Broadcom has unveiled its updated 256-port and 512-port Fibre Channel Director switches, operating at 64Gbps. This represents the seventh generation of Fibre Channel storage networking technology, accompanied by a higher-capacity extension switch.
Fibre Channel (FC) is a lossless networking scheme used in Storage Area Networks (SANs). The seventh-generation FC succeeds the 32Gbps Gen 6 version. Systems, including servers and storage arrays, employ FC host bus adapters for switch connections and subsequent access to host systems. The larger switches with the most network ports are termed Directors, while devices designed for long-distance links are known as Extension Switches. Almost three years after launching its first 64Gbps Fibre Channel (FC) switch gear, Broadcom is updating its products with more 64Gbps ports.
Broadcom’s Dennis Makishima, VP and GM for its Brocade Storage Networking division, said: “High density and global network extension technology enables Broadcom customers to build datacenter infrastructure that is scalable, secure, and reliable.”
Broadcom Brocade X7-8 and X7-4 Directors in their 14RU and 8RU chassis
In 2020, Broadcom announced the first-generation Brocade brand X7 Directors with up to 384 64Gbps line rate ports, using 8 x 48-ports or 512 x 32Gbps ports, G720 switches with 56 x 64Gbps line rate ports in a 1RU design, and 7810/7840 extension switches. Now it has been able to work up to providing 512 x 64Gbps ports in the X7 Director by using a new 64-port blade with SFP-DP transceivers, which is 33 percent faster, it says, than the prior transceivers.
Broadcom has also added the 64Gbps Brocade 7850 Extension Switch to the product set, enabling faster worldwide scale and delivering up to 100Gbps over long distances. It manages the longer latency and packet losses that occur with such extended distances. The new switch complements the existing 7810 switch, with its 12 x 32Gbps FC and 6 x 1/10Gbps Ethernet ports, and also the 7840 with its 24 x 16Gbps FC/FICON and 16 x 1/10Gbps Ethernet ports. FICON is the Fibre Channel IBM mainframe link.
Brocade 7850 Extension Switch
The 7850 is significantly faster than the 7810 and 7840, with 24 x 64Gbps FC and FICON ports, and 16 x 1/10/25Gbps and 2 x 100Gbps Ethernet ports. It supports in-flight encryption and can be used to hook up a disaster recovery site to the main site, with lossless failover between WAN links.
Cisco’s MDS 9700 Fibre Channel Director uses a 48-Port 64Gbps Fibre Channel Switching Module (blade). Its MDS 9000 24/10-Port Extension Module provides 24 x 2/4/8/10/16Gbps FC ports and 8 x 1/10 Gbps Ethernet Fibre Channel over IP (FCIP) ports. Broadcom’s new gear is faster.
There is backwards compatibility for 8, 16, and 32Gbps Fibre Channel with the new Broadcom products. The Brocade X7 Director and 7850 Extension Switch are available now. Get an X-7 Director product brief here and 7850 Extension Switch details here.
Supermicro has launched a PCIe gen 5 storage server line with E3.S flash drives and CXL memory expansion support aimed squarely at the HPC and ChatGPT-led AI/ML markets.
The EDSFF’s E3.S form factor updates and replaces the U.2 2.5-inch drive format, inherited from the 2.5-inch disk drive days. Supermicro is supporting single AMD and dual Intel CPU configurations in either 1RU or 2RU chassis, with up to four CXL memory modules (CMM) in the 1RU chassis, and NVMe SSDs filling the E3.S slots. Given that they use the latest AMD and Intel processors, these are likely the fastest raw spec storage servers on the market and are aimed at the AI inferencing and training markets.
Supermicro president and CEO Charles Liang said: “Our broad range of high-performance AI solutions has been enhanced with NVMe based Petabyte scale storage to deliver maximum performance and capacities for our customers training large AI models and HPC environments.”
The systems support up to 256TB/RU of capacity, meaning a full rack could hold 10.56PB of raw storage.
There are four separate products or SKUs and a table lists their characteristics:
The 1RU models can accommodate up to 16 hot-swap E3.S drives, or eight E3.S drives, plus four E3.S 2T 16.8mm bays for CMM and other emerging modular devices. The 2RU servers support up to 32 hot-swap E3.S drives. Maximum drive capacity is 15.36TB in the E3.S format currently, but 30TB E3.S drives are coming later this year, and that will double the maximum capacity at 512TB/RU, meaning 1PB in 2U and 20PB in a full rack. The data density and raw access speed will seem incredible to users with arrays of 7 or 15TB PCIe gen 3 or 4 drives.
Both Kioxia and Solidigm are working with Supermicro to get their coming higher-capacity SSDs supported by these new storage servers.
It’s likely that the other main storage server suppliers – Dell, HPE, and NetApp – will use similar designs for their scale-out storage hardware in the near future. A lids-off picture shows the basic Supermicro design: drives at the front, then fans, logic, memory and processors in the middle, with power supplies and network ports at the back.
Clockwise from top left: single AMD 2U, dual-Intel 2U, dual-Intel 1U, single AMD 1U
UK startup BlueShift Memory has won an FMS 2023 Most Innovative Memory Technology award for its memory accelerating FPGA that it claims offers up to 1,000 times speed up for structured data set access.
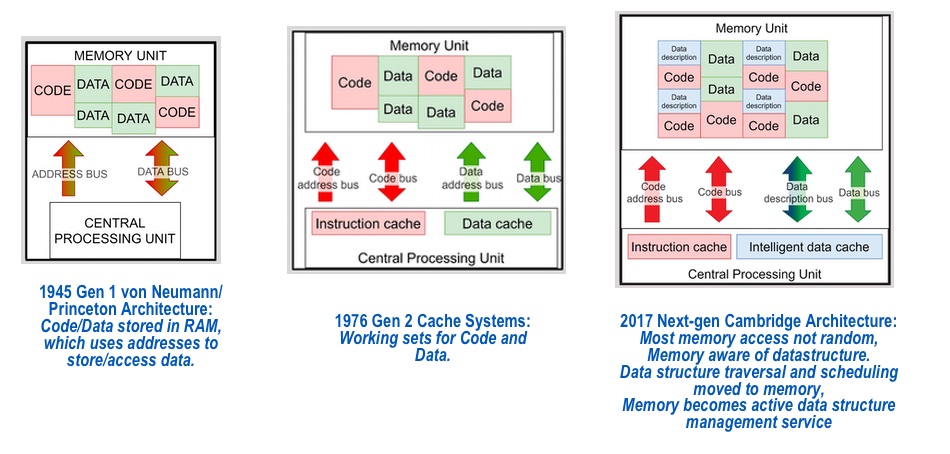
Fabless semiconductor company BlueShift was founded in 2016 in Cambridge, England, by CTO and ex-CEO Peter Marosan, a mathematician with experience in cloud and grid computing. He said he realized that a memory wall was developing between processors and memory with cores sitting idle between memory accesses because there was not enough CPU-memory bandwidth, with caching being rendered less useful as data set sizes increase.
Marosan said: “We have worked extremely hard over the past couple of years to prove the concept of our disruptive non-Von Neumann architecture and to develop our self-optimizing memory solution, and it is very rewarding to have our efforts acknowledged by the Flash Memory Summit Awards Program.”
He has devised the ‘Cambridge’ architecture to follow on from current cached CPU-memory systems developed from researchers at Harvard/Von Neumann/Princetonm who created architectures specifying CPU-memory interactions.
BlueShift diagrams
The Cambridge architecture way to provide more bandwidth is for the memory system to understand some data structures and stream data as it’s needed to the CPU cores instead of waiting for them to finish an instruction, move on to the one in cache, rinse and repeat, coping with cache misses and going to DRAM, etc.
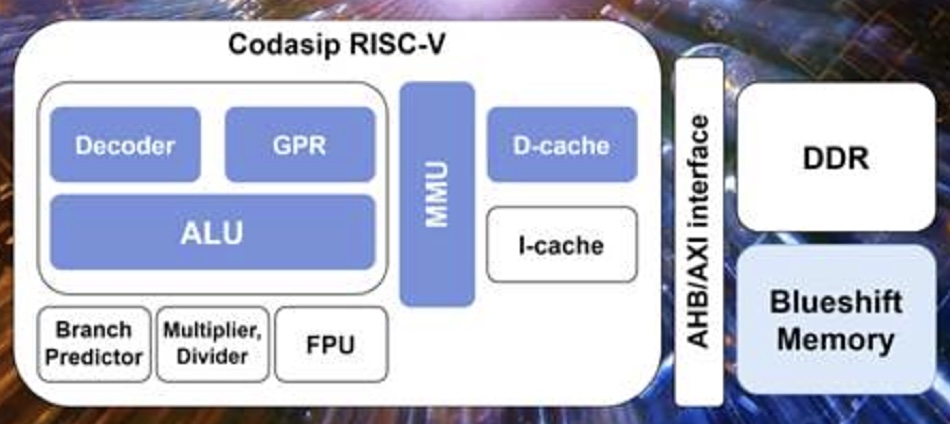
BlueShift has developed an FPGA featuring an integrated RISC-V Processor with a modified Codasip core to maximise memory bandwidth, and accelerate CPU core-DRAM access. It does this for HPC, AI, augmented and virtual reality machine vision, 5G Edge and IoT applications where large datasets have to be processed in as short a time as possible.
