Cloud content collaborator Egnyte is now majority-owned by a pair of private equity companies.
GI Partners (GI) and TA Associates (TA) have bought a majority investment to “infuse Egnyte with the capital and expertise needed to expand its global market presence and accelerate innovation through continued investment in research and development.”
Egnyte was founded by CEO Vineet Jain, CTO Amrit Jassal, CSO Kris Lahiri, and Chief Growth Officer Rajesh Ram in 2007. It has raised $137.5 million thus far across a seed round and four VC rounds, the last for $75 million in 2018. Since then, it has been relying on revenue for continuing operations and growing its business. It had amassed more than 17,000 customers in mid-2023 including Red Bull, Yamaha, and Balfour Beatty. The total customer count is now 22,000.
Vineet Jain
Jain stated: “This is a significant milestone in Egnyte’s journey and opens exciting new avenues for Egnyters, our customers, and channel partners. The investment and expertise that GI and TA bring will help us accelerate our ability to bring innovative new products and solutions to our existing and future customers as well as deliver accelerated growth and expansion into additional vertical industries and international markets.”
Egnyte was one of several cloud-based file sync and share collaboration startups, along with CTERA, Panzura, and Nasuni.
Cloud file services suppliers operate in an area that overlaps with distributed on-premises file storage. Typically, they’ll use core public cloud object storage and layer file access on top of that, also ensuring that distributed users across an enterprise see files in a synchronized state. They’ll provide fast file access by using local caches. Some, such as Nasuni, want to replace on-premises filers but that general movement has not happened.
Lately, data orchestrators such as Arcitecta and Hammerspace have appeared on the distributed file access scene, adding to the competitive pressures on the original four cloud file sync and sharers.
All four have taken in private equity dollars. None of them felt able to tap VCs for more cash, yet their businesses were solid enough to attract private equity investors.
Panzura went into private equity ownership when it was bought by Profile Capital Management in 2020. Since then, it has been rejuvenated and is growing its business, with a new CEO appointed in January 2024. Panzura acquired Moonwalk Universal for its hybrid cloud unstructured data estate scanning, migration, and tiering technology in July last year.
Nasuni also went into private equity ownership that month with a majority investment led by Vista Equity, in partnership with KKR and TCV, valuing the company at $1.2 billion. It looks like the three spread the risk.
CTERA took in $80 million in primary and secondary funding from PSG Equity, also in July 2024. The cash is set to be used for taking advantage of AI opportunities and growing CTERA by acquiring other businesses.
Now Egnyte has opened the door to private equity as well. TA says it’s focused on scaling growth in profitable companies. GI is an Egnyte customer.
Following GI and TA’s investment, we’re told Egnyte’s founders, management team, and existing investors – including funds and accounts managed by Springcoast, GV, Polaris, and Kleiner Perkins – will retain significant ownership in Egnyte. Financial terms of the transaction were not disclosed. Qatalyst Partners served as financial advisor.
Western Digital and Sandisk started trading their stocks as separate businesses on February 24, with Western Digital shares losing 2.9 percent and Sandisk’s 7 percent of their value, which, in stock market value terms, justifies their separation.
The day before they started trading separately, Western Digital shares were priced at $51.90 with a market capitalization of $17.94 billion based on 345.71 million outstanding shares. The next day, they opened at $52.61 and finished at $49.02, with a $16.95 billion market capitalization. SanDisk started its separate trading on February 24 at $52.20, finishing the day at $48.60. Given its 115.24 million shares and 0.33333 share ratio against Western Digital’s shares, this results in a market cap of $5.6 billion.
Thus, the day before the split, Western Digital – including its Sandisk operation – was valued at $17.94 billion. The day after the split, Western Digital was valued at $16.95 billion and Sandisk at $5.6 billion, a combined total of $22.55 billion. This gives justification to activist investor Elliott Management, which pushed for separation.
Back in May 2022, Elliott revealed that it had a stake in Western Digital and published a letter calling for Sandisk to be spun out as the overall shareholder value of Western Digital and Sandisk could be much greater if its HDD and SSD businesses were separated. Nearly three years later, the split has taken place, and Elliott Management’s view has been vindicated.
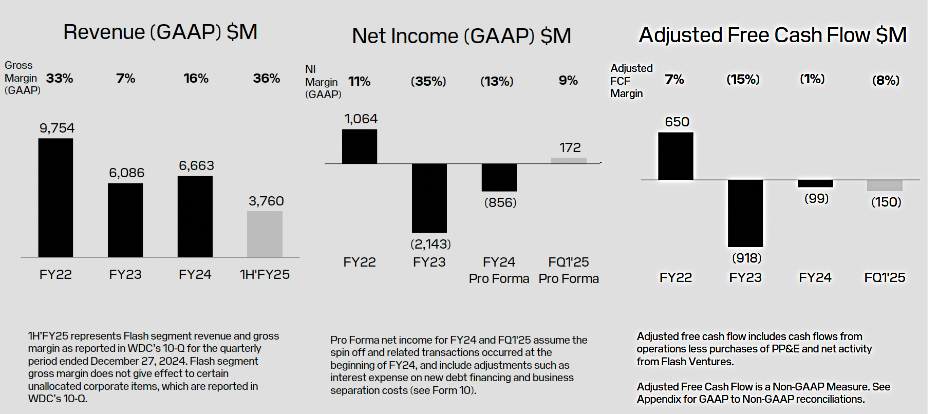
Sandisk published some financial history at a February 12 investor day, providing revenue, GAAP net income, and free cash flow numbers:
They show a decline in revenue from FY 2022’s $9.75 billion to FY 2024’s $6.66 billion, along with losses and negative free cash flow in FY 2023 and FY 2024. CEO David Goeckeler said Sandisk should generate positive free cash flow at a $10 billion/year revenue level. It may generate revenue of $7.5 billion in FY 2025 and reach $10 billion in three years at a 10 percent annual growth rate.
Sandisk’s joint venture partner, Kioxia, projects full-year 2024-2025 revenue of $11.3 billion, considerably more than Sandisk is likely to earn. If each company receives half of the NAND chip output from their joint-venture fabs, then Kioxia is doing a better job of monetizing NAND chips. Will Elliott Management now sell its Sandisk shares? Or will it examine the apparent disparity between Kioxia and Sandisk’s earnings from their shared JV and consider how to capitalize on it?
Broadcom has tested an end-to-end PCIe Gen 6 setup with a Micron SSD and Teledyne LeCroy protocol analyzing equipment.
The multi-lane PCIe (Peripheral Component Interconnect Express) bus is used to interconnect high-speed peripheral devices to a host server’s motherboard with its memory and processor. PCIe Gen 6 (64 Gbps) is twice as fast as PCIe Gen 5 (32 Gbps) and four times faster than PCIe Gen 4 (16 Gbps). The Computer Express Link (CXL) v3.0 scheme to interconnect high-speed devices with pooled memory and multi-level switching relies on PCIe Gen 6. Broadcom is focusing on direct SSD-to-AI host system speed, rather than CXL, with its PCIe Gen 6 product and testing initiatives.
Spokesperson Jas Tremblay, VP and GM of its Data Center Solutions Group, said: “The transition from PCIe Gen 5 to Gen 6 has been monumental given the accelerated need for trusted and reliable building blocks in next-gen AI systems.”
Broadcom is developing a PEX 90144 PCIe Gen 6 switch and two retimers: the BCM85668 8-lane and BCM85667 16-lane products. Retimers are PCIe bus relay stations, receiving a signal, cleaning it up, fixing any degradation, and sending it onward. They enable the bus to operate over longer distances than otherwise. It “retimes” the signal’s data by aligning it with a fresh clock pulse and removing jitter (timing noise) and distortion.
The company has not disclosed the number of ports in the PEX90144 switch. Broadcom’s PEX naming conventions typically designate the switch port count using the last two or three digits in the product name. The PEX89072 (PCIe Gen 5) offers up to 72 configurable ports and the earlier PEX88096 (PCIe Gen4) has up to 98 ports. This suggests the PEX90144 will have up to 144 ports.
Micron and Teledyne LeCroy are Broadcom’s PCIe Gen 6 ecosystem partners. Joe Mendolia, VP of Marketing, Protocol Solutions Group at Teledyne LeCroy, said: “Our early collaboration with Broadcom, leveraging our Summit M616 and M64 Protocol Analyzers and Exercisers and Broadcom’s PCIe switch portfolio, has led to the industry’s first PCIe 6.x interoperability and compliance testing development.”
Micron’s storage business SVP and GM, Jeremy Werner, played the AI card, saying: “Combined with Broadcom’s high-port switch, our SSDs serve as a critical building block for PCIe Gen 6 AI storage. Our successful interoperability testing with Broadcom and Teledyne LeCroy is evidence of the industry’s rapid transition toward a robust end-to-end PCIe Gen 6 portfolio capable of taking AI performance to the next level.”
