StorONE is the basis for Accessium Group’s HIPAA-compliant storage offering for the healthcare market.
Ryan Erwin.
The StorONE S1 offering provides scale-out and performant block, file, or object storage with auto-tiering between three levels of SSD performance and disk drives, and immutable snapshots. The Buffalo, NY-based Accessium Group is an IT infrastructure services and outsourcing supplier to the healthcare market with a focus on networking, security, and compliance.
A statement from Accessium CEO Ryan Erwin read: “With its vast stores of sensitive data and the need to be up and available for patients 24×7, the healthcare sector continues to be one of the most attractive targets for cyber attacks. Additionally, it is critical to have the most recent patient data at hand at any time.
“The StorONE platform provides it all: ready access to data and robust security. With StorONE, Accessium can provide access to the highest standards of privacy and trust that patients rightfully expect and deserve.”
Ken Brower
The suppliers say StorONE’s high-performance storage can “ensure lightning-fast access to medical images, reducing retrieval times, enhancing data access speeds, and minimizing latency issues. These improvements are critical for timely diagnostics and treatment.”
KJB Consulting Group CEO Ken Brower commented: “As a former CIO, I’ve been on the front line in remediating three global corporate cyber attacks and my experience has been that the road to recovery is full of potholes. Today, with the ever-increasing frequency of cyber attacks that deny access to data, maintaining frequent backups and robust recovery capabilities is an absolute imperative.
“A comprehensive data backup plan, as required by HIPAA’s Security Rule, should include disaster recovery, emergency operations, critical data analysis, and periodic testing. StorONE supports this level of back up and response and provides these vital actions for safeguarding data and ensuring operational resilience against cyber threats.”
Invest in a dependable backup and disaster recovery solution. By having a solid plan in place, you can minimize the risk of data loss and swiftly restore your systems in case of any disruptions.
Maintain up-to-date systems. Keeping your systems updated not only reduces the chances of cyber attacks but also simplifies the recovery process if one occurs.
Ensure your staff is trained in recovery procedures. Make sure your staff is familiar with whom to contact and the immediate steps to take to mitigate any potential damage.
Regularly test your backup and disaster recovery solution. Testing ensures that your plan functions as intended and allows for adjustments if needed. This proactive approach can save you from headaches down the line.
With malware disasters affecting healthcare systems, like the disastrous Synnovis attack in the UK, these four fundamental points seem highly relevant, and a storage system that supports them will be worthwhile.
Gal Naor, CEO and co-founder of StorONE, said: “Our Enterprise Storage Platform is designed to support high capacity and performance, ensuring healthcare providers can manage their data with confidence and ease.”
OpenDrives is launching composable storage software in a bid to end capacity-centric licensing.
The pitch is that a typical storage software product is full of features users may not want but can’t avoid buying. This is similar to using a word processor with hundreds of different and powerful features, but in reality you just use a handful of the basic functions. Businesses small and large are forced to purchase all the functions, even if they only use 5 percent of them. In terms of storage software, customers can buy a reduced function entry-level product with capacity constraints and a full-function feature set with higher capacity and performance. Both can be inflexible.
OpenDrives supplies storage software to the media and entertainment industry, appointing Sean Lee as CEO last month. Its Atlas 2.8 storage product has a composable architecture. It says all customers, regardless of storage capacity limitations, “receive a high-performance, enterprise storage software platform that can be configured according to creative workflow requirements.”
Trevor Morgan, OpenDrives VP of Product, said in a statement: “We are breaking the boundaries of traditional storage models to fully cater to content creators across the spectrum.
“In conversations with our customers, it was clear that they needed a storage solution that didn’t put them in a box, increasing costs as their creative requirements changed and capacity increased. Atlas 2.8 brings forth a scalable solution that doesn’t compromise on performance, capabilities, or affordability.”
OpenDrives claims this is a “game-changing shift from the industry-standard practice of storage pricing based on capacity.”
Morgan added: “We now have the ability to combine feature sets into larger ‘tiered’ bundles, which are designed for specific market segments. We can also offer smaller add-on feature packages that customers can combine with one of our standard bundles. We even offer the ultimate flexibility, à la carte add-on features, for those critical must-have capabilities without the need to step up to a more comprehensive (and more expensive) tier.”
There are two prepackaged software bundles: Atlas Essentials and Atlas Comprehensive. Core features of both include proactive data prefetching, atomic writes with checksums, and snapshots.
OpenDrives bundle feature contents
Atlas Essentials is for small, localized organizations and satellite offices. Atlas Comprehensive is for businesses and enterprises that might be highly distributed, and dealing with resource-intensive workflows. Both bundles come with unlimited capacity per controller, meaning you can add another 500 TB or 2 PB without additional software fees.
Upgrading or downgrading from one to the other only requires a new license key. Future releases will offer intermediary bundle tiers with different combinations of pre-packaged functionality.
Customers can purchase Atlas Essentials, which is certified to run on specific Supermicro hardware platforms, through select OpenDrives channel partners. Atlas Comprehensive is available through all OpenDrives partners.
Micron has launched a 9550 datacenter SSD using the PCIe gen 5×4 bus, and it looks to be among the fastest models currently available.
Update: Micron answers to questions about the new drive added; 26 July 2024. Update removed 27 July 2024!Micron sent invalid data.
The 9550 is built from 232-layer NAND in TLC (3 bits/cell) format, now termed gen 8 by Micron. It comes in three physical versions – E1.S, E3.S, and U.2. Micron classes it as a cloud (hyperscaler) high-performance and enterprise server NVMe drive developed with three trends in mind. AI workloads need more storage performance and infrastructure scalability, while electrical efficiency is increasingly important.
The 9550 follows on from Micron’s PCIe gen 4 7450 SSD, which used 176-layer NAND, and the 7500 built from 232-layer flash. Both the 7450 and 7500 came along after Micron’s earlier 7300 and 9300 PCIe gen 3 datacenter SSDs. The 7500 has faster sequential read and write bandwidth and random read IOPS than the 7450. With PCIe gen 5 bus support, the same 6-plane design, and Micron’s in-house controller ASIC and firmware, the 9550 is purported to be even faster.
A couple of charts show the maximum IOPS and bandwidth performance progression as the layer count and PCIe generations progress with these SSDs:
The 9550 demonstrates a major step up in performance compared to the previous generation. This is mainly due to the PCIe gen 5 bus being twice as fast as PCIe gen 4 but also helped by Micron’s controller.