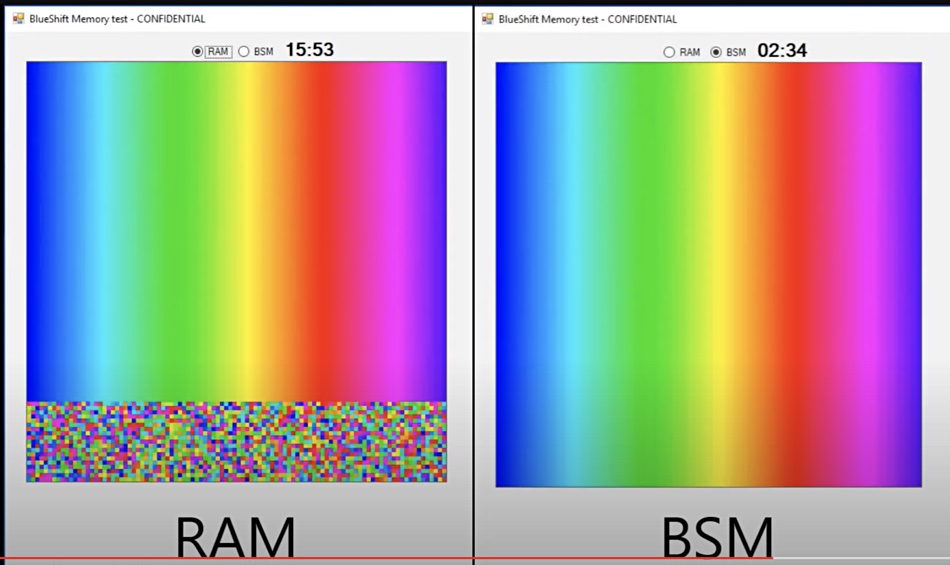
The sort job compared two systems sorting an array of random coloured squares into a spectrum. One was a 100 MHz CPU/DRAM system doing the job along with a 100MHz BlueShift Memory (BSM) system shipping data to its CPU. The BSM system completed the job in 2 minutes 34 secs while the unaided CPU system took 19 minutes and 34 secs, 8.3x longer.
Data sort demo with BSM system completed in 2 mons and 34 seconds.
BlueShift presented a paper, titled “Novel memory-efficient computer architecture integration in RISC-V with CXL” at FMS 2023. It reported that its demonstration BSM device had achieved an acceleration factor of 16 to 128 times for processing image data, along with ultra-low power consumption.
The BlueShift Memory IP can be integrated into either memory chips or processors, or can be used in a stand-alone memory controller. The company says it can cut memory energy access costs in half, and provide zero-latency memory accesses.
Nutanix has launched a turnkey GPT-in-a-box for customers to run large language model AI workloads on its hyperconverged software platform.
Update: Nutanix does not support Nvidia’s GPU Direct protocol. 5 Sep 2023.
GPT (Generative Pre-trained Transformer) is a type of machine learning large language model (LLM) which can interpret text requests and questions, search through multiple source files and respond with text, image, video or even software code output. Sparked by the ChatGPT model, organizations worldwide are considering how adopting LLMs could improve marketing content creation, make chatbot interactions with customers better, provide data scientist capabilities to ordinary researchers, and save costs while doing so.
Greg Macatee, an IDC Senior Research Analyst, Infrastructure Systems, Platforms and Technologies Group, said: “With GPT-in-a-box, Nutanix offers customers a turnkey, easy-to-use solution for their AI use cases, offering enterprises struggling with generative AI adoption an easier on-ramp to deployment.”
Nutanix wants to make it easier for customers to trial and use LLMs by crafting a software stack including its Nutanix Cloud Infrastructure, Nutanix Files and Objects storage, and Nutanix AHV hypervisor and Kubernetes (K8S) software with Nvidia GPU acceleration. Its Cloud Infrastructure base is a software stack in its own right, including compute, storage and network, hypervisors and containers, in public or private clouds. GPT-in-a-box is scalable from edge to core datacenter deployments, we’re told.
The GPU acceleration involves Nutanix’s Karbon Kubernetes environment supporting GPU passthrough mode on top of Kubernetes.
Thomas Cornely, SVP, Product Management at Nutanix, said: “Nutanix GPT-in-a-Box is an opinionated AI-ready stack that aims to solve the key challenges with generative AI adoption and help jump-start AI innovation.”
We’ve asked what the “opinionated AI-ready stack” term means and Nutanix’answer is: “The AI stack is “opinionated” as it includes what we believe are the best in class components for the model runtimes, Kubeflow, PyTorch, Torchserve, etc. The open source ecosystem is fast moving and detailed knowledge of these projects allows us to ensure the right subset of components are deployed in the best manner.’’
Nutanix is also providing services to help customers size their cluster and deploy its software with open source deep learning and MLOps frameworks, inference server, and a select set of LLMs such as Llama2, Falcon GPT, and MosaicML.
Data scientists and ML administrators can consume these models with their choice of applications, enhanced terminal UI, or standard CLI. The GPT-in-a-box system can run other GPT models and fine tune them by using internal data, accessed from Nutanix Files or Objects stores.
Gratifyingly for Nutanix, a recent survey found 78 percent of its customers were likely to run their AI/ML workloads on the Nutanix Cloud Infrastructure. As if by magic, that bears out what IDC’s supporting quote said above.
Nutanix wants us to realize it has AI and open source AI community credibility through its:
Participation in the MLCommons (AI standards) advisory board
Co-founding and technical leadership in defining the ML Storage Benchmarks and Medicine Benchmarks
Serving as a co-chair of the Kubeflow (MLOps) Training and AutoML working groups at the Cloud Native Computing Foundation (CNCF)
Get more details about this ChatGPT-in-a-box software stack from Nutanix’s website.
Bootnote. Nutanix’ Acropolis software supports Nvidia’s vGPU feature, in which a single GPU is shared amongst accessing client systems, each seeing their own virtual GPU. It does not support Nvidia’s GPUDirect protocol for direct access to NVMe storage, bypassing a host CPU and its memory (bounce buffer).
Coughlin Associates’ recent forecast on disk, SSD, and tape shipments extending to 2028 suggests that the rise in SSD sales will have minimal impact on disk drive shipments, contrary to some predictions of a complete phase-out of disk drives
Pure Storage is vigorously asserting that no new disk drives will be sold after 2028. CEO Charlie Giancarlo said in June: “The days of hard disks are coming to an end – we predict that there will be no new hard disks sold in 5 years.”
This is based on Pure’s belief that flash drives, especially the high-capacity QLC (4bits/cell) drives, are reducing the total cost of ownership for all-flash arrays to a point lower than that of disk arrays.
