Seagate Technology has taken the wraps off its Exos Corvault 5U84 mass storage system, saying it could help media and entertainment (M&E) organizations reduce their carbon emissions and operating costs by keeping drives in service for longer.
“The proliferation of streaming services, growing media viewership and content resolution, together with reduced IT resources, costly archiving, constrained data flow and security concerns, are already a few of the key M&E industry challenges,” said Seagate.
The new service is designed to cut e-waste, reduce operational costs, and slash the overall power consumption of CPU, RAM, and networking resources in software-defined datacenter architecture “by up to 50 percent,” said Seagate. This performance is enabled by Seagate data protection technologies, including ADAPT (advanced distributed autonomic protection technology) erasure coding, combined with autonomous drive regeneration (ADR) to automatically renew hard drives on demand.
“Exos Corvault’s groundbreaking technology provides comprehensive high-capacity, secure and reliable storage ideal for the data-hungry M&E industry,” said Melyssa Banda, vice president for storage solutions and services at Seagate. “Through ADAPT and ADR innovation, our latest solution reinforces our commitment to sustainability.”
The block storage system for datacenter deployments is also said to offer a “simplified user experience” that is “comparable” to managing a single hard drive, except with multi-petabyte capacity.
The tech was previously available in a standard 4U form factor for large 1.2-meter-deep racks, and Seagate is now offering a 5U form factor for smaller 1-meter-deep racks – commonly used at M&E companies.
“For many years now, pixitmedia has worked in partnership with Seagate to provide game-changing technology for our M&E customers. Now, we are combining the new Corvault 5U84 with our pixstor software defined storage solution, to create high performance, scalable, and flexible data storage with best-in-class TCO (total cost of ownership) that is purpose-built to meet rigorous media workflow demands,” said Ben Leaver, CEO of pixitmedia.
Seagate’s total revenues in its last quarter, ended June 30, were $1.6 billion – 39 percent lower year-on-year. That generated a GAAP loss of $92 million.
There’s archiving and there’s archiving. The Arch Mission Foundation aims to archive data for billions of years as the memory of humanity.
We first came across it with the lunar library concept which involved putting a nickel-engraved 25-layer nanofiche on the Moon’s surface, in April 2019, courtesy of SpaceIL’s (Space Israel) Beresheet lander vehicle. An earlier gimmicky demo space library involved putting a 5-dimension optical disk in the glove compartment of a Tesla roadster car launched into an initial orbit round the Earth and subsequent elliptical one around the sun by Elon Musk’s SpaceX.
The Arch Mission Foundation (AMF) – with Arch being an abbreviation for archive pronounced “Ark” – intends to have libraries scattered around the solar system. Their knowledge content will be stored on etched nickel, read-only, nanofiche disks. The libraries function, in Arch’s high-faluting language, as a backup of planet Earth to preserve the knowledge and biology of our planet in a solar system-wide project called the Billion Year Archive. The nanofiche disks can theoretically endure for several billion years, since they are resistant to electrical, radiation, high heat, deep cold and many chemicals.
The language used by AMF sounds like the most portentous stuff imaginable: “Long after the Pyramids have turned to dust, and no matter what transpires on Earth, the Billion Year Archive will remain … humanity’s gift to the future.”
Arch has many advisors, amongst whom is the magician and entertainer David Copperfield – which seems a bit gimmicky in its own right.
The concept is based on having Arch library devices or “time capsules” placed in orbit around the Earth, at several locations on the Moon and elsewhere in the solar system.
The next scheduled lunar shot hitches a ride on the Astrobotic Peregrine Mission One lander, which was expected to land on the Moon in 2022. However, rocketry development being unreliable, Astrobotic pushed that back to May, 2023, and is now pushing it back to an unscheduled time in the future. This was due to a test anomaly – otherwise known as an explosion – nearby the testing rig that housed the United Launch Alliance (UAL) Vulcan Centaur rocket that should carry the lander to the Moon. The first flight is now delayed indefinitely as the rocket undergoes a design modification.
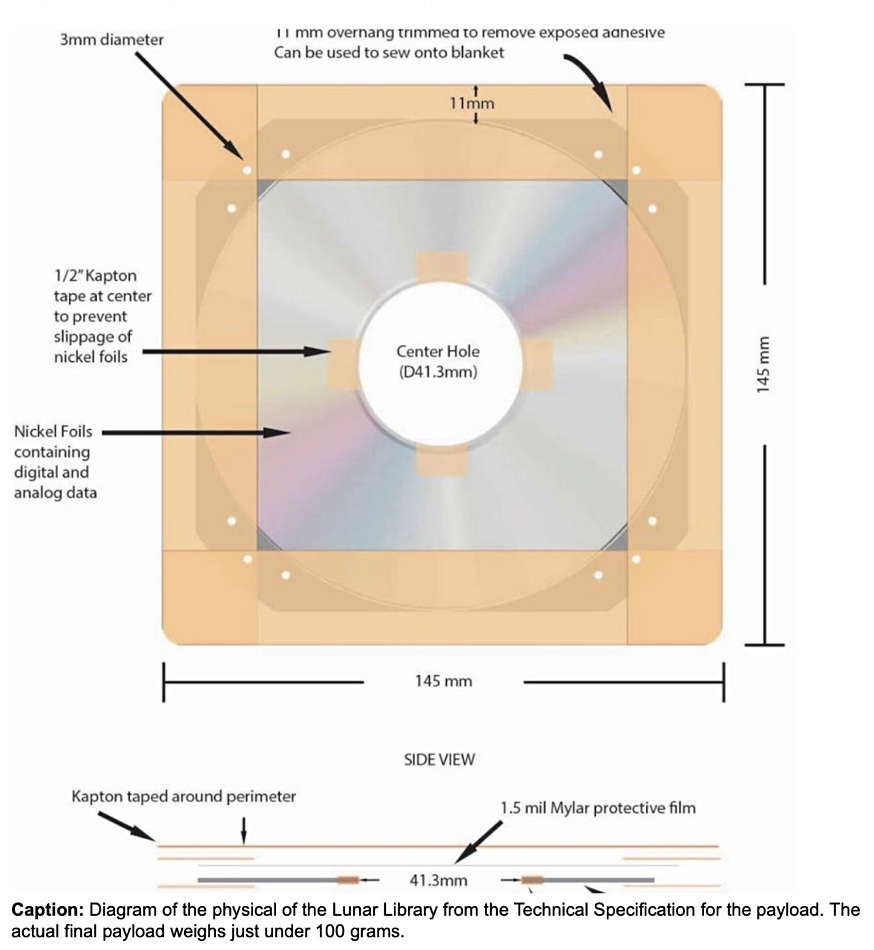
Nanofiche
The 4 gram, 120mm nanofiche disk is 40 microns (0.04mm) thick. It has 25-layers, or foils. The first four are analog layers with nearly 60,000 pages of content accessible by a simple magnifying glass or 100–200x optical microscope. The content includes technical and scientific specifications to teach a future reader how to retrieve and interpret the DVD-like digital data stored on the remaining 21 layers.
