Dell has added faster PowerProtect appliances, enabled PowerProtect to back up all-flash PowerMax arrays, and introduced an AI copilot to help customers use its APEX Backup Services.
The company is basically making backup and restore faster and easier to use, pitching it as addressing the business use case of helping secure data in an era of increased malware risk.
Arthur Lewis, President of Dell’s Infrastructure Solutions Group, said: “With the exponential growth of data, generative AI (GenAI) presents organizations with opportunities to streamline processes, improve decision-making and drive innovation, but it also extends the attack surface for cyberattacks – especially with trained models, which are quickly becoming one of the most valuable assets for enterprises.”
APEX Backup Services are SaaS-based backup and restore facilities based on PowerProtect systems and Druva software that protect apps such as Microsoft 365, Google Workspace, Salesforce, and other cloud-based workloads, as well as endpoints and hybrid workloads. The APEX Backup Services AI is a GenAI copilot to help users access APEX backup services.
They can:
Request real-time custom reports, ask follow-up questions to refine report variables and act on AI-powered suggestions to remediate backup failures
Understand and improve their backup and security postures via assisted troubleshooting with simple written prompts, analyze logs, and troubleshoot errors
Use intelligent responses with recommendations and best practices customized to their specific environments
Simplify admin operations, from creating new backup policies to triggering new backups of specific workloads
PowerProtect target appliances
Dell has given its top two Data Domain (DD) target appliance models faster CPUs to speed backups and restores.
Currently the DD target appliance series consists of the DD9900, DD9400, DD6900, DD6400, DD3300, and software-defined appliances with PowerProtect DD Virtual Edition (DDVE) for on-premises and Dell APEX Protection Storage for Public Cloud.
The new DD9410 and DD9910 appliances have a 2RU enclosure, based on a Dell PowerEdge R760 platform with dual socket-supporting Intel Sapphire Rapids CPUs. They have more cores and memory to improve performance and scale, and are based on Data-Less head (DLH) architecture, which does not store any user data on the head unit’s internal drive. In both the models, the DDOS and Cache Tier are configured on the head unit’s internal SSDs. Both support 24x 2.5-inch SAS-4 SSD drives, as well as 8 TB HDDs. They come in normal and high-availability configurations.
Dell says there are three different storage tiers in these new systems:
Cache Tier – 3.84 TB SSDs (5 in 9410, 10 in 9910) in RAID 101
Active Tier – 8 TB HDDS in RAID 6
Cloud Tier – 8 TB HDD in RAID 6
For backup and restore operations, the DDR software fetches related metadata from the previous backup operation and stores it in the Cache Tier to accelerate high-performance hash lookups on the active backup streams. All user data is stored in the Active and Cloud Tiers after it is deduplicated and compressed.
Dell PowerProtect DD9410 and DD9910 configuration video
The new systems each support up to eight DS600 disk array enclosure (DAE), which is a 4RU, 24 Gbps chassis holding 60x SAS-4 3.5-inch drives – 480 TB raw capacity, 384 TB usable. Note that in both the new models, two disk groups are required as overprovision disks.
The new products offer:
Up to 38 percent faster backups, and up to 44 percent faster restores
Up to 11 percent less power consumed and claimed industry-leading 65x deduplication
Up to 1.5 PBs of usable capacity in a single appliance
Replication of DD9910 is 58 percent faster than the previous model, DD9900
DD9910 supports 64 concurrent VM instant restores and supports 118,000 IOPS for instant access, which is 18 percent faster than for DD9900
Maximum throughput numbers, with and without DD Boost, for the DD9410, are 44 TB/hour and 75 TB/hour respectively. Maximum logical capacity, with and without the Cloud Tier, for the DD9410 is 49.9 PB and 149.8 PB respectively, and for the DD9910 is 97.5 PB and 293 PB respectively.
Download a DD9410 and DD9910 white paper here. Watch a configuration video here. Get the latest PowerProtect DD product line specs here.
Dell PowerProtect competitor Quantum has just announced all-flash target DXi systems. Competitor ExaGrid believes it is faster and cheaper than any all-flash backup target competitors.
PowerMax all-flash protection
Dell PowerProtect Data Manager now has native integration with Dell’s high-end PowerMax all-flash enterprise storage so that it can have its data protected via the Storage Data Protection agent. This is snapshot-based and provides backup and recovery for VMAX3 and PowerMax arrays by using DD series target appliances. Features include:
Backup and recovery of multiple storage arrays with up to 46 TB/hr for a single backup and up to 21 TB/hr for a single recovery
Protection of Dell PowerMax with full restore to original or alternate PowerMax system
Data resilience through immutability and optional cyber vault integration
Centralized management and orchestration
Multicloud support for PowerProtect Data Domain replication and cloud tiering
Availability
Dell PowerProtect Data Domain DD9410 and the DD9910 systems are available globally
Dell APEX Backup Services AI is available globally
Storage Direct Protection for PowerMax will be available globally in the third quarter of 2024
Recovery from ransomware attacks needs to be tested and Commvault’s aiming its Cloud Cleanroom tech at those who are looking for on-demand checks.
The prevalence of business-crippling ransomware attacks means every company needs a disaster recovery strategy, not just those that can afford failover between physically separate datacenters. The most cost-effective way of doing this is to have a backup datacenter in the cloud which is fired up when needed, not one that’s operational all the time.
There is a restriction here in that the existing systems that need protection against disaster must be capable of being instantiated in the target cloud. This instantiation needs rehearsing so that it can be relied on. Commvault’s pitching its Cloud Cleanroom Recovery, an isolated cleanroom in the cloud, as allowing you to set up and test a ransomware recovery datacenter.
Brian Brockway.
Commvault CTO Brian Brockway said: “With disaster recovery, testing your recovery strategy once a year was fine. For example, with a natural disaster, you didn’t have to worry about bad actors infiltrating your systems. You just needed to be able to recover. Now, with AI-driven attacks, threat vectors change by the hour. The need to not only test your recovery frequently but know you have a clean place to recover in the cloud has never been more important.”
Commvault’s existing Cleanroom Recovery facility relies on Microsoft’s Azure to provide recovery from immutable backups to a cleanroom in the cloud for faster recoveries and also incident response testing.
It is being extended to support Commvault’s SaaS customers. When bad actors attack, Cleanroom Recovery orchestrates recovery into a clean, isolated location in Microsoft’s Azure cloud. Customers can do this on-demand and only pay for it when they use it.
Cleanroom Recovery gives customers the ability to quickly, easily, and regularly test recovery plans across their IT infrastructure. It is integrated with Microsoft Defender to automate threat scanning to help ensure data is clean and is planned to include Microsoft Active Directory restoration capabilities later this year. Commvault says that being able to restore Active Directory and validate its consistency and operational integrity can help ensure proper authorizations for data access remain in place.
Later this year Cleanroom Recovery will include capabilities that enable customers to rebuild applications and services from a known clean state, as needed.
Other features:
AI-enabled Cleanpoint Validation automatically empowers customers to identify the last clean recovery point.
Users can customize recovery sequences so data is recovered in a logical order. Users can convert VMs from any hypervisor to Azure VMs.
A forthcoming integration with Palo Alto Networks later this year will use Cortex XSOAR (Extended Security Orchestration Automation and Response) to add the latest threat intelligence data to incidents, streamlining the recovery of compromised assets into the cleanroom for forensic analysis and secure cyber recovery.
Commvault states that its Cleanroom Recovery customers also benefit from the Commvault Cloud platform, powered by Metallic AI. This enables customers to secure and recover their data, across any workload, and from any location to any location. In the future, via Commvault’s recent Appranix acquisition, customers will be able to use Appranix’s cloud application rebuild capabilities.
Aung Oo, General Manager for Azure Storage, Microsoft, said: “Commvault Cloud Cleanroom Recovery augments air-gapped data protection built on Azure with fast and secure recovery. It enables customers to test their resilience plans, and when necessary, recover to a trusted, clean, isolated location in Microsoft Azure. The clean and isolated copy also enables forensics for auditors and insurers and gives organizations a tremendous advantage in the fight against ransomware and other cyber threats.”
Pure Storage has a Cloud Block Store Azure offering. Mark Bridges, Senior Director, Strategic Alliances, Pure Storage, commented: “As cyberthreats grow in frequency and sophistication, global enterprises recognize the need to bolster their defenses with proactive security measures that safeguard not just their data, but the entirety of their business operations.”
Hitachi Vantara has a Commvault partnership. Dan McConnell, SVP of Product Management for Digital Infrastructure, Hitachi Vantara, said: “Providing customers with the ability to test their cyber recovery plans in advance, along with having a clean recovery point, fills a critical gap in the marketplace today.”
Competition
HPE’s Zerto Cyber Resilience Vault also provides protection by allowing for clean copy recovery from an air-gapped setup if a replication target is also breached. AWS has a cleanroom facility but it is used for collaboration and not ransomware attack recovery.