There are two versions of the 9550, the read-intensive 9550 PRO supporting 1 drive write per day (DWPD) over its five-year warranty period, and the mixed-use 9550 MAX supporting 3 DWPD. The gumstick-sized E1.S format is only available with the 9550 PRO variant. Available 9550 PRO capacities are 3.84, 7.68, 15.36, and 30.72 TB. The 9550 MAX has lower capacity levels due to the over-provisioning needed to support the 3DWPD rating at 3.2, 6.4, 12.8, and 25.6 TB.
Both versions support TCG Opal 2.01, secure erase, boot and signed firmware, power loss and enterprise data path protection, and OCP 2.0.
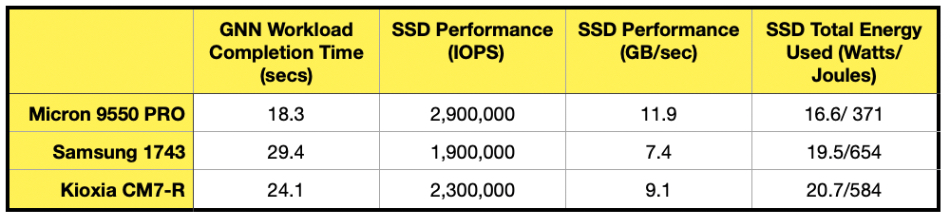
The 9550 is claimed by Micron to be faster than competing PCIe gen 5 devices from Samsung (1743) and Kioxia (CM7-R) except at sequential reading, as Micron’s numbers show:
It’s also said to be quicker and more power-efficient at AI GNN (Graph Neural Network) workloads:
This SSD efficiency is reflected in the total server energy used during the GNN training run, with the 9550-equipped server using 15 kJ, the Samsung 1743 using 21 kJ, and the server using Kioxia CM7-R SSDs needing 18 kJ. The server in question is a dual Xeon 8568Y, 48-core chassis fitted with an Nvidia H100 GPU.
Micron claims its 9550 is both faster than competing Kioxia and Samsung drives, and more power-efficient, leading to lower server electricity loads during AI workload runs.
Vector-specific databases and knowledge graph extensions are being promoted as a way to have GenAI large language models (LLMs) access unstructured and block data. SingleStore, a database provider, claims that you don’t need either to have great GenAI applications.
SingleStore provides a multi-dimensional database supporting both online transactional and analytic processing – OLTP and OLAP. It also supports external table access to massive unstructured data sets stored in Iceberg format. It provides a multitude of data search methods including relevance scoring, phonetic similarity, fuzzy matching and keyword-proximity-based ranking in full text search and also vector search.
The company’s assertion is that its Pro Max database is a real-time data platform designed for all applications, analytics and AI. It supports high-throughput ingest performance, ACID transactions, low-latency analytics, and structured, semi-structured (JSON, BSON, text) and unstructured data (vector embeddings of audio, video, images, PDFs, etc.) data storage.
Startups like PineCone, Qdrant and Zilliz have developed vector databases to store the vector embeddings of text, audio, images and video data used for GenAI’s semantic search. Proprietary data in such formats is being used in retrieval-augmented generation (RAG) to improve LLM response accuracy and completeness.
Raj Verma.
Such specialized databases are not favored by SingleStore. CEO Raj Verma told us in a briefing this month: “Two and a half years ago vector databases became every database company’s worst nightmare. … Because all the investors started to think that that was the just the ultimate way to solve it all, you know, world hunger, whatever.”
Vector storage is a feature, not a product.
“It’s just now that we’ve all seen that the vector layer will belong to the incumbent database. And no one’s going to add a layer of complexity by introducing yet another vector database into the data architecture.
“Yes, I think, you know, when you get off the gate, Pinecone had some advantage over the rest of us, right from within its vector capabilities, for sure. But we all caught up.
“What we’re seeing is, if you were to ask a organization what vector database they’re using, a vast majority – I’m talking about 95 percent plus – are going to say that they are using their incumbent database for the vector capability.”
Verma thinks that the vector-only database companies may not survive. As an illustration of how he sees it: “One of our investors said that there was about $4 billion spent on applications that helped do some form of AI for Adobe Photoshop. There was actually $4 billion worth of investments. So you could probably say $14 billion worth of market cap at which companies got investments at least. And then what happened is about eight months ago, Adobe released its AI suite of products on Photoshop, and all 135 of the startups are either dead, or they don’t know that they are dead yet.”
He thinks that GenAI and other major data access applications work best when they access a single virtual silo of data built for real-time and fast access. It provides a single point of management and support, a complete source of an organization’s data and simpler supplier relationships. And it includes both structured and unstructured data.
Vectors are representations of unstructured data, not structured data, as is stored in relational and other databases. That cannot be readily vectorized and much of a record’s context and meaning is encapsulated in row and column metadata. A startup like illumex says that the best way to representing this is using knowledge graph (KG) technology. Connector applications are then written to make such information available to the GenAI LLMs.
SingleStore does not support knowledge graph representations of structured data record meaning. Its position is that KG technology is not needed – particularly because, at scale, its data access rates are slow.
CMO Madhukar Kumar tells us that with structured data: “You need to get deterministic queries, answered at an extremely fast rate.”
He explained, “When it comes to knowledge graph, if you boil it down to first principles, it’s really the entity and the relationships. And you can store it actually in different ways. You can store it in a graph database, which is RDF (Resource Description Framework). But then you have ETL (Extract, Transform and Load). You have a whole different team moving data. It’s not really efficient when you’re talking about 10 petabytes of data, and trying to create something like a breadth-first search.
“Sure, it’s more efficient maybe. And it also maybe gives you more accuracy. But at the end of the day, a knowledge graph is an addition to a bunch of other things that you do – which is structured, unstructured, you do vector or semantic search, you do read ranking, and you do exact keyword match.
“One of our largest customers is LiveRamp, and LiveRamp used to have a graph database – the largest identity graph in the whole world. It’s a marketing analytics company and it’s massive. And they went from a graph database to SingleStore and their workloads that were taking about 18 hours or so came down to like 18 seconds.”
As with vector databases, SingleStore’s view is that any point advantages are neglible when set against the ones accruing to having a single, real-time source of database truth for an organization. In Verma’s words: “We have been saying for years and years that the time is now for real-time data. … Truly with AI now, it’s table stakes, because you are mixing and matching real-time context with your vast corpus of data that’s sitting everywhere in various different data types. That’s why we feel it’s really the perfect time for us.”
Interview. Object First, the Veeam-only backup target hardware supplier, is in a highly penetratable growth market because it prioritizes security over low cost/TB and can easily be sold by Veeam’s channel and bought by Veeam’s customers.