The first layers’ content also includes a primer consisting of thousands of pages that teach the meanings of more than a million words and concepts in many languages. It also includes collections of knowledge about many subject areas – such as the Wikipedia Vital Articles collection.
The content is first etched as nano-scale diffractives by laser onto a glass master disk at 300,000dpi. A thin nickel foil is grown from the glass master by electro-depositing the nickel atom-by-atom.The resulting foil is then separated from the glass. All this is carried out by NanoArchival at Stamper Technology.
The digital layers are physically the same but carry >100GB of compressed digital data (>200GB decompressed). The content includes the English Wikipedia, Project Gutenberg’s book library, the Internet Archive and the Wearable Rosetta; information on the world’s nearly 7,000 languages with the full PanLex dataset, and more.
Her’’s where it might be thought ridiculous. The digital content also includes special vaults – one of which is called David Copperfield’s Secrets, and explains the art and science of his illusions.
The idea is that far, far in the future, the then residents of Earth could discover the Arch time capsules in an archaeological exercise, build a DVD player using instructions in the nanofiche disk’s analog layers, and then retrieve the digital information. Also extra-terrestrial beings could do the same thing – and both find out all about David Copperfield.
Content collaborator Egnyte has introduced specific AI/ML services to trigger workflows for images and documents in the Architecture, Engineering, and Construction (AEC) market.
Egnyte is a file-based collaboration services company founded in 2007 and funded to the tune of $137.5 million. It has a less prominent position in the cloud file services market than CTERA, Nasuni, and Panzura but has built up a solid roster of 17,000-plus enterprise customers such as Red Bull, Yamaha and Balfour Beatty, with more than 3,000 AEC customers. In July it added a generative AI chatbot to its content intelligence software engine to summarize documents and create audio/video transcripts.
Ronen Vengosh, SVP of Industry Solutions at Egnyte, stated: “Our AEC customers upload millions of photos to the Egnyte platform every week as a means to report on progress updates, create safety documents, support RFIs, and more. The new AI services will help our customers simplify and automate all manner of business processes that surround these images.”
In an August 2022 blog, Egnyte’s Joëlle Colosi, product marketing lead for AEC, said: “Egnyte’s AEC customers have, on average, nearly quadrupled their data storage in recent years – increasing from 0.9TB in 2017 to 3.5TB in 2021.” That’s a lot of paperwork and images to handle.
Customers will be able to use the AI models in the new services to label job site photos and documents based on their contents. They will be able to tag pictures with labels such as “roofing” or “HVAC” or documents with labels like “RFI” or “submittal” and so trigger workflows and policies based on those labels.
Amrit Jassal, Egnyte co-founder and CTO, said in a statement: “Out-of-the-box AI models can support an astounding array of applications, but are not well suited for the more specialized, and often regulated, business settings that many of our customers operate in. Just as they must be careful when selecting and training new hires for their organizations, today’s knowledge-based businesses need to select and tune their AI to ensure the highest degrees of accuracy and reliability. And now they can, without the typical complexity.”
Egnyte plans to introduce other specific vertical market AI models, for life services perhaps, and will roll out a next generation of its Trainable Classifier, enabling non-technical business users to train their own classification models, without exposing those models or the underlying data to any third parties.
The company will be showcasing its new capabilities at the the Vertical AI for AEC at the Procore Groundbreak event being held this week in Chicago, and at the Egnyte Virtual Summit in December.
You can read an Egnyte blog about its existing AI/ML work with documents to get more of a sense to the background to Egnyte’s AI/ML work.
MLCommons, the machine learning standards engineering consortium, has produced a machine learning storage benchmark with results from DDN, Nutanix, Weka and others.
Update: DDN comment added below disagrees with my MBps/accelerator metric. 20 Sep 2023.Nutanix note added 21 Sep 2023
MLCommons was founded in 2020 by the people who produced the MLPerf benchmark for testing ML hardware performance in 2018. It wants to increase the AI/ML adoption rate by developing quality and performance measures, large-scale open datasets and common development practices and resources. MLCommons has more than 50 members including software startups, university researchers, cloud computing and semiconductor giants. Among them are Dell EMC, HPE, Huawei, Intel, Lenovo, Meta, Nvidia, Nutanix, and VMware. It has announced results from its MLPerf Inference v3.1 and first ever MLPerf Storage v0.5 benchmarks.
David Kanter, executive director of MLCommons, stated: “Submitting to MLPerf is not trivial. It’s a significant accomplishment, as this is not a simple point and click benchmark. It requires real engineering work and is a testament to our submitters’ commitment to AI, to their customers, and to ML.”
The MLCommons MLPerf Inference benchmark suite measures how fast systems can run models in a variety of deployment scenarios. The open source MLPerf Storage benchmark suite measures the performance of storage systems in the context of ML training workloads. It’s built on the codebase of DLIO – a benchmark designed for I/O measurement in high performance computing, adapted to meet current storage needs.
Oana Balmau, Storage Working Group co-chair, stated: “Our first benchmark has over 28 performance results from five companies which is a great start given this is the first submission round. We’d like to congratulate MLPerf Storage submitters: Argonne National Laboratory (ANL using HPE ClusterStor), DDN, Micron, Nutanix, WEKA for their outstanding results and accomplishments.”
There are both open and closed MLPerf Storage submissions. Closed submissions use the same reference model to ensure a level playing field across systems, while participants in the open division are permitted to submit a variety of models. We only look at the closed submissions as they enable cross-vendor comparisons in principle.
The benchmark was created through a collaboration spanning more than a dozen industry and academic organizations and includes a variety of storage setups, including parallel file systems, local storage, and software defined storage.
MLCommons says that when developing the next generation of ML models, it is a challenge to find the right balance between and efficient utilization of storage and compute resources. The MLPerf Storage benchmark helps overcome this problem by accurately modeling the I/O patterns posed by ML workloads, providing the flexibility to mix and match different storage systems with different accelerator types.
The MLPerf Storage benchmark is intended be an effective tool for purchasing, configuring, and optimizing storage for machine learning applications, as well as for designing next-generation systems and technologies.
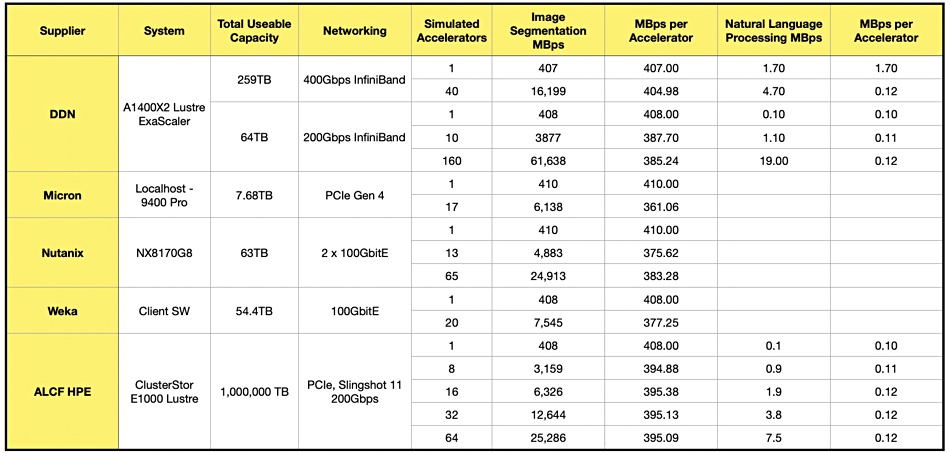
Submitting systems are scored for two MLworkloads – medical image segmentation and natural language processing – with samples per second and MBps ratings in each category. MLCommons says samples/second is a metric that should be intuitively valuable to AI/ML practitioners, and the MBps metric should be intuitively valuable to storage practitioners. We look at MBps.
The dataset used in each benchmark submission is automatically scaled to a size that prevents significant caching in the systems actually running the benchmark code. The submitted systems all use a simulated V100 accelerator (Nvidia V100 Tensor core GPU) with varying numbers of these accelerators tested, making cross-supplier comparisons difficult. There are GitHub reference links for details of code per submitter and system.
We have extracted the basic systems and scores data from the full benchmark table. Then we have added a column of our own – MBps per accelerator – to try to normalize performance per accelerator and so enable cross-supplier comparisons:
ALCF refers to the ALCF Discretionary Allocation Program, and shows results for HPE ClusterStor systems that are available in the Argonne National Laboratory Discretionary Allocation Program.
Overall there is not that much difference between the suppliers and systems, with the image segmentation MBps/Accelerator scores bunched between 410 and 361. Micron has both the the highest score at 410, and the lowest, at 361. The natural language processing MBps numbers are much lower, with DDN having the single highest result, 1.7, and all the others varying between 0.12 and 0.10. We suggest it’s good to have a vendor-independent benchmark in this area at all, even if its first iteration is not that informative.
We have no means of relating these numbers to supplier performance when delivering data to Nvidia GPUs with the GPUDirect protocol. There are much greater storage performance variations between suppliers with GPU Direct than with MLPerf Storage.
It would be good to have missing MLPerf Storage performance data for GPUDirect-supporting storage suppliers such as IBM (ESS3500), Huawei (A310), NetApp (A800, EF600) and VAST Data (Ceres). Then we could compare how suppliers look against both benchmarks.
MLPerf Inference v3.1 edge inference results can be inspected here and datacenter inference results here.