Cohesity is aware of cleanroom concepts but has no specific clean room offering. From its glossary: “Before restoring, backups are typically decontaminated in cleanroom environments where malware, vulnerabilities and other threats are identified before the recovery of backup data. This ensures that threats can not immediately relaunch after restoration.”
Rubrik doesn’t have a cloud clean room as such but it has some equivalent facilities. For example, it has “Orchestrated Application Recovery [which] integrates with Ransomware Investigation to identify impacted applications and rapidly recover them in-place using the recommended points in time just before infection.”
It also has a cyber-recovery facility with a “SaaS application that enables the deployment of isolated recovery environments for testing of recovery processes, and can help to parallelize the forensics process for faster recoveries in the event of a cyber attack. Integrates with Threat Monitoring & Hunting, Threat Containment, and Ransomware Monitoring & Investigation to pinpoint both safe and malicious recovery points for recovery, dependent on the scenario.”
Unless otherwise noted, the latest features of Commvault Cleanroom Recovery are available now. Learn more about Cleanroom Recovery via a Commvault blog and website. There’s a solution brief here.
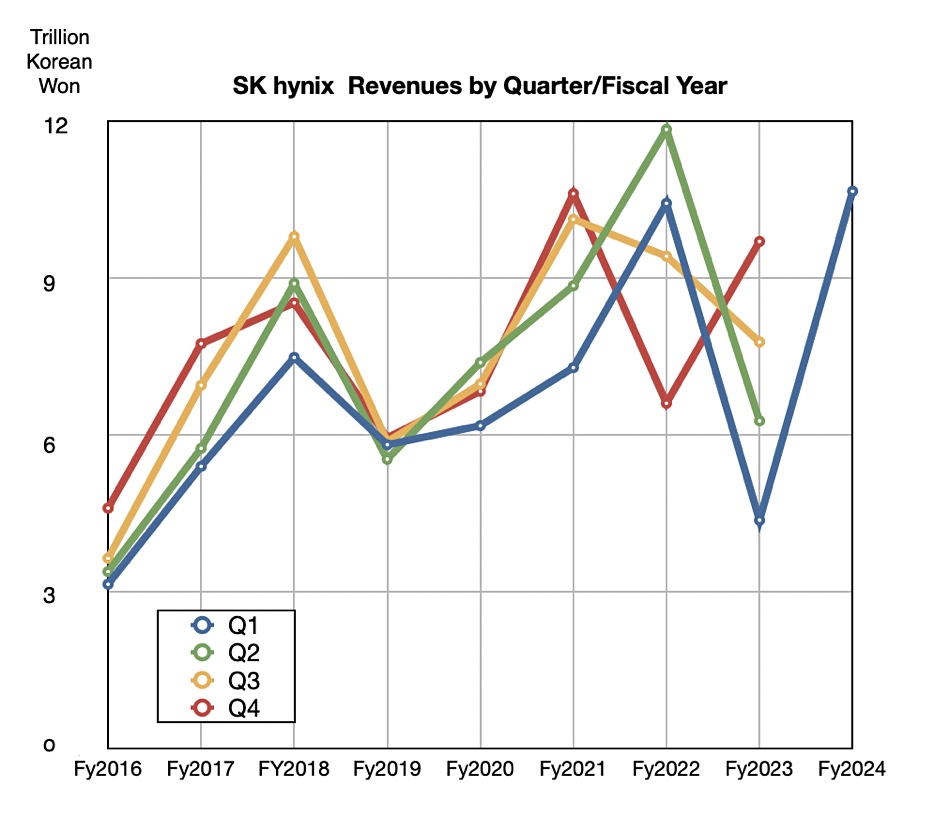
SK hynix saw first 2024 quarter revenues soar 144 percent as demand for high-bandwidth memory (HBM) chips rocketed.
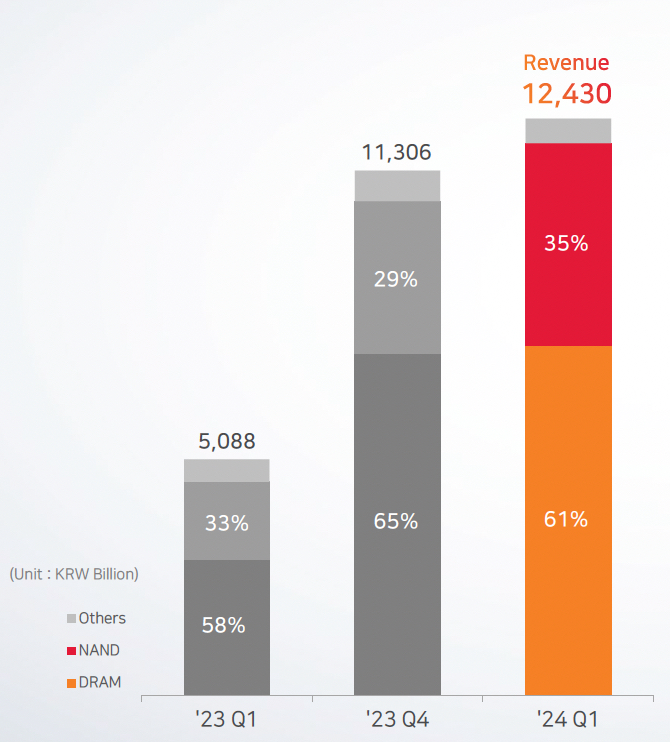
The DRAM and NAND manufacturer reported ₩12.43 trillion ($9.03 billion) in revenues with a ₩1.92 trillion ($1.4 billion) profit compared to last year’s ₩2.6 trillion ($1.9 billion) loss. This was a record first quarter revenue amount. DRAM accounted for 61 percent of its revenue and NAND 35 percent, with the remainder coming from other activities.
If this growth trend continues, SK hynix will have record revenues in Q2
CFO Kim Woohyun said: “With the industry’s best technology in the AI memory space led by HBM, we have entered a clear recovery phase.”
It attributed the rise to demand for its HBM in GPU-powered AI servers, with the GPUs needing HBM rather than x86 server-style socket-attached DRAM.
SK hynix product revenue splits and growth
In order to keep the GPUs busy, more memory bandwidth and capacity is needed than can be supported by the socket-attach method, which connects planar (single layer) DRAM to CPUs. HBM is built up from multiple layers – 4, 8, or 12-high – with a more direct connection to GPUs providing the needed capacity and bandwidth.
According to Reuters, HBM chips now account for 15 percent of the general memory market, compared to 8 percent last year. SK hynix has the largest market share in the HBM market, where demand has skyrocketed due to the generative AI boom fueling demand for Nvidia GPUs. It is the sole supplier of HBM3 memory to Nvidia, which has 80 percent of the AI GPU market, and started mass-producing the latest generation HBM3E generation in March.
Competing suppliers such as Micron and Samsung are developing their own HBM products to stop SK hynix dominating the market.
For example, Micron said in February that it would build 24 GB HBM3E, with 8 x 3 GB stacked DRAM dies, for use by Nvidia in its H200 Tensor Core GPUs shipping this quarter. It also started sampling a 36 GB 12-high HBM3E product in March. Samsung announced its own 12-high, 36 GB HBM3E device earlier this year.
Looking ahead, Micron is developing an HBM4 product, with 12 or 16 decks, meaning 36 GB or 48 GB capacity, and a >1.5 TBps data rate. HBM3E data rates are in the 1.2 TBps area. SK hynix has signed an MOU with TSMC for HBM4 development and its next-generation packaging technology.
It predicts that the general memory market will follow a steady growth path in the coming months as HBM demand continues to rise and the conventional DRAM market begins to recover in the second half of the year. New technology DRAM will be introduced, specifically 32 GB DDR5 chips built with the 1bnm process
SK hynix said that its premium or eSSD sales also rose. This, along with price rises, sent SSD revenues up as well. The company said it will “aggressively increase” its own 16-channel and Solidigm business unit’s QLC-based eSSD sales. SK hynix will also launch a new generation of capacity SSDs for the AI market.
It sees DRAM and NAND demand rises in its three main market areas: PCs, mobile phones, and servers. PC market recovery is expected in the second half, driven by enterprise demand due to the ending of Windows 10 support and AI PCs prompting an installed base replacement. The smartphone market should also see more memory shipments in the second half as phones get AI apps.
In the server area, demand is divided between AI (GPU) servers and ordinary (x86) servers. AI server demand is high due to GenAI and general or datacenter server replacement coming as servers from 2017/2018 reach end of life. Both AI servers and x86 servers will need SSDs to store data for GenAI training and inferencing needs. It plans to launch PCIe gen 5 SSDs later this year for use in AI PCs.
SK hynix is investing in new chip building capacity both in Korea and the US. The new M15X foundry in Korea should be ready by November 2025 and will focus on HBM production. It’s also building an advanced packaging plant in Indiana, with production scheduled to start in 2028. Having gained an HBM market advantage, SK hynix will be reluctant to give it up.
Western Digital’s third quarter results were boosted by a strong rise in disk revenues along with increased demand for SSDs.
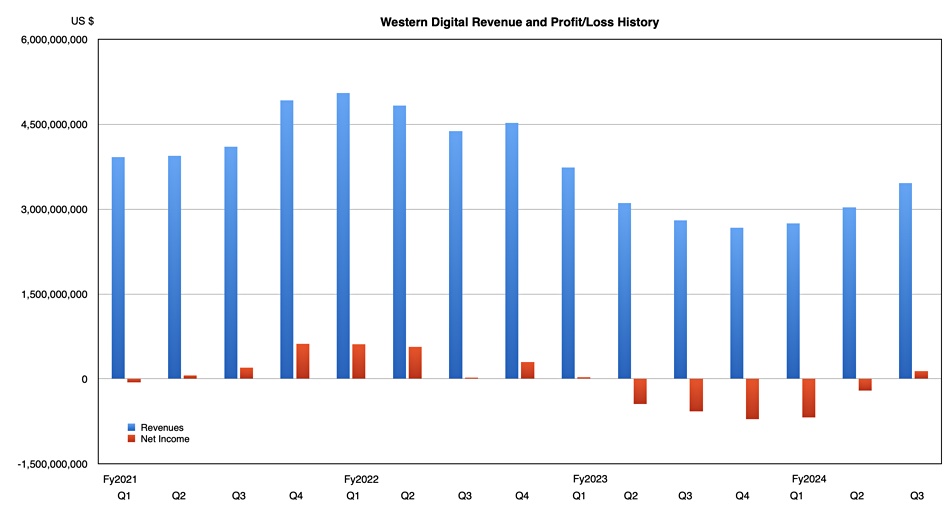
Its revenue slump is ending. Earnings in its third fy2025 quarter rose 29 percent year-on-year to $3.46 billion, beating its $3.3 billion outlook, and it made a $135 million profit, after five consecutive loss-making quarters.
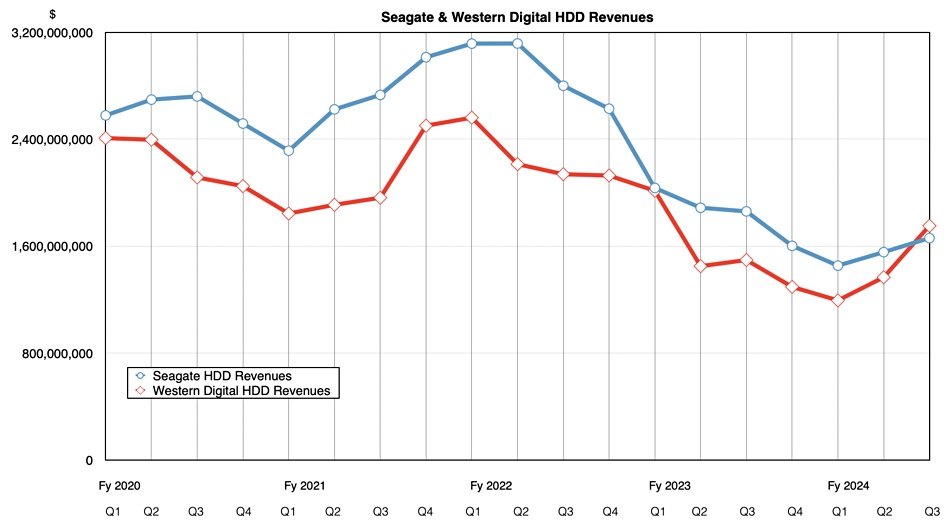
This contrasts with HDD maker rival Seagate where revenues of $1.66 billion were down 11 percent year-on-year with a $25 million profit. WD made $1.75 billion in disk revenues, overtaking Seagate after years of playing second fiddle. Seagate’s bet on HAMR technology is not, so far, paying off.
WD CEO David Goeckeler said in prepared remarks: “As evidenced by our excellent third quarter results, Western Digital continues improving through-cycle profitability and dampening business cycles by leveraging our strategy of developing a diversified portfolio of industry-leading products across a broad range of end markets.”
Financial Summary
Gross margin: 29 percent vs 29.3 percent a year ago
Operating cash flow: $58 million vs -$110 million a year ago
Free cash flow: $91 million
Cash & cash equivalents: $1.9 billion
EPS: $0.34 vs $0.63 last year
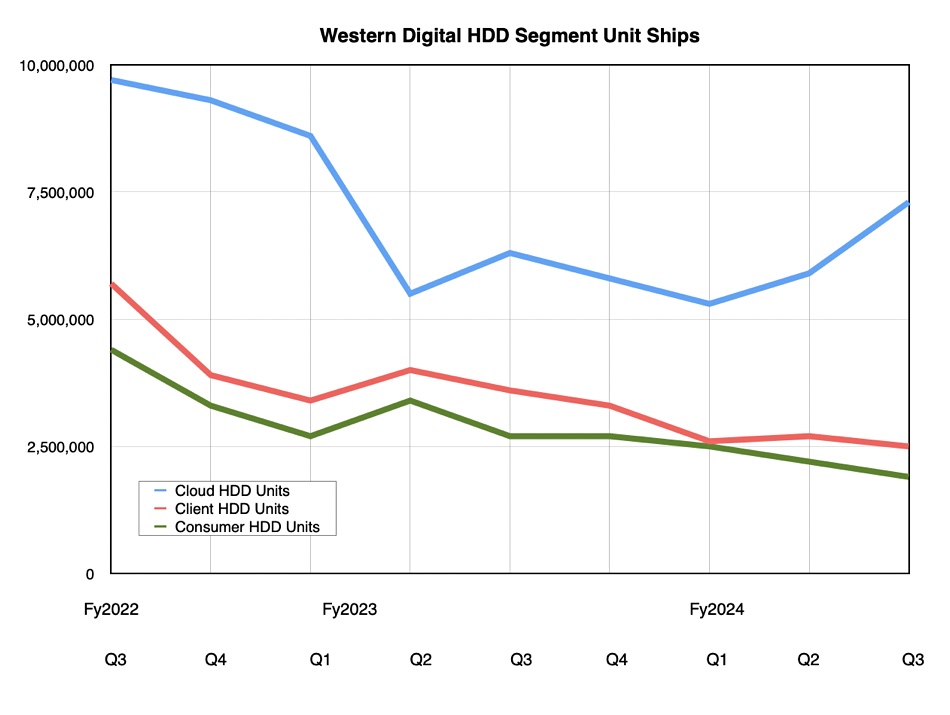
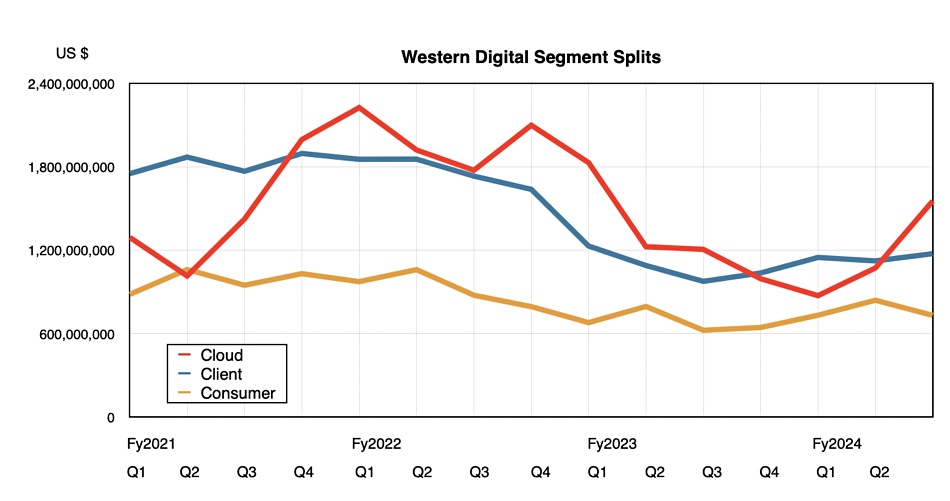
Flash revenues were $1.7 billion, up 30.5 percent annually, while disk revenues of $1.75 billion rose 17.1 percent annually and overtook the SSD earnings after three lagging quarters. Nearline drive revenue reached a six-quarter high point. HDD exabyte shipments increased 41 percent quarter-on-quarter and the average HDD selling price increased from $109.00 a year ago to $145.00.
Disk units totalled 11.7 million, down 7.1 percent annually but the second consecutive quarterly rise. Cloud buyers bought 7.3 million drives, 15.9 percent more than a year ago, while there was a 30.7 percent Y/Y drop in client drive (non-cloud OEM and enterprise) units to 2.5 million and a 29.6 percent drop in consumer drive shipments to 1.9 million. Cloud buyers bought 62 percent of WD’s disk drives in the quarter and represent its largest unit shipment and HDD revenue market. Gpesckeler said the quarter saw WD’s largest HDD sequential exabyte growth in some time.
Two of the three main market segments were affected by rising HDD demand while all three were affected by SSD revenue rises:
Cloud (up 29 percent to $1.56 billion) was 45 percent of total revenue with growth primarily attributed to higher nearline shipments, improved nearline unit pricing, and flash revenue up both sequentially and year-over-year.