Broadcom also says it has a PCIe Gen 6 Interop Development Platform (IDP) with telemetry and diagnostics capabilities. It is offering its PCIe Gen 6 portfolio – IDP + switch + retimers – to early access customers.
Astera Labs announced its Scorpio PCIe Gen 6 switch in October last year. Its PF60641L product has 64 lanes.
SPONSORED FEATURE: Considering it has such a large share of the data protection market, Veeam doesn’t talk much about backups in meetings with enterprise customers these days.
Instead, the company focuses on two other terms: data resilience, and data portability. This is a response to new threats that are emerging for enterprise customers – including some from vendors themselves.
You’d be forgiven for thinking that data resilience was just another term for what we used to call business continuity. However, it goes further than that, explains Brad Linch, director of technical strategy at Veeam. It’s a response to a shift in the data protection landscape over the last few years.
“Business continuity plans were designed for fires and power outages and natural disasters. But in this next evolution of the data protection industry focused on data resilience, you’re dealing with a subcategory of disaster, which is cyberattacks,” he says. “Dealing with cyber recoveries is a whole different ball of wax. It’s much more common than a natural disaster. For one thing, it’s going to happen more often than an accidental fire, or a power outage, or even a hurricane.”
Disasters of this type carry different challenges. For example, when hit by ransomware, which often focuses on encrypting backups, it’s more difficult to identify your last clean backup copy. That makes it inadvisable to automatically restore a backup directly to production without doing some further analysis. The whole backup and restoration process changes.
From VMware……to everywhere
Natural disasters and cyberattacks aren’t the only modern threats to data resilience. Another threat is commercial. Many enterprises’ natural data habitat has become VMware, which was Veeam’s original focal point for backup solutions. They happily processed their data in VMware virtual machines, but now, commercial changes from VMware’s new owner are threatening that situation.
Broadcom’s licensing changes eliminated stand-alone support services for perpetual license holders and shifted them to per-core subscription-based support packages. In October, the company backtracked, reintroducing its vSphere Enterprise Bundle so that enterprise customers could use the software without upgrading to the full VMware Cloud Foundation suite.
Experts fret that Broadcom’s capitulation wasn’t enough. In November Gartner VP analyst Michael Warrilow said that VMware enterprise customers were “all miserable” because of the Broadcom changes, adding that licensing costs have risen by 200-500 percent on average. A migration away from the platform hasn’t happened yet, he said – but it’s likely coming, given that IT procurement often moves in multi-year cycles.
This tense situation highlights the need for something that Veeam has been investing in heavily for years; broad cross-platform support that goes well beyond VMware. Enterprise customers need a data resilience solution that can protect them across all of the platforms they use, enabling them to make technical and commercial decisions that easily support their business decisions. That includes expanding out from – or away from – VMware, or any hypervisor or cloud platform, should they need to.
This concept of cross-platform support for backups underpins a central tenet of Veeam’s: ‘data portability’. The company is an advocate for platform-agnostic backup, enabling people to store or recover copies of their data wherever they wish. It has built data portability into its products to satisfy long-term strategic reasons such as a Broadcom-driven migration along with shorter-term technical ones such as system outages.
“It’s about making sure you can run your data not so much where you want, but sometimes where you need to,” explains Matt Crape, senior technical product marketer at Veeam. “Say you get ransomware, and you lose access to all your hardware as the insurance company investigates. If you do it right, you can restore to the cloud and get things back up and running very quickly.”
To do this, Veeam embarked on a multi-year effort to provide extensive cross-platform options. This began in 2011, when it rolled out support for Microsoft’s Hyper-V. In 2016, it launched a direct restore to Azure service.
Since then, it has gone much further. Today, it supports Nutanix’s AHV open-source enterprise hypervisor platform, along with both Red Hat Virtualization (which Red Hat will sunset in 2026) and the newer Red Hat OpenShift Virtualization. It has also delivered support for Oracle Linux Virtualization Manager, and for the Proxmox Virtual Environment (VE) virtualization management platform. On the cloud side, it now supports AWS and Google Cloud alongside Azure.
Support for these platforms enables it to offer an instant cross-platform virtual machine recovery feature that mounts your best available backup to whichever target – or targets – that you choose – including Kubernetes container environments.
Building deep data resilience
Veeam has a dual-pronged strategy to support its data resilience mission. Alongside its focus on breadth of platform support, it has also spent the last few years building out a deep set of features to protect enterprise customer data and assist with migration.
The company provides support for both single, multi-cloud, and hybrid environments (including its own Veeam Data Cloud Vault storage service). Scalability is a critical factor here, as the larger and more complex your data backup infrastructure becomes the more complex it is to manage.
The company’s Scale-out Backup Repository feature provides a layer of abstraction across an enterprise customer’s entire data landscape, virtualizing it into a single pool for ease of management. This, combined with support for backup policies, enables administrators to keep sprawling data collections in line.
Alongside support for multiple cloud and virtualization platforms, Veeam has built out a variety of tool integrations. These are especially strong in the cybersecurity and incident response realm that forms such a big part of the data resilience proposition. Alongside SIEM integrations with the likes of Splunk and Sophos, it also offers SIEM and SOAR integrations with Palo Alto. Its SOAR partnerships extend to other companies including ServiceNow and Cisco, with more reportedly on the way.
Veeam has built a quite expansive set of threat detection capabilities covering before, during, and after attacks which can help users achieve even greater protection across their environments. The firm has also partnered with various companies across other functions, including cybersecurity readiness, incident response, ransomware detection and reconnaissance, and encryption.
These partnerships have helped the data resilience company to enhance its Data Platform tool with various security protections that spot and squash cyberattacks including ransomware. They enable it to take a multi-faceted approach that includes scanning during the backup process. It will watch for file extensions and tools such as NMAP or Filezilla which are known to be used by bad actors, enabling it to detect attackers that ‘live off the land’ by using generic tools to fly under the radar.
Immutability is another key part of ransomware protection, as this type of malware is known to attempt encryption of backups in many cases. Veeam offers immutability protections for its backups, enabling administrators to set time periods during which data cannot be altered. Administrators can use its immutability workload monitoring feature to spot any changes made to that time window. This immutable backup works across a wide range of enterprise technology platforms, including all of the usual cloud suspects, alongside those from a tranche of hardware and software partners.
Confidence in reporting and restoration
Immutable data is only useful if you’re confident that you can restore it. The US Department of Homeland Security’s CISA advocates for testing of backup restoration in its CPG Cross-Sector Cybersecurity Performance Goals guidance. Veeam achieves this via its SureBackup feature, which stands up virtual machines from backup data and then tests them to ensure they’re healthy.
Data restoration must be more than quick, explains Linch – it must also be flexible so that victims of a cyberattack can work around whatever damage the attacker has done. This is a critical part of the data resilience proposition.
“You have to be able to recover from multiple layers, such as backups, snapshots and replicas,” he says. “When you look at Veeam, we’re the only one in the industry that allows you to do those three things in any license of Veeam you bought.” The company also offers restoration of full VMs, individual files, and application-specific data such as database content.
In many industries, it isn’t enough to backup and test your data; you have to prove that you’re doing it well. That’s where the final element of data resilience – compliance – comes into play.
Veeam offers various compliance tools, including policy-driven automation for tasks like retention management and the storage of tagged data in specific areas, along with constant compliance monitoring through its Security and Compliance Analyzer. Its reporting capabilities give you something to satisfy the auditors, streamlining the compliance process so that you – and the regulators – can be sure you’re protecting data properly.
Tools like these are just one part of data resilience. Enterprises that don’t prepare a strategy to orchestrate all of this properly run the risk of ‘all the gear and no idea’ syndrome. “Organizations fall to the level of their preparation,” says Rick Vanover, who is on the product strategy team in Veeam’s Office of the CTO.
At a strategic level, data resilience requires good risk management, which means sitting down with the rest of the business to understand what kinds of data it wants to protect and why.
There are also considerations at the technical level. “Performance management is a big one,” warns Vanover. And enterprises must also consider the full spectrum of technical and commercial challenges. “If people move to the cloud, they must assess networking, security and billing. All three of those bite different, and hard.”
Data resilience is a far-reaching discipline that includes data portability. The option to migrate your backup data quickly between backup platforms is critical in an industry where an attack can knock infrastructure out of action – or where your costs can balloon on a vendor’s whim. Veeam is building a solid tool set to support a strategic move for data resilience. That looks set to become more important for enterprise users of VMware and other platforms alike in the future.
