


Interview. Ten years after it was founded, as an on-premises scale-out filer supplier, Qumulo is becoming an unstructured data lake services company in a hybrid multi-cloud world, with its own management layer providing a consistent experience across the platforms it supports. Qumulo says it wants to make the infrastructure invisible.
Blocks & Files talked to Qumulo CEO Bill Richter about where the company is now and where it is going.
Blocks & Files: Other companies have started just disassociating themselves from their proprietary hardware, or even from hardware all together. They’ll certify suppliers, say, and design hardware with certified builders. But the hardware that users buy is never on the supplier’s books. Would Qumulo be thinking of doing the same thing?
Bill Richter: We did that. When we built the software, that was the design feature. [It] would always run on standard hardware. Four years ago, we started enabling other OEMs to run our software like HPE; on their hardware. And last year, we completely got out of the hardware business altogether. So today, from a business model perspective, all Qumulo sells is its software and the HCl, the hardware compatibility list, is very large. And it spans the most dense, economical form factors all the way up to screaming fast, all-NVMe form factors.
Where is Qumulo today?
Right now, customers run Qumulo on in their datacentres on standard hardware. And in all three major hyperscale clouds as code.
As code. You don’t use the the Equinix datacentre sidestep?
Absolutely not. We never have. So we run directly natively on cloud infrastructure. And the magic for customers is that they they get the GUI, the enterprise features and capabilities, all the things that they use and rely on … are exactly identical. … So that kind of a universal unstructured data management layer for the multi-cloud world is exactly how you should think of us.
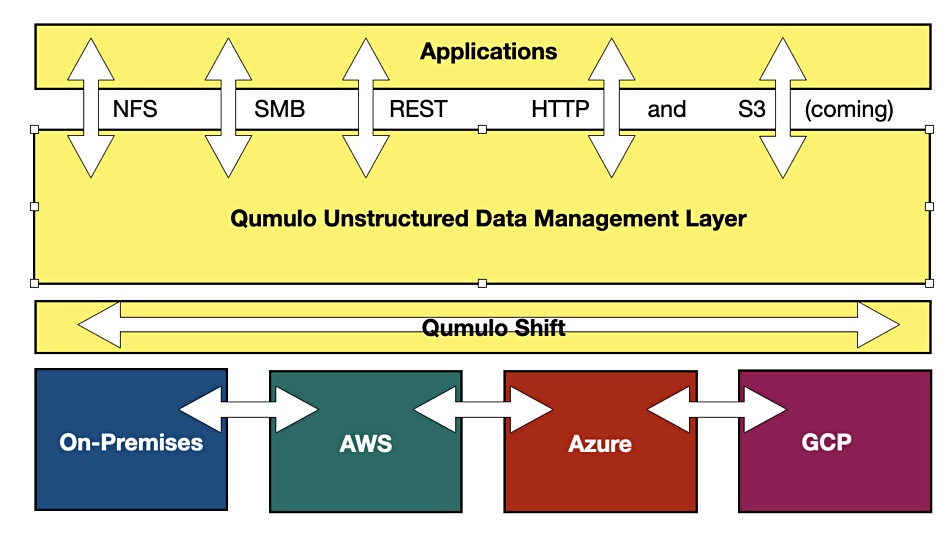
You have your business model so that you’re no longer dependent on on-premises hardware sales. And you support both on-premises and the three main public clouds with a consistent user experience across those four environments. Where next are you going with this platform, with the on-premises datacentre and the four public clouds below it. Are you thinking of erecting some kind of software superstructure on top of that platform? And expanding upwards?
One of the things that customers were most excited about Qumulo in the early days was already analytics stuff. And if you extend that notion into a multi-cloud world, the next set of questions they ask us is, hey, what does multi-environment or multi-cloud management look like? I love that I can run Qumulo, on AWS, and in my datacentre, and scale from one environment to another. Help me manage those environments more elegantly. And that is absolutely a direction that we’re going. There’s no question about it, it’s customer-led.
