


MLCommons, the machine learning standards engineering consortium, has produced a machine learning storage benchmark with results from DDN, Nutanix, Weka and others.
Update: DDN comment added below disagrees with my MBps/accelerator metric. 20 Sep 2023. Nutanix note added 21 Sep 2023
MLCommons was founded in 2020 by the people who produced the MLPerf benchmark for testing ML hardware performance in 2018. It wants to increase the AI/ML adoption rate by developing quality and performance measures, large-scale open datasets and common development practices and resources. MLCommons has more than 50 members including software startups, university researchers, cloud computing and semiconductor giants. Among them are Dell EMC, HPE, Huawei, Intel, Lenovo, Meta, Nvidia, Nutanix, and VMware. It has announced results from its MLPerf Inference v3.1 and first ever MLPerf Storage v0.5 benchmarks.
David Kanter, executive director of MLCommons, stated: “Submitting to MLPerf is not trivial. It’s a significant accomplishment, as this is not a simple point and click benchmark. It requires real engineering work and is a testament to our submitters’ commitment to AI, to their customers, and to ML.”

The MLCommons MLPerf Inference benchmark suite measures how fast systems can run models in a variety of deployment scenarios. The open source MLPerf Storage benchmark suite measures the performance of storage systems in the context of ML training workloads. It’s built on the codebase of DLIO – a benchmark designed for I/O measurement in high performance computing, adapted to meet current storage needs.
We focus on the storage benchmark results here.