Used Seagate EXOS drives presented as new are being sold through online retail channels, duping both buyers and sellers. The storage biz has now launched an investigation to find out what happened and is warning customers to be mindful of the warranty implications.
This follows a recent rise in the number of customers reporting drive fraud after used devices sold as new found their way into the authorized supply chain, according to a report by Heise in Germany. The drives indicated a runtime of zero hours yet tests showed that some had been in operation for an average of 25,000 hours.
This could be done by hacking the drive’s SMART data, and it is claimed that BAB Distribution and ctn-systeme in Germany, Digitec-Galaxus from Switzerland, DiTech from Austria, the Luxembourg branch of Alternate, and some Amazon and eBay retailers were unwittingly caught out, though they have offered to replace the dirves or refund the purchase price. Resellers Bechtle and Wortmann had been similarly duped, it was reported by the German media outlet.
In a statement, Seagate said:
“Seagate has not sold or distributed these mislabeled drives to retailers. We recommend that retailers purchase drives only from certified Seagate distribution partners to ensure they are purchasing and selling only new or Seagate factory recertified drives. Drives refurbished by Seagate, factory certified and resold under the Seagate Drive Circularity Program can be identified by the green-bordered white drive label and the designation ‘Factory Recertified.'”
Segate told Block and Files: “These are clearly used drives that are fraudulently sold as new drives on the open market. So the buyer gets these drives, they’re clearly used. They bought them at a new price and that is what is happening from what we can tell early in this investigation. The majority of those drives, so they’ve come from an OEM or they come from a cloud provider, they’ve been pulled and then they’ve sold out on the open market as new. Those are clearly fraudulent drives.”
Seagate says it also knows of cases of blatant deception – drives “which might consist of what we call outright fraud, which are counterfeit labels. It’s not unusual for customers to get a counterfeit drive and that might be a drive of a different class remarketed as a higher class, like an EXOS category to command a higher price. We see outright drives that often come in with no guts inside. Basically they’re a paperweight. So we occasionally run into a few of those, not widespread, but occasionally.
“So we really want to try to make sure customers know who they’re buying them from and use our tools to validate that their parts and that the product they bought is in warranty. So in the case of what we’re seeing in the fraud [highlighted by Heise], again, those are largely used drives sold as new. We also see some counterfeit labels where country names aren’t spelled correctly. There’s a whole host of things that you can start to identify in a label that are pretty good indicators of fraud.
“We have a security and brand council. We engage authorities and we’ll take down resellers where we’ve identified fraudulent activities. And if they’re resellers of ours, we try to proactively work with them. And a lot of times in the majority of cases, they’re unaware that they have this fraudulent inventory. So we work with them on trying to identify where they source that from and correct that with those parties that have been identified.
“We’ve actually even had a third-party investigative firm that’ll continue to conduct these buys on our behalf and then take any necessary legal actions required. So we take this very seriously. We hate to see our customers being the recipient of these fraudulent drives. We try to make it right.”
Seagate sells new and reconditioned drives. Both are warranted, but the reconditioned drives are only for six months or so, much less than new drives. New drives are sold through a two-tier distribtion channel (wholesaler to reseller), as well as to OEMs, systems integrators, and hyperscalers. The distributors are located within geographic regions and drive warranties are specific to these regions.
A Seagate spokesperson told Blocks and Files: “Those resellers, the vast bulk of them will buy first-party drives from their distributors for obvious reasons. They get a good price, they’re trustworthy, they have backup, they have support, so on and so forth. But there’ll be some who may buy drives from somewhere else. This is not something that Seagate can prevent even if it wished.”
A diagram shows what’s going on:
OEMs and system integrators (SIs) treat drives as components, building systems using them, like servers, and then supplying the systems either to distributors who then sell to resellers, directly to resellers, or directly to larger customers.
A regional supplier may wish to sell off an inventory of unwanted drives; perhaps ones with too low a capacity for their current customers, and offer them at a lower price to resellers. This can be an attractive price to both in-region and out-of-region resellers or etailers who buy the drives to sell on, but Seagate then deems that their warranty has been invalidated by the drive being sold out of its original region.
“Drives that are new legitimate drives, but they are sold outside of their region… are not eligible for warranty in a region other than where they were sold. So typically, we will see gray market, in particular for markets like China. We are working very closely to make sure that those clearly say China-only.”
“Those are typically new drives [and] not an issue, except when a customer buys them from out-of-region, they’re looking for a deal, they’ll quickly realize should they have an issue that those are not eligible for return in a region that they were sold. So that’s not uncommon.”
Customers with a population of used but no longer wanted drives can destroy them or return them to Seagate, which will either destroy them or, if they still have a useful working life, refurbish them and sell them explicitly as reconditioned drives with “Re-certified” on a white label, and etched “Re-certified” on the casing base. Such drives are sold to online channels and you may find them, for example, on eBay.
The Seagate spokesperson told us these are called pulled drives. “Those are typically used drives that have come from an OEM or a hyperscaler or another region. Those were integrated, subsequently used, and then pulled out. And typically when they’re pulled, most companies will either destroy them or they will resell them on the market, but should advertise [them] as such.” This happens “in the majority of these cases.”
“You might have resellers that warranty those products for a longer period of time. That’s at their discretion, but it’s important the public knows we warranty those drives for only six months.
”In general, we’ve had a second-hand market for a very long time. I think it’s really proliferated with etail and the ability to have third party marketplaces that can sell. I think eBay is one of the marketplaces [where] we see a lot of third party activity. Even Amazon 3P (third party) continues to grow, and so it’s really important buyers are aware of who that third party it is. We encourage them to buy first-party material because that is what we sell to Amazon. That is legitimate. Anything that comes through third party, make sure you’re buying from a reputable seller on Amazon.”
It’s a case of buyer beware. “In the event that they’ve caught… not only do we encourage them to return that, more importantly, we actually ask them to report it. Because what often happens is someone might identify a used drive sold as new, they return it, that stays in the supply chain and we’re not able to pull that out of the supply. It gets put back into circulation. So we actively encourage them to report that to us and actually return the drive to us. We have a program in place that allows them with proof of purchase and that securing that drive, we will replace that drive for them.”
Bootnote
Heise reports some customers buying Western Digital drives may have been similarly deceived. We have asked Western Digital for comment.
SanDisk reckons we can have a smartphone running a mixture-of-experts (MOE) AI model, with each expert operating using data stored in dedicated HBF mini-arrays.
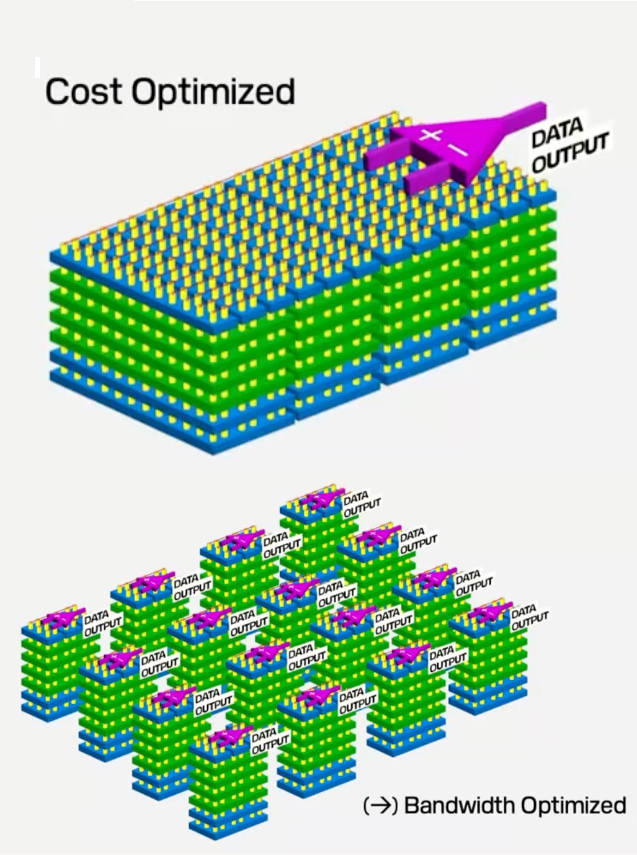
SVP Technology and Strategy Alper Ilkbahar presented SanDisk’s NAND technology strategy at the recent investor day, where he introduced the high-bandwidth flash (HBF) concept as a NAND equivalent of high-bandwidth memory. He started by envisaging a current NAND array optimized for capacity and having a single I/O channel. We can, in theory, subdivide this into mini-arrays in a bandwidth-optimized design, he said, and give each one its own I/O channel. “When you do that, you get massive amounts of bandwidth and bandwidth optimization.”