The startup was announced by Veeam co-founders Ratmir Timashev and Andrei Baronov in 2022. It provides its Ootbi backup target appliance with disk storage front-ended by an SSD ingestion cache and object lock-style immutability. Object First recently announced encouraging growth numbers and CEO David Bennett talked about Object First’s market fit in a briefing session last week. We’ve edited the session for readability.
David Bennett.
Blocks & Files: Talk about the founding of Object First.
David Bennett: When Ratmir and Andre sold the majority stake of Veeam back in 2019, you’d think two guys that make that kind of money would go off and sit on the beach somewhere, but not those two guys. They both said, what’s the first thing we’re gonna go and do? Why don’t we build a storage company to make Veeam a better company?
Why don’t we go and create a modern storage company that customers love, uniquely solves the security problem by not putting the burden on the user, and deals with a modern technology, which is S3, which is how the hyperscalers store data, but then bring it into a backup use case.
We launched in North America in last year and at end of last year and beginning of this year, we also extended into Europe. And Europe has been Veeam’s biggest installed base. Our big focus now is launching in Europe. And we’ve built an inside sales organization in Barcelona. We have a support organization in Poland and a development organization in Poland too.
We are recruiting like crazy. As a global company, we added 52 people already this year. We’re looking to add about another 35 people this year, and 26 of those are in Europe.
if you look at some of the results, you know we can talk about the big 700 percent plus year over year growth. Actually that’s not as important because actually this time last year, we were testing the product. So 700 percent is like, anyone could do 700 percent when you only sell one last year, and you sell seven this year.
What’s really more interesting is since Q4 last year, we’ve been able to grow north of 30 percent every single quarter. I have been really, really beyond happy in our growth. Because if you think about it: new company, new product in a space that’s dominated by legacy technology, and nobody runs out and goes and buys the latest storage product.
Blocks & Files: Are you still specifically focused on Veeam as a source for all the backup data you store? Or will you gradually open out to other backup software sources?
David Bennett: Everyone asks that question. And so my answer to that is, we are going to stay absolutely focused on Veeam for three predominant reasons. Number one, is, if you create a storage product that is designed for multiple vendors and product sets, you actually become mediocre. Because if you create a product, it’s got to work with the Commvault, Veritas, Avamar, etc. I mean, how many other backup software solutions are there?
Number two is, because of being able to try and create a product that operates across multiple vendors, there is no way you can ensure the highest level of security across every single one of those vendors.
And then, as you think about growing an organization, building a sales team, building a market and uniquely solving a problem, it’s way easier for me to say we uniquely solved the one problem that Veeam has, which is a complex storage environment that is insecure. And so from a kernel market perspective, I’m just absolutely focused on uniquely solving that that Veeam problem. And Veeam has 550,000 customers globally.
Blocks & Files: You’re not target-restricted.
David Bennett: We’re not target-restricted at all. If we penetrated that customer base 20 percent, we’d be a billion dollar storage company. That would put us in the number two position behind Dell if we did nothing else.
Blocks & Files: Will you add deduplication capabilities to the product?
David Bennett: Great question. Simple answer is, is no, we will not. And here’s the reason why: Every other product and storage vendor has tried to create their own tech stack and say we do all these cool things. What we’ve said is, why don’t you use the power of Veeam as that already has dedupe, and manage it and use the the power of Veeam? We leverage that on our box and our software stack, rather than saying we need to go and create this feature or functionality of dedupe, or encryption and things like that. That makes zero sense.
Blocks & Files: You could add hardware compression?
David Bennett: We could add hardware compression. Again, the way I think about it is, let’s tie our product to how Veeam should be working to get the power of Veeam, and then you’re going to get the outcome you would have had.
Blocks & Files: Okay, I’m a Quantum DXi channel salesperson. I’ve listened to what you’ve said, and I’m really, really happy. Because my cost per terabyte of backup effective backup data storage is way way lower than yours is going to be. Because I dedupe and compress and you don’t.
David Bennett: My answer to that is, what’s the point of deduping and compression if someone gets into your Quantum backup repository and deletes the data? Absolutely zero. And the big difference between us and all these other guys is, is two things.
I’m more paranoid than anyone about everything, and don’t trust any anything. And we built our product from the ground up and designed it with a zero trust architecture from day one.
If you think about everyone else, all of these legacy companies, they’re good products. But they were designed for a world that existed five or six years ago. So by designing a product with zero trust by design, we took the view that we’re going to assume the bad guys have got access to your VM credentials. We’re going to assume the bad guys get the admin credentials into our infrastructure. And, by the way, we’re also going to assume the bad guys have been sniffing around your business and everything anyhow. And so even if somebody has access to the VM server, has access to our UI, they cannot go and delete information on the device. So sorry, we’re very different from everyone else.
Some vendors say they are immutable – until you have to get root access to go and change something. But as soon as you give someone root access, you might as well just give them the keys to your kingdom, because you’ve given them literally the ability to go and delete something.
Blocks & Files: So from your point of view, you’re talking to customers who are sensitized to malware and ransomware. And whose priority is ensuring they’ve got clean backups from which they can recover. They are going to get hit by ransomware. They need clean backups to recover from and this is far, far more important than a lower dollars per terabyte of backup capacity.
David Bennett: Absolutely. And we will always say to people you have to modernize your backup tech stack. Everybody rushes out to go and buy the latest security product. Maybe don’t try CrowdStrike after this latest problem! Everyone says I get about security and adds a new security layer. People aren’t yet thinking about that in the backup world, because the backup side has always been like this ugly stepchild. But what we’re saying to people is, it needs to be elevated to a first class citizen. Because if you have no data in a business, you have no business.
And what you need to do is, you need to have a fully, truly immutable storage solution that operates on a zero trust framework.
Blocks & Files: Does the public cloud have a role?
David Bennett: You should absolutely also include the cloud. For archiving and things like that, the cloud is awesome. You should absolutely use the cloud. You should archive your backups after seven days, 14 days to the cloud.
The problem is, is if you want to recover 30, 40, 50, 100 terabytes from the cloud, two things are going to happen. One, they’re going to charge you. So not only have you been kicked in the shins, by being hacked, you’ve been kicked in the shins because you have to pay to get your information back.
And then it’s going to take you four to six weeks to get that information back because they’re going to throttle it. That’s a bad scenario. And so what we’re saying to people is, you need to modernize your security tech stack. You need to solve the number one problem, which is: you don’t have any data, you have no company.
Blocks & Files: Are you going to scale out your clusters to more than four nodes?
David Bennett: That’s a marketing limit, because I don’t want sales reps going and chasing Fortune 500 companies for instance. The simple answer is, there is no technical restriction on the scale over four. With Veeam’s latest update they allow something called multiple scale-out backup repositories.
