There are granularity consequences of the network fabric choices made by composable systems suppliers. Go the PCIe route and you can compose elements inside a server as well as outside. Go the Ethernet route and you’re stuck outside.
This is by design. PCIe is designed for use inside servers as well as outside, so it can connect to components both within and without. Ethernet and InfiniBand aren’t designed to work that way, so they don’t. You can only compose what you can connect to.
The composability concept is that an individual server, with defined CPU, network ports, memory and local storage, may not be perfectly sized in capacity and performance terms for the application(s) it runs. So applications can run slowly or server capabilities — DRAM, CPU cores, storage capacity, etc. — can be wasted, stranded and idle.
If only excess capacity from one server could be made available to another server, then the resources would not be wasted and stranded but become productive. A composable system dynamically sets up — or composes — a bare metal server from resource pools so that it is better sized for an application, and then decomposes this server when the application run is over. The individual resources are returned to the pool, for re-use by other dynamically-organised servers later.
HPE more or less pioneered this with its Synergy composable systems, organised around racks of its blade servers and storage. A set of startups followed in its footsteps — such as DriveScale, bought by Twitter, as well as GigaIO and Liqid. Western Digital joined the fray with its OpenFlex scheme, and then Fungible entered the scene, with specifically designed Data Processing Unit (DPU) chip-level hardware. Nvidia is making composability waves also, with its BlueField-2 DPU or SmartNIC and partnership with VMware.
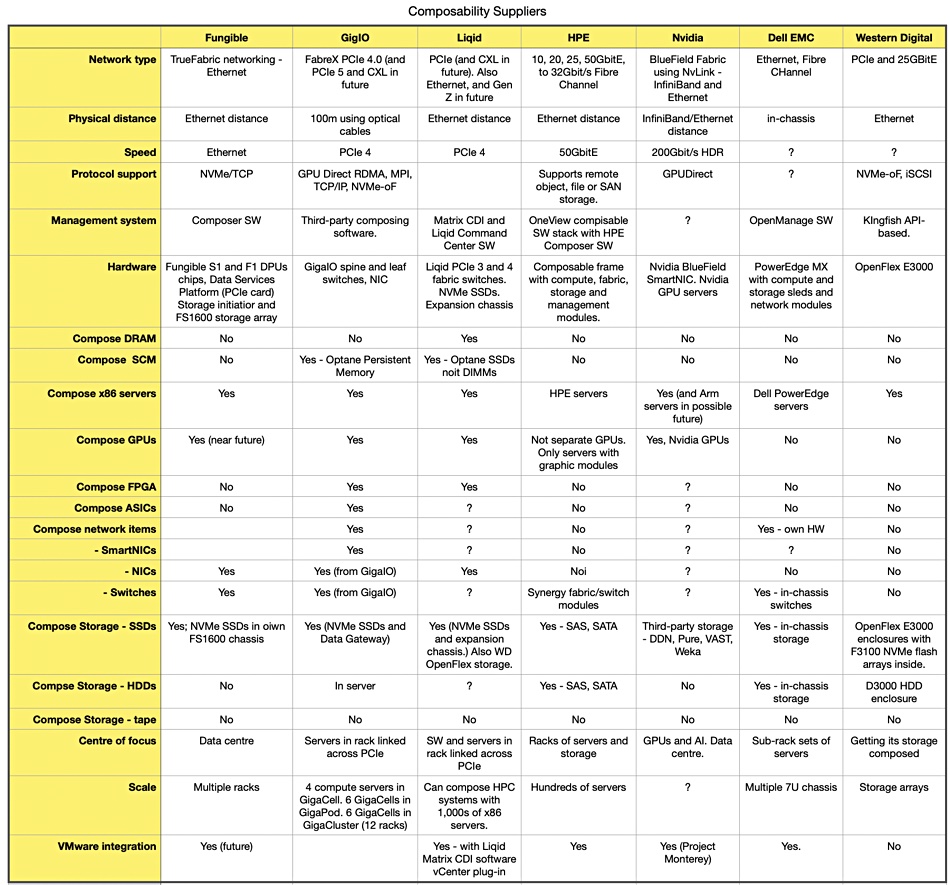
These suppliers can be divided into pro-Ethernet and pro-PCIe camps. A table shows this and summarises their different characteristics:
It notes that PCIe is evolving towards the CXL interconnect which can link pools of DRAM to servers.
Composing and invisibility
In order to bring an element into a composed system you have to tell it and the other elements that they are now all inside a single composed entity. They then have to work together as they would if they were part of a fixed physical piece of hardware.
If the hardware elements are linked across Ethernet, then some server components can’t be seen by the composing software because there is no direct Ethernet connection to them. The obvious items here are DRAM and Optane Persistent Memory (DIMMs), but FPGAs, ASICS and sundry hardware accelerators are also invisible to Ethernet.
Fungible, HPE and Nvidia are in the Ethernet camp. GigaIO and Liqid are in the PCIe camp. The Fungible crew firmly believe Ethernet will win out, but the founders do come from a datacentre networking background at Juniper.
Nvidia has a strong focus on composing systems for the benefit of its GPUs and is still exploring the scope of its composability, with VMware’s ESXi hypervisor running on its SmartNICs and managing the host x86 server into which they are plugged. Liqid and GigaIO believe in composability being supplied by suppliers who are not server or GPU suppliers, as does Fungible.
Liqid has made great progress in the HPC/supercomputer market, while the rumour is that Fungible is doing well in the large enterprise/hyperscaler space. GigaIO says it owns the IP to make native PCIe into a routable network enabling DMA from server to server throughout the rack. It is connecting servers over PCIe, to compose masses and multiple types of accelerators to multiple nodes to get around BIOS limitations and so getting compute traffic off the congested Ethernet storage network.
Dell EMC has its MX7000 chassis with servers composed inside it, but this is at odds with Dell supporting Nvidia BlueField-2 SmartNICs in its storage arrays, HCI systems and servers. We think that there is a chance the MX7000 could get BlueField SmartNIC support at some point.
The composability product space is evolving fast and customers have to make fairly large bets if they decide to buy systems. It seems to us here at Blocks & Files, that the PCIe or Ethernet decision is going to become more and more important and we can’t see a single winner emerging.
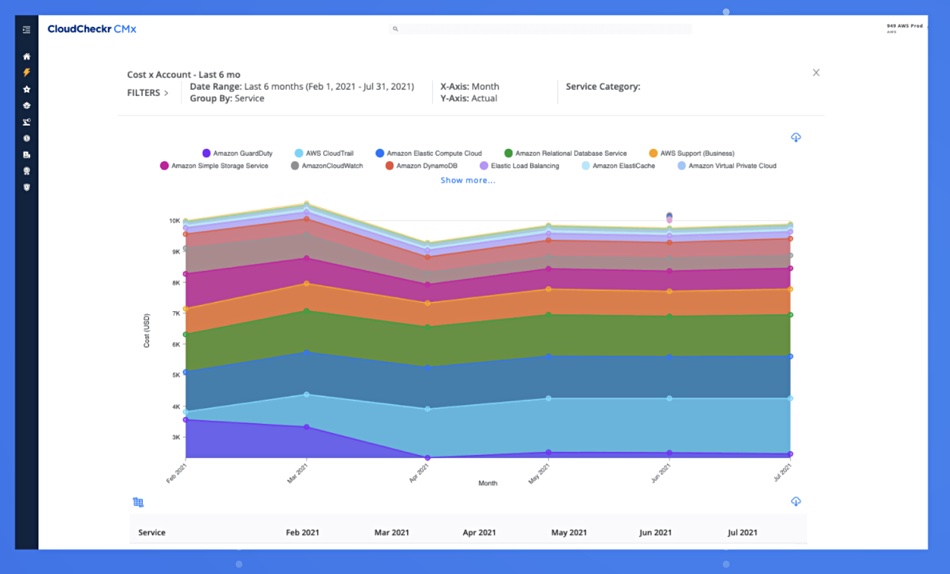
NetApp has acquired CloudCheckr and its cost-optimising public cloud management CMx platform to expand its Spot by NetApp CloudOps offering.
CloudCheckr’s software analyses the costs for AWS, Azure and GCP clouds, looking at billing details for multiple accounts and provides a full set of a customers cloud account details, including resources, configurations, permissions, security, compliance and changes. Customers should be able to analyse and control their cloud costs better with this software.
Anthony Lye.
An announcement quote from Anthony Lye, EVP and GM of NetApp’s Public Cloud Services business unit, said: “By adding cloud billing analytics, cost management capabilities, cloud compliance and security to our CloudOps platform through the acquisition of CloudCheckr, we are enabling organisations to deploy infrastructure and business applications faster while reducing their capital and operational costs. This is a critical step forward in our FinOps strategy … Simply put, NetApp continues to empower customers to achieve more cloud at less cost.”
Financial details of the transaction are not being disclosed. As CloudCheckr’s total funding is $67.4 million, and it’s been growing fast, and is backed by private equity, we would expect a $200 million to $300 million acquisition cost range.