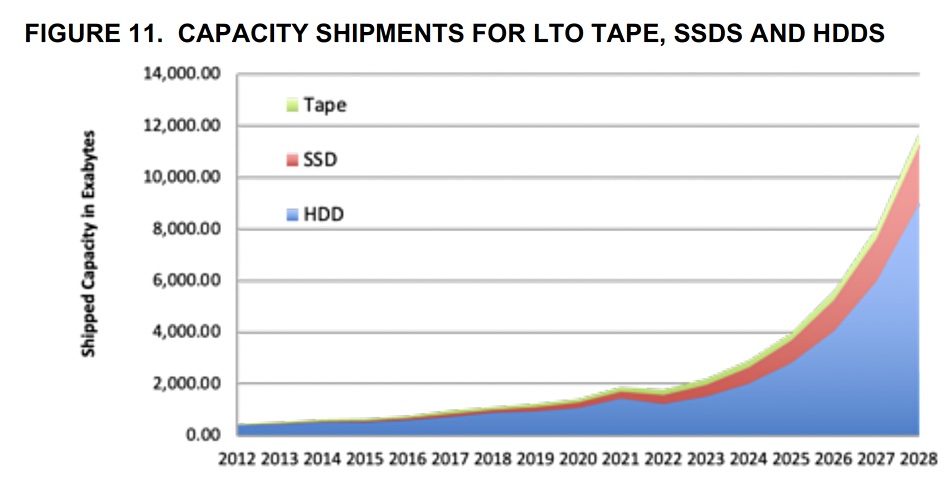
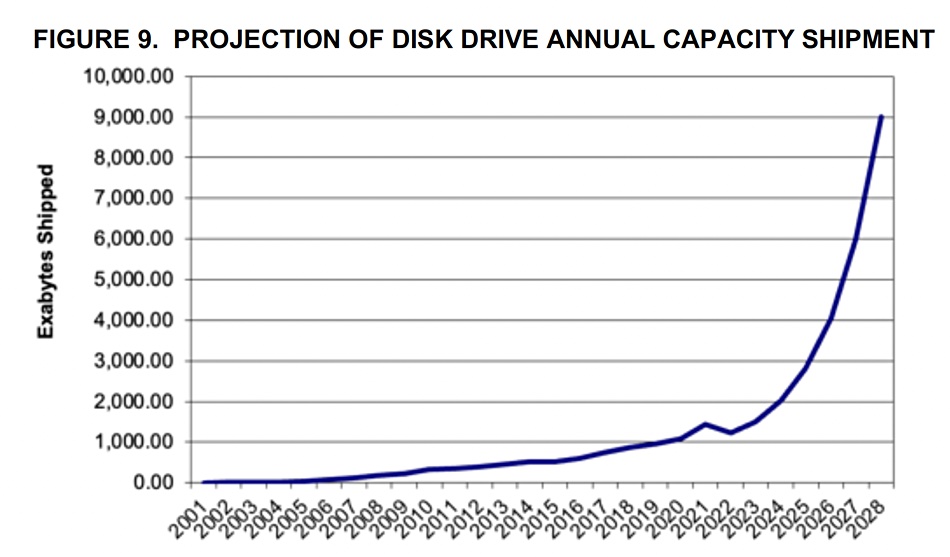
Yet this forecast is not shared by Thomas Coughlin in his August 2023 Digital Storage Technology newsletter. Page 151 of the newsletter has a chart forecasting tape, SSD and HDD capacity shipment out to 2028, which shows no decline in HDD capacity growth at all:
The report text states: ”The chart [above] is the latest Coughlin Associates history and projections for hard disk drive, solid state drive and tape capacity shipments out to 2028. Barring a significant economic downturn, we expect demand for digital storage to support AI, IoT, media and entertainment as well as genomic and other medical applications to drive increased storage demand. This should bring growth back to HDDs, SSDs and magnetic tape capacity shipments as all of these storage media increase in their per-device storage capacities.”
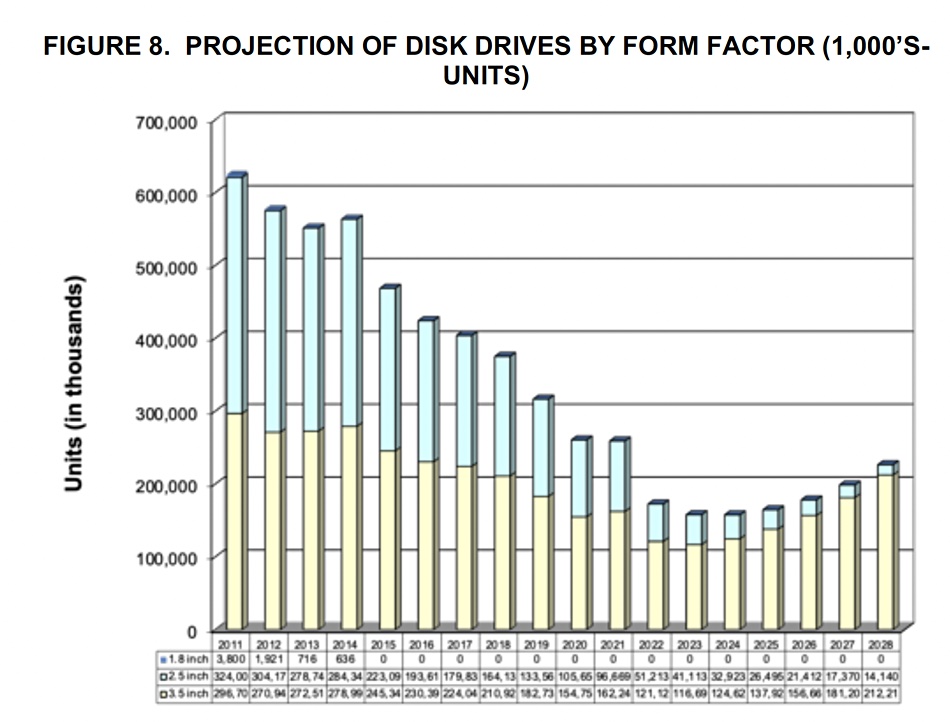
A separate chart looks at disk drive form factor unit shipments out to 2028, and shows a recent decline reversing:
The yellow bars are 3.5-inch drives with the blue bars being 2.5-inch units. A disk drive capacity ship forecast also shows a steep rise to 2028:
The report says: “We project a doubling of head and media demand by 2028, assuming a recovery in the nearline market starting in later 2023 or early 2024. The growth of capacity-oriented Nearline drives for enterprise and hyperscale applications will result in more components per drive out to 2028 and provides the biggest driver for heads and media.”
The industry seems to be divided on this matter. While Thomas Coughlin believes in the continued growth of disk drives, Charlie Giancarlo predicts a dominant future for flash drives. The outcome by 2028 will determine which perspective holds true.
IBM claims it has the fastest storage node data delivery to Nvidia GPU servers with its ESS 3500 hardware and Storage Scale parallel file system.
Nvidia GPU servers are fed data through its GDS (Magnum GPU Direct) protocol which bypasses source data system CPUs by setting up a direct link to the storage subsystem. We had previously placed IBM in second place behind a DDN AI400X2/Lustre system, with that ranking based on IBM’s ESS 3200 hardware.
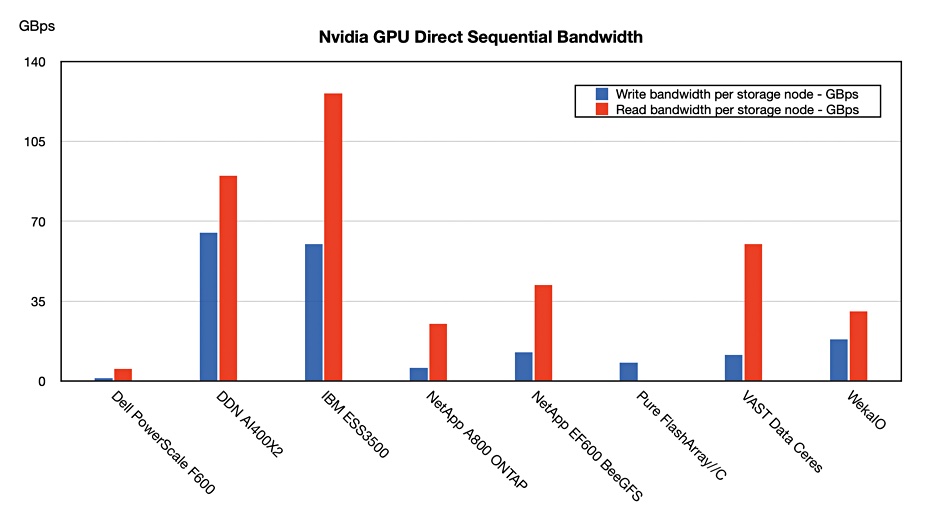
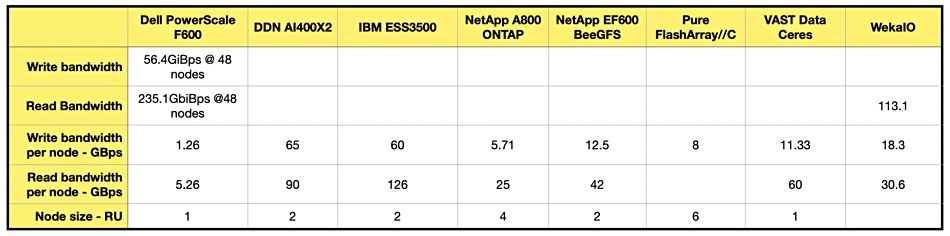
IBM told us about a faster result with its ESS 3500 storage system, which has a faster IO controller processor, an AMD 48-core EPYC 7642 vs the ESS 3200’s 48-core EPYC 7552. The ESS 3200’s 31/47GBps sequential write/read bandwidth gets upgraded to 60/126GBps with the ESS 3500. A chart shows the comparison of this against the DDN, VAST, Pure, NetApp and, Dell PowerScale systems:
IBM leads on read bandwidth and is second to DDN on write bandwidth. Here are are the numbers behind the chart:
The ESS 3500 has a Power9 processor-based management server runing Storage Scale, the rebranded Spectrum Scale parallel filesystem software, with a cluster of building blocks providing the actual storage. Each building block is a pair of X86 CPU-based IO servers attached to one to four external storage chassis containing PCIe gen 4 NVMe drives. The system supports 100Gbit Ethernet or InfiniBand running at 100Gbps (EDR) or 200Gbps (HDR). There’s a lot more information in an IBM ESS 3500 presentation.