There’s actually a benefit as, instead of saying, let’s create one large, monolithic cluster of let’s say, 12 boxes, if you wish create three different sets of four clusters. That’s an order of magnitude, even higher security level from a customer perspective.
In Veeam’s 12.1, you can have these multiple backup scattered repositories all look like one. And the data is segmented between them. Another benefit is it’s all managed in Veeam. It all looks very simple to manage.
Blocks & Files: Will you think about adding all-flash systems, or are you content with a flash landing zone and then just letting Western Digital and Seagate bring you bigger and bigger discs?
David Bennett: The simple answer is, I could see potentially in the future – and this is like a year for us – then maybe there’s a benefit with an all-flash capability.
I think the question is, what are we trying to solve for? Today, with flash ingestion to hard drive, we’ve seen zero bottleneck – even with companies that have 100 terabytes backups and things like that. Speed is not a problem today. And normally you’re going to flash because flash gives you faster ingest and faster recovery.
Obviously, as our business grows, as we become more and more proliferated in our customer base, we may see segments of the customers that today we’re not targeting. Because ‘I don’t have a mission-critical financial system,’ or ‘I’m not a telco that for every minute, I’m down, I’m losing 10 million bucks.’
In the future, that may be a need. Today, we don’t see that need. Today, we’re more than enough covering the speed requirements of the customer base that we’re targeting.
Blocks & Files: You’re selling into accounts that, before you knock on the door, are storing backups somewhere else. I think by definition, you’re taking business from somebody else. Have you made enough sales to start getting a feel of who you’re taking share from?
David Bennett: I think there’s actually three or four answers to that.
You’re absolutely right, everybody has already got something. But we’re also a new category. We had a pretty large regional school in North America said that a school down the road got hacked. They called us on Thursday, and said, ‘I don’t have an immutable backup solution, I already have a storage infrastructure. If I don’t get something in, I am worried that literally, I’m going to be the next guy.’ And that business closed within an eight hour window.
The second piece is, as we know, the storage industry has typically historically always been on storage lifecycle refresh rates. So everyone says, ‘I’m going to refresh my storage infrastructure between the three and five year period.’ Just happens. So in that scenario, okay, yeah, we are replacing other vendors. They’re the vendors you mentioned [Dell PowerProtect, HPE StoreOnce, Quantum DXi, Veritas.] Honestly, it’s a mix across all of them.
Because now we’re now we’re able to say, here’s a modern solution, it frees you from the backup admin hell that you’ve had to actually go and do something that’s worthwhile for your organization, rather than doing maintenance.
What’s interesting here, as well, as you think about the reseller marketplace. If you’re a Quantum partner, or HPE partner and Dell partner, you’re going to say, ‘Hold on a minute. I’m already selling HPE.’ Well, they don’t do what we do. So we’ve been able to go to those partner networks and say, it’s a new category.
What’s also interesting is a lot of Veeam partners are software-centric resellers. Software-centric resellers don’t want to go anywhere near hardware and they certainly don’t want to go anywhere near storage infrastructure, because it’s technically challenging to sell. Well, now they’ve got a product they could sell into a customer base and know intrinsically. I mean, the product’s so easy to set up, even I can do it.
And it gives them more money. And ultimately, somebody else is already selling into their customer. So they get more account control.
Blocks & Files: So Object First is Veeam first?
David Bennett: Obviously we’re two separate companies. We’re not affiliated with Veeam or anything like that – OK, founders aside, etc. But if you think about Veeam, it wants to make its customers happy. It’s a win win. We only win if Veeam wins. And so we’ve got one focus – which is to make the Veeam ecosphere better and more secure.
Pure Storage‘s International CTO thinks we’re rushing towards scalability limits in storage, networking, and software dataset size.
Alex McMullan offered Pure Storage’s stance on the scalability topic, its dimensions and issues, at a briefing in London this month. The starting point was incoming higher capacity Direct Flash Modules (DFMs) from Pure – its NAND drives, with 75 TB are shipping, a 150 TB model was previewed at its Accelerate event in Las Vegas, and a 300 TB version is on the roadmap.
Alex McMullan
McMullan said: “We’ll be making some announcements in the next couple of months.”
He thinks Samsung and other NAND suppliers are positive about reaching 500 and even 1,000 layers, and building petabyte-capacity drives.
SSD capacity is being driven higher by having more layers in a chip – Micron is at the 232-layer level, for example, and possible cell expansion from QLC (4 bits/cell) to PLC (5 bits/cell). Such higher capacity NAND drives will need more capable controllers to handle the data placement, drive wear, and garbage collection (cells with deleted data collected together and returned to use). A 150 TB drive has 150 trillion bytes to track, 1.2 quadrillion bits, and that’s without adding in an extra 10-20 percent for over-provisioning. The controller’s metadata storage and handling for this represents a major task and processing load.
“It’s much more likely that we will even retrench from QLC to go to higher numbers of layers, where you’re kind of mid-hundreds to high hundreds later this year,” McMullan added.
But he added: “There’s two different sides to this in terms of can we and then should we?”
Carbon footprints
Such silicon devices come with a relatively high embedded carbon content. “A Pure Storage array weighs about 40 to 50 kilos, depending on where it’s delivered in the world. But the CO2 footprint of that is 100 times higher. The data sheet will tell you that that same box represents 4,000 kilograms of CO2 from a manufacturing perspective – of which 92 percent is the silicon process, from cradle to grave in terms of mining a rock in a desert somewhere to crush it, to refine it, to redefine it, turn it into a wafer, and then to etch that.”
“The question is, then, if we’re heading – if you buy into the Gartner and many other analysts’ view – towards the zettabytes and then yottabyte era, can we continue to incur that same carbon cost? And what can we do about that to mitigate it?”
McMullan said Pure enterprise customers are serious about embedded carbon reduction, meaning embedded carbon in the arrays as well as ongoing electricity consumption.
“There’s a number of things we’re working on, in terms of the usual… hardware engineering, in terms of better algorithms for this and more efficiency from our suppliers.”
“We’ve foreshadowed that we’ll be building more power optimization into our platforms to run a power cap, rather than at full tilt, or to optimize with artificial intelligence to run the systems at lower power when it expects to use less… So those are all things that we’ve started already.”
“Let’s assume we continue with them in the short term. And we make a petabyte drive. I think it’s more than likely that we will hit that milestone … We’re actually working with the NAND firms [alredy] in terms of what the chip might look like, for that size drive.”