NetApp said that the acquisition extends Spot by NetApp’s cloud FinOps offerings by combining cost visibility and reporting from the CloudCheckr platform with continuous cost optimisation and managed services from Spot by NetApp. It suggests public cloud customers will be better able to understand and continuously improve their cloud resources.
Lye has written a “More cloud. Less cost” blog to discuss the acquisition. In it he writes: “CloudCheckr will add cost visibility with automated actions, secure configurations, deep insights, and detailed reporting to our Spot portfolio’s continuous optimisation.” It will help them control their public cloud financial operations or FinOps.
CloudCheckr was started up Rochester, NY, in 2011 by COO Aaron Klein and previous CEO and now Exec Chairman Aaron Newman. Klein gave up the COO position at the end of 2017 and he and Newman founded BlocWatch, a SaaS offering to manage blockchain environments. CloudCheckr has taken in a total of $67.4 million in funding through a 2012 seed round for $400,000, a two-part A-round in 2013 for $2 million and (slight delay!) $50 million in 2017 and a 2019 B-round raising just $15 million. Both the late A-round and B-round were led by Level Equity Management, which operates as a private equity firm.
At the time of the $50 million A-round funding event CloudCheckr serviced over 150 AWS and Azure authorised resellers and provided support to nearly 40 per cent of all AWS Premier Consulting Partners. Its direct client roster included managing over $1 billion in cloud spend for enterprises such as Nasdaq, Siemens, and Regeneron.
By B-round time CloudCheckr said it was experiencing explosive growth, doubling customers, and achieving a 5x increase in revenue over the last three years. It then claimed a full 40 per cent of the top 50 MSPs, ranked by ChannelE2E, were powered by CloudCheckr.
CloudCheckr is led by CEO Tim McKinnon, who joined in June 2019, two months before the $50 million B-round. He had been President and CEO at Sonian, an Amazon- and VC-funded company, acquired by Barracuda Networks.
Interestingly Nutanix Chief Commercial Officer Tarkan Maner sits on CloudCheckr’s board. He was appointed at B-round time. At that time CloudCheckr said “Tarkan has had many successful exits and held executive roles at Nexenta (acquired by DDN), Dell, Wyse (acquired by Dell), CA (acquired by Broadcom), IBM, Quest, and Sterling Software (acquired by CA).” It seems that old Maner magic, aided by McKinnon, has worked again.
This week we have have panned more nuggets and fragments of gold from the storage news stream. It features automated driving systems, Kubernetes container data protection, media workflow storage, Oracle supporting RoCE and Optane, Amazon Web Services partnering, technology patent awards and more, from ReRAM to data warehousing via edge computing right out to DNA-based malware.
The amount of what we might call weekly background news in the storage industry is getting steadily larger. Scan this bulletin and see for yourself.
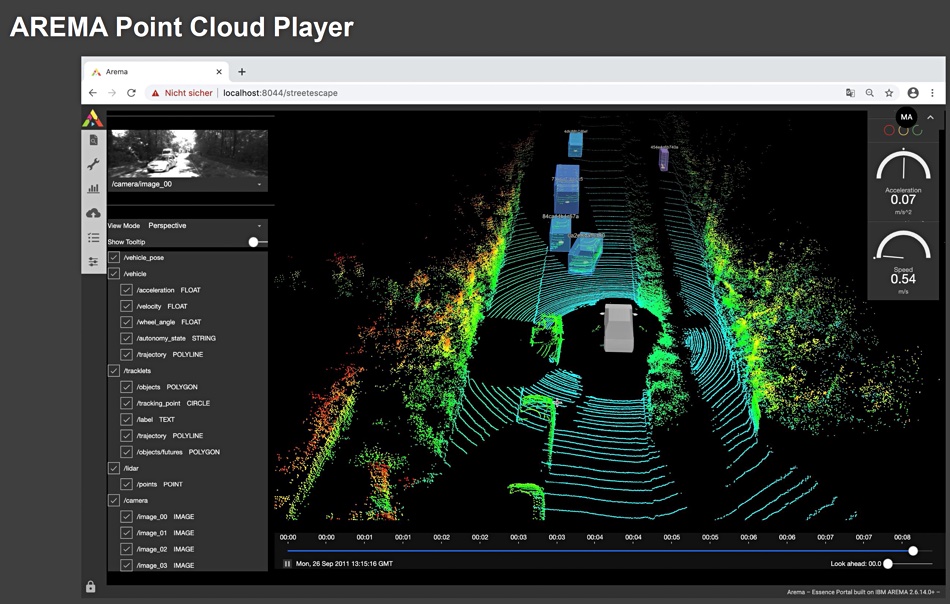
IBM AREMA and ADAS
IBM Archive and Essence Manager (AREMA) orchestrates any file-based broadcast production workflow and is used in Autonomous SDRiving (AD) and Automated Driver Assistance Systems (ADAS). AREMA is a media asset management system, and has more than 140 different, ready-to-deploy agents and new workflows can be swiftly modified or created. Each agent interacts with the workflow engine and executes one specific functionality — such as actual functionality in file transfers or adapters to control third-party systems. “AREMA for Automotive” was introduced about four years ago on a project by project base and it’s now becoming a standard IBM Software product.
We’re told AREMA is the “clue” software which is needed by the automotive engineers to find the needle in the haystack data snippets to be used for AI training for Level 4/5 robo cars. AREMA works with Spectrum Scale, NAS filers and any S3 Object Storage, all at the same time. OpenShift/K8 is also supported.
You can ask questions like: “Please find all data in the data lake where the temperature was >5 degrees, the road was wet, speed 40–60km/h and yellow buses with flashing lights were involved”. It will find all relevant files and timings and works with video, radar and LiDAR data.
Catalogic crams more into CloudCasa
Cloud-native data protector Catalogic has added more features to its CloudCasa product. This provides scalable data protection, with a free service tier, and disaster recovery service for cloud-native apps, and supports all leading Kubernetes distributions and managed services and cloud database services.
CloudCasa now supports backup of Kubernetes persistent volumes (PVs) to cloud storage including Amazon Elastic Block Storage (EBS) persistent volumes and is offered in a new capacity-based subscription model. The PVs get:
Fair, capacity-based pricing for persistent volume backups — Users pay only for the data being protected vs what infrastructure is in use.
Free Service Tier — Unlimited PV and Amazon RDS snapshots with up to 30 days’ retention, with no limits on worker nodes or clusters, and Kubernetes resource data included.
Free Amazon RDS snapshot management — Multi-region copies with no limits on databases or accounts.
Software and storage included — as a SaaS application, there are no software costs, no storage to purchase, no infrastructure to provision.
Security and compliance — SafeLock protection provides tamper-proof backups that are locked from deletion by any user action or API call.
Oracle Exadata X9M, Optane and RoCE
Database and ERP supplier Oracle announced the availability of its Exadata X9M prouducts, converged systems to run Oracle Database. They include the Exadata Database Machine X9M and Exadata Cloud@Customer X9M, which runs Oracle Autonomous Database in customer datacentres. It supports small databases running with fractional CPUs to enable agile, low-cost consolidation, application development, and testing.
Oracle says they deliver higher performance at the same price as the previous generation. They accelerate online transaction processing (OLTP) with more than 70 per cent higher IOPS rates and IO latencies of under 19 microseconds. They also deliver up to an 87 per cent increase in analytic SQL throughput and machine learning workloads.
This enables customers to reduce the costs of running transactional workloads by up to 42 per cent, and analytics workloads by up to 47 per cent.
Juan Loaiza, EVP Mission-Critical Database Technologies at Oracle, said: “For X9M we adopted the latest CPUs, networking, and storage hardware, and optimized our software to deliver dramatically faster performance. Customers get the fastest OLTP, the fastest analytics and the best consolidation — all at the same price as the previous generation. No other platform, do-it-yourself infrastructure, database, or cloud service comes close to Exadata X9M performance, cost/performance, or simplicity.”
The X9M systems use Intel’s latest Xeon SP processors and support Optane persistent memory and RDMA over Converged Ethernet (RoCE). They have 33 per cent more database server CPUs and memory, as well as 28 per cent more storage than previous generations.
Oracle says that, compared to Amazon RDS using all-flash storage, Exadata Cloud@Customer X9M delivers 50x better OLTP latency. Compared to Microsoft Azure SQL using all-flash storage, Exadata Cloud@Customer X9M delivers 100x better OLTP latency. For analytics, Exadata Cloud@Customer X9M delivers up to 25x faster throughput than Microsoft Azure SQL, and up to 72x faster throughput than Amazon RDS. Exadata Cloud@Customer X9M also delivers 50x better OLTP latency and 18x more aggregate throughput than databases running on AWS RDS using a full rack AWS Outposts configuration.
DNA-based malware
A Wired article discusses a demonstration of DNA-based malware:
Read the article and enjoy the ingenuity of it all.
