Datto management believes it is currently the largest pure-play backup software supplier to the MSP market and growing faster than competitors ConnectWise, Kaseya, and N-able. (Thanks to Jason Ader of William Blair.) It think it is well positioned in the long term to capitalise on secular trends toward outsourced IT via the roughly $130 billion managed service provider (MSP) channel. Datto counts more than 18,200 MSP customers (out of an estimated 125,000 MSP providers worldwide), which creates abundant opportunity for deeper penetration. Management is looking to substantially expand its security capabilities over time to fulfil its stated mission of securing all digital assets for its MSP/SMB customers.
…
Quest Software announced GA of SharePlex v0.1.2 which can replicate Oracle databases in real time to MySQL and PostgreSQL. This can be useful when creating mobile or API-based applications, supported by PostgreSQL or MySQL databases, that require data from a legacy Oracle system. SharePlex for PostgreSQL and MySQL supports AWS (RDS and Aurora) and Azure (Azure Database for PostgreSQL and Azure Database for MySQL). It also supports replication to Oracle data warehouses, SQL Server data warehouses, PostgreSQL data warehouses, Kafka, which can then feed other systems, and Event Hubs, which can then feed other systems in the Azure ecosystem.
…
A new release of Raidix’s Era software RAID, version 3.4, provides improved automatic error correcting in case of write hole (inconsistent checksum or data), file drive error monitoring, and support for multi-path NVMe drives.
…
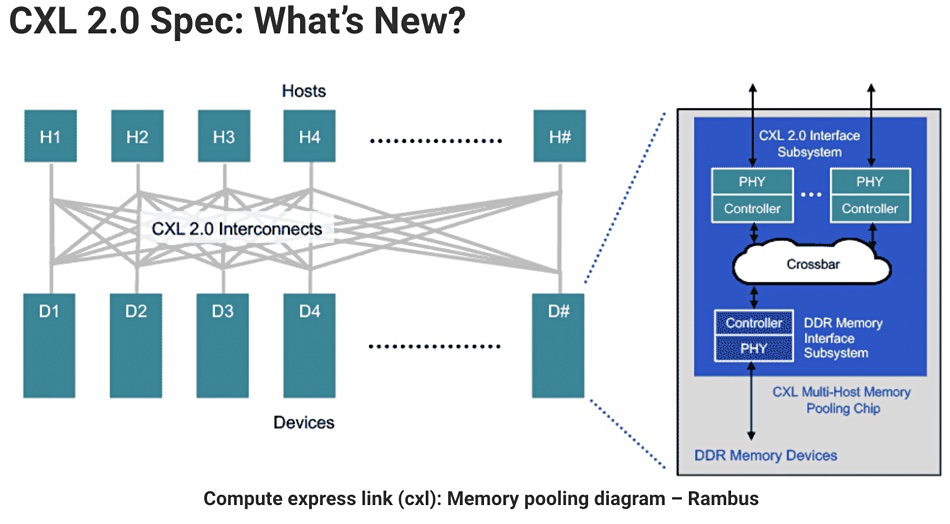
Semiconductor technology developer Rambus has posted a blog about CXL v2.0. It states:”Server architecture — which has remained largely unaltered for decades — is now taking a revolutionary step forward to address the yottabytes of data generated by AI/ML applications. Specifically, the datacentre is shifting from a model where each server has dedicated processing and memory — as well as networking devices and accelerators — to a disaggregated ‘pooling’ paradigm that intelligently matches resources and workloads.” CXL 2.0 supports memory pooling using persistent memory and internal-to-the-host DRAM.
“By moving to a CXL 2.0 direct-connect architecture, datacentres can achieve the performance benefits of main memory expansion — and the efficiency and total cost of ownership (TCO) benefits of pooled memory.”
…
SK hynix’s desire to upgrade its DRAM manufacturing operation in Wuxi, China, by using Extreme Ultraviolet (EUV) lithography equipment to draw finer lines on wafers and thus make denser chips, has had doubt raised over it, according to Reuters. The export of EUV gear to China could fall foul of US State Department rules preventing high tech exports to China.
