Cybersecurity supplier Varonis Systems is partnering with Pure Storage to provide a data security and cyber resilience system to prevent breaches and deliver rapid recovery if disaster strikes.
Varonis competes with firms like CrowdStrike and Palo Alto Networks. Its software and services enable customers to proactively secure their sensitive data, detect threats, and comply with evolving data and AI privacy rules. It is the first data security company to natively integrate with Pure Storage. This integration is based on the high-performance, immutable storage provided by Pure and wide-ranging data security delivered by the Varonis Data Security Platform.
Dan Kogan
Dan Kogan, Pure VP of Enterprise Growth and Solutions, stated: “With this partnership, Pure Storage and Varonis are empowering organizations to proactively secure critical and sensitive data, detect threats, and recover rapidly from cyber incidents. By combining Pure Storage’s layered resilience approach and indelible snapshots with Varonis’ intelligent data security, customers can confidently protect their unstructured data, mitigate risk, and maintain uninterrupted operations.”
The partnership enables Pure Storage customers to automatically:
Discover and classify sensitive data –Varonis scans data in Pure Storage FlashArray and FlashBlade systems in real time, matching classification results with identities, permissions, and activity to identify and fix exposed or at-risk data.
Reduce data exposure –Varonis maps complex permissions, such as nested groups and inheritance, right-sizes access, and automatically fixes excessive permissions, such as removing over-privileged access.
Detect and stop threats –Varonis uses AI and machine learning to analyze user behavior to detect threats, suspicious activity, and malicious insiders.
In general, Varonis directly accesses metadata from Pure’s storage arrays, using Pure APIs to perform real-time data discovery and classification and analysis of file access patterns and user activity. This visibility enables customers to right-size permissions, uncover overexposure, and detect abnormal behavior that could indicate insider threats or unauthorized access. Automated remediation capabilities enable Varonis to address issues like risky permissions or mislabeled files swiftly, reducing the potential blast radius in case of an attack.
Pure’s FlashArray and FlashBlade systems have immutable snapshots and recovery from cyber incidents takes advantage of them.
Varonis has a Managed Data Detection and Response (MDDR) service with which Pure Storage customers can take advantage of a 24x7x365 incident response SLA.
Varonis acquired Cyral in March for its ability to reduce data exposure and mitigate AI-related risks. It partnered with Concentrix earlier this month to deliver end-to-end AI security capabilities and became a Sustaining Partner with Black Hat, joining other cybersecurity firms like CrowdStrike.
Varonis EVP of Engineering and CTO David Bass said: “Ensuring the security of data – and the data powering AI – is challenging and critical. More and more customers rely on Pure Storage to harness the full potential of their AI data, from ingestion to inference. Customers love Pure Storage, and we are thrilled to partner to ensure that they can innovate with AI securely.”
VAST Data is open sourcing its VUA (VAST Undivided Attention) KVCache software technology to store generated AI model training and inferencing tokens in NVMe-connected SSDs for fast transfer GPU memory to avoid recomputing them.
A KVCache is an in-memory store of AI LLM tokens, keys and value vectors, generated in an attention phase of a model’s inference processing. The tokens are generated sequentially and provide a context for the model. In this multi-stage process, with the model generating one token at a time, the next step after the current one would require it to recompute all the tokens in the sequence thus far. Holding them in a server’s GPU and then CPU memory avoids this recomputation and speeds multi-step token generation. But, as LLMs deal with more and more parameters the available GPU memory gets full, overflows, and limits the KVCache token count, slowing model processing. VUA stores generated tokens evicted from the in-memory cache in NVMe-connected SSDs, a third caching tier, so they can be re-used instead of being recomputed. VUA is software providing this SSD caching of KVCache tokens.
Jeff Denworth
Such evicted context could be stored back in the source data repository, a cloud object store for example. But, VAST co-founder Jeff Denworth blogs: “Yes, caches can be rehydrated from remote disk, but this today is a clumsy and disconnected operation that often depends upon (and suffers from) slow cloud object storage. The time to rehydrate the context and session is so long that several leading AI-as-a-service shops choose to simply recalculate an entire prompt history rather than grab all of the context and attention data from object storage.”
A second VAST blog notes “AI models are increasingly evolving to store larger contexts, or knowledge, into a model. To put this into perspective, LLaMA 1 was released in 2023 with support for a context window of 2,048 tokens. Fast forward to LLaMA 4, just announced last week by Meta, which can support new AI models with up to 10 million tokens. …Ten million tokens consume far more memory than can be accommodated in GPU memory, so larger storage and caching methods are required.”
Denworth says the vLLM GPU and CPU memory paging scheme “does not integrate with distributed NVMe based systems to provide another tier in the memory hierarchy, nor is it global…so GPU environments are divided into small and divided caches.”
What VAST has “built is a Linux-based agent that runs in your GPU servers and provides a new data presentation layer to AI frameworks.” It is “a hierarchical system to manage data across GPU memory, CPU memory and shared, RDMA-attached NVMe storage subsystems,” such as VASTs storage that supports Nvidia’s storage controller CPU-bypass RDMA-using GPUDirect protocol.
Denworth says: “VUA layers in the ability to intelligently store and serve prefixes” so they “can be served according to priority and policy. For example, the longest prefixes associated with a sequence can be served first to a GPU machine so that the full self-attention of a session can be most quickly understood.” VUA can search through billions to trillions of prefixes in on-SSD Element Store data structures” using wide-fanout V-Trees that can be searched through in millisecond time across massive metadata spaces.
Another way to describe this is to say it has intelligent prefix caching: “VUA surpasses basic caching by breaking down attention keys into chunks, which are stored in a nested structure. This enables sophisticated partial context matching using longest prefix identification, significantly improving cache hit rates in workloads such as Retrieval-Augmented Generation (RAG), where the same base documents appear across multiple distinct prompts.”
The VUA system “is global. Each GPU server now has shared access to the same extended context cache space, the same rapidly-searchable metadata space and the same global context and attention data and data index.”
Denworth says this VUA “accelerator, in terms of data sharing, only works north-south today (each machine sees a global hierarchical data space, but machines don’t see what’s in each other’s cache… so a CPU/GPU memory cache miss always goes to NVMe).” VAST is “considering a globally distributed cache where machines will also be able to see their peers within or across data centers and do low-latency retrieval of relevant keys and values based upon the above prefix filtering.”
VUA is now available as open source SW providing a prefix-search-based global and exabyte-scale KV cache, using NVMe SSDs, accessible throughout a GPU cluster. It integrates with popular AI inference workloads “providing infinite context scalability” and reduces “time to first token (TTFT) while also saving significantly on GPU and CPU memory.”
VUA shortens TTFT and also the average time to generate each subsequent token or TPOT (Time Per Output Token). It “enables persistent conversational state across turns or sessions. KV caches representing prior dialogue can be stored in off-GPU memory between queries, freeing GPU resources while retaining the ability to resume context quickly.”
VAST tested TTFT on a vLLM system, using the Qwen2.5-1.5B-Instruct model, with and without VUA, and found adding VUA made the test system 292 percent faster at the 30,000 token level:
It says VUA is particularly valuable for applications requiring common question prompts, multi-round dialogues (faster context switching), long document Q&A (improved throughput), and high-concurrency scenarios (reduction in preemptions).
WEKA and Hammerspace
B&F wrote in March that Parallel-access filesystem supplier WEKA announced “A new Augmented Memory Grid feature enables AI models to extend memory for large model inferencing to the WEKA Data Platform. It’s a software-defined extension, which provides exascale cache at microsecond latencies with multi-terabyte-per-second bandwidth, delivering near-memory speed performance. This provides additional petabytes of capacity, said to be 1,000x more “than today’s fixed DRAM increments of single terabytes.”
This is similar to VAST’s VUA.
Data orchestrator Hammerspace’s Tier Zero feature adds “a GPU server’s local NVMe flash drives as a front end to external GPUDirect-accessed datasets, providing microsecond-level storage read and checkpoint write access to accelerate AI training workloads.”
And: “By incorporating these drives into its Global Data Environment as a Tier 0 in front of Tier 1 external storage, they can be used to send data to GPUs faster than from the external storage and also to write checkpoint data in less time than it takes to send that data to external storage.”