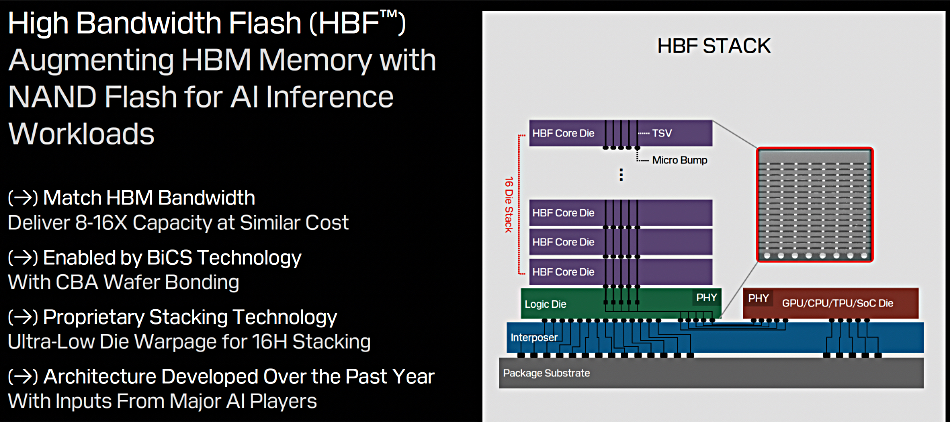
Having set the scene, he introduced the HBF concept with a 16-layer NAND stack connected via a logic die to an interposer that provides a multi-lane, high-bandwidth channel to a GPU or other processor: the high-bandwidth memory (HBM) idea.
SanDisk’s CBA (CMOS directly Bonded to Array) technology has a logic die bonded to a 3D NAND stack. That logic die becomes the NAND-to-interposer logic die, and the 3D NAND stack is replaced by a 16-layer stack of core dies, interconnected by HBM-like through silicon vias (TSV) connectors. This will have much more capacity than an equivalent HBM package: “We are going to match the bandwidth of HBM memory while delivering eight to 16x capacity at a similar cost point.”
In effect, although Ilkbahar didn’t explicitly say it, each stack layer is a miniature NAND array with its own I/O channel. The logic die, aka NAND controller, now has to do much more work handling these multiple and parallel I/O channels.
Initially, SanDisk engineers thought the HBF package would need a mixture of NAND and DRAM, with the DRAM used for caching critical data: “The reason we thought we still need the HBM is because, although inference workloads are heavily really intensive, you have data structures such as KV caches that need frequent updates, and we thought, for those, you might require HBM”.
This turned out not to be the case because multi-head latent attention was developed by DeepSeek AI researchers. This enables compressed latent KV caches or vectors to be stored, leading to a reduction in memory needed. Ilkbahar said: “As a matter of fact, they are reporting that they’re able to reduce KV caches by 93 percent. So any innovation like that actually now would enable us to pack four terabytes of memory on a single GPU.”
The 4,096 GB of HBF memory is formed from 8 x 512 GB HBF dies
That means “GPT-4 has 1.8 trillion parameters with 16-bit weights, and that model alone would take 3.6 terabytes or 3,600 gigabytes of memory space. I can put that entire model on a single GPU now, I don’t need to shuffle around data any longer.”
The next generation of AI models are going to be larger still. Ilkbahar said mixture-of-experts models “require a significant number of experts for different skills. Or think about the next generation of multimodal models that are bringing together the world of texts, audio, and video. All of them are going to be memory-bound applications and we have a solution for it” with HBF.
Alper Ilkbahar
He then switched away from GPU servers (or AI PCs with GPUs inside) to smartphones: “How is your experience with your AI, with your cell phones or mobile phones? Mine is pretty non-existent because, actually, it takes incredible resources to run AI or reasonable AI in a mobile phone. Now, just throwing money [at it] doesn’t quite solve the problem. You just don’t have the real estate, you don’t have the power envelope, you don’t have the compute power, you don’t have the memory.”
HBF changes the equation, he said. “People have been trying to solve this problem by reducing the model significantly, to a few billion model parameter models, but the performance of those models has been really frustrating for the users. They just don’t deliver the experience. You really want to use a significantly larger model size, and I’m going to propose here a hypothetical model of 64 billion parameters. Although this is hypothetical, Lama 3.1 or the DeepSeek 70 B are very similar models to this in size and capability and they have been very satisfactory for people who are using it. But still, you would need 64 gigabytes of memory just to put this in.”
He reckons “I could fit an entire model” on a single HBF die, not a stack. At which points he returns to the mixture-of-experts topic: “Mixture-of-expert models divide up a very large model into multiple smaller models, and for each token generation, you actually activate only a few of those, by which you are actually reducing the need for large compute. The problem becomes more memory capacity-bound, but no longer compute-bound.”
An HBF 512GB die split into 8 mini-arrays of 64GB, each providing data for one of the experts in an MoE model
The next step in his argument is this: “If you were to put this mixture-of-experts model into an HBF and ask a question … it’ll very smartly give the right answer, and that we are truly excited about.”
An animated slide showed one HBF die split into eight units (aka mini-arrays) with a 64 billion MOE model. Each expert model has its own mini-array and executes using data from that. Ilkbahar said: “We are truly excited about the potential of making the impossible possible and truly enable amazing AI experiences at the edge.”
He concluded: “We are bringing back SanDisk. We are incredibly excited about that and we can’t wait to disrupt the memory industry.”
If this HBF concept flies, it could do wonderful things. We think it will have a greater chance of success if there is general NAND industry buy-in. We note that Ilkbahar was once the VP and GM of Intel’s Optane group. Optane technology did not succeed and one of its characteristics was that it was proprietary to Intel and its fabrication partner Micron.
Interview DDN has been supplying high speed file access with its EXAScaler Lustre parallel file system software for many years. This supports Nvidia’s GPUDirect protocol. It has just announced its Infinia 2.0 fast access object storage and this will support GPUDirect for objects.
Led by VAST Data and Glen Lockwood, a Microsoft Azure AI supercomputer architect, there is a move to file-based consign AI training on NVIDIA GPUs to history and use object storage in future. How does DDN view this concept? We discussed this with by James Coomer, SVP For Products at DDN, and the following Q and A has been edited for brevity.
Blocks & Files: Where would you start discussing file and object storage use and AI?
James Coomer
James Coomer: There’s three main points. Firstly, it’s not really as if all large scale AI systems can, out of the box, use S3 and we try it, right? So we’ve got the fastest S3 in the planet with Infinia. The [general object storage challenge] is it’s really not mature. So the fact is, just ask any one of these SuperPODs, ask Nvidia, ask the largest language model developers on the planet. They’re using file systems and they’re using parallel file systems. So are they all wrong? I’m not sure they are. So firstly, the current state of play isn’t what they’re stating. If you were starting from scratch today, could you design an IO model which could avoid the use of a parallel filesystem and try to do things in parallel?
Yes, you could. And I think gradually things are moving that way and that’s why we built Infinia.
That’s why we built the lowest latency S3 platform with a faster state of discovery like way faster than any of our competitors, because we see that a very important aspect is object store’s scalability. They’ve got great benefits; you can scale ’em easier, you can handle distributed data easier. It’s great, but they’re just not great at moving large amounts of data to small numbers of threads.
Blocks & Files: Talk about checkpointing
James Coomer: Our competitors tend to dumb down the challenges of checkpointing because their writes are slow, so they can’t write fast. They say, “oh, it doesn’t matter.” And I’ve seen now four articles over the past three years where first they said, “oh, checkpoints don’t matter.” And then it became obvious that they did matter and they said, “it’s okay, our writes are faster now,” but they still weren’t that fast.
And now they say, “oh, you don’t need it at all.” It’s just like any excuse to kind of pretend that checkpoints aren’t a big problem and parallel filesystems are the fastest way of doing it. The challenge is this; it’s not the box – as in the box could say, “I’m doing a terabyte a second, 10 terabytes a second.” It can say whatever it likes. The challenge is how do you push the data into the application threads?
Blocks & Files: What do you mean?
James Coomer: Application threads are running up there across maybe one GPU, maybe a thousand GPUs, maybe 10,000 GPUs, maybe a 100,000 GPUs. But there’ll be a subset of ranks which are requesting IO. And the cool thing about a parallel filesystem is we can really pack that thread full of data when it reads a request, we can pack the single thread so anybody can create a million threads and get great aggregate performance. But that’s not what these applications are doing.
They are spawning a few IO threads. A few ranks out of the parallel programme are making data requests. And the parallel file system magic is in pushing massive amounts of data to those limited number of threads. So when you’re talking about performance is such a big spectrum of course, but it’s certainly not an aggregate performance question. It’s about application performance.
