Data processing unit (DPU) startup Fungible has launched a Storage Initiator card supporting NVMe/TCP and says it makes deploying NVMe/TCP effortless in existing datacentres.
The card is the latest member of its Fungible Storage Cluster product range and is claimed to deliver the world’s fastest and most efficient implementation of NVMe/TCP. It uses Fungible’s S1 DPU chip and, Fungible says, enables the benefits of pooled storage without sacrificing performance.
Eric Hayes, Fungible CEO, said: “With our high-performance and low-latency implementation, Fungible’s disaggregated NVMe/TCP solution becomes a game changer. Over the last five years, we have designed our products to support NVMe/TCP natively to revolutionise the economics of deploying flash storage in scale-out implementations.”
The company says it offers technology, managed by Fungible’s Composer, to unlock the capacity stranded in silos by disaggregating these resources into pools, and composing them on-demand to meet the dynamic resourcing needs of modern applications.
There are FC200, FC100 and FC50 storage initiator cards, and a single FC200 card is capable of delivering 2.5 million IOPS to its host. The SI cards are available in a standard PCIe form factor, manage all NVMe/TCP communication for the host, and in turn present native NVMe devices to the host operating system using standard NVMe drivers. The cards offload the processing of NVMe/TCP from the host, freeing up approximately 30 per cent of the general-purpose CPU cores to run applications.
This approach enables interoperability with operating systems that do not natively support NVMe/TCP, such as Windows, older Linux kernels and macOS.
Fungible claims that, when paired with a Fungible FS1600 storage server node or other non-Fungible NVMe/TCP storage targets, the SI cards enhance the performance, security and efficiency of those environments, as well as providing the world’s highest-performance implementation of standards-based NVMe/TCP.
It also says these cards allow datacentre compute servers to get rid of all local storage — even boot drives — allowing the complete disaggregation of storage from servers.
In the last few days NetApp announced NVMe/TCP, followed yesterday by VMware and Dell, and now today Lightbits and Fungible. It’s becoming an open house party.
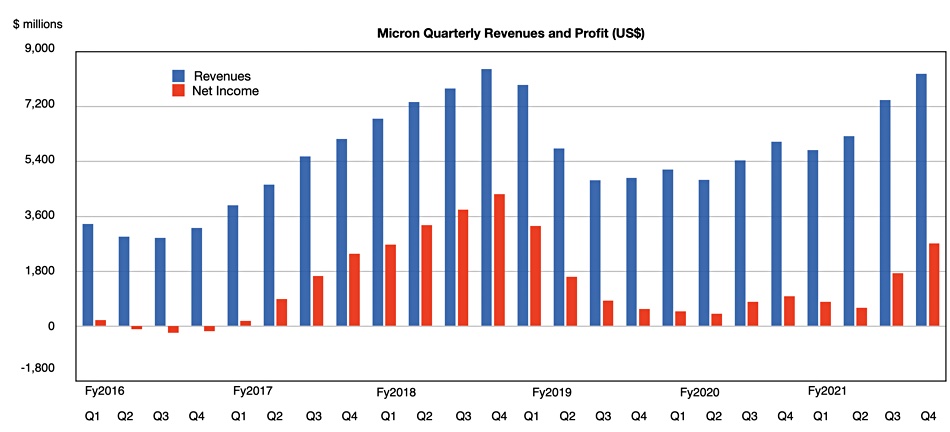
Businesses just keep on needing more DRAM and NAND chips. Quarterly revenues at memory and flash chip maker Micron climbed to the second highest level ever in its latest quarter, with record flash revenues. The demand environment is tremendous and the outlook rosy. Happy days.
Revenues in Micron’s Q4 FY2021, ended September 2, were $8.27 billion, up 36.6 per cent on a year ago, with profits of $2.7 billion, up a thumping 175 per cent on the previous year. Full FY2021 revenues were $27.7 billion, 29.3 per cent higher than FY2020 revenues, with profits of $5.86 billion, 118 per cent more than the prior year.
Micron CEO and President Sanjay Mehrotra’s results statement read: ”Micron’s outstanding fourth quarter execution capped a year of several key milestones. In fiscal 2021, we established DRAM and NAND technology leadership, drove record revenues across multiple markets, and initiated a quarterly dividend. The demand outlook for 2022 is strong, and Micron is delivering innovative solutions to our customers, fueling our long-term growth.”
Micron revenue history show potential to exceed previous record of Q4 FY2018. How far can this DRAM+NAND up cycle go on?
DRAM represented 74 per cent of Micron’s revenues in the quarter, up 39.9 per cent annually. NAND was 24 per cent of total revenues and increased at a lower rate: 29 per cent year-on-year. However there was record NAND revenue in the quarter.
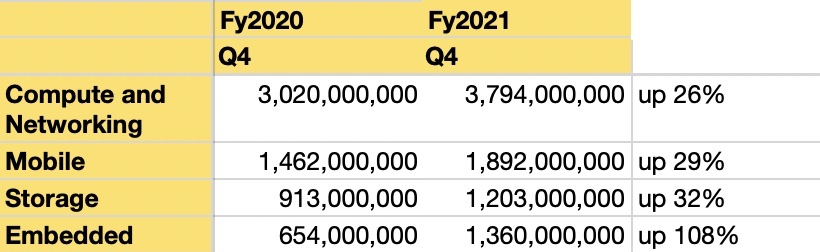
Micron has four business units, one of which, the embedded unit, saw stellar growth of 108 per cent year-on-year as this table shows:
In his prepared remarks Mehrotra said: “We achieved our highest-ever mobile revenue, driven by all-time-high managed NAND revenue and multichip package (MCP) mix. Our embedded business had a tremendous record-breaking year, with auto and industrial businesses both at substantial new highs. And our Crucial-branded consumer business and overall QLC mix in NAND all hit records in fiscal 2021.”
Financial summary for the quarter:
Gross margin — 47.9 per cent
Cash flow from operations — $3.9B
Free cash flow — $1.9B
Liquidity — $13B
Cash minus debt — $3.7B (there’s a rock solid balance sheet here)
Diluted earnings per share — $2.42 vs $1.08 a year ago
The DRAM and NAND technology leadership claims refer to Micron’s 1α (1-alpha) DRAM and 176-layer NAND being industry’s most advanced nodes in high-volume production. Mehrotra said: “We believe we are several quarters ahead of the industry in deployment of these process technologies.”
On the SSD front: ”We are … enhancing our NVMe SSD portfolio and will soon introduce PCIe Gen-4 datacentre SSDs with Micron-designed controllers and leveraging the full benefit of vertical integration.” It has already qualified 176-layer Gen-4 NVMe client SSDs with several PC OEMs.
In general: “Datacentre has become the largest market for memory and storage, driven by the rapid growth in cloud.” The other end-user markets — PC, graphics, mobile, auto and industrial — all exhibited revenue growth for Micron.
Mehrotra made general comments about technology developments: “We … expect to increase FY22 R&D investment by approximately 15 per cent from FY2021 to deliver bold product and technology innovations designed to fuel the data economy, as well as to expand our portfolio to capitalise on opportunities such as high-bandwidth memory and Compute Express Link (CXL) solutions.”
Micron withdrew from the 3D XPoint storage-class memory market earlier this year, saying that it was interested in developing new storage-class memory technologies accessed across the CXL interconnect. Perhaps this is an area for bold product innovation.
Outlook
The guidance for its next quarter, Q1 in FY2022, is for revenues of $7.65 billion plus/minus $200 million. This would be a 32.5 per cent rise year-on-year at the mid-point and represent Micron’s highest-ever quarterly revenue.
Micron is also planning for record revenues in the full fiscal 2022 year, as there is strong demand across the board for its products.
Data protector and manager Cohesity has hired Kevin Delane as its Chief Revenue Officer, replacing the departed Michael Cremen.
Cremen resigned in August to go to another company, and Delane has been hired quite quickly. He comes from being worldwide sales VP at all-flash array supplier Pure Storage, a strategic Cohesity partner. Like Cohesity, Pure is embarking on a transition to SaaS-based services and so Delane will be able to hit the ground running from that point of view.
Kevin Delane.
Mohit Aron, Cohesity founder and CEO, said in a statement: “Kevin has proven success in advancing global go-to-market strategies and consistently delivering strong results. With an extensive knowledge of the technology industry, strong partner and international expertise, and a management approach that puts culture first, Kevin will play a key role in accelerating our global momentum. We are thrilled to welcome Kevin to the Cohesity executive leadership team at this exhilarating time.”
Exhilarating? Yes, because Cohesity has just announced a knock-out quarter.
We understand Delane was recommended by some Cohesity board members — for example Carl Eschenbach, who was previously hired by Kevin to work at EMC. It’s a small world.
Cohesity’s announcement points out that, at Pure, Delane was responsible for the company’s global go-to-market strategy, including sales, field sales, sales operations, and systems engineering, and he was also instrumental in preparing the company for its IPO. (We like this point, being sure that Cohesity has an IPO in its near-term plans. And that could mean stock options for Delane.)
Delane spent nearly eight years at Pure, having previously spent almost 19 years at EMC, then Dell EMC, finishing up as SVP business operations for Isilon.
His comment about joining Cohesity? “This was an opportunity I simply could not pass up.”
Taking advantage of VMware’s NVMe/TCP support Dell is adding it to the PowerStore array product line via a SmartFabric Storage Software (SFSS) feature.
Dell says it is the first supplier to support VMware’s Update 3 to vSphere 7, and there will be an NVMe IP SAN portfolio across Dell Technologies’ storage, networking and compute products.
SFSS automates storage connectivity for NVMe IP SAN. It will allow host and storage interfaces to register with a Centralized Discovery Controller that can notify hosts of new storage resources. In full the additions are:
PowerStore NVMe/TCP protocol and SFSS integration Dell EMC’s PowerStore storage array can use the NVMe/TCP protocol and will support both the Direct Discovery and Centralized Discovery management models.
VMware ESXi 7.0u3 NVMe/TCP protocol and SFSS integration Dell partnered with VMware to add support for the NVMe/TCP protocol and add the ability for each ESX server interface to explicitly register discovery information with SFSS via the push registration technique.
PowerSwitch and SmartFabric Services (SFS) Dell EMC PowerSwitch and SmartFabric Services (SFS) can be used to automate the configuration of the switches that make up customers’ NVMe IP SAN.
PowerMax and PowerFlex plans Dell is planning support for NVMe/TCP in both its Dell EMC PowerMax all-flash enterprise data storage and Dell EMC PowerFlex software-defined storage product lines.
That last point emphasises Dell’s commitment to NVMe/TCP. ESXi 7.0u3 using NVMe/TCP can now be used on Dell EMC PowerEdge servers.
Industry NVMe/TCP support is strengthening significantly.
VMware has updated vSphere and vSAN to provide faster storage networking, better Optane support, more cloud-native features, simplified operations and better vSAN resilience and security in an Update 3 release.
vSphere now supports NVMe-over-Fabrics networking across a TCP/IP link (NVMe/TCP) providing remote direct memory access speed to external NVMe storage drives. Unlike NVMe-oF RoCE, which needs costly lossless Ethernet links, NVMe/TCP uses everyday Ethernet cabling — a tad slower but less expensive and an easy migration for iSCSI users.
A VMware blog explains: “NVMe/TCP allows vSphere customers a fast, simple and cost-effective way to get the most out of their existing storage investments,” and provides more information.
Dell Technologies, VMware’s owner and partner, is introducing SmartFabric Storage Software with support for NVMe/TCP in vSphere.
VMware’s vSphere and vSAN support the snapshotting of Optane persistent memory (DIMMs) in app direct (DAX) mode. This is another helpful brick in the wall of Intel’s expanding Optane ecosystem.
Update 3 to vSphere and VSAN 7 also provides enhanced cloud-native developer and deployment support with:
vSphere VM Service support for vGPUs Using the VM Service through Kubernetes API, developers can provision VMs that leverage underlying GPU hardware resources.
Simplified setup of vSphere with Tanzu Faster and easier setup of networking with fewer steps and inputs needed.
vSAN Stretched Clusters for Kubernetes Workloads Users can extend a vSAN cluster from a single site to two sites for a higher level of availability and intersite load balancing. VMware now supports Kubernetes workloads in a stretched cluster deployment.
Kubernetes Topology Support in vSAN Enables Kubernetes to see the underlying topology and manage data placement across availability zones (AZs) to ensure availability in case of a planned or unplanned outage.
The update also provides simplified operations and better vSAN resilience and security. Read more in another VMware blog by senior product marketing manager Glen Simon.
Both vSphere 7 Update 3 and vSAN 7 Update 3 will become available by the end of VMware’s Q3 FY22 (October 29, 2021).
HPE has announced additions to its GreenLake subscription offerings, marking the company’s shift into direct competition with public cloud data warehouses like Snowflake and SaaS-based data protectors such as Cohesity, Druva, HYCU and others.
We are told this represents HPE’s entry into two large, high-growth software markets — unified analytics and data protection — and accelerates HPE’s transition to a cloud services company. HPE announced GreenLake for analytics with Ezmeral Unified Analytics and an Ezmeral Object Store, GreenLake for data protection with disaster recovery (DR) and backup cloud services, and a professional services-based Edge-to-Cloud Adoption Framework. No HPE announcement is complete these days unless it includes the phrase “edge-to-cloud” — preferably several times.
Antonio Neri, HPE president and CEO, said: “The $100 billion unified analytics and data market is ripe for disruption, as customers seek a hybrid solution for enterprise datasets on-premises and at the edge. … The new HPE GreenLake cloud services for analytics empower customers [and] gives them one platform to unify and modernise data everywhere. Together with the new HPE GreenLake cloud services for data protection, HPE provides customers with an unparalleled platform to protect, secure, and capitalise on the full value of their data, from edge to cloud.”
HPE’s GreenLake platform now has more than 1200 customers and $5.2 billion in total contract value, and is growing. In its most recent quarter, Q3 2021, the Annualised Revenue Run Rate was up 33 per cent year-over-year, and as-a-service orders up 46 per cent year-over-year.
Unified analytics
HPE reckons to take on the big beasts in the cloud data warehouse and data lake market — like Snowflake and Databricks — who use proprietary technology, by offering a cloud-native, open-source software base with no lock-in. It has a two-pronged approach, offering Ezmeral-branded Unified Analytics and Data Fabric Object Store. These are available as services or software, deployed on-premises, in the public cloud or across a hybrid environment.
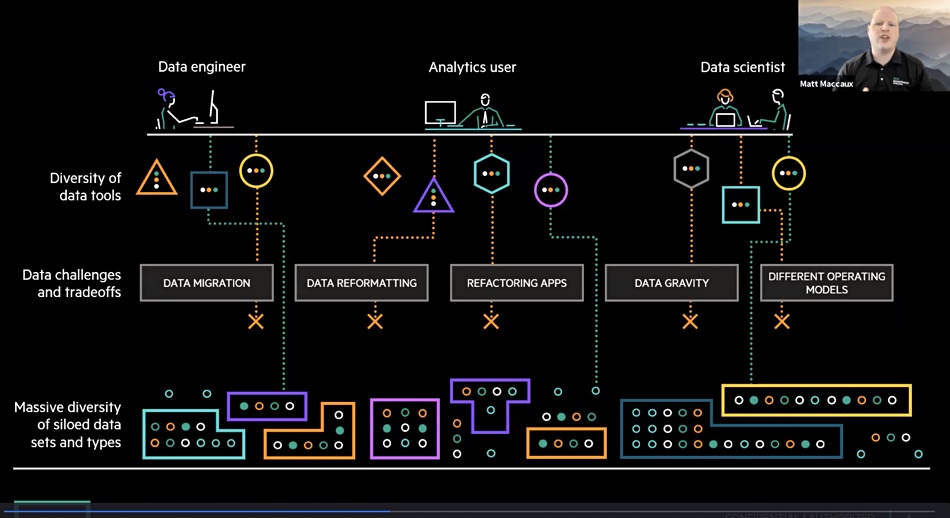
HPE analytics chaos slide.
Matt Maccaux, the global CTO for Ezmeral SW at HPE, said that different analytics users — data engineers, analytics users and data scientists — faced a massive diversity of siloed data sets and types. Ezmeral Unified Analytics has a common set of application tools, is usable by all three kinds of user and based on an underlying data fabric file and object store.
There are three Ezmeral offerings accessing this:
Ezmeral Runtime Essentials and Enterprise Editions — an orchestrated Kubernetes app modernisation platform;
The new Ezmeral Unified Analytics — a hybrid lakehouse offering for analytics and machine learning (ML);
Ezmeral ML Ops — integrated ML workflows, which Maccaux called the crown jewels.
The existing Ezmeral Data Fabric file and streaming data store has been used here, but the object store is new and can run on-premises or in the cloud. It can store files and streaming data as well as objects, and supports the S3 API.
Maccaux said it did not use MinIO technology, nor Scality’s: “We wrote our own object store abstraction and it’s based upon some of the underlying technology of the data fabric.” We understand it is cloud-native and optimised for small file performance — think 100-byte objects placed on NVMe flash, which are then aged into larger objects on slower storage.