Hammerspace is not providing a KVCache facility on such Tier 0 SSDs – but it could and then would provide even more acceleration to AI inferencing workloads
VAST said it invites “the AI community to explore, use, and contribute to the VAST Undivided Attention project. Source code, documentation, and initial usage examples are available at https://github.com/vast-data/vua.” We understand that using VUA with non-VAST storage would likely introduce latency or compatibility issues, as VUA’s performance depends on VAST’s ability to search and serve data in constant time via its V-Tree technique.
Cohesity RecoveryAgent is AI-powered recovery orchestration software for Cohesity NetBackup and DataProtect customers.
It is the first product to emerge from the joint development efforts of Cohesity and Veritas since the companies merged in December 2024. RecoveryAgent combines the capabilities of NetBackup Recovery Blueprints and Recommended Recovery Points with AI-powered intelligence and technology native to DataProtect. It generates customizable blueprints that automate recovery workflows, making cyber recovery response more efficient and adaptable. Customers can better prepare for cyber incidents before they happen.
Vasu Murthy
Cohesity chief product officer Vasu Murthy stated: “Having a comprehensive and thoroughly tested incident response plan can be the difference between minimal disruption and massive impact. By simplifying and automating every step of the complex cyber recovery process, RecoveryAgent helps customers boost resilience and respond faster with more confidence to cyber incidents.”
The RecoveryAgent UI enables IT staff to build recovery plans with scripted workflows that automatically integrate steps for incident response, such as threat hunting, malware scanning, and instant data restores. It can automate forensics investigation, configuration hardening, and patching when orchestrated on virtual machines that are recovered with it.
Users can manage granular recovery across multiple domains in complex hybrid environments, including on-premises, cloud, PaaS, and containers. They can rehearse recoveries to prove the blueprint will effectively recover their data in a non-production environment without impacting production applications. This frequent testing helps ensure readiness for real-world incidents.
Cohesity says RecoveryAgent helps customers increase confidence in their ability to recover cleanly from incidents with intelligent recovery point recommendations powered by agentic AI and blast radius analysis of infected files across domains.
RecoveryAgent implements standard recovery practices and is designed to support compliance with DORA, NIS2, and other recent legislative requirements. It speeds up forensic investigations through integrated and automated threat scanning using native tools delivered by Cohesity Data Security Alliance partners.
RecoveryAgent is currently available to select customers in Tech Preview and is expected to be generally available for NetBackup and DataProtect customers in the second half of calendar 2025. A RecoveryAgent video provides more information.
HYCU has added R-Shield anomaly and ransomware detection, fortified protection, and instant recovery features to its R-Cloud data protection-as-a-service offering.
R-Cloud, with R standing for Resiliency, is the renamed Protégé backup and recovery service. It provides data backup and recovery for on-premises, public clouds, hybrid clouds, and Software-as-a-Service (SaaS) apps. R-Shield is designed to protect and provide always-on detection and recovery capabilities for distributed IT environments with VMs, data warehouses, finance applications, storage buckets, and git repositories. It is intended to protect them against both cybercriminal attacks and human error.
Simon Taylor
Simon Taylor, HYCU founder and CEO, stated: “What’s been missing from data protection solutions to date is comprehensive protection for the entire data estate. Most solutions offer only limited liability protection focused narrowly on VMs, leaving critical parts of the data estate exposed and difficult to recover … With R-Shield, we’re providing organizations with the ability to protect and recover data that was previously challenging at a minimum or nearly impossible to secure.”
HYCU says R-Shield offers constant protection based on a hardened backup service built on a virtual appliance with DISA-STIG certification. It has a near-zero network footprint with backup data cloaking and an isolated, independent network. There are no proxy servers, agents, or gateways to help reduce vulnerabilities. An R-Lock feature provides customer-owned, offsite, immutable backups for on-prem, cloud, SaaS, and AI/ML workloads.
R-Shield scans near-production copies of virtual data using rule-based and anomaly-driven malware detection without touching backup storage, with real-time alerts sent directly to customer SIEM systems. There is SaaS, app-level, and service discovery so customers can visualize as-a-service infrastructure and apps used by departments and identify unprotected applications. R-Shield continuously monitors for suspicious activities across protected data sources for hybrid and SaaS workloads.
There is continuous validation of backups within single and complex distributed environments. Recovery can be at a site or granular levels, and there is offline recovery to ensure offsite, offline access to cloud and SaaS data. HYCU says this provides protection against supply-chain attacks that many traditional data protection offerings may not fully address.
Chris Evans, principal and founder of Architecting IT, said: “The ability to visualize your data estate, detect anomalies, and ransomware, and recover quickly are must-haves in any cyber resilience solution.”
AWS has lowered the price of its fast S3 Express One Zone object storage service, affecting storage, reads, writes, data uploads, and retrieval per byte with reads seeing the maximum reduction at 85 percent. Price examples are for AWS’s US East (N. Virginia) region.
Read requests – $0.00003 per 1,000 requests with no request limit vs $0.0002 per 1,000 requests up to 512 KB before.
Storage – $0.11/GB/month vs $0.16/GB/month – a 31 percent reduction
Write requests – $0.00113 per 1,000 requests with no limit vs $0.0025 per 1,000 requests up to 512 KB; a 55 percent reduction.
Data uploads and retrieval components – $0.0032 and $0.0006 per GB compared to $0.008 and $0.0015 per GB respectively; a reduction up to 60 percent.
…
Data integration supplier Fivetran has monitored data movement by its customers and says companies are investing heavily in training LLMs, refining ML models and automating critical business processes. Its numbers show that AI-driven data demand grew by 690 percent in 2024. Legal firms saw a 211.2 percent growth in data volumes as they are processing massive volumes of contracts and case data using AI. Healthcare’s 99.7 percent growth shows demand for AI-driven solutions in patient diagnostics. Retail (+54.2 percent) and manufacturing (+64.7 percent) are using AI to optimize supply chains, predict demand and automate operations. Insurance (+40.7 percent) and financial services (+27.5 percent) are leveraging AI to detect fraud, model risk, and improve customer experiences. AI-powered underwriting and automated compliance monitoring are driving major shifts in how financial data is handled.
…
Hitachi Vantara released its FY2024 Sustainability Report, marking the second edition of its annual ESG progress and transparency reporting.
…
IBM announced Q1 2025 results with revenues up 1 percent year-over-year to $14.5 billion and GAAP profits of $1.1 billion, down 31 percent. Software brought in $6.3 billion, up 7 percent and the highlight. Consulting delivered $5.1 billion, 2 percent down, while Infrastructure brought in $2.9 billion, a 6 percent decline. Financing returned $191 million, down 1 percent while Other revenues were 43.5 percent down at $61 million. CEO Arvind Krishna said: “We’re off to a strong start in 2025, exceeding our expectations for the quarter, driven by solid revenue growth, profitability and cash flow generation. While sentiment and the operating environment have been rapidly shifting, our performance reflects the continued success of our focused strategy around hybrid cloud and AI—especially where clients are looking for cost savings, productivity gains, and trusted partners to help them move fast and scale.”
Note the strong seasonal pattern with Q4 peaks and Q1 drops
Krishna’s outlook in these times of Trump’s tariff turbulence was quite stable in tone: “While it is still very early in the second quarter, we have not seen a material change in client buying behavior. With the caveat that the macro situation is fluid, based on what we know today, we are maintaining our full year guidance for accelerating revenue growth to 5 percent plus and about $13.5 billion of free cash flow.” IBM has z17 mainframe revenues to look forward to in the next and subsequent quarters.
Stability exemplified!
…
The presentations of the IBM Storage Scale User Group Meeting 04/2025 can be found here.
…
Self-hosted cloud SaaS backup storage services supplier Keepit has teamed with disti Ingram Micro to expand access to Keepit’s services for VARs, MSPs, and managed security service partners (MSSPs) in the UK.
…
MSP-focused CSP Livewire has selected VergeOS from VergeIO as its alternate virtualization offering for those not wishing to upgrade to new VMware licensing. VergeOS offered Livewire a smooth transition path with native migration tooling, an intuitive interface familiar to VMware users, and compatibility with existing infrastructure. VergeIO’s support ecosystem provides guided proof-of-concept deployments, hands-on migration services, and 24×7 engineering assistance.
