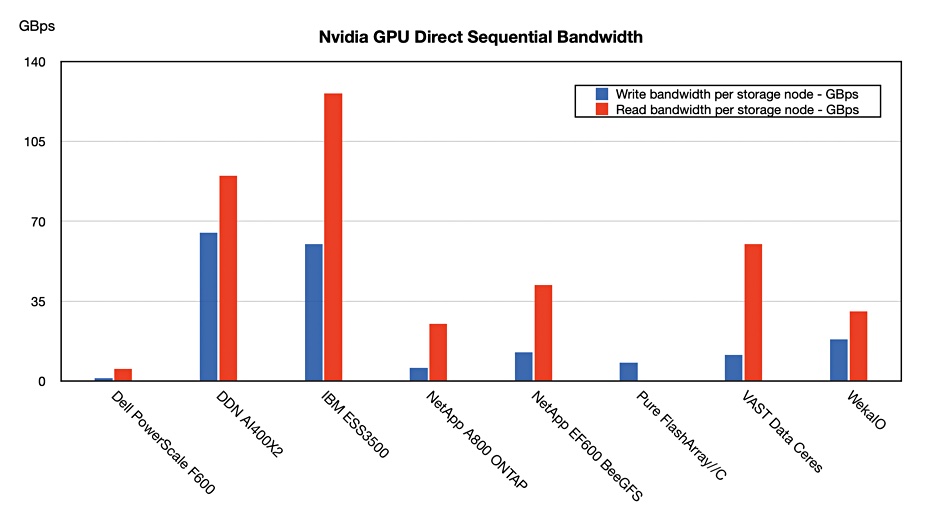
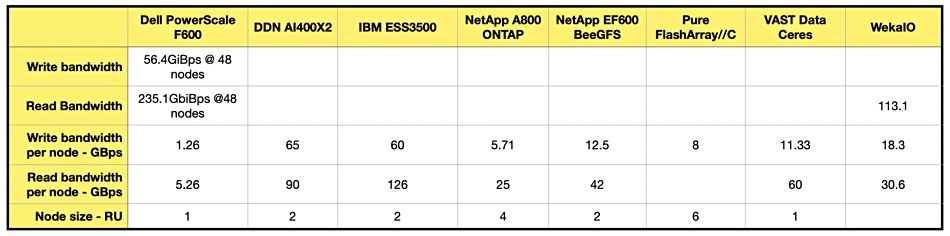
IBM told us about a faster result with its ESS 3500 storage system, which has a faster IO controller processor, an AMD 48-core EPYC 7642 vs the ESS 3200’s 48-core EPYC 7552. The ESS 3200’s 31/47GBps sequential write/read bandwidth gets upgraded to 60/126GBps with the ESS 3500. A chart shows the comparison of this against the DDN, VAST, Pure, NetApp and, Dell PowerScale systems:
IBM leads on read bandwidth and is second to DDN on write bandwidth. Here are are the numbers behind the chart:
The ESS 3500 has a Power9 processor-based management server runing Storage Scale, the rebranded Spectrum Scale parallel filesystem software, with a cluster of building blocks providing the actual storage. Each building block is a pair of X86 CPU-based IO servers attached to one to four external storage chassis containing PCIe gen 4 NVMe drives. The system supports 100Gbit Ethernet or InfiniBand running at 100Gbps (EDR) or 200Gbps (HDR). There’s a lot more information in an IBM ESS 3500 presentation.
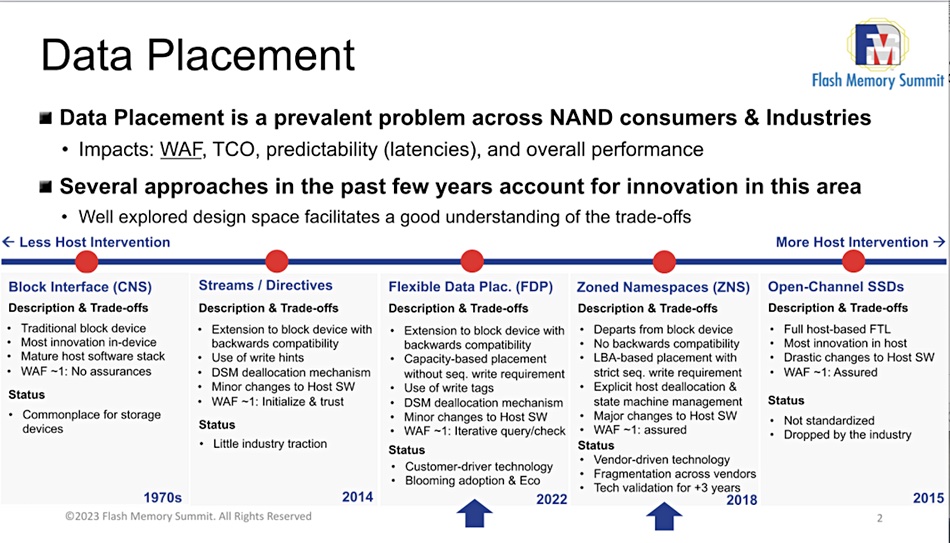
Analysis: ZNS and FDP are two technologies for placing data more precisely on SSDs to lengthen their working life and improve performance. How do they work? Will both be adopted or will one prevail?
ZNS (Zoned Name Space) and FDP (Flexible Data Placement) have the server hosting an SSD tell its controller where to place data so as to reduce the number of writes needed when the controller recovers deleted space for reuse.
The reason this is needed is that there is a mismatch between an SSD’s writing and deleting data processes, which results in the SSD writing more data internally than is actually sent to it. This is called write amplification. If 1MB of data is written to the SSD and it internally writes 2.5MB of data then it has a write amplification factor (WAF) of 2.5. Since NAND cells have a fixed working life – in terms of the number of times that data can be written to them – then reducing the write amplification factor as much as possible is desirable. And greatly so for hyperscalers who can have thousands of SSDs.
Write amplification
An SSD has its cells organized in blocks. Blocks are sub-divided into 4KB to 16KB pages – perhaps 128, 256 or even more of them depending upon the SSD’s capacity.
Data is written at the page level, into empty cells in pages. You cannot overwrite existing or deleted data with fresh data. That deleted data has to be erased first, and an SSD cannot erase at the page level. Data is erased by setting whole blocks, of pages and their cells, to ones. Fresh data (incoming to the SSD) is written into empty pages. When an SSD is brand new and empty then all the blocks and their constituent pages are empty. Once all the pages in an SSD have been written to once, then empty pages can only be created by recovering pages from blocks which have deleted data in them – from which data has been removed, or erased.
When data on an SSD is deleted, a flag for the cells occupied by the data is set to stale or invalid so that subsequent read attempts for that data fail. The data is only actually erased when the block containing those pages is erased.
SSD terminology has it that pages are programmed (written) or erased. NAND cells can only endure so many program/erase or P/E cycles before they wear out. TLC (3bits/cell) NAND can support 3,000 to 5,000 P/E cycles, for example.
Over time, as an SSD is used, some of the data in the SSD is deleted and the pages that contain that data are marked as invalid. They now contain garbage, as it were. The SSD controller wants to recover the invalid pages so that they can be re-used. It does this at the block level by copying all the valid pages in the block to a different block with empty pages, rewriting the data, and marking the source pages as invalid, until the block only contains invalid pages. Then every cell in the block is set to one. This process is called garbage collection and the added write of the data is called write amplification. If it did not happen then the write amplification factor (WAF) would be 1.
Once an entire block is erased, which takes time, it can be used to store fresh, incoming data. SSD responsiveness can be maximized by minimizing the number of times it has to run garbage collection processes.
This process is internal to the SSD and carried out as a background process by the SSD controller. The intention is that it does not interfere with foreground data read/write activity and that there are always fresh pages in which to store incoming data.
Write amplification is an SSD feature that shortens working life.
Individual pages age (wear out) at different rates and an SSD’s working life is maximised by equalizing the wear across all its pages and blocks.
If particular blocks experience a high number of P/E cycles they can wear out and the SSD’s capacity is effectively reduced. ZNS and FDP are both intended to reduce write amplification.