…
The Taipei Times reports that China’s Alibaba group will lead a consortium offering ¥50 billion ($7.8 billion) to take over the bankrupt Tsinghua Unigroup which makes semiconductor products. There are several Chinese state-backed bids to take over Tsinghua Unigroup, which is seen as important to China’s desire to be self-sufficient in making semiconductor products. It owns, for example, Yangtze Memory Technology Corp.
…
Yangtze Memory Technology Corp. 128-layer 3D NAND Chips.
DigiTimesreported Chinese NAND fabber YMTC has improved the yield rate for its 128-layer 3D NAND. Output could reach 100,000 wafers per month in the first half of 2022. That could/would mean lower NAND chip sales in China for Kioxia, Micron, Samsung, SK hynix and Western Digital.
Peter Oan - Wikipedia public domain - https://upload.wikimedia.org/wikipedia/commons/2/21/Peter_pan_1911_pipes.jpg
What is a startup? What do you call a startup that refuses to grow up and have an IPO — a Peter Pan?
Is Nebulon, a four-year-old company that has raised $14.8 million in a single VC round a startup? Obviously, yes.
Is VAST Data, a six-year-old company that has raised $263 million in four funding events, a startup? We’ll say yes.
Is Fungible, a seven-year-old company that has raised $310.9 million in three rounds a startup? We’ll say yes, again.
Is Databricks, a nine-year-old VC-funded company that has raised $3.6 billion in eight funding events, a startup? The VCs clearly expect a great exit and don’t see this company as a never-to-grow-up Peter Pan.
What of Cloudian, an eleven year-old company that has raised $173 million in six funding events? Still a startup? Well, it’s not so clear, and we’d probably say not.
And how about Delphix, a fourteen-year-old company that has raised $124 million in four funding events. Do we still call it a startup? Fourteen years is a long time to be in startup mode.
Are fifteen-year-old Egnyte and Scale Computing, with $137.5 million and $104 million raised respectively, startups? The founders are still in control. Both say they are growing. Both are VC-funded. And yet to call them startups just seems wrong — their starting-up phase is surely over.
The classic startup in the storage space is a venture capital-funded enterprise growing at a faster-than-market rate through technology development and demo, prototype product build, first product ship, to general availability and market acceptance, followed by an IPO or an acquisition.
Startup-to-IPO journey
Let’s look at three classic startup-to-IPO stories.
All-flash array supplier Pure Storage raised $470 million over six rounds and took seven years from founding to IPO. Six years later it is still going for growth over profitability and making losses.
Hyperconverged Infrastructure (HCI) vendor Nutanix took eight years and five funding events, raising $312.6 million, to reach its IPO. It’s still loss-making five years after IPO as it keeps on prioritising growth over profitability.
It took Snowflake nine years from founding to run its IPO. That effort needed seven funding rounds and $1.4 billion in raised capital.
The overall picture is eight years from startup to IPO. This is startup success. This, or being acquired — especially being acquired in a bidding war, as Data Domain. Acquisitions like this are successful but other acquisitions can be made at a discount to raised capital because the acquiree had not reached escape velocity and was a semi-successful (Actifio) or semi-failing (Datrium) company.
Escape Velocity
We can view venture capital as the rocket fuel needed to enable a startup to reach escape velocity and become a self-sustaining — meaning ultimately profitable — business.
Some startups clearly fail to reach escape velocity, such as Coho Data, which closed down six years after being founded and raising $65 million. Ditto Data Gravity, which closed down in 2018 six years after startup with $92 million raised.
A semi-success or semi-failure was Datrium, which was bought by VMware nine years after its founding with $165 million raised. Tegile was another similar company, bought by Western Digital with $178 million raised nine years after being founded
Other startups fail or semi-fail and get bought by private equity, which aims to extract value from the ruins and then sell it off. Thus PE-owned StorCentric bought seven-year-old Vexata, into which VC backers had ploughed $54 million.
Veeam was bought for $5 billion by private equity, but this was not a failure — it was a signal of its success, and an outlier.
And what of the rest? Older, VC-funded startups, such as Cloudian, Databricks and Delphix, that have not reached escape velocity?