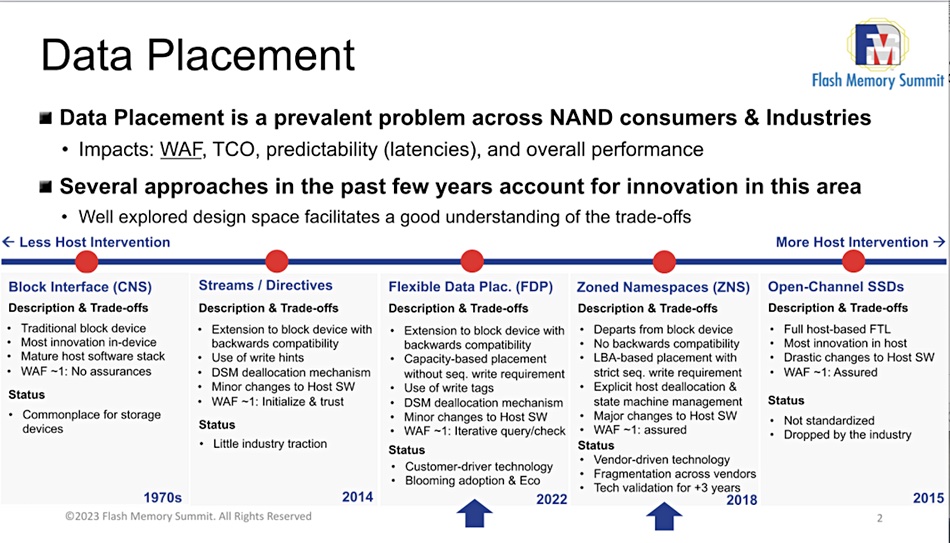
Analysis: ZNS and FDP are two technologies for placing data more precisely on SSDs to lengthen their working life and improve performance. How do they work? Will both be adopted or will one prevail?
ZNS (Zoned Name Space) and FDP (Flexible Data Placement) have the server hosting an SSD tell its controller where to place data so as to reduce the number of writes needed when the controller recovers deleted space for reuse.
The reason this is needed is that there is a mismatch between an SSD’s writing and deleting data processes, which results in the SSD writing more data internally than is actually sent to it. This is called write amplification. If 1MB of data is written to the SSD and it internally writes 2.5MB of data then it has a write amplification factor (WAF) of 2.5. Since NAND cells have a fixed working life – in terms of the number of times that data can be written to them – then reducing the write amplification factor as much as possible is desirable. And greatly so for hyperscalers who can have thousands of SSDs.
Write amplification
An SSD has its cells organized in blocks. Blocks are sub-divided into 4KB to 16KB pages – perhaps 128, 256 or even more of them depending upon the SSD’s capacity.
Data is written at the page level, into empty cells in pages. You cannot overwrite existing or deleted data with fresh data. That deleted data has to be erased first, and an SSD cannot erase at the page level. Data is erased by setting whole blocks, of pages and their cells, to ones. Fresh data (incoming to the SSD) is written into empty pages. When an SSD is brand new and empty then all the blocks and their constituent pages are empty. Once all the pages in an SSD have been written to once, then empty pages can only be created by recovering pages from blocks which have deleted data in them – from which data has been removed, or erased.
When data on an SSD is deleted, a flag for the cells occupied by the data is set to stale or invalid so that subsequent read attempts for that data fail. The data is only actually erased when the block containing those pages is erased.
SSD terminology has it that pages are programmed (written) or erased. NAND cells can only endure so many program/erase or P/E cycles before they wear out. TLC (3bits/cell) NAND can support 3,000 to 5,000 P/E cycles, for example.
Over time, as an SSD is used, some of the data in the SSD is deleted and the pages that contain that data are marked as invalid. They now contain garbage, as it were. The SSD controller wants to recover the invalid pages so that they can be re-used. It does this at the block level by copying all the valid pages in the block to a different block with empty pages, rewriting the data, and marking the source pages as invalid, until the block only contains invalid pages. Then every cell in the block is set to one. This process is called garbage collection and the added write of the data is called write amplification. If it did not happen then the write amplification factor (WAF) would be 1.
Once an entire block is erased, which takes time, it can be used to store fresh, incoming data. SSD responsiveness can be maximized by minimizing the number of times it has to run garbage collection processes.
This process is internal to the SSD and carried out as a background process by the SSD controller. The intention is that it does not interfere with foreground data read/write activity and that there are always fresh pages in which to store incoming data.
Write amplification is an SSD feature that shortens working life.
Individual pages age (wear out) at different rates and an SSD’s working life is maximised by equalizing the wear across all its pages and blocks.
If particular blocks experience a high number of P/E cycles they can wear out and the SSD’s capacity is effectively reduced. ZNS and FDP are both intended to reduce write amplification.
ZNS
Applications using an SSD can be characterized as dealing with short-life data or long-life data and whether they are read- or write-intensive. When an SSD is used by multiple applications then these I/O patterns are mixed up. If the flash controller knew what kind of data it was being given to write then it could manage the writes better to maximize the SSD’s endurance.
One attempt to do this has been the Zoned Name Space (ZNS) concept, which is suited to sequentially-written data with both shingled media disk drives and SSDs. The Flexible Data Placement (FDP) concept does not have this limitation and is for NVMe devices – meaning prediminantly SSDs.
A zoned SSD has its capacity divided into separate namespace areas or zones which are used for data with different IO types and characteristics – read-intensive, write-intensive, mixed, JPEGs, video, etc. Data can only be appended to existing data in a zone, being written sequentially.
A zone must be erased for its cells to be rewritten. Unchanging data can be put into zones and left undisturbed with no need for garbage collection to be applied to these blocks.
A host application needs to tell the SSD which zones to use for data placement. In fact all the host applications that use the SSD need to give the controller zoning information.
FDP
The NVM Express organization is working on adding FDP to the NVMe command set. It is being encouraged by Meta’s Open Compute Project and also by Google, because hyperscalers with thousands of SSDs would like then to have longer working lives and retain their responsiveness as they age.
An OCP Global Summit FDP presentation (download slides here) by Google Software architect Chris Sabol and Meta’s Ross Stenfort, a storage hardware systems engineer, revealed that Google and Meta were each developing their own flexible data placement approaches and combined them to be more effective. As with ZNS, a host system tells the SSD where to place data. (See the Sabol-Stenfort pitch video here.)
The two showed an FDP diagram:
Javier González
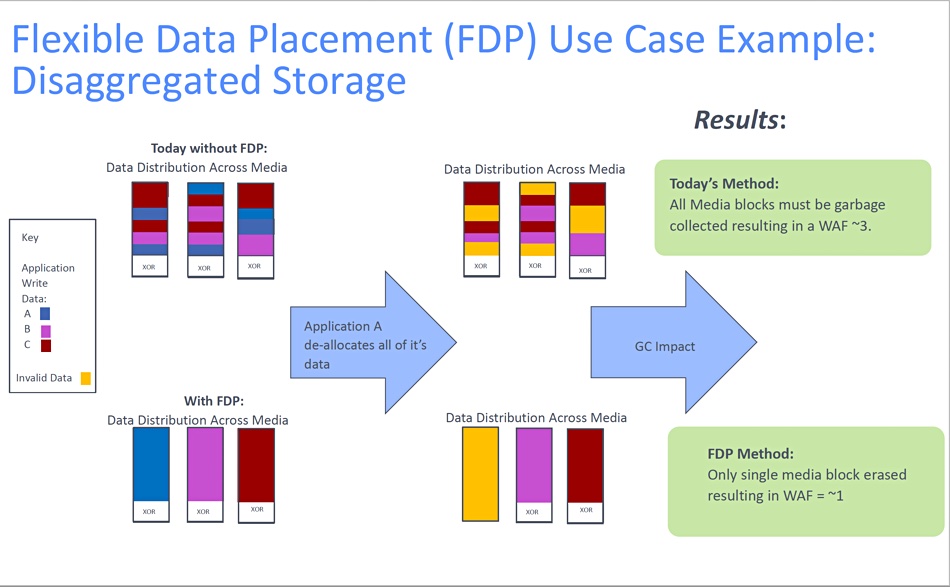
In effect, data from an application is written to an application-specific area of the SSD, to a so-called reclaim unit or block/blocks. Without FDP, data from a mix of applications is written across all the blocks. When one app deallocated (deletes) its data then all the blocks must undergo garbage collection to reclaim the deleted space and the resulting WAF in this example is about 3.