DDN Comment
DDN’s SVP for Products James Coomer sent me this note: Chris, you say “We have extracted the basic systems and scores data from the full benchmark table. Then we have added a column of our own – MBps per accelerator – to try to normalize performance per accelerator and so enable cross-supplier comparisons:”
I don’t think that works. This benchmark is like… “how many GPUs can the proposed system drive at a specified performance level”.. so in this case the specified performance level equates to around 400MBps .. but that is defined by the benchmark
The interesting thing is only : how many GPUs are driven (to that rate above) from a given:
Number of controllers
Number of SSDs
Power consumption
DDN drives 40 GPUs from a single AI400X2 (2 controllers).
The other reasonable comparison might be Weka who hit 20 GPUs from 8 nodes (controllers).
Nutanix Blog
A Nutanix blogger noted: “The benchmark metric is the number of accelerators that the storage can keep busy. In the first ML-Perf benchmark report we showed that we were able to supply enough storage bandwidth to drive 65 datacenter class ML processors (called “accelerators” in MLPerft language) with a modest 5-node Nutanix cluster. We believe that 65 accelerators maps to about 8x NVIDIA DGX-1 boxes. The delivered throughput was 5 GBytes per second over a single NFS mountpoint to a single client, or 25GB/s to 5 clients using the same single mountpoint. Enforcing that the results are delivered over a single NFS mountpoint helps to avoid simplistic hard-partitioning of the benchmark data.” This used Nutanix Files software.
Nutanix says Nutanix Files implements a cluster of virtual file-servers (FSVMS) to act as a distributed NAS storage head. We place these FSVMs on our existing VM storage which acts as a distributed virtual disk-shelf providing storage to the FSVMs.
The result is a high performance filer where storage compute load and data is spread across physical nodes and the disks within the nodes – thus avoiding hotspots.
Each CVM uses all the local disks in the host for data, metadata and write log
Each FSVM uses all CVMs to load balance its back-end
Each NFS mount is balanced across all FSVMs using NFS V4 referrals (no client configuration required)
On the linux client we use the mount option nconnect=16 to generate multiple TCP streams per mountpoint
A Single File-Server VM (virtual storage controller) spreads its data disks (virtual disk shelf) across all nodes in the cluster.
Bootnote
The Standard Performance Evaluation Corporation (SPEC) is developing its own machine learning benchmark. It has an ML Committee and its first benchmark, SPEC ML, will measure the end-to-end performance of a system handling ML training and inference tasks. The SPEC ML benchmark will better represent industry practices by including major parts of the end-to-end ML/DL pipeline, including data prep and training/inference. This vendor-neutral benchmark will enable ML users – such as enterprises and scientific research institutions – to better understand how solutions will perform in real-world environments, enabling them to make better purchasing decisions.
Cigent Technology, which supplies zero trust data protection, is partnering with encrypted storage drive supplier Kanguru to bring full disk encryption to global customers. Kanguru Defender SED300 Secure SSDs, powered by Cigent, have security capabilities built into the firmware to ensure only authorized users and processes have access to data. Kanguru drives are AES 256 Self-Encrypting Drives, FIPS 140-2 Level 2 validated, come in internal PCIe M.2 2280 NVMe and external USB storage, and are available in 512GB, 1TB, and 2TB capacities.
Kanguru Secure SSDs are Cigent Ready, enabling the advanced security storage level features to be invoked and managed with the Kanguru Data Defense software. Data Defense enables the firmware features and also provides:
Full drive encryption with pre-boot authentication
Automated FIPS-mode configuration
Secure Vaults, protected partitions that are invisible until unlocked
Zero Trust File Access to ensure only trusted users and processes have access to protected files.
…
Continuity is an official Dell Technologies partner, helping to secure the storage and data protection systems of Dell customers who get:
Visibility of all security misconfigurations and vulnerabilities in your storage and backups
Remediation guidelines & commands for all these security risks
Continuous hardening of your storage & backups, to withstand cyberattacks
Compliance reports to prove adherence with security regulations & standards (e.g. NIST, ISO, CIS, etc.)
Digital in-memory compute chip startup d-Matrix has raised $110 million in a B-round led by Singapore-based Temasek, with other investors including Playground Global and Microsoft. The previous funding round raised $44 million. The company also announced Jayhawk II, the next generation of its silicon-based generative AI compute platform, which features an enhanced version of its digital in-memory-compute (DIMC) engine with chiplet interconnect. This industry-first silicon demonstrates a DIMC architecture coupled with the OCP Bunch of Wires (BoW) PHY interconnect standard for low-latency AI inference on LLMs from ChatGPT to more focused models like Meta’s Llama2 or Falcon from the Technology Innovation Institute. Jayhawk II is now available for demos and evaluation. Learn more here.
…
Postgres accelerator EDB is making Trusted Postgres Architect (TPA) available as an open source tool accessible to all PostgreSQL users. This deployment automation and configuration management tool streamlines the setup of High Availability (HA) Postgres clusters, helping enterprises deploy robust, production-ready clusters while saving time and reducing the chance of errors.
…
Wells Fargo analyst Aaron Rakers noted after attending an HPE investors’ session that, in terms of retention rates, the company is seeing a GreenLake churn rate in the ~5 percent area (95 percent retention), which is meaningfully lower than traditional compute refresh churn rates in the 30-40 percent range. Standard HPE GreenLake customers sign up for fixed capacity/consumption usage with flexibility around these thresholds; HPE GreenLake pricing is somewhat dictated around these consumption plans/flexibility.
…
Micron has become a Nutanix customer, using its offering for its global manufacturing facilities.