ZNS
Applications using an SSD can be characterized as dealing with short-life data or long-life data and whether they are read- or write-intensive. When an SSD is used by multiple applications then these I/O patterns are mixed up. If the flash controller knew what kind of data it was being given to write then it could manage the writes better to maximize the SSD’s endurance.
One attempt to do this has been the Zoned Name Space (ZNS) concept, which is suited to sequentially-written data with both shingled media disk drives and SSDs. The Flexible Data Placement (FDP) concept does not have this limitation and is for NVMe devices – meaning prediminantly SSDs.
A zoned SSD has its capacity divided into separate namespace areas or zones which are used for data with different IO types and characteristics – read-intensive, write-intensive, mixed, JPEGs, video, etc. Data can only be appended to existing data in a zone, being written sequentially.
A zone must be erased for its cells to be rewritten. Unchanging data can be put into zones and left undisturbed with no need for garbage collection to be applied to these blocks.
A host application needs to tell the SSD which zones to use for data placement. In fact all the host applications that use the SSD need to give the controller zoning information.
FDP
The NVM Express organization is working on adding FDP to the NVMe command set. It is being encouraged by Meta’s Open Compute Project and also by Google, because hyperscalers with thousands of SSDs would like then to have longer working lives and retain their responsiveness as they age.
An OCP Global Summit FDP presentation (download slides here) by Google Software architect Chris Sabol and Meta’s Ross Stenfort, a storage hardware systems engineer, revealed that Google and Meta were each developing their own flexible data placement approaches and combined them to be more effective. As with ZNS, a host system tells the SSD where to place data. (See the Sabol-Stenfort pitch video here.)
The two showed an FDP diagram:
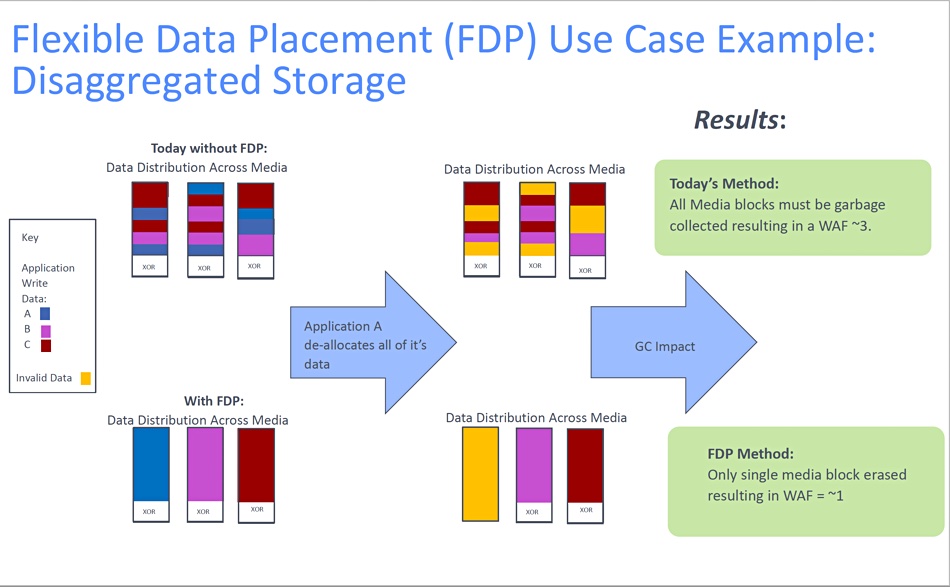
Javier González
In effect, data from an application is written to an application-specific area of the SSD, to a so-called reclaim unit or block/blocks. Without FDP, data from a mix of applications is written across all the blocks. When one app deallocated (deletes) its data then all the blocks must undergo garbage collection to reclaim the deleted space and the resulting WAF in this example is about 3.
With FDP in place then only one block is erased and the WAF is closer to 1. This reduces the amount of garbage collection, lengthens the drive’s endurance and helps maximize its responsiveness. An additional benefit is that there is a lower need for over-provisioning flash on the drive, and thus a lower cost.
Javier González of Samsung presented on FDP at the FMS 2023 event in Santa Clara this month and his slide deck can be seen at the bottom of a LinkedIn article – here.