With FDP in place then only one block is erased and the WAF is closer to 1. This reduces the amount of garbage collection, lengthens the drive’s endurance and helps maximize its responsiveness. An additional benefit is that there is a lower need for over-provisioning flash on the drive, and thus a lower cost.
Javier González of Samsung presented on FDP at the FMS 2023 event in Santa Clara this month and his slide deck can be seen at the bottom of a LinkedIn article – here.
He said FDP and ZNS are the latest in a series of moves attempting to lower SSD write amplification, as a slide showed:
In Samsing testing, ZNS applied to a RocksDB workload achieved a slightly better WAF reduction than FDP.
He said that both ZNS and FDP have potential roles to play. For ZNS: “If you are building an application from the ground up and can guarantee (i) sequential writes, (ii) fixed size objects, (iii) write error handling, and (iv) a robust I/O completion path to handle anonymous writes if you are using Append Command (which is mandatory in Linux), then ZNS is probably the way to go. You will achieve an end-to-end WAF of 1, and get the extra TCO benefits that ZNS devices provide.”
However, “ZNS is an explicit, strict interface. You either get all the benefits – which are plenty – or none.”
FDP is different: “If you are retrofitting an existing application where (i) writes are not always sequential, (ii) objects may be of different sizes, and (iii) the I/O path relies in existing, robust software, then FDP is probably your best bet.”
He writes: “Our experience building support for RocksDB, Cachelib, and lately XFS (still ongoing after four weeks) tells us that reaching the first 80 percent of the benefit is realistic without major application changes” for FDP.
He thinks both technologies could co-exist but believes that one will prevail and expand to cover different use-cases.
More engineering effort in the SSD hardware and software supplier and user ecosystem is needed for ZNS while FDP needs less engineering support from an application-oriented ecosystem.
Gonzalez thinks only one of these technologies will gain mainstream adoption, but doesn’t know which one. ZNS is best suited for applications designed around fully sequential writes, while FDP is a better fit for users starting to deploy data placement in their software ecosystem.
An NVM Express TP4146 – TP standing for Technical Proposal – deals with FDP and has been ratified.
Interview Rob Young serves as a storage architect at Mainline Information Systems, a Florida-based company specializing in systems design, development, consultancy, and services. With a rich legacy in IBM mainframes and Power servers, Mainline has been progressively transitioning to hybrid cloud and embracing the DevOps paradigm in recent times.
In our discussion, we delved into topics surrounding both monolithic and distributed, scale-out storage systems to gain insights into Rob’s perspectives on the evolution of high-end storage. Young posits that the future of Fibre Channel may be constrained and anticipates that high-end arrays will integrate with the major three public cloud platforms. He provided a lot of interesting points of view, prompting us to present this interview in two parts. Herein is the first installment.
Rob Young
Blocks & Files: What characterizes a high-end block array as distinct from dual-controller-based arrays?
Rob Young: Scalability and reliability. High-end comes with more pluggable ports, more throughput. [With] reliability, the gap is closing as Intel kit is found in the high-end and lower-tier space and has gained more RAS (reliability, availability, serviceability) features over the years. High-end [has] N+2 on power supplies and other components that don’t make their way into lower end (physically not enough room for large power supplies in some cases) and Infinidat’s Infinibox is famously N+2 on all components, including Intel-based controller heads. IBM’s DS8000 series is Power-based with a great RAS track record.
But not to be overlooked is high-end history. After decades with a number of these high-end arrays in the field, the solid service procedures, and deep skilled personnel to troubleshoot and maintain enterprise arrays, is a huge advantage come crunch time. For example, I was at a site with a new storage solution, field personnel didn’t quite follow an unclear procedure and caused an outage – thankfully prior to go-live.
Blocks & Files: What architectural problems do high-end array makers face in today’s market?
Rob Young: Funny you ask that. I’ve had several recent conversations just about that topic. History blesses and history curses. The issue here is something that was innovative 20 years ago is no longer innovative. Incumbency allows high-end to soldier on meeting business needs. You risk bad business outcomes if moving away from enterprise storage that your organization is familiar with, on a switch-up that your tech team had little input to the decision.
I’ve personally seen that happen on several occasions. New CIO, new IT director, new vendors that introduce their solutions that is not what you have on the floor. There are years of process and tribal knowledge you just can’t come up with in short order. That problem has been somewhat ameliorated by newcomers. Their APIs are easier to work with, their GUI interfaces are a delight, simpler procedures, HTML5 vs Java, data migrations are much simpler with less legacy OS about, etc. Petabytes on the floor and migrating test/dev in a week or less.
There are designs that are trapped in time which offer little or painfully slow innovation, and feature additions that require change freezes while they are introduced. Contrast that to Qumulo which transparently changed data protection via bi-weekly code pushes. (A 2015 blog describes how they delivered erasure coding incrementally.) I pointed out one vendor will never get their high-end array with 10 million+ lines of code into the cloud. Why is that even a concern? Well, we should anticipate an RFP checkbox that will require on-prem and big-three cloud for the same array. At that point, the array vendor without like-for-like cloud offering is in a tight spot. That may be happening already; I personally haven’t seen it.
Blocks & Files: How well do scale-up and scale-out approaches respond to these problems?
Rob Young: A good contrast here is a Pure Storage/IBM/Dell/NetApp mid-range design versus a traditional high-end implementation. You could have multiple two-controller arrays scattered across a datacenter, which itself may have multiple incoming power feeds in different sections of the datacenter. You’ve greatly increased availability and implement accordingly to take advantage of the layout at the host/OS/application layers. The incremental scaling nature here has obvious advantages and single pane management to boot.
Regarding scale-out and perhaps one ring to rule them all? We’ve seen where vendors have moved file into traditional block (Pure is a recent example) and now we will see block make its way into traditional file. Qumulo/PowerStore/Pure/Netapp could be your single array for all things, but architecturally that doesn’t give you that warm feeling. For example, you don’t want your backups flowing into the same storage as your enterprise storage.
Not just ransomware but what about data corruption – rare but happens. There is a whole host of reasons you don’t want backups in the same storage as the enterprise data you are backing up. We’ve seen it.
That’s where our company comes in. Mainline has been in the business of solutioning for decades and would assist in sorting out all these design options based on budget. The good vendor partners are assisting in getting it right, not just selling something.
One closing thought here on scale-out. I believe we are headed for a seismic shift away from Fibre Channel in the next 3–5 years. Why? 100Gbit Ethernet port costs will become “cheap” and you will finally be able to combine network+storage like cloud providers. Currently with a separate storage network (most large shops have SAN/Fibre Channel) that traffic is not competing with general network traffic. Having two separate domains of storage traffic and network traffic has several advantages, but I think cheap 100Gbit will finally be the unifier.
An additional benefit is that deep traditional Fibre Channel SAN skills will no longer be an enterprise need, like they are today. It will take time, but protocols like NVMe will eventually go end-to-end.
Blocks & Files: Does memory caching (Infinidat-style) have generic appeal? Should it be a standard approach?
Rob Young: When we say, “memory caching,” we mean the unique story that Infinidat calls Neural Cache. It delivers a significant speed-up of I/O. At the end of the day, it is all about I/O. I penned a piece that details how they’ve accomplished this, and it is an astounding piece of engineering. They took Edward Fredkin’s (he recently passed in June at 88; what an amazing polymath he was!) prefix tree which Google implements as you type with hints for the next word.
Infindat uses this same method to track each 64K chunk of data via timestamps and from that can pre-fetch into memory the next-up series of I/O. This results in a hit rate from the controller memory north of 90 percent. The appeal is a no-brainer as everyone is trying to speed up end of day, month-end runs.
Those runs occasionally bend and now the hot breath of management is on your neck wondering when the re-run will complete. A myriad number of reasons we all want to go faster and faster. Brian Carmody (former Infinidat CTO – now at Volumez) humbly described how they were first to perform neural caching.
That statement had me scratching my head. You see there are several granted patents that encompass what Infinidat is doing for caching. Unless I’m missing the obvious, others won’t be doing what Infinidat is doing until the patents expire.