How is the application behaving? And, over time, applications change their behaviour for the better. But as we saw in HPC over the past, what, 30 years, have they changed? Think of all these applications. No, they still all use parallel file systems. All of them, like all big HPC sites are using parallel file systems because the applications take ages to change.
Now in AI, definitely faster, definitely much better, and we’re right in the heart of that. We’re working with Nvidia on NEMO, enhancing its IO tools to paralellize the S3 stuff. We’re right in the middle of it because we’ve built the fastest S3.
But still, the fact is parallel file systems currently for the broad range of AI frameworks are by far the fastest way of moving data to those GPUs and getting the most out of your 10 million, a hundred million, a billion dollars spend on AI infrastructure, data, data scientists, et cetera.
Blocks & Files: You said you had three points to make. What are the others?
James Coomer: The first one is the world isn’t ready yet. Secondly, the people who implement these systems aren’t the ones installing the AI frameworks and running them. That’s the data scientists. Often they don’t even know who the infrastructure people are. So they’ll come along and they’ll do what they’re going to do. You’ve got no control over it. How are they going to push their IO and stuff like that? So the fact is the majority of these AI frameworks run really, really fast on parallel file systems and don’t run very fast in S3 or don’t work at all.
The third one, is if it [object] was ready, we’d be the best because Infinia is like a hundred times faster than the object storage we’ve compared with in data discovery, what we call bucket listing. We’re twenty, twenty five times faster in time to first byte from the best, the fastest object store competitor we could find on the same hardware system. And we provide around five times the puts and gets per second than anything else we’ve seen. So we think, if it was the case, that object was the new utopia for AI, then we are down there ready, and we can compete with everybody on that plane.
Blocks & Files: Is this much, much more than just satisfying a GPUDirect for object protocol?
James Coomer: Oh yes, yes. I’m glad you said that because, otherwise, DDN will be like the others who are going to be supporting that protocol.
Most of the latency from the object data path does happen at the storage end. HTTP’s non-RDMA accelerated stack at S3 is not exactly fast and it’s not very well paralellised. So by using GPUDirect for object, we’re going to accelerate the RDMA network component, but then we’re not accelerating what the storage is doing it to make that data available. Once the servers receive the object, how does it make it safe and then respond with the acknowledgement?
That is actually, in our tests, where the bulk of the latency resides. It’s actually the back-ends. And it can make sense historically because until today, until now, nobody’s really cared that much about huge object store latency and straight performance.
Blocks & Files: No, they haven’t. They haven’t at all, because it’s been basically disk-based arrays for objects, being cheap and very, very scalable data storage; not for real time data. And you’ve been writing Infinia for five years or more?
James Coomer: Yes, more than five years.
Blocks & Files: You’ve been putting in a lot of effort to do this, and what you’re saying makes sense. You’re not just sticking a fast GPUDirect funnel on top of your object store. You’ve got the tentacles going down deep inside it so you can feed the funnel fast.
James Coomer: We’ve been really paranoid about it during the development of our underlying data structures. So the Key-Value store we use is designed to provide a very, very low latency data path for small rights and small reads, and a completely different, also optimised, path for large writes and reads, all in software. This does contrast with the rest.
Definitely, let’s say the first generation of object stores and the second generation were archives. They’re supposed to be low cost and supposed to be disk-based. And if they’re talking about performance, they tend to talk about aggregate performance, which anybody can do. You have a million requesters and a million disks and you can get a great number. That’s never a performance challenge. Anybody can do that because there’s no contention in the IO requests.
The challenge is from a single server, from a small amount of infrastructure, from a small number of clients, how much data can you push them? What’s the latency for the individual put in response? And we’ve got that probably sub millisecond, which is less than a thousandth of a second. If you look at other object stores, you’ll see the best of the best that we’ve seen out there is 10 times that And then if you go to cloud-based object stores, historically, they’re going to be often close to a second in response time, especially when the load is high.
So that’s one aspect, the latency of the puts and gets. But actually it’s not the biggest complaint we see from consumers of object stores who are interested in performance. The biggest complaint is the first thing they’ve got to do when they’re doing the data preparation is find the bits of data they’re interested in doing the preparation on.
Blocks & Files: Can you give me an example?
James Coomer: So imagine you’re a autonomous driving company. And you’ve got a million videos from a million cars, and each video’s got a label. Well, actually, it’s got a thousand labels on each video, and for every frame on each video, there’s maybe a hundred labels because it’s being unsupervised learning.
It’s going to label all the contents of that frame and say “there’s a cat, there’s a traffic light, there’s a car, there’s a building.” It’s all there in metadata. And the data scientist, who wants to do with these million files, each one with tens of thousands of labels, is going to say, I am interested in finding all the video file frames with a ginger cat, and that is data discovery. It is object listing. You’re not even getting the objects, you’re just finding out where they are. And that’s really the biggest issue, the biggest bottleneck right now for data preparation, which is about 30 percent of the overall walk-on time of AI, is doing this bit.
And the biggest part of doing that bit, the data preparation part, is finding these pieces of data. And we’ve done that. We do that really, really fast, like a hundred times faster than anything else we’ve tested. This object listing sounds like it’s really deep in the weeds, but that’s how fast we find the data. And data scientists are doing it all the time.
So I think when people focus on checkpointing, it’s for a marketing reason. And actually what we’re trying to do is work out firstly where people are spending their time and where storage is a bottleneck, and data is a bottleneck. And we find in the data preparation cycle, we think of this as ingest, preparation, training and inference.
It’s in the data preparation cycle actually where objects storage is mostly used because you tend to get images and stuff coming into object stores, satellite data, microscope data tend to go to an object store.
The challenge there for the data scientist is munging that data at massive scale using things like Spark, like Hadoop. They’re basically preparing their data, creating these datasets ready for training. And the biggest problem there is finding that stuff, and that’s object listing.
The second one is time to first byte. Third one is puts and gets per second, fourth one is actually throughput. So fourth in the list of importance is the throughput of the objects in this case.
Blocks & Files: Regarding the object listing; I’m moderately familiar with trying to find a particular file in a billion file/folder infrastructure with tree walks being involved and so on and so forth. But you obviously don’t have a file-folder structure with object, yet you’ve got this absolutely massive metadata problem. Could be just a simple flat space or is it partitioned up somehow? Do you parallelize the search of that space?
James Coomer: It is massively paralellized, but also, it’s a multi-protocol data plane. So even though we are exposing an object store first, we’re not an object store.
It’s actually a key-value (KV) store underneath. It’s a KV store with a certain data structure. And we chose this particular KV store because it’s really fast at managing commits and renders as we call them or reads.
So it’s writes and reads, but small things and big things, and we do a lot of this stuff in a very intelligent way. The log structuring is done very intelligently, so we don’t need a write buffer that other people need and those kind of things. But the point is, think about your knowledge of file systems and blocks and kind of modify writes. That’s nothing to do with what we’re doing. Nothing. Even though we are going to present a file system and an object store and an SQL database and a block store at this key-value store, there’s none of that traditional file system construct built into the backend of what we’re doing and how we’re laying this data out.
So we can index data and create parallel indexes of the metadata of all the objects, and we can basically cache these indexes and then query them in parallel like you would a parallel database, like something like Cassandra. The same kind of architecture that Cassandra uses is a similar approach to how we’re allowing people to access and search the metadata associated with the objects.
Blocks & Files: When you were talking about an underlying key value store with object on top of it, and I believe you just mentioned file systems on top of it as well. Then you could stick a block system on top of it if you wanted.
James Coomer: Exactly. Completely. So the KV store is here and we just expose the KV store through different protocols. So we expose it now through a containerized set of services, exposing it as S3. it’s a really thin layer. The S3 is really thin.
Then we can do the same. We’d expose the same key KV pairs, which are basically hosting the data and metadata, as file, as block, as an SQL database. All of these different things can be exposed very efficiently from a KV store. And they’re all peers, right? There’s nothing static. They’re all peers to each other, these different services, and they’re all just exposing the same underlying scalable KV store, which can hold tiny things and big things, millions and billions of pieces of tiny metadata or a small number of terabyte size objects equally efficiently.
We do it all in software. You don’t need any special storage class memory, anything like that. It’s all software, all scalable, super fast and very, very simple. We’ve done a better architectural job than others in building this underlying scalable data plane with this KV store to suit the different characteristics of block versus SQL versus S3 versus file.
StorONE is offering updated storage tiering with AI-powered TierONE software and improved data protection with SnapONE.
The company claims customers don’t need all-flash array (AFA) systems to get fast performance, saying its new software release offers “superior performance and cost savings by automatically tiering data based on access frequency.”
The company announced faster auto-tiering and vSNAP features in its v3.8 S1 software release last June. Now it has improved both features with a v3.9 release, adding quicker NAS performance, automated storage unit provisioning, a modernized GUI, and scheduled, customized PDF reports on S1’s operations.