Symply’s new product range for digital media professionals
Media-centric shared storage supplier Symply has launched its SymplyFIRST product range with personal RAID protected storage, backup/archive, cloud archive/transfer, and connectivity features for media pipelines in on-set production, post production, VFX, and for independent filmmakers, in-house creatives, photographers, and other media professionals.
SymplyPRO LTO and SymplyPRO DIT are Thunderbolt 3-connected desktop and rack systems with LTO-9 tape with up to 18TB native storage per tape and over 400Mbits/s read/write speed. Systems are available in multiple configurations including a cable-less design, all-metal enclosure that allows for fast removal and insert of tape drives for transport or upgrade. SymplyPRO LTO systems are certified for use with popular backup and archive utilities for macOS and Windows including YoYotta, Hedge Canister, and Archiware P5.
SymplyATOM (Advanced Tape Operations and Management) software is included with every SymplyPRO LTO system.
SymplyPRO DIT is an archive and transfer system with multi-access technology combining camera card readers for RED, Atomos and Blackmagic Design along with removable 2.5″ SSD and LTO tape for fast all-in-one DIT storage operations.
SymplySPARK is a personal transportable media-optimized RAID system with quiet operation, Thunderbolt 3 connectivity and capacities up to 144TB. Its impact-resistant flight-friendly carry case features tool-free user serviceability of drives, fans, and power supplies.
Symply LTO products.
SymplyNEBULA is a cloud backup and archive with S3 compatibility with datacentres throughout the US and Europe and no egress charges. It is available for a single per-TB price and is up to ten times faster than other providers. It enables easy movement of content to and from AWS EC2 for a variety of media processing and compute functions.
SymplyADDR is a series of affordable high-performance PCIe expansion slot systems.
SymplyLOCK is a simple Thunderbolt cable lock that works with all SymplyFIRST products and any Apple-certified Thunderbolt cable preventing accidental disconnection of a Thunderbolt device.
SymplyFIRST products are now generally available from resellers worldwide. Prices range from:
$4,599 USD for SymplyPRO LTO (thunderbolt connected tape drive);
$3,299 USD for SymplyLTO (SAS connected tape drive);
$4,199 USD for SymplySPARK (thunderbolt connected eight bay storage);
$4.99 USD per month for SymplyNEBULA.
WANdisco replicates loss
Replicator WANdisco has seen revenues fall six per cent year-on-year. Its first half 2021 revenues of $3.4 million compare to the $3.6 million earned a year ago. Back in September 2020 we wrote that this UK company is heavily loss-making and the revenue picture is muddied as it transitions from selling perpetual licences to subscription. However, it is buoyed by a recent capital raise of £25 million and on the back of strong demand for its Azure software “expects to deliver significant revenue growth in FY2021 with the Board expecting a minimum revenue of $35 million.”
We now hear that the General Availability of its Azure service is expected in the next few weeks, “a critical step in converting pipeline customers.” You don’t say. Its statutory loss from operations has risen to $20.3 million from the $14.0 million reported a year ago. Also WANdisco has reduced its full year revenue target from $35 million to a minimum of $18 million. That is still an ambitious 71 per cent increase on the $5.2 million 2020 revenue amount.
The company has raised $42.4 million through a share placing and subscription to accelerate its growth ambitions and pursue near-term opportunities with channel partners. It has won a contract with the analytics division of a global telco to migrate analytical data to the Microsoft Azure cloud, worth a minimum of $1 million over a maximum term of five years.
The problem for WANdisco is that its ability to transfer bits from source to target is not matched by its ability to transfer dollars from customers to its own bank account.
Amazon Web Services
Chinese American distributed OLAP startup Kyligence, originator of Apache Kylin and developer of the AI-augmented data services and management platform Kyligence Cloud, has been accepted into the Amazon Web Services (AWS) Independent Software Vendor (ISV) Accelerate Program, a co-sell program for AWS Partners who provide software solutions that run on or integrate with AWS.
File data lifecycle manager Komprise announced a special offer with Amazon Web Services (AWS) to attendees of the AWS D.C. Summit, taking place September 28 and 29. AWS Summit attendees could get a risk-free assessment of their data savings from Komprise, and be eligible to receive up to 25 per cent off their estimated first year AWS spend if they convert within 90 days.
Cloud file storage supplier Nasuni is working with AWS to address ransomware in the public sector with three new offerings designed to deliver extremely fast ransomware file recovery, as well as built-in backup and disaster recovery, all at a reduced price. These new bundles are available for a limited time as Ransomware “First Aid Kits” for Public Sector Files in AWS. The Nasuni Ransomware First Aid Kits for Public Sector can be procured in AWS Marketplace, while also leveraging AWS Consulting Partners like CDW-G, SHI Government, Presidio and AHEAD.
Patents
Cloud-native storage startup Robin.io has been awarded nine new US patents in the first nine months of 2021. They boost the company’s IP portfolio in three technologies central to the management and orchestration of 5G and enterprise cloud-native applications with Kubernetes. The patents are:
Orchestration of heterogeneous multi-role applications (#11086725).
Rolling back Kubernetes applications (#11113158).
Reducing READ loads on cloned snapshots (#11099937).
Automated management of bundled applications (#11036439).
Automated management of bundled applications (#10908848).
Redo log for append-only storage scheme (#11023328).
Block map cache (#10976938).
Implementing secure communication in a distributed computing system (#10896102).
Health monitoring of automatically deployed and managed network pipelines (#11108638).
Ionir, which supplies storage and data services for Kubernetes-orchestrated containers, has been awarded a US patent for its system of synchronising data containers and improving data mobility. It says its patent allows application data to move with the ease of applications. This data mobility ensures the application can start working immediately at the new location. Full volumes — regardless of size or amount of data — are transported across clouds or across the world in less than 40 seconds. The company owns ten issued patents in this field and has submitted applications for many more.
Shorts
Backblaze says it offers instant recovery in any cloud through its use of Veeam Backup and Replication. Its “Backblaze Instant Recovery in Any Cloud [is] an infrastructure as code (IaC) package that makes ransomware recovery into a VMware/Hyper-V based cloud easy to plan for and execute for any IT team.” Customers “can use an industry-standard automation tool to run a single command to quickly bring up an orchestrated combination of on-demand servers, firewalls, networking, storage, and other infrastructure in phoenixNAP, drawing data for your VMware/Hyper-V based environment over immediately from Veeam Backup & Replication backups.”
Cloudflare’s R2 Storage zero egress cost takes on egregious S3 egress charges. R2 Storage is a public cloud storage service that is S3-compatible but at a lot lower cost than Amazon’s S3 service. The Register, our sibling publication, covered this last week. Our interest is that there is a growing number of cloud services taking on Amazon’s S3 — witness Backblaze — and we should see S3 price cuts shortly, even if they are nominal.
Red Hat OpenShift containers can read and write object data from Cloudian HyperStore object storage systems. Cloudian supports the Kubernetes CSI (Container Storage Interface)as well as Amazon’s S3 interface and both SSDs and Optane for faster object IO performance. OpenShift containers get API call access, multi-tenancy, support for multiple public cloud (AWS, Azure and GCP) back-end storage, and data encryption.
Enterprise file collaboration supplier Egnyte released its 2021 Data Governance Trends Report, which surveyed 400 IT executives in July 2021. It found that unchecked data growth, combined with a lack of visibility, is increasing the risk of breaches, ransomware, and compliance violations dramatically. The most commonly cited application of AI that companies are currently using or plan to invest in the next 12 months is to identify and protect sensitive data in files (47 per cent). Another 42 per cent are using AI to assess risk and threats, and 40 per cent are using it to monitor for malicious behaviour. (Expect Egnyte to buff up its AI credentials.)
In-memory SW supplier Hazelcast announced GA of its Hazelcast Platform product for transactional, operational and analytical workloads. It combines the capabilities of a real-time stream processing engine with in-memory computing with a robust library of connectors from MongoDB to Redis Labs to Snowflake.
SaaS data protector HYCU has recruited service provider Teraflow to its Cloud Services Provider Program. Teraflow is a data engineering and artificial intelligence firm based in London with offices in Johannesburg, South Africa. Its also recruited Extreme Solution, a Google Cloud partner servicing customers across Egypt, UAE and North America, Extreme Solution is used by millions of users across a number of industries for Mobile and Web Solutions Development, Public Cloud and mission-critical Infrastructure initiatives.
IBM Spectrum Scale container native v5.1 adds:
Separate operator namespaces;
Multiple custom resources and controllers;
Core pods managed by daemon controller;
Online rolling pod upgrade;
Set memory and CPU requests and limits for pods;
Support for storage cluster encryption;
Automated deployment of CSI Driver;
Using the GUI;
Automated IBM Spectrum Scale performance monitoring bridge for Grafana.