Oana Balmau, Storage Working Group co-chair, stated: “Our first benchmark has over 28 performance results from five companies which is a great start given this is the first submission round. We’d like to congratulate MLPerf Storage submitters: Argonne National Laboratory (ANL using HPE ClusterStor), DDN, Micron, Nutanix, WEKA for their outstanding results and accomplishments.”
There are both open and closed MLPerf Storage submissions. Closed submissions use the same reference model to ensure a level playing field across systems, while participants in the open division are permitted to submit a variety of models. We only look at the closed submissions as they enable cross-vendor comparisons in principle.
The benchmark was created through a collaboration spanning more than a dozen industry and academic organizations and includes a variety of storage setups, including parallel file systems, local storage, and software defined storage.
MLCommons says that when developing the next generation of ML models, it is a challenge to find the right balance between and efficient utilization of storage and compute resources. The MLPerf Storage benchmark helps overcome this problem by accurately modeling the I/O patterns posed by ML workloads, providing the flexibility to mix and match different storage systems with different accelerator types.
The MLPerf Storage benchmark is intended be an effective tool for purchasing, configuring, and optimizing storage for machine learning applications, as well as for designing next-generation systems and technologies.
Submitting systems are scored for two MLworkloads – medical image segmentation and natural language processing – with samples per second and MBps ratings in each category. MLCommons says samples/second is a metric that should be intuitively valuable to AI/ML practitioners, and the MBps metric should be intuitively valuable to storage practitioners. We look at MBps.
The dataset used in each benchmark submission is automatically scaled to a size that prevents significant caching in the systems actually running the benchmark code. The submitted systems all use a simulated V100 accelerator (Nvidia V100 Tensor core GPU) with varying numbers of these accelerators tested, making cross-supplier comparisons difficult. There are GitHub reference links for details of code per submitter and system.
We have extracted the basic systems and scores data from the full benchmark table. Then we have added a column of our own – MBps per accelerator – to try to normalize performance per accelerator and so enable cross-supplier comparisons:
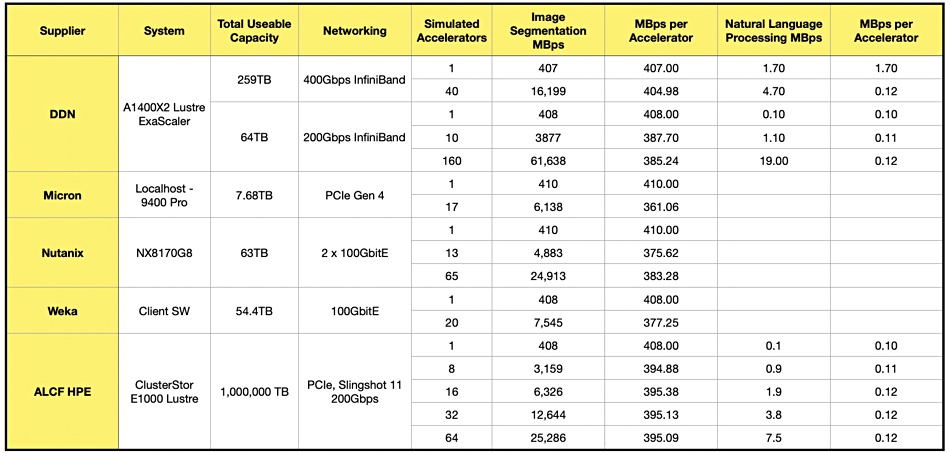
Overall there is not that much difference between the suppliers and systems, with the image segmentation MBps/Accelerator scores bunched between 410 and 361. Micron has both the the highest score at 410, and the lowest, at 361. The natural language processing MBps numbers are much lower, with DDN having the single highest result, 1.7, and all the others varying between 0.12 and 0.10. We suggest it’s good to have a vendor-independent benchmark in this area at all, even if its first iteration is not that informative.
We have no means of relating these numbers to supplier performance when delivering data to Nvidia GPUs with the GPUDirect protocol. There are much greater storage performance variations between suppliers with GPU Direct than with MLPerf Storage.
It would be good to have missing MLPerf Storage performance data for GPUDirect-supporting storage suppliers such as IBM (ESS3500), Huawei (A310), NetApp (A800, EF600) and VAST Data (Ceres). Then we could compare how suppliers look against both benchmarks.
MLPerf Inference v3.1 edge inference results can be inspected here and datacenter inference results here.
DDN Comment
DDN’s SVP for Products James Coomer sent me this note: Chris, you say “We have extracted the basic systems and scores data from the full benchmark table. Then we have added a column of our own – MBps per accelerator – to try to normalize performance per accelerator and so enable cross-supplier comparisons:”
I don’t think that works. This benchmark is like… “how many GPUs can the proposed system drive at a specified performance level”.. so in this case the specified performance level equates to around 400MBps .. but that is defined by the benchmark
The interesting thing is only : how many GPUs are driven (to that rate above) from a given:
- Number of controllers
- Number of SSDs
- Power consumption
DDN drives 40 GPUs from a single AI400X2 (2 controllers).
The other reasonable comparison might be Weka who hit 20 GPUs from 8 nodes (controllers).
Nutanix Blog
A Nutanix blogger noted: “The benchmark metric is the number of accelerators that the storage can keep busy. In the first ML-Perf benchmark report we showed that we were able to supply enough storage bandwidth to drive 65 datacenter class ML processors (called “accelerators” in MLPerft language) with a modest 5-node Nutanix cluster. We believe that 65 accelerators maps to about 8x NVIDIA DGX-1 boxes. The delivered throughput was 5 GBytes per second over a single NFS mountpoint to a single client, or 25GB/s to 5 clients using the same single mountpoint. Enforcing that the results are delivered over a single NFS mountpoint helps to avoid simplistic hard-partitioning of the benchmark data.” This used Nutanix Files software.
Nutanix says Nutanix Files implements a cluster of virtual file-servers (FSVMS) to act as a distributed NAS storage head. We place these FSVMs on our existing VM storage which acts as a distributed virtual disk-shelf providing storage to the FSVMs.
The result is a high performance filer where storage compute load and data is spread across physical nodes and the disks within the nodes – thus avoiding hotspots.
- Each CVM uses all the local disks in the host for data, metadata and write log
- Each FSVM uses all CVMs to load balance its back-end
- Each NFS mount is balanced across all FSVMs using NFS V4 referrals (no client configuration required)
- On the linux client we use the mount option nconnect=16 to generate multiple TCP streams per mountpoint
A Single File-Server VM (virtual storage controller) spreads its data disks (virtual disk shelf) across all nodes in the cluster.
Bootnote
The Standard Performance Evaluation Corporation (SPEC) is developing its own machine learning benchmark. It has an ML Committee and its first benchmark, SPEC ML, will measure the end-to-end performance of a system handling ML training and inference tasks. The SPEC ML benchmark will better represent industry practices by including major parts of the end-to-end ML/DL pipeline, including data prep and training/inference. This vendor-neutral benchmark will enable ML users – such as enterprises and scientific research institutions – to better understand how solutions will perform in real-world environments, enabling them to make better purchasing decisions.