CEO Gal Naor stated: “StorONE is delivering, for the first time, a solution for storing cold data that meets three seemingly contradictory requirements: extremely high-performance writes, long-term data storage at a low cost, and immediate availability of the data for customer use.”
S1 provides performant and affordable block, file, and object storage from a single array formed from clustered all-flash and hybrid flash+disk nodes. TierONE dynamically optimizes data placement across SSD and disk drive tiers, providing real-time insights and recommendations, “cuts storage costs by over 50 percent for inactive data without compromising performance, manages data movement between tiers in the background, and allows users to configure flash usage for active data held in the flash tier.” The exact way it does this has not been revealed.
The S1 software already converts application random writes into sequential writes when moved to lower and slower tiers like HDD. They are written to disk faster than random writes, with write speeds up to 18 GBps. Writes to SSDs are managed in such a way as to reduce subsequent garbage collection activities that cause additional writes, slowing down the SSD.
Naor says: “Until now, customers had no alternative and were forced to pay 2-3 times more for AFA systems or endure very long recovery times from off-line media.” S1 can provide recovery from disk media.
SnapONE “revolutionizes data protection snapshots with file-level tracking and restoring individual files, streamlined restores for intuitive recovery and snapshot summaries.” This provides better recovery from ransomware attacks.
v3.9 automates full data services provisioning, such as NAS, block, or object volumes, achieving simplified management. With this automation, “application managers can handle volume creation without technical expertise.”
StorONE says a redesigned, user-friendly interface enhances workflows and usability based on customer feedback. Detailed and custom S1 operations reports can be configured and sent automatically, saving admin time.
This software release should improve S1 operations for StorONE’s customers and give its resellers fresh ammunition when selling against AFA competition from suppliers such as Dell, HPE, Hitachi Vantara, Huawei, IBM, Lenovo, NetApp, and Pure Storage. You don’t need to spend big money on all-flash systems when StorONE’s software finesse can tweak extra performance from hybrid flash+disk systems. And if you do need all-flash systems, StorONE says it can make them go faster as well.
Marc Staimer, CEO of Dragon Consulting, offered his thoughts on the release: “StorONE’s auto-tiering solution delivers Tier-1 performance with Tier-2 costs. By dynamically reallocating resources, the platform allows businesses to maximize efficiency and reliability, offering exceptional value in the storage market.”
Cloud and backup storage provider Backblaze is partnering with Kandji to deploy Backblaze with zero-touch across a fleet of Macs to back up their data. More info here.
…
SaaS backup provider Cobalt Iron has a strategic alliance with Jeskell Systems, an IBM-skilled data lifecycle management consultancy, with Cobalt Iron’s Compass and Secure Automated Backup for Power Virtual Servers products used in Jeskell’s data lifecycle management services.
…
Cohesity, which now owns Veritas, has appointed Carol Carpenter as CMO. She has been a Unity CMO, VMware CMO, and Global VP of Marketing at Google Cloud. She will focus on driving increased brand awareness, refining go-to-market strategies, and creating programs to drive demand generation. Lissa Hollinger – former VP of Marketing at Veritas – oversaw the transition period. VP Raj Dutt, formerly Cohesity head of marketing, remains with Cohesity, leading product marketing, and will be reporting to Carpenter.
Carol Carpenter and Raj Dutt
…
CTERA announced a record-breaking 2024 marked by accelerated international growth. Its edge-to-cloud file services annual recurring revenue (ARR) grew by 35 percent, with the Asia-Pacific region growing by 82 percent. It experienced 60 percent growth in the government segment and doubled the number of customers generating seven-digit ARR. Chairman and co-founder Liran Eshel said: “Over the past year, enterprise AI has become a top priority for nearly every IT organization. While the potential of AI is transformational, the primary challenge lies in adapting data platforms to support the new AI workflows securely and efficiently.”
..
EnterpriseDB (EDB) said an independent benchmark study by the McKnight Consulting Group showed EDB Postgres AI delivers superior performance over Oracle, SQL Server, MongoDB, and MySQL across transactional, analytical, and AI workloads. McKnight used the TPC-C benchmark and said EDB Postgres AI was:
150x faster than MongoDB in processing JSON data
4x faster than MySQL in handling insert operations
Outperformed Oracle by 17 percent and SQL Server by 30 percent in processing New Orders Per Minute (NOPM)
7x better price performance than Oracle and 6x better than SQL Server (measured in cost per transaction)
Security supplier Securiti and Databricks are partnering to integrate Databricks’ Mosaic AI and Delta Tables into Securiti’s Gencore AI so customers can use their proprietary data to more easily and quickly build enterprise-grade, personalized AI applications. Securiti says Gencore AI accelerates GenAI adoption in the enterprise by making it easy to build AI pipelines using data from hundreds of data systems.
…
MRAM developer EverSpin says its PERSYST MRAM is now validated for configuration across all Lattice Semiconductor Field Programmable Gate Arrays (FPGAs), and enabled through the Lattice Radiant software suite. It says that, unlike NOR flash, which requires long program and erase time, MRAM offers high endurance, fast read/write speeds, and exceptional data retention. This makes it suitable for real-time sensor processing, data logging in avionics, and in-orbit reprogramming for space systems. The PERSYST EMxxLX MRAM family is now available and shipping in industry-standard packages and interfaces.
…
HighPoint Technologies positioned its RocketAIC E1.S NVMe Storage AIC products as an alternative to the Samsung PM1735. It says that, as enterprises transition to PCIe Gen 4 and Gen 5 NVMe storage, selecting the right flash drive depends on whether single-drive performance or RAID-based scalability takes priority.
For compact, ultra-fast single-drive NVMe storage: Samsung PM1735
For high-performance, RAID-enabled NVMe storage: HighPoint RocketAIC 7749EW
For flexible, software-defined NVMe storage expansion: HighPoint Rocket 1749E
…
Hitachi Vantara says its UK customer, independent primary school Manor Lodge, has upgraded from a Netgear ReadyNAS to a VSP G350 storage system, achieving 100 percent uptime. It’s also upgraded its Lenovo servers to newer models. The G350 is a hybrid flash+disk, block access, rack-class, storage system designed for mid-range enterprise environments.
…
Hydrolix has been accepted into the AWS ISV Accelerate Program. The company says it also recently achieved Amazon CloudFront Ready status, “due in part to the 75 percent savings on observability and storage costs. Customers use it to ingest and analyze hundreds of terabytes of log data in real time, consolidating data into a unified view and spotting issues in seconds.”
…
InfluxData announced Amazon Timestream for InfluxDB Read Replicas – a new capability for its time-series database to boost query performance, scalability, and reliability for enterprise-scale time series workloads. It provides scalable query capacity, rapid failover, and uninterrupted access to time series data, without the complexity of cluster management. This builds on InfluxData’s partnership with AWS announced last year to deliver Amazon Timestream for InfluxDB. It’s a managed offering for developers to run open source InfluxDB natively on AWS without self-management.
…
SaaS backup provider Keepit, which uses its own distributed datacenter infrastructure, says it had a great high-growth 2024. It intends to accelerate its global expansion, prioritizing key markets across the Americas and Europe, and other high-growth regions. It also plans to deliver intelligent resilience and recovery through broader workload coverage, as well as deeper data management and intelligence capabilities for the enterprise.
…
Micron says its LPDDR5X memory and UFS 4.0 are featured in select devices in the Samsung Galaxy S25 series. “With its One UI 7 update, the Galaxy S25 series is a true AI companion that provides personalized experiences tailored to users’ unique needs, powered by multimodal AI agents that seamlessly interpret text, speech, images, and videos.”
…
On March 11, MLCommons will present its MLPerf Client v0.5, Storage v1.0, Inference v4.1, and Training v4.1 results. Register here to attend a community meeting.
…
Oracle has integrated its AIStore (AIS) open source object storage system with Nvidia GPUs and AI software services available on the OCI (Oracle Cloud Infrastructure) public cloud. Oracle LiveLabs offers a workshop, AIStore Cluster in OCI, to explore the integration.
Oracle AIS diagram
…
Back in October, SingleStore bought data integration platform BryteFlow to help it ingest data workflows from CRM and ERP platforms such as SAP, Oracle, Salesforce, and other sources. Now it’s offering SingleStore Flow, “a no-code platform that makes data migration and CDC effortless, making it easier to prepare data for AI workloads and real-time analytics.” SingleStore Flow eliminates the need for complex scripts and manual transfers.