Data protection
HPE is entering the rapidly growing Data Protection-as-a-Service market with GreenLake for Data Protection. This consists of two offerings:
GreenLake for Disaster Recovery — this uses acquired Zerto’s journal-based Continuous Data Protection (CDP) technology for disaster recovery, backup, and application and data mobility across hybrid and multi-cloud environments. It helps customers recover in minutes from ransomware attacks.
GreenLake for Backup and Recovery — backup as a service built for hybrid cloud with integrated snapshot, on-premises backup, and cloud backup. It provides policy-based orchestration and automation and protects customers’ virtual machines. HPE says it eliminates the complexities of managing and operating backup hardware, software, or cloud infrastructure.
The HPE Backup and Recovery Service code consists of new cloud-native micro services, along with existing Aruba Central, HPE Catalyst and HPE Recovery Manager Central code.
HPE storage czar Tom Black wrote in a blog, which we saw pre-publication, “With HPE GreenLake for data protection, now customers can secure their data against ransomware, recover from any disruption, and protect their VM workloads effortlessly across on-premises and hybrid cloud environments.”
The Edge-to-Cloud Adoption Framework is a professional services-led set of capabilities to help customers adopt HPE GreenLake offerings. It addresses eight domains which HPE says are critical to the strategy, design, execution, and measurement of an effective cloud operating model: Strategy and Governance, People, Operations, Innovation, Applications, DevOps, Data, and Security.
HPE supplies an AIOps for infrastructure offering, InfoSight, that constantly observes applications and workloads running on the GreenLake platform. A new capability, called HPE InfoSight App Insights, detects application anomalies, provides prescriptive recommendations, and keeps the application workloads running disruption-free.
Ezmeral Unified Analytics should become available in the first half of 2022.
Comment
Neri is in a tremendous hurry to transform HPE into a data services-led company, and boost GreenLake’s revenues. He has changed its leadership, recruiting VMware exec Fidelma Russo as CTO and effective GreenLake head. The move into analytics and head-on competition with Snowflake, Databricks and others is a massive bet that HPE, with an open-source unified offering can offer a compelling choice to customers who are no doubt feeling pressured to jump aboard the analytics juggernaut.
The move into SaaS data protection is much less of a risk. This market is, unlike the cloud analytics market, nowhere near being dominated by elephant-sized players. Zerto has good DR technology and HP acquired a failing company with tremendous promise. The SaaS data protection field is comparatively young. Dell has made its entry by OEMing Druva, and competitors such as Commvault (with Metallic), HYCU, Cohesity, Rubrik and others are not out of reach. If HPE’s backup service is good then it should grow nicely and penetrate HPE’s customer base.
Analytics is the one to watch. Snowflake is busily and effectively building out an ecosystem and marketplace around its offering. HPE will need to match that with its Ezmeral marketplace.
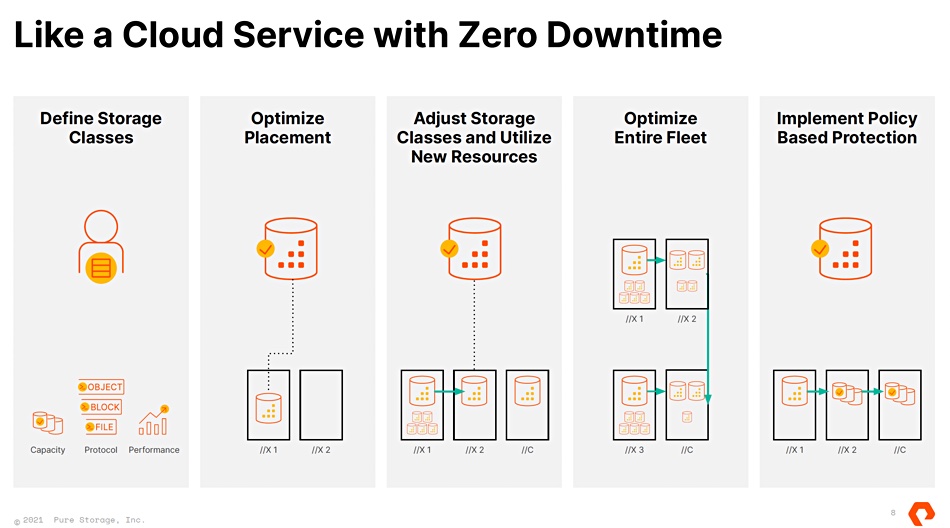
Pure Storage has added greatly increased scale-out for its arrays with clusters in availability zones, and added cloud-like storage resource consumption and management, as well as automated database deployment services for containerised apps.
It lifted the veil today on Pure Fusion, which it calls a self-service, autonomous, SaaS management plane; enhanced Pure1 operational management; and Portworx Data Services (PDS). Fusion is a federation capability for all Pure devices — on- and off-premises — with a cloud-like hyperscaler consumption model. PDS, meanwhile, brings the ability to deploy databases on demand in a Kubernetes cluster.
Pure’s chief product officer, Ajay Singh, said: “Customers want a new agile storage experience that is fully automated, self-service, and pay-as-you-go. Pure Fusion breaks down the traditional barriers of enterprise storage to deliver true storage-as-code and much faster time to innovation.”
Murli Thirumale, VP and GM, Cloud Native Business Unit, Pure Storage, said Portworx Data Services showed the firm had made progress in helping customers to deploy stateful applications on Kubernetes: “Now we don’t just give IT teams the tools needed to run data services in production, we are providing an as-a-service experience for the data services themselves so our customers can focus on innovation, not operations.”
Pure provides all-flash storage resources for both traditional applications and for containerised applications. Drilling down into the conceptual aspect, traditional apps running on-premises are provisioned using abstractions such as LUNs, and arrays with defined capacities, whereas public cloud provisioning is on the basis of capacity, service classes, protection levels and near-infinite scale-out. In the containerised world, Kubernetes facilitates storage provisioning but also brings a whole new dimension of complexity with application deployment and monitoring. It can be used to automate both storage provisioning and application deployment.
The idea is for the Pure infrastructure to combine to form greater resource pools. For traditional environments that infrastructure is presented as cloud-like, with service classes and in-built workload placement and balancing. For cloud-native — for example Kubernetes-based — shops, their ability to deploy databases on the Pure infrastructure is now automated, as is their ongoing (“day 2”, as the kids say) management.
Pure Fusion
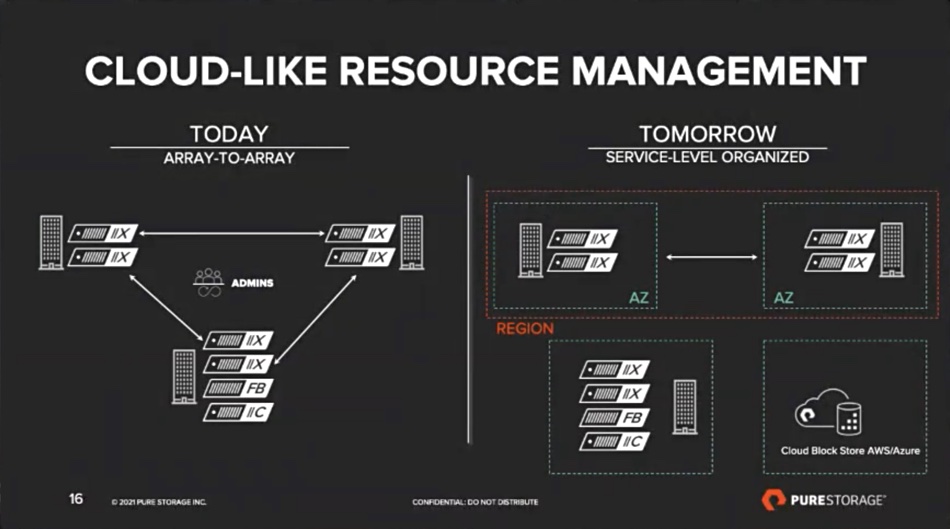
Pure International CTO Alex McMullan told B&F: “Fusion … is a SaaS layer to federate Pure arrays together into a software-defined and multi-tenant private cloud.”
He added: “This is Pure’s first major journey into active management. Pure1 today is a monitoring and read-only portal. The change that comes with Fusion is that we’ll be managing Pure devices actively from the cloud layer, from the SaaS layer, and that’s a huge thing that has been planned, discussed, syndicated with customers for many years.”
Pure Fusion provides availability zones and regions across clusters of Pure arrays, including Cloud Block Store, with everything organised by service level. Storage admins can define a catalogue of storage classes with different access types (block, object, file), performance and protection and cost profiles. Users can then self-select the class they want with a UI click, or software API call and a “Pure1 layer for Fusion to automatically implement those changes behind the scenes, without anyone knowing.”
