Quantum has added two all-flash appliances to its deduping backup target product set.
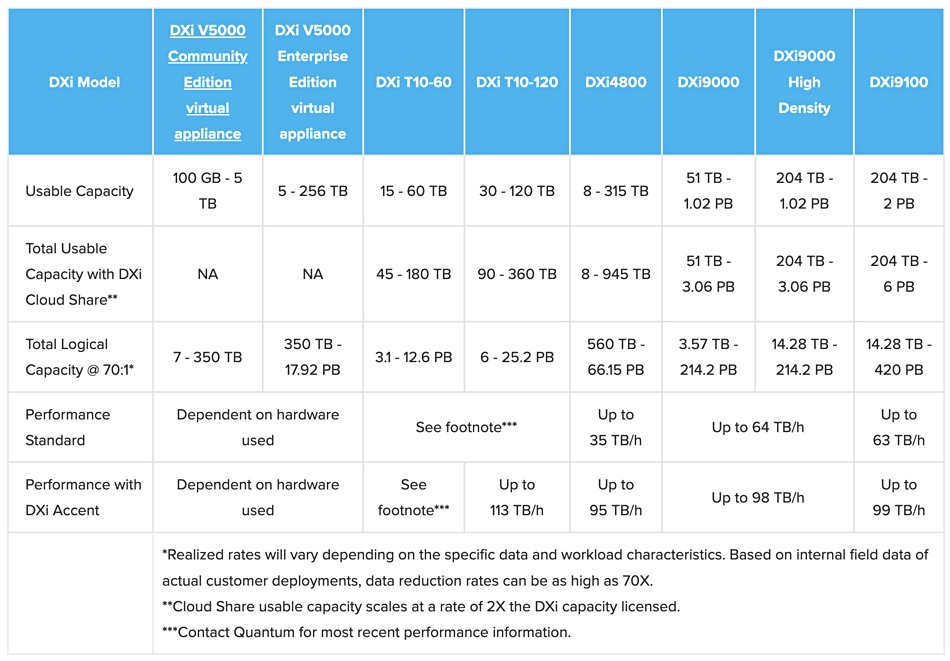
The T10-60 and T10-120, in 1RU chassis, will replace the current DXi mid-range, according to an IT Press Tour briefing in March. Deduping backup appliances – aka purpose-built backup appliances (PBBA) – take in data from backup software products such as Veeam, Veritas, and Commvault. They deduplicate the backup data and store it for later recovery if needed – typically using disk storage because of its affordable capacity. But all-flash devices, using TLC (3bits/cell) or QLC (4bits/cell) flash, like the T-series, provide faster ingest and recovery.
Quantum says the T-Series is the industry’s first all-flash target backup appliance. It’s designed for edge deployments, small and medium businesses (SMBs), and mission-critical data storage infrastructure. The T-Series can also be used as the edge component in larger edge-core-cloud setups. There, the DXi 9000 is the core datacenter appliance.
Sanam Mittal
Sanam Mittal, vice president, DXi engineering for Quantum, explained: “With continued improvements in density, cost, performance, and energy efficiency, QLC flash is the right choice for the next generation of data protection, especially for mission-critical relational and NoSQL databases, file systems and object stores that fuel data-intensive workflows, data lakes and AI pipelines.
“With all-flash DXi T-Series backup appliances, our customers can more efficiently protect their data and quickly recover operations in the face of a widespread ransomware attack.”
Quantum claims the T-Series has ingest rates of up to 113TB per hour, providing up to 65x faster backup rates and up to 13x faster restore times compared to competing products based on hard disk drives. The T-Series accelerates data rehydration to speed up other workflows including test and dev for analytics and application development, e-discovery and compliance, and long-term archiving.
Quantum DXi product range
Competition
Dell is market leader with the PowerProtect DD (DataDomain) line. These use SAS nearline disk drives for backup dataset storage and can use an external FS25 shelf, filled with SSDs, for caching metadata.
HPE’s three StoreOnce products – the 3660, 5260, and 5660 – use SAS nearline disk drives for dataset storage and have SSD metadata caching as well.
ExaGrid’s two-tier, disk-based backup target appliance ingests data without deduping it, stores it for a while in native state in this landing zone, then dedupes it to backend storage. Restoration from the landing zone is faster than from the backend store as no rehydration from the deduped state is needed.
Veritas’s NetBackup Flex Appliances, the 5260 and 5360, are disk-based as well.
Quantum DXi T10-120 management screenshot
There are several all-flash arrays that have backup target configurations such as Pure Storage (FlashBlade//), Infinidat, and VAST Data. But these are generally high-end systems not geared to providing relatively simple and cost-effective dedicated backup dataset target functionality.
It seems likely that Dell will provide all-flash PowerProtect configurations in response to the same needs for faster ingest and restore identified by Quantum. HPE, Veritas, and ExaGrid may well follow suit.
DXi T-Series backup appliances are planned for release in Q2 2024. Get a datasheet here.
Jimmy Tam is Peer Software’s CEO and reckons Peer’s multi-master replication is something that cloud file data services gateways can’t match.
Jimmy Tam
Tam talked about this in a briefing call and claimed the gateway folks, companies like CTERA, Nasuni, and Panzura, rely on having a single central copy of data to which all edge sites deferred; their single source of truth, their master data file so to speak. Maintaining this concept grows increasingly difficult as the amount of data involved increases, from tens to hundreds of petabytes and on to the exabyte level, he went on to claim.
Tam said: “How do you handle that scale? Number one, you need to create a scale-out system, right? Just like all the storage suppliers have a scale-out systems; like Dell PowerScale is a scale-out system. NetApp also has a scale-out system.”
“We have adapted our technology to accommodate scale out from a distributed system perspective. So, as our storage partner scales out, our software scales out so that we can put more and more agents to match those subsets of their scale-out architecture. And then we’re parallel processing that to distribute their distributed storage into multiple sites.”
These gateways want to replace filers in Tam’s view, but they are not primary storage suppliers: “[When] writing data the edge, what we need is an overlay on top of the original storage companies that we really trust, like Dell PowerScale, previously Isilon, NetApp, Nutanix files; we need an overlay on top of them, because we need a distributed systems to make sure that the data as we wrote it to the edge gets propagated to the central sites or the cloud or wherever else we want it.”
He says that level of scale defeats restoring an affected live system from a tape backup, asking rhetorically: “Imagine if ransomware hits? Am I going to be restoring 100 petabytes? How long will that take?”