Client rose 20 percent annually to $1.17 billion and was 34 percent of total revenue. Sequentially, the increase in flash ASP more than offset a decline in flash bit shipments while HDD revenue decreased. The year-over-year increase was driven by growth in both flash and HDD ASPs and flash bit shipments.
Consumer at $730 million was up 17 percent annually and represented 21 percent of total revenue. Sequentially, both flash and HDD were down at approximately similar rates and in line with seasonality. The year-over-year increase was driven by growth in flash bit shipments and ASP.
Earnings call
The earnings call saw an anodyne comment about the looming separation of WD’s disk and NAND/SSD businesses by Goeckleler: “I am proud of the team’s ongoing efforts as we drive toward completion of the separation in the second half of the calendar year. We remain focused on achieving the separation as soon as possible, and we’ll continue to provide further updates on our progress as appropriate.” But he couldn’t really say anything else.
David Goeckeler
He commented on the flash market: “We are seeing demand returning for NVMe SSDs that we qualified before the downturn. We are also experiencing significant interest in providing these products in dramatically higher capacities for AI-related applications, which we expect to ship in the second half of the year.” WD currently ships DC SN640 TLC PCIe gen 3 SSDs with up to 30.72 TB capacity and PCIe gen 4 SN650 and 655 drives with 15.36 TB. We now expect 60 TB SSDs to be announced by WD later this year, with Goeckeler saying customers: “want them in much bigger capacity points, 30 and 60 TB capacity points.”
SMR drives are being adoped by hyperscalers, with Goeckeler saying: “Our cloud customers continue to transition to SMR with our 26 TB and 28 TB UltraSMR drives, quickly becoming a significant portion of our capacity enterprise exabyte shipments. SMR-based drives represented approximately 50 percent of nearline exabyte shipments in the quarter.”
He reckons: “Our portfolio strategy to commercialize ePMR, OptiNAND, and UltraSMR technologies in advance of our transition to HAMR, has proven to be the winning strategy and enables us to deliver to customers the industry’s highest capacity and leading TCO drives.” It’s certainly led to WD’s disk revenues overtaking those of Seagate.
HAMR is on WD’s roadmap; Goeckeler saying: “The right time for HAMR is at 40 terabytes. And we’ve got a lot of development going on that product. … [We] have a lot of confidence in our HAMR development. And quite frankly, our customers know exactly what we’re doing, and where we’re at, and what our plans are, and they’re comfortable with that as well.”
Seagate is planning on launching its 40 TB HAMR drives in the second half of calendar 2025.
Flash killing disk
Goeckeler was asked about SSDs cannibalizing the HDD market, as Pure Storage has proposed. This is how he responded: “We do not see any cannibalization. Clearly, HDD plays a big role in the AI storage life cycle as well as the whole ingest phase, because all of the big data lakes and all of the raw data sets; those are all going to be stored on HDD. It’s just the economics of where you store that data, and how do you access that data. It’s all that part of the AI pipeline, if you will, is going to be HDD.”
And SSD’s role: “Now, you have all of these other new use cases around training and inference, and those are all going to be SSDs. So, it’s really about growth as opposed to substitution. And that’s what’s so exciting about this. And obviously, once you get the models trained, then the models are going to turn out more data, which is going to be stored on HDD.”
He emphasized this: “You’ve got this virtuous cycle going. So, it’s kind of literally rising tide lifts all boats. It’s not a substitution game.” Basically Pure Storage is wrong.
WD expects fourth fy 2024 quarter revenues to be in the range of $3.6 billion to $3.8 billion. The $3.7 billion mid-point would represent a 38.8 percent annual increase, making for a $12.94 billion full year; a 4.8 percent rise on fy 2023.
Object First, the developer of a “ransomware-proof” backup storage appliance, purpose-built for Veeam, has named its first channel partner for the UK market.
Object First offers its Ootbi (Out-of-the-Box-Immutability) appliance – with zero access to root – and Vitanium will be the first company to sell it in the UK.
Object First Ootbi appliance
Ratmir Timashev and Andrei Baronov, Veeam’s original founders, launched Object First in 2022, to provide on-premises object storage backup for Veeam workloads.
Insight Venture Partners invested $500 million into Veeam in January 2019. Veeam was then acquired by Insight for around $5 billion a year later.
The Ootbi appliance is aimed at mid-sized Veeam customers, and can be “racked, stacked, and powered in 15 minutes,” says Object First. The device is accessed using Amazon’s S3 protocol.
With over 20 years of experience selling business backup solutions, Object First says its new channel partner is well positioned to support its growth strategy in the UK market.
With a team of certified Veeam engineers, and ISO 27001/ISO 9001 accredited data backup services, Vitanium offers secure data protection services to MSPs, enterprise customers and other users in various sectors.
“As one of the largest markets in Europe for Veeam, the UK presents a significant growth opportunity for us,” said Mark Haddleton, EMEA channel sales director at Object First. “We are partnering with Vitanium, a company known for its expertise in data protection and strong partnership with Veeam.”
Paul Houselander, technical director at Vitanium, added: “In response to the ever-present threat of ransomware, there’s a notable shift in customer preference for data protection solutions that are both highly effective and easy to manage.
“Our search for a solution prioritised ease of deployment, secure and immutable storage capabilities, scalability, and the ability to handle modern workload demands efficiently. With its tight Veeam integration, opting for Ootbi enables our customers to safeguard their backups with on-premise immutable object storage.”
Earlier this week, Veeam announced the acquisition of Coveware, a provider of cyber-extortion incident response services. The capture, for an undisclosed sum, adds improved ransomware recovery and first responder capabilities to Veeam’s portfolio of services.
According to analyst house IDC, in the very crowded global data replication and protection market, Veeam is the market leader with a 13.1 percent share. It is followed by Dell Technologies on 11.9 percent. Next up is Veritas on 8.8 percent, and IBM with 8.3 percent. Completing the top five is Commvault with 6.4 percent.
Cohesity is currently in the process of buying most of the operations of Veritas, so may well break into IDC’s top five in the future.
Kioxia America has launched the latest generation of its Universal Flash Storage (UFS) embedded flash memory devices, designed to maximise 5G application performance.
Supported in capacities of 256 GB, 512 GB, and 1 TB, the new version 4.0 products are suited for leading-edge smartphones and other devices.
UFS is a class of embedded memory product built to the JEDEC UFS standard specification. Due to its serial interface, UFS supports full duplexing, which enables both concurrent reading and writing between the host processor and UFS device.
Kioxia says the new offering provides “optimal utilization” of 5G connectivity, resulting in accelerated downloads, minimized latency, and an enhanced user experience. A smaller package size – around 18 percent smaller – when compared to the last version also contributes to board space efficiency and design flexibility.
Version 4.0 devices integrate the company’s BiCS FLASH 3D flash memory and a controller in a JEDEC standard package. They incorporate MIPI M-PHY 5.0 and UniPro 2.0 technology, and support theoretical interface speeds of up to 23.2 Gbps per lane, or 46.4 Gbps per device. UFS 4.0 is backward compatible with UFS 3.1.
Compared to the previous generation 512 GB offering, the read/write speed improvement is +15 percent sequential write, +50 percent random write, and +30 percent random read.
“The newest generation of our UFS 4.0 devices is testament to our commitment to continually push performance boundaries, and make improved user experience a reality,” said Maitry Dholakia, vice president of the memory business unit at Kioxia America.
Sample shipments for the 256 GB and 512 GB products started this month, with the 1 TB offering following in June 2024.
Kioxia America is a subsidiary of Kioxia Corporation, the global supplier of flash memory and solid-state drives (SSDs). Kioxia Corporation is 56.24 percent owned by a Bain Capital-led private equity consortium, and 40.64 percent owned by Toshiba.
Last week, Kioxia Europe unveiled its EXCERIA G2 SD memory card series, offering capacities of up to 1TB. The “next gen” products are designed for long-time 4K video recording, for instance, and have an improved read speed of up to 100 MB/s, and a write speed of up to 50 MB/s.
Kioxia is reportedly preparing an IPO to recapitalize itself as a loan payment of ¥900 billion ($5.8 billion) becomes due in June.
Data connector company CData Software has appointed of Adam DeMichele as its CRO, Marie Forshaw as SVP of Product Marketing and Arielle Daigle as VP of Growth & Demand Generation. Amit Sharma, CData co-founder and CEO, said: “Our newest GTM executives come with proven track records of delivering customer growth and customer success initiatives at a massive scale.” DeMichele joins CData from Bitsight, a prominent Cyber Risk Management company. Forshaw was the first VP of Marketing at Apprentice.io, a life sciences manufacturing platform. Daigle previously led demand generation efforts at SmartBear, a provider of software development tools.
…
Graid Technology has a new software release, SupremeRAID v1.6, for its Supreme RAID card. It addresses data integrity issues associated with double failures in RAID configurations. A double failure occurs when a RAID system experiences a power outage or an unclean shutdown during the rebuilding of data from a previous disk failure. With v1.6, a distributed journal feature is designed to eliminate this single point of failure and significantly improve performance bottlenecks by distributing data and parity across all disks in a RAID group and redundantly journaling to provide maximum RAID stability with minimal impact on overall system performance.
