


Nvidia’s CPU-bypass GPUDirect Storage (GDS) technology is now available, and has been added to its HGX AI supercomputer. There are three vendors already in production and five more ramping up.
The HGX is a rack-based system loaded with multiple GPUs to function as a high-end AI acceleration engine. It is based on a 2017 Microsoft HGX-1 OPC design using eight Tesla P100 GPUs and a PCIe interconnect, linking them to Xeon CPUs.
Nvidia introduced its HGX-2 design in May 2018, and it featured 16x Tesla V100 GPUs and 6x NV switches, running at 300Gbit/sec. Nvidia’s DGX-2 server, based on the HGX-2 platform, has added the A100 80GB PCIe GPU along with 400Gbit/sec NDR InfiniBand switching. Quantum-2 modular switches provide scalable port configurations up to 2048 ports of NDR 400Gbit/sec with a total bidirectional throughput of 1.64 petabits per second — a 5x boost over the previous generation.
These numbers are so high as to make traditional SAN and filer users envious, but NVMe over Fabrics technology should make them happier as it gains adoption.
GDS
We have written several times about Nvidia’s GPUDirect CPU-bypass IO technology linking external storage and Nvidia GPUs, and that has been added to the HGX as well.
Magnum IO GPUDirect Storage, to give it its formal name, is now officially available from Nvidia and supported by DDN, Dell Technologies, Excelero, HPE, IBM Storage, Micron, NetApp, Pavilion, ScaleFlux, VAST and WekaIO, among others — get a full list here.
DDN, VAST and WekaIO are in production, while Excelero, IBM, Micron, Pavilion and ScaleFlux are actively adopting it. Several other storage vendors are in the early stages of adoption: Dell EMC, Hitachi, HPE, Kioxia, Liqid, NetApp, Samsung, System Fabric Works, and Western Digital.
VAST Data view
We saw a pre-publication version of a blog by Jeff Denworth, VAST Data’s co-founder and CMO. In it he writes: “Since Magnum IO GPU-Direct Storage (GDS) was originally announced at SC19, the storage world has been on the edge of its seat waiting for Nvidia to unveil its CPU-bypass capability.” There are two benefits of GDS: faster storage-to-GPU links and reduced CPU involvement, meaning the CPU can spend more cycles running application code.
VAST is supplying data to GPUs over GDS using vanilla NFS over RDMA and multi-pathing, not using a parallel file system as, for example, IBM does with Spectrum Scale.
Denworth blogs: “GDS with NFS multi-path scales in performance as you add more network bandwidth to high-end compute servers.”
VAST ran an experiment using both NFS multi-path and GDS on a DGX A100 server configured with eight 200Gb InfiniBand NICs connected to a VAST storage cluster. Nvidia measured over 162GB/sec of read performance via a single NFS mountpoint. He includes a chart to illustrate this:
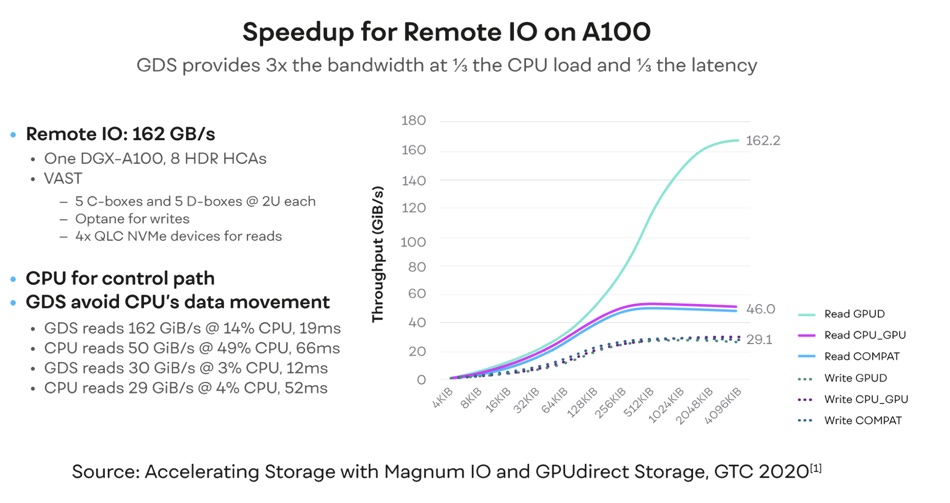
With charts and numbers like this, the use of GDS to link external storage arrays to Nvidia’s GPUs will surely become a default decision.