In the meantime, some technology is sneaking up on them. We are seeing much larger memories showing up in controller designs. I’d guess a pre-fetch of entire LUNs into memory to close the gap on memory cache I/O hits could be coming.
Infinidat’s classic (disk) array has a minuscule random read I/O challenge and for applications that seem to have a portion of random I/O, their SSA (all-flash) system eliminates that challenge. We read that Infinibox SSA small random I/O (DB transactional I/O) has a ceiling of 300μs (microseconds) and that number catches our attention. We see that Volumez describes their small I/O as 316μs latency (360μs including hitting the host), AWS with their Virtual Storage Controller showing 353μs small I/O reads to NVMe-oF R5b instances (same ephemeral backends it seems).
You will read about hero numbers from others, but details are sparse with no public breakdown on numbers. The point here is it appears Infinidat will be at the top of the latency pyramid and several others filling in at 300μs with direct attach via PCI (cloud/VSAN) NVMe SSD.
Will we see faster than 300μs end-to-end? Yes, maybe even lurking today. Perhaps when the next spin on SLC becomes cheaper (and more common, or next go-fast tech) we see modestly sized SLC solutions with max small I/O latency in the 50–80μs range (round trip). DSSD lives again! Finally, what does a memory read cache hit on small I/O look like end-to-end? Less than 50μs for most vendors and Infinidat has publicly shown real-world speeds less than 40μs.
Part two of this interview will be posted in a week’s time.
Amazon Web Services (AWS) has integrated Hammerspace data orchestration to imrove its globally distributed render farm capabilities through AWS Thinkbox Deadline.
According to an AWS blog, AWS Thinkbox Deadline serves as a render manager that allows users to use a mix of on-premises, hybrid, or cloud-based resources for rendering tasks. The platform offers plugins tailored for specific workflows. The Spot Event Plugin (SEP) oversees and dynamically scales a cloud-based render farm based on the task volume in the render queue. This plugin launches render application EC2 Spot Instances when required and terminates them after a specified idle duration.
SEP supports multi-region rendering across any of the 32 AWS regions. With a single Deadline repository, users can launch render nodes in a preferred region. This offers regional choices to optimize costs or prioritize energy sustainability. For effective distributed rendering, the necessary data for a region’s render farm must be appropriately positioned.
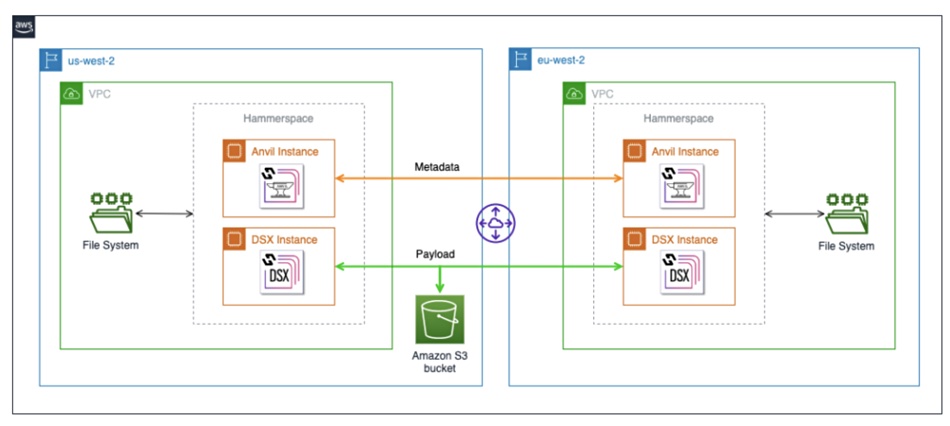
Along with Hammerspace, AWS has introduced an open source Hammerspace event plugin for Deadline. This plugin utilizes Hammerspace’s Global File System (GFS) to ensure data is transferred to its required location.
Hammerspace setup to sync file systems across two AWS Regions
The data is categorized into render farm content data and associated metadata. Hammerspace’s GFS Anvil Nodes consistently synchronize the metadata, which is typically a few kilobytes for larger files, across the involved regions. However, the content or payload data is synchronized by Hammerspace Data Service Nodes (DSX) when needed.
The nodes operate as EC2 instances, with DSX nodes using AWS S3 for staging. By default, payload data remains in its originating region. If required in another region, the primary DSX node transfers it to the destination node. Hammerspace’s directives and rules can be configured to establish policies for this process, ensuring files are pre-positioned as required.
The AWS blog has information about how Hammerspace and Deadline handle file:folder collisions to ensure a single version of file truth.
This is an example of how using Hammerspace can avoid the network traffic load of continuous file syncing and gives Hammerspace something of an AWS blessing.
Samsung made a splash at Flash Memory Summit (FMS) 2023 by highlighting advancements such as a 256TB SSD concept, a petabyte SSD architecture with Flexible Data Placement, SSD bandwidth management to address the “noisy neighbor” challenge, and the introduction of their new PCIe gen 5 SSD.
The annual event in Santa Clara serves as the prime venue for NAND, SSD hardware, software, and CXL suppliers to unveil their cutting-edge technologies. Consistent with its showing in 2022, Samsung once again dominated this year with a significant exhibition stand accompanied by multiple presentations.
The PM9D3a SSD, equipped with an 8-channel controller, is slated for release over the upcoming four quarters. It will offer capacities ranging from 3.84TB to 30.72TB, with various form factors, including 2.5 inches. Samsung informed attendees that the PM9D3a has a sequential read bandwidth up to 2.3 times superior to the existing PM9A3 with its PCIe gen 4 interface. This results in roughly double the random write IOPS.
The PM9A3 has a sequential read bandwidth reaching 6.95GBps. This suggests a groundbreaking 16GBps for the PM9D3a – a PCIe gen 5 SSD sequential read bandwidth previously unseen. For perspective, Fadu’s Echo achieves 14.6GBps, while Kioxia’s CM7-R reaches 14GBps.
While the PM9A3 achieves 200,000 random write IOPS (and 1.1 million random read IOPS), the PM9D3a is projected to deliver up to 400,000 random write IOPS, we’re told. Kioxia’s CM7-V and CD8P drives, both PCIe gen 5, achieve up to 600,000 and 400,000 IOPS, respectively. This puts Samsung’s 400,000 IOPS figure into a competitive context.
Samsung highlighted that the drive possesses telemetry capabilities, transmitting data back to the company throughout its lifecycle, aiding in troubleshooting, though this feature was introduced at the previous year’s FMS.
Samsung had previously touched upon its petabyte-scale architecture (PBSSD) at an OCP APAC tech day in Seoul. At FMS 2022, a 128TB QLC SSD was displayed, hinting at the progression towards the petabyte scale.
The architecture features Flexible Data Placement (FDP), which enables server hosts to manage data placement within the flash blocks of the drive. Data with specific attributes can be grouped together, enhancing the drive’s longevity by minimizing the write frequency, thus reducing write amplification. Samsung demonstrated this feature in collaboration with Meta using open source software.
Another feature of the PBSSD allows drives to regulate performance for each accessing virtual machine by setting traffic limits – dubbed Traffic Isolation. This ensures no single VM monopolizes the drive’s performance capabilities, ensuring balanced responsiveness.
As its latest marker on the road to a 1PB SSD, Samsung unveiled its 256TB drive concept using QLC (4bits/cell) NAND technology. Solidigm has been a prominent advocate for this format, evident from their recent 61.44TB D5-P5336 SSD. Samsung’s message is clear: they are in the race for the long haul. Impressively, their 256TB drive reportedly consumes seven times less power compared to the energy used by eight 32TB SSDs to achieve a combined 256TB.
Airbyte has made available connectors for the Pinecone and Chroma vector databases as the destination for moving data from hundreds of data sources, which then can be accessed by artificial intelligence (AI) models. Now Pinecone and Chroma users don’t have to struggle with creating custom code to bring in data – they can use the Airbyte connector to select the data sources they want.