He said FDP and ZNS are the latest in a series of moves attempting to lower SSD write amplification, as a slide showed:
In Samsing testing, ZNS applied to a RocksDB workload achieved a slightly better WAF reduction than FDP.
He said that both ZNS and FDP have potential roles to play. For ZNS: “If you are building an application from the ground up and can guarantee (i) sequential writes, (ii) fixed size objects, (iii) write error handling, and (iv) a robust I/O completion path to handle anonymous writes if you are using Append Command (which is mandatory in Linux), then ZNS is probably the way to go. You will achieve an end-to-end WAF of 1, and get the extra TCO benefits that ZNS devices provide.”
However, “ZNS is an explicit, strict interface. You either get all the benefits – which are plenty – or none.”
FDP is different: “If you are retrofitting an existing application where (i) writes are not always sequential, (ii) objects may be of different sizes, and (iii) the I/O path relies in existing, robust software, then FDP is probably your best bet.”
He writes: “Our experience building support for RocksDB, Cachelib, and lately XFS (still ongoing after four weeks) tells us that reaching the first 80 percent of the benefit is realistic without major application changes” for FDP.
He thinks both technologies could co-exist but believes that one will prevail and expand to cover different use-cases.
More engineering effort in the SSD hardware and software supplier and user ecosystem is needed for ZNS while FDP needs less engineering support from an application-oriented ecosystem.
Gonzalez thinks only one of these technologies will gain mainstream adoption, but doesn’t know which one. ZNS is best suited for applications designed around fully sequential writes, while FDP is a better fit for users starting to deploy data placement in their software ecosystem.
An NVM Express TP4146 – TP standing for Technical Proposal – deals with FDP and has been ratified.
Interview Rob Young serves as a storage architect at Mainline Information Systems, a Florida-based company specializing in systems design, development, consultancy, and services. With a rich legacy in IBM mainframes and Power servers, Mainline has been progressively transitioning to hybrid cloud and embracing the DevOps paradigm in recent times.
In our discussion, we delved into topics surrounding both monolithic and distributed, scale-out storage systems to gain insights into Rob’s perspectives on the evolution of high-end storage. Young posits that the future of Fibre Channel may be constrained and anticipates that high-end arrays will integrate with the major three public cloud platforms. He provided a lot of interesting points of view, prompting us to present this interview in two parts. Herein is the first installment.
Rob Young
Blocks & Files: What characterizes a high-end block array as distinct from dual-controller-based arrays?
Rob Young: Scalability and reliability. High-end comes with more pluggable ports, more throughput. [With] reliability, the gap is closing as Intel kit is found in the high-end and lower-tier space and has gained more RAS (reliability, availability, serviceability) features over the years. High-end [has] N+2 on power supplies and other components that don’t make their way into lower end (physically not enough room for large power supplies in some cases) and Infinidat’s Infinibox is famously N+2 on all components, including Intel-based controller heads. IBM’s DS8000 series is Power-based with a great RAS track record.
But not to be overlooked is high-end history. After decades with a number of these high-end arrays in the field, the solid service procedures, and deep skilled personnel to troubleshoot and maintain enterprise arrays, is a huge advantage come crunch time. For example, I was at a site with a new storage solution, field personnel didn’t quite follow an unclear procedure and caused an outage – thankfully prior to go-live.
Blocks & Files: What architectural problems do high-end array makers face in today’s market?
Rob Young: Funny you ask that. I’ve had several recent conversations just about that topic. History blesses and history curses. The issue here is something that was innovative 20 years ago is no longer innovative. Incumbency allows high-end to soldier on meeting business needs. You risk bad business outcomes if moving away from enterprise storage that your organization is familiar with, on a switch-up that your tech team had little input to the decision.
I’ve personally seen that happen on several occasions. New CIO, new IT director, new vendors that introduce their solutions that is not what you have on the floor. There are years of process and tribal knowledge you just can’t come up with in short order. That problem has been somewhat ameliorated by newcomers. Their APIs are easier to work with, their GUI interfaces are a delight, simpler procedures, HTML5 vs Java, data migrations are much simpler with less legacy OS about, etc. Petabytes on the floor and migrating test/dev in a week or less.