What will the future be like from Qumulo’s viewpoint?
If you believe as we do that the future is in multi-cloud world, customers will use at least one but perhaps more than one hyperscaler. For these datasets that we serve as they’re very large, they’re at scale, very often customers will have on premises environments; on prem clouds. … What we believe customers want is a multi-cloud platform for their unstructured data. And that’s what we built. It’s very, very different from the legacy box sellers, or even some of the new emergent folks out there that have completely different points of view of what the future should be like.
Can you say more about the sorts of high level functions that you may be thinking of adding to the product?
The direction of the product has three major pillars to it. The first is to allow customers to get out of the business, not just of managing hardware, but out of the business of managing software altogether … and just consume capabilities. So the first major step in that direction is our deployment on Microsoft Azure. That’s very different. That is a service on Azure. So customers go to a UI, they choose … their requirements and then they simply deploy or consume. There’s no notion of upgrades; there’s no notion of managing software. They just consume.
The second one … customers want more and more management features out of us, they want a single pane of glass, to be able to look at these various environments. And then they want to be able to action, they want to be able to click a button and say this application or workload where this pattern of IO is going to move from on-premises to my AWS environment, or vice versa, or from AWS to Azure, or if there’s been a corporate decision at my company.
I don’t want to have to change my data structures, or the way that my information workers do business. I want them to have a like for like experience with Qumulo. … You can set up a simple replication relationship between an AWS environment and Azure or any one of these clouds, and press a button and … inside of a few hours, that data set will be replicated over using our tools. And then the customer is up and running. They can even failover from one environment to another.
The third one, building management for a multi-cloud world. [Adding] powerful features to allow customers to do interesting things with their data. We introduced a product called Qumulo Shift last year, that allows customers to write files and then read them as objects. And be able to shift those concepts or blend those concepts between file and object together.
And the reason that we did that is because we want customers to get max value out of their data. So a specific example there is, let’s say, I’m running a toll bridge. And I’m imaging, car plates or licence plates. And that system is built on file. We might want to take that data set, send it to AWS, transform those files into objects, and use AWS machine imaging software [like] Recognition to register those images and let machines reason over them. And then I might want to send the results of that workflow back into a file workflow. And so instead of having a point of view that this world of file an object has to be separate, forever, our point of view is, hey, how do you allow customers to blend these concepts?
Are you doing anything with Nvidia? You’ve got this great file platform and Nvidia needs data for its GPUs.
We are increasingly the unstructured data lake that sits behind Nvidia GPU farms.
Now, that’s an interesting thing to say. I see Nvidia having two requirements in storage very, very simplistically. One is, if I’m an Nvidia GPU server, I need a frighteningly fast, high bandwidth data server to keep my GPUs busy. But this primary store, isn’t where I keep everything because there’s too much to keep. So I need something behind it and you’re the first person I’ve come across that said, we do that.
Yes, that’s that’s really where we operate today. There are lots of products to keep GPUs maximally computing. And I completely agree with you. One hour later, that data needs moving. And the scale is massive. And the complexity of that data is significant. And so when you look at Qumulo, unstructured data lake, it has all four major file protocols NFS, SMB, Rest and HTTP. And very soon we’ll have S3. And so if you think about the five, that makes the five, inclusively, the five major unstructured data, protocols, being able to write and read and transcribe in a single, unified multi-cloud, unstructured data lake; that completes the grand plan for customers around their data analytics environments, and we’re pulled into that very often.
Okay, does that mean that you’ve made a conscious decision that you’re not going to go and partner Nvidia with things like GPUDirect?
We might, we might. That’s not off the table for us. It’s just that we’re doing so well in the at scale, unstructured data lake. That’s such a pronounced need for customers and it’s unfulfilled, if not for Qumulo. That’s keeping us quite busy today.
I can understand that because I think the primary storage for GPU servers might be in the tens of petabytes. The secondary storage is probably going to be in the hundreds of petabytes; maybe extend out to exabytes. You’re going to want to move the darn stuff off primary storage.