Peer with GFS v6.0 can provide replication that enables a live failover to a hot standby site, Tam claimed, saying: “It starts at how do you accommodate to move that much data every single day and that’s where the scale-out architecture, the optimizations and network traffic, as well as ability to multiple parallel process that replication across multiple sites” comes in.
Tam claims the cloud storage gateway suppliers can’t match this either: “because, ultimately, the cloud storage gateway companies are cloud storage gateways. They’re not primary storage. And at this scale, petabytes and petabytes and petabytes scale, [customers are] realising the cloud storage gateways weren’t meant to write a massive amount of files quickly, every single day.”
Tam does not want Peer to replace filers. He wants Peer GFS to move data between filers, to augment their operation, and has struck deals with filer suppliers to do this.
Multiple masters
He thinks that internationally distributed enterprises will have moving master files. A media company may create a project file set in one location and it then follows the sun and moves to another location and then another, all the while with edge sites and remote workers needing to access it.
Another part of this media business could have a separate project with its own master file set which also moves due to project workflow needs. There are multiple master data sets and their location changes Tam says that the Peer Global File System (GFS) has been built to handle this situation.
He said: “The concept of one datacenter, one main source of truth; that’s out the window just because how we’ve changed and adapted, especially through COVID.”
“Our customers want multi-master systems, because you never know where the source of truth is going to be the next day, because people want a very flexible workforce, where you’re going to pull teams of people together, based on expertise. If the expertise in London, even though we’re a USA headquartered company, why don’t we create the centre of truth in London for that project? Hopefully, they’re doing that.”
“And then the company say, hey, we have another project coming out. The best person for that’s out of Tokyo. So let’s create Tokyo as main centre of truth for that project. And then another project spins up in New York, right. Just as the workflows are becoming much more fluid, and you’re creating pods of excellence, centres of excellence everywhere, the storage infrastructure, t and architecture has to be has to be fluid and flexible to accommodate that as well.”
The idea of having a single data center of truth in a public cloud can’t cope. Whatever happens anywhere around the world, in all the traditional cloud storage gateway edge sites, gets loaded up to the single centre of truth in the cloud. So when Tokyo comes online, after Turin goes away, it’s there up in the Amazon cloud ready and waiting for you. What Tam is saying is that’s just too slow. Datasets are so huge now that you cannot do that. What you have to do instead is keep a constant amount of replication going on between the various edge sites, because you cannot have a single centre because it simply can’t keep up.
Tam said:”That’s exactly it. When you make the cloud the source of truth, you’ve done that for simplicity’s sake, to accommodate the IT administrator, but you’re not serving the customer.”
He said: “We see the cloud as what they were originally meant for. Number one is going to be it’s powerful elasticity. So I’m creating all this data in these multi-master systems on premises everywhere. The cloud is going to be my ultimate repository for my backup and my archives, to make sure that I have everything stored in one place and have it right. That is my final and full copy of everything.”
Peer’s replication supports a hybrid on-premises to public cloud environment.
An AWS Storage blog, “Create a cross-platform distributed file system with Amazon FSx for NetApp ONTAP” says most organizations would like to enjoy the benefits of the cloud while leveraging their existing on-premise file assets to create a highly resilient hybrid enterprise file share. This can bring the challenging requirement of having different storage systems that exist at the edge, in the data center, and AWS to work together seamlessly, even in the face of disaster events.”
Blogger Randy Seamans writes: “I explore how Peer Software’s Global File Service (“PeerGFS”) allows customers to access files from the edge, data centers, and AWS through the use of cross-platform file replication, synchronization, and caching technologies. I also explore how to prevent version conflicts across active-active storage systems through integrated distributed file locking. I utilize Amazon FSx for NetApp ONTAP as the repository of record in AWS and Windows SMB, NetApp, Nutanix, or Dell storage for the on-premises edge and data center storage.”
He covers four situations:
File caching from FSx for ONTAP to on-premises edge Windows file storage
Distributed file system between on premises, edge, and data center storage with FSx for ONTAP
Continuous data protection and high availability from on-premises storage to FSx for ONTAP
Migration from on-premises storage to FSx for ONTAP
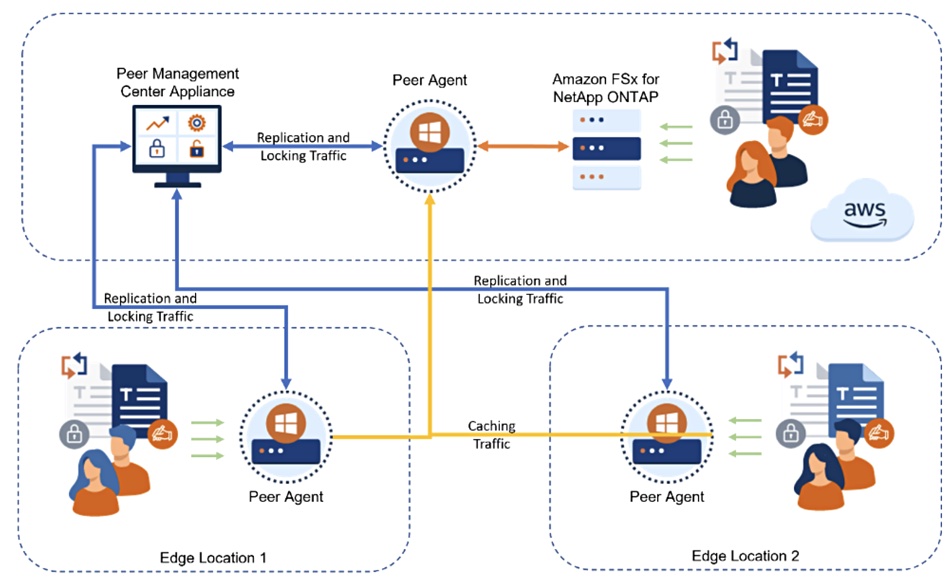
Caption: A typical configuration of PeerGFS file caching from FSx for ONTAP to two on-premises Windows file servers.
Configuration example of PeerGFS file caching from FSx for ONTAP to two on-premises Windows file servers.
The public cloud is a globally distributed set of data centers
Much as Tam separates Peer GFS use from an edge to a single data center or cloud center master data set idea, he says the cloud is not, in fact, a single location. It’s composed of regions and zones, each with their own data center infrastructure. A filer’s instantiation in the cloud, like FSx ONTAP, isn’t necessarily a single instantiation. There could be FSx ONTAP instances in many zones and regions for resilience and also for follow-the-sun type working.