…
Lucidity’s Q1 product release includes updates designed to streamline scaling IT operations for enterprise customers. Highlights include:
Bulk onboarding via CSV with smart batch scheduling and job tracking
Revamped Jobs module for bulk agent installation with success metrics and progress tracking
Azure permission visibility enhancements to meet evolving compliance requirements
Support for Linux data volume onboarding via CSV
Cleaner policy management across AutoScaler agent installation with success metrics and progress tracking
…
Cloud file services supplier Nasuni announced 189 percent growth in the AEC sector in the last two years, almost tripling data under management. Nasuni is supporting over 250 global AEC firms, including 8 of the 10 largest firms in the US, to defend their data, while enabling global collaboration. Customers include Perkins & Will, GeoVerra, LEO A DALY, Kimley-Horn, McKim & Creed, and Ramboll Global.
…
Veeam object storage backup target supplier Object First has added a Pay-As-You-Go consumption business model alongside the traditional CapEx model. It says it now offers backup capacity from 17 TB to 7 PB with no upfront payment, monthly billing and a 1-year subscription. Users can achieve greater cost efficiency with lower per-TB pricing as they scale. All technology refreshes, service, support, and software updates are included. Customers do not pay for the appliances themselves – just for the storage that is used. Customers can reduce the risk of over- or under-sizing with Object First’s Storage Calculator, expert support, and access to an experienced partner network.
…
Henry Marshall
Hyperscale analytics data warehouse supplier Ocient, which has doubled revenues for the third successive year, has closed its $132 million Series B funding and appointed Henry Marshall, previously with space infrastructure provider Loft Orbital, as CFO. Total invested funding is now $159.4 million. The B-round started in 2021, continued in 2024 and has now closed. New investors taking part in the Series B close, amounting to $42.1 million, included Allstate Strategic Ventures, Blue Bear Capital, Solidigm (SK hynix’s SSD-building subsidiary), Massive, Zelkova, and Northwestern Mutual. The cash will be used for the development and delivery of energy efficient solutions – including, we think, high-capacity Solidigm SSDs – for costly, complex, and operationally burdensome data and AI workloads.
Ocient recently launched its first named system, the Data Retention and Disclosure System for telecommunications, which enables service providers to meet lawful disclosure requirements far below the mandated timeframes and for significantly less cost and energy. It said its deepening work with industry partners including AMD, Vertosoft, Solidigm and Amdocs, and has recently been accepted into the Nvidia Inception program.
…
Universal data lakehouse supplier Onehouse says its OpenEngines software automatically deploys and integrates with lakehouse tables, eliminating the headaches of manually deploying engines to support new use cases and providing a simpler alternative to commercial counterparts. Engines supported include Apache Flink for stream processing, Trino for distributed SQL queries for business intelligence and reporting, and Ray for ML, AI and data science workloads. The engines are deployed on Onehouse Compute Runtime (OCR), a specialized lakehouse runtime, and can access tables that are continuously optimized for performance. Together, these innovations accelerate queries 2x to 30x and reduce customer cloud infrastructure bills 20 to 80 percent.
…
Operant AI, claiming to be the world’s only Runtime AI Defense Platform, announced its AI Gatekeeper product to bring end-to-end runtime AI protection to everywhere enterprises are deploying AI Applications and AI Agents – from Kubernetes to hybrid and private clouds. It says AI Gatekeeper not only brings Operant’s powerful 3D Defense capabilities beyond Kubernetes, it also provides completely new industry-first defenses against rogue agents, including trust scores, agentic access controls, and threat blocking for MCPs (Model Context Protocols) and Agentic AI Non-Human Identities (NHIs).
It says that, as enterprises deploy increasingly sophisticated AI Applications and Agentic AI workflows, the sprawling cloud footprint required to support such complex systems has become critically difficult to secure. AI Applications and agents are not only being built on cloud hyperscalers like Amazon EKS, Fargate, Bedrock, and similar services from Azure and Google Cloud, they are now expanding onto non-traditional platforms like Databricks, Snowflake, and Salesforce. The AI ecosystem – and the threats that come with it – are shifting closer to where the data that fuels AI actually lives. As a result, security and threat exposure are expanding. AI Gatekeeper blocks rogue AI agents, LLM poisoning, and data leakage wherever AI apps are deployed, securing live AI applications end-to-end beyond Kubernetes and the Edge.
…
Vector database startup Pinecone launched the first remote MCP server to bring knowledge to agentic workflows. Every Pinecone Assistant will now also be an MCP server. The Developer MCP Server integrates into IDEs, enabling vector database prototyping and accurate code generation with tools like Cursor. The Remote MCP Server provides context from proprietary data for precise, hallucination-free RAG and agentic workloads. A general blog tells you more with a Pinecone Assistant blog focusing on that aspect.
…
Chinese-founded but Silicon Valley headquartered PingCAP has launched TiDB v8.5 of its distributed SQL database. This is a unified platform for data transactions, real-time analytics and AI applications. It delivers performance similar to NoSQL with the resilience and reliability of a transactional RDBMS, making it a good choice for hyperscale SaaS services like Pinterest, Plaid and Bolt.
TiDB 8.5 includes built-in support for vector and hybrid search, along with enhancements to full-text search that improve retrieval accuracy for RAG and other AI-powered applications. TiDB 8.5 also includes enhancements such as global indexes, parallel query execution and foreign key support. TiDB’s managed Cloud Dedicated option now supports Microsoft’s Azure cloud in addition to AWS and Google Cloud. Support for Alibaba Cloud International is coming soon.
…
Pure Storage Cloud for Azure VMware Solution is now in public preview. You can take a look at this new fully managed Azure Native service in a blog.
…
Scale-out filesystem supplier Qumulo announced the availability of Pay-As-You-Go pricing for Cloud Native Qumulo (CNQ) in the AWS Marketplace. It says Pay-As-You-Go is ideal for customers evaluating cloud storage without committing to an upfront purchase. As organizations migrate data to the cloud, they can better assess costs based on actual usage. The existing Prepaid Credits are ideal for customers who want to align with a pre-budgeted procurement model or are happy to pre-pay in exchange for a discounted rate. Credits are consumed as the product is used, just like Pay-As-You-Go. Cloud Native Qumulo (CNQ) Pay-As-You-Go is available now in AWS Marketplace. Pre-paid pricing remains available for volume-based discounts for enterprise customers with predictable workloads.
…
China’s Sangfor Technologies, a supplier of cloud computing and cybersecurity, has been named a Sample Vendor in Gartner’s A Guide to Choosing a VMware Alternative in the Wake of Broadcom Acquisition report, published March 18, 2025. It says its Sangfor Hyperconverged Infrastructure (HCI) has been recognized as a tactical alternative for organizations seeking to modernize infrastructure while mitigating risks associated with VMware’s acquisition by Broadcom.
…
App HA and DR supplier SIOS Technology announced a strategic partnership with DataHub Nepal, which supplies co-lo, hosting, datacenters, cloud, and managed services in Nepal. The collaboration aims to strengthen the availability and resilience of mission-critical applications for businesses across the region.