…
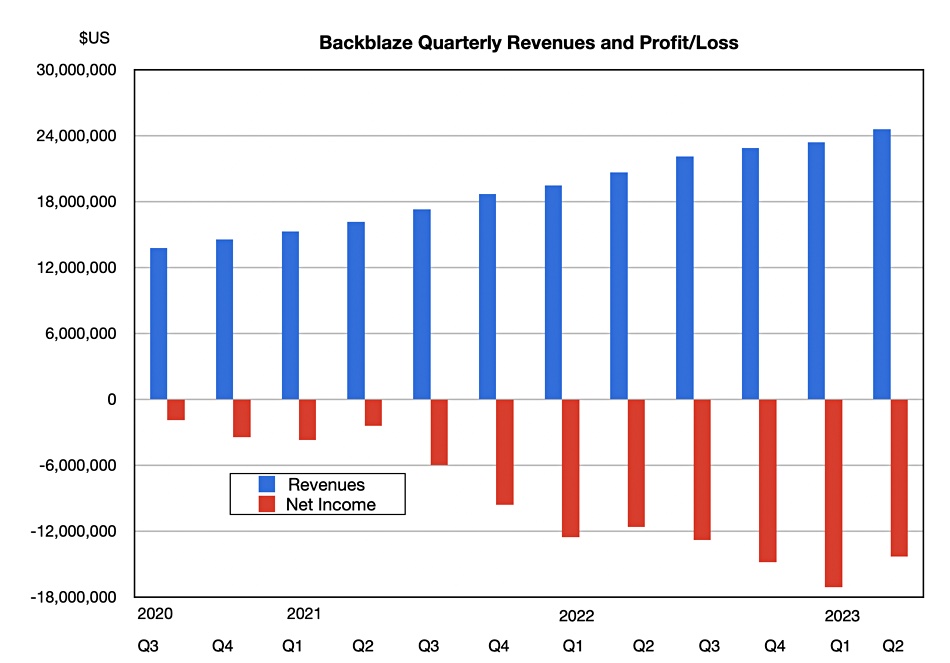
Cloud backup provider Backblaze has announced Q2 2023 revenue of $24.6 million, up 19 percent year-over-year, with a loss of $14.3 million. B2 Cloud Storage revenue was $10.8 million, an increase of 39 percent year-over-year. Computer Backup revenue was $13.8 million, an increase of 7 percent year-over-year.
In July 2023, following approval by Class B stockholders, all outstanding shares of Class B common stock were converted into shares of Class A common stock (on a 1:1 basis), thereby eliminating the company’s dual-class share structure and providing all shareholders equal voting rights. The change underscores Backblaze’s commitment to good corporate governance and being a shareholder-friendly company by simplifying the capital structure and administration processes. Q3 outlook is for revenue between $25.0 million to $25.4 million.
…
We asked Broadcom’s PR agency if Broadcom was committed to Project Monterey, the Dell-VMware-Nvidia initiative to have VMware’s vSphere hypervisor run on Nvidia BlueField DPUs. The EU Commission investigating the competitive effects of Broadcom’s intended VMware acquisition has possible doubts about this going ahead. Broadcom’s reply via its agency was: “I’m afraid Broadcom can’t answer this one. Pardon.”
…
Cohesity has appointed Eric Brown as its CFO. Brown led Informatica’s initial public offering as CFO, raising $1B in proceeds at a $10B enterprise value. Srinivasan Murari has been hired to be chief development officer. He most recently served as vice president of engineering at Google Cloud, where he was responsible for the productivity of approximately 20,000 software engineers encompassing compute, storage, networking, security, databases, analytics, AI/ML, Kubernetes, serverless, cloud console, platforms, and fleet management. Previous Cohesity chief development officer Kirk Law is now an advisor to the CEO.
…
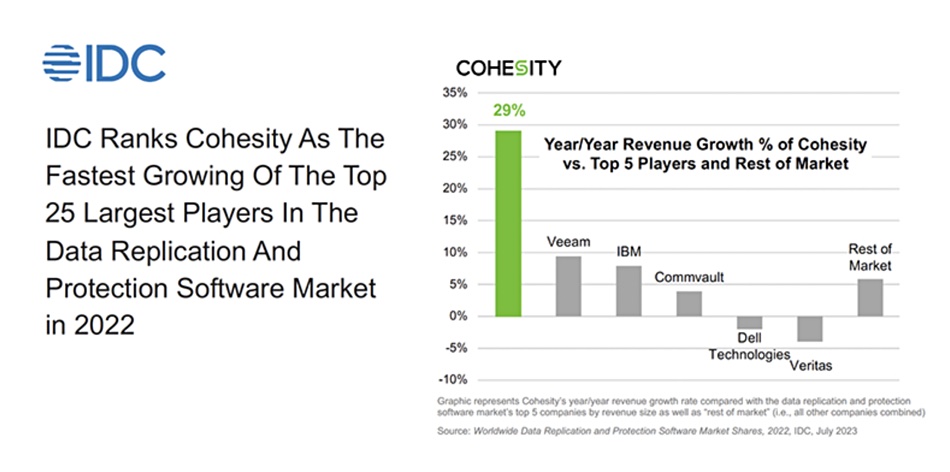
IDC ranked Cohesity as the fastest-growing of the top 25 data protection supplier in 2022.
Veeam was next, followed by – surprise – IBM and then Commvault. Dell and Veritas exhibited negative growth.
…
DataStax announced the availability of vector search capabilities in v7.0 DataStax Enterprise (DSE), its on-premises database built on Apache Cassandra. This enables any enterprise to build applications with the power of generative AI in its own datacenter. This follows its recent announcement of vector search GA for its Astra DB cloud database. Vector search in DSE is available today as a developer preview. Get started here.
…
Dell has announced a Partner First Strategy for Storage, which designates more than 99 percent of Dell’s customers and potential customers as partner-led for storage sales. Dell is compensating Dell sellers more when transacting storage through a partner, and quadrupling the number of storage Partner of Record-eligible resale accounts for more predictability of engagement. We haven’t heard about any drop in Dell storage sales heads or their redeployment.
…
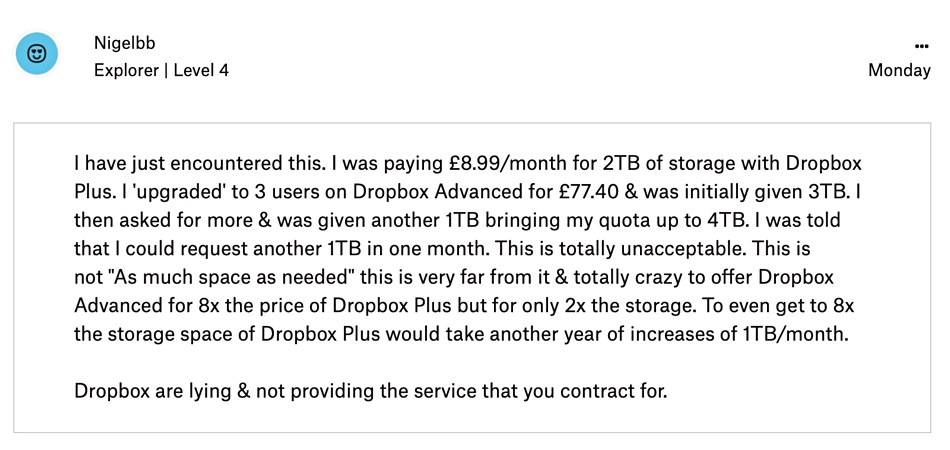
There are user complaints in a Dropbox forum that the online storage provider is throttling capacity on its costliest Advanced service offering advertised as offering “As much space as needed.”
Eg; user Nigelbb;
We have asked Dropbox what is going on.
…
SaaS data protector Druva has made it onto the 2023 Forbes Cloud 100 List, which recognizes the world’s top private cloud companies. This list is published in partnership with Bessemer Venture Partners and Salesforce Ventures.
…
Federica (Fred) Monsone, founder and CEO of storage PR company A3 Communications, has been appointed as a member of the Advisory Board for the Flash Memory Summit.
…
Google Cloud says its Chronicle CyberShield enables governments to build an enhanced cyber threat intelligence capability; protect web-facing infrastructure from cyber attacks; monitor and detect indicators of compromise, malware, and intrusions; and rapidly respond to cyber attacks to limit widespread impacts. In addition, it enables governments to raise threat and situational awareness, build cybersecurity skills and capabilities, and facilitate knowledge sharing and collaboration to raise the bar for security at a national level. CyberShield includes consulting services from Google Cloud and Mandiant to further assist governments.
…
Hitachi Vantara has achieved the Amazon Web Services (AWS) SAP Competency status.
…
HPE has accepted the resignation of EVP and CFO Tarek Robbiati, effective August 25, 2023. He’s leaving to become CEO at RingCentral. HPE has named Jeremy Cox, SVP corporate controller and chief tax officer, as interim CFO while the company and its board of directors conduct a search for a new CFO.
James Whitemore.
…
Ex-NetApp CMO and EVP James Whitemore has become CMO at iPaaS (Integration Platform-as-a-Service) supplier Celigo. Gabrielle Boko became NetApp’s CMO in January.
…
N-able, which supplies data protection for MSPs to sell to their customers, reported Q2 2023 revenues of $106.1 million, up 16 percent Y/Y, with profits of $4.5 million compared to $4.3 million year ago. Subscription revenue was $103.4 million, also up 16% Y/Y.