In theory, customers will be able to provision and deploy storage volumes faster, from common tools developers use today like Terraform and Ansible, with an API-first interface. Their storage will also have higher availability through the use of availability zones.
Suppose there is an array problem? McMullan said that, with Pure1’s access to array telemetry data, the firm and Fusion can “work between themselves to work out the best place for a data set to be and to move it there with Active Cluster. … it’s all completely transparent to the user, the storage administrator, the DBA and, of course, to the end application as well.”
McMullan added: “Each part of the federation of pools of capacity is carved into tenant spaces. For each of those tenant spaces there’s an overall administrator, allowing different storage classes to be defined per tenant space, each with its own separate administrator. … Each tenant space can call out into any Availability Zone, any region or more than one region with protection policies to be able to run their business in the way that they see is optimal.”
Pure Fusion scaling will integrate first with FlashArray//X, FlashArray//C, and Pure Cloud Block Store, and has future integrations planned with FlashBlade and Portworx.
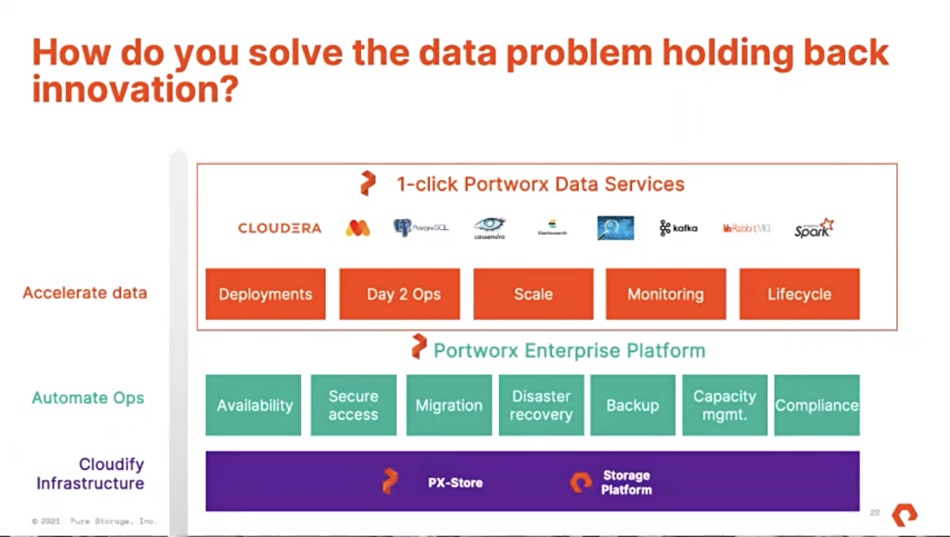
Portworx Data Services
Cloud native development features rapid code iterations and complex database deployments, which means DevOps staff end up doing a lot of Ops work along with the Dev. Portworx Data Services is aimed at reducing their Ops-type workload by automating database deployments. It’s built on the Portworx Enterprise product.
Users select a database type — such as Cassandra, Couchbase, ElasticSearch, Kafka, or MongoDB — its name and size, and it is then downloaded from the container registry, installed on a cluster, and brought up by the Kubernetes operator. The user then gets a connection string back so they can use the database.
Alex McMullan.
The data protection is taken care of by Portworx. The product is database-as-a-service, McMullan said: “No more ServiceNow tickets, no more help desk tickets, no more calling help desks. You click and you go; you deploy as you would do in the public cloud.”
A range of SQL and NoSQL databases will be supported. According to McMullan: “We’re going to start with a couple of the obvious ones in terms of Cassandra, Kafka. Rabbit MQ, I think, is one of the others, and that list will get longer as we approach GA.”
He said: “Portworx Data Services is able to maintain, expand capacity, monitor, feedback, and take repetitive actions, if and when there’s a database problem.
“It won’t do DBA-based tasks in terms of table management, the traditional things. That still goes via the normal service, but the actual capability of bringing the database up inside the application for the developer, the DBA, the data scientists to consume the endpoint, is all taken care of automatically.”
He emphasised that “the ability to repeatedly deploy and manage and maintain and protect containerised applications is something that nobody else can offer, talk about or even do right now, so this is an industry first for us.”
Availability
Both Pure Fusion and Portworx Data Services are in an Early Access Programs. Fusion will be in preview by the end of this year, with general availability to come in the first half of 2022. Portworx Data Services should be generally available in early 2022.
The Arctic World Archive has held a depositing event for data ingestion this month, following a prior one in February, thus providing an effective five to six months write latency.
Data is written on reels of Piql-format 35mm film and is claimed to be recoverable for more than 1000 years. The AWA stores the film reels of data in shipping containers in a steel vault, 300m inside Gruve 3 — an old coal mine at Longyearbyen, in Spitzbergen. This is the largest island in the Svalbard archipelago, located between Norway and Greenland, 965km south of the North Pole. This offline archive is marketed as the place to store the most precious artworks, cultural artefacts and data in the world over the very long term. Customers include the Vatican Library, the National Museum of Norway, the European Space Agency, Github for source code, and several global corporations.
At the event Piql’s Managing Director, Rune Bjerkestrand, said in a portentous statement: ”The data you have deposited today holds significance for communities around the world. Choosing to preserve these items and ensuring they will never be forgotten is passing on value to future generations.”
New data depositers included the Norwegian Armed Forces Museum with digitised photographs, Norway’s Natural history museum, an digital art collection, the National Library of Hungary, and the corporate history of Norway’s Tronrud Engineering — shades of a vanity project.
We wondered if the read latency (restoring items from the archive) was five to six months as well. Not so. A spokesperson said: “If a client needs to retrieve their data, they make a request through our online platform, piqlConnect. The reel is then loaded on to a piqlReader at the vault and the files are made available online (or on a portable media device if the client wishes). … PiqlConnect is hosted in Microsoft Azure … and there is a high-speed fibre optic connection to the vault.” The film reel holding the data has to be identified and manually fetched from the vault before being placed in the reader. This process could take just 30 minutes, but is likely to take longer.
We also asked about prices but didn’t get anywhere. “We unfortunately don’t publish our prices as the needs of each client (including file preparation, cataloguing, archival actions, etc) vary from client to client.”
AWA clients can request a private deposit ceremony if they wish. The AWA says it won’t accept deposits from just anybody — it’s all very worthy.
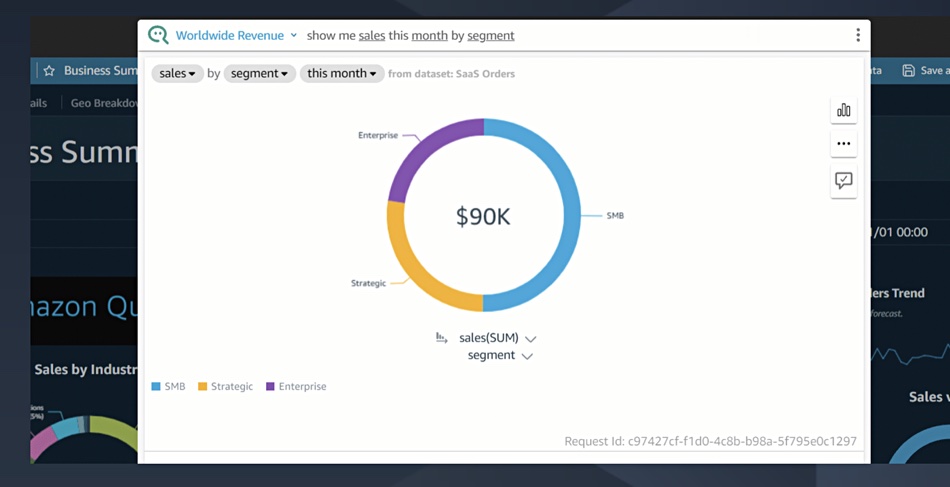
Amazon has extended its QuickSite business intelligence (BI) service with QuickSite Q, which enables users to type questions about their business data in natural language and receive accurate answers in seconds.
QuickSite is a scalable, serverless, embeddable, machine learning-powered BI service built for the cloud that makes it easy to create and publish interactive BI dashboards. With the Q version users can type in questions using natural language instead of using a point-and-click dashboard selection method.
QuickSite Q screengrab.
Matt Wood, VP of Business Analytics at AWS, provided a statement: “With Amazon QuickSight Q, anyone within an organisation has the ability to ask natural language questions and receive highly relevant answers and visualisations. For the first time, anyone can tap into the full power of data to make quick, reliable, data-driven decisions to plan more efficiently and be more responsive to their end users.”