…
HighPoint says its Rocket 1608A NVMe Switch AIC is the first in the industry to deliver 56 GBps transfer speed and 64TB of storage on Intel and AMD desktops. It’s compatible with Intel 600/700 and AMD X670E systems, supports up to eight M.2 SSDs without compromising performance, due to independent PCIe switching technology with built-in bifurcation. It supports PCIe gen 4 and 5 media by using Broadcom’s 48-lane PCIe Gen5 Switch ICs. Find out more here.
…
IBM’s Q1 fy2025 revenues were $14.5 billion, up 1% Y/Y. There was a $1.6 billion profit, up 73%. IBM is buying HashiCorp and its infrastructure management and security software for $6.4 billion. Infrastructure segment revenues were $3.1 billion, down 1%, wih revenues benefitting from AI across IBM Z mainframes and storage. We’re told the distributed infrastructure performance reflected strength in Power servers and storage.
…
iXsystems announced the production release of TrueNAS SCALE 24.04 alongside its new series of hybrid storage appliances, the TrueNAS Enterprise H-Series. TrueNAS 24.04 introduces SMB and Admin auditing, and the Enterprise support of Restricted Admins and Immutable Snapshots. It has a simplified and improved Share Creation workflow, and open client SMB and NFS file sharing protocol sessions can be managed from the TrueNAS web UI.
The 2RU H-Series is for cost-optimized workloads at the edge or data center. The H10 is available now with the H20 coming later. The boxes have optional 24, 60, or 102-bay expansion shelves and can grow from 20TB all-flash to 2PB hybrid storage. They have a high-availability dual-controller architecture proving 99.999 percent uptime. Find out more here.
…
Mainframe migrator Mechanical Orchard has appointed Edward Hieatt to Chief Customer Officer, with him having been a part-time advisor from March last year. He joined Pivotal Labs in 2003 and became SVP for Customer Success in 2015. CEO Rob Mee founded and was the CEO of is Pivotal. Hieatt joined VMware in 2019, overseeing Customer Experience and Success at VMware Tanzu, and became an advisor to Mechanical Orchard in March 2023.
…
Micron has signed a non-binding Preliminary Memorandum of Terms (PMT) for $6.1 billion in funding under the CHIPS and Science Act to support planned leading-edge memory manufacturing in Idaho and New York. The grants will support Micron’s plans to invest approximately $50 billion in gross capex for U.S. domestic leading-edge memory manufacturing through 2030. These grants and additional state and local incentives will support the construction of one leading-edge memory manufacturing fab to be co-located with the company’s existing leading-edge R&D facility in Boise, Idaho, and the construction of two leading-edge memory fabs in Clay, New York. It envisages a four-fab manufacturing complex in Clay, New York to be built over the next 20-plus years.
…
Carahsoft will serve as a Federal Distributor for Quantum, making the company’s cutting-edge end-to-end data solutions available to the Public Sector through Carahsoft’s reseller partners and GSA Schedule, NASA Solutions for Enterprise-Wide Procurement (SEWP) V, Information Technology Enterprise Solutions – Software 2 (ITES-SW2), National Association of State Procurement Officials (NASPO) ValuePoint, OMNIA Partners, E&I Cooperative Services Contract and The Quilt contracts.
…
Renesas Electronics Corp has developed circuit technologies for an embedded spin-transfer torque magnetoresistive random-access memory (STT-MRAM) test chip with fast read and write operations. Fabricated using a 22-nm process, the microcontroller unit (MCU) test chip includes a 10.8-megabit (Mbit) embedded MRAM memory cell array. It achieves a random read access frequency of over 200 MHz and a write throughput of 10.4-megabytes-per-second (MB/s).
…
Rubrik IPO’d at $32/share, higher than its initial $28 to $31 range, with 23.5 million shares on offer, implying gross proceeds of $752 million and a valuation of $5.6 billion. The IPO will formally close on April 29, 2024, subject to customary closing conditions, and Rubrik will trade on the NYSE under the symbol RBRK.
…
Samsung has begun mass production for its one-terabit (Tb) triple-level cell (TLC) 9th-generation vertical NAND (V-NAND or 3D NAND), with 286 layers according to the Nikkei, not 290 as we initially thought. Sammy claims this has the industry’s smallest cell size and thinnest mould, and improves the bit density by about 50 percent compared to the 8th-generation V-NAND with its 236 layers. It says cell interference avoidance and cell life extension enhance product quality and reliability, while eliminating dummy channel holes has significantly reduced the planar area of the memory cells.
Gen 9 V-NAND uses 2-string stacking, with 2 x 143 decks, and has the industry’s highest cell layer count in such a structure. It has a Toggle 5.1 interface, supporting up to 33 percent increased data IO speeds to 3.2 Gbps (Gen 8 V-NAND – 2.4 Gbps) and 10 percent lower power consumption, compared to Gen 8 V-NAND. QLC gen 9 V-NAND mass production will start in the second half of 2024.
…
SK hynix intends to build a new DRAM chip foundry in South Korea costing ₩5.3 trillion ($3.86 billion). This M15X foundry should be ready by November 2025 and will focus on HBM production.
…
Western Digital has an Ultrastar Transporter offering, a small roll along-sized case with a small rackmount server and all-flash storage array inside. It has a 12-core Ice Lake 4320 Xeon processor, 128 GB DRAM, 2 x 200 GbitE ports, 7 x PCIe Gen 4 slots, and 368 TB of SSD capacity. The idea is to provide physical storage transfer with high-speed data ingest and egress. You load up the server with data, extract it from the rack, whack it in the case and transport it and yourself to a destination with a waiting rack to receive the server and offload its data. Think of it as the world’s heaviest notebook computer.
…
SW RAID shipper Xinnor is partnering HPC and AI systems integrator Versatus HPC in Brazil to supply its xiRAID software to academic and corporate HPC and AI environments.
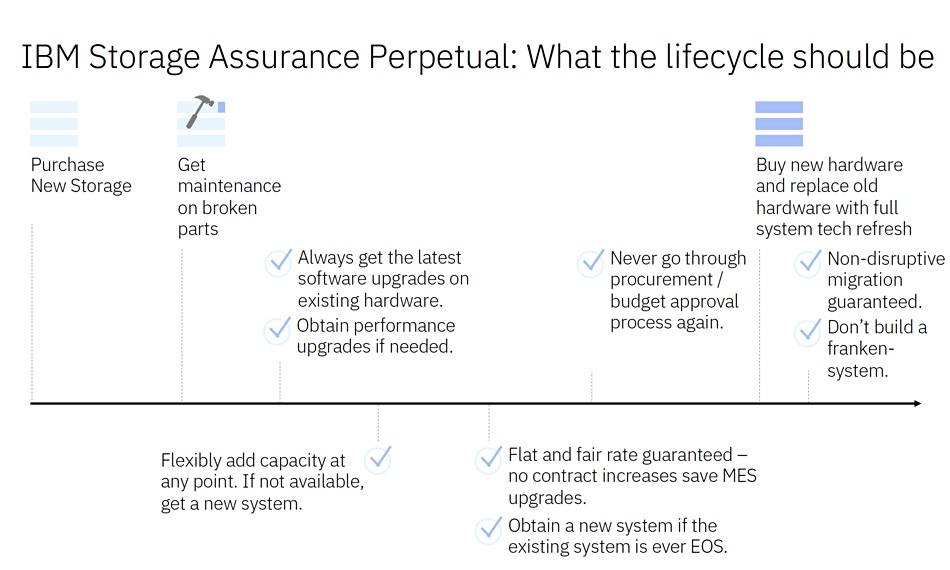
The latest IBM FlashSystem 5300 array has a PCIe 4 bus, computational drives, and Ice Lake CPUs, accompanied by a Storage Assure scheme to upgrade hardware and software during the life of a system.
Similar to Pure’s 2015 Evergreen program, Storage Assurance is a customer subscription with regular drive and controller hardware and software refreshes plus premium-level Expert Care support to keep storage infrastructure up to date without downtime, disruptive migrations, and recurring purchases. It works with the FlashSystem 5300, 7300, and 9500 but not the non-NVMe drive 5015 and 5045 arrays.
Denis Kennelly, IBM Storage General Manager, said: ”IBM Storage Assurance challenges the status quo of enterprise storage with a program that delivers client focused guarantees, computational storage with AI-powered data services, and an all-inclusive software integration designed to address customers’ most pressing problems, including a path for them to adopt future innovations from IBM.”
The Storage Assurance hardware and software upgrades are covered by SLAs and a flat pricing contract with four and eight-year terms. Clients can easily increase capacity by adding as few as just one additional drive at a time. Customers can receive a trade-in credit for out-of-cycle upgrades.