Post-NAND green drives
“Obviously, we’re in that transition from one terabit to two terabit die packaging. But we’re heading in terms of the roadmap way beyond that; four or five times, four times anyway. But finally, how we take that forward at that point is, do we continue with the paradigm?”
Meaning the NAND SSD paradigm. He mentioned a trio of alternative candidate technologies.
“I guess the three primary candidates are optical media … The second one, you’ve got the various PMems and you’ve got the MRAMs, and ReRAMs still sitting at a gigabit … that’s great for embedded systems. But we’d need thousands and thousands of chips to get even where we are today (with NAND).
“That kind of leaves you with … DNA storage, which, on the face of it, sounds very green. But given where that research direction is going, again, that involves silicon chips.
“It’s not just growing a short strand sequence and putting it in a test tube or a freezer. What they’re calling enzymatic DNA research is heading towards essentially, producing small silicon chips with little drill holes, basically you’d plug in the written medium inside each of those little holes. And then access them via silicon, which means a lot of the same embedded carbon that we already have.”
In his view, “DNA has a great story in terms of data density and can be made to work, but the current … sensor size is so painfully slow …. four bits an hour or something. Wonderful. It’s great if you want to be sending Morse code messages. But in terms of recording videos … I think it has 10 or 12 orders of magnitude to climb before it catches up with where we are today [with NAND].”
Which means that “maybe there’s a long term capability for archiving or those aspects. But realistically, that’s not a 2030 thing we think at this point in time.”
Then there is a fourth alternative: Ceramic etching on a glass substrate, like Cerabyte’s technology. McMullan has talked with Cerabyte’s US exec Stefen Hellmold.
Unlike NAND or DRAM, there is no direct electrical connection to a cell and so access time will be slower than NAND. McMullan thinks: “It’s time first byte, I think, was less than a minute. Now, maybe there’s a way around that, caching or prefetching.”
Networking
However, this is only one aspect of a multi-dimensional scaling problem. McMullan said: “We’re hearing feedback and thought processes from our customers, particularly those who are dealing with petabytes, in some cases exabytes already, and not just for AI workloads.”
“Everybody’s having the same challenges in terms of data management, data gravity, the throughput aspects that go with that, not just on the box, but also off-box.” He mentioned “Nvidia’s dominant position over InfiniBand and on Spectrum X.” That monopoly is not good, he said.
“We’ve signed up to the Ultra Ethernet Consortium as a company because we think that … Ethernet is the way forward but also that it needs to hurry up and scale … We are at 400 gig on the Ethernet side of things. We already have customers asking for 800.”
“You’ve got things like CXL, which we’re pushing on now. Specification 3.1 brings us pooling and sharing and memory. You’ve got CXL over fiber optic, which is an interesting development. And all of this is aimed at accelerating the shipping of data.”
Assuming you can store the coming massive datasets by federating systems and ship data across a network fast enough, “data scientists are telling us in terms of, we’ve got this giant cluster, we’ve got a whole massive, rapidly changing data set, which will mean indexing and tagging with rank-based technologies, huge factor databases hanging off the back of it, which are in some cases getting off at the same size as a source dataset – which was a thing that shocked a lot of people. There’s almost a double whammy when it comes to the AI tag on these things.”
He said: “I think PCIe 5 will, again, have hardware iterations on that next year. But it’s only incremental. It’s not foundational.”
This coming limit in NAND drive scaling and networking and the lack of fast enough alternatives to NAND that are also green is puzzling McMullan, along with software problems.
Software
He said: “It’s really about where we can go now in terms of where our engineers are telling us. It’s great talking about all these big drives that we’re going to make and ship. But how do we solve for a file system with 10 trillion objects in it? This is two orders of magnitude beyond what customers use today, but in the same time frame by 2030, which is where we’re pushing the engineers to go?”
“That’s what most of our focus is now, in terms of how do we build a system, which is two orders of magnitude bigger or better, or everything here that we bought today? That has impacts on compute, on memory, on networking, on bandwidth, as well as it’s actually a bigger software problem [than] hardware. We can throw more hardware at these things easily. We can go to four to eight to 12 controllers if we wanted to. How do we solve for the datasets?”
“We’re doing a lot more work on the algorithm side, on the data management data reduction side of things. … We shipped a compression card by default on bigger systems last year. There’s now a second generation of that card coming based on what we’ve seen in terms of actual telemetry, and workload profiles and cardinality.”
This is incremental, though, not foundational.
“There’s a computer science challenge with that …We support a billion files on a file system currently. And we’ve got some use cases where they’re asking for 10x. And that’s OK. But if you have to have a test system to test 200 million files in a single directory, you’ve got to have something that makes 200 billion files in the directory, which takes in some cases, days, weeks.”
“We’re now operating a scale of test where we use actual arrays as a pseudo-drive connected to another array in a test system. So we effectively have a Pure FlashArray, which is passing itself out to a bunch of other arrays and offering itself up as a drive each of these. And there’s more testing at scale currently. We’ve got a 500 terabyte drive that has been tested by us – but it’s actually an array with a pass-through connection to an appliance … That’s part of our test set up in the labs now.”
“The big problems are the carbon impact, and the software engineering to build this kind of scale. Everything else is easy. If we could magically mine pure silicon wafers out of the field, that’d be great. But it’s the impact that we’re focused on … That’s a big direction of travel for us in terms of is there a way of leveraging carbon-friendly media in our future roadmap?”
“It’s a fascinating time to be in tech. But you do feel that everywhere you go, now you’re in that maze, and there doesn’t seem to be a way out. It’s just a question of how long you can run on … We can blindly carry on and make bigger and more powerful systems based on that. But there will be a point where we have to acknowledge that the whole manufacturing chain needs to to change dramatically.”
“It’s interesting in terms of where we might go from there and lots of befuddled engineers are scratching their heads about what the 2026 platforms look like. It’s a big deal. But we’re at that point where we almost tear everything up and start again. That’s what it feels like.”
McMullan thinks he and other IT technologists in the enterprises and suppliers he talks to, who are all aware of these coming scalability issues, will likely be retired before ways of solving the problems he’s identified come along.
A lack of comprehensive data strategies among Global 2000 enterprises is curtailing use of AI tools and undermining business goals, according to research.
Nearly 85 percent of enterprise leaders agree that effective data management significantly drives top line, bottom line, and shareholder value, but they believe “over 40 percent” of their organizational data is “unusable.” This junk data is either “not trusted,” “lacks quality,” hasn’t been updated, or is inaccurate, duplicated, or “inconsistent.”
Improving operational data availability to integrate AI tools is emerging as the “number one” challenge for supporting overall AI technologies, among top execs, with unified data management deemed “critical.”