Data lakehouse supplier Starburst says it had a record FY25 close, growing net new customers by 20 percent and Starburst Galaxy customer growth by 76 percent year-over-year. It achieved record global sales, including significant growth in North America and EMEA, and signed the largest deal in the company’s history – a multi-year, eight-figure contract per year with a global financial institution. It also increased ARR per customer to over $325,000 and increased adoption of Starburst Galaxy, its flagship cloud product, by 94 percent year-over-year. Starburst was selected by Dell Technologies to be the analytics query engine powering the Dell Data Lakehouse, and its customers include ten of the top 15 global banks.
…
Veeam said its Recovery Orchestrator simplifies and automates the Hyper-V disaster recovery (DR) planning, testing, and execution process. It allows customers to create, manage, and test DR plans. Orchestrator, which already supports VMware, is available to Veeam Data Platform Premium customers. It also orchestrates the recovery of vSphere VMs to Hyper-V. Veeam Data Platform Premium Edition, including Veeam Recovery Orchestrator v7.2, is now available.
…
VergeIO says New York state’s Lancaster Central School district has become a customer for its VergeOS, moving from VMware vSAN and “achieving $150,000 in annual cost savings while improving performance, data protection, and storage efficiency.” Its stated reasons for moving included:
Complex stretched cluster dependencies, leading to potential disruptions
Rising capacity-based licensing costs, making budgeting unpredictable
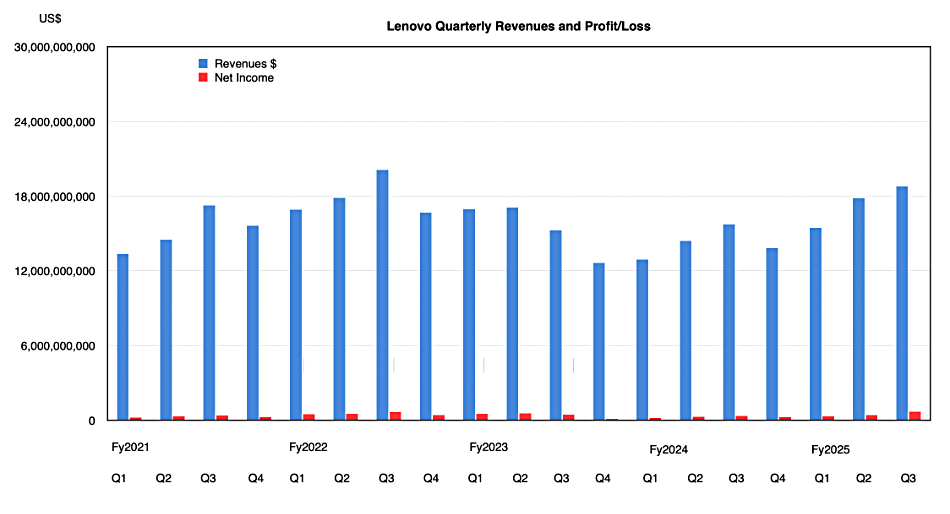
Lenovo reported its third consecutive quarter of double-digit revenue growth, with all three business units contributing at double-digit levels.
Yuanqing Yang
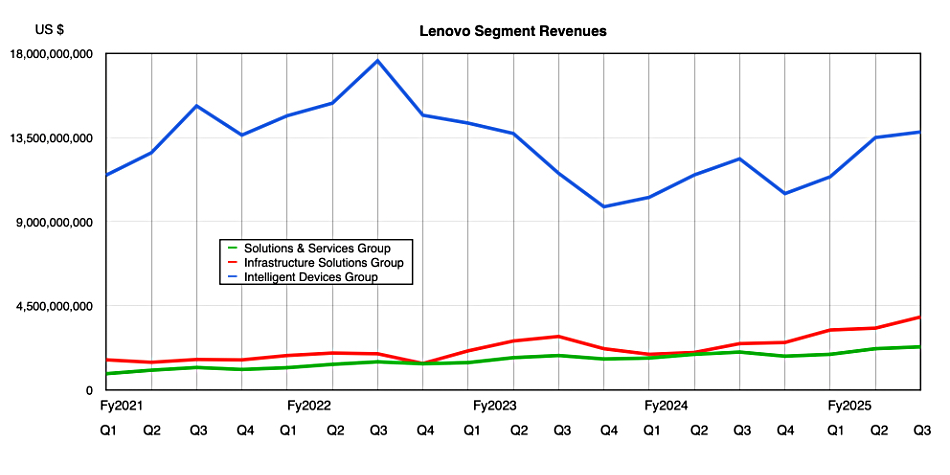
Revenues in the quarter ending December 31, 2024 were $18.8 billion compared to the year-ago $15.5 billion, with an HKFRS profit of $693 million – 106 percent higher than a year ago. The PC-selling Intelligent Devices Group (IDG) brought in $13.8 billion, up 12 percent. $3.9 billion flowed in from the turned-around Infrastructure Solutions Group (ISG), a 59 percent rise for its servers, storage, and so on. The SSG (Services and Solutions Group) was responsible for a 13.8 percent rise to $2.3 billion. Lenovo’s cash balance grew 14 percent year-on-year to $3.93 billion.
Chairman and CEO Yuanqing Yang stated: “Lenovo’s revenue and profit both achieved significant growth last quarter, with strong performance across all core businesses. Notably, the ISG business returned to profitability and the smartphone business experienced rapid growth. AI technology, with higher efficiency and lower costs, is accelerating the maturation of personal AI, particularly on-device AI and edge AI. It has also accelerated enterprise adoption of AI.”
Lenovo believes the AI boom is creating enormous opportunities for devices, infrastructure, and services. It has a hybrid AI strategy that includes building a foundational AI technology platform, AI PCs, edge, and datacenter AI products and services.
IDG gained a top 24.3 percent share of the PC business, almost five points clear of the number-two player (Dell), its highest share in 5 years, and was profitable. Lenovo saw strong growth in smartphones with revenue up double digits year-on-year, and hypergrowth in both the Asia Pacific (+155 percent) and EMEA (+28 percent) markets. It says it will “optimize AI agent capabilities, enhance multi-device connectivity, and build application ecosystems to provide seamless user experiences across devices and ecosystems.”
Lenovo expects the AI PC to represent approximately 80 percent of the PC industry landscape by 2027.
The ISG business experienced continued hypergrowth in the Cloud Services Provider (CSP) market (+94 percent), and steady growth in the enterprise and SMB (E/SMB) business (+7 percent). AI server revenue grew steadily and Neptune liquid cooling systems expanded beyond supercomputing and academia to wider vertical industries. This business unit was profitable for the first time in seven quarters.
No storage business results were called out. The ISG unit is under new executive leadership with Ashley Gorakhpurwalla now its EVP and president. Lenovo is acquiring Infinidat, an enterprise storage array business, with the deal expected to complete in the second half of this year. This will enable Lenovo to compete more strongly against the storage businesses of Dell, HPE, and Huawei.
It sees AI driving demand across public clouds, on-premises datacenters, private clouds, and edge computing. AI benefited the SSG unit with hardware-attached services, although revenue from non-hardware systems and services remained SSG’s strong profit engine, as it has been for 15 straight quarters.
The company said more than 46 percent of its revenues now come from non-PC sources, meaning smartphones, infrastructure, and services, up from 42 percent a year ago. It wants to drive its three businesses’ revenues and profitability higher:
The company does not present a revenue outlook for the next quarter.
Bootnote
Lenovo is FIFA’s official technology partner in a sponsorship deal that includes the FIFA World Cup 2026 in Canada, Mexico, and the United States, and the FIFA Women’s World Cup 2027 in Brazil. It also has a strategic technology partnership with Formula 1 racing.
DDN has announced the Infinia 2.0 object store for AI training and inference, making big claims for up to 100x improvement in AI data acceleration and 10x gain in datacenter and cloud cost efficiency.
Infinia is a object storage system designed from the ground up with a key-value-based foundation. We have recently written about Infinia’s technology here.
DDN CEO and co-founder Alex Bouzari stated: “85 of the Fortune 500 businesses run their AI and HPC applications on DDN’s Data Intelligence Platform. With Infinia, we accelerate customers’ data analytics and AI frameworks with orders-of-magnitude faster model training and accurate real-time insights while future-proofing GPU efficiency and power usage.”
His DDN founding partner, president Paul Bloch, said: “Our platform has already been deployed at some of the world’s largest AI factories and cloud environments, proving its capability to support mission-critical AI operations at scale.” DDN has previously said Elon Musk’s xAI is a customer.
AI data storage is front and center in DDN’s intentions for Infinia. CTO Sven Oehme declared: “AI workloads require real-time data intelligence that eliminates bottlenecks, accelerates workflows, and scales seamlessly in complex model listing, pre and post-training, RAG, Agentic AI, Multimodal environments, and inference. Infinia 2.0 was designed to maximize AI value in these areas, while also delivering real-time data services, highly efficient multi-tenancy, intelligent automation, and a very powerful AI-native architecture.”