The in-betweeners
Such companies are no longer operating in startup mode, surely? You can’t sustain that sense of developing completely new technology to change the world for nine, eleven or fourteen years. The backing VCs might still hope for a profitable exit — they surely do with Databricks. Yet these post-puberty companies, if you will forgive the expression, these near-teen and teenage companies, are in-between the startup phase and whatever their exit phase from VC funding will be.
HPEer Neil Fleming, tweeting personally, wrote: “Can we talk about what defines a startup? Databricks is eight years old, has 2K employees and turn over of $425Mm (according to Wikipedia). What’s the threshold of when something stops being a startup and starts being a business?”
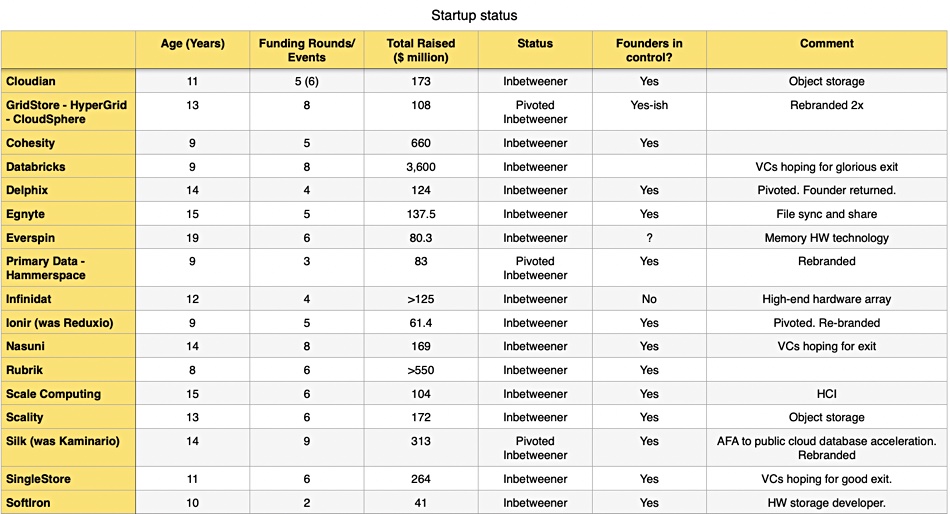
Storage consultant Chris Evans identifies Peter Pan companies as the ones that never grow up. We listed pre-IPO, pre-acquisition, post-startup storage companies that could be classed as “in-betweeners” in a table, showing their age, number of funding events, and total raised:
This is far from an exhaustive list.
They are all nine or more years old, with Everspin topping this characteristic at 19 years of age. The in-between stage can clearly be a long march.
Pivots
Some of them are marked as having pivoted — meaning that they changed the marketing direction of their technology. Thus Kaminario started out as an all-flash array hardware vendor, pivoted to being an all-flash array software vendor and then pivoted again, with a rebrand to Silk, and focussed its software technology on accelerating databases in the public cloud. It is fourteen years old and still has its founding CEO in charge. He’s managed to raise $313 million in nine rounds and the VCs are still, it appears, hoping for a successful exit. Similarly, GridStore became HyperGrid, which became CloudSphere. Reduxio has become Ionir, and Primary Data evolved into Hammerspace. These companies may prefer to say that their new enterprises are fresh startups, but we can see a technology trail and a founding team link between the old and new companies.
The oldest inbetweener we have in the table is Everspin. ExaGrid is 18 years old and still hoping for an IPO. HCI vendor Pivot3 was bought by Quantum 19 years after it started up, passing through 11 eleven funding events which raised $247 million. That was not a successful exit.
Nantero, developing carbon nanotube memory, is 20 years old, with $120 million funding accumulated through eight funding events.
One of the longest-lived in-betweeners is HPC storage vendor Panasas, at 21 years, and $155 million raised in, we think, eight rounds. It may well be profitable. We should note that DataCore, although older, at 23 years old, is an outlier. It had not been a VC-backed startup for many years until it took in $30 million in 2008. The company has been profitable for ten years and very recently bought Maya Data.
It is ridiculous, we would assert, to view DataCore, Everspin, Nantero and Panasas as startups.
We think a better term is in-betweener, until a better one comes along at any rate. We won’t refer to any company more than nine years old – the Snowflake startup-to-IPO period – as a startup any more.