Kevin Campbell, Syniti CEO.
Analyst house HFS Research, commissioned by enterprise data management firm Syniti, compiled the report: “Don’t drown in data debt, champion your data first culture.” For the above findings in the report, more than 300 Global 2000 business leaders across different industries were interviewed, to find out how their organisations are trying to navigate a complex data management landscape.
“Data debt” can include outdated data structures, poorly documented data sources, inefficient data processing, and improperly secured data.
The report recommends five “strategic principles” that will enable “meaningful progress” in addressing data debt and championing a “data first” culture:
Data isn’t just IT’s problem, it’s a core business issue. The strategic goal for data management is to facilitate seamless end-to-end business processes, supporting the “OneOffice” experience, where people, intelligence, processes, and infrastructure come together as one integrated unit, with one set of business outcomes.
Data and AI have a chicken-and-egg relationship. You need to address both together. Better data management is the number one initiative to leverage AI capabilities better.
Measure the impact of bad data – it’s critical to reducing your data debt. Less than 40 percent of organizations interviewed have methods and metrics in place to quantify the impact of bad data.
Data is a huge people issue. The shortage of specialized talent is one of the top three challenges in data management.
Professional services need to be reframed as business data services, with a focus on outcomes, not effort. Nearly 90 percent of enterprises rely on third-party providers for data initiatives. However, focusing on effort rather than results leads to inefficiencies. Enterprises must demand providers prioritize meaningful results to drive true value.
“We are now at an inflection point in the evolution of data skills, from generalists to specialists. Data work is unique and complex and requires 100 percent dedicated focus to build specialized skills, training and needed career paths,” said Kevin Campbell, CEO of Syniti. “To achieve real, tangible business benefits from your data, you need skilled data specialists who understand data in context, not business generalists or developers.”
Phil Fersht, CEO and chief analyst at HFS Research, added: “Many business leaders still take a back seat when it comes to setting key data objectives, causing data to remain siloed across departments, and resulting in misaligned expectations across IT and business professionals.
“The focus for enterprise leaders must be on developing strategic talent that understands the business context behind the data.”
Lancaster University spinout firm Quinas has sealed £1.1 million ($1.42 million) in new project funding from a UK government investment vehicle, to coordinate the first step towards volume production of the universal computer memory ULTRARAM.
ULTRARAM was invented by Lancaster University physics professor Manus Hayne, and combines the non-volatility of data storage memory, like flash, with the “speed, energy-efficiency, and endurance” of “working memory” like DRAM, Lancaster University said. It is seen as a power-saving and carbon-reducing technology.
Blocks & Files last reported on Hayne’s efforts in April, 2023, and the ULTRARAM technology, which has previously been patented in the US, is now moving to commercialization with the establishment of Quinas – not the Portuguese beer brand.
ULTRARAM exploits quantum resonant tunnelling to achieve its properties and is implemented in compound semiconductors that are used in photonic devices such as LEDs, laser diodes and infrared detectors, but not in digital electronics, which is the preserve of silicon.
The investment cash is coming from Innovate UK, with the project also involving global semiconductor company IQE, Lancaster University, and Cardiff University. This latest award takes total grant funding for ULTRARAM to £4 million ($5.17 million).
Most of the funding for the new one-year project will be spent at IQE, which will scale up manufacturing of the compound semiconductor layers gallium antimonide (GaSb) and aluminium antimonide (AlSb) at its Cardiff, South Wales facility.
Top3 Quinas execs
Professor Hayne, who is the Lancaster University team lead, and co-founder and chief scientific officer at Quinas, said: “IQE has committed to developing the first part of ULTRARAM mass production, with it representing a tremendous economic opportunity for the UK. The efficiencies it could bring to computing at all scales has the potential for huge energy savings and carbon emission reduction.”
“We are supporting our spin-out Quinas on its journey to an industrial process suitable for a semiconductor foundry fab,” added Jessica Wenmouth, Lancaster University head of research commercialization.
“Such collaborations are crucial for bringing new products to market and driving significant investment into the UK for emerging technologies, enhancing our national and global standing in cutting-edge fields.”
The goal of the project to industrialize the process involves scaling up ULTRARAM wafer diameters from 75mm (3-inches) at Lancaster to 150mm (6-inches) at IQE. This in intended to be achieved using the mainstream production technique of metal-organic vapour phase epitaxy (MOVPE), also called metal-organic chemical vapour deposition (MOCVD), rather than molecular beam epitaxy (MBE), which is typically used at universities.
Hayne added: “Lancaster will do some initial MBE epitaxy as a control/template for the industrial growth. Our key role will be to characterise the antimonide material grown at IQE, and once sufficient quality is confirmed, we will fabricate and test ULTRARAM memory on small areas of the wafers from IQE.”
In parallel with this, Lancaster will continue to work on ULTRARAM scaling, by reducing the size of individual devices, and making larger and larger arrays. Once devices are small enough and arrays are large enough, the following stage will be to demonstrate fabrication on a complete 200mm (8-inches) wafer, and then to translate the process to an industrial one, suitable for a semiconductor foundry fab.
Dr Peter Hodgson, who is the overall project leader, and co-founder and chief technical officer at Quinas, said: “A memory combining non-volatility with fast, energy-efficient write and erase capabilities has previously been considered unattainable. ULTRARAM’s ability to switch between a highly resistive state and a highly conductive state is the key to its unique properties.”
ULTRARAM’s energy efficiency is reportedly impressive. It is said to have a switching energy per unit area that is 100 times lower than DRAM, 1,000 times lower than flash, and over 10,000 times lower than “other emerging memories”. Its ultra-low energy credentials are further enhanced by its non-destructive read and non-volatility, which removes the need for refresh.
AIM-listed IQE is headquartered in Cardiff and has eight manufacturing sites across the UK, the US and Taiwan.
Suppliers and JEDEC are bringing their HBM4 plans forward as they suspect the forecasted Gen AI boom means incoming Nvidia GPUs will need it sooner.