…
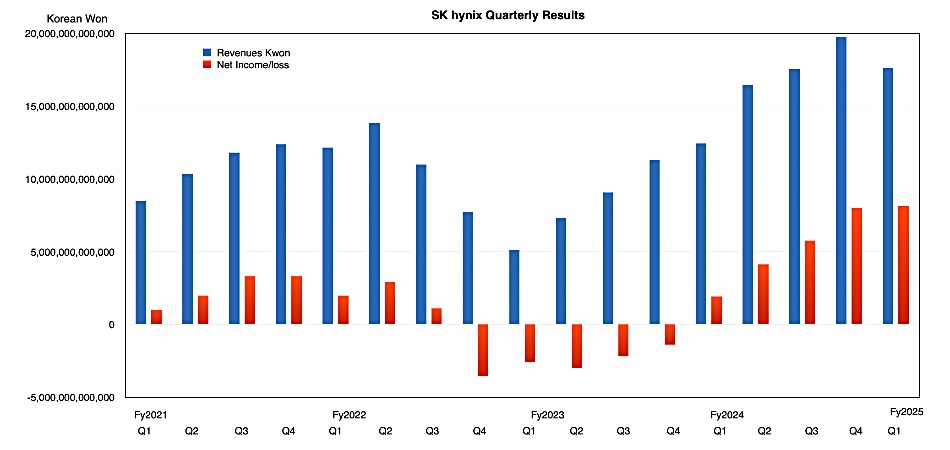
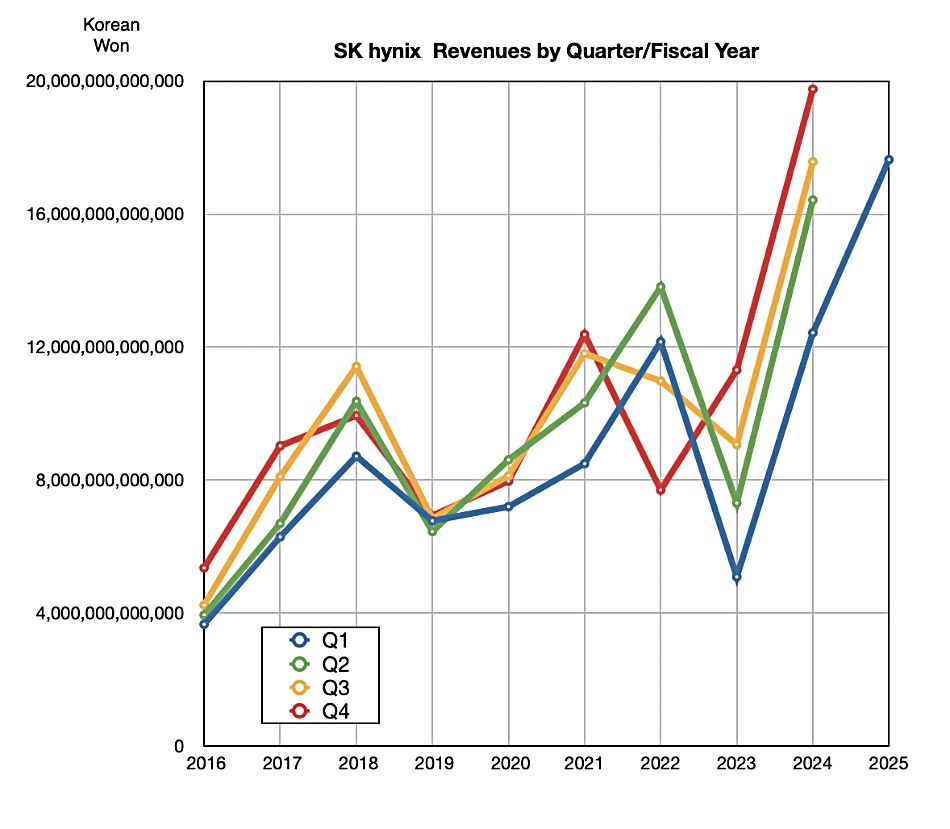
Korean DRAM and NAND fabber SK hynix’s revenues for its first 2025 quarter were 17.6391 trillion won ($12.4 billion), its second-ever highest, with 8.1082 trillion won ($5.7 billion) in net profit. It said the memory market ramped up faster than expected due to competition to develop AI systems and inventory accumulation demand. It responded to the demand with an expansion in sales of high value-added products such as 12-layer HBM3E and DDR5.
The latest revenue result is a sequential downturn after seven successive growth quarters
Due to the characteristics of the HBM market, in which supply volume is mutually agreed a year in advance, the company maintains its earlier projection that HBM demand will approximately double compared to the last year. As a result, sales of 12-layer HBM3E are expected to favorably increase to account for over 50 percent of total HBM3E revenues in the second quarter. For NAND, the company plans to actively respond to demand for high-capacity eSSD, while maintaining profitability-first operation with cautious approach for investment.
…
SMART Modular has expanded its CXL Offerings with the E3.S 2T 128 GB CMM (Compute Express Link Memory Module) being added to the CXL Consortium’s Integrator List. The E3.S 2T 128 GB CMM utilizes the CXL 2.0 standard, providing a PCIe Gen5 x8 interface and supporting up to 128 GB of DDR5 DRAM. It’s designed to enhance server and datacenter performance by enabling cache-coherent memory expansion, good for HPC, AI, ML, and other data-intensive applications. This complements the existing listing of SMART’s 4-DIMM and 8-DIMM CXL memory Add-in Cards (AICs).
…
Data warewhouser Snowflake unveiled research revealing 93 percent of UK businesses are reaping efficiency gains from the adoption of generative AI, outpacing the global average of 88 percent. As many as 98 percent of UK businesses say that they’re training, tuning or otherwise augmenting their LLMs to capitalise on the success of gen AI. Yet just 10 percent of UK businesses have a high level of capability when it comes to using unstructured data for gen AI. Despite this, 93 percent of UK businesses say they plan to increase spending on cloud-based data warehousing solutions over the next 12 months. The “Radical ROI of Generative AI,” research report by Snowflake, in collaboration with Enterprise Strategy Group, surveyed 1,900 business and IT leaders across nine different countries — all of whom are actively using gen AI for one or more use cases.
…
StorONE has announced an expansion of its strategic partnership with Phison Electronics to launch an AI-native, intelligent on-premises storage platform. Available in Q2 2025, the joint system combines StorONE’s platform with Phison’s aiDAPTIV+ memory extension technology to support secure, scalable LLM training and natural language-accessible storage management.
…
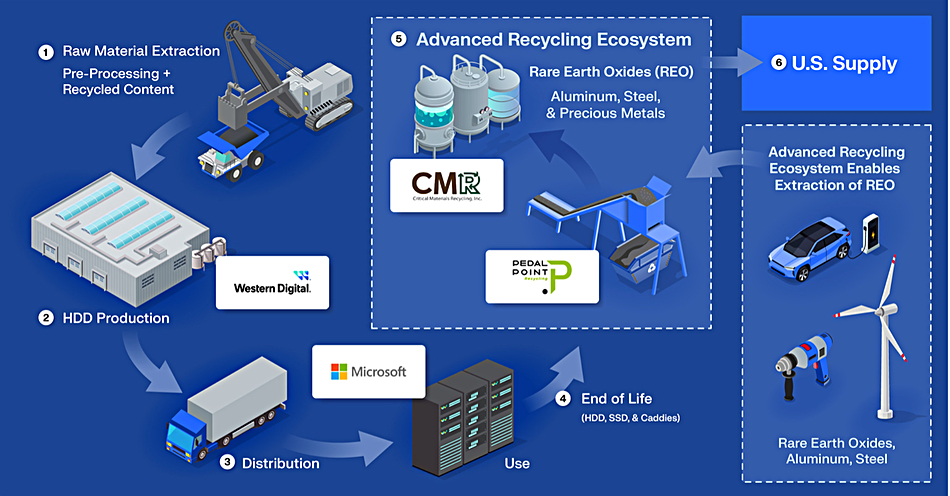
HDD manufacturer Western Digital, in collaboration with Microsoft, Critical Materials Recycling (CMR) and PedalPoint Recycling, announced that its multi-party pilot program transformed ~50,000 pounds of shredded end-of-life HDDs and other materials into critical rare earth elements (REEs), while reducing environmental impact. HDDs use a range of rare earth elements (REEs) like Neodymium (Nd), Praseodymium (Pr) and Dysprosium (Dy) to help HDDs read and write data. Trad recycling methods recover only a fraction of these aterials, often missing rare earths entirely, leading to unnecessary waste.
This multi-party pilot showcases what WD says is a highly efficient, economically viable system that achieved a ~90 percent high-yield recovery of elemental and rare earth materials that can be used by the US supply chain. The process also extracts metals like gold (Au), copper (Cu), aluminum (Al) and steel, feeding them back into the American supply chain. The environmentally friendly, acid-free dissolution recycling (ADR) technology used in this project was invented and initially developed at the Critical Materials Innovation (CMI) Hub. A WD blog discusses this topic.
Veeam announced data resilience, cybersecurity, and AI integration updates and initiatives at the VeeamON 2025 conference in San Diego, April 21-23. The company, now the largest data protection vendor by market share, is growing its enterprise, AI, and SaaS capabilities to better compete with Cohesity/Veritas, Commvault, and Rubrik in the enterprise data protection and cyber resilience market.