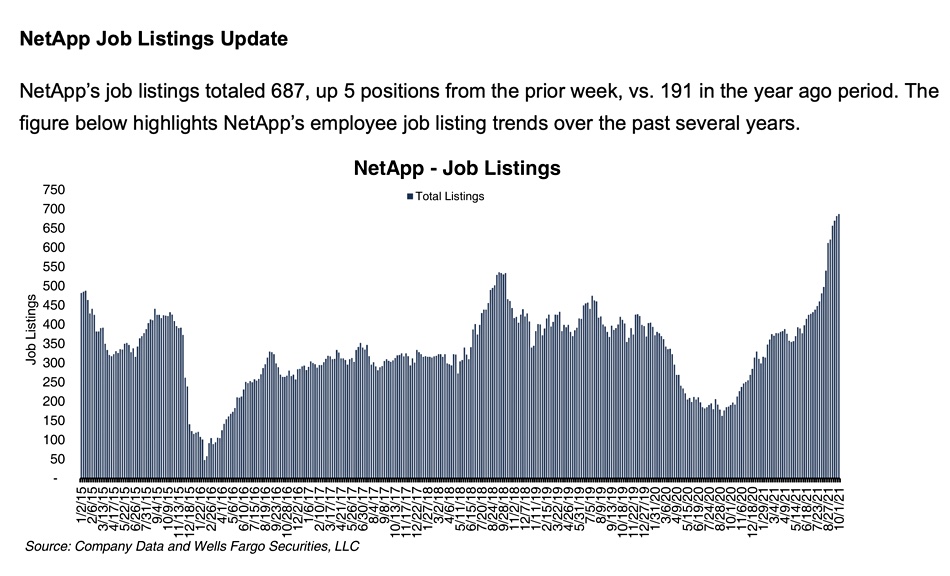
NetApp is recruiting more staff. Wells Fargo analyst Aaron Rakers tracks some mainstream storage suppliers’ recruitment trends and a chart of NetApp’s open job positions shows a sustained rise over recent months.
We think this may be to do with its cloud services business unit led by Anthony Lye.
Blast-from-the-past: privately-owned and legacy storage supplier Overland-Tandberg, now separated from Sphere3D, has added RDX SSD drives alongside its RDX HDD line of removable disk drive cartridges. Having removable SSDs in RDX cartridges gives RDX users a faster backup and restore medium. The available capacities are 500GB, 1TB, 2TB, 4TB, and 8TB.
Phison has announced a technology development of PCIe Gen-5 customisable SSD controller products for enterprise and client SSDs. It is actively developing its first PCIe Gen-5 platform — the E26 Series Controller and SSD which will support PCIe Dual Port and have advanced features such as SR-IOV and ZNS, and support for the newest, fastest NAND interfaces ONFI 5.x and Toggle 5.x. The E26 Gen-5 test chip has been successfully taped out in 12nm advanced process, and customised SSD solutions are targeted to be shipping in the second half of 2022.
Managed multi-cloud Kubernetes-as-a-Service provider Platform9 has, during the past 12 months, grown as a company by 50 per cent, quadrupled its customer base and tripled revenue. It’s increased the capacity that Model9 Cloud Data Manager protects by 10 times.
New Zealand-based Portainer launched its Portainer Business Charmed Operator, supporting integration with Canonical’s Charmed Kubernetes distribution. It enables the automatic installation and integration of Portainer Business as part of the Kubernetes cluster deployment process, using Juju, the Charmed Operator framework. Portainer Business transforms any Kubernetes implementation into a containers-as-a-service setup. [See bootnote about used of ‘Charmed’ term.]
IOMesh by Kubernetes storage supplier SmartX has achieved Red Hat OpenShift certification, and is officially available on Red Hat Ecosystem Catalog. Kyle Zhang, CTO & Cofounder of SmartX, said: “The Red Hat certification demonstrates our ability to support mission-critical workloads on OpenShift.”
24Gbit/sec SAS connectivity was highlighted by the the SCSI Trade Association (STA) at the 2021 Storage Developer Conference, a virtual storage industry event sponsored by the Storage Network Industry Association. A SAS Integrator’s Guide, which provides additional detail on the subject, can be downloaded here. See the event agenda here.
The SNIA’s Storage Management Initiative has announced the approved ISO certification for the Swordfish 1.1.0d specification. The SNIA Swordfish specification extends the DMTF Redfish Scalable Platforms Management API specification to define a comprehensive, RESTful API for managing storage and related data services.
Synology announced GA of its new operating system, DSM 7.0.1 for the vast majority of its storage devices, including its enterprise NAS and surveillance-focused offerings. It features expedited processing of support requests through Active Insight integration, Fibre Channel support, flash volume deduplication, and a K8s CSI driver to improve volume management in Kubernetes.
Synology also announced Hybrid Share which enables simple and fast file synchronisation between locations or offices, combining efficient local file caching with bandwidth offloading to the cloud to improve productivity while reducing IT burdens.
Data Warehouse-as-a-Service supplier Vertica has launched its Vertica Accelerator, which runs on the new Vertica 11 Unified Analytics Platform. Vertica Accelerator runs on AWS public cloud infrastructure in a customer’s own AWS account, providing the ability to preserve all negotiated pricing and committed spend while automating the setup and management of the Vertica environment. It includes all of the core functionality — from advanced analytical functions including time series, pattern matching, geospatial, and in-database end-to-end machine learning.
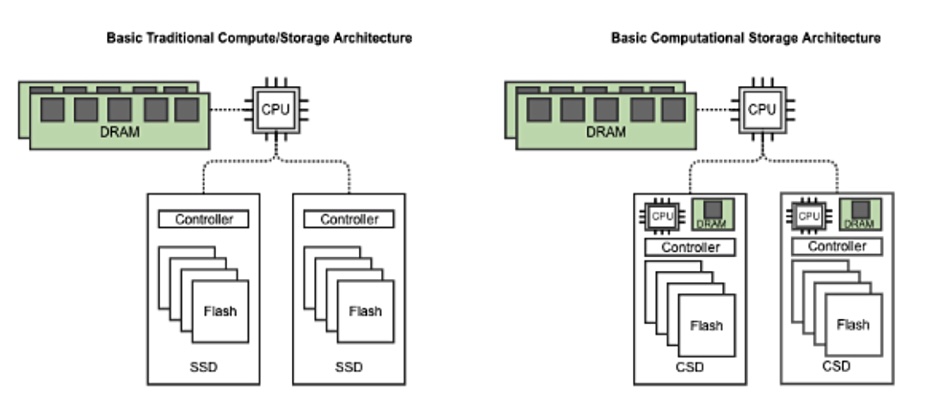
Server virtualiser and containeriser VMware has a blog arguing for the use of computational storage at the edge. It’s to get rid of computational bottlenecks caused by moving data to compute. “Computational storage devices (CSx) enhance the capabilities of traditional storage devices by adding compute functionality that can improve application performance and drive infrastructure efficiency.”
VMware computational storage diagram.
The blog explains: “Instead of moving the data to a central location for processing, we move the processor to the data! By allowing the storage devices to process the raw data locally, CSx (SSDs with embedded compute, like those provided by NGD Systems) are able to reduce the amount of data that needs to be moved around and processed by the main CPU. Pushing analytics and raw data processing to the storage layer frees up the main CPU for other essential and real-time tasks.”
ReRAM developer Weebit Nano has implemented its ReRAM in a 28nm process. This is much denser than the 130nm process with which most of its development work has been done, and a step on from the prior 40nm process. It says this is a key step in productising the technology for the embedded memory market and the technology can support smaller geometries used in AI, autonomous driving, 5G and advanced IoT.
Western Digital says the World Economic Forum (WEF) has named two of its smart factories in Penang, Malaysia and Prachinburi, Thailand to its Global Lighthouse Network, a community of world-leading companies that have demonstrated leadership in the adaptation of Fourth Industrial Revolution at scale in both technology innovation and workforce engagement. Lighthouses apply 4IR technologies such as artificial intelligence, 3D printing and big data analytics to maximise efficiency and competitiveness at scale, transform business models and drive economic growth, while augmenting the workforce, protecting the environment, and contributing to a learning journey for all-sized manufacturers across all geographies and industries.
Zadara’s enterprise-grade, expert-managed cloud services — including compute, storage and networking — are now available to Cyxtera customers. Zadara’s fully managed storage-as-a-service has been available in Cyxtera’s 61 highly connected, hybrid-ready datacentres worldwide. Now Zadara’s zCompute has been added and delivers a seamless on-demand cloud experience available in Cyxtera datacentres, built and managed by Zadara.
People
Victoria Grey has resigned from her role as CMO at Arm server startup Bamboo Systems. Previously she had been CMO at Nexsan and VP Marketing at Quantum as well as a VP at EMC after it bought Legato where she was OEM Sales Manager.
NVMe-oF storage supplier Excelero has hired Jeff Whitaker as its VP of Product. He joins Excelero from NetApp, where he was a founding member of the NetApp cloud team that defined its first cloud-based products. His most recent role was NetApp’s senior manager of hyperscaler portfolio marketing.
HYCU has hired Michele Lynch to be its EMEA Channel Director. She comes via stints at Spirent, Localis, Scality and Commvault.