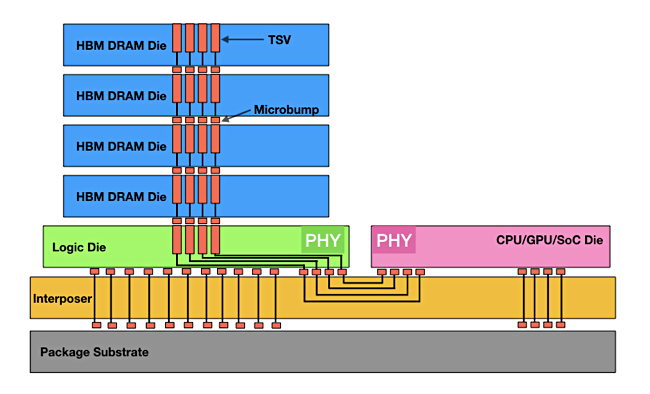
High bandwidth memory (HBM) bypasses X86 socket-connected DRAM capacity and bandwidth limits by having memory dies stacked on top of a logic layer, with interconnecting TSV channels, all linked to a GPU via an interposer component providing higher bandwidth than X86 sockets. The Joint Electron Device Engineering Council (JEDEC) confirms and issues HBM standards, with the current one being its fifth, HBM3E (extended).
Generic HBM diagram.
The main HBM suppliers are SK hynix, followed by Samsung and then Micron. In April SK hynix saw first 2024 quarter revenues soar 144 percent due to HBM chip demand from Nvidia, which packages them with its GPUs. TrendForce says the HBM market is poised for “robust growth,” driven by pricing premiums and increased capacity needs for AI chips.
Micron is building 24 GB HBM3e chips, with 8 x 3 GB stacked DRAM dies (8-high), for use by Nvidia in its H200 Tensor Core GPUs. It also has a 12-high device with 36 GB capacity and >1.2 TBps performance. Samsung has its own 12-high, 36 GB HBM3e device, with up to 1.28 TBps bandwidth.
JEDEC has said it will issue a completed HBM4 spec by the end of this year – just few months ago the schedule was for a 2025 delivery. Preliminary HBM4 characteristics are emerging already.
An HBM4 controller will able to control HBM3E DRAM. HBM3E chips have a 1024 bit wide channel which HBM4 doubles to 2048 bits. The maximum number of stacked DRAM dies with HBM3E is 12. HBM4 increases that by a third to 16, with both 24 Gb and 32 Gb layers supported. This will give a boost to both capacity, with up to 512 Gb (64GB) supported, and bandwidth up to 6.4 GTps, meaning the host GPU can get more data faster, and so process bigger large language models.
A 16-high stack is, obviously, higher than a 12-high stack and JEDEC is considering increasing the HBM chip maximum height parameter from 720μm to 775μm. One way to reduce the height is to move to smaller process technology.
TSMC and SK hynix originally planned to use a 12nm 12FFC+ process but are now intending to add 5nm N5 process technology. Samsung says it is going to use 4nm technology for its HBM4 logic die, which will increase the die’s performance and lower its power consumption compared to the 10nm process used for its HBM3E chips.
A diagram in Korea’s JoonAng shows an SK hynix HBM4 stack directly-connected to a GPU. We haven’t been able to translate the Korean characters.
A direct HBM-to-GPU connection, obviating the need for an interposer component, would shorten the distance between DRAM and GPU, speeding data access. However thermal design limits could prevent HBM4 stacks being bonded directly to a GPU. Two warm devices could make a single hot one difficult to cool.
Generic diagram showing direct HBM-to-GPU connection.
Whatever the outcome of these issues we can be confident that the fierce competition between SK hynix, Samsung and Micron will produce GPU systems with HBM4 accessing more memory faster and making Gen AI LLM development both more affordable and able to scale out to larger models.
Pure Storage’s Portworx product is ahead of other suppliers of storage for Kubernetes-orchestrated container apps, at least according to research house GigaOm.
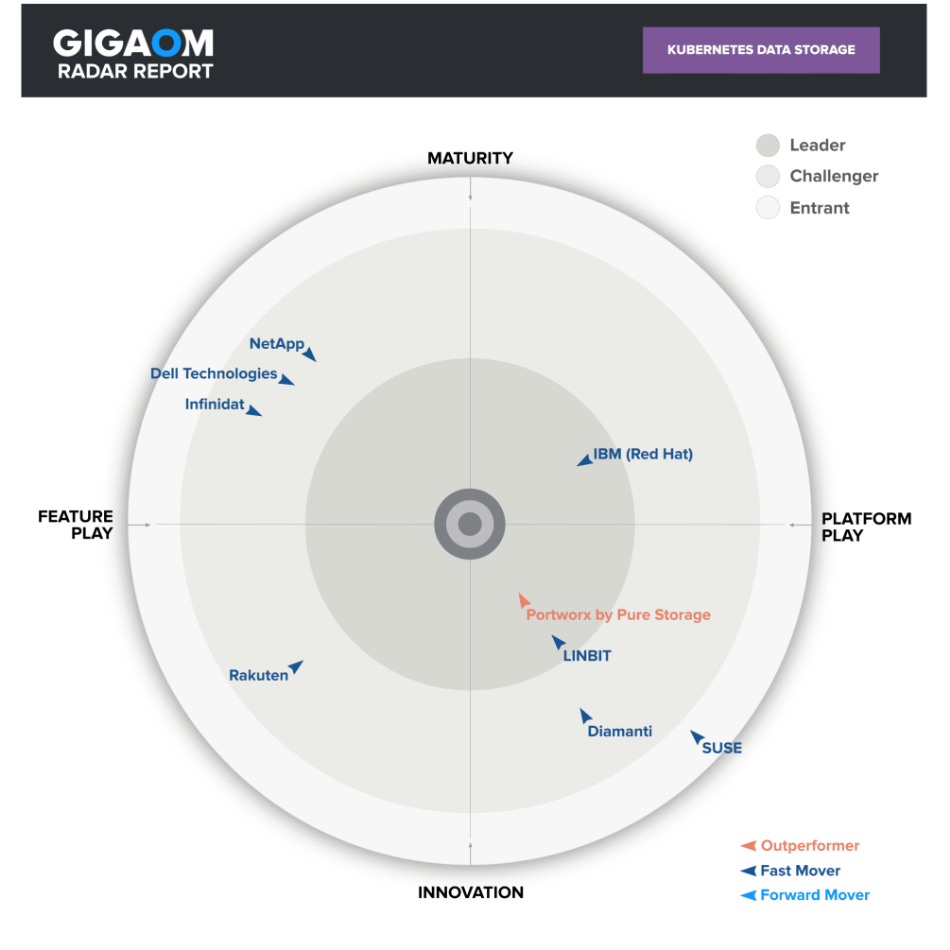
The GigaOm Radar for Kubernetes Data Storage report looks at nine vendors, down from 22 rated in separate cloud-native and enterprise reports previously. These include Dell, Diamanti, IBM (Red Hat), Infinidat, LINBIT, NetApp, Pure’s Portworx, Rakuten and SUSE. Their products are either traditional enterprise storage re-used for Kubernetes referring to Dell, Infinidat and NetApp, or Kubernetes-native storage, which covers the other six suppliers.