Anand Eswaran
CEO Anand Eswaran stated: “Data resilience is critical to survival – and most companies are operating in the dark. The new Veeam DRMM (Data Resilience Maturity Model) is more than just a model; it’s a wake-up call that equips leaders with the tools and insights necessary to transform wishful thinking into actionable, radical resilience, enabling them to start protecting their data with the same urgency as they protect their revenue, employees, customers, and brand.”
The main announcements were:
CrowdStrike Falcon Extensions and Integrations: Veeam partnered with CrowdStrike to introduce two new extensions and integrations, combining Veeam’s backup insights with CrowdStrike Falcon’s threat intelligence. This collaboration aims to provide centralized visibility of critical data and advanced threat detection, enhancing cybersecurity for clients.
Ransomware Trends Report: Veeam released the “From Risk to Resilience: Veeam 2025 Ransomware Trends and Proactive Strategies” report, highlighting that 70 percent of organizations remain vulnerable to cyberattacks despite improved defenses. The report noted that only 10 percent of attacked organizations recovered more than 90 percent of their data, emphasizing the need for robust data resilience strategies.
Data Resilience Maturity Model (DRMM): In collaboration with McKinsey, Veeam launched the industry’s first DRMM, addressing the gap where 30 percent of CIOs overestimate their organization’s data resilience, while fewer than 10 percent are adequately prepared. Veeam says this framework helps organizations align people, processes, and technology to minimize risk and enhance resilience.
AI Integration with Anthropic’s MCP: Veeam unveiled new capabilities enabling AI systems to securely access and utilize data stored in Veeam repositories, powered by Anthropic’s Model Context Protocol (MCP). This integration positions Veeam as a bridge between its protected data and enterprise AI tools, aiming to unlock the potential RAG value of backup data for AI-based applications.
Veeam Data Cloud for Microsoft Entra ID: Veeam introduced a new SaaS offering to simplify the protection of Microsoft Entra ID users, groups, and application registrations. This enterprise-ready service offers backup and restore capabilities with unlimited storage and a unified UI for streamlined management. Veeam says Entra ID is facing over 600 million attacks on a daily basis.
Inaugural ESG Report: Coinciding with Earth Day, Veeam released its first Environmental, Social, and Governance (ESG) Report, detailing efforts like preventing 3,402 pounds of e-waste and contributing 2,793 volunteer hours.
Veeam CDP for Windows and Linux: Veeam announced Continuous Data Protection (CDP) for Windows and Linux, enabling data protection every few seconds. This feature enhances data portability and is expected to significantly impact the industry, with a competitive thrust against HPE’s Zerto offering.
Sneak Peek at Veeam v13: Veeam provided a preview of v13 of its software, which features a fully Linux-based backup server and web UI.
Partner Awards and Integrations: Veeam recognized its 2024 Veeam Impact Partner (VIP) Awards winners and announced deeper integrations with partners like Scale Computing, with support for the Scale Computing Platform expected in Q4 2025. Live demos were featured at the event.
Regarding the Anthropic MCP initiative, Veeam CTO Niraj Tolia said: “We’re not just backing up data anymore – we’re opening it up for intelligence. By supporting the Model Context Protocol, customers can now safely connect Veeam-protected data to the AI tools of their choice. Whether it’s internal copilots, vector databases, or LLMs, Veeam ensures data is AI-ready, portable, and protected.”
US startup Diskover is a top-down open source metadata management software company with relatively few but significant customers in Media, EDA, Energy, and Life Science, and appears to have grown by word of mouth instead of by mass developer adoption.
We’ll look at the basic idea behind the company in part one of this examination of Diskover and move on to its AI and other data pipeline activities in a second part.
Diskover is a data management company, somewhat like Arcitecta, Datadobi, Data Dynamics, Komprise, and others. Its market strategy is to provide the best and widest lens possible through which customers can find, monitor and manage their data estate using direct and derived file and object metadata to set up data pipelines. It has a dozen employees and has gathered a roster of some 60-plus customers, doing so with minimal marketing activity.
Will Hall
We were briefed by CEO Will Hall and Chief Product Officer Paul Honrud. The basic details are that Diskover was founded by initial CEO and current CTO Chris Park in 2016 and developed a web application, diskover-web to manage files and provide storage analytic functions. It used Elasticsearch for indexing and crawling supported on-premises and public cloud NFS/SMB accessed file systems. The aim was to provide visibility into a heterogeneous data estate, identifying unused files and reducing storage waste.
Diskover has free community edition software and developed supported paid editions – Professional, Enterprise, Media, Life Science – for enterprises. It has also developed a plug-in architecture to make its SW extensible.
Paul Honrud became the CEO in June 2021 and Chief Product Officer in July 2024 when Will Hall was appointed the CEO. Honrud had previously founded and run unstructured data management startup, DataFrameworks, in 2009. Its ClarityNow SW provided data analytics and management functions for file and cloud storage, offering a holistic view of data across heterogeneous storage systems.
Chris Park
Dell acquired the company in 2018. Honrud stayed at Dell as a field CTO for Unstructured File and Object Management until 2020, joining Diskover the next year. Hall, with sales and exec experience at NetApp, Fusion-io and Scality before DataFrameworks, worked at Dell as a global account manager for unstructured data customers but leaving to be VP Sales at wafer-scale company Cerebras in 2020. He then became an operating partner at Eclipse Ventures in 2023, subsequently rejoining Hornrud by becoming Diskover’s CEO the next year.
Diskover says there is a data management spectrum ranging from basic filesystem fault fixers – something goes wrong – to workflow and pipeline operations, where it locates itself.
Paul Honrud
Honrud says the something-goes-wrong suppliers have “a set of data management functionality and it’s clearly targeted to when something goes wrong like a backup or Cohesity; how do I recover when something goes bad, or ransomware? These are kind of like your Veeam, your Cohesity, your RNAs for that matter. Their value really shines when something went wrong.”
Next up, he says: “You have what I call our space tattle tale tools. And this what the traditional storage vendor thinks about space. How old is it? How big is it? When was the last time it was accessed? Are there duplicates? It’s literally a space tattletale tool and that is really hard to build a business off of.”
Space tattle tale tools can be really important: “When the storage is full and they need to go on a crash diet, I immediately need to clean up some stuff, go on a crash diet so I can continue working. Or they buy new storage, they just kicked the can down the road. But you literally in between those time periods can turn the software off and nobody complains. It is very hard. It’s very hard to build a business model.”
The data mobility suppliers are one step on: “If you don’t want to actually change your lifestyle and lead a healthier lifestyle and want to keep going on this crash diet thing, then here you go. We’ll help you identify where to cut the fat quickly. You have a whole bunch of technologies around data mobility. These are data movers, right? … and there’s like 30 of them.”
“This is a crowded market and there’s more every day. There’s another one called MASV. These are all your companies that are in data movement. And what they realized with data movement is that it’s hard to build a recurring business. If your data movement is really data migration; they’ve sold a big new Isilon piece of storage and they need to get the data off of old Isilon and onto new Isilon. That is kind of a one-and-done data movement use case.”
Honrud says they moved in a tad: “What they started to realize is that’s not the heart of the problem. The heart of the problem is what data needs to be where, when, to support a workflow. So they started to build analytics, but the analytics are biased because they have a horse in the race. They’re trying to build analytics that drive data movement, that drive demand to their technology. So look, if you move it over here, it’s cheaper. Oh, look how old this stuff is. They’re really not understanding the data. They’re just trying to provide analytics to move data.”
Now we come to the workflow/pipeline area: “Then you have data management where it comes to workflow and pipeline. This is what data do I have? Why do I have it and how do I run my business more efficiently?”
He says that many organizations are: “generally trying to produce some widget, a movie, a new chip design. They’re trying to cure cancer. And so how do I take the data associated with that and produce more movies shorter, shorten the cycle for chip design? How do I actually manage data to help me run my business better? It’s super hot right now because everybody’s realising if you don’t understand your data and what is good data and bad data, you have no way to feed your AI models.”