…
Israeli SQL query acceleration startup NeuroBlade, which produces Xiphos SPU (SQL Processing Unit) hardware using XRAM processing-in-memory technology, is working with Meta’s Velox open source software optimization to speed SQL queries. Velox can achieve a 3x speedup on its own and NeuroBlade claims an up to 10x acceleration. Pedro Pedreira, software engineer and Velox lead at Meta, stated: “We have created Velox to unify software-based optimizations into a single execution engine that can be reused across engines such as Presto, Apache Spark, and beyond. Our long-term strategy for Velox, however, is to provide a unified framework that allows hardware accelerators to be seamlessly integrated into data management.” NeuroBlade’s SPU architecture offloads the CPU by executing many sub-query operations more efficiently and doing the data reduction close to storage. Velox APIs allow arbitrary parts of query execution to be offloaded to an accelerator. The implementation later this year will be accompanied by a white paper describing the methodology, benchmark techniques, and outcomes.
…
Korea startup Panmnesia has raised a $12.5 million seed funding round with a valuation exceeding $81.4 million for its fabless CXL product development. The round was led by Daekyo Investment, with contributions from SL Investment, Smilegate Investment, GNTech Venture Capital, Time Works Investment, Yuanta Investment, and Quantum Ventures Korea. Panmnesia presented the world’s first CXL 2.0-based full-system memory pooling framework at the USENIX ATC conference in Boston last year.
It unveiled a system this May that accelerates datacenter-oriented AI applications using CXL 3.0 technology. At the Flash Memory Summit 2023 in Santa Clara, Panmnesia disclosed a full system, from devices to operating systems, connected through a multi-level switch architecture supporting CXL 3.0. It will refine its CXL semiconductor technology and develop additional offerings to speed up AI applications and massive parallel data processing through CXL.
…
Prague-based post-production media studio PFX is a Qumulo customer, consolidating multiple locations and workflows onto the Qumulo File Data Platform. It uses the software for efficient management and real-time operational analytics, basing it on HPE ProLiant DL325 Gen10 Plus hardware. PFX is using Qumulo for its active storage, while Hitachi Vantara’s HNAS covers NAS storage without performance needs, and the backup area.
…
Seagate announced the Exos CORVAULT 5U84 at the International Broadcasting Convention (IBC) 2023. Previously available in a standard 4U form factor for large 1.2m-deep racks, Seagate now offers a 5U form factor for smaller 1m-deep racks, commonly leveraged in media companies. Ben Leaver, CEO and co-founder of pixitmedia, stated: “We are delighted to combine the new Corvault 5U84 with our pixstor software defined storage solution to create high performance, scalable, and flexible data storage with best-in-class TCO that is purpose-built to meet rigorous media workflow demands.”
…
China-based SmartX has announced an upgraded hyperconverged infrastructure portfolio, SmartX HCI 5.1, which supports virtual machines and containers. It features:
New virtualization features: GPU passthrough, vGPU, DRS, USB passthrough, PCI passthrough, and Virtual NIC QoS.
Enhanced storage performance through features like large page memory allocation, CPU binding, storage concurrent access mechanism, and I/O logic optimization. The three-node configuration achieves a remarkable 1.38 million IOPS for 4K random read.
“Network Visualization” feature to display VM data flows and security policy enforcement results.
Software-defined network load balancer to improve application performance and security.
A more comprehensive data protection and disaster recovery solution: upgraded backup, replication, and recovery functionalities.
Wider CPU and GPU compatibility.
Supports a broader range of migration sources (from virtualization/HCI, bare metal, mainstream public clouds, and OpenStack private clouds, to SmartX) with SMTX CloudMove.
…
Cloud data warehouse and analytics supplier Snowflake has published its Modern Marketing Data Stack 2023 report. Key findings include:
Customer adoption of AI and machine learning usage is up to 15.5 percent among marketing teams as marketers begin to explore the potential impact of large language models and generative AI in their work.
There are typically six technology categories organizations consider when building their marketing data stacks: analytics, integration & modelling, identity & enrichment, activation & measurement, business intelligence, and data science & AI.
Data intelligence platform Similarweb has been recognized as a Data Enrichment leader in the report. Access the full report here.
…
Ulink noticed that long latency read data was given high importance scores by algorithms during the training of its own machine learning algorithms for UlinkDA Drive Analyzer to predict the remaining useful life of drives. This meant the algorithms determined that long latency read data was useful in predicting drives’ remaining useful life. The data used to rank drive models was SATA HDD health data collected from NAS users in May 2023.
Whenever your system sends a request to read data from your drive, it keeps track of the amount of time that the drive is taking to return that information to the system. For HDDs, the criterion for incrementing long latency read count is typically when a read command takes longer than 1,000ms + (the number of sectors being read / 256)*2ms.
Long latency reads on an HDD are usually caused by excess read retries, typically due to one of two reasons: bad sectors, and badly written data. Bad sectors, or damaged disk media, can be caused by manufacturing defects, or after the manufacturing process by loose particles or head crashes. Data may be badly written if the write was weak, written off-track, or overwritten by data belonging to an adjacent track, which may be caused by vibration. These two reasons usually cause the drive to retry the read several times, possibly with slightly altered head positions or electrical strength. And because each retry requires the platter to make another rotation, the read may require several rotations, and thus a longer time, to succeed.
…
Dr Joye Purser, field chief information security officer at Veritas, has received the ISC2 Harold F. Tipton Lifetime Achievement Award, the highest tribute in cybersecurity. In her current role at Veritas, Purser is responsible for the company’s cybersecurity field strategy and vision. Prior to Veritas, Purser founded East by South Solutions, a consultancy aimed at helping clients address regulatory compliance risk and increase cyber resiliency. Before that, she served as regional director for cybersecurity at the US Department of Homeland Security and managing consultant at PricewaterhouseCoopers. She has also held leadership positions with the Pentagon, Artemis Strategies, and US Congress.