QuickSite Q uses machine learning (natural language processing, schema understanding, and semantic parsing for SQL code generation) to automatically interpret the intent of a question and relationships among business data. The machine learning models behind QuickSight Q are pre-trained on data from various domains such as sales reporting, ads and marketing, financial services, healthcare, and sports analytics.
It can handle questions such as “How are my sales tracking against quota?” and “What are the top products sold week-over-week by region?” The answers come as visualisations and text and mean a business intelligence analyst is not needed to interrogate data to get the answers to such questions.
Users don’t need to learn SQL but, on the flip side, they can’t ask such detailed questions as one can with SQL. QuickSight Q continually improves over time based on the auto-complete phrases a user selects. Amazon says “Customers can [also] refine the way Amazon QuickSight Q understands questions with an easy-to-use editor, which removes the need for complex data preparation before users can ask questions of data in natural language.“
We’re told that, as QuickSite does not depend on pre-built dashboards and reports, users are not limited to asking only a specific set of questions. QuickSight Q provides auto-complete suggestions for key phrases and business terms. It performs spell checking and acronym/synonym matching, so users need not worry about typos or remembering exact business terms for their data.
There are no upfront commitments to use Amazon QuickSight Q, and customers only pay for the number of users or queries. Amazon QuickSight Q currently supports questions in English and is generally available today to customers running Amazon QuickSight in US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Europe (Ireland), and Europe (London), with availability in additional AWS Regions coming soon.
There’s a strong focus on data querying and analysis in this week’s digest. Data querying has been improved by Elastic enhancing its search products. A US research institute is using MemVerge’s virtual memory to speed plant DNA analysis. And data warehouse data feeder Fivetran has pulled off an amazing funding round.
Apart from these things we look at two funding rounds for Fivetran and Stairwell, and have masses of shorter news items about people being hired and product news. Grab a coffee and read on …
Elastic stretches its software
Elastic has announced enhancements to its ElasticSearch Platform offering with v7.15 Elastic. The platform includes Elasticsearch and Kibana, and its three built-in features: Elastic Enterprise Search, Elastic Observability, and Elastic Security.
Web crawler improvements in Search include automatic crawling controls, content extraction tools, and the ability to analyse logs and metrics natively in Kibana, giving users a single platform to search all of their organisation’s data. There is a native Google Cloud data source integration with Google Cloud Dataflow, providing customers with faster data ingestion in Elastic Cloud.
APM (Application Performance Monitoring) correlations, now generally available in Elastic Observability, help DevOps teams and site reliability engineers accelerate root cause analysis and reduce mean time to resolution by automatically surfacing attributes correlated with high-latency or erroneous transactions.
Enhancements have been added to Limitless Extended Detection and Response (XDR) in Elastic Security, including malicious behaviour protection for Windows, macOS and Linux hosts, and one-click host isolation for cloud-native Linux environments. Powered by analytics that prevent attack techniques leveraged by known threats, malicious behaviour protection strengthens existing malware and ransomware prevention by pairing post-execution analytics with response actions to disrupt adversaries early in an attack.
Read a blog to find out about several more additions made by Elastic.
MemVerge case study
Penn State Huck Institutes of the Life Sciences is using MemVerge’s Memory Machine Big Memory software to speed genomic analytic processing in plant DNA research to develop plant products that can better sustain droughts, diseases and achieve longer transportation and shelf life. The bioscientists at Penn State need to analyze genome sequences that are even more complex than human genomes. Using traditional analytic methods, it could take weeks to process specific workloads and running jobs can often fail as data is much larger than the available compute memory.
By deploying a pool of MemVerge software-defined DRAM and Optane persistent memory (PMem), the Institute has been able to speed the completion of its analytic pipeline and run jobs that it hasn’t been able to process before.
In the MemVerge announcement, Claude dePamphilis, Director of the Center for Parasitic and Carnivorous Plants at Penn State Huck Institutes of the Life Sciences, said: “The innovative technology helps us achieve DRAM-like performance from a mixed memory configuration. This has not only dramatically increased our time to research findings but has also saved us considerable budget in the process.”
We respectfully suggest he meant to say “dramatically decreased our time to research findings”. 🙂
Fivetran funding
Data integration startup Fivetran has taken in a massive $565 million at a valuation of $5.6 billion, taking total funding to $730 million. The round was led by Andreessen Horowitz with existing investor General Catalyst and new investors such as YC Continuity. Fivetran also bought private equity-owned HVR and its enterprise, mission-critical, real-time database replication technology for $700 million in a cash-and-stock transaction.
The new funding made the acquisition possible.
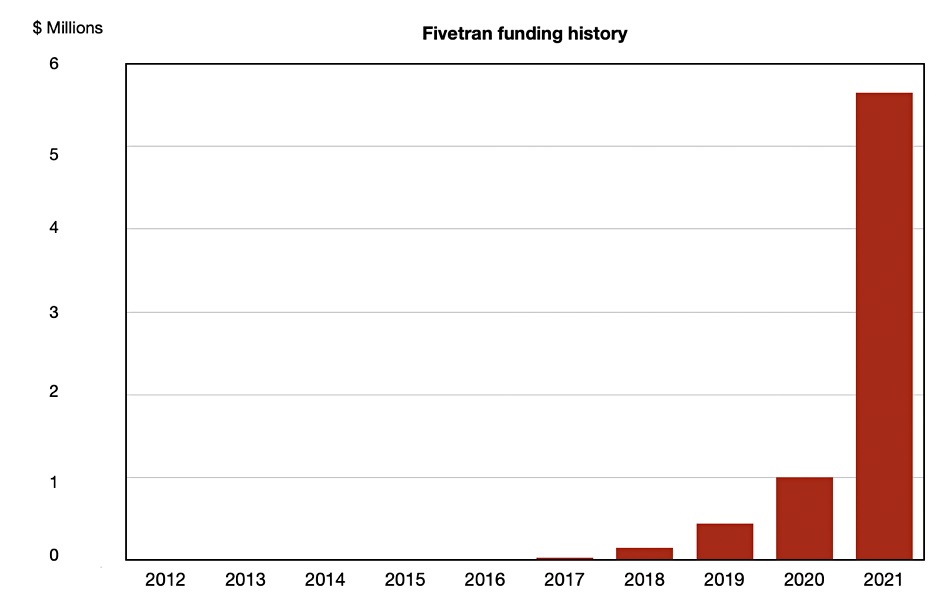
Fivetran was founded in 2012 and its funding history shows a hockey-stick curve:
2013 — $743,000 seed
2017 — $3.4M second seed
2018 — $15M A-round
2019 — $44M B-round
2020 — $100M C-round
2021 — $565M D-round
A chart shows this spectacular betting at the Fivetran funding casino in more detail:
The reason for this funding frenzy, panic investing almost — don’t you think it resembles panic buying? — is that Fivetran’s software, provided as a managed service, provides connectors to get formatted data into data warehouses, such as Snowflake, from disparate and distributed data sources. The sources can be databases, files, applications, events and functions. Fivetran is, in one way, just another ETL (Extract, Transform and Load) process, but provided as a separate function with more than 150 pre-built change data capture connectors and automated schema migrations.
Fivetran has more than 1000 customers, such as ASICS, Autodesk, Monzo, Square, DocuSign, Everlane and Lime. A blog explains some of Fivetran’s thinking behind the HVR deal.
HVR sold itself for $51 million to private equity business Level Equity Management in 2019 and has a partnership with Snowflake and Snowflake competitor Databricks. The Fivetran deal represents a near 14x return for Level Equity Management.
VC bets on data analytics, spurred by the success of Snowflake’s IPO, are getting bigger and bigger. This is blitz-scaling with a vengeance.
Stairwell Funding
Mike Wiacek.
Palo Alto-based startup Stairwell has raised $20 million in an A-round and launching an Inception offering to detect threats by looking at a company’s data. Stairwell was founded in 2019, by CEO Mike Wiackek, an ex-principal software engineer at Google. He worked on threat analysis intelligence at an Alphabet company called Chronicle, which he co-founded.
There the main development was called Backstory — a planet-scale data analysis platform that could search petabytes of security data in just milliseconds.
Stairwell’s web site reads “Security is currently practised as a linear process, but ideally it is circular, continuous and should alway be building on itself. And, it should always start by looking at what’s most important to an organisation, which is their own internal data. Good security starts with a deep understanding of the assets, software, and files inside your environment.“ It calls this an inside-out approach.
Investors include Sequoia, Accel, Allen and Company and Gradient Ventures. Inception is in a beta test release with GA slated for next year.
Shorts
archTIS, supplying software for collaboration of sensitive information, has acquired select assets including customers, technology and the European operations of Cipherpoint Ltd’s software division. This includes the IP for cp.Protect, a SharePoint on-premises data encryption offering, and cp.Discover, a data discovery and classification platform. Existing cp.Protect and cp.Discover customers include DHL, Bank of Finland, California State University, Arthur J Gallagher, US DARPA, Singapore Power, Singapore Tote and Acronym Media.