Tam said: “The customers requirement is this: if one availability zone goes down, and I log back in to the next availability zone, where it’s still live, how do I make sure that all my profiles, my virtual desktop profiles, and the data is also there? Because Central is down? You will you need a distributed system, you need an active-active distributed system. … AWS is missing a distributed system, so AWS partnered with us.”
In other words there is a need for multi-master file replication inside a public cloud, and Peer has an arrangement with AWS to support this for AWS’s first-party managed FSx ONTAP service.
It is partnering Liquidware to provide, as an AWS blog title says, “Amazon WorkSpaces Multi-Region Resilience with ProfileUnity and PeerGFS”. This works with FSx ONTAP, and enables the ability “to replicate a user’s profile and data to standby Amazon WorkSpaces in a separate Region. This offers a business continuity and disaster recovery solution for your end users to remain productive during disruptive events.”
In-cloud multi-region resilience with AWS and FSx ONTAP
We can go further. We are in a multi-cloud era, with enterprises not wishing to be locked in to a single public cloud provider if they can avoid it. Tam said: “A government entity here in the USA that has mandated a resilient multi-cloud strategy. Because the government, the military, cannot put all their eggs in one basket, they need that risk abatement.”
But “AWS can only do it with their traditional active-passive technology with manual failover. But, in our world, everything is active-active and in real time.”
So, as night follows day, there is also a need for replication between file processing instances across public clouds. Now, with Peer providing the dataset mobility plumbing to facilitate this, between, say AWS and Azure, we have multi-master, multi-cloud replication.
There’s a new data lake service provider in town. Cribl, a data engine for IT and security observability, has announced the launch of Cribl Lake. It’s a “turnkey” data lake solution designed to put IT and security teams “on the fast-track” to having “complete control and flexibility” over their data.
Customers use Cribl’s vendor-agnostic offerings to analyze, collect, process, and route IT and security data from any source to any destination.
San Francisco-headquartered Cribl’s existing product suite, which is used by Fortune 1000 companies globally, includes Cribl Stream, an observability pipeline; Cribl Edge, an intelligent vendor-neutral agent; and Cribl Search, a search-in-place solution.
Cribl Lake’s unified management layer allows organizations to leverage low-cost object storage, either Cribl-managed or customer-owned, and automate provisioning, unify security and retention policy, and use open formats to eliminate vendor lock-in.
As data volumes rapidly increase, organizations are faced with tight budgets and lean engineering resources that prohibit them from effectively managing these data volumes. Cribl Lake is a flexible, “cost-effective” offering that “seamlessly scales” with data growth, said the provider, giving IT and security teams the autonomy to effectively manage retention, meet compliance mandates, centralize telemetry aggregation, and improve analytics and threat hunting, without dependence on other departments.
Clint Sharp
“To unlock the true value of data, it needs to be easily accessible so the right teams can retrieve the right data in the right format,” said Clint Sharp, co-founder and CEO of Cribl. “IT and security data, which is ingested in various shapes and formats, is traditionally challenging to structure, and will continue to become more complex as data variety and volume increases.”
Sharp co-founded Cribl in 2017, after leaving Splunk where he had been a senior director of product management for 5 years.
With Cribl Lake, he said, users can onboard huge volumes of data and set security and retention policies, all in open formats that empower them to efficiently analyze and extract value from any analytics tool, “today or in the future”.
Users can store any type of IT and security data, including raw, structured, unstructured, or other various formats. It can be optimized for future value through schema-on-need, stored in any format, and reformatted when needed.
There is easy access through open formats to simplify future analysis, replay operations, and with data portability. Security and compliance is maintained with unified security features, retention policies, authentication features, and access controls.
There are reduced storage costs through tiered storage based on data value.
And data silos are broken by improving data accessibility and analysis by sharing data across the enterprise with a central repository.
Cribl Lake is fully integrated with Cribl’s suite of products and can be onboarded “in a matter of minutes”, said the company, with no data or cloud-service provider expertise required by users.
Teams can “effortlessly” ingest, share, and route data downstream through Cribl Stream and Cribl Edge in any format, to any tool, at any time, without needing to move or “rehydrate” data to run analysis. Cribl Search unifies the query experience no matter where data is stored, so users can get value from data without delays.
Last December, Cribl said it had surpassed $100 million in ARR, becoming the fourth-fastest infrastructure company to reach centaur status (behind Wiz, Hashicorp, and Snowflake). A Series D funding round of $150 million brought its total funding to over $400 million.
Cribl Edge was brought to the AWS Marketplace as an Amazon Elastic Kubernetes Service (EKS) add-on, last November.
Veeam has the largest market share in the data replication and protection market by revenue, according to IDC.
The analyst house gave its clients a Semi-Annual Software Tracker/Data Replication & Protection – 2H 2023 report, and Veeam shared the numbers for the change in growth by the top five companies worldwide for the second half of 2023. It had the highest revenue, the fastest growth rate and the largest market share. Here is the table it presented at a briefing in London today:
The IDC analysts say this tracker covers the data protection and recovery software, data-replication services and public cloud services market sectors.
An initial observation is that the market is highly fragmented. Veeam, the leader, has just over one eighth of the market. Because backup processes and file formats are proprietary and very “sticky” this is a market that’s enormously resistant to consolidation. Veeam has a 1.2 percent market share lead over second-placed Dell, and is growing faster than any other top five supplier on a year-on-year basis – but not a sequential half year by half year basis. By that measure IBM leads, with 25.6 percent growth. However, IBM’s year-on-year growth rate is a derisory 0.2 percent.
By buying the major part of Veritas’s data protection business, but not all of it, Cohesity will likely jump into a top five position at the end of 2024 when the acquisition is slated to complete. The Veeamsters at the presentation didn’t think Cohesity plus the majority share of Veritas would topple it from the number one slot.
We have charted the vendor revenues from the table:
It is also obvious from this chart that no one vendor has a commanding lead. We also charted market shares and year-on-year growth rates:
The top two, Veeam and Dell, and also Commvault, have growth rates higher than their market shares, whereas Veritas’s growth rate is slightly less than its market share and IBM is hardly growing at all. The leading two are growing their market share the fastest and are set to enlarge their lead over IBM and Commvault next year. We don’t know the growth rate of the combined Veritas-Cohesity business and so can’t predict what will happen there.
B&F thinks there is a likelihood that there will be another acquisition or merger in the data protection/cyber security market between now and the end of 2025. A legacy vendor could join with a thrusting upstart – one like HYCU, Clumio or Druva say – to bolster its market share, move more quickly into a growing market area, and offer broader coverage, of the on-premises and public cloud SaaS areas, to its enterprise customers. Imagine what might happen if an incumbent vendor like IBM and Commvault combined with a newcomer such as HYCU or Clumio, OwnBackup or Keepit.