Infinia includes event-driven data movement, multi-tenancy, a hardware-agnostic design, more than 99.999 percent uptime, up to 10x always-on data reduction, fault-tolerant network erasure coding, and automated QoS. It lines up with other fast, recently accelerated object stores such as Cloudian’s HyperStore, MinIO, Quantum Myriad, Scality’s RING, and VAST Data.
The Infinia software works with Nvidia’s Nemo and NIMS microservices, GPUs, Bluefield 3 DPUs, and Spectrum-X networking to speed AI data pipelines. DDN claims it “integrates AI inference, data analytics, and model preparation across core, cloud, and edge environments.” Infinia is integrated with Trino, Apache Spark, TensorFlow, PyTorch, “and other AI frameworks to accelerate AI applications.”
Nvidia DGX platforms VP Charlie Boyle commented: “Combined with Nvidia accelerated computing and enterprise software, platforms like DDN Infinia 2.0 provide businesses the infrastructure they need to put their data to work.”
Infinia, with TBps bandwidth and sub-millisecond latency, “outperforms AWS S3 Express by 10x, delivering unprecedented S3 performance.” Other DDN superlatives include 100x AI data acceleration, 10x faster AI workloads with 100x better efficiency than Hadoop based on “independent benchmark tests,” 100x faster metadata processing, 100x faster object lists per second than AWS, and 25x faster querying for AI model training and inference.
An Infinia system “scales from terabytes (TB) to exabytes (EB), supporting up to 100,000-plus GPUs and 1 million simultaneous clients in a single deployment, enabling large-scale AI innovation.” DDN says it is “proven in real-world datacenter and cloud deployments from 10 to 100,000-plus GPUs for unmatched efficiency and cost savings at any scale, ensuring maximum GPU utilization.”
Supermicro CEO Charles Liang said: “By combining DDN’s data intelligence platform Infinia 2.0 with Supermicro’s cutting-edge server workload-optimized solutions, the companies collaborated on one of the world’s largest AI datacenters.” We think this refers to xAI’s Colossus datacenter expansion for Grok 3 phase 1. DDN provides more information on Infinia here.
SPONSORED FEATURE: When it comes to artificial intelligence, it seems nothing succeeds like excess.
As AI models become bigger and more capable, hyperscalers, cloud service providers, and enterprises are pouring cash into building out the storage and compute infrastructure needed to support them.
The first half of 2024 saw AI infrastructure investment hit $31.8bn, according to IDC. In 2028, the research company expects full-year spending to exceed $100bn as AI becomes pervasive in enterprises through greater use of discrete applications as part of their broader application landscape. Once AI-enabled applications and related IT and business services are factored in, total worldwide spending is forecast to reach $632bn in 2028.
But while surging investment is one thing, reaping the full potential of AI in empowering engineers, overhauling and optimizing operations, and improving return on investment, are whole different ball games. For enterprises looking to truly achieve these objectives, data management right through the AI pipeline is likely to prove critical.
The problem is that traditional storage and data management offerings, whether on-prem or in the cloud, are already under strain given the crushing demands of AI. Capacity is part of the issue. AI models, and the data needed to train them, have steadily grown bigger and bigger. Google Bert had 100 million parameters when it launched in 2018, for example. ChatGPT 4 was estimated to have over a trillion at last count.
At the other end of the pipeline, inference – often carried at real-time speeds – makes latency and throughput equally as critical. There are many other challenges. AI requires a multiplicity of data types and stores, spanning structured, semi-structured, and unstructured data. This in turn requires the full range of underlying storage infrastructure – block, file, and object. These datastores are unlikely to all be in one place.
In addition to the sheer complexity involved in capturing all the information required, the breadth and distribution of data sources can also create a major management problem. How do organizations and their AI teams ensure they have visibility both across their entire data estate and throughout their entire AI pipeline? How do they ensure that this data is being handled securely? And this is all further complicated by the need for multiple tools and associated skill sets.
When legacy means lags
The introduction of newer and increasingly specialized AI models doesn’t remove these fundamental issues. When the Chinese AI engine DeepSeek erupted onto the broader market earlier this year, the huge investments hyperscalers have been making in their AI infrastructure were called into question.
Even so, building LLMs that don’t need the same amount of compute power doesn’t solve the fundamental data problem. Rather it potentially makes it even more challenging. The introduction of models trained on a fraction of the infrastructure will likely lower the barrier to entry for enterprises and other organizations to leverage AI, potentially making it more feasible to run AI within their own infrastructure or datacenters.
Sven Oehme, CTO at DataDirect Networks (DDN) explains: “If the computational part gets cheaper, it means more people participate, and many more models are trained. With more people and more models, the challenge of preparing and deploying data to support this surge becomes even more critical.”
That’s not just a challenge for legacy on-prem systems. The cloud-based platforms data scientists have relied on for a decade or more are often not up to the job of servicing today’s AI demands either. Again, it’s not just a question of raw performance or capacity. Rather it’s their ability to manage data intelligently and securely.
Oehme cites the example of metadata, which if managed correctly, means “You can reduce the amount of data you need to look at by first narrowing down the data that is actually interesting.”
An autonomous or connected vehicle will be grabbing pictures constantly, for example of stop signs. And in the event of an accident, and the subsequent need to update or verify the underlying model, the ability to analyze the associated metadata – time of day, speed of travel, direction – all become paramount.
“When they upload this picture into their datacenter… they would like to attach all that metadata to this object,” he says. That’s not a theoretical example. DDN works with multiple automotive suppliers creating autonomous capabilities.
It quickly becomes apparent that AI success depends on not just the amount of data to which an organization has access. The “richness of the data that is stored inside the system” and the ability to “Integrate all these pipelines or workflows together, where from the creation of the data to the consumption of the data, there is full governance” all come into play.
However, many organizations must currently juggle multiple databases, event systems and notifications to manage this. This can be expensive, complex, time consuming, and will inevitably create latency issues. Even cloud giant AWS has had to develop a separate product – S3 Metadata – to tackle the metadata problem.
Data needs intelligence too
What’s needed says DDN is a platform that can deliver more than just the required hardware performance, but also the ability to intelligently manage data securely, at scale. And it needs to be accessible, whether via the cloud or on-prem, which means it has to offer multi-tenancy.
This is precisely where DDN’s Data Intelligence Platform comes in. The platform consists of two elements. DDN’s Infinia 2.0 is a software-defined storage platform, which gives users a unified view across an organization’s disparate collections of data. EXAScaler is its highly scalable file system, which is optimized for high-performance, big data and AI workloads.
As Oehme explains, Infinia is “A data platform that also happens to speak many storage protocols, including those for structured data.” That’s a critical distinction he says, “Because what Infinia allows you to do is store data, but not just normal data files and objects. It allows me to store a huge amount of metadata combined with unstructured data in the same view.”
Data and metadata are stored in a massively scalable key value store in Infinia, he says: “It’s exactly the same data and metadata in two different ways. And so therefore we’re not doing this layering approach that people have done in the past.”
This can result in far more efficient data pipelines and operations, both by eradicating the multiple silos that have mushroomed across organizations, and by removing the need for data scientists and other specialists to learn and maintain multiple data analysis and management tools.
Because they’re designed to be multi-tenant from the outset, both EXAScaler and Infinia 2.0 are able to scale from enterprise applications through cloud service providers to hyperscalers.
The result are clear: Multiple TB/second bandwidth systems, with sub millisecond latency, delivering a 100 times performance advance over AWS S3, according to DDN’s comparisons. When it comes to access times for model training and inference, DDN’s platform shows a 25x speed boost, says the company.
As for on premises solutions, Infinia 2 supports massive density, with 100PB in a single rack, and can deliver up to a 75 percent reduction in power, cooling and datacenter footprint, with 99.999 percent uptime. That’s an important capability as access to power and real estate are emerging as a constraint on AI development and deployment, as much as access to skills and data.
DDN partners closely with chip maker NVIDIA. It’s closely aligned with the GPU giant’s hardware architecture, scaling to support over 100,000 GPUs in a single deployment, but also with its software stack, meaning tight integration into NIMs microservices for inference, as well as the NVIDIA NeMO framework, and Cuda. And NVIDIA is itself a DDN customer.
AI technology is progressing at a breakneck pace, with model developers competing fiercely for users’ attention. However, it is data – and the ability to manage it – that will ultimately dictate whether organizations can realize the promise of AI, whether we’re talking hyperscalers, cloud service providers, or the enterprises that use their services.
The potential is clear, says Oehme. “If you have a very good, very curious engineer, they will become even better with AI.” But that depends on the data infrastructure getting better first.