Cirrus Migrate Cloud can migrate live block data from a public cloud-based or on-premises block storage system to Azure. Migration uses cMotion technology and is performed while the original system is still in operation. It involves distributed Migration Agents running on every host that allows direct Host-to-Host connections. Each Host-to-Host migration is independent making the solution infinitely scalable, without central bottlenecks for the dataflow. A user guide explains more.
Cloud-native service provider Civo has launched a new region in Germany, based in Frankfurt, for its Kubernetes-focussed cloud platform, adding to existing regions in the USA and UK. It aims to be a disruptive alternative to the hyperscale providers, such as AWS, Google and Microsoft. Civo’s platform launched to early access in May 2021, and the company has seen strong demand for Civo Kubernetes with users from over 130 countries worldwide, and Germany accounting for nearly five per cent of its user base. Civo will launch a further region into Asia this year, with another five regions planned across the globe in 2022.
FileCloud which offers file sync-and-share to enterprises, has introduced v21.2 of its product, which features a native drag-and-drop workflow automation tool that allows managers and team members to create business workflows with no coding necessary.
Multi-cloud security vendor Fortanix announced a partnership with cloud data warehouser Snowflake to make its Data Security Manager SaaS (DSM SaaS) available to Snowflake customers, giving them the ability to tokenise data inside and outside Snowflake. Tokenisation is related to masking. It replaces personally identifiable information (PII) such as credit card account numbers with non-sensitive and random strings of characters, known as a ‘Token’, that preserves the format for the data and the ability to extract the real information.
Public cloud supplier Linode is rolling out NVMe SSD storage. The rollout kicks off in the company’s Atlanta data center, with the remainder of its global network upgrading over the next quarter. It includes the company’s first erasure-coded block storage cluster, using Ceph. The performance upgrade is provided free to all Linode customers. Linode Block Storage rates will remain at $0.10/GB per month. Customers with existing block storage volumes in Linode’s ten other global data centres will be able to migrate their block storage volumes when NVMe becomes available.
AIOps supplier OpsRamp announced a summer release which includes alert predictions for preventing outages and incidents, alert enrichment policies for faster incident troubleshooting, and new monitoring integrations for Alibaba Cloud, Prometheus metrics ingestion, Hitachi, VMware, Dell EMC, and Poly. CloudOPs engineers can visualize, alert, and perform root cause analysis on ECS instances, Auto Scaling, RDS, Load Balancer, EMR, and VPC services within Alibaba Cloud and accelerate troubleshooting for multi-cloud infrastructure within a single platform.
Platform9 can run virtual machines (VMs) on Kubernetes and you can read about it in a white paper. This should be called Project Uznat <- read it backwards and think VMware.
Startup Pliops which sells an x86 server offloading XDP storage accelerator, has set up a distribution deal with TD SYNNEX covering North America. Pliops has implemented a partner assist, channel-centric go-to-market strategy and will strategically align with systems integrators and value-added resellers offering database, analytics, ML/AI, HPC and web-scale solutions, as well as cloud deployments.
Pure Storage’s FlashBlade file and object-storing array has been adopted by DC BLOX, a provider of interconnected multi-tenant datacentres across the Southeastern US. The array comes through Pure-as-a-Service and Pure’s Evergreen storage service for non-disruptive upgrades and future expansion.
Redstor, a UK- and SaaS-based data protection and management supplier, is partnering with Bocada, so its automated, aggregation of backup and storage performance metrics reduce the work for MSPs involved in daily backup operations monitoring, monthly SLA audits and provide better reporting.
Samsung’s T7 SSD is a credit card size portable external drive with up to 2TB capacity and a USB 3.2 Gen-2 connecting cable. The drive uses embedded PCIe NVMe technology and can transfer data fast, with sequential reads up to 1050MB/sec and sequential writes at 1000MB/sec. The aluminium-cased drive can survive a fall up to two metres, weighs 58 grams, and has a three-year warranty. It’s compatible with PCs, Macs and Android devices and comes in silver, blue and red colours.
Samsung T7 external SSD.
Earlier this month Seagate’s La Cie unit launched the LaCie Mobile SSD Secure, and the LaCie Portable SSD, both with up to 2TB capacity and the same read and write performance as Samsung’s T7 drive. OWC’s Envoy Pro Elektron portable external SSD, like the La Cie and Samsung products, also uses a USB 3.2 Gen-2 cable connector and has equivalent performance.
OWC Electron fast portable SSD.
Scale Computing, which supplies HCI systems for edge sites — smaller and remote IT sites — says it’s doing well in the North America public sector, with sales to the Kitselas First Nation, a self-governing nation and tribe in British Columbia, The Summit County Board of Elections in Ohio, and Madison County, Kentucky.
Scality has announced Splunk SmartStore-Ready validation with its RING product providing Splunk customers with petabyte-scale storage for SmartStore single-site, multi-site active-active and multi-site stretched deployments. A Scality blog explains the details: “Scality RING holds the master copy of warm buckets while indexers’ local storage is used for hot and cache copies of warm buckets. With most data residing on Scality RING, the indexer maintains a local cache that contains a minimal amount of data: hot buckets, copies of warm buckets participating in active or recent searches, and bucket metadata. This renders indexers stateless for warm and cold data, boosting operational flexibility and agility.”
Seagate is working with Microsoft to provide more affordable expansion SSDs for the Xbox XIS console. Such expansion storage has a proprietary format. There is talk of a 500GB capacity card costing around $150. The existing 1TB card costs $220 or so but you can get a 1TB M.2 format SSD for $130 or less. A French media outlet, Xboxsquad.fr, reported this story.
The SNIA (Storage Networking Industry Association) has made v1.2.3 of Swordfish available for public review. Swordfish extends the DMTF Redfish Scalable Platforms Management API specification to define a comprehensive, RESTful API for managing storage and related data services. Version 1.2.3 adds enhanced support for NVMe advanced devices (such as arrays), with detailed requirements for front-end configuration specified in a new profile, and enhancements to the NVMe Model Overview and Mapping Guide. It also includes new content in both the User’s Guide and the Error Handling Guide. You can also learn more about SNIA Swordfish and access developer resources here.
The SNIA’s Developer Conference runs from September 28 to September 29. There are over 120 technical sessions on topics including NVMe, NVMe-oF, Zoned Storage, Computational Storage, Storage Networking, Persistent Memory, and more. Register here.
Synology is launching a cloud-based C2 Backup forever-incremental offering. It backs up Windows devices, whether they are located at home (C2 Backup For Individuals) or distributed across multiple offices (C2 Backup For Businesses). Data backed up on C2 Backup is fully shielded against unauthorised access by end-to-end AES-256 encryption, with a user-held private key necessary to unlock backup files and sensitive information. File-level recovery allows you to retrieve any file you need immediately, while entire devices can be restored to their previous state with bare-metal recovery.
TeamGroup is developing a liquid-cooled SSD family — yes, really. The T-Force Cardea Liquid II drives are for extreme gamers. This SSD is an M.2 format product and presumably will run at high speed for longer than at room temperature.
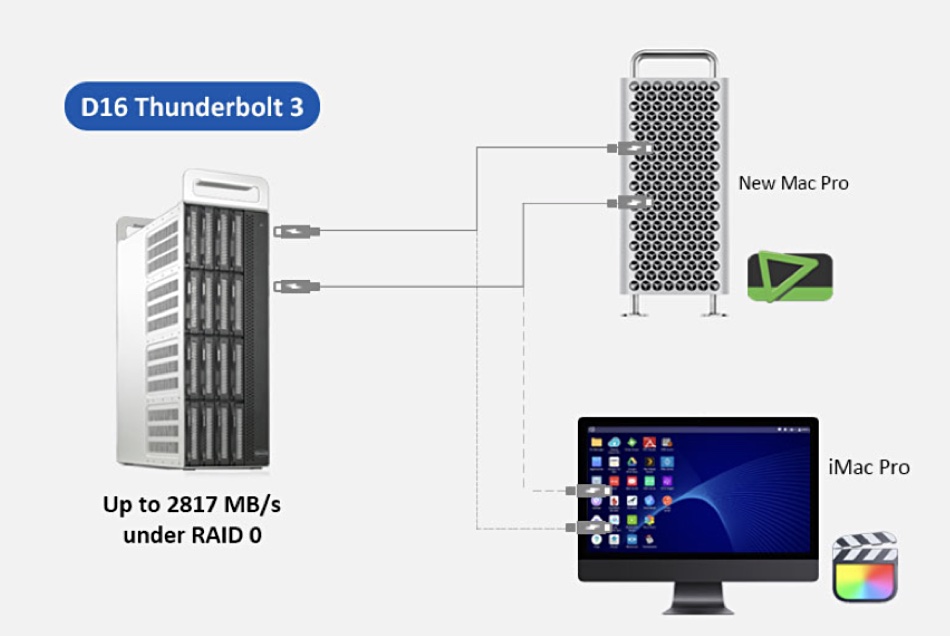
China’s TerraMaster has a D16 Thunderbolt 3 tower storage box for digital image technology workflows. It as 16 bays for 3.5-inch SATA disks or 2.5-inch SSDs and can be configured with a total storage capacity of up to 288TB (18TB HDDs x 16). The box has a 40Gbit/sec connection, delivering speeds of up to 2817MB/sec when fitted with 16 SSDs in RAID 0 array mode on Windows OS. In RAID 6 mode, it can deliver speeds of up to 2480MB/sec.