…
HPE’s Zerto business unit co-sponsored an ESG report that found “ransomware continues to pose a serious threat and is viewed today as one of the top concerns for viability within organizations.” No surprise there then. It stated companies are becoming increasingly aware of the damage caused by these attacks and are understanding the reality of potential compromise. The research indicates that nearly two-thirds (65 percent) of respondents consider ransomware to be one of the top three most serious threats to the viability of the organization. The findings are published in an e-book titled “2023 Ransomware Preparedness: Lighting the Way to Readiness and Mitigation.” Download the e-book here.
Cloud data management vendor Acronis has released its Acronis Advanced Automation solution, with the idea of making it easier for small- to mid-sized managed service providers (MSPs) to generate more backup, disaster recovery and security services revenue from their customers.
Acronis says Advanced Automation is aimed at helping MSPs transition from simple break-fix services to cloud-centric, subscription-based services, but which require a streamlined approach to often complicated billing and contract management.
With the system, the storage company is promising “error-free” invoices and billing, offering an integrated service desk, automated time tracking, and support for subscription-based services.
With centralized control and management of services, and automated, consumption-based billing, Acronis says it is allowing MSPs to gain full visibility of their contracts, deliveries, tickets, and work items – “maximizing revenue and improving client trust.”
“New use cases for native automation solutions continue to emerge in the IT industry, and Acronis offers a product that allows MSPs around the world to automate their operations and make better, data-driven decisions,” said Patrick Pulvermueller, CEO at Acronis. “Whether emerging as a startup or evolving to maturity, Acronis Advanced Automation helps service providers control and grow their managed service business.”
Acronis Advanced Automation is available for existing Acronis MSP partners, and is also aimed at those MSPs just starting out in the cloud data management space.
Nasdaq-listed Quantum Corporation has released pre-configured data bundles to make it easier to purchase and deploy the company’s ActiveScale Cold Storage, the Amazon S3-like object storage system.
The ActiveScale offering claims to reduce cold storage costs by up to 60 percent through making it easier for organisations to dynamically move cold data across their own on-premises cloud infrastructure, rather than storing it in the public clouds run by the likes of AWS and Microsoft Azure.
Customers can build their own cloud storage system to control costs while ensuring “fast, easy access” to their data, said Quantum, for compliance, analysis, and business insight requirements. The data can be held in their own datacenter, colocation facility or at edge locations.
“We’re using Quantum ActiveScale to build Amidata Secure Cloud Storage, which delivers highly scalable, available, and affordable storage for organisations,” said Rocco Scaturchio, director of sales and marketing at Amidata, a managed service provider based in Australia. “The new bundles offering enables organizations to tap into cloud storage benefits even if they lack internal cloud expertise.”
ActiveScale Cold Storage is available in pre-configured bundles complete with all the components customers need to deploy it. The bundles are available in four standard capacity sizes – small, medium, large and extra large – that range from 10 petabytes up to 100 petabytes in data capacity size.
ActiveScale combines the required object store software with hyperscale tape technology to provide “massively scalable, highly durable, and extremely low-cost storage for archiving cold data,” said Quantum. If organizations don’t have the internal skills to manage tape systems, they can use a managed service provider to run the system for them. The public cloud hyperscalers themselves use tape systems to hold customer data, as it is a cheap medium delivering bumper data density.
Jochen Kraus, managing director at German managed service provider MR Datentechnik, said: “ActiveScale provides the reliable, highly scalable, S3-compatible object storage we needed for building our new storage service. We have a very flexible platform for meeting a broad spectrum of customer needs.”
“Quantum’s end-to-end platform empowers customers to address their unstructured data needs across the entire data lifecycle and create flexible, hybrid cloud workflows that are designed for their unique needs and goals,” added Brian Pawlowski, chief development officer at Quantum.
Growing business caution has hit European server and storage sales, according to analysts, leaving the industry in negative growth territory.
Analyst house Context has revised down its overall 2023 forecast for sales growth through the European IT channel – from 1.6 percent growth for the year to -3.3 percent.
“The cumulative impact of the war in Ukraine, the high cost of living, the cost of capital and high interest rates has led to sinking business confidence, and not just in the European Union, but also in China and the US,” said Context.
The enterprise server market experienced a year-on-year decline in revenue growth in the first quarter of 3.8 percent, said Context, and an even bigger drop in the second quarter of -11.7 percent.
Performance was worst in the UK (-38 percent) and Italy (-29 percent), which are, of course, two of the bigger European markets. Although sales are said to have “held up” in Spain, France and Germany.
Volume server sales growth fared little better, however, declining -21 percent across Europe. This was driven by a 26 percent year-on-year drop in the two-socket segment.
In the storage space, revenue growth fell significantly from 17.3 percent in the first quarter to -9.5 percent in the second quarter, thanks largely to the poor performance of the storage array segment (-13 percent), and especially hybrid and flash arrays.
The hyperconverged infrastructure (HCI) segment recorded a slight revenue increase in the second quarter of 2.9 percent, thanks to a strong performance in the UK (up 15 percent), and Italy – up 53 percent.
Other factors potentially influencing sales going forward are component pricing and availability, especially in artificial intelligence-ready components, the analyst said.
Comparatives from last year will also drag down server and storage growth figures for the rest of 2023. “Those double-digit server sales in 2022 are not going to be replicated in 2023, as they were driven mainly by the clearing of backlogs last year,” said Context.
So will there be a recovery in the server and storage market any time soon? The analyst says inflation is slowly receding across the European Union and opportunities remain for the IT channel thanks to enterprise digital transformation efforts, public sector investments, product refreshes, and the drive for sustainability.
Context is “hopeful” for a return to growth next year.
