


Scality has patented software to capture billions of files in multi-petabyte environments in a single snapshot, orders of magnitude faster than traditional filers, and enabling better recovery from ransomware attacks.
The company’s claim means at least two orders of magnitude — a hundred times faster — and maybe three — a thousand times faster. How, after 20-plus years of snapshot technology development, is it possible to do this?
Scality CTO Giorgio Regni said in a statement that Scality “advances the state of the art in the storage industry and, more importantly, provides the foundation for new and enhanced products.”
Evaluator Group senior strategist and analyst Randy Kerns sang off the same hymn sheet: “Scality continues to push the envelope with innovations for protecting data at massive scale, as demonstrated by its new US patent for snapshot technology. This promises to be a key foundation for enabling future ransomware protection solutions.”
Ironically it uses some of the key concepts in Scality’s own RING object storage system — as we shall see.
Limited snapshot capabilities

A Scality blog by Chief Product Officer Paul Speciale reads: “Snapshots are a traditional method of data protection in most NAS file systems. The challenge for snapshot implementations at larger scale is to keep them fast, accessible and space efficient. The underlying management and tracking needed for each snapshot is complex, creating overhead in both space, CPU consumption and time.
“That’s one reason why (in most NAS systems) snapshots haven’t been applicable for truly high-scale file systems. Most snapshot technology works well for use cases such as user directories or shared folders — typically in the range of thousands to tens of thousands of files — but it’s rare to see NAS file systems with millions or billions of files.
“The frequency of snapshots also tends to be quite sparse, typically with policies that take daily and weekly snapshots but purge more granular and longer-term ones.”
And the conclusion is this: “The important breakthrough in our patent is that Scality has figured out how to make snapshots work at cloud-scale, with millions to billions of files in a file system, and enable an essentially unlimited number of snapshots.”
Okay. We thought we’d better take a closer look at the patent. It is US Patent number 11,061,928: “Snapshots and forks of storage systems using distributed consistent databases implemented within an object store.” So Scality is using an object store, its own RING no doubt, as the basis for a high-speed snapshotting process. That seems surprising.
The intro para says the patent involves “providing a snapshot counter for a storage system implemented with multiple distributed consistent database instances.” Reading the Background part of the patent brings out some very interesting points. We summarise a great deal here. Bear with it — we’ll arrive at familiar territory.
Patent background
The text reminds readers of several core physical ways of accessing stored information which, ultimately, comes down to accessing blocks on a disk or solid state drive. These are objects accessed via their own unique alphanumeric ID, and key:value stores which link keys uniquely connected to values (stored information or objects). There are files holding individual pieces of information, accessed through folders, which themselves can contain folders thus firming a directory tree.
There are also blocks on drives which store information and which are accessed by the block number or offset from a starting point on the drive. We are told that a database is away of using a core physical storage system. And consists of “a database interface 108, an indexing layer 109 and a storage layer 110.” [The numbers refer to defined items in the patent.] The indexing layer exists to speedup lookups into the storage layer and so avoid scrolling through the storage layer item by item until the right one is found. It is a mechanism for searching the storage layer’s contents.
The storage layer can be implemented using either object, file or block storage methods.
A relational database (RDBMS) is a type of database with a collection of tables using rows and columns. Rows are records in the database and columns are data items for a particular row with one column used as a primary key to identify a row in a table. Columns in a table may include primary keys of other rows in other tables.
An index layer, such as B+ tree, can be added on top of tables to provide primary keys for items with specific values. Thus sounds vague but the essential idea is that indexing provides faster access to items in the RDBMS than traversing the rows and columns following primary key references. The patent says: “In a basic approach there is a separate index for every column in a table so that any query for any item of information within the table can be sped up.”
Having laid all this out the patent describes a key:value [object] store accessed via a distributed database (DDS) management system and connector nodes, and diagrams it:
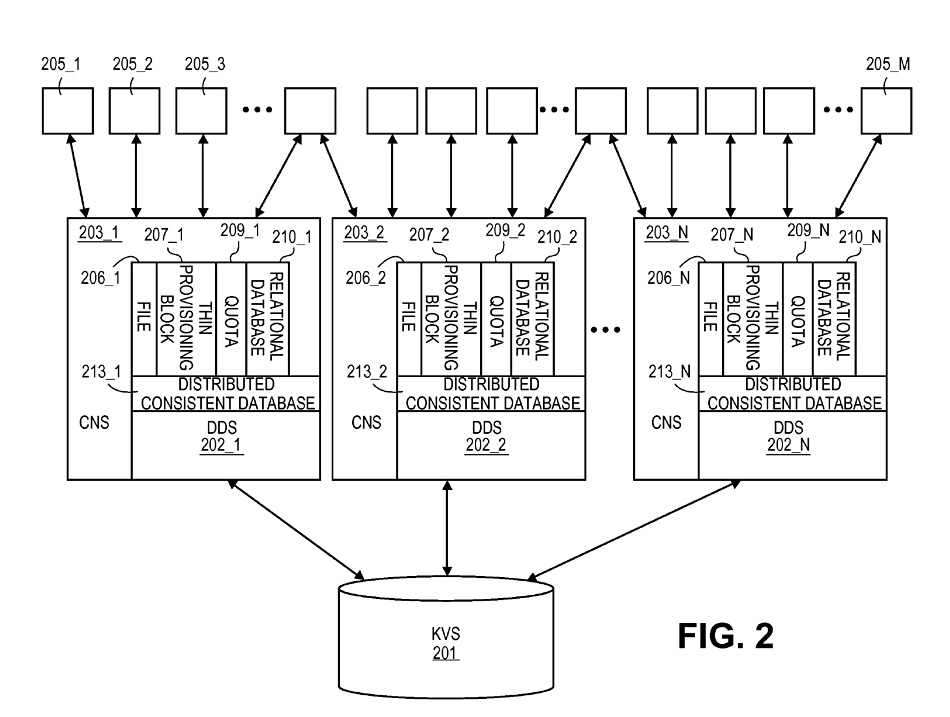
The distributed databases provide scale and parallel access speed.
Scality’s patent has a Chord-like distributed hash table access mechanism. The hash table stores key:value pairs with keys indicating different computers (nodes) with Chord being a hash table protocol saying how the keys are assigned to nodes. Nodes and keys are logically arranged in an identifier circle in which each node has a predecessor and a successor. Keys can have successors as well.
And here we are. We’ve arrived at Scality’s RING object storage system, which we first wrote about 11 years ago.
The DDS permits the underlying key:value store to be so used or “to be used as [a] file directory or block based storage system.” File accesses are converted into object ID accesses. Block access numbers are converted into Object IDs also. The patent reads: “If the KVS 201 is sufficiently large, one or more of each of these different types of storage systems may be simultaneously implemented” and “multiple distributed consistent database instances can also be coordinated together as fundamental kernels in the construction of a singular, extremely large capacity storage solution.”
These can “effect extremely large scale file directories, and … extremely large block storage systems.” The connector nodes can provide various interfaces to end users, such as Cloud Data Management Interfaces (CDMI) and the Simple Storage System (S3). NFS, CIFS, FUSE, iSCSI, Fibre Channel, etc.
Implications
This seems to us to be an astonishingly powerful idea. It implies that this combined key:value store and DDS bundle can be used in many different ways, not just for storing the data for billions of files captured in snapshot exercises.
We asked Scality if the technology in the patent could specifically be used for blocks and objects as well as files, and what that means in terms of Scality’s software strategy.
Speciale and Regni replied, saying: “We do agree that the core innovations in our patent are applicable to both block and object storage over time (in principle they share similar semantics). Especially as platform technologies (flash, RDMA/NVMEoF and networking) speeds and latencies continue to progress — we certainly see ways to leverage the patent for block storage.
“The idea of implementing Point-in-Time snapshots for object storage is potentially very useful for future cloud-native application workloads, and we do believe our innovations will be applicable to it in the future.”
It will be interesting to see how and when Scality implements the technology in this patent. Clearly it now has a way of protecting data in files it stores in its own SOFS (Scale-Out File System) software.





