


Analysis: With Dell’s PowerScale scale-out filer being included in the company’s generative AI announcement this week, we looked at how it and other storage systems compare when using Nvidia’s GPUDirect protocol, to serve data to and from Nvidia’s GPUs.
Update. Pure Storage FlashBlade GDS readiness clarified. 1 Aug 2023.
GPUDirect Storage (GDS) is an NVMe and CPU-bypass protocol to enable storage systems to send data to SuperPod and other Nvidia GPU servers as fast as possible. For reads, traditional storage has a server’s CPU copying data from its storage resource, DAS, SAN or NAS, into a memory buffer, and then writing it out to the network interface device for onward transmission. The data bounces, as it were, from the storage to a memory buffer before going to its destination. Incoming data (writes) follow the same route in reverse. GDS cuts out this bounce buffer stage and sends it direct from storage to the destination GPU system’s memory.
It is supported by Dell, DDN, IBM, NetApp (ONTAP and E-Series BeeGFS), Pure Storage, VAST Data and WekaIO. Pure told us: “Pure Storage’s FlashBlade hardware portfolio is GPU Direct Storage (GDS) ready, with software enhancements delivering complete GDS support to be available in the near term, further strengthening Pure’s collaboration with NVIDIA and enhancing the AIRI//S solution.”
GPUDirect is not the only method of sending data between NVIDIA GPUs and storage systems but it is reckoned to be the fastest.
Dell yesterday announced a Validated Design for Generative AI with Nvidia, featuring compute, storage and networking. The storage products included are PowerScale, ECS, and ObjectScale, with Dell’s PowerEdge servers providing the compute.
PowerScale is scale-out filer storage, the rebranded Isilon, while ECS is object storage with ObjectScale being containerized object storage based on ECS. Neither have any public GPUDirect bandwidth numbers published. The PowerScale F600 was noted as being GPUDirect-compatible in 2021; “PowerScale OneFS with NFSoRDMA is fully compatible and supported by NVIDIA GDS (GPUDirect Storage).” The ECS and ObjectScale systems do not have public GPUDirect bandwidth numbers.
We collated all the public sequential read and write storage node bandwidth numbers that we could find for Dell, DDN, IBM, NetApp, Pure and VAST Data systems when serving data to and from Nvidia GPU servers using GPUDirect.
We tried to find WekaIO numbers and did find a 113.1GB/sec sequential read bandwidth result for its scale-out and parallel filesystem. But it was an aggregate result from a cluster of servers using Weka’s file system. The number of servers was not revealed, nor their physical size, and so we couldn’t obtain a per-node bandwidth number. Nor could we find any write bandwidth numbers, and our table of results, which we charted below, does not include Weka numbers. It doesn’t have a Pure FlashArray//C read bandwidth number either as we could not locate one.
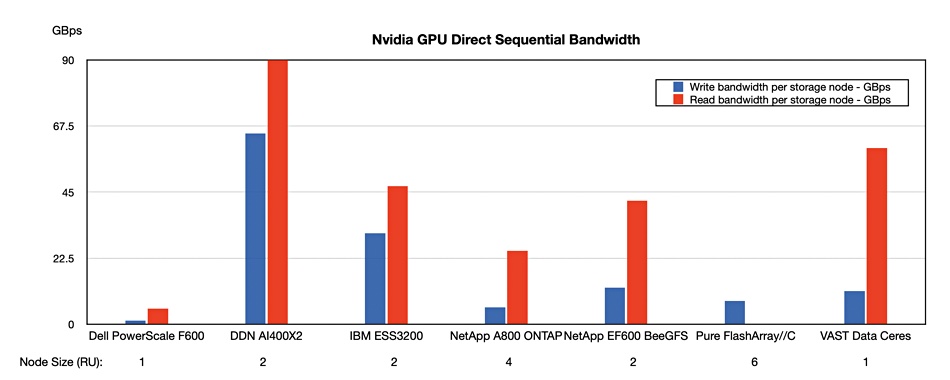
The overall read bandwidth per node results showed DDN in first place, VAST in second place, IBM ESS3200 third, NetApp E series in fourth place, ONTAP in fifth place and Dell in last place.
The write bandwidth results were different: DDN first, IBM second, NetApp E series third, VAST fourth, Pure fifth, NetApp ONTAP sixth and Dell seventh.
We should point out that the VAST storage nodes need compute nodes to go with them and the node size row at the bottom of the chart is only for the VAST Ceres storage node.
Our actual numbers are reproduced here:
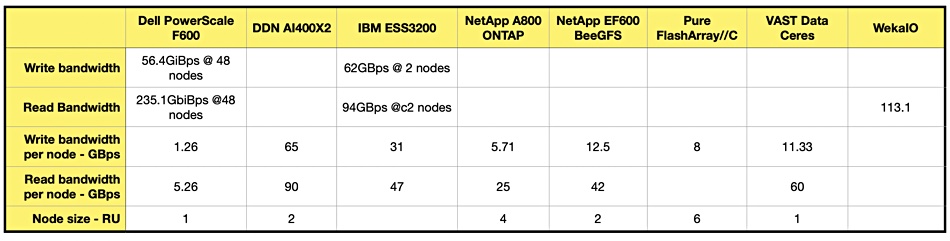
The PowerScale numbers were derived from public Dell PowerScale F600 GiBps numbers for a 48-node GPUDirect system. We derived the per-node numbers from them.