Analyst Joep Piscaer describes Kubernetes-native storage this way: “The storage system itself runs as a set of containers on a Kubernetes cluster, exposing storage via container storage interface (CSI) to the cluster to be consumed by workloads. These distributed storage solutions are tightly coupled with the container orchestrator and are container-aware so that when the orchestrator spins up or destroys a container, it also handles storage provisioning and de-provisioning operations. Storage operations are automated and invisible to the user and scale up and down based on cluster size.”
The traditional enterprise players are grouped together, with “feature parity” according to Piscaer, in the mature-feature play quadrant of GigaOM’s Radar diagram (see bootnote) while the K8S-native suppliers are placed in the three other quadrants.
Portworx is the clear leader in terms of innovating faster than all the other suppliers and with a balance of being innovative and a platform supplier. It is followed by IBM’s Red Hat and then LINBIT, with all three in the Leaders’ section of the chart.
There are five challengers, which includes the three trad players followed by SUSE, classed as an entrant. Only Portworx is classed as an outperformer with the rest rated as fast movers.
Piscaer writes: “Portworx remains the gold standard in cloud-native Kubernetes storage for enterprises. Portworx is a complete enterprise-grade solution with outstanding data management capabilities, unmatched deployment possibilities, and superior management features.”
In an emerging features comparison Diamanti (4) scores higher than Portworx (3.5) on Generative AI support, Edge support and fleet management. LINBIT (4.8) is placed ahead of Portworx (4.3) in business criteria such as efficiency and manageability.
GigaOM subscribers can access the Kubernetes data storage supplier report here.
Bootnote
The GigaOm Radar diagram locates vendors across three concentric rings, with those set closer to the center judged to be of higher overall value. The new entrants are in the outside ring, challengers in the next inner ring, and leaders in the one closer to the center after that. The central bullseye area is kept clear and positioned as a theoretical target that is always out of reach.
The chart characterizes each vendor on two axes – balancing Maturity versus Innovation and Feature Play versus Platform Play – while providing an arrow that projects each solution’s rate evolution over the coming 12 to 18 months: Forward mover, fast mover, and outperformer.
GigaOm says mature players have an emphasis on stability and continuity and may be slower to innovate. Innovative suppliers are flexible and responsive to market needs. Feature players provide specific functionality and use case support while perhaps lacking broad capabilities.
Platform players have the broad capability and use case support with, possibly, more complexity as a result.
Expanding data management provider Denodo has hired Christophe Culine as its first ever chief revenue officer (CRO) to help accelerate the global growth of the business.
Culine brings over 25 years of experience in leading early- to mid-stage technology companies to growth. Before joining Denodo, Culine served as president and CRO at cyber security firm Dragos. He has also held key sales and CRO roles at RiskIQ, Qualys, Fortinet, and Venafi.
Angel Viña.
Now reporting directly to Denodo founder and chief executive officer Angel Viña, he will be responsible for developing and executing strategies to further enhance Denodo’s market position.
“Christophe’s track record as a successful sales leader and CRO for high-growth organizations is impressive,” said Viña. “His focus on customer satisfaction and his expertise in building world-class sales teams align perfectly with our goals.”
Culine added: “As a definitive leader in logical data management, Denodo’s commitment to delivering data in the language of business, at the speed of business, resonates with me. I look forward to contributing to the company’s ongoing success and growth.”
TPG, a global alternative asset management firm, invested $336 million in Denodo in September 2023.
Denodo’s global presence spans offices across the Europe, Middle East, Africa, Asia-Pacific, North America, and Latin America regions. Its customers include the US Federal Aviation Agency (FAA), which is using Denodo to reduce costs and streamline its IT operations, through consolidating multiple data platforms into one “modern data platform.”
Christophe Culine.
Denodo’s data virtualization capabilities have enabled the FAA to logically integrate hundreds of data sources, including software asset inventories, project data, contracts, Microsoft SharePoint sites, databases, and spreadsheet files. Ultimately, the consolidation and modernization project helped reduce IT operations costs by 99.8 percent, while “accelerating data access” by 96 percent, reported the FAA.
Last month, the supplier launched Denodo 9, equipped with AI-enabled data delivery. We’re told this version enables intelligent data delivery through AI-driven support for queries delivered in natural language, “eliminating the need to know SQL.” In addition, Denodo 9 has the ability to provide large language models (LLMs) with real-time, governed data from across the enterprise, powering retrieval-augmented generation (RAG) for “trusted, insightful results.”
As part of the NetApp Keystone Partner program, the ePlus offering combines flexible subscription models for storage consumption with ePlus technical support and customer success resources.
With its offerings, ePlus promises “accelerated issue resolution” to minimize downtime, enhanced capacity planning with insights into usage patterns and billing, and a pay-as-you-grow model to align storage costs with actual consumption to “eliminate” over-provisioning.
Justin Mescher.
“Our commitment is to provide customers with the industry’s best technologies in a cloud-like experience for their on-premises datacenter infrastructure,” said Justin Mescher, vice president of AI, cloud and datacenter solutions at ePlus. “Customers can now leverage enterprise-grade NetApp technology, backed by our dedicated support and customer success team, for a worry-free, scalable storage solution.”
NetApp Keystone promises to deliver a hybrid cloud experience in a single subscription, “reducing the burdens” of managing data storage, and allowing IT teams to focus on “driving beneficial outcomes” for the business.
David Sznewajs, vice president of the US partner organization at NetApp, said: “By working with ePlus, we are giving more organizations the chance to benefit from a fully managed service that can grow and scale with their business, supported by a team of experts to offer technical support and customer success.”
David Sznewajs.
US systems integrator IGXGlobal is a subsidiary of ePlus Inc. It recently started to offer its customized storage as-a-service, powered by Pure Storage Evergreen//One, to customers across the UK and Europe.
Pure Storage overhauled its partner program earlier this year in response to to its expectation that half of its revenue will come from subscriptions, as it shifts from product sales to become an as-a-service supplier.
Technology systems and managed service provider ePlus is headquartered in Virginia, with other locations in the US, the UK, mainland Europe and the Asia‐Pacific region.
Its annual results for the full year ended March 31, 2024, showed that net sales increased 7.6 percent to $2.22 billion when compared to the previous year, with services revenues jumping 10.4 percent to $292.1 million.
The total consolidated gross profit increased 6.4 percent to $550.8 million. Net earnings decreased three percent to $115.8 million, and the adjusted EBITDA decreased 0.1 percent to $190.4 million