FlashSystem 5300
IBM says its latest FlashSystem array has a number of enhancements, including the latest gen 4 FlashCore Modules (FCMs), IBM’s proprietary flash drives with computational storage. This means onboard compression and encryption, and firmware-based real-time detection of ransomware and other attacks using machine learning. The vendor claims FCM 4s keep detailed statistics about every IO in real time, and the firmware uses machine learning models to distinguish ransomware and malware from normal behavior.
The FCMs use 176-layer TLC NAND chips and have 4.8, 9.6, 19.2 and 38.4 TB capacities. The built-in compression increases effective capacity by up to 2.3 times, meaning 14.4, 28.8, 57.6, and 115 TB capacities respectively. A FlashSystem 5300 with 12 gen 4 FCM drives can have 1 PB or more of effective capacity.
The 5300 comes in a 1RU chassis and uses a PCIe gen 4 bus, twice as fast as the PCIe gen 3 bus used in the 2RU FlashSystem 5200 array, which it supersedes. It accompanies the higher-end 7300 and 9500 FlashSystems. The 5300 supports 2 x 4-port 32 Gbps Fibre Channel HBAs or 2 x 2-port 64 Gbps HBAs. There are onboard 10/25 GbE ports for IO and replication without consuming an HBA slot.
The 5300’s 400,000 IOPS and 28 Gbps bandwidth are 1.45x and 1.3x greater respectively than the 5200’s performance in half the physical size.
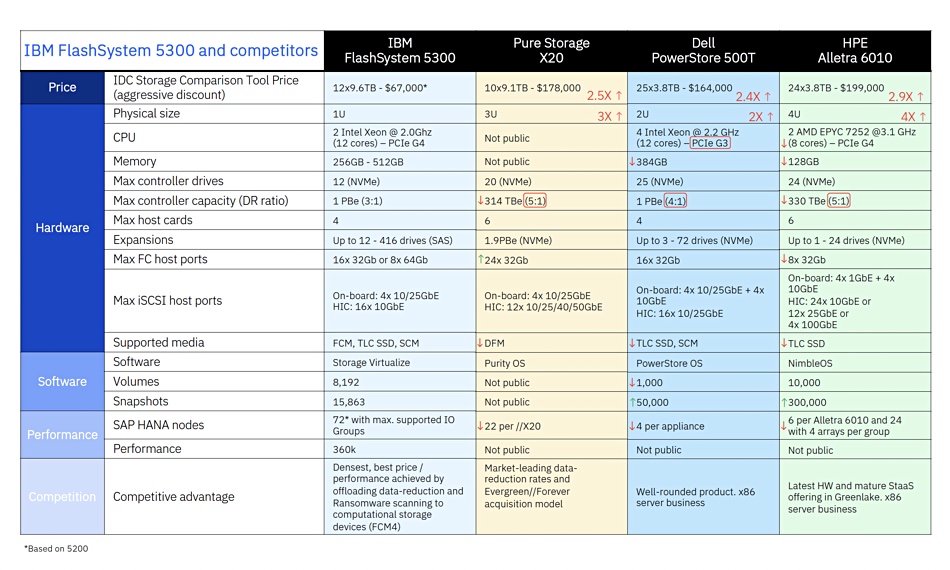
Using data from an IBM TechXchange community presentation (login required), we see that the 5300 has a $67,000 base price. Dell’s PowerStore 500T, Pure Storage FlashArray//X20, and HPE Alletra 6010 are 2.4 to 2.9 times more expensive, based on IDC pricing data.
This presentation has a neat competitive comparison table for you to inspect:
Flash Grid
Today’s Big Blue news blast also has Flash Grid technology and Policy-Based High Availability aspects. Flash Grid enables customers to manage storage systems as a highly available and independently scalable environment, from a single control pane, with the ability to move workloads between FlashSystems.
Customers can aggregate IBM FlashSystem devices and manage them as a single scalable storage grid, with high-availability, replication, and non-disruptive app data migrations. They can use AIOps and AI-powered workload simulation to determine the best placement for workloads on the Flash Grid.
FlashSystem policy-based replication and high availability for disaster recovery enables the system to automatically deploy and manage replication between two systems with minimal overhead, higher throughput, and lower latency.
Later this year IBM intends to extend this with with replication to a third system, and simplify the tasks associated with configuring, managing, and monitoring replication.
IBM’s Storage Assurance program and the FlashSystem 5300 are now generally available. Learn more about IBM Storage Assurance here and the IBM FlashSystem 5300 here.
Veritas has revealed that its NetBackup and Alta Data Protection products include defence against threats from compromised user credentials. An Alta Copilot can also be conversationally guided to identify cyber vulnerabilities and operational inefficiencies, proactively assist with troubleshooting, and guide users through complex data management tasks.
The company’s Alta Cloud is a secure data management platform composed of multiple Veritas products, such as NetBackup, Enterprise Vault, and the cloud-native Alta Data Protection. It has an extensible architecture, called Veritas 360 Defense, with three focus areas: data protection, data governance, and data security. A number of partners work with Veritas in a 360 Defense ecosystem, such as CrowdStrike, CyberArk, Microsoft, Qualys, Semperis, and Symantec (Broadcom), and all offerings are certified and validated in the Veritas REDLab facility.
Richard Wainwright
Veritas UK&I Field CTO Richard Wainwright said: “Ransomware attacks are changing and using more AI-driven methods to attack the humans operating the systems, to corrupt backup data using the stolen credentials of administrators.”
He claims: “By using AI to fight against AI, this new solution is the industry’s first self-learning behavior monitoring solution that makes it possible for businesses to detect and respond to threats faster and, in turn, boost their cyber resiliency.”
NetBackup and Alta Data Protection will, as well as detecting anomalies in admin user behaviors, automatically flag unusual admin behavior and autonomously adjust security parameters, such as multi-factor authentication and multi-person authentication, to lock down access to data and protect it against attacks.
The Alta AI Copilot part of Veritas’s announcement gives general-purpose admin staff better facilities to use the Veritas data management environment. It is a large language model (LLM) that has been trained with Veritas’s best practices and product documentation. By using this, IT generalist admins can, Veritas says, attain the skill levels of highly specialized Veritas experts. The customer can thus obtain optimal performance from their Veritas infrastructure.
There are five new 360 Defense partners, including Securonix, to help provide increased threat monitoring, protection, and recoverability. Veritas says Securonix is a leader in next-generation security information and event management, user and entity behavior analytics, and security orchestration automation and response.
Mark Stevens, global VP of channels and alliances at Securonix, said: “With Securonix joining the Veritas 360 Defense ecosystem, Veritas customers will be able to easily access an early warning from our AI-powered detection solution that stolen credentials are being used across a wide range of other applications. This will enable them – or their Veritas AI tools – to trigger enhanced security measures for their protection environments before they’re compromised.”
The other four new partners have not been named. As Cohesity is buying the bulk of Veritas’s data protection and management products, it will inherit the self-defending NetBackup and Alta products, the 360 Defense ecosystem, and AI Copilot.
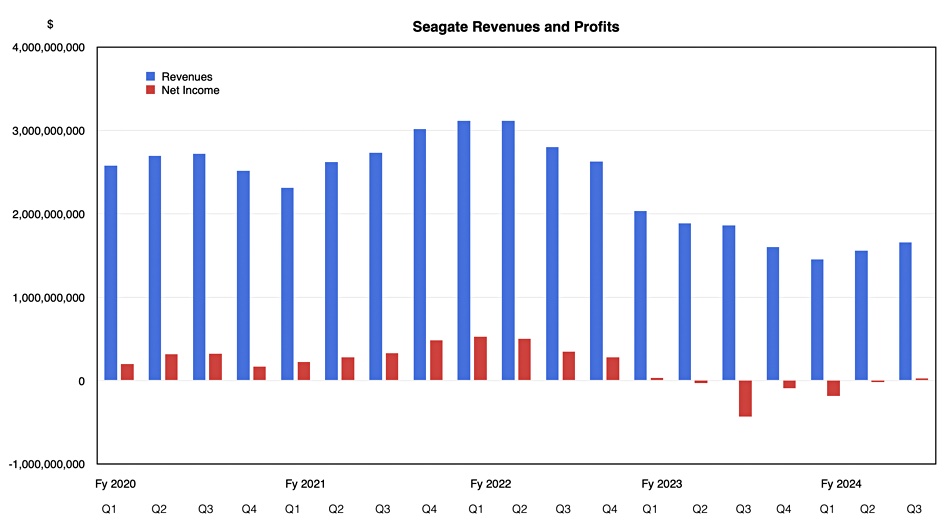
Disk drive supplier Seagate reported its first profit after five consecutive quarters of losses as major buyers upped their nearline high-capacity drive orders. Broadcom has acquired its ASIC assets, including development engineering and related IP, for $600 million in cash.
Although revenues of $1.66 billion beat last quarter’s $1.65 billion guidance, they were down 11 percent year-on-year, with a $25 million profit, just 1.5 percent of its revenues, contrasting with the year-ago $433 million loss. It made $1.18 billion from high-capacity drives (down 4.3 percent year-on-year), $297 million from legacy drives (down 20 percent), and $178 million from enterprise drive systems and SSDs (down 30.5 percent). Seagate shipped 99.1 EB of capacity, down 16.5 percent on the year, with an average of 8.7 TB per drive capacity, up 7 percent from 8.2 TB a year ago.