The second generation of Panzura’ CloudFS SaaS filesystem software, also known as Data Services, introduces two-tier licensing with complementary basic and per-user tiers, functional licensing, high-availability nodes and search across multi-vendor file storage systems.
Panzura says its global cloud file system acts like an enterprise NAS, and looks like a standard Windows file share to applications and users. The software has automated, distributed file locking and real-time data consistency for every location in a global cloud network. It is not using capacity-based licensing for its CloudFS software and has made it more enterprise-capable by adding support for highly available nodes, bringing in file scanning on non-Panzura systems, audit data retention improvements, plus a preview of automated CloudFS node configuration and management.
Edward Peters.
Panzura’s chief innovation officer, Edward Peters, said: “Now [users] can go beyond an exclusively storage-based approach and separately license access for value-added functions such as enhanced audit and search capabilities.”
The configuration and management services include faster connection status detection of CLoudFS nodes, new inventory management tables, a Dataset View of a customer’s data sources for a CloudFS deployment, and a Node View feature to access an inventory of all CloudFS nodes.
Basic tier
The Basic tier allows file access and provides:
Inventory of CloudFS components;
Summary of component operational status;
Monitoring and reports on metrics for the CloudFS network;
Configurable alerts if storage, system and cloud thresholds are exceeded — quotas can be set — and may require attention;
List of plug-ins for nodes registered on Data Services.
Disaster recovery capabilities enable the instantaneous rollback of files to a previous, granular state prior to accidental deletion or file corruption by ransomware or other malware exploits, with no data loss.
Licensed tier and functions
This is a tier of licensable services with separate licensing for Search, Audit and Audit Retention.
The Search license is provides up-to-the-second results and insight into the entire global file system including recovery services, quota services and data analytics.
This global function enables search and data analysis across all connected file systems, including Panzura and other compatible SMB and NFS file shares, for files, directories and snapshots. Data Services ingests the metadata of files and directories from connected file shares, including CloudFS, NetApp, and Dell EMC Isilon according to a periodic schedule, and indexes them into a searchable database.
The Audit license allows users to track and audit file opens, changes and access, find renamed or deleted files and recover them with a single click.
Audit functionality is provided by ingesting file logs in near real-time, providing a one-click view into user actions taken on files such as read, write, delete, move or update permissions.
The Audit Retention license provides for 180 days of data-log retention — double the prior amount. Multiple licenses can be purchased to cover longer data-retention periods.
Comment
In September, Panzura said it had been officially refounded, almost a year and a half since it was bought by private equity and given a new CEO. Refounding means, we think, that a founders-type mindset has been reimposed on the company to get it growing again and to get fresh employee commitment. The website was given a new look and the company gave itself a fresh new logo as well to mark a break from the past. Behold:
New Panzura logo.
Let’s see if Panzura gets growing again and becomes a file collaboration and sharing company to be reckoned with. Download Panzura white papers from here to get more details of its software’s capabilities.
AT SC’21 Dell EMC announced new and updated Dell Technologies Validated Designs available for Siemens Simcenter Star CCM+. They provide multi-physics CFD simulation on the latest Dell EMC PowerEdge servers with PowerSwitch and InfiniBand networking, and options for HPC storage. A new Dell EMC PowerSwitch S5448F-ON top-of-rack switch has higher density with 100/400Gbit/sec speeds, and simplifies complex network design, deployment and maintenance when running the Dell EMC SmartFabric OS10 with integrated SmartFabric Services, or CloudIQ for cloud-based monitoring, machine learning and predictive analytics.
…
MemVerge (in-memory computing with virtualised memory) has a SpotOn Early Access Program. It asks: “Do you have non-fault-tolerant and/or long-running workloads, and would like to run them on much lower cost AWS Spot Instances? Then join our SpotOn early access program to mitigate the risk of terminations which can save you a ton of heartache and money.”
…
Micron has shipped the first batch of samples of LPDDR5X memory built on its first-to-market 1α (1-alpha) node. It’s designed for high-end and flagship smartphones, powered by artificial intelligence (AI) and for 5G. Micron has validated samples supporting data rates up to 7.5Gbit/sec, with samples supporting data rates up to 8.533Gbit/sec to follow. Peak LPDDR5X speeds of 8.533Gbit/sec deliver up to 33 per cent faster performance than previous-generation LPDDR5.