There are designs that are trapped in time which offer little or painfully slow innovation, and feature additions that require change freezes while they are introduced. Contrast that to Qumulo which transparently changed data protection via bi-weekly code pushes. (A 2015 blog describes how they delivered erasure coding incrementally.) I pointed out one vendor will never get their high-end array with 10 million+ lines of code into the cloud. Why is that even a concern? Well, we should anticipate an RFP checkbox that will require on-prem and big-three cloud for the same array. At that point, the array vendor without like-for-like cloud offering is in a tight spot. That may be happening already; I personally haven’t seen it.
Blocks & Files: How well do scale-up and scale-out approaches respond to these problems?
Rob Young: A good contrast here is a Pure Storage/IBM/Dell/NetApp mid-range design versus a traditional high-end implementation. You could have multiple two-controller arrays scattered across a datacenter, which itself may have multiple incoming power feeds in different sections of the datacenter. You’ve greatly increased availability and implement accordingly to take advantage of the layout at the host/OS/application layers. The incremental scaling nature here has obvious advantages and single pane management to boot.
Regarding scale-out and perhaps one ring to rule them all? We’ve seen where vendors have moved file into traditional block (Pure is a recent example) and now we will see block make its way into traditional file. Qumulo/PowerStore/Pure/Netapp could be your single array for all things, but architecturally that doesn’t give you that warm feeling. For example, you don’t want your backups flowing into the same storage as your enterprise storage.
Not just ransomware but what about data corruption – rare but happens. There is a whole host of reasons you don’t want backups in the same storage as the enterprise data you are backing up. We’ve seen it.
That’s where our company comes in. Mainline has been in the business of solutioning for decades and would assist in sorting out all these design options based on budget. The good vendor partners are assisting in getting it right, not just selling something.
One closing thought here on scale-out. I believe we are headed for a seismic shift away from Fibre Channel in the next 3–5 years. Why? 100Gbit Ethernet port costs will become “cheap” and you will finally be able to combine network+storage like cloud providers. Currently with a separate storage network (most large shops have SAN/Fibre Channel) that traffic is not competing with general network traffic. Having two separate domains of storage traffic and network traffic has several advantages, but I think cheap 100Gbit will finally be the unifier.
An additional benefit is that deep traditional Fibre Channel SAN skills will no longer be an enterprise need, like they are today. It will take time, but protocols like NVMe will eventually go end-to-end.
Blocks & Files: Does memory caching (Infinidat-style) have generic appeal? Should it be a standard approach?
Rob Young: When we say, “memory caching,” we mean the unique story that Infinidat calls Neural Cache. It delivers a significant speed-up of I/O. At the end of the day, it is all about I/O. I penned a piece that details how they’ve accomplished this, and it is an astounding piece of engineering. They took Edward Fredkin’s (he recently passed in June at 88; what an amazing polymath he was!) prefix tree which Google implements as you type with hints for the next word.
Infindat uses this same method to track each 64K chunk of data via timestamps and from that can pre-fetch into memory the next-up series of I/O. This results in a hit rate from the controller memory north of 90 percent. The appeal is a no-brainer as everyone is trying to speed up end of day, month-end runs.
Those runs occasionally bend and now the hot breath of management is on your neck wondering when the re-run will complete. A myriad number of reasons we all want to go faster and faster. Brian Carmody (former Infinidat CTO – now at Volumez) humbly described how they were first to perform neural caching.
That statement had me scratching my head. You see there are several granted patents that encompass what Infinidat is doing for caching. Unless I’m missing the obvious, others won’t be doing what Infinidat is doing until the patents expire.
In the meantime, some technology is sneaking up on them. We are seeing much larger memories showing up in controller designs. I’d guess a pre-fetch of entire LUNs into memory to close the gap on memory cache I/O hits could be coming.
Infinidat’s classic (disk) array has a minuscule random read I/O challenge and for applications that seem to have a portion of random I/O, their SSA (all-flash) system eliminates that challenge. We read that Infinibox SSA small random I/O (DB transactional I/O) has a ceiling of 300μs (microseconds) and that number catches our attention. We see that Volumez describes their small I/O as 316μs latency (360μs including hitting the host), AWS with their Virtual Storage Controller showing 353μs small I/O reads to NVMe-oF R5b instances (same ephemeral backends it seems).