Yugabyte, which supplies an open-source distributed SQL database, announced the general availability of Yugabyte Cloud, its fully-managed, public database-as-a-service offering. Developers can create and connect to a highly scalable, resilient Postgres compatible database in minutes with zero operational overhead.
Managed storage provider Zadara has a deal with connectivity supplier Zenlayer for its fully-managed zStorage to be available in Zenlayer’s North American locations and will soon expand into emerging markets such as India, China, and South America. Zadara and Zenlayer now offer managed storage solutions that businesses can deploy from on-premises datacentres, private colocation facilities, or the cloud with 100 per cent OpEx model.
People
Cloud backup and file storage supplier Backblaze has appointed two new board members: Evelyn D’An and Earl E. Fry. D’An currently serves as a member of the board of directors of Summer Infant, Inc. and is a former partner of Ernst & Young, where she spent 18 years serving clients in retail, consumer products, technology, and other sectors. Fry serves as a member of the board of directors of Hawaiian Airlines, including as chair of their Audit and Finance Committee. Previously, Fry was chief financial officer, chief administrative officer, chief customer officer, and executive vice president, operations strategy at Informatica Corporation.
Danial Beer.
HCI and virtual SAN supplier StorMagic has hired a new CEO, Danial Beer, ex-CEO of Ottawa-based GFI Software, to replace the departed Hans O’Sullivan. Beer will oversee operational efficiencies and moves into Edge, security and video surveillance markets.
We asked if “operational efficiencies” refers to layoffs, office closures or other cost-cutting measures and a StorMagic spokesperson replied: “We are in a growth phase of the company and are expanding, not shrinking. The reference to operational efficiencies means we will align our operational processes with our GTM strategy to accelerate growth. We are continuing to find ways to update our operations to better enable our expected growth.”
Western Digital and Toshiba have promoted their advances in disk drive areal density and performance based on specific technology advances, such as bias currents, enhanced PMR using a microwave oscillator and embedded NAND in the controller — Western Digital’s OptiNAND. Yet Seagate, apart from saying its over-arching recording technology development is heat-assisted magnetic recording (HAMR) in contrast to Toshiba and Western Digital’s focus on microwave-assisted magnetic recording (MAMR) as a stage before possible HAMR, has nothing to say about such things.
This can lead commentators to think it is running out of technology advancements. We asked Colin Presley, a Senior Director in Seagate’s CTO organisation, about the recent technology advances in the HDD area — bias currents, ePMR, and embedded controller NAND. Then we had a discussion about the state of HAMR.
Colin Presly
Bias current/ePMR
Without disputing Western Digital’s internal data, Presly doesn’t think that the use of bias current-type technology will provide an intrinsic advantage or gain. For him the changeover from longitudinal magnetic recording to perpendicular magnetic recording (PMR) provided an intrinsic gain in areal density. The bias current idea doesn’t, in his view, provide an intrinsic gain of itself.
He said: “We consider complete system optimisation for given head designs. The physics behind bias currents is well understood. … We can do it in other ways with head designs and geometry design.” Seagate could control the write field, head spacing, domain alignment and other items from the hundreds of features affecting a specific HDD design point.
According to Presly, Western Digital reached the 18TB level with ePMR and Seagate reached it without PMR, supporting his point that Seagate can reach higher incremental capacity levels without relying on any one specific technology to get there.
Embedded controller NAND
Seagate does know about shipping NAND with disk drives because: “We have shipped approximately 40 million hybrid drives with NAND on them for performance gains. It’s not really new. … It was good technology but it’s not used in today’s nearline drives.”
Western Digital says its OptiNAND embedded NAND technology provides more performance and better metadata management, leading to areal density increases.
Embedding NAND in the controller is not something that Seagate thinks is worth doing. If customers want more performance then it has its MACH.2 dual actuator technology providing two read:write channels to the drive and effectively doubling performance, not increasing it by low percentage numbers through better metadata management.
Presly said: “We don’t see any reason to put NAND in the controller for performance.” As for metadata: “There are ways of managing metadata; other ways of solving the same problem. … We just don’t see the value of adding NAND to a nearline drive.”
A NAND-enhanced controller was not needed for the 20TB PMR drives that Seagate is now sample shipping, although one such is used in Western Digital’s sampling 20TB drive. Presly reiterated Seagate’s over-arching areal density increase direction: “For capacity we’re focussed on HAMR.”
He was keen on the idea of deterministic performance gains, saying customers wanted predictable and consistent (deterministic) performance, not variable or non-deterministic performance, and that’s why it uses DRAM in its controllers and not NAND. But: “In the future, if there was a reason to do it then we could make that pivot.”
HAMR
Presly was clear about one aspect of HAMR: “[It] is really really hard technology.” Even so: “The industry across the board recognises HAMR is the road to high capacity.”
Seagate HAMR graphic.
Inside Seagate: “HAMR continues to progress. We’re not ready to publish an areal density record but we are progressing. … We’re strong believers in HAMR; it is a step change.”
I asked him about the apparent capacity gap between the latest 20TB sampling drive and the coming 30TB HAMR drive mentioned by Seagate’s CFO Gianluca Romano. Presly said: “The 20 to 30TB transition is a good discussion point … but I can’t talk about that. …. We will have competitive technologies in the 20 to 30TB space. … We’ll absolutely be competitive.”
Comment
It is apparent that Seagate believes it is in pole position in the HAMR race. It is gaining customer feedback on its 20TB Gen-1 technology and also manufacturing experience. This knowledge is being fed into its Gen-2 30TB product. By the time when, and if, both Toshiba and WD make a transition to HAMR, Seagate will have several years of experience from manufacturing and shipping millions of HAMR drives.
That could give it an advantage when competing with HAMR newbies. Until then it has to stay competitive when WD and Toshiba bring out their full MAMR technology. Who knows, but we could see Seagate’s Gen-2 HAMR drive facing up against WD’s first full MAMR drive. Competitive bakeoffs will be interesting. We hope Backblaze gets its hands on both types of drives and publishes its stats on drive reliability about them.
Scality has patented software to capture billions of files in multi-petabyte environments in a single snapshot, orders of magnitude faster than traditional filers, and enabling better recovery from ransomware attacks.
The company’s claim means at least two orders of magnitude — a hundred times faster — and maybe three — a thousand times faster. How, after 20-plus years of snapshot technology development, is it possible to do this?
Scality CTO Giorgio Regni said in a statement that Scality “advances the state of the art in the storage industry and, more importantly, provides the foundation for new and enhanced products.”
Evaluator Group senior strategist and analyst Randy Kerns sang off the same hymn sheet: “Scality continues to push the envelope with innovations for protecting data at massive scale, as demonstrated by its new US patent for snapshot technology. This promises to be a key foundation for enabling future ransomware protection solutions.”
Ironically it uses some of the key concepts in Scality’s own RING object storage system — as we shall see.
Limited snapshot capabilities
Paul Speciale.
A Scality blog by Chief Product Officer Paul Speciale reads: “Snapshots are a traditional method of data protection in most NAS file systems. The challenge for snapshot implementations at larger scale is to keep them fast, accessible and space efficient. The underlying management and tracking needed for each snapshot is complex, creating overhead in both space, CPU consumption and time.
“That’s one reason why (in most NAS systems) snapshots haven’t been applicable for truly high-scale file systems. Most snapshot technology works well for use cases such as user directories or shared folders — typically in the range of thousands to tens of thousands of files — but it’s rare to see NAS file systems with millions or billions of files.
“The frequency of snapshots also tends to be quite sparse, typically with policies that take daily and weekly snapshots but purge more granular and longer-term ones.”