…
AKQUINET, MT-C and the Fenix consortium have teamed-up to enhance the multifunctional Data Mover NODEUM to provide a data mover service within the Fenix infrastructure. This service will allow users to seamlessly manage data stored in high-performance parallel file systems as well as on-premise cloud data repositories. There are different Fenix locations, including the European supercomputing centres JSC (Germany), BSC (Spain), CINECA (Italy), CEA (France) and CSCS (Switzerland). Federated cloud object stores are used at these locations, which enable researchers to exchange their data. With the Data Mover, researchers can copy their data locally to the existing parallel file systems in order to process them on the fast HPC systems. They can also copy data to cloud object stores to make them accessible to other researchers globally.
…
OWC announced the OWC miniStack STX, the world’s first Thunderbolt 4-certified storage and hub expansion box that stacks with the Mac mini. It is also a Plug and Play expansion companion for Thunderbolt or USB-equipped Macs, PCs, iPads, Chromebooks, and Android tablets. It has three Thunderbolt 4 (USB-C compatible) ports, a universal HDD/SSD bay and an NVMe M.2 SSD slot to provide storage capacity expansion and can be combined in a RAID 1 configuration. There is up to 770MB/sec of storage performance, and the OWC miniStack STX is good for bandwidth-intensive video editing, photography, audio, virtual machines, and everyday data backup and access tasks.
OWC miniStack STX.
…
NAND Flash controller maker Phison announced its consolidated revenue in October 2021 ($216M) was the highest single month in the company’s history, and cumulative revenue for the first ten months of 2021 was also a record high for any ten-month period ($1.848B). It has increased its head count to more than 3000 globally, including expanded Enterprise SSD Engineering Lab in Colorado. Phison recently signed a ten-year green power purchase agreement to minimize its environmental impact.
…
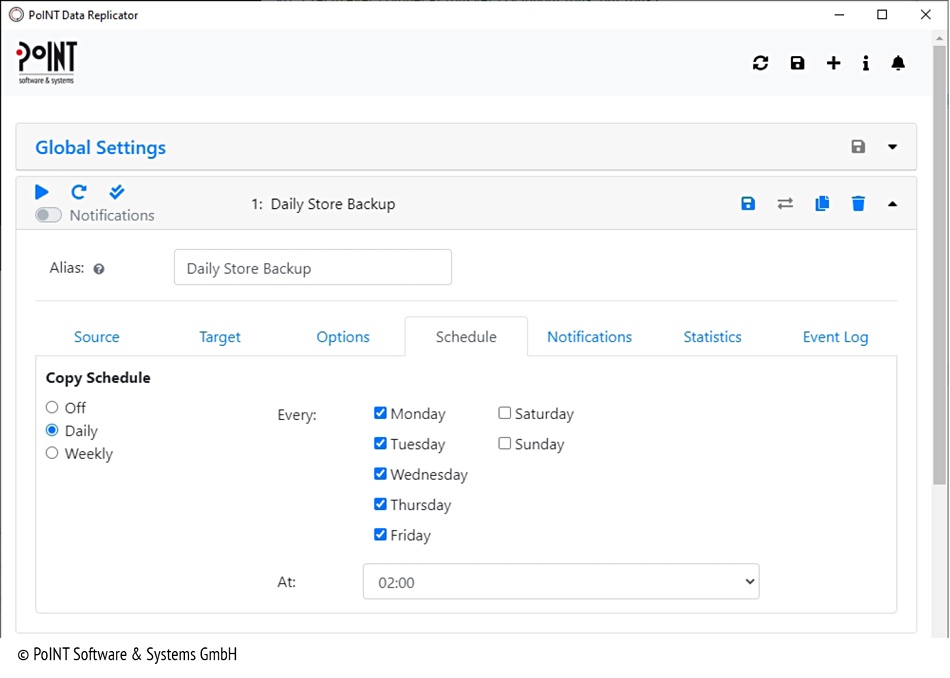
PoINT Data Replicator 2.0 has been announced with S3 Bucket Notification. Version 2.0 is based on GUI independent services. Several replication jobs can be run in parallel and independently. Jobs can be triggered manually; alternatively, execution is controlled by a newly integrated scheduler. With the automated S3 bucket notification PoINT Data Replicator can be used to execute backups of object storage systems. With this function, only new objects are identified and replicated, so that the replication process is much more efficient. The regular jobs then perform a full data synchronization for control purposes.