Panzura CEO Jill Stelfox has been named Transformation Leader of the Year for 2021 in the annual Globee Awards by an international panel of experts. A Panzura spokesperson tells us: “The accolade is based on Jill’s leadership through Panzura’s Refounding process which started with our acquisition last May and officially concluded a few weeks ago.” Among the achievements are a Net Promoter Score of 87, and rocketing past all previous sales records with year-over-year revenue growth of 525 per cent and an ARR of 96 per cent.
CharmingBootnote. Where did the term Charmed Opertator come from? Portainer tells us: “‘Juju was created in 2009 in order to tackle the infrastructure and application management problem, trying to take the solution a step forward from the traditional configuration management tools. Ever since its beginning, Juju used “charms”, wrappers of code to manage infra/app components by encapsulating the knowledge of human operators.
“These two names were employed, because at that time people considered the solution working “like magic”. In recent years, Kubernetes operators have started to make their appearance to solve the same problem within the cloud native ecosystem. Since Kubernetes quickly became a first class citizen in Juju, we decided to slightly rebrand charms into “charmed operators”. The difference between standard Kubernetes operators and charmed operators is the latter’s ability to integrate and drive software lifecycle management across different cloud environments, not only Kubernetes, but also legacy systems, virtualization platforms (e.g. Openstack) and public clouds.”
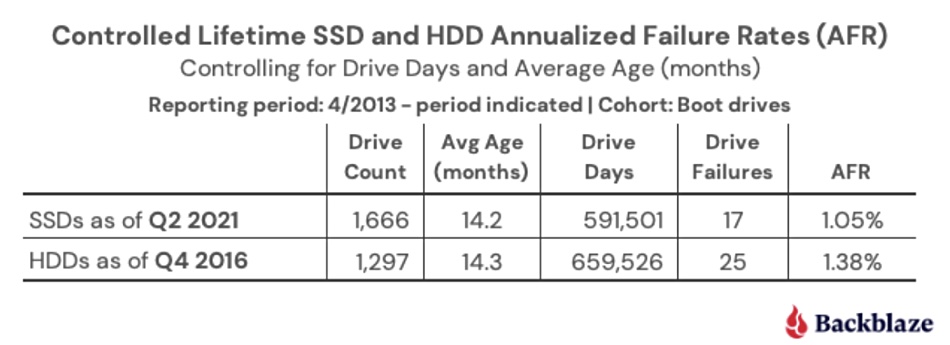
Cloud backup and data storage provider BackBlaze is finding its SSDs fail at nearly the same rate as its disk drives at the equivalent stage in their life cycle.
A Backblaze blog by Andy Klein, its oddly titled Principal Cloud Story Teller, outlines how Backblaze used to boot its systems off disk drives and then started using SSDs instead. It monitors its disk drive reliability and does the same for its SSDs, so it can compare their failure rates. To make the comparison fair, it compared the SSD failure rates to the HDDs used for boot drive duty at a similar age in their life cycle and found similar failure rates.
Klein wrote: “Where does that leave us in choosing between buying a SSD or a HDD? Given what we know to date, using the failure rate as a factor in your decision is questionable. Once we controlled for age and drive days, the two drive types were similar and the difference was certainly not enough by itself to justify the extra cost of purchasing a SSD versus a HDD. At this point, you are better off deciding based on other factors: cost, speed required, electricity, form factor requirements, and so on.”
Here’s the tabulated Backblaze summary data:
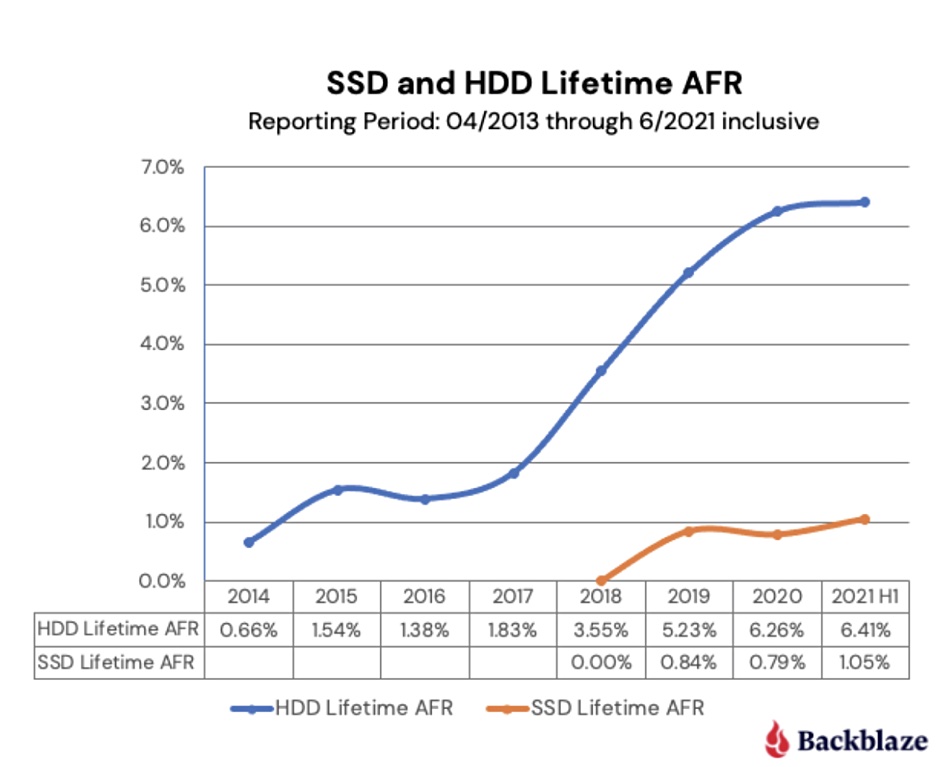
The SSDs did fail less often than the HDDs — with a 1.0 per cent annual failure rate as opposed to 1.38 per cent for the disks. Then Klein charted the data over time to see what the curves looked like:
There’s an uncanny resemblance in the shape of the two curves. However the HDD curve steepens substantially after four years of deployment. So the big, big question is whether the SSD curve will do the same thing. We guess we’ll see in October 2022, so long as Andy Klein puts the data out for us all to see.
Western Digital has launched an SSD tailored for acting as a cache in disk drive-based network-attached storage arrays and so speeding them up.
Red is WD’s drive brand for NAS products. The Red SN700 SSD is a long-life drive in the M.2 gumstick card format with 250GB, 500GB, 1TB, 2TB and 4TB capacity levels. It follows on from 2019’s Red SA500 SATA SSD with its 500GB to 4TB capacity range, and is much, much faster as well as having a doubled endurance rating.
The SN700 is rated as a 24×7 operation drive and its endurance makes it suitable for NAS use with much reading and writing of data. The Red SA500 came in both 2.5-inch and M.2 formats, but the SN700 is M.2 only.
WD is being coy about the type of flash inside the SN700. We know the SA500 used BiCS 3 generation 3D NAND, 96-layer TLC flash, but WD is now shipping BiCS 4 96-layer product and foundry partner Kioxia has announced BiCS 5 176-layer products.
Tamblyn Calman, sales and marketing director at QNAP, provided a quote for WD: “The WD Red SN700 NVMe SSD helps to further enhance the QNAP product portfolio’s storage capabilities by boosting the NAS system’s read/write speeds without adding to the overall number of disks in the array.”
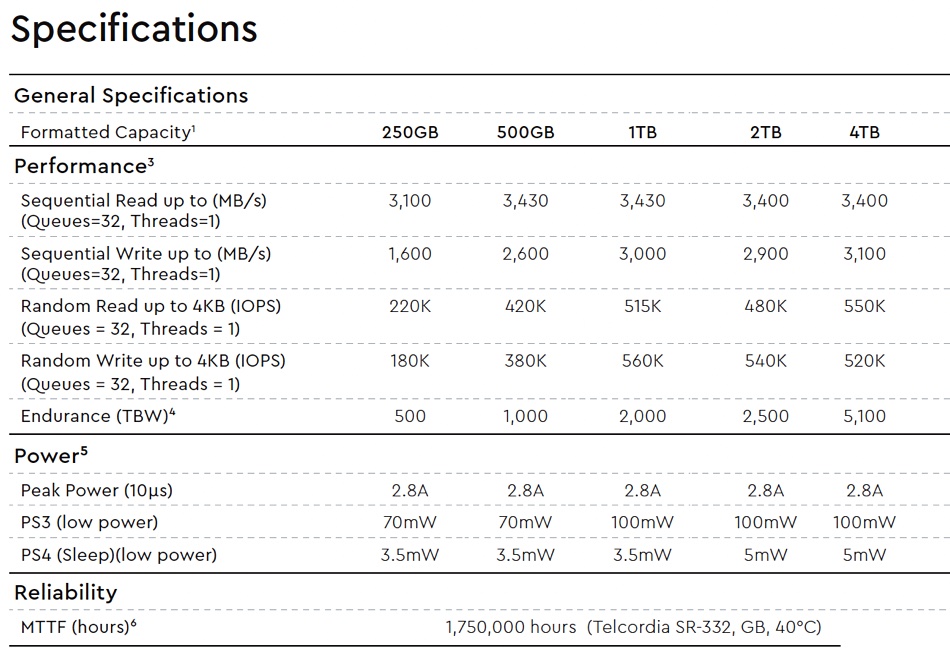
Here is WD’s performance table for the SN700:
It’s roughly similar to WD’s existing Black SN750 M.2 format SSD aimed at the PC gaming market and announced in January 2019.