And the conclusion is this: “The important breakthrough in our patent is that Scality has figured out how to make snapshots work at cloud-scale, with millions to billions of files in a file system, and enable an essentially unlimited number of snapshots.”
Okay. We thought we’d better take a closer look at the patent. It is US Patent number 11,061,928: “Snapshots and forks of storage systems using distributed consistent databases implemented within an object store.” So Scality is using an object store, its own RING no doubt, as the basis for a high-speed snapshotting process. That seems surprising.
The intro para says the patent involves “providing a snapshot counter for a storage system implemented with multiple distributed consistent database instances.” Reading the Background part of the patent brings out some very interesting points. We summarise a great deal here. Bear with it — we’ll arrive at familiar territory.
Patent background
The text reminds readers of several core physical ways of accessing stored information which, ultimately, comes down to accessing blocks on a disk or solid state drive. These are objects accessed via their own unique alphanumeric ID, and key:value stores which link keys uniquely connected to values (stored information or objects). There are files holding individual pieces of information, accessed through folders, which themselves can contain folders thus firming a directory tree.
There are also blocks on drives which store information and which are accessed by the block number or offset from a starting point on the drive. We are told that a database is away of using a core physical storage system. And consists of “a database interface 108, an indexing layer 109 and a storage layer 110.” [The numbers refer to defined items in the patent.] The indexing layer exists to speedup lookups into the storage layer and so avoid scrolling through the storage layer item by item until the right one is found. It is a mechanism for searching the storage layer’s contents.
The storage layer can be implemented using either object, file or block storage methods.
A relational database (RDBMS) is a type of database with a collection of tables using rows and columns. Rows are records in the database and columns are data items for a particular row with one column used as a primary key to identify a row in a table. Columns in a table may include primary keys of other rows in other tables.
An index layer, such as B+ tree, can be added on top of tables to provide primary keys for items with specific values. Thus sounds vague but the essential idea is that indexing provides faster access to items in the RDBMS than traversing the rows and columns following primary key references. The patent says: “In a basic approach there is a separate index for every column in a table so that any query for any item of information within the table can be sped up.”
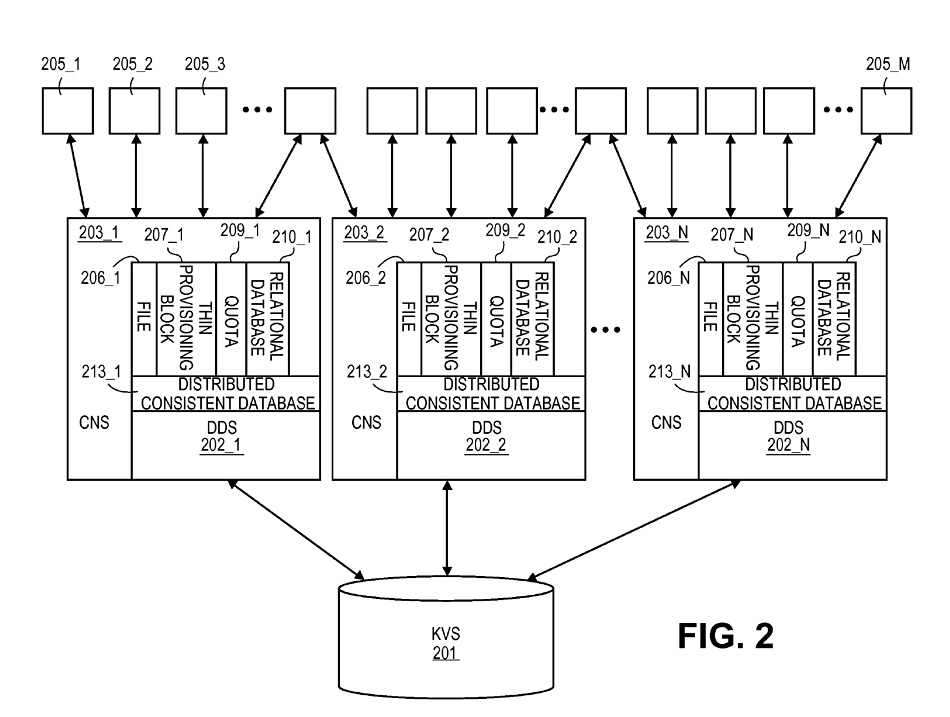
Having laid all this out the patent describes a key:value [object] store accessed via a distributed database (DDS) management system and connector nodes, and diagrams it:
The numbers refer to defined items in the patent. Read the patent text to understand them.
The distributed databases provide scale and parallel access speed.
Scality’s patent has a Chord-like distributed hash table access mechanism. The hash table stores key:value pairs with keys indicating different computers (nodes) with Chord being a hash table protocol saying how the keys are assigned to nodes. Nodes and keys are logically arranged in an identifier circle in which each node has a predecessor and a successor. Keys can have successors as well.
And here we are. We’ve arrived at Scality’s RING object storage system, which we first wrote about 11 years ago.
The DDS permits the underlying key:value store to be so used or “to be used as [a] file directory or block based storage system.” File accesses are converted into object ID accesses. Block access numbers are converted into Object IDs also. The patent reads: “If the KVS 201 is sufficiently large, one or more of each of these different types of storage systems may be simultaneously implemented” and “multiple distributed consistent database instances can also be coordinated together as fundamental kernels in the construction of a singular, extremely large capacity storage solution.”
These can “effect extremely large scale file directories, and … extremely large block storage systems.” The connector nodes can provide various interfaces to end users, such as Cloud Data Management Interfaces (CDMI) and the Simple Storage System (S3). NFS, CIFS, FUSE, iSCSI, Fibre Channel, etc.
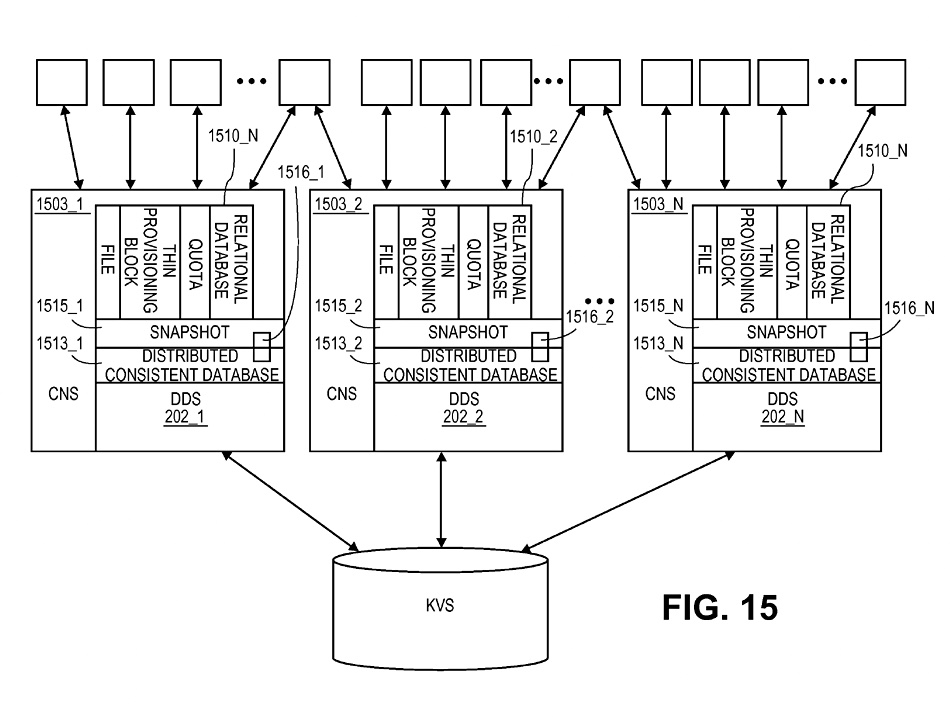
Snapshot layer added to previous diagram.
Implications
This seems to us to be an astonishingly powerful idea. It implies that this combined key:value store and DDS bundle can be used in many different ways, not just for storing the data for billions of files captured in snapshot exercises.
We asked Scality if the technology in the patent could specifically be used for blocks and objects as well as files, and what that means in terms of Scality’s software strategy.
Speciale and Regni replied, saying: “We do agree that the core innovations in our patent are applicable to both block and object storage over time (in principle they share similar semantics). Especially as platform technologies (flash, RDMA/NVMEoF and networking) speeds and latencies continue to progress — we certainly see ways to leverage the patent for block storage.
“The idea of implementing Point-in-Time snapshots for object storage is potentially very useful for future cloud-native application workloads, and we do believe our innovations will be applicable to it in the future.”
It will be interesting to see how and when Scality implements the technology in this patent. Clearly it now has a way of protecting data in files it stores in its own SOFS (Scale-Out File System) software.