My mental data and storage classification landscape has been getting confused and briefings with suppliers made it obvious a refresh was needed.
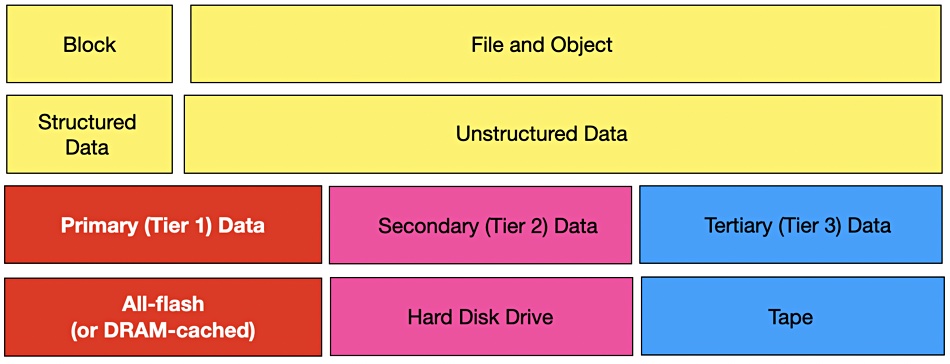
Going back to the basic block-file-object data types I had a landscape clear-out and then tidied everything up — notably in the mission-critical-means-more-than-block area. See if you agree with all this.
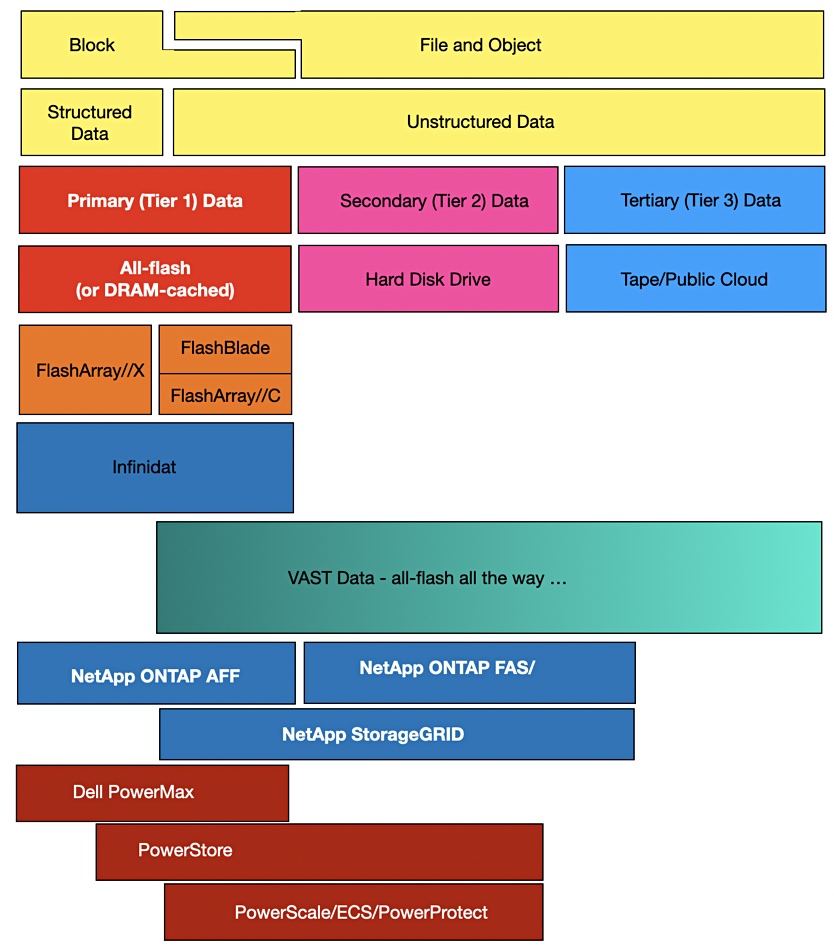
Update. Suppliers and storage categories diagram updated to remove VAST DAta from block category and add FlashArray//C. 25 Oct 2020.
