


Enfabrica is building massive scale interconnect silicon, a Server Fabric Adapter (SFA), an accelerated fabric silicon device to link intelligent end-point devices inside racks and also between racks, bridging the in-rack PCIe/CXL and between-rack Ethernet, RDMa-over-fabric worlds with terabits-per-second bandwidth.
It sees an opportunity in the need for such enormous bandwidth because AI and machine learning is demanding more and more scale of GPU, CPU, accelerators, memory and storage and current networking trends are insufficient. AL/ML resource needs are increasing at a high rate and the network, the data moving architecture in the datacenter, is not keeping up, creating stranded and underutilized resources, expensive GPUs and other accelerators sitting idle.
CEO and co-founder Rochan Sankar told B&F that AI application spread was demanding enormous increases in in-rack and between-rack networking speed: “We’re not talking about what the GPU architecture is optimised for, which is millions of flows running at a megabit per second. Okay. AI is hundreds of lanes running at a terabit per second.”
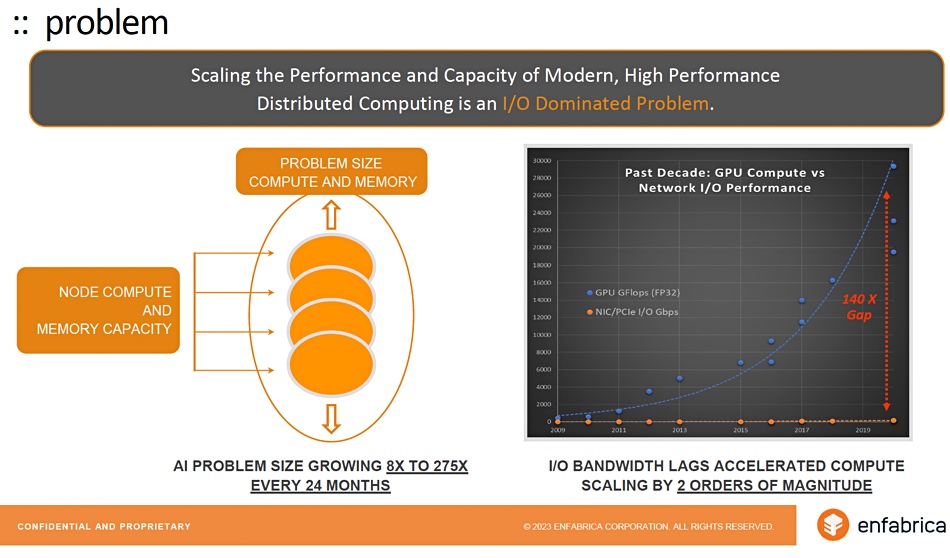
He said the AI problem size (eg, the number of training model parameters) is growing, although he gave a broad range here of between 8x to 275x every two years. GPUs and specific AI processors represent accelerated compute. IO bandwidth lags accelerated compute scaling by two orders of magnitude.
PCIe is an in-chassis, in-rack system interconnect, and CXL, which can bridge racks, won’t deliver true memory pooling until CXL 3.0-class componentry in 2027. That’s late and the consequence is a network bandwidth gap that exists now.
Bob Wheeler, principal analyst at Wheeler’s Network, said in a statement: “With first-generation chips now available, the early hype around CXL is giving way to realistic expectations around performance and features.”
“The CXL-hardware ecosystem remains immature, with CXL 3.x components, including CPUs, GPUs, switches and memory expanders still under development. Meanwhile, hyperscalers have scaled RDMA-over-Ethernet (RoCE) networks to thousands of server nodes. By collapsing CXL/PCIe–switch and RDMA-NIC functions into a single device, Enfabrica’s SFA uniquely blends these complementary technologies, removing dependencies on advanced CXL features that are not yet available.”