Data integrity biz Index Engines has boosted its product development and sales efforts with the hiring of two well-known industry veterans.
Update: IndexEngines says no change to existing exec roster. 16 Sep 2023.
Geoff Barrall and Tony Craythorne have joined the leadership team – Barrall as the new chief product officer, and Craythorne as chief revenue officer.
Their additions come as Index Engines says it continues to experience “rapid growth” driven by the rise of ransomware attacks, with its CyberSense analytics engine able to detect ramsomware data corruption and expedite the recovery of that data.
“They’re amazing executives with decades of experience in scaling businesses and storage technologies,” said Tim Williams, Index Engines chief executive officer. “These are the right people to help support our current strategic partners and the ones we are onboarding.”
“We’ve both followed Index Engines for years and we’ve been admirers of what they’ve built,” Craythorne said of himself and Barrall, who previously worked together at three other organizations. “They have a solution that is completely differentiated and superior to any other product on the market.”
Barrall added: “Ransomware detection on primary and secondary storage is no longer optional, it is a necessary component to ensure cyber resiliency across the enterprise.”
Prior to Index Engines, Barrall was the vice president and chief technology officer at Hitachi Vantara, where he led product strategy, partnerships, advanced research and strategic mergers and acquisitions. Before that, he founded several infrastructure companies, including BlueArc and Drobo. He has also undertaken leadership roles at Nexsan, Imation, and Overland Storage, where he was involved in product development.
Barrall is currently involved in various board memberships and advisory roles for both public and private companies.
Craythorne has experience of leading high-growth, scale-up companies in the US, Europe and Asia. Before joining Index Engines, Craythorne served as chief revenue officer of edge cloud provider Zadara, where he rebuilt the sales process and go-to-market strategy. Prior to that, he was CEO of Bamboo Systems Group where he led a rebrand, and developed and launched Bamboo’s Arm Server.
Craythorne has also served as the senior vice president of worldwide sales at unstructured data management vendor Komprise, where he built a new sales strategy, sales team, and channel strategy. In addition, he has held senior management positions at Nexsan, Brocade, Hitachi Data Systems, Nexgen, Bell Micro, and Connected Data. He is currently a board member and advisor to various startups.
Update: We asked Index Engines: “What happens to Jeff Sinnott whom we have listed as Index Engines’ VP Sales? Also what happens to Jeff Lapicco, Index Engines’ current VP Engineering?”
An Index Engine statement said: “Index Engines has unified product management, engineering, and support under Geoff as Chief Product Officer to help scale these areas as the company grows, and all sales and marketing role up under Tony as Chief Revenue Officer to continue our successful expansion into new customer markets, while driving innovation into our product. No change for existing management.”
AI is becoming a major data management challenge for IT and business leaders, according to just published research.
Companies are largely allowing employee use of generative AI, but two-thirds (66 percent) are concerned about the data governance risks it may pose, including privacy, security, and the lack of data source transparency in vendor solutions, according to the research.
The “State of Unstructured Data Management” survey, commissioned by data management vendor Komprise, collected responses from 300 enterprise storage IT and business decision makers at companies with more than 1,000 staff in the US and the UK.
While only 10 percent of organizations did not allow employee use of generative AI, the majority feared unethical, biased or inaccurate outputs, and corporate data leakage into the vendor’s AI system.
To cope with the challenges, while also searching for a competitive edge from AI, the research found 40 percent of leaders are pursuing a multi-pronged approach for mitigating risks from unstructured data in AI, encompassing storage, data management and security tools, as well as using internal task forces to oversee AI use.
The top unstructured data management challenge for leaders is “moving data without disrupting users and applications” (47 percent), but it is closely followed by “preparing for AI and cloud services” (46 percent).
“Generative AI raises new questions about data governance and protection,” said Steve McDowell, principal analyst at NAND Research. “The research shows IT leaders are working hard to responsibly balance the protection of their enterprise’s data with the rapid rollout of generative AI solutions, but it’s a difficult challenge, requiring the adoption of intelligent tools.”
“IT leaders are shifting focus to leverage generative AI solutions, yet they want to do this with guardrails,” added Kumar Goswami, chief executive officer of Komprise. “Data governance for AI will require the right data management strategy, which includes visibility across data storage silos, transparency into data sources, high-performance data mobility and secure data access.”
Edge-to-cloud file services provider CTERA has today taken the wraps off its Vault WORM (write once, read many) protection technology. The Vault offering provides regulatory compliant storage for the CTERA Enterprise Files Services Platform.
CTERA Vault aids enterprises in guaranteeing the preservation and tamper-proofing of their data, while also ensuring compliance with data regulations through strict enforcement.
Many industries need WORM-compliant storage, driven by the need to comply with regulations requiring immutable storage, such as HIPAA and 21 FDA CFR Part 11 for healthcare, NIST 800-53 for government, Sarbanes-Oxley for legal services, and Financial Industry Regulatory Authority (FINRA Rule 4511[c]) for financial services.
WORM compliance ensures that data remains inviolable, creating a trustworthy and irrefutable business record, essential for both regulatory compliance and addressing cyber security best practices.
“Regulated industries require a tamper-proof, secure, reliable, and scalable storage system to safely and confidently protect their data,” said Oded Nagel, CEO of CTERA. “CTERA Vault provides robust immutable WORM compliant storage for our global file system, allowing our customers to create permanent records that can be easily managed and which prevent unauthorised changes.”
Vault is designed to provide the flexibility and granularity to create WORM Cloud Folders with customised retention modes for specific periods of time to fit organisations’ specific regulatory or compliance requirements. The CTERA Portal provides centralised control and management of the policies that are enforced at every remote CTERA Edge Filer.