Block storage is for structured — meaning relational or traditional database — data, and is regarded as tier 1, primary data, and also as mission-critical data. If the ERP database stops then the business stops. Typically such data will be stored in all-flash arrays attached to mainframes — big iron — or powerful x86 servers.
Illustrating this diagrammatically started out being simple, on the left, but then became more complex as we moved rightwards:
File and object data is regarded as unstructured data, also often as secondary data — which it may be, but that is not the whole story. Because file data certainly, and object data also, can be mission-critical. It can be primary data and will be put in all-flash arrays as well.
It’s different from block-based primary data where the applications are all database-centric.
Primary file and object data storage tends to be used in complex application workflows where applications work in sequence to process the data towards a desired end result. Think entertainment and media with a sequence of steps from video capture through special effects stages with layers of effects built up, through editing to production. The same set of files is being used, added to, and extended in a concurrent, real-time fashion needing low latency and high throughput.
The same is true in a hospital medical imaging system, though with fewer stages. There is image capture which can involve many and large scan files, analysis and then comparison with potentially millions of other files to find matches, and follow treatment and outcomes trails to find the best remedial procedure.
This needs to be done in real time, while the consultant doctor is with the patient and reviewing the captured image scans.
These both seem similar to a high-performance computing (HPC) application involving potentially millions of files with low-latency and parallel, high-throughput access by dozens of compute cores running complex software to simulate and calculate results based on the data.
We might say that primary file and object storage is needed by mission-critical applications (at the user level certainly and organisation level possibly) which have enterprise HPC characteristics. A separate use case is for fast restore of backup data.
Secondary and tertiary data
Secondary data is different. It is unstructured, file and object-based, not block, and it is much less performance-centric, both in a latency and throughput sense. The need is more for capacity than performance. This does not, therefore, need the speed of all-flash storage and we see hybrid flash/disk or all-disk arrays being used.
Tertiary data is the realm of tape, of cold storage, of low access rate archives. These can be either be on-premises in tape libraries or in the public cloud, hidden behind service abstractions such as Glacier and Glacier Deep Archive.
Suppliers
Having laid out this data and storage landscape we can match some suppliers’ products to it and see how valid the ideas are.
Let’s start with a straightforward matching exercise: Pure Storage. Its FlashArrays are for storing and accessing primary block data. Its FlashBlade products are for storing and accessing primary unstructured data and for the fast restore of backup data.
Block area extended to overlap File and Object area to reflect Pure’s FlashArray//C product.
Infinidat is another straightforward case. Its arrays store block data, hence primary data and, although predominantly disk-based, have effective DRAM caching and caching software to provide faster-than-all-flash performance. Recently it has launched an all-flash system with the same DRAM caching.
VAST Data supplies a one-trick hardware pony — this is meant in a positive way — an all-flash system with persistent memory used to hold metadata, and compressed and deduplicated data stored in QLC flash. This so-called Universal Storage is presented as a single store for all use-cases except primary block data.
NetApp supplies all-flash FAS for primary data, both file and block, hybrid FAS systems for secondary unstructured file data, and StorageGRID systems for object data, both primary (all-flash StorageGRID) and secondary.
A look at Dell’s products suggests that PowerMax is for primary block data, PowerStore for primary block and file data and secondary file data, and PowerScale for primary and secondary unstructured file data. ECS is for object data.
We can position Qumulo too. It’s for primary and secondary file data, with WekaIO targeting primary file data with its high-performance file software.
The two main take-aways from this exercise are that, first, unstructured data refers to both primary and secondary data storage, and second, that primary unstructured data is being used in enterprise HPC applications across a variety of vertical markets.