Yes. Then the other part of that equation is this multi-cloud point. You might have a GPU farm that’s training a model. And, of course, that’s important. But then what? And now that you’ve produced that dataset, how are you going to manage it across clouds? And that’s very much where Qumulo comes in. I know some vendors say no, no, it just will be on me in this datacentre in this rack forever. That’s just not how it is.
Because it’s not going to happen. Because racks have finite sizes and datacentres have finite sizes. And components have finite limitations. It’s not going to happen.
Yes. You know, something like storage class memory (SCM), for example, is kind of an interesting concept for one very specific thing. But going to a CIO, which I do often, they don’t want to talk about that. They want to talk about at-scale data management across clouds. Yes. Now somebody does [SCM-type stuff], and we, of course, get that, but that’s just not our market.
Suppose I say that my mental landscape round files is three sided, roughly speaking. On one side, there’s NetApp. On another side there’s Isilon and PowerScale. And the third side of this triangle is WekaIO and very fast scale out parallel storage. Spectrum Scale might be another one. Where in that space would you position Qumulo? Would it be in one place? Or would it be in several places?
I like to do it slightly differently, but I’ll use your three. Now we all think NetApp created the market back in the 90s. But the file system was created for Office document consolidation, fundamentally, which was a great innovation. And people had to get PowerPoint off their desktop and into a shared central storage environment.
PowerScale, Isilon, you know – that’s my old company. The notion there was that people were going to do more with file then than Office documents and so large file formats for the media and entertainment industry, and kind of digitising content was the core use case, but very much still with a proprietary hardware and systems approach. Dell might say Isilon is software-defined, except you can only buy it on this piece of Dell hardware period. I don’t think that that passes the sniff test for anybody.
This other group, like the one you mentioned, like any sort of parallel file system has its place. They’ve been around for a long time, like GPFS. There are science experiments, though. They require client-side drivers, they require an enormous amount of complexity. And it’s all about the infrastructure. If you have a very specific need, and you’re willing to invest the people, the significant amount of money, and the time to go make that work for very narrow need, you’ll do it. We have a completely different point of view, which is, instead of making it all about the infrastructure, we don’t want customers to even think about the infrastructure.
I understand that that plays back into the the invisible infrastructure part of Qumulo’s message.
You got it. And and the truth is in the history of time, you’ve never seen a parallel file system become standard in an enterprise because it’s very complicated for labs, for very specific use cases. For hardcore and sometimes ageing storage administrator, folks, it does have a good use case, but the broad enterprise that’s trying to scale and meet business requirements, and bring down costs and get onto the value of the data, not just the sort of production of it; that’s really our market.
To maybe round that out, we take share from NetApp. We take share from all the legacy folks as you can imagine – Dell PowerScale, IBM. And there are some of the emergent vendors that have made specific hardware optimizations. We see them sometimes, but actually less than you might think,
That will be like, for example, possibly StorOne and VAST Data to name a somewhat louder voiced competitor?
We see them. We actually are very happy with our win rates against them. But we see them less than you might think.
How’s the business doing? Can you provide any numbers without betraying any commercial secrets, run rates or customer numbers or deployed units or something like that?
We just crossed over $100 million of pure software sales [run rate]; now we just simply only measure software. We have nearly 700 independent customers and well over 1,000 deployments. There’s multiple exabytes of data out there in the world that’s being managed on Qumulo.
You can’t have 700 customers, and 1,000 deployments without having something that’s becoming quickly the standard for the enterprise. And the big question that I get get asked – not so much from folks like you, but from customers – is what’s the experience? We measure NPS every single quarter and it lands somewhere between 85 and 90.
That’s a very high score.
It’s high, particularly when the basis of customers is high. Because it’s easy to make three customers happy. If you have 700, that relies on the fit and finish of the product and technology, and then the at-scale way that we’ve designed the business to service those customers.