PCI and CXL use memory semantics whereas Ethernet and RDMA links use a networking protocol. Enfabrica said industry needs to bridge the two somehow to get consistent interconnect speed inside and between racks. Otherwise, we have stranded and under-utilized compute accelerators like GPUs. Sankar told us a step function increase in bandwidth per $ could help achieve a more sustainable cost of AI and database compute. And an elastic connection fabric that can scale up and down wouldn’t hurt either, according to Sankar.
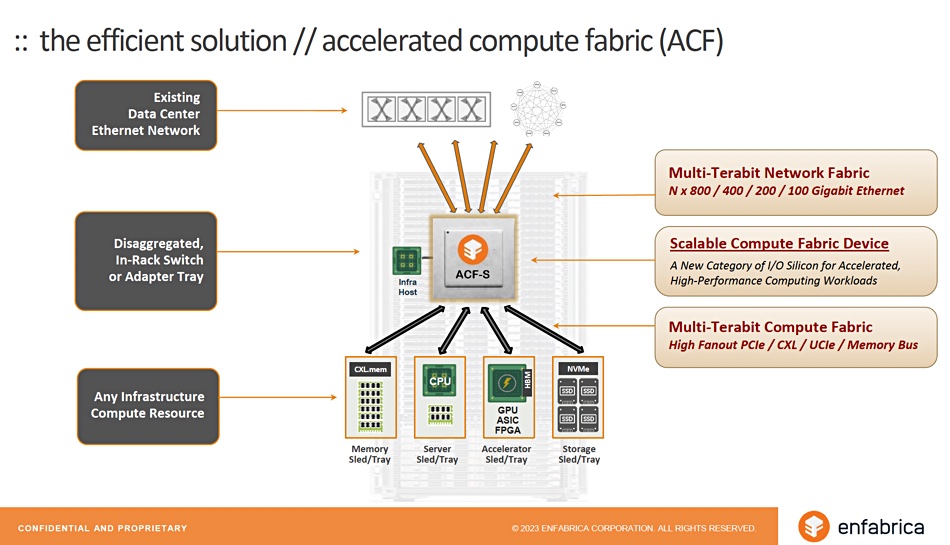
That’s what Enfabrica’s SFA chip is claimed to provide, of course. Sankar told us it uses standard interfaces and doesn’t require changes to application, compute, storage and network elements in the AI/ML IT stack. It can provide access to disaggregated memory before CXL 3.0 arrives but will support CXL 3.0 and not break that standard.
More details of its ACF-S chip functions are shown in a pair of slides:
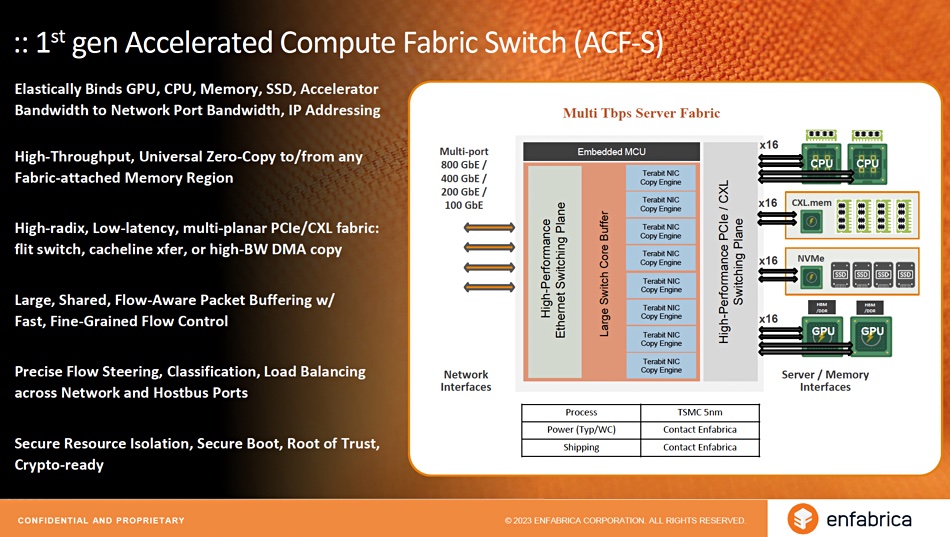
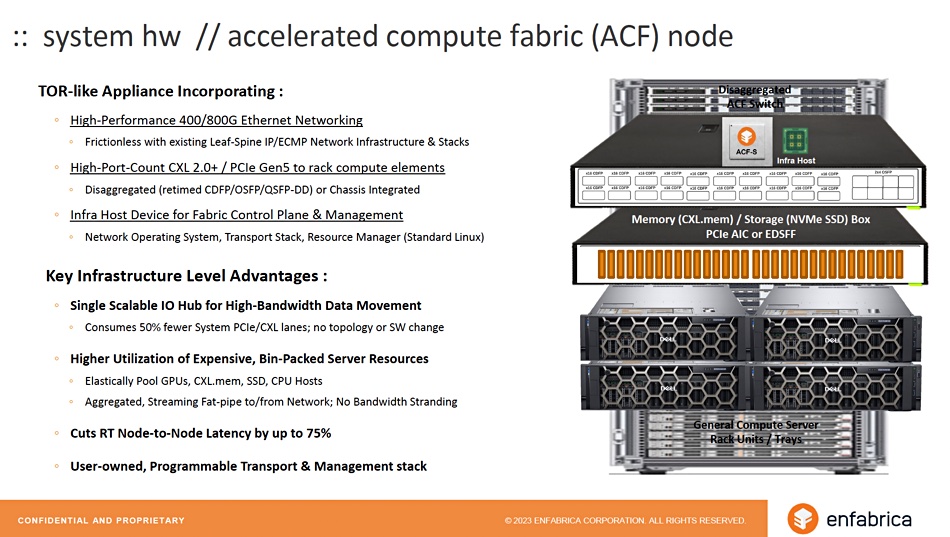
The SFA chip system will, Enfabrica said, have cost, scaling and performance advantages over products from NVIDIA and Grand Teton systems used by Meta:

The company said it sees a $20 billion interconnect market for its SFA chip in 2027 and is targeting public and private cloud operators, HPC and network system builders. The benefits they will see is a removal of existing interconnect components, freeing up space and reducing component complexity in their racks, it added. There will be a great increase in link speed driving up accelerator utilization, shortening AI model training run times and lowering costs:
Sankar suggested there could be an up to 40 percent reduction in AI Cluster total cost of ownership and GPU rack and cluster power draw could decrease by 10 percent. As well as that AI clusters could increase 10x in size, from hundreds of nodes to 1,000s of nodes, facilitating increases in model size and/or decreases in model run times.

This is not a DPU in the Fungible/Pensando style. It’s not aimed at enabling x86 processors to devote more time to application execution. This is more of a networking chip intended to free up stranded accelerator compute devices; GPUs and AI-specific processors, and memory-limited x86 processors, and get them utilized and scaling better so the AI computational gap which Enfabrica has highlighted can be reduced.
There will be product-specific announcements later this year.