Here, for reference, is our filed data for the SA500:
The SN700 is around five times faster than its SATA predecessor. The endurance numbers equate to one drive write per day (DWPD) for the 250GB, 500GB and 1TB capacity models but 0.7 DWPD for the 2TB and 4TB product.
Competitor Seagate, which ships IronWolf disk drives into the NAS market, has its own IronWolf 510 SSD. This is also an M.2 format product with lower capacity and performance earnings than the SN700. It has a smaller maximum capacity of 1.92TB and lower performance across its NVMe interface: 380,000/28,000 random read/write IOPS, 3.15GB/sec sequential read and 1GB/sec sequential write. Its endurance is on a par with the SN700 at 1DWPD.
SN700 pricing ranges from $65 for the 250GB model up to $650 for the 4TB product.
AI server developer Graphcore is setting up a reference architecture with four external storage suppliers to get data into its AI processors faster.
DDN, Pure Storage, Vast Data, and WekaIO will provide Graphcore-qualified datacenter reference architectures. Graphcore produces IPU (Intelligence Processing Unit) AI compute chips which power its IPU-Machine M2000 server and IPOD multiple server systems. These are claimed to be better in price/performance terms than Nvidia GPUs at running AI applications such as model training.
Quad-processor M2000 with massive cooling block at the rear.
The M2000 is basically a compute and DRAM box and needs fuelling with data to process. It has four IPUs and a PCIe Gen-4 RoCEv2 NIC/SmartNIC Interface for host server communication. A dual 100Gbit RNIC (RDMA-aware Network Interface Card) is fitted. Stored data will be shipped to the IPU-M2000 from the host server across the Ethernet link.
The system is controlled by Poplar software, which has a PCIe driver. As the system supports RoCE (RDMA over Converged Ethernet), NVMe-over-Fabrics interconnection to external storage arrays is possible.
Vanilla quotes
The four announcement quotes from DDN, Pure, VAST and Weka are pretty vanilla-like in flavour — none revealing much about how they will send data to the M2000s.
“DDN and Graphcore share a common goal of driving the highest levels of innovation in artificial intelligence. DDN’s industry-leading AI storage, combined with the strength of the Graphcore IPU, brings a powerful new solution to organisations looking for a whole AI infrastructure and data management solution with outstanding performance and unlimited scalability,” said James Coomer, SVP for Products at DDN.
“Turning unstructured data into insight lives at the core of an organisation’s effort to accelerate every aspect of AI workflows and data analytic pipelines. Pure FlashBlade, the leading unified fast file and object (UFFO) storage platform was built to meet the demands of AI. It is purpose-built to blend bigger, faster analytics capabilities,” commented Michael Sotnick, VP, Global Alliances, Pure Storage. “Customers want efficient, reliable infrastructure solutions which enable data analytics for AI to deliver faster innovation and extend competitive advantage.”
“The Graphcore IPU, coupled with VAST’s Universal Storage, will help customers achieve unprecedented accelerations for large and complex machine learning models, furthering adoption of AI across the enterprise data centre,” said Jeff Denworth, Co-Founder and CMO at VAST Data. “VAST Data is breaking the tradeoff between performance and capacity by rethinking flash economics and scale, making it possible to afford flash for the entirety of a customer’s dataset. This is especially important in the new era of machine intelligence where fast and easy access to all data delivers the greatest pipeline efficiency and investment return.”
“WekaIO’s approach to modern data architecture helps equip AI users to build and scale highly performant, flexible, secure and cost-effective datacentre systems. Working with Graphcore allows us to extend next-generation technologies to our customers, keeping them at the forefront of innovation,” said Shailesh Manjrekar, Head of AI and Strategic Alliances at WekaIO.
Comment
Nvidia has its GPUDirect program to encourage storage suppliers to ship data as quickly as possible to its GPU servers. That’s accomplished through bypassing the host server CPU, its DRAM and storage IO software stack, and setting up a direct connection between the external storage system and the GPU server.
The four storage suppliers partnering with Graphcore here are all supporting GPUDirect. We would hope, and expect, a similar program for the Graphcore system — IPUDirect if you like — to appear. Asked about this, a Graphcore spokesperson said: “We probably need to wait for the first reference architectures to be released to answer that. We’ve said that this will be happening throughout the remainder of 2021.”
That was unexpected. We thought Graphcore would be driving this.
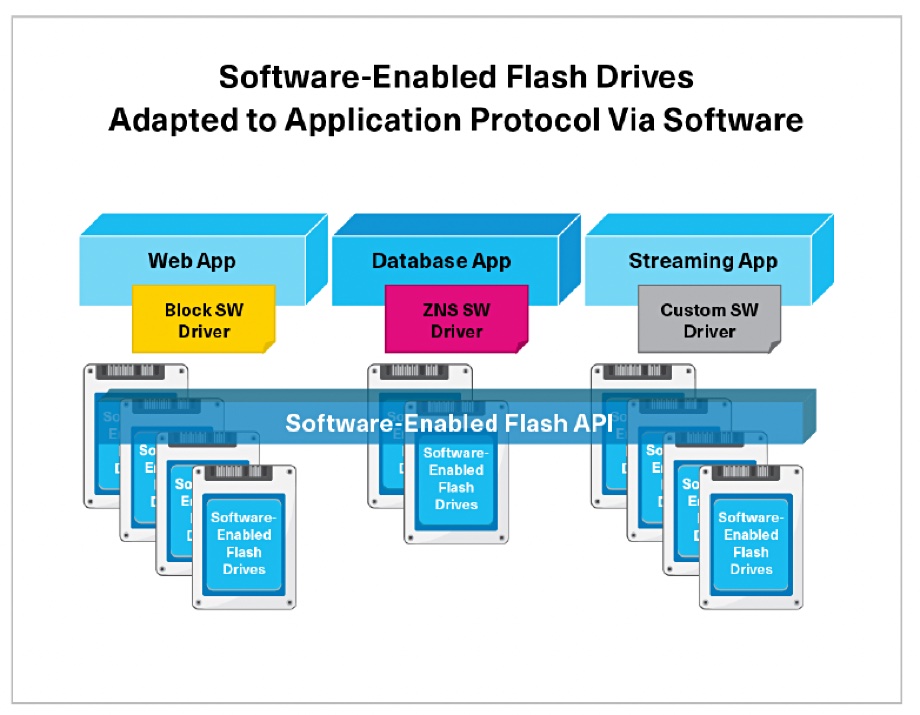
Kioxia has been talking about its software-defined flash technology at this week’s SNIA Storage Developer Conference and introduced a new Software-Enabled Flash SDK to speed the development of software drivers.
The SSD-using market is seeing the development of application-specific flash drives, separate from the base standard SSD with its block interface. They include key:value store SSDs, zoned namespace SSDs, and even customer Flash Translation Layer SSDs for hyperscalers. The problem Kioxia highlights is a hyperscaler one because such customers will have large populations of flash drives, making change-overs of drive technology and supplier problematical.
They can end up with sub-populations of drives of a particular sort, facing costly and inconvenient migrations to adopt new technology. The trouble is that drive format types — such as key:value stores and zoned namespaces — are hard-coded into the drives and also require host software control, locking these drives into specific application use and preventing their re-use for different applications. It would be good for hyperscalers if their key:value store drives could also be used or re-used for zoned namespace applications and block applications.
That’s what Kioxia is doing: creating a flash drive API-based interface that enables SSD operators to reprogram their drives and thereby create a base population of SSDs which can be purposed for specific applications under software control, and then repurposed for different applications.
The drives have a controller and software on them that accept API-delivered instructions, giving access to SSD features down to the die level. New drive types — say QLC drives replacing TLC drives — can have the same design, enabling the host software to drive them in the same way and speed their adoption.
A Kioxia tech brief describes this concept and explains that Kioxia’s software-defined flash tech is open-source and SNIA support is being sought.
The test of whether this idea is generally adoptable will be to see if other SSD suppliers line up and support it, such as Micron, Samsung, SK hynix and Kioxia partner Western Digital — a supporter of the zoned namespace idea. Check out a section of Kioxia’s web site to explore the concept in more detail.
Spurred on by the development of its DNA storage Shannon system, Catalog has taken in $35 million in B-round funding to help devise a storage and computation system based on DNA.
The round was led by Hanwha Impact and the money will also help create an ecosystem of Catalog collaborators, partners, and users of DNA-based computing. Korea-based Hanwha Impact is the rebranded Hanwha General Chemical. DNA is a double-helix molecule present in the cells of all living organisms. It carries genetic instructions for the development, everyday functioning, and reproduction of cells — the base coding foundation for living creatures.
Hyunjun Park, Catalog’s founding CEO and an MIT researcher, said in a statement: “Simply preserving data in DNA is not our end goal. Catalog will fundamentally change the economics of data by enabling enterprises to analyse and generate business value securely from data that previously would have been thrown away or archived in cold storage. The possibility of a highly scalable, low energy, and potentially portable DNA computing platform is within our reach.”
Catalog’s head of molecular biology, Tracy Kambara, prepares Shannon, the first commercially viable automated DNA storage and computation platform for enterprise use.
Catalog’s DNA storage technology involves creating quasi-letters which can represent binary data, and “writing” the resulting DNA sequences to fluid or dry pellets for later retrieval. Such stored DNA is orders of magnitude denser than flash or tape-based storage, air-gapped from online systems like tape, and can last for, it is claimed, thousands of years.
It is possible, Catalog says, to compute the data stored in DNA molecules. This concept is of a compute-in-storage product and its programming and other details have yet to be revealed.
Catalog does say that, by incorporating DNA into algorithms and applications there could be “potential widespread commercial use through its proprietary data encoding scheme and novel approach to automation. Expected areas of early application are artificial intelligence, machine learning, data analytics, and secure computing. In addition, initial use cases are expected to include fraud detection in financial services, image processing for defect discovery in manufacturing, and digital signal processing in the energy sector.”
The firm says that its coming data and compute platform will be more energy efficient, affordably scalable, and highly secure compared to conventional electronic platforms.
Catalog was founded at Boston in 2016 and has taken in a total of $44.3 million according to our records. We think we’ll hear about more progress in 2022.
High tech electronic PCB (Printed circuit board) with processor and microchips. 3d illustration
Israeli startup Speedata revealed its existence today by showing off its big data analytics processing chip development and a $55 million funding round from keen VCs showing they think it’s a good bet.
Jonathan Friedmann.
The big bet here is that data analytics workloads can run one to two orders of magnitude faster than x86 processors when running on the Speedata analytics processing unit (APU) chip. The APU does for analytics what GPUs do for graphics processing.
A statement from Speedata’s co-founder and CEO, Jonathan Friedmann, said: “Analytics and database processing represents an even bigger workload than AI with regard to dollars spent. That’s why industries are anxiously seeking solutions for accelerating database analytics, which can serve as a huge competitive advantage for cloud providers, enterprises, datacentres, and more. …
“Our amazing team of academic and industry leaders has built a dedicated accelerator that will change the way datacenter analytics are processed — transforming the way we utilise data for years to come.”
Pedal to the metal
Speedata has designed a dedicated accelerator chip for these workloads and claims a server with this APU will replace multiple racks of CPUs, dramatically reducing costs, electricity usage and saving space.
The chip is said to address the main bottlenecks of analytics, including I/O, compute, and memory, effectively accelerating all three. It is compatible with all legacy software so workloads can execute on it with no code changes.
High tech electronic PCB (Printed circuit board) with processor and microchips.
The illustration shows the chip fastened to a board. How does it get its data? How is it linked to a host system? We asked Friedman some questions to find out more.
Blocks & Files: How does it get the data it needs to work?
Friedmann: Speedata’s APU connects via a PCIe to a NIC or Smart NIC and/or to local storage. The data flows from local storage via PCIe bus, and/or from remote storage via Ethernet to the NIC and the connected APU.
Does it have its own pool of DRAM with a PCIe bus linking it to storage resources?
Yes. The APU does have its own pool of DRAM and a PCIe bus linking it to storage resource. Since the APU will do all the data processing, this will dramatically reduce the amount of DRAM needed next to the CPU.
How does it hook up to normal servers?
The APU connects to normal servers via a standard PCIe card. The PCIe card contains an APU and is inserted into a standard server. The APU PCIe card is thus hooked up within normal servers in the same way that a GPU PCIe card is hooked up within normal servers.
Any information on its size and number of processing elements and types?
The size and number of processing elements is similar to a GPU. It is important to note that Speedata’s APU elements are optimized for Analytics and Databases, while the GPU elements are optimized for Graphics and AI.
How would the performance in on-premises APU system running database analytics software compare to that same software running in AWS, Azure etc?
Speedata’s APU performance will be up to 20x to 100x more powerful than a CPU when running database analytics. The APU will work equally well on-premise and in public cloud systems.
How does it compare to Snowflake and similar public cloud data warehouses?
The boost in performance may be utilised by multiple types of analytic tools and data warehouses. Snowflake and other similar public cloud data warehouses can use Speedata’s APU to benefit from this improvement in their own data warehouses.
Funding and founding
Speedata has pulled in $55 million of A-round funding from VCs led by Walden Catalyst Ventures, 83North, and Koch Disruptive Technologies (KDT), with participation from existing investors Pitango First, Viola Ventures and prominent individual investors including Eyal Waldman, Co-Founder and former CEO of Mellanox Technologies. Waldman has joined Speedata’s board.
There was a previous undisclosed seed round of $15 million from a group of investors led by Viola and Pitango. This took place in 2019, the year Speedata was founded. Speedata’s total funding is $70 million.
There were six founders: Friedmann, CTO Yoav Etsion, Chief Architect Rafi Shalom, VP System Engineering Dani Voitsechov, Chairman Dan Charash, and Itai Incze, Chief Software Architect.
Friedman was CEO and founder of processor developer Centiped Semi, and a COO at Provigent, a fabless developer of broadband wireless SoCs before that. Charash was the CEO of Provigent. Etsion is an associate professor at Technion, the Israel Institute of technology. Shalom was a chief architect at storage networking NIC supplier QLogic. Voitsechov was a post-doctoral researcher into massively parallel computer systems architecture at Technion. Interestingly, Voitsechov and Etsion have partnered to write research papers. For example, Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays.
We think Speedata will get the APU chip into test use at sample customers and we’ll hear more about it next year.
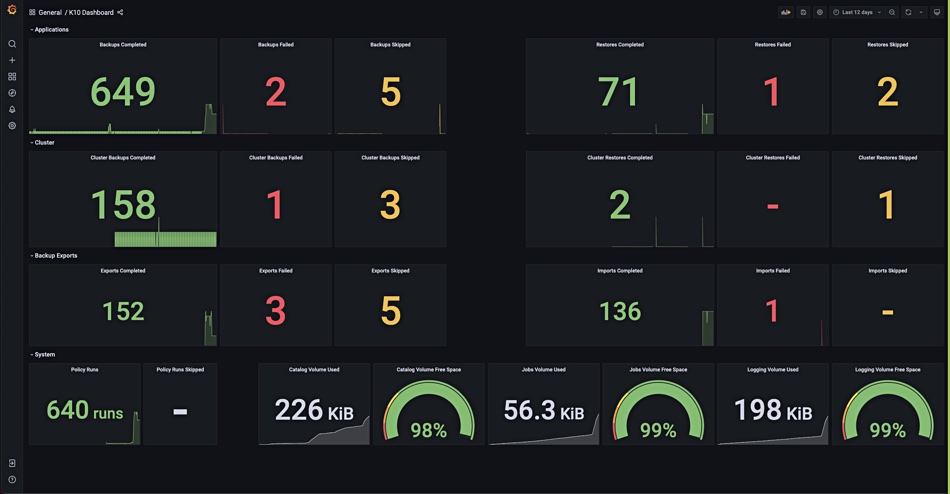
Veeam’s Kasten business unit has upgraded its K10 Kubernetes backup product to extend its coverage to more applications and to edge environments, and to support Veeam’s own Backup and Replication, bringing the two closer together.
Veeam CTO Danny Allan said: “With Veeam Backup and Replication (VBR) data path integration added to Kasten K10 4.5, VBR customers have a pathway to extend their investments into their Kubernetes environments. Users will have better visibility and easier access to a common repository that includes containerised Kubernetes apps, access to Veeam’s portable backup file format for volume content, and more capabilities for enriching their Kubernetes deployments.”
Version 4.5 of the K10 product adds coverage for Kafka, Apache Cassandra, K8ssandra, and Amazon RDS. It supports the K3s and EKS Anywhere Kubernetes distributions extending K10 coverage to edge environments and applications such as video streaming.
Kasten K10 dashboard.
Kasten says that K10 now has an improved out-of-the-box experience through “integration with a complete set of tools to effectively deploy, manage, monitor and troubleshoot Kubernetes environments.”
Clumio has introduced a managed service to protect object data in AWS customers’ S3 buckets, transforming the clunky and limited versioning and replication-based AWS facilities into a single centralised and more capable operation.
Clumio Protect is available for the protection of Amazon EBS, EC2, RDS, Microsoft 365, and VMware Cloud on AWS. It has been extended with Clumio Protect for S3 to cover S3 buckets and their contents in all of a customer’s S3 accounts and regions.
Chad Kenney.
Chadd Kenney, VP of Product at Clumio provided an announcement quote: “S3 is massive and requires a cloud-native data protection solution that is built from the cloud up, to deliver all the scale and efficiencies that existing data protection products cannot provide at a reasonable cost.”
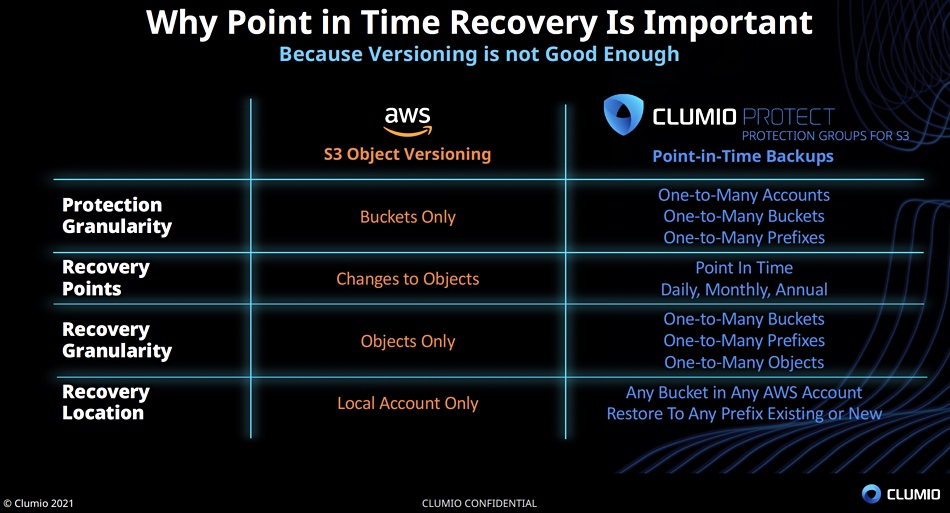
The thinking is that AWS S3 storage is now used for increasing amounts of increasingly critical data, for such things as in-cloud analytics using data lakes. AWS’s own S3 protection involves versioning and replication, both creating extra copies of data which has to be stored at extra cost. That is better than nothing, but far from optimal.
Clumio Protect for S3 protects buckets and prefixes (object groups defined by object name string) across all of a customer’s AWS accounts and regions by moving the data into its own Secure Vault outside of a customer’s region. There is no need for 1-to-1 object mapping, and a Protection Group facility can apply protection polices to multiple objects. Such policies can define periods and which objects and S3 tiers to include or exclude.
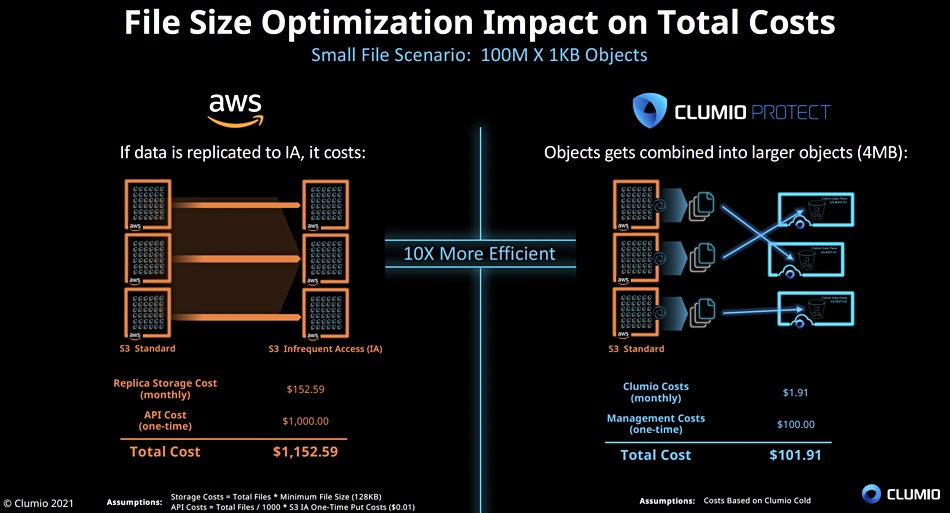
A big selling point of Clumio Protect for S3 is cost. In-house AWS protection for S3 is based on replication with a second copy of the data created in the lower-cost S3 Infrequent Access (IA) tier. The Clumio service combines smaller objects into larger ones and so saves cost. Clumio has modelled the monthly replication costs for 1000 files (objects) in S3 and claims a greater than 10x reduction as its chart shows:
The Clumio service stores a customer’s data in its Secure Vault in a separate out-of-region AWS Clumio account, thus providing a logical air-gap defence against ransomware. Data is encrypted, with customers bringing their own keys, immutable, and access involves multi-factor authentication.
A management plane provides protected object information across all of a customer’s S3 buckets, accounts and regions, in a single dashboard. This makes compliance reporting much easier than fetching data yourself from a bucket survey.
Restoration is to a point-in-time with global search and cross-account browsing capabilities. It also has varying granularity — at bucket level, at object level or at object prefix (object grouping by named type) and to any buckets, prefixes or objects to any S3 tier, prefix or AWS account. That makes recovery from data loss or corruption much faster, potentially decreasing it from hours to a matter of minutes.
Comment
AT first glance an AWS S3 data protection service would seem redundant — as several backup suppliers store their backup data in S3, because it’s cheaper than on-premises storage and the various S3 tiers provide lower costs for ageing data. Clumio makes the point that S3 is being used for online access to data in data lake/warehouse analytics scenarios. That data is growing rapidly and its protection is necessary.
AWS’s own facilities are clunky, not optimised for cost as much as they could be, and limited in management reporting and restoration flexibility. Step forward Clumio with a slicker and more comprehensive service that can cost much less.
This is the first such AWS S3 protection service and we expect other SaaS backup service providers protecting data in AWS to follow in Clumio’s footsteps.
AWS has introduced cross-account and cross-region protection for files with CRAB for FSx, and could well upgrade its S3 protection facilities in the future.
Clumio Protect for Amazon S3 is expected to be available for early access by late October and generally available by December 2021.
Startup Lightbits has gained NVMe/TCP certification from VMware with vSphere 7 Update 3 for its LightOS software and is now competing head-on with other NVMe/TCP storage suppliers.
LightOS is a storage array controller product, featuring NVMe/TCP, and provides independent scaling of compute and storage on commodity hardware. It supports Intel’s Gen-3 Xeon SP processors, Optane persistent memory, and 100Gbit/sec Ethernet NICs, and QLC SSDs. A single LightOS cluster can deliver over 40 million IOPS (random Read) and 10PB of user capacity, with less than 200μs latency.
Kam Eshghi.
Kam Eshghi, Chief Strategy Officer at Lightbits, provided a quote: “We are super-excited to have a high performance, highly available storage solution also for VMware users, with in box support for NVMe/TCP. Organisations with private clouds and hybrid clouds, as well as cloud service providers and financial service providers, can now realise the performance, scalability, and cost-efficiency benefits of a combined solution from VMware, Lightbits, and Intel.”
Performance and cost
Basically Lightbit’s message is equivalent or better data services and faster storage access performance at lower cost. We understand that In general, Lightbits NVMe/TCP scales linearly with over 6x more IOPS vs iSCSI at the same thread counts while attaining as much as 4x lower latency vs iSCSI (on the same hardware).
It will be revealing more performance data this week at a VMworld event.
The company tells us it reduces a customer’s storage TCO by:
QLC SSDs, ~30 per cent lower cost than TLC SSDs;
Higher density per storage node, amortizing the fixed cost of the storage server over larger capacity;
No hypervisor required on storage node (no license fee).
Comment
Since NVMe/TCP is becoming table stakes in storage networking — witness the array of vendors supporting it — Lightbits is competing in the level playing ground of the software-defined storage market, looking for greenfield wins and iSCSI upgraders.
It is in competition with other NVMe-oF suppliers such as Excelero, as well as QLC flash and Optane supporting suppliers such as StorONE and VAST Data. On the NVMe/TCP front it is facing up to to Dell, NetApp, Infinidat and Pavilion Data, and may find attacking HPE accounts fertile ground as that company does not have NVME/TCP support — yet. Ditto IBM. The iSCSI upgrade market in the two installed bases may provide a fertile hunting ground.
Just being a fast access NVMe/TCP target is not enough. Lightbits has to match competing suppliers with their various data services. LightOS supports multi-tenancy, thin-provisioning, snapshots, clones, remote monitoring, dynamic rebalancing, SSD-level Elastic RAID, per-volume replication, cloud-native applications, Kubernetes orchestration, and more. Its SSD management improves flash endurance by up to 20x, which is good as it supports low-endurance QLC flash drives.
LightOS is listed in the VMware compatibility guide and LightOS software-defined storage with Intel high-performance hardware for VMware ESXi 7.0U3 is now generally available.


















 with processor and microchips. 3d illustration")