Hitachi Vantara recently entered into an OEM deal with CTERA for file and data management services, with its Hitachi Content Platform storing the data. “CTERA Vault’s innovative data retention and protection technology represents a significant step toward robust data resilience,” said Dan McConnell, senior vice president of product management and enablement at Hitachi Vantara in a statement. “As customers seek enterprise-grade solutions for regulatory compliance, Vault’s immutability, combined with our Hitachi Content Platform, can become the top choice for safeguarding critical data.”
Startup Enfabrica, which is developing an Accelerated Compute Fabric switch chip to combine and bridge PCIe/CXL and Ethernet fabrics, has raised $125 million in B-round funding.
Its technology, which converges memory and network fabric architectures, is designed to bring more memory to GPUs than current HBM technology using CXL-style pooling, and to feed data into memory through a multi-terabit Ethernet-based switching scheme. This relies on the ACF-S chip, under development, and 100-800Gbps Ethernet links.
Rochan Sankar
CEO and co-founder Rochan Sankar stated: “The fundamental challenge with today’s AI boom is the scaling of infrastructure… Much of the scaling problem lies in the I/O subsystems, memory movement and networking attached to GPU compute, where Enfabrica’s ACF solution shines.”
The funding round was led by Atreides Management with participation from existing investors Sutter Hill Ventures, Valor, IAG Capital Partners, Alumni Ventures, and from Nvidia as a strategic investor. Enfabrica’s valuation has risen 5x from its 2022 $50 million A-round valuation.
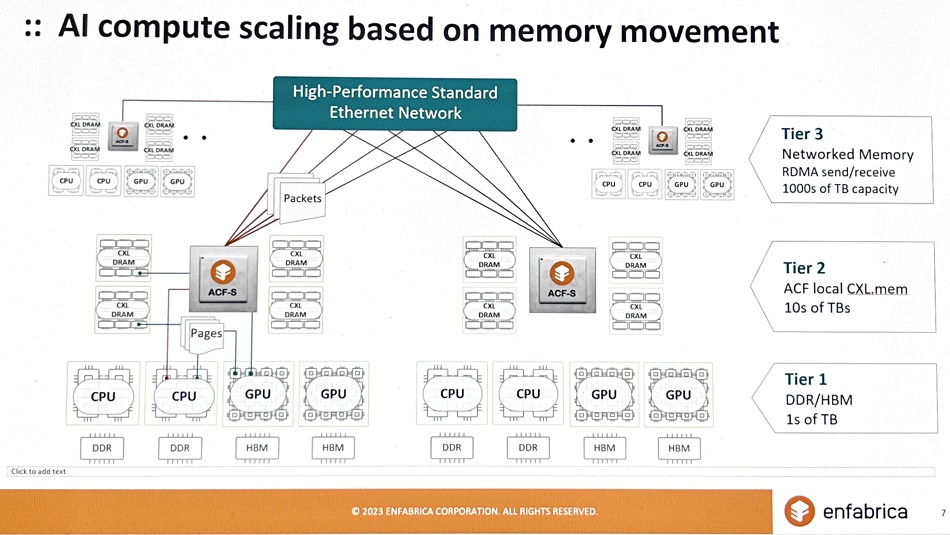
Enfabrica is developing an 8Tbps switching platform, enabling direct-attach of any combination of GPUs, CPUs, CXL-attached DDR5 memory, and SSD storage to high-performance, multi-port 800-Gigabit-Ethernet networks. It has around 100 engineers building chips and software, based in Mountain View, CA, Durham, NC, and Hyderabad, India.
It sees memory in terms of tiers. DDR and HBM forms the fastest layer with single digit terabyte capacities. Tier 2 is CXL memory local to the ACF-S device, and comes in the tens of terabytes. Networked memory accessed by RDMA send/receive is tier 3 and has thousands of terabytes of capacity. ACF-S-connected memory can be composed for specific workloads as needed.
The company has proved that its switch chip architecture and design is correct and should accelerate data delivery to GPUs as intended. The VCs have been convinced by its progress so far and now it has funding to build it. Sankar said: ”Our Series B funding and investors are an endorsement of our team and product thesis, and further enable us to produce high-performance ACF silicon and software that drive up the efficient utilization and scaling of AI compute resources.”
Enfabrica is developing an ACF-S-based system
Enfabrica thinks that its technology is especially suited to AI/ML inference workloads, as distinct from AI/ML training. Sankar said that current training systems gang together more GPUs than are needed for compute just to get sufficiency memory. According to Sankar, this means the GPUs are under-utilized and their expensive processing capacity is wasted.
The ACF-S chip and allied software should enable customers to cut their cost of GPU compute by an estimated 50 percent for LLM inferencing and 75 percent for deep learning recommendation model inferencing at the same performance point. This is on top of interconnect device savings as the Enfabrica scheme replaces NICs, SerDes, DPUs, and top-of-rack switches.
ACF switching systems with Enfabrica’s ACF-S silicon will have 100 percent standards-compliant interfaces and Enfabrica’s host networking software stack running on standard Linux kernel and userspace interfaces.
Sankar confirmed that the Enfabrica technology will be relevant to high-performance computing and little development will be needed to enter that market. Enfabrica could, in theory, support InfiniBand as well as Ethernet, but sees no need to do so.
Customers can pre-order systems by contacting Enfabrica.
Bootnote
A SerDes is a Serializer Deserializer integrated circuit device which interconnects single line parallel and serial network links. The Serializer or transmitter converts parallel data to a serial stream, while the Deserializer or receiver converts serial data to a parallel stream.