In an era of constant and pervasive ransomware attacks, enterprises would surely like to deal with large data protection + security suppliers who could offer broader coverage of their at-risk data assets. That would be opposed to relying on several artisanal suppliers with little or no coordinated data protection and security coverage and unknown gaps in coverage.
Silvaco Group has enhanced its partnership with flash memory and chipset maker Micron Technology. Silvaco is a provider of TCAD (technology computer-aided design), EDA (electronic design automation) software, and SIP (system in package) solutions that enable efficient chip design and support AI.
The deal includes expanding the scope and timescale of Silvaco’s software license and support services, and securing a $5 million investment from Micron. “This reflects our partnership with Micron for the development of our FTCO digital twin modeling tools,” said Silvaco.
“We have combined our expertise in semiconductor technologies with machine learning and data analysis to develop an artificial intelligence-based solution named ‘fab technology co-optimization,’ or FTCO, for wafer-level fabrication facilities,” said Babak Taheri, Silvaco CEO.
FTCO uses manufacturing data to perform statistical and physics-based machine learning software simulations to create a computer model or “digital twin” of a wafer that can be used to simulate the fabrication process.
Customers can utilize this model, said Silvaco, to run simulation experiments to understand and enhance wafer yield, without the need to run physical wafers that can be time-consuming and expensive.
“Silvaco’s AI and digital twin solution is enabling us to accelerate our ground-breaking advancements in memory and storage,” said Gurtej Sandhu, principal fellow of technology pathfinding at Micron Technology.
Silvaco’s technology is used for process and device development across displays, power devices, memory, high performance computing, photonics, the Internet of Things, 5G/6G mobile, the automotive industry, and complex SoC (System-on-Chip) design. It is headquartered in Santa Clara, California, and has offices across North America, Europe, Brazil, China, Japan, Korea, Singapore, and Taiwan.
Earlier this week, Micron launched a 2500 QLC NAND internal fit client product that’s faster than its 2550 TLC predecessor.
For its second quarter, Micron returned to profitability. For the three months ended February 29, revenues of $5.8 billion were generated, 57.6 percent higher than a year ago. There was a net profit of $793 million versus a $2.3 billion net loss for the same quarter a year ago. The firm’s technology is in big demand as organizations scale up their AI strategies.
Kioxia Europe has unveiled the EXCERIA G2 SD memory card series, offering capacities of up to 1 TB.
The “next gen” products are designed for long-time 4K video recording, for instance. Kioxia says they are a step up from the EXCERIA SD series “mainstream” models.
The new cards have an improved read speed of up to 100 MBps and write speed of up to 50 MBps. They correspond to UHS Speed Class 3 (U3) and Video Speed Class 30 (V30).
EXCERIA G2 cards are available in capacities from 32 GB to 1 TB. At 1 TB capacity, up to 1,258 minutes of recording time is possible using 4K video (100 Mbps). Alternatively, up to 154,070 photos (18 MP) can be stored.
These speeds and capacities are the best values obtained in a specific test environment at Kioxia Corporation, and they obviously may vary depending on the devices used by customers.
“With the launch of the larger SD cards, Kioxia is happy to address market needs. Customers can now take even more photographs and videos on any camera suited with an SD card slot, with less worry about space,” said Jamie Stitt, general manager B2C sales and marketing at Kioxia Europe.
The new memory cards will be available during this quarter, said the vendor.
Kioxia Europe was formerly known as Toshiba Memory Europe, and is the European subsidiary of Kioxia Corporation, the global provider of flash memory and SSDs.
According to recent reports, Kioxia is preparing an IPO to recapitalize itself as a loan payment of ¥900 billion ($5.8 billion) becomes due in June.
The company is 56.24 percent owned by a Bain Capital-led private equity consortium, and 40.64 percent owned by Toshiba.
Kioxia made a loss in its last financial year, and is expected to report another one in the financial year ended March 2024. The firm expects to return to profitability in its current financial year, ending March 2025, driven by a buoyed NAND market.
Cohesity says the French Red Cross (Croix-Rouge française) has been a customer in migrating, backing up, and protecting its data for almost two years. Cohesity’s DataProtect and Data Cloud offerings, operating on-prem and in the cloud, make it possible to encrypt, store, and protect all flows and all data transmitted from the various applications used by its healthcare staff, administrators, and emergency doctors. The backup operation, which protects the entire stack, from the bare metal server to files to applications, has a 100% success rate and the system is 95% self-sufficient, we’re told. Read the case study here.
…
Dell is partnering MaxLinear to integrate MaxLinear’s Panther III storage accelerator into the Dell PowerMax storage array, aiming “to deliver unparalleled performance gains.” The Panther III Storage Accelerator delivers throughput of 200Gbps, with scalability up to 3.2Tbps. It has single-pass data reduction, security, data protection, deduplication (MaxHash), and real-time validation (RTV), and “a remarkable 12:1 data reduction ratio achieved through a combination of compression and deduplication techniques.” The inclusion of industry-standard encryption algorithms such as Suite B Secret & Top-Secret Decryption/Encryption ensures robust data protection against unauthorized access or breaches, we’re told. The pairing will offer:
5:1 data reduction (Open) & 3:1 Data Reduction (Mainframe) Guarantee: optimizing storage resources, reducing TCO, and enabling an effective capacity per array of 18 petabytes.
Under 60-microsecond response times
Industry’s most secure and energy-efficient mission-critical storage offeringwith best-in-class security features and energy-efficient design.
…
Hammerspace was named at NAB 2024 as the winner for the second consecutive year in the “Store” category for the IABM BaM Awards 2024. It says the award was for delivering software “which accelerates production pipelines by bridging incompatible storage silos, providing extreme high-performance global file access and automated data orchestration across on-premises and/or cloud resources from any vendor.”
…
Hazelcast, which supplies in-memory data grid software, announced its Hazelcast Platform 5.4 software release with an AI focus. It has an advanced CP Subsystem – a component of its cluster software with CP standing for Consistent and Partition-tolerant – for strong consistency that retains a performance advantage over other comparable systems. Any updates made to the data structure are immediately reflected across all nodes in the system, ensuring that all nodes always have access to the most up-to-date information, eliminating the potential for corrupted or failed transactions. V5.4 has a Thread-per-core (TPC) architecture that extends performance, and also access to larger data volumes with Tiered Storage.