…
Nvidia solidified its lead in AI-focussed GPU/CPU chips by announcing its coming upgraded Grace Hopper GH200 device composed of dual Grace144-core Arm CPUs and Hopper H1000 GPUs with 282GB of HBM3e memory and 1TB of LPDDR5x DRAM. The GH200 can be scaled up to 256 units in the DGX GH200 config. It’s aimed at the AI/ML inferencing market. The upgraded GH200 commences sample ship by end of 2023 with volume production to commence in C2Q24
…
Trillion row analytics database supplier Ocient says it has demonstrated a 171 percent year-over-year growth so far this year.
…
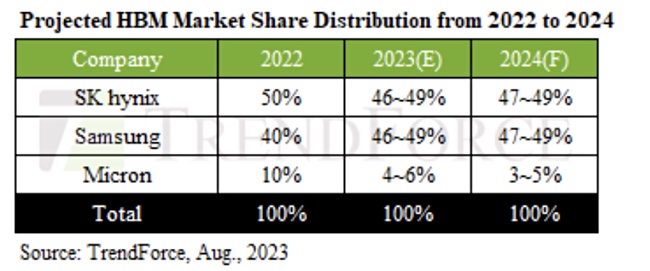
Research house TrendFocus reports that memory suppliers are boosting their production capacity, both DRAM and HBM, in response to escalating orders from Nvidia and CSPs, with “a remarkable 105 percent annual increase in HBM bit supply by 2024.”
It believes that primary demand is shifting from HBM2e to HBM3 in 2023, with an anticipated demand ratio of approximately 50 percent and 39 percent, respectively. Demand in 2024 will heavily lean toward HBM3 and eclipse HBM2e with a projected HBM3 share of 60 percent. SK hynix currently holds the lead in HBM3 production, serving as the principal supplier for Nvidia’s server GPUs – but Samsung will catch up.
…
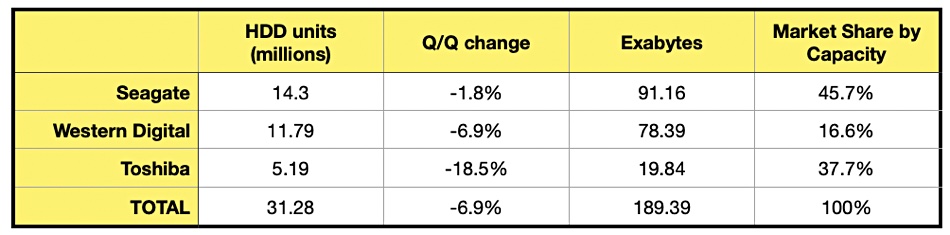
Storage Newsletter published Trendfocus HDD unit and capacity ships for Q2 2023, confirming the dire results recorded by Seagate and Western Digital. A table provides the numbers:
…
Middle East cloud provider G42 Cloud selected VAST Data to build a central data foundation for a global network of AI supercomputers and to store and learn from hundreds of petabytes of data. A single VAST Data cluster will support multiple ExaFLOPs of AI supercomputing capability in one of the world’s largest AI clouds.
…
Data protector Veritas has announced a Veritas Managed Service Provider Program to offer managed service providers (MSPs) a set of incentives, a range of training and enablement, and flexible pricing models to expand their offerings and capitalize on the growing demand for data protection and cloud-native cyber resilience solutions.
…
Identity security company Veza announced Capital One Ventures and ServiceNow Ventures have investments in Veza, bringing total financing to $125 million. The money will be used for product development, integrations for enterprise systems, and increasing go-to-market capacity. Veza’s product gives security and identity professionals a complete understanding of who can do what with data, across all enterprise systems so customers can find and fix permissions that are risky, dormant, or non-compliant. The product ingests permissions metadata from enterprise systems, including SaaS apps, data systems, custom applications, and cloud infrastructure. This month, Veza passed 125 integrations.
…
Wannabee bounce-back-from-disaster replication firm WANdisco will hold its AGM on August 30 with potential name change to Cirata being suggested. Sky News reports WANdisco ex-chairman and CEO Dave Richards and ex-CFO Erik Miller are refusing to return their 2022 bonus payments. WANdisco’s board wanted them repaid because it believes the bonus payments were unjustified as they were based on completely wrong 2022 revenue reporting which nearly crashed the business.
…
Weebit Nano has qualified its ReRAM module for automotive grade temperatures – confirming its suitability not only for automotive but also high-temp industrial and IoT applications.
ScaleFlux is upping its computational storage drive’s capacity from 12TB to a logical 24TB.
The company provides CSD 3000 drives featuring an SFX 3000 ASIC, a system-on-chip with twin quad-core ARM processors, hardware compute engine, and a PCIe gen 4 interface. It provides transparent compression/decompression, increases the drive’s logical capacity, and also its endurance by reducing the drive’s write storage burden. We have seen a presentation deck it will use at FMS 2023 where it is exhibiting this week in Santa Clara.
ScaleFlux FMS 2023 presentation deck slide
The company is increasing the CSD 3000’s maximum raw capacity by a third to 16TB. The SoC’s so-called capacity multiplier function extends this by up to 24 TB by expanding its logical NVMe namespace. E1.S form factor support is coming soon but is not available yet.
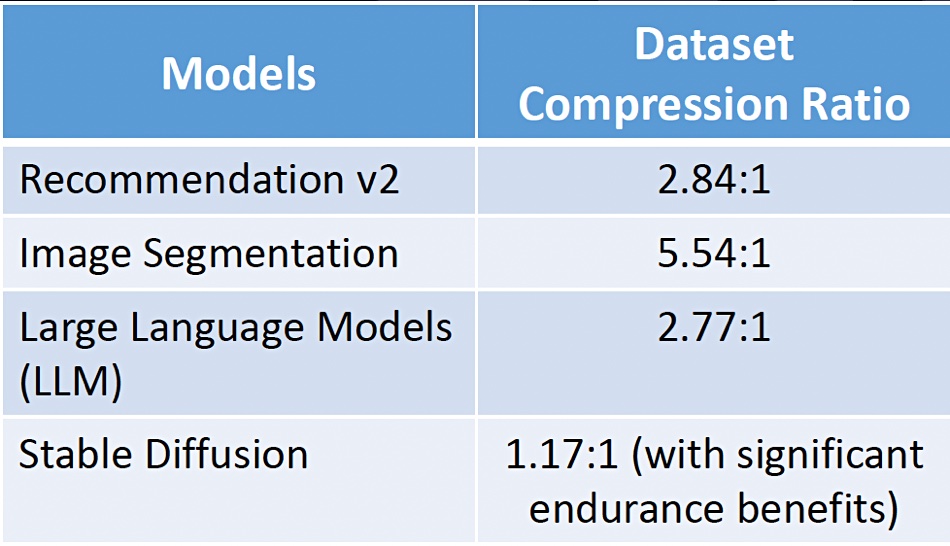
ScaleFlux has a PCE gen 5 interface product in development, which should arrive in 2024. The company says it is continuing to integrate its ASIC and firmware with partner products and services. There is a new focus on AI workload support, with ScaleFlux saying its compression provides more data for AI training. It cites MLCommons to assert that AI training sets are significantly compressible. It can optimize checkpoint data during training and improve handoffs between GPUs.
ScaleFlux and AI data set compressibility
It says it’s working on improving queuing and Flash Translation Layer functions and has announced system integrator partnerships coming to sit alongside an existing Nvidia GPUDirect relationship. There will also be support for new drive form factors and even higher capacity points. The ASIC is going to be developed as well, with joint-development and collaboration partners.
Comment
ScaleFlux raw capacities appear to be behind those of off-the-self SSDs. Although it is promising to increase raw capacity to 16TB and logical capacity to 24TB, customers can buy larger, 30TB, SSDs now, and even 61.44TB SSDs from Solidigm.
The company says it can boost a 16TB raw capacity to 24TB in the near future and so speed AI training workloads, while Solidigm says it provides 61.44TB . Pure Storage provides 24 or 48TB DFM drives today and has a route to 300TB by 2026. IBM has a 38.4TB FLashCore Module with on-board compression and other functions boosting it to 116TB effective capacity.
ScaleFlux has to deliver more than the benefits of a compressed small standard SSD, and its partnerships with database, silicon and other software vendors are probably key to that. Compression on its own might not be enough.
But this is a capability that will have to be enhanced with every raw capacity increase coming from the NAND suppliers, as they increase 3D NAND layer counts.
The company’s integration and partnerships with a vertical market and edge computing focus look to be vital in sustaining its growth.
We have asked ScaleFlux about these points and will update things when we hear back.