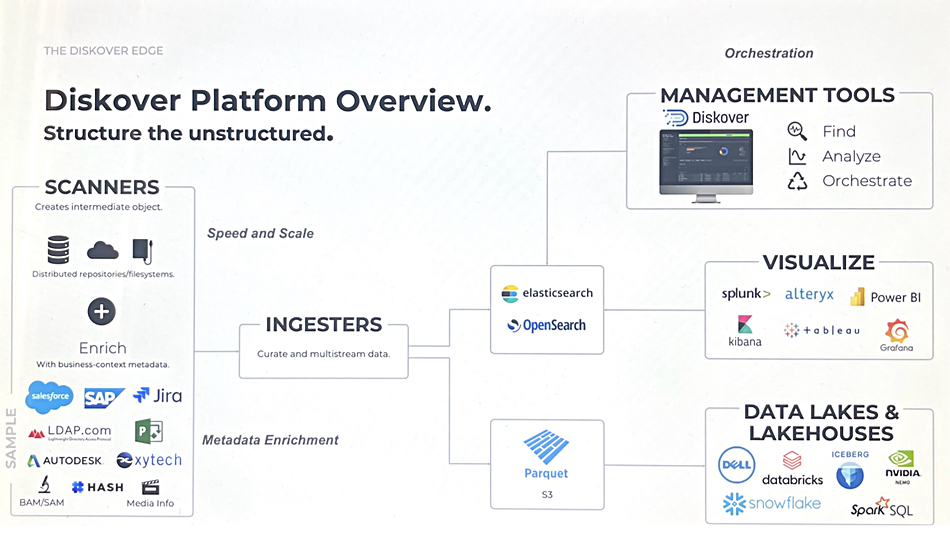
Diskover’s software scans and indexes data, builds a metadata catalog, and uses that to support searches, analysis, actions and automation:
Its software consists of scanners and ingesters to populate the catalog, elasticsearch to support management tools for finding data amongst files and objects, analyzing the data, orchestrating it and visualizing it. The software supports Parquet for feeding data to data lakes and lakehouses:
It’s built to operate in a scale-out environment assuming a distributed index of storage repositories, and with a scale-out index. Honrud says its continuous, cached and parallel scanning can connect to any file system and handles massive amounts of data:
The scanning technology uses both direct, system-produced file and object metadata, and deduced indirect metadata. Honrud talks about reverse engineering access fingerprints left on data.
He said: ”If I came over and looked in your garage or I came over and looked on your laptop, I could tell whether you like tennis or bicycling or stamp collecting. I could tell a lot about you by the fingerprint there.”
“That’s the first thing. Second thing is most storage vendors, and most people in data management try to manage data at the end of the food chain. When it’s time to archive it. Oh, it’s over three years old. Let’s move it. The whole thought processes around there, it is way too late.
“You’ve missed way too many opportunities to capture metadata, but the content is most valuable when it’s originally created, when it’s coming off of a camera or a microscope or a genome sequencer. So let’s move our thought process for data management and metadata to when data originally lands on the storage and then let’s follow that data through its lifecycle. Okay.
“So when a new piece of storage is provisioned out, it usually gets provisioned by somebody creating a service ticket in Jira or ServiceNow. That ticket goes to the IT department, they create an NFS share, an SMB share, and an S3 bucket. And then they close the ticket and the business community is now allowed to start putting data on storage. First time they missed an opportunity to capture metadata, right? Because in that Jira ticket is usually the project name, project owner, project start date, and probably estimated project end date. But if you just create the share and leave, you just dropped a bunch of metadata on the floor.”
Diskover picks up that discarded potential metadata and uses it. There’s more to say about this though.
Honrud adds: “The next way to capture metadata, yes, is if the owner and group are actually accurate on the file system. In other words, I may be the project owner, but you were the guy that loaded the data on the file system. So you show as the owner, but I’m the guy that’s actually running the whole project. So first thing that you miss there is you’re talking to the wrong guy. Like, Hey Chris, what should we do with this data? Well, you’re not the guy using it. You’re the guy that loaded it. So you need to know project owner, project primary investigator in a research environment. That information you can find if the user logs in via AD or LDAP. You could do a reverse lookup in Active Directory or LDAP. There’s a lot of metadata there. I could usually tell who you report to, what division you are in.”
Diskover scans and indexes the data and ingests the index metadata into Elasticsearch. It can then feed it upstream to visualizers, data warehouses and lakehouses and so forth.
In part two of this look at Diskover we’ll examine its upstream pipeline supporting capabilities.
Lenovo has released 21 storage products, including a liquid-cooled HCI system, in a major storage portfolio refresh aimed at customers building AI-focused infrastructure.
Scott Tease
Scott Tease, Lenovo’s Infrastructure Solutions Product Group VP and GM, talked of helping “businesses harness AI’s transformative power,” stating: “The new [systems] help customers achieve faster time to value no matter where they are on their IT modernization journey with turnkey AI solutions that mitigate risk and simplify deployment.”
Marco Pozzoni, Director, EMEA Storage Sales at Lenovo’s Infrastructure Solutions Group, stated: “Our largest-ever data storage portfolio refresh delivers the performance, efficiency, and data resiliency required by Data Modernization and Enterprise AI workloads.”
Lenovo says “businesses are moving to a disaggregated infrastructure model, turning compute, storage, and networking into on-demand, shared resources that can adapt to changing needs to boost scalability, efficiency, and flexibility.” New AI Starter Kits for Lenovo Hybrid AI Platform are pre-configured and validated infrastructure systems comprising compute, storage, GPUs and networking. The storage elements are new ThinkSystem Series Storage Arrays, OEMed from NetApp, delivering unified file, block, and object storage using “high-performance SSD flash technology.”
The ThinkSystem DG and DM arrays feature include new AI-powered autonomous ransomware protection – ONTAP ARP/AI – plus encryption for greater data protection and synchronous replication with transparent failover.
Marco Pozzoni.
There are five areas of Lenovo storage product portfolio change:
ThinkAgile SDI V4 Series provides full-stack, turnkey solutions that simplify IT infrastructure and accelerate computing for data-driven reasoning.
New ThinkSystem Storage Arrays deliver up to 3x faster performance while reducing power consumption – comparing the DE4800F to the DE4000 – and providing up to 97 percent energy savings and 99 percent density improvement for the DG7200 over a Lenovo device featuring 10K HDDs for smaller data center footprints and lower TCO and when upgrading legacy infrastructure.
New converged ThinkAgile and ThinkSystem hybrid cloud and virtualization systems deliver flexible and efficient independent scaling of compute and storage capabilities, reducing software licensing costs for additional storage, but not core-based licenses, up to 40 percent. A ThinkAgile Converged Solution for VMware brings together the enterprise-class features of ThinkAgile VX Series – lifecycle management and operational simplicity – , with the ThinkSystem DG Series storage arrays data-management to provide a unified [private] cloud platform supporting hybrid storage workloads.
New ThinkAgile HX Series GPT-in-a-Box solutions featuring Lenovo Neptune Liquid Cooling leverage the industry’s first liquid cooled HCI appliance to deliver turnkey AI inferencing, from edge to cloud, yielding up to 25 percent energy savings for the HX V4 over the HX V3 generation.
New AI Starter Kits for Lenovo Hybrid AI Platform deliver a validated, flexible, and easy on-ramp for enterprise inferencing and retrieval-augmented (RAG) workflows.
Lenovo partnered Nutanix in 2023 in order to sell GPT-in-a-Box-based ThinkAgile HX Series systems. There are no details available about the liquid-cooled system, with Lenovo saying it is a “full-stack generative AI solution [and] jumpstarts AI integration using a repeatable solution that lowers energy costs for faster data-powered AI reasoning.” It has “up to 2.6x higher transaction rate and up to 1.4x faster input/output operations per second (IOPs) compared to traditional cooling methodS,” specifically comparing ThinkAgile SDI V4 Series to 3 racks of Dell VxRail Cascade Lake models. It also has a more compact form factor with increases of up to 1.4x in Container/VM density over its ThinkAgile SDI V3 Series predecessor
The disk drive manufacturers more or less stopped selling 10,000rpm disk drives in the 2018-2019 era when capacities were limited at up to 2.4TB or so. Lenovo and its competitors continue to ship 10k drives up to 2.4TB. The DG7200 is an-QLC flash system supporting up to 120 SSDs in an HA pair; implying 61.66TB drives. The comparison with the older Lenovo array using 10,000rpm 2.4TB disk drives does not seem that appropriate.