TPC can increase Hazelcast Platform throughput by 30 percent on large workloads with a high number of clients. Tiered Storage combines the speed of Hazelcast Platform fast data storage with the scale of SSD-based storage. By using the strengths of in-memory and SSD-based storage, uses can handle large data sets required by AI applications at an affordable cost, or so the vendor says. More info in a blog.
…
The Defense Information Systems Agency (DISA), a combat support agency of the United States Department of Defense (DoD), has awarded HPE a prototype Other Transaction Authority (OTA) agreement to develop its Distributed Hybrid Multi-Cloud (DHMC) prototype as part of a phased-acquisition approach. HPE will develop the prototype on HPE GreenLake, and upon successful completion, says it will enable DISA to simplify management of its disparate IT infrastructure and resources across public and private clouds through a unified hybrid, multi-cloud platform.
…
HighPoint Technologies has released the industry’s first PCIe Gen5 NVMe switch and RAID AIC / adapters. The RocketRAID 7600 and Rocket 1600 series feature the industry’s first implementation of Broadcom’s PEX89048 switch IC, supporting up to 32 NVMe devices, offering speeds up to 64GB/s, optimizing high-volume data transfers. Rocket 1600 series switch AICs/adapters provide enterprise-class NVMe storage connectivity of up to eight M.2, U.2/U.3 or E3.S SSDs , suitable for use with a range of industry-standard x86 server and workstation platforms. The Rocket 7600 series has RAID technology and a storage health monitoring and management suite. More data here.
…
Backup-as-a-Service data protector Keepit announced Kim Larsen as its new Chief Information Security Officer (CISO). He has more than 20 years of leadership experience in IT and cybersecurity from government and the private sector. Larsen’s areas of expertise include: business driven security; aligning corporate, digital and security strategies; risk management and threat mitigation; and developing and implementing security strategies. He started his career in the Danish National Police and subsequently spent nine years with the Security and Intelligence Service (PET) where he served as delegate for the Danish government in both NATO’s and the EU’s security committees.
…
A Microsoftdocument gives details about the maximum configuration for components you can add and remove on a Hyper-V host or its virtual machines, such as memory and disk storage or checkpoints. You can configure up to 240 TB of memory for gen 2 Hyper-V virtual machines and 64 TB of virtual hard drive capacity. There can be up to 4 PB of memory for hosts that support 5-level paging and 256 TB for hosts that support 4-level paging.
…
Asked about its promotion of co-founder and COO Garima Kapoor to co-CEO alongside co-founder Anand (AB) Periasamy, a MinIO spokesperson claimed: “We had an outstanding 2024FY close posting another year of outstanding growth. The board was pleased with Garima’s leadership on the business side and felt it was time to elevate her to co-CEO. She continues to oversee the business side of MinIO. The addition of [CFO] Mark Khavkin brings further structure and process to the finance function. His operational skills are well documented and he will be a valued partner for Garima on the management team enabling MinIO to continue to scale its growth as more and more customers adopt large scale AI data infrastructure.”
…
Startup Neon.tech has built a serverless Postgres database and announced its official release, transitioning from a technical preview stage. The database offers instant database branching which is available for every new development team. The number of Neon databases surged from 6,000 to over 700,000 within one single year. “Serverless and database branching are the new table stakes for teams that want to maximize their developer velocity,” says CEO Nikita Shamgunov.
…
Pure Storage announced that the French National Agency for Radioactive Waste Management (Andra) is a FlashArray customer. Pure’s products have, we’re told, helped Andra to reduce the total energy consumption of its data center by 20 percent; reduce its physical footprint by 80 percent (from 30U to 6U); and cut its CO2 emissions by 4 tons per year. Additionally, Pure’s Evergreen architecture helps Andra better manage the product lifecycle and reduce e-waste by enabling non-disruptive software and hardware upgrades.
…
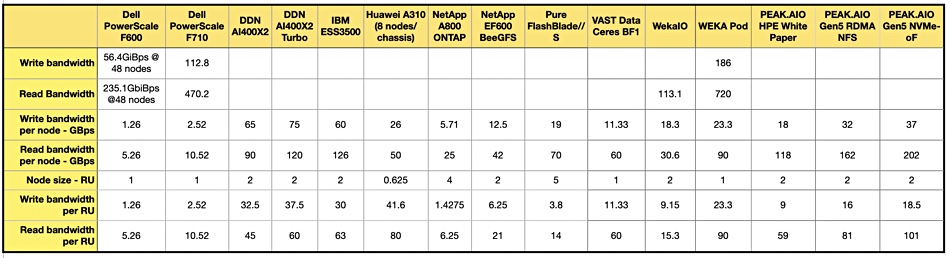
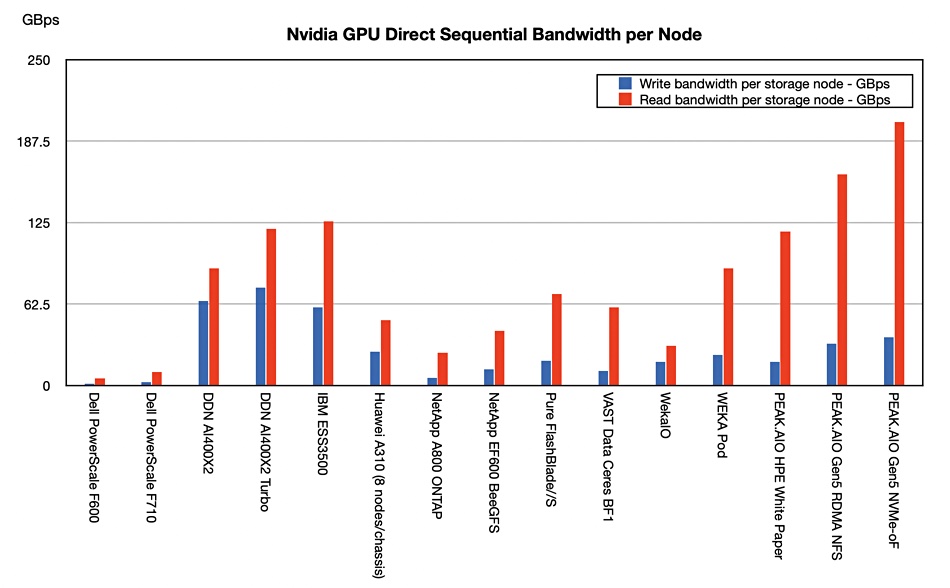
Our updated collection of vendor performance numbers for Nvidia GPU Direct shows that Pure Storage’s FlashBlade//S has good performance, beating a VAST Data/Ceres BF1 system:
…
…
Cyber security and data protector supplier Rubrik anticipates its IPO listing day on the NYSE on Thursday, April 25.