CEO Dave Mosley, focused on the quarterly picture, said: “Seagate’s March quarter revenue grew six percent and non-GAAP EPS more than doubled over the December quarter as we benefit from improving cloud demand, our strong operating discipline, and price execution. This combination sets the foundation for a return to target margin performance as the markets recover.”
Putting up its prices again, as it did yesterday, will certainly help improve margins.
Mosley said in the earnings call: “Nearline cloud demand trends are increasingly positive across both US and China customers, and we also saw a sequential improvement in the enterprise OEM markets in the March quarter … Cloud continues to lead the demand recovery … We believe the long-running cloud customer inventory correction is mostly complete and their end demand is also improving.”
He added: ”We expect enterprise OEM revenue to improve as server growth resumes.” Seagate has better visibility of its large customer demand due to its build-to-order initiative that is now in place with the majority of large mass-capacity customers.
The cloud demand increase offset seasonally lower video surveillance market demand.
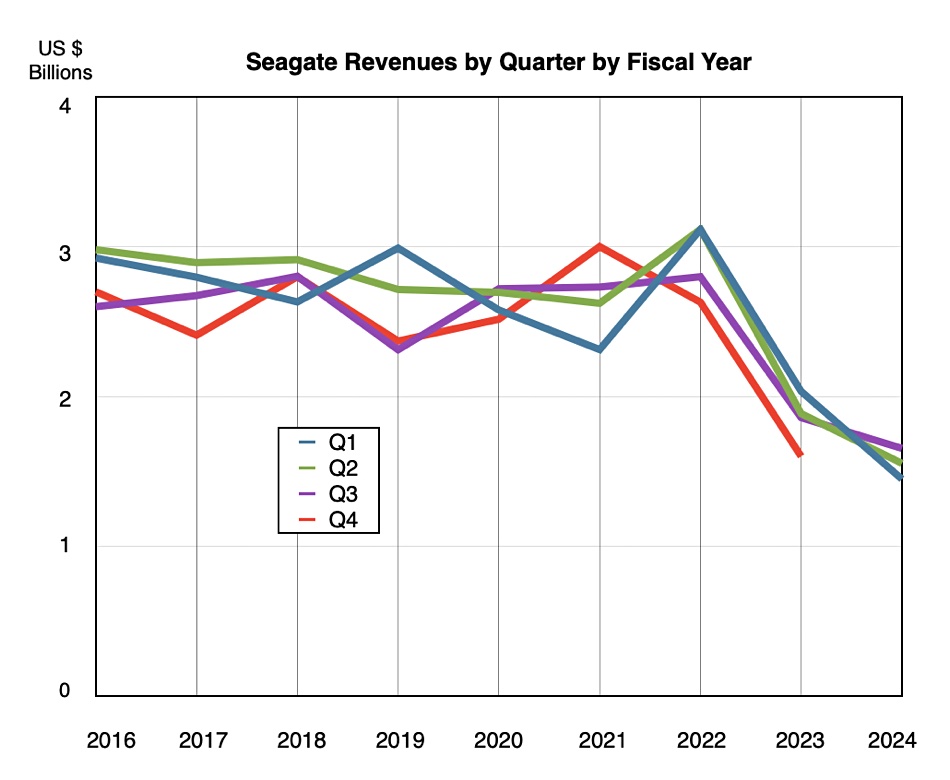
A chart of quarterly revenues by fiscal year shows a continuing downward trend:
The earnings recession has been deep and it will take a while for revenues to return to their FY 2016-2022 levels.
Qualification of its Mozaic 3 TB/platter HAMR drives is proceeding slowly. A lead cloud services provider qualification, where Seagate experienced a slowdown in recent weeks due to a non-HAMR, externally sourced, mechanical component failure, is expected in the current quarter, pending final test completion. A single top non-cloud customer has qualified the drives.
The qualification of its latest conventional PMR drives, at 24 TB and 28 TB SMR, is proceeding much faster. Mosley said they “are in qualification at most of our global cloud and enterprise customers. We have already completed qualification with one major enterprise customer, some global Tier 2 customers, and with our enterprise systems business.”
Seagate says prototype 4 TB/platter HAMR drives are now working with a launch set for the second half of calendar 2025. It claims there is a clear path to the gen 3 5 TB/platter HAMR drives, with 50-plus TB capacity.
Mosley said: “We are scaling drive capacity through aerial density gains rather than adding heads and disks … We believe HAMR provides the path for achieving margin performance beyond our current target range as production scales and also positions Seagate well to continue capitalizing on megatrends like AI and machine-learning, which drive long-term demand for cost-efficient mass storage.”
”Over the next several years, the volume of AI-generated content is expected to increase and also shift toward more imagery and videos, which can be up to 1,000 times larger than text. These trends bode well for HDD demand over the long term, as HDDs remain the most cost-effective means to house and subsequently use mass capacity data.”
In his view, there is no possibility of SSDs replacing HDDs, as Pure Storage claims will happen. Answering an analyst question, Mosley said: “This idea of mass capacity being in conflict with flash I don’t think is right. I don’t think that’s the way architects think about it in datacenters.”
“I don’t think that economically it makes sense. And even when you get into things like power and space, I think hard drives are going to stay very, very competitive on the workloads that they offer.”
Financial summary
Gross margin: 25.7 percent vs 17.2 percent a year ago
Diluted EPS: $0.12 vs -$2.09 last year
Operating cash flow: $188 million
Free cash flow: $128 million
Quarterly dividend: $0.70/share and $147 million total
Cash & cash equivalents at quarter end: $795 million
Principal debt: $5.7 billion
The outlook for the final FY 2024 quarter is for $1.85 billion revenues, give or take $150 million, which is a substantial 15.5 percent uplift on the year-ago Q4 at the midpoint. This outlook would make for $6.5 billion in FY 2024 revenues, again at the midpoint, 22 percent down on FY 2023.
Analysis. A conversation with Arun Gururajan, NetApp’s VP for research and data science and a GenAI expert, has shed light on the use of vector embeddings in chatbots for leveraging an organization’s proprietary textual data.
I had previously learned from DataStax and Barnacle.ai founder John-David Wuarin that this would be a time-consuming and computationally intensive task. Gururajan suggests that it is less time and compute-intensive than we might think. But there are nuances to bear in mind.
Let’s just set the scene here. Generative AI involves machine learning large language models (LLMs) being given a request. They operate on stored data and mount a semantic search of it to find items that correspond as much as possible to what it is looking for. The LLMs don’t understand – in a human sense – what they are looking for. They turn a request into vector embeddings – code strings or hashes for multiple dimensions of the request, then search a vector database for similar vector embeddings.
There isn’t a one-to-one relationship between words and vectors. Vectors will be calculated for tokens, parts of words, whole words or groups of words.
An organization will generally want the LLMs it uses to search its own proprietary data – retrieval-augmented generation (RAG) – to find the most relevant responses to employee requests. But that means the proprietary data needs vectorizing before it can be semantically searched. This background can be explored further here.
The data estate could involve, text, images, audio, and video files. The first pass general LLM usage will focus on text and that’s what we look at here.
Arun Gururajan
Gururajan and I talked in a briefing last week and he explained: “I come from Meta. I was leading applied research at Meta, where I was building all things from like multimodal deep learning models for fraud detection on Facebook, and Instagram, building all the search and personalization for Meta’s online store. And of course, solving their supply chain problems doing traditional optimization problems as well.
“Before that, I spent a while at Microsoft, where I led multiple teams on AI working on cyber security for Microsoft 365. And my Master’s and PhD were in computer vision. So I’ve been at this for about a couple of decades now.”
He made the point that an organization’s text-based data estate might not be as large as all that. “If you take Wikipedia, for example, which is a significant corpus of text representing most of the world’s knowledge, the textual form of Wikipedia is less than 40 gigabytes.”
That’s a surprise. I was thinking it amounted to tens of terabytes. Not so.
He noted my surprise: “A lot of people will give me the surprised look when I tell them, but if you take Wikipedia as just textual articles, it is less than 40 gigabytes … So most organizations, I would say 80 percent of the organizations, will have textual data that’s probably less than that.”
Pre-processing
You can’t just give this raw text data to an LLM. There will be pre-processing time. Gururajan continued: “Data can be in Word documents, it could be in PDF documents, it could be in HTML. So you need to have a parser that takes all those documents and extracts that text out. Once you parse out the text, you need to normalize the data. Normalization is like you might want to remove punctuation, you might want to remove capitalization, all of those things. And then you want to tokenize the words.”
Documents might need converting into sub-chunks. “For example, a HR document might contain something about finance, it may contain some other topics. Typically, you want to chunk the documents [and] the chunking process is also part of the pre-processing … The pre-processing does take a finite amount of time.”