You will read about hero numbers from others, but details are sparse with no public breakdown on numbers. The point here is it appears Infinidat will be at the top of the latency pyramid and several others filling in at 300μs with direct attach via PCI (cloud/VSAN) NVMe SSD.
Will we see faster than 300μs end-to-end? Yes, maybe even lurking today. Perhaps when the next spin on SLC becomes cheaper (and more common, or next go-fast tech) we see modestly sized SLC solutions with max small I/O latency in the 50–80μs range (round trip). DSSD lives again! Finally, what does a memory read cache hit on small I/O look like end-to-end? Less than 50μs for most vendors and Infinidat has publicly shown real-world speeds less than 40μs.
Part two of this interview will be posted in a week’s time.
Amazon Web Services (AWS) has integrated Hammerspace data orchestration to imrove its globally distributed render farm capabilities through AWS Thinkbox Deadline.
According to an AWS blog, AWS Thinkbox Deadline serves as a render manager that allows users to use a mix of on-premises, hybrid, or cloud-based resources for rendering tasks. The platform offers plugins tailored for specific workflows. The Spot Event Plugin (SEP) oversees and dynamically scales a cloud-based render farm based on the task volume in the render queue. This plugin launches render application EC2 Spot Instances when required and terminates them after a specified idle duration.
SEP supports multi-region rendering across any of the 32 AWS regions. With a single Deadline repository, users can launch render nodes in a preferred region. This offers regional choices to optimize costs or prioritize energy sustainability. For effective distributed rendering, the necessary data for a region’s render farm must be appropriately positioned.
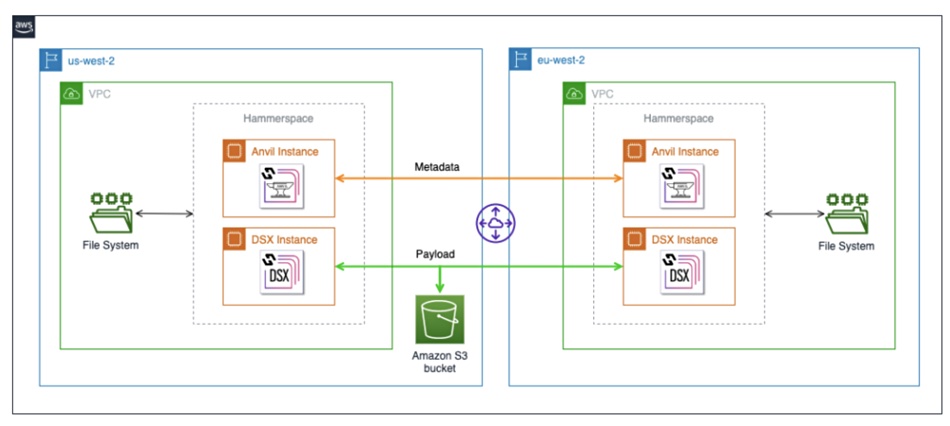
Along with Hammerspace, AWS has introduced an open source Hammerspace event plugin for Deadline. This plugin utilizes Hammerspace’s Global File System (GFS) to ensure data is transferred to its required location.
Hammerspace setup to sync file systems across two AWS Regions
The data is categorized into render farm content data and associated metadata. Hammerspace’s GFS Anvil Nodes consistently synchronize the metadata, which is typically a few kilobytes for larger files, across the involved regions. However, the content or payload data is synchronized by Hammerspace Data Service Nodes (DSX) when needed.
The nodes operate as EC2 instances, with DSX nodes using AWS S3 for staging. By default, payload data remains in its originating region. If required in another region, the primary DSX node transfers it to the destination node. Hammerspace’s directives and rules can be configured to establish policies for this process, ensuring files are pre-positioned as required.
The AWS blog has information about how Hammerspace and Deadline handle file:folder collisions to ensure a single version of file truth.
This is an example of how using Hammerspace can avoid the network traffic load of continuous file syncing and gives Hammerspace something of an AWS blessing.