Lenovo says that its “ThinkAgile SDI V4 Series and new ThinkSystem Storage Arrays deliver full-stack, turnkey AI-ready infrastructure for enterprises beginning AI implementations while delivering faster inferencing performance for LLM workloads.” The primary AI use cases include AI inferencing, RAG, and fine-tuning AI models, while “the offerings are purpose-built for a broad range of enterprise AI and data modernization workloads, from databases, ERP and CRM, to virtualization, hybrid cloud, backup and archive.” AI model training is not a primary AI use case.
Lenovo is in the process of buying Infinidat and that will give it an entry into the high-performance enterprise block storage array market. It will also provide it with its own storage IP and a different, enterprise-focussed, go-to-market sales channel.
You can dig around in Lenovo’s storage web pages here to find out more about today’s storage news.
WEKA has appointed new chief revenue, product, and strategy officers.
The company supplies high-performance, parallel access file system software for enterprise and HPC, with AI and agentic AI workloads now a major focus. It lost senior execs in December 2024, when president Jonathan Martin, CFO Intekhab Nazeer, and CRO Jeffrey Gianetti left. Hoang Vuong became the new CFO that same month. WEKA then laid off some employees – sources estimated around 50 – as it said it was restructuring for the AI era, having 75 open positions at the time.
Now WEKA has hired Brian Froehling as chief revenue officer, Ajay Singh as chief product officer, and reassigned Nilesh Patel, prior CPO, to chief strategy officer and GM of Alliances and Corporate Development.
Brian Froehling
CEO and co-founder Liran Zvibel stated: “WEKA is operating at the forefront of the AI revolution … Ajay, Brian, and Nilesh each bring deep domain expertise and seasoned leadership experience that will be instrumental in accelerating our global sales execution, scaling go-to-market strategies with our strategic partners, and advancing product development to provide the foundational infrastructure needed to power the agentic AI era into WEKA’s next growth phase – and beyond.”
Froehling was most recently CRO at cloud-native logging and security analytics company Devo Technology, responsible for sales, customer success, training, and operations. Before that, he served as EVP of global sales at video cloud services supplier Brightcove, driving $220 million in revenue. He also held senior sales leadership roles at CA Technologies and Pivotal Software, where he helped scale go-to-market teams and played a role in Pivotal’s IPO.
Froehling said: “This is a once-in-a-generation opportunity to empower AI-driven organizations with market-leading solutions.”
Ajay Singh
Singh comes from being Snorkel AI’s CPO. Snorkel’s product tech focuses on accelerating the development of AI and ML apps by automating and streamlining data labeling and curation to build AI training datasets faster. He was also CEO and co-founder of Zebrium, which developed software using ML and generative AI to analyze software logs for the root cause of outages. Zebrium was acquired by ScienceLogic in April 2024. Before that, he was Head of Product at Nimble Storage, leading from concept through its IPO and eventual acquisition by HPE, and a product management director at NetApp.
Singh said: “WEKA has been trailblazing in AI data infrastructure innovation with the ultra-powerful WEKA Data Platform, which dramatically speeds model training and inference by orders of magnitude.”
Nilesh Patel
Patel’s lateral move indicates that alliances and partnerships are going to play an important role at WEKA. He said: “We’re at a pivotal moment in the evolution of AI, and WEKA is powering many of the world’s largest AI deployments to supercharge innovation. This is an incredible opportunity to shape WEKA’s path forward and work closely with key partners that will help us scale AI solutions and fuel sustained hypergrowth.”
Possible partnership and alliance opportunities exist in the AI large language model, retrieval-augmented generation, vector database, and AI data pipeline areas.
Several other storage suppliers are intensely focused on storing and supplying data for AI training and inference workloads, including DDN, Pure Storage, VAST Data, and NetApp, which is developing an AI-focused ONTAP variant. Dell, which has a strong AI focus for its servers, has said it is parallelizing PowerScale. WEKA has to show that its customers can develop and run AI applications faster and better by using WEKA’s software over alternatives.
Another recent WEKA exec-level change was Sean Hiss, VP of GTM Operations and chief of staff to the CEO, who resigned in February, having joined WEKA in October 2021 from Hitachi Vantara.
Scality has combined its ARTESCA object storage with Veeam’s Backup & Replication in a single software appliance running on commodity x86 servers.
Having a single server with co-located, integrated Scality and Veeam software eliminates the need for separate (physical or virtual) infrastructure for Veeam, reducing deployment complexity, time, and cost by up to 30 percent, the vendor claims. The server hardware can come from suppliers such as Dell, HPE, Lenovo, and Supermicro.
Andreas Neufert
Veeam’s Andreas Neufert, VP of Product Management, Alliances, stated: “This innovative solution simplifies the deployment of our industry-leading data resilience software alongside Scality’s robust object storage, making it easier for organizations to enhance their cyber resilience. Scality has integrated Veeam into this new solution, combining our strengths to empower our joint customers to create secure defenses against cyber threats while optimizing their backup operations.”
The competition to provide object storage-based Veeam backup targets is intensifying. Cloudian, Scality, and MinIO object storage can be targets for Veeam backups, as can the Ootbi hardware/software appliance from Object First.
Scality reckons its single box Veeam-ARTESCA software appliance offers better cyber resilience than an Ootbi-type alternative because ARTESCA + Veeam bring backup and storage together in a single, secure, unified environment that reduces malware exposure.
The ARTESCA OS is a dedicated, security-optimized Linux distribution developed and maintained by Scality with only the minimum required packages, and no root or superuser privileges. Veeam runs inside this hardened environment, reducing the total attack surface compared to traditional Veeam-on-ESXi deployments.
There is internal-only communication between Veeam and the ARTESCA storage components, ensuring there are no exposed S3 endpoints that can be accessed externally, no need for external DNS resolution, and no IAM access keys or secret keys shared outside the appliance. Another point is that running backup and storage on a single server reduces hardware requirements and integration effort, while providing unified, single-pane-of-glass monitoring and management, minimizing the need to switch between separate interfaces.
Erwan Girard
Erwan Girard, Scality chief product officer, said: “The unified software appliance marks a major milestone in our partnership with Veeam. By combining ARTESCA’s security and simplicity with Veeam’s industry-leading data resilience solutions we’re enabling organizations to build unbreakable defenses against cyber threats while optimizing backup operations without compromising performance.”
The Scality ARTESCA + Veeam unified software appliance will initially be available as a single node, configurable from 20 VMs/TBs to hundreds of VMs/TBs. It will need to go multi-node to provide more backup storage capability.
Note that object storage does not natively deduplicate stored data, with backup data deduplication being carried out by the backup software. Non-object-based backup target systems from Dell (PowerProtect), ExaGrid, HPE (StoreEver), and Quantum (DXi) provide their own deduplication capabilities.
Customers will be able to purchase the combined Scality-Veeam offering from their channel partners. Scality will provide the partners with documentation and tooling to install the software appliance on one of a number of pre-validated hardware configurations.
If you’re interested in accessing the new ARTESCA + Veeam unified software appliance, you can submit a request here. The appliance can be viewed at the VeeamON 2025 conference in San Diego, which runs today and tomorrow.
Partner Content In any VDI deployment, storage is crucial for success and user experience. It ensures performance and responsiveness while supporting scalability and reliability. Storage bottlenecks can undermine the best VDI strategies, especially during peak times like boot storms and login surges. Consequently, storage choices are central to VDI design discussions, with organizations typically selecting between a traditional virtual SAN (vSAN) or an external all-flash array (AFA).
While a vSAN may appear to be the more cost-effective option — especially in VDI environments where per-desktop economics are critical — many organizations are forced to abandon it. Traditional vSAN implementations often fall short in real-world VDI scenarios, struggling with high I/O demands during boot storms, and they lack the flexibility required to deliver their promised price advantage. vSAN’s layered architecture introduces latency, reduces responsiveness, and lacks the efficiency for consistent user experiences. As a result, IT teams often resort to dedicated all-flash arrays to overcome these limitations despite the added cost and infrastructure complexity. Though this approach addresses the performance gap, it creates new challenges in management, scalability, and long-term cost control.