…
Samsung Electronics has developed the industry’s first LPDDR5X DRAM with performance of up to 10.7 Gbps (gigabits-per-sec), improving performance by more than 25 percent and capacity by more than 30 percent, compared to the previous generation. It uses Samsung’s 12-nanometer (nm) process technology, the smallest chip size among existing LPDDRs. It has enhanced power efficiency by 25 percent over the previous generation and “expands the single package capacity of mobile DRAM up to 32-gigabytes (GB), making it an optimal solution for the on-device AI era that requires high-performance, high-capacity and low-power memory.”
…
HCI vendor Scale Computing announced record revenue for the first quarter of 2024, increasing sales by 35 percent YoY from Q1 2023. Increased partner and customer demand for new virtualization and edge computing solutions drove the record growth. The company also announced that Don Aquilano has joined as Chief Administrative Officer. With decades of experience as a venture capitalist, Aquilano has a an understanding of the supply chain, operations, and how to structure both long-term and short-term financial deals. Previously, Aquilano held positions at HP, Diageo, and the Boston Consulting Group and has been a lead investor, advisor, and board member with Scale Computing since 2009.
“We have seen a seismic shift in demand for both enterprise edge computing and alternative virtualization platforms generally, resulting in record inbound interest and pipeline growth. This is unlike anything I’ve seen in my career. The Q1 results put us on a trajectory to exceed 50 percent year-to-year revenue growth in 2024,” said Jeff Ready, CEO and co-founder of Scale Computing.
…
Scality has appointed CRO Peter Brennan as CEO of Scality Inc., the US business, while retaining the CRO role. Since joining Scality as CRO in March 2023, Scality has grown its US and worldwide sales team, established a two-tier sales channel with the addition of new distribution partners Ingram Micro, TD SYNNEX and a burgeoning Value Added Reseller (VAR) programme. Jerome Lecat, who co-founded Scality in 2009, remains in his current role as global CEO and chairman of Scality and continues to lead the company’s operations globally with a specific focus on EMEA, Asia Pacific and Japan. Brennan will lead Scality Inc.’s overall strategic direction, operations, and execution to grow the company’s footprint across the US, and will continue to play a role in driving revenue growth opportunities globally.
…
Scality announced a deal with Ingram Micro to distribution ARTESCA, Scality’s secure, simple object-storage software for immutable backups throughout the US. This news follows the recent launch of ARTESCA 2.0, which has seen a 5x year-over-year growth rate where channel partners are driving 100 percent of the business.
…
Wedbush financial analyst Matt Bryson tells subscribers: “We believe two significant fundamental demand shifts occurred towards the end of the first quarter: 1) Standard server builds began to rebound driven by hyperscale demand, and 2) Enterprise storage demand began to lift. In turn, we believe storage component vendors were some of the most significant beneficiaries of these shifts.” He’s positive about he upwards effects of these trends on Seagate and Western Digital, particularly the latter: “We believe WDC’s NAND and HDD businesses should have both exceeded even our modeled numbers (which were originally set well above guidance).” Regarding Seagate: ‘While we are not changing our STX numbers today, we believe that nearline shipment volumes should meaningfully exceed our prior modeled outlook.” However: “Our one concern is apparent delays in HAMR production/shipments. We believe shipments are trailing prior expectations, and we are uncertain if STX can catch up to its prior 1H targets in CQ2.”
…
SingleStore CEO Raj Verma has written a book; “Time is Now”. In the introduction he writes: “With AI, we are now dead center of the Fourth Industrial Revolution. Many companies are poised to become AI driven, or as the last round taught us, they will turn into AI themselves. … Data is at the core of AI. A company will eventually use its data to make decisions with AI – which will help it form its identity to stand apart from its competitors. … Our environment is constantly feeding us data – information that our brains must then interpret to make the best decision possible. … Before we can decide how to use AI, we have to understand its relation to Real Time. We must first pause to consider the power of Now: How it is shaped through Information, how it is given Context by technology and human behavior, and how it drives Choice. The moment we are in is not isolated – it has been shaped by the past, is powered by the present, and molds the future.” Buy the book from Amazon.
…
SK hynix is working with TSMC, the Taiwanese contract semiconductor manufacturer, on building HBM4 memory chips, adopting its foundry process and advanced packaging technology; CoWoS (Chip on Wafer on Substrate). HBM4 chips are to be mass produced from 2026, through this initiative. The collaboration is expected to enable breakthroughs in memory performance through trilateral collaboration between product design, foundry, and memory provider.
The two will first focus on improving the performance of the base die that is mounted at the very bottom of the HBM package. HBM is made by stacking a core DRAM die on top of a base die that features TSV technology, and vertically connecting a fixed number of layers in the DRAM stack to the core die with TSV into an HBM package. The base die located at the bottom is connected to the GPU, which controls the HBM. SK hynix used proprietary technology to make base dies up to HBM3E, but plans to adopt TSMC’s advanced logic process for HBM4’s base die so additional functionality can be packed into limited space.
…
Taipei’s TeamGroup has launched an MP44Q M.2 PCIe 4.0 SSD using TLC flash offering capacities of up to 4TB. It achieves maximum sequential read and write speeds of up to 7,400 MBps and 6,500 MBps, respectively, and has a patented graphene heat dissipation sticker, whose thickness is less than 1 mm. The drive has a 5-year warranty and is expected to be available globally starting in early May.
…
Veeam announced Veeam Data Platform support for host-based backups of VMs running on the Oracle Linux KVM hypervisor. Reflecting growing customer demand to move data between platforms, Veeam extends its major virtualization platforms protection. Veeam says its product integrates with numerous virtualization platforms and clouds, including VMware vSphere, VMware Cloud Director, VMware Cloud on AWS, VMware Cloud on AWS Outposts, VMware Cloud on Dell, Microsoft Hyper-V, Microsoft Azure Stack HCI, Microsoft Azure VMware Solution, Amazon AWS, Nutanix AHV, Red Hat Virtualization, Google Cloud, Google Cloud VMware Engine, Oracle Cloud VMware Solution and IBM Cloud, ensuring compatibility across diverse environments. All of this is unlocked with the portable Veeam Universal License.
Israeli startup RAAAM Memory Technologies has announced $4 million in seed funding to develop a System-on-Chip (SoC) SRAM replacement.