Now we come to the next aspect of all this. “The third thing is the complexity of the embedding model. Because you need to take all those document chunks, and you want to convert that into a vector, and that’s typically done by an embedding model. And embedding models come across in a variety of sizes. If you look at Hugging Face [and its] massive text embedding benchmark leaderboard, you can see a list of embedding models which are on the leaderboard, and categorized by their size.
“You can look at models less than 100 million parameters, between 100 million to 500 million, up to a billion, and greater than a billion. Within each category, you can pick a model. Obviously, there are trade-offs, so if you pick a model with a huge computational footprint, computing the embedding – which means you are doing a forward pass on the model – is going to take more time.”
He explained a lot of the applications use very compact models – such as MiniLM, a distilled version of Google’s Bert model. This is fast and can convert a chunk to a vector in milliiseconds.
Another factor comes into play here. “The fourth thing is dimensionality of the embeddings. If you want the vector to be 380-dimensional? Great. If you want it to be 2,000 dimensional then you’re going to require more computation.”
If you choose a long vector, it means that you’re getting more semantic meaning from the chunk. However, “it really is a trade-off between how much you want to extract versus how much latency you want. Keep in mind that the vector length also impacts the latency the user faces when interacting with the LLM.”
He said lots of people have found a happy medium with the 384-dimensional vector and MiniLM, which works across 100 languages by the way.
Now “the embeddings creation for RAG is mostly like a one time process. So you can actually afford to throw a bunch of pay-as-you-go compute at it, you can throw a GPU cluster at it.” Doing this,”“I can tell you that the all of Wikipedia can be embedded and indexed within 15 minutes.”
The embedding job you send to a GPU farm needs organizing. “If you’re not thoughtful about how you’re batching your data and sending it to the GPU then you’re going to be memory bound and not compute bound, meaning that you’re not going to be using the full computational bandwidth of the GPU,” and wasting money.
Indexing
The next point to bear in mind is the index of the embeddings that an LLM uses. “When the user puts in a new query, that query is converted to a vector. And you cannot compute the similarity of the vector to all of the existing vectors. It’s just not feasible.”
So when selecting a vector database with in-built indexing processes, “you need to be smart about how you are indexing those vectors that you’ve computed … You can choose how you want to index your embeddings, what algorithm that you want to use for indexing your embeddings.”
For example, “there’s K nearest neighbor; that is approximate nearest neighbor.” The choice you make “will impact the indexing time. Keep in mind that vector indexing can also be done on a GPU, so if you’re going to throw compute at for the embedding, you might as well use the compute for indexing as well.”
What this comes down to in terms of time is that “for most enterprises, and I’m just giving a ballpark number, if they really throw high-end GPUs, they are really talking in the order of minutes, tens of minutes for embedding their data. If you’re throwing mid-size GPUs, like A10s or something like that, I would say you’re really talking about an order of a few hours for indexing your data.
“If you’re talking about hundreds of gigabytes of data, I would say it’s probable we are talking about a ten-hour time to indexing your entire data set.”
Up until now, this is all about RAG vectorization and indexing for text. It won’t stop there.
Multi-modal RAG
Gururajan continued: “The next evolution of RAG … is that there are going to be three different embedding models. There’s one embedding model that takes text and converts it to embeddings. There’s going to be another embedding model that either takes video or images and then converts that into embeddings. So those are two embedding models.
“Then there’s a third embedding model which actually takes these two embeddings, the text embeddings and the images beddings and maps it to a common embedding space. And we call this as contrastive learning.”
A V7 blog explains this “enhances the performance of vision tasks by using the principle of contrasting samples against each other to learn attributes that are common between data classes and attributes that set apart a data class from another.”
It adds time, as Gururajan explained: “When you’re thinking about three different embedding models, when you’re doing multimodal RAG, you might end up doubling the time it takes to generate the embeddings or slightly more than that … But it should not really be something that will take the order of days. It will probably be like a day to get everything set.”
An organization could hire a group of people to do this, but Gururajan thinks that won’t be the general pattern. Instead people will use tools, many open source, and do it themselves. He observed: “So many tools have come up that actually abstract out a lot of things. The whole of the field has become democratized.”
DIY or hire bodies?
“You take a tool, and it says these are all the ML algorithms, which ones do you want to run? It actually gives you a default selection. You almost get a Turbo Tax-like interface, you just click click, and you’re done building a model.”
He thinks the RAG area is at an inflexion point, with tools and optimizations appearing. “People are going to create open source and, in fact, they’ve already started coming out, open source RAG frameworks.”
These would “package everything for you, from data loaders to tokenizers to embedding models, and it makes intelligent choices for you. And obviously, they are going to tie it with the GPU compute and make it so that a good engineer should be able to use it end to end.”
We can envisage NetApp possibly making such frameworks available to its customers.
Hallucinations
Can RAG reduce LLM hallucinations? One of the characteristics of an LLM is that it doesn’t know it’s hallucinating. All it knows is what’s likely to follow a particular word in a string of text, based on probabilities. And the probabilities could be high, or they could be low, but they still exist. In Gururajan’s view: “LLMs are autoregressive machines, meaning they essentially look at the previous word, and then they try to predict the next one; they create a probability distribution and predict the next word. So that’s all there is to an LLM.
“There’s a lot of research going on in knowledge graphs that can augment this retrieval process so that the LLM can summarize it in a better manner.” The LLM uses a recursive chain of reasoning. “You have a chain of prompts that make the LLM look at the article again, and again, make it look at the document from different angles with very targeted prompts.”
This can help reduce hallucinations, but it’s not a cure. Gururajan asks: “Can we completely reduce hallucinations? No, I don’t think there’s any framework in the world that’s there yet that can claim zero hallucinations. And if something claims zero hallucinations, I would really be very wary of that claim.”
Veeam has acquired cyber-extortion incident response provider Coveware. We’re told Coveware has helped thousands of cyber extortion victims and developed software and services to enable rapid attack forensic triage, extortion negotiation and remediation, to help organizations recover their data from ransomware attacks.
Veeam CEO Anand Esware said in a statement: “It’s no longer a question of when your organization is attacked, but how often. Seventy-six percent of organizations have been attacked over the past 12 months, and addressing that cyber threat is critical for every enterprise.”
He added: “Coveware is already helping enterprises across the world improve their defense and if the worst happens, helping them recover. … Veeam now provides enterprise customers with proactive threat intelligence that helps identify any security gaps with forensic triage and decryption, all combined with the capabilities of the market leader.”
Bill Siegel.
Coveware was founded in 2018 in the NewYork area by CEO Bill Siegel and CTO Alex Holdman. Siegel said: “Our goal is to minimize the cost of disruption by providing best-in-class incident response tools and services. The threat intelligence gathered from our incident response work also benefits our proactive large enterprise clients – 41 percent of which are in the Fortune 500 – to reduce their risk and increase their resiliency.”
Siegel was CFO at cybersecurity company SecurityScorecard from 2016 to 2018. Prior to that he was the head of the NASDAQ private market after selling SecondMarket, where he was CEO, to NASDAQ. His background is in corporate finance, portfolio management, and equity research.
Holdman is an ex-product manager at Paperless Post and Datto, and worked at SecondMarket as a lead software engineer in 2011-2015.
Coveware chart
Siegel and Holdman said in a 2018 introduction to Coveware: “There is a stigma associated with paying a ransom. We expect criticism and scrutiny of our model. Coveware makes it easier for businesses to pay. Popular refrains involve a utopian vision of every afflicted business and person, ceasing to pay, and the problem disappearing for good. While we understand and appreciate these refrains, we deem the implementation unrealistic.”
They added: ”We also have no intention of profiting off of the payment of ransomware. In the future, we envision opening up Coveware case management as a public utility, so that any victim can have a clean experience without predatory fees, and our interested institutions, both private and public, can glean the insights they need to make a difference.”
Coveware has accumulated data and insights on miscreants patterns. This means it has access to continuously updated data on ransomware variants, attack vector analysis, attack footprints, and recovery options. It has automated SaaS technology that runs across a client’s operational environment to perform forensic triage analysis. The service assesses the impact, identifies the ransomware (strain, threat actor group, entry point), and helps recover encrypted data from known ransomware groups.
Veeam prides itself on the immutability of its backups, claiming they are safe from ransomware. With ransomware crews sometimes being present in a victim’s IT systems for up to 200 days, there is a risk that corrupted data could be inadvertently backed up. Asked about this in a briefing in London, Dan Middleton, Veeam VP for the UK and Ireland, told us Coveware’s services could help when data was exfiltrated.
Coveware is privately owned and there is no record of any outside funding. The acquisition price has not been revealed. LinkedIn lists around 25 employees and Coveware says it has a global team of cyber threat experts.
Coveware will operate as a fully owned Veeam business – Coveware by Veeam – and selected Coveware capabilities will be incorporated into Veeam’s products including Veeam Data Platform and the Veeam Cyber Secure Program. In effect, the Coveware tech now gets a market boost by using Veeam’s hundreds of channel partners. The acquisition may trigger acquisitions by competitors such as Rubrik.







 SK hynix's 128-Layer 1Tb TLC NAND Flash")