The cost problem with external all-flash arrays
Traditional external all-flash arrays, though powerful, are typically costly and often become a significant portion of the overall VDI budget. Beyond the initial purchase, this expense also encompasses ongoing support contracts, expansion shelves, and frequent hardware upgrades to maintain performance.
For VDI deployments, where storage performance can make or break the user experience, IT often finds itself buying expensive storage equipment designed to handle infrequent peak loads. Consequently, organizations overspend on storage resources.
Complexity and separate infrastructure management
External all-flash arrays demand their own management expertise, separate from the rest of the VDI environment. Storage admins must manage the arrays, monitor performance, troubleshoot bottlenecks, and tune storage configurations independently from the virtualization and application layers. This creates operational silos and complicates VDI management.
Every change to the external array—whether an upgrade, firmware update, or configuration adjustment—requires coordination across storage, virtualization, and networking teams. The result is longer downtime, an increased risk of misconfigurations, and more frequent user disruptions.
Lack of VM and application awareness
A critical shortcoming of external arrays in VDI environments is their lack of direct integration and visibility into the virtual machines they support. Without VM-level awareness, these storage systems cannot automatically optimize storage resources based on real-time application and desktop needs. Instead, IT administrators must manually tune performance, which is complex, time-consuming, and reactive rather than proactive.
For example, external arrays do not automatically understand how to distribute resources best to prevent bottlenecks during boot storms or login events. Administrators must continuously monitor and adjust storage policies manually, resulting in inefficiencies and a higher potential for performance degradation.
Vendor lock-in risks
Investing heavily in external all-flash storage arrays often leads to vendor lock-in. Each vendor uses proprietary technologies and unique management interfaces. Consequently, IT teams become heavily dependent on a single vendor, limiting flexibility and reducing negotiating power for future expansions or upgrades.
As storage requirements grow or evolve, organizations face substantial hardware refresh costs or forced upgrades to maintain compatibility and performance. This situation limits an organization’s ability to adapt quickly to new requirements or take advantage of more cost-effective storage technologies as they become available.
Next-generation vSAN: A better alternative
A next-generation vSAN eliminates many drawbacks of external all-flash arrays. A modern vSAN architecture:
• Delivers High Performance: A next-generation vSAN integrates storage services directly into the hypervisor, eliminating unnecessary software layers and reducing I/O latency. This streamlined architecture increases efficiency, eliminates boot storm concerns, and delivers performance that rivals—and sometimes exceeds—external all-flash arrays.
• Reduces Costs: By using internal storage and supporting a wide range of industry-standard flash drives across multiple vendors, a next-generation vSAN enables organizations to avoid expensive, proprietary hardware. This flexibility allows IT teams to deploy high-performance storage at a fraction of the cost, often reducing capital and operational expenses by up to 10x.
• Simplifies Management: Integrated storage eliminates the need for separate infrastructure and specialized storage skills. Administrators manage the system from within the virtualization console, streamlining operations and allowing them to seamlessly manage VDI storage alongside their other virtualization tasks.
• Provides VM-level Awareness: Because a next-generation vSAN operates at the hypervisor layer, it inherently understands VM workloads. This awareness enables automatic resource allocation, proactive performance optimization, and rapid response to changing demands, improving the user experience during boot storms or peak usage periods.
• Avoids Vendor Lock-in: Using commodity hardware and integrated storage software, organizations gain flexibility in their hardware purchasing decisions. They can select best-of-breed components based on cost, performance, and support without being locked into a single vendor's proprietary ecosystem.
• Enhances Scalability: Expanding storage is as simple as adding additional standard servers with internal drives, allowing organizations to scale incrementally and cost-effectively without the significant capital investments required by external arrays.
Conclusion
While external all-flash arrays can deliver performance for VDI, they come with high costs, increased complexity, vendor lock-in risks, and a lack of VM-level optimization. A next-generation vSAN solution integrated into the virtualization layer addresses these issues head-on, providing a simplified, cost-effective, scalable, and VM-aware storage solution ideal for modern VDI deployments.
VergeOS is one example of a next-generation vSAN approach. It integrates storage directly into the hypervisor, delivers VM-level performance insights, and scales using standard hardware without needing separate storage infrastructure. Organizations looking to maximize their VDI investment should strongly consider a next-generation vSAN strategy like VergeOS to reduce cost and complexity while improving performance and resiliency.
If you are looking for an alternative to VMware or Citrix, watch VergeIO’s on-demand webinar: Exploring VDI Alternatives.
Hitachi Vantara is joining Dell, IBM, and Infinidat in using Index Engines’ AI-powered ransomware detection software.
The CyberSense product from Index Engines uses AI and machine learning analysis to compare unstructured data content as it changes over time to detect suspicious behavior and cyber corruption. Index Engines claims a 99.99 percentccuracy rating and flags anomalies and indicators of corruption. The full-content analytics approach is said to be better able to detect malware-caused corruption than just checking metadata. Hitachi Vantara is integrating CyberSense with its Virtual Storage Platform One (VSP One) products.
Octavian Tanase
Hitachi Vantara chief product officer Octavian Tanase stated: “IT complexity, cyber threats, and sustainability challenges continue to put enterprises under extreme pressure. With VSP One’s latest enhancements, we are eliminating those roadblocks by delivering a unified, automation-friendly platform with guaranteed performance, resilience, and efficiency built in. This is more than just data storage – it’s a smarter, more sustainable way to manage enterprise data at scale.”
The company said it is adding three guarantees:
Performance Guarantee: Applications run at predictable, high-performance levels with minimal intervention by meeting workload demands with confidence through guaranteed minimum performance levels across all VSP One Block platforms, backed by EverFlex from Hitachi. Service credits apply if performance targets aren’t met.
Cyber Resilience Guarantee: Organizations can mitigate downtime and data loss after cyberattacks with protections enabled by immutable snapshots and AI-driven Ransomware Detection powered by CyberSense. If data can’t be restored, Hitachi Vantara provides expert incident response and up to 100 percent credit of the impacted storage volume.
Sustainability Guarantee: Helps businesses track and optimize energy consumption and contributes to a lower CO₂ footprint by up to 40 percent with VSP One’s energy-efficient architecture and reporting. A power efficiency service level agreement (SLA) ensures improved cost efficiency and environmental responsibility.
These join three existing Hitachi Vantara guarantees. A 100 percent data availability guarantee provides uninterrupted access to critical business data. The Hitachi Vantara Effective Capacity Guarantee provides 4:1 data reduction and maximizes storage efficiency. The Modern Storage Assurance Guarantee delivers continuous innovation with perpetual, non-disruptive upgrades to new controllers, ensuring a path to the future of storage without needing to repurchase capacity.
Index Engines says Hitachi VSP Ransomware Detection, powered by CyberSense, detects corruption early, isolates threats, and guides IT to the last known clean backup so recovery is fast, precise, and trusted.
Index Engines says CyberSense supports NIST CSF (Cyber-Security Framework) functions by embedding data integrity analytics and recovery assurance into the storage product layer:
Identify: CyberSense indexes and analyzes metadata and content at scale, helping organizations understand what data they have and identify potential risks related to data corruption or tampering.
Protect: While Hitachi provides immutable storage and encryption, CyberSense adds another layer by continuously validating the integrity of backup data, protecting against undetected ransomware dwell time.
Respond: With audit trails and forensic-level reporting, CyberSense enables quick investigation and targeted recovery, reducing the time to respond to a data breach.
Recover: CyberSense identifies the last known clean copy of data and enables precise, surgical recovery, supporting fast, verified restoration in line with NIST’s Recover function.
Jim McGann
Jim McGann, VP of strategic partnerships at Index Engines, said: “The addition of VSP One’s Cyber Resilience Guarantee, including Ransomware Detection powered by CyberSense, equips organizations with the intelligence and automation needed to strengthen their cyber resilience. By integrating advanced tools like VSP One and CyberSense, IT teams can streamline recovery workflows, minimize downtime and validate the integrity of critical data with greater confidence to minimize the impact of an attack.”
Hitachi Vantara gets up to the minute ransomware detection technology while Index Engines notches up a fourth OEM for its software. McGann will now be turning his attention to uncommitted potential OEMs, such as DDN and Pure Storage, but not NetApp, which has its own ransomware detection tech, or HPE, which offers Zerto ransomware detection.