Robert Giterman, RAAAM co-founder and CEO, said in a statement: “RAAAM’s Gain-Cell Random Access Memory (GCRAM) technology is a unique on-chip memory solution that only requires three transistors to store a bit of data, as opposed to 6-8 transistors needed for the existing SRAM-based highest-density memory technology. The GCRAM solution reduces area by half and power consumption by a factor of five and can be manufactured cost efficiently using the standard CMOS process.”
Robert Giterman
RAAAM says GCRAM is fully compatible with standard CMOS and can be used as a drop-in SRAM replacement in any SoC, allowing for lower fabrication costs through reduced die size or enhanced system performance by increasing memory capacity within the same die size.
The firm says that SoCs are devoting increasing amounts of their on-chip area to embedded memory, typically SRAM. As our glossary states, SRAM uses a flip-flop circuit with two stable states to store a binary bit value. The circuit needs four transistors to store a bit and two to control access to the cell. In contrast, DRAM needs one transistor and one capacitor to store a bit, making its cells smaller than SRAM cells. RAAAM says the size of SoC embedded memory is increasing, reaching up to 75 percent of the total SoC real estate in some applications like artificial intelligence and machine learning. This will limit SoC development and applicability.
It was founded in 2021 by four PhDs from Bar-Ilan University and the Swiss Federal Institute of Technology Lausanne (EPFL) that specialize in Very Large-Scale Integration (VLSI) design. These are Giterman plus Andreas Burg, Associate Professor, Head of the Telecommunications Circuits Lab at EPFL, Alexander Fish, Professor at Bar-Ilan University and Advisor, and Adam (Adi) Teman, Associate Professor at Bar-Ilan University and Scientific Advisor.
Seed round investors include Serpentine Ventures, J-Ventures, HackCapital, Silicon Catalyst Angels, Claves Investments, and a large multinational semiconductor company as a strategic investor.
A downloadable GCRAM presentation, created by Adam Teman, explains how the technology uses separate read and write ports, in contrast to DRAM’s combined read/write port per cell. This enables it to amplify the cell’s stored charge and separately optimize the read and write processes while retaining SRAM-like performance.
HPC parallel filer outfit Panasas has tapped Avnet to be its primary manufacturing and fulfillment operations partner.
Panasas supplies scale-out PanFS software, with NFS and SMB/CIFS protocol support, and ActiveStor Ultra hardware nodes. Avnet helps design, build, and deliver systems with electronic components. Its global systems integration arm, Avnet Integrated, has a worldwide supply chain and manufacturing footprint. Going forward, Avnet Integrated will be the principal commercial manufacturing partner for Panasas worldwide.
Panasas CEO Ken Claffey said in a statement: “One of my first goals when joining Panasas was to move to a best-in-class operational model that would enable greater supply chain efficiency and flexibility in order to meet the demand growth that we are seeing across our global customer base, while also accelerating our ability to bring a broader range of solutions to market.”
Nicole Enright, president of Avnet Integrated, added: “The agreement with Panasas provides access to our global manufacturing and supply chain capabilities, accelerating both time to market and time to scale for their solutions.”
Erik Salo
In her view, such partnerships enable Avnet customers to increase their pace of innovation and ultimately elevate their competitiveness.
Since joining Panasas in September 2023, Claffey has hired many new execs and is pointing the company at the AI and HPC markets. Erik Salo joined Panasas in December 2023 to become its VP for Marketing and Product Management, moving from Seagate where he was VP for Products and Markets. Salo was involved with the launch of the CORVAULT product line, contributions to the creation of the IT4.0 (Fourth Industrial Revolution) initiative, and the strategic acquisitions of Xyratex, Dothill, and Evault.
Claffey also hired a new CFO, Paul Hiemstra, in March, away from a Group CFO position at HPE’s HPC & AI division, with time spent at Cray before that.
Comment
Paul Hiemstra
Panasas is now effectively a software company with a commodity hardware platform focus, which lessens the need for involvement in hardware design, manufacturing, and related capital commitments. In this it is to some extent following VAST Data, which exited hardware design and manufacturing three years ago, and with certified hardware appliances also built by Avnet.
Last year we speculated that Panasas, re-energized by Claffey and a new leadership team, could look towards making its software available in the public clouds and deliver data faster to GPUs by supporting protocols like GPUDirect. We can’t add anything to that but we can say that Panasas is now able to commit more resources and energy to software development, and must have roadmap plans.
Its competitors – BeeGFS, DDN, IBM, VAST Data, and Weka, for example – better get prepared for stronger product and market offerings.
Lakehouse supplier Databricks says it has seen over 70 percent year-over-year growth for its EMEA region business in its latest fiscal year, without providing numbers. It is now moving to bump up its physical presence in the region with new hubs for staff, to help along further growth.
Last September, privately funded Databricks completed a Series I funding round, raising over $500 million. That funding at the time valued the company at $43 billion.
Globally, Databricks claims to have it generated over $1.6 billion in revenue for its fiscal year ending 31 January, 2024. That figure represented over 50 percent year-over-year growth.
The period saw the firm acquire a string of companies, which will no doubt boost the topline. It bought MosaicML, Arcion, Okera, Einblick and Rubicon. It also recently invested in French-based Mistral AI, and announced the launch of DBRX, an open source, general-purpose large language model (LLM), to help feed its increased business in AI-driven data management.
In EMEA, there is said to be “an increased appetite” for Databricks SQL, the “intelligent data warehouse”. Built with “data intelligence engine” DatabricksIQ, the firm claims Databricks SQL “democratizes” analytics for technical and business users alike.
AXA, FrieslandCampina, Gousto, HSBC, LaLiga, L’Oréal, Michelin, Rolls Royce, Shell, and Unilever have adopted this platform to help improve their business outcomes. Databricks has helped grow this type of business through global system integrators, including Accenture, Avanade, Capgemini, Deloitte, and EY, and in partnership with business software heavyweights like Salesforce and SAP.
To help the handling of all this company data activity in the region, Amazon Web Services datacenter capacity has been acquired in Paris and Azure capacity in Qatar, it said.
“There can be no generative AI without good data. Our technology is a critical enabler for businesses across EMEA to stand out from their competitors, scale AI, and recognise tangible business outcomes,” said Samuel Bonamigo, senior vice president and general manager, for Databricks EMEA. “We’ve had the pleasure to work with such a strong ecosystem of partners and customers across the region.”
“Working with Databricks has created a step change in terms of how our internal stakeholders view data and AI”, added customer Paul Hollands, chief data and analytics officer at AXA UK. “We previously had a disparate set of data platforms that didn’t scale, making it difficult to fully leverage machine learning and data across the organisation.
“Databricks’ unified platform has enabled us to go from data engineering to data science really efficiently. This is pivotal to success in serving customers, supporting colleagues, and ultimately driving value for the business.”
To fuel progress in EMEA, Databricks announced a roadmap of new offices and office expansions for 2024, including a new seven-story EMEA headquarters in London, planned to open in the second-half of this year. This building will house 400 staff. The company will also open new offices in Madrid and Milan in H2, alongside moving to a brand new office space in Paris.
There are also plans to expand existing office space in Amsterdam, Belgrade, and Munich. Earlier this year, the company opened an engineering site in Zagreb.
Nasuni customers can now integrate their data stores and workflows with customized Copilot assistants.
Microsoft’s Copilot is a GenAI chatbot integrated with Microsoft 365 apps such as Teams. Users can build their own customized Copilots using a Copilot Studio facility, which will work with their Microsoft app data. Nasuni provides distributed cloud-based File Data Platform services and stores its customers’ unstructured data in an Amazon S3 object store. It has developed a way for this data to be made available to customized Copilot chatbots to improve and broaden its ability to answer requests using Nasuni-stored unstructured data.
Jim Liddle, Nasuni’s chief innovation officer, said: “While Microsoft Copilot is an incredible general-purpose AI assistant, its true enterprise value is realized when it is infused with an organization’s domain-specific data. File data is typically locked up in siloed environments, making AI impossible. With Nasuni, customers can consolidate their data in the cloud and then leverage AI.”
To demonstrate this, Nasuni developed a version of Copilot for internal use. “We created our own Copilot chatbot that leverages our Nasuni data, called ‘Ask Nasuni,’ that is deployed within the Microsoft Teams environment for our employees to interact with. It only makes sense that our customers would want to do something similar to leverage their own corporate information.”
The Copilot Studio facility enables customers to produce their own specific versions of the chatbot. Nasuni has a white paper guide to giving such customized Copilot chatbots Nasuni data access:
It suggests such Copilots “work particularly well for static data sets that change infrequently” and typical use cases include:
Domain-specific assistance: Create Copilots specialized in specific domains (e.g., healthcare, legal, finance) to provide accurate and relevant information
Custom FAQs: Build Copilots that answer frequently asked questions, reducing the load on human support teams
Content recommendations: Develop Copilots that recommend relevant articles, products, or services based on user queries
Process automation: Copilot Studio can guide users through complex processes or workflows
Personalized conversations: Customize Copilots to engage in natural conversations with users, enhancing user experience
Nasuni wants clients who are also Microsoft customers adopting Copilot chatbot technology to have Copilot-mediated natural language interaction with data in Nasuni-stored documents and files.
Comment
This seems like a “no-brainer” issue. We could see all unstructured data storage suppliers adopting a similar approach and ensuring that data held in their stores is made available to their Microsoft-using customers’ Copilot-based chatbots.
Scale-out parallel file system supplier Qumulo now runs natively in AWS. The company has announced the initial private availability of Qumulo Cloud Native file system in the AWS cloud.
Qumulo’s Core file system software was available on AWS back in 2021, but this latest addition is different.
Kiran Bhageshpur
Kiran Bhageshpur, CTO at Qumulo, told B&F: “What we had announced back in 2021 was what I would call our ‘Gen 1’ offering, i.e. a ‘lift and shift’ from our on-premises node-based architecture. A node on-premises became an EC2 instance, drives on-premises became EBS volumes, and you could tie together 4-265 nodes to deliver an ‘on-premises’-like file service. Even that was less expensive in terms of TCO as compared to alternatives like FSx-ONTAP while being more scalable and more performant.”
“What we announced as being in private availability to a select number of customers is our ‘cloud native architecture,’ similar to the ‘engine’ behind our Azure Native Qumulo offering we released in November 2023.”
Qumulo Cloud Native file system uses S3 to store file data. This file system layer is disaggregated from object storage, but both work together to deliver high throughput and transactional performance. The company says this disaggregation provides the ability to complete 90-99 percent of all transactions in the file system layer, reducing and saving costs. Customers can deploy a Qumulo file system on AWS in minutes and scale from 4 GBps to hundreds of GBps while using AWS’s elastic cloud compute (Amazon EC2) and storage (Amazon S3) infrastructure.
Bhagespur said: “It leverages AWS S3 for persistent storage. This is eleven nines (99.999999999 percent) durability and is resilient to zonal faults. We use compute (EC2) to run file and data services, i.e. it’s just code. We leverage node local storage (instance-attached NVMe and EBS) explicitly for caching with no long term persistence at this layer.”
Qumulo Cloud Native’s scalability is only limited by the scale of S3. It’s elastic in that compute and cache can be dynamically increased and reduced based on the workload need. Bhageshpur told us it brings to customers “the same file and data services that they know and love, whether they were on-prem or using our ‘Gen 1’ offering in AWS.”
He claims it’s also “around 80 percent less expensive than all other alternatives.”
Additionally, Qumulo has a Global Namespace (GNS), which lets customers consolidate all their Qumulo instances – edge, core, and cloud – into a unified data plane that enables local-like access to remote files. It is based on an AI-driven algorithm to pre-fetch data from any Qumulo Instance anywhere before it is needed. GNS lets users define virtual paths to data, effectively freeing it from physical location constraints. It enables all of a customer’s workflows to use the same path to access the same data no matter where it’s physically located.
Qumulo has been using and developing this algorithm over ten years. Customer Bardel Entertainment plans to use this capability to centralize data and make it accessible to artists in remote locations without sacrificing performance, or so we’re told.
The company said that, combined with its Cloud Native file system, the GNS offering allows creative or other teams to collaborate from geographically dispersed locations, from any device connected to AWS infrastructure. This allows members of a global organization to work together, without sacrificing file system performance or cost.
Bardel technology VP Arash Roudafshan said: “A project that would have been region-bound is now global and can go to any resource at any time, anywhere. By being more agile, we give that opportunity back to our clients, and they can be more creative and agile in their thinking about how they want to run production.”
At present, Qumulo’s Cloud Native file system on AWS is offered only through private availability. Contact Qumulo to inquire about eligibility for private availability.
Comment
This remote-access-made-to-appear-local is a feature of the Hammerspace Global Data Environment. Does this position Qumulo for further encroachments onto the Hammerspace turf? We think Qumulo may announce a cloud-native version of its file system software on the Google Cloud Platform as well.