The latest OceanStor all-flash array from Huawei is set to feed Nvidia GPUs almost four times faster than the current top-rated system, IBM’s ESS 3500on a per-rack unit basis.
Update. Text and graphics corrected to show Huawei A310 has 8 nodes per 5RU chassis. 5 Sep 2023.
Systems are compared using Nvidia’s Magnum GPU Direct in which data is sent direct from an NVMe storage resource direct to the GPUs without a storage host system being involved, by first copying the data into its memory for onward transmission to the GPUs. All the systems involved scale out in some way and that means they can add nodes (controller+drive combinations) to reach a set IO bandwidth level. We compare them on a per-node basis to see how powerful they are.

Huawei briefed us on the coming OceanStor A310 system, the development of which was revealed in July as a data lake storage device for AI. Evangeline Wang, Huawei Product Management and Marketing, said: “We know that for the AI applications, the biggest challenge is to improve the efficiency for AI model training. The GPUs are expensive, and it needs to keep running to train the models as soon as possible. The biggest challenge for the storage system during the AI training is to keep feeding the data to the CPU, to the GPUs. That requires the storage system to provide best performance.”
The A310 has a 5RU enclosure containing up to 96 NVMe SSDs, processors, and a memory cache. The maximum capacity has not been revealed, but 96 x 30TB SSDs would provide 2.88PB. A rack of eight A310s would hold 23PB, which seems data lake size.
Each 5RU chassis can deliver up to 400GBps sequential read bandwidth, 208GBps write bandwidth, and 12 million random read IOPS performance. The chassis contains eight individual nodes. Up to 4,096 A310’s can be clustered together and performance scales linearly. A clustered set of nodes shares a global file system. According to a Huawei blog, the company’s Global File System (GFS) “supports the standard protocols (NFS/SMB/HDFS/S3/POSIX/MP-IO) for applications.” Node software can provide data pre-processing such as filtering, video and image transcoding, and enhancement. This so-called near-memory computing can reduce the amount of data sent to a host AI processing system.
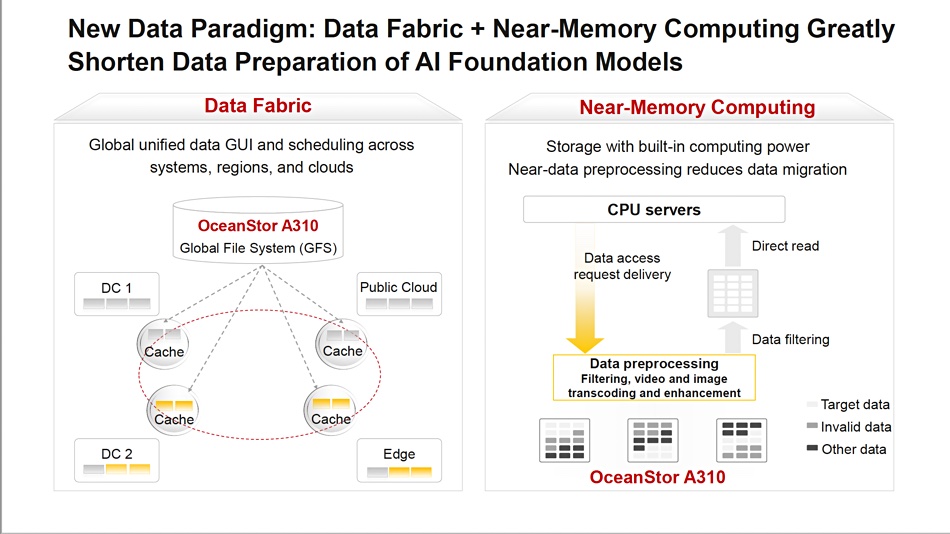
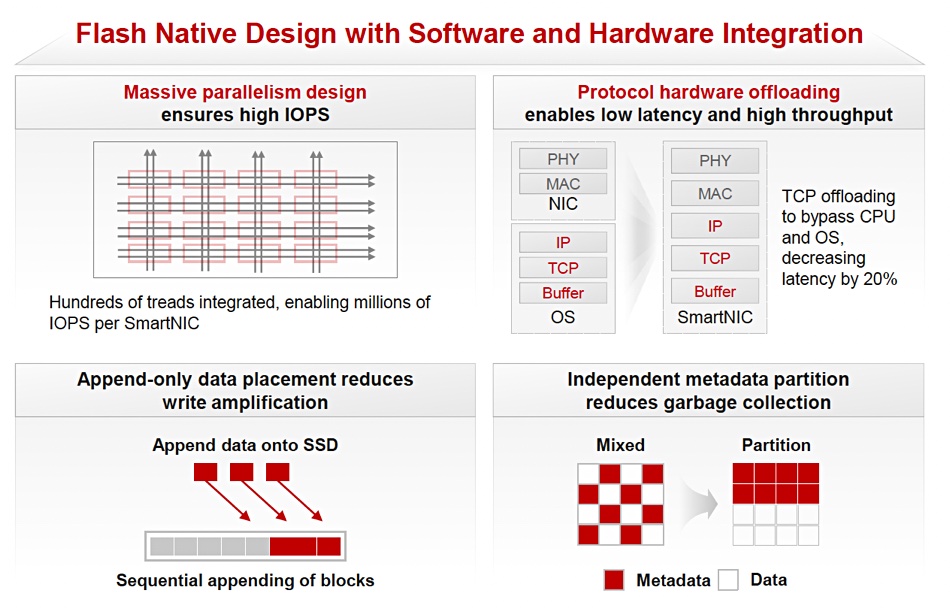
The system uses SmartNICs, with TCP offloading, and employs a massively parallel design with append-only data placement to reduce SSD write amplification. A separate metadata-only partition reduces the garbage collection inherent in having metadata distributed with data.
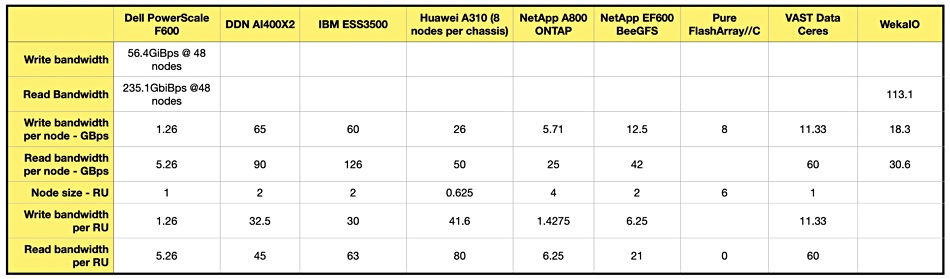
We compared the Huawei A310 sequential bandwidth numbers to other GPU Direct-supporting systems from Dell, DDN, IBM, NetApp, Pure, and VAST Data for which we have sequential bandwidth performance numbers. First of all we looked at per-node numbers:
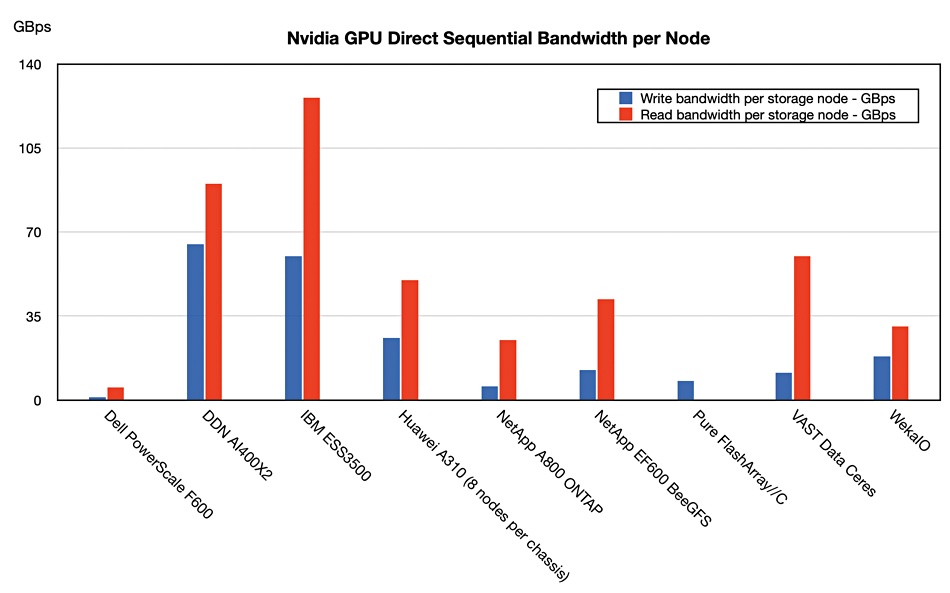
IBM and DDN are still number 1 and 2 respectively, with VAST third in read bandwidth. Huawei was fourth fastest in read bandwidth terms and third fastest looking at write bandwidth. The A310 chassis is equivalent, in rack unit terms, to five VAST Data Ceres nodes in their 1U enclosures. We can compare systems on performance per RU to compensate for their different enclosure sizes, and the rankings then differ:
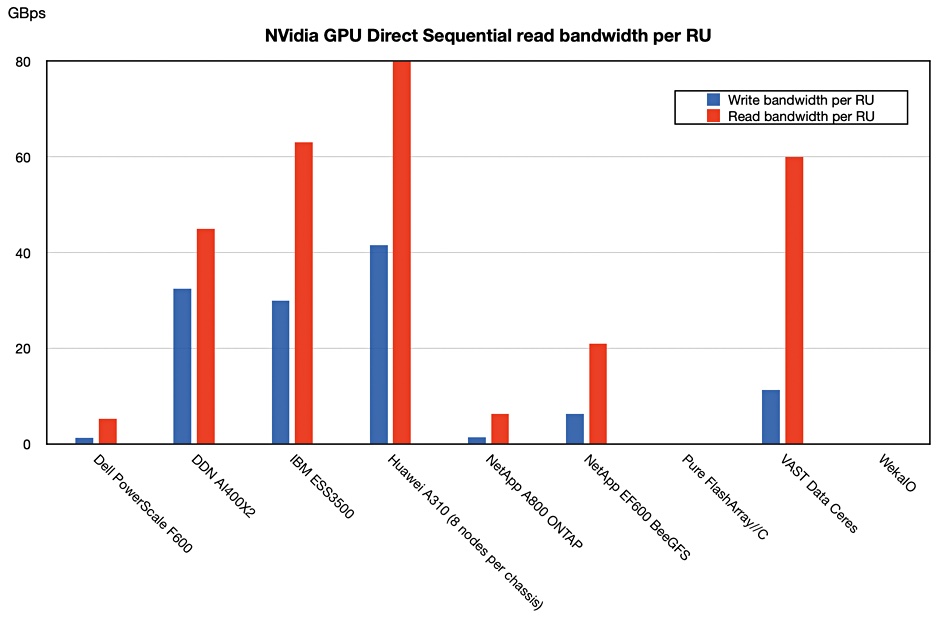
Huawei’s A310, with its small nodes, was fastest overall at both sequential reading and writing, with its 41.6/80GBps sequential write/read bandwidth vs IBM’s 30/63GBps numbers. VAST has the third highest read bandwidth per RU at 60, close behind second-placed IBM’s 63GBps/RU. Its write performance, 11.33Gbps, is slower.
VAST Data uses NFS rather than a parallel file system, and the parallel file systems from DDN and IBM are faster at writing.
We don’t know whether Huawei’s GFS is a parallel file system, though we suspect it is. The company said A310 technical documents weren’t ready yet. The A310 should be shipping some time in 2024 and will provide a challenge in the regions where it is available to the other suppliers.
Bootnote
For reference our table of supplier bandwidth numbers is reproduced here: