Cohesity announced a collaboration with NVIDIA for its Gaia Gen AI software to include Nvidia’s NIM microservices. Gaia will be integrated with NVIDIA’s AI Enterprise software. Nvidia has also invested in Cohesity. Gaia nearest and dearest now get:
- Domain-specific and performant generative AI models based on the customers’ Cohesity-managed data, using NVIDIA NIM. Customers can fine-tune their large language models with their data and adapt them to fit their organisation.
- A tool for customers to query their data via a generative AI assistant to gain insights from their data, such as deployment and configuration information, security, and more.
- Cohesity’s secondary data to build Gen AI apps that provide insights based on a customer’s own data.
- Gen AI intelligence to data backups and archives with NVIDIA NIM.
…
Distributor TD SYNNEX’ Hyve hardware building business unit has announced an array of products tailored for the AI lifecycle at NVIDIA GTC. They include:
- NVIDIA MGX / OCP DC-MHS 2U Optimized Generational Platforms for Compute, Storage and Ruggedized Edge
- OAM-UBB 4U Scalable HPC-AI Reference Platform
- Next Generation AI-Optimized ORv3 Liquid-Cooled Enclosure
- Various 1U Liquid-Cooled Inference Platforms
…
Real-time streaming analytics data warehouse supplier Kinetica, which has integrated ChatGPT to its offering, is adding a real-time RAG capability, based on NVIDIA’s NeMo Retriever microservices and low-latency vector search using NVIDIA RAPIDS RAFT technology. Kinetica has built native database objects that allow users to define the semantic context for enterprise data. An LLM can use these objects to grasp the referential context it needs to interact with a database in a context-aware manner. All the features in Kinetica’s GEN AI offering are exposed to developers via a relational SQL API and LangChain plugins.
Kinetica claims its real-time generative AI offering removes the requirement for reindexing vectors before they are available for query. Additionally, we’re told it can ingest vector embeddings 5X faster than the previous unnamed market leader, based on the VectorDBBench benchmark.
…
Lenovo has announced that hybrid AI systems, built in collaboration with NVIDIA, and already optimized to run NVIDIA AI Enterprise software for production AI, will now provide developers access to the just–announced NVIDIA microservices, including NIM and NeMo Retriever. Lenovo has expanded the ThinkSystem AI portfolio, featuring two new 8-way NVIDIA GPU systems that are purpose-built to deliver massive computational capabilities.
They are designed for Gen AI, natural language processing (NLP), and large language model (LLM) development, with support for the HGX AI supercomputing platform, including H100 and H200 Tensor Core GPUs and the Grace Blackwell GB200 Superchip, as well as Quantum-X800 InfiniBand and Spectrum-X800 Ethernet networking platforms. The new Lenovo ThinkSystem SR780a V3 is a 5U system that uses Lenovo Neptune liquid cooling.
Lenovo claims it’s the leading provider of workstation-to-cloud support for designing, engineering and powering OVX systems and the Omniverse development platform. It’s partnering with NVIDIA to build accelerated models faster using MGX modular reference designs.
…
NVIDIA launched enterprise-grade generative AI microservices that businesses can use to create and deploy custom applications on their own platforms. The catalog of cloud-native microservices built on top of NVIDIA’s CUDA software, includes NIM microservices for optimized inference on more than two dozen popular AI models from NVIDIA and its partner ecosystem.
NIM microservices provide pre-built containers powered by NVIDIA inference software — including Triton Inference Server and TensorRT-LLM — which, we’re told, enable developers to reduce deployment times. They provide industry-standard APIs for domains such as language, speech and drug discovery to enable developers to build AI applications using their proprietary data hosted in their own infrastructure. Customers will be able to access NIM microservices from Amazon SageMaker, Google Kubernetes Engine and Microsoft Azure AI, and integrate with popular AI frameworks like Deepset, LangChain and LlamaIndex.
Box, Cloudera, Cohesity, Datastax, Dropbox, NetApp and Snowflake are working with NVIDIA microservices to help customers optimize their RAG pipelines and integrate their proprietary data into generative AI applications.
NVIDIA accelerated software development kits, libraries and tools can now be accessed as CUDA-X microservices for retrieval-augmented generation (RAG), guardrails, data processing, HPC and more. NVIDIA separately announced over two dozen healthcare NIM and CUDA-X microservices.
…
NVIDIA has introduced a storage partner validation program for Its OVX computing systems. OVX servers have L40S GPUs and include AI Enterprise software with Quantum-2 InfiniBand or Spectrum-X Ethernet networking, as well as BlueField-3 DPUs. They’re optimized for generative AI workloads, including training for smaller LLMs (for example, Llama 2 7B or 70B), fine-tuning existing models and inference with high throughput and low latency.
NVIDIA-Certified OVX servers are available and shipping from GIGABYTE, HPE and Lenovo.
The validation program provides a standardized process for partners to validate their storage appliances. They can use the same framework and testing that’s needed to validate storage for the DGX BasePOD reference architecture. Each test is run multiple times to verify the results and gather the required data, which is then audited by NVIDIA engineering teams to determine whether the storage system has passed. The first OVX validated storage partners are DDN, Dell (PowerScale), NetApp, Pure Storage and WEKA.
…
SSD controller array startup Pliops has a collaboration with composability supplier Liqid to create an accelerated vector database offering to improve performance, capacity and resource requirements. Pliops says its XDP-AccelKV addresses GPU performance and scale by both breaking the GPU memory wall and eliminating the CPU as a coordination bottleneck for storage IO. It extends HBM memory with fast storage to enable terabyte-scale AI applications to run on a single GPU. XDP-AccelKV is part of the XDP Data Services platform, which runs on the Pliops Extreme Data Processor (XDP).
Pliops has worked with Liqid to create an accelerated vector database product, based on Dell servers with Liqid’s LQD450032TB PCIe 4.0 NVMe SSDs, known as the Honey Badger, and managed by Pliops XDP. Sumit Puri, president, chief strategy officer & co-founder at Liqid, said: “We are excited to collaborate with Pliops and leverage their XDP-AccelKV acceleration solution to address critical challenges faced by users running RAG applications with vector DBs.”
…
Snowflake and NVIDIA announced an expanded agreement around adding NVIDIA AI products to Snowflake’s data warehouse. NVIDIA accelerated compute powers several of Snowflake’s AI products:
- Snowpark Container Services
- Snowflake Cortex LLM Functions (public preview)
- Snowflake Copilot (private preview)
- Document AI (private preview)
…
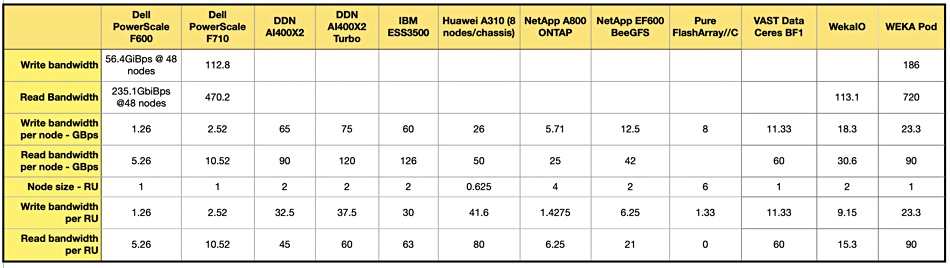
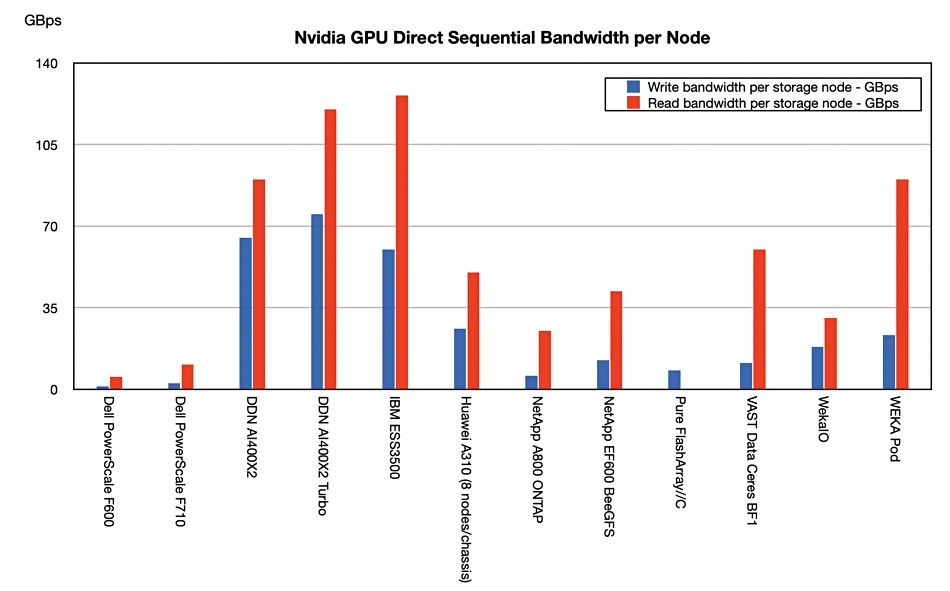
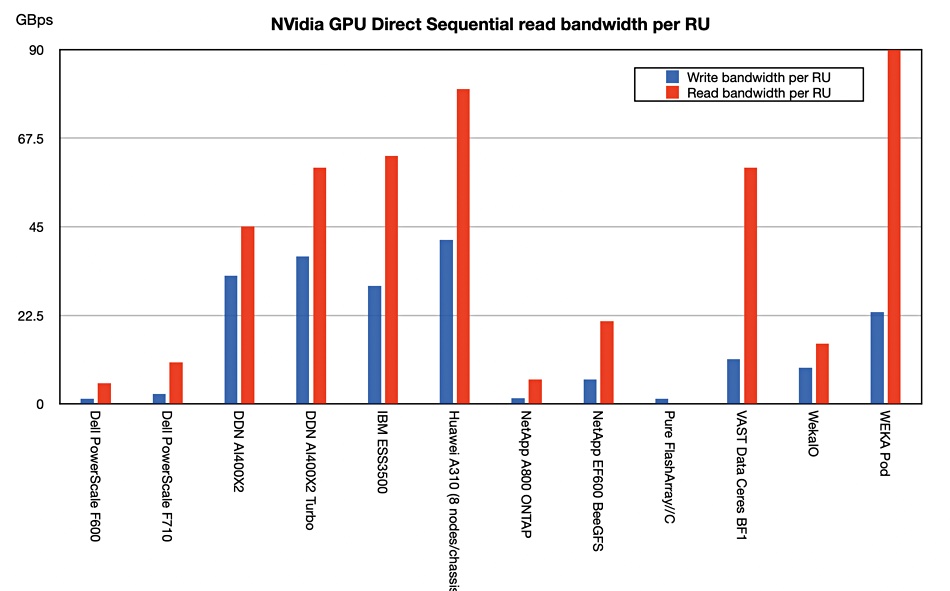
We have updated our table of suppliers’ GPUDirect file access performance in the light of GTC announcements;
A chart show the suppliers’ relative positions better;
There is a divide opening up between DDN, Huawei, IBM, VAST Data and WEKA on the one hand and slower performers such as Dell (PowerScale), NetApp and Pure Storage on the other. Recharting to show performance density per rack unit shows the split more clearly.
We note that no analysis or consultancy business such as ESG, Forrester, Futurum, Gartner, or IDC has published research looking at supplier’s GPUDirect performance. That means there is no authoritative external validation of these results.