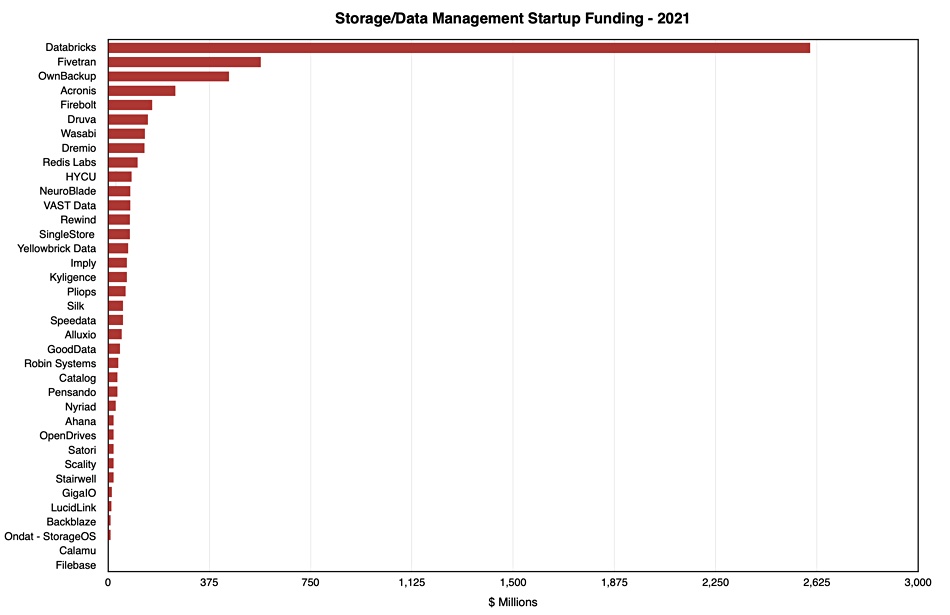
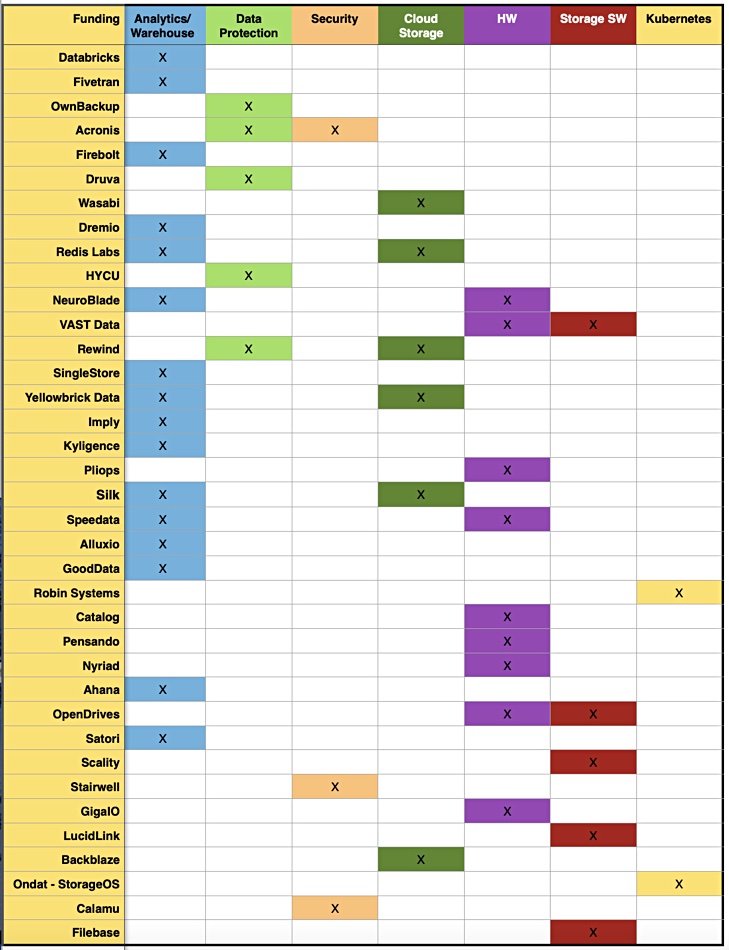
$5.74 billion was invested in 36 storage startups this year, with the vast majority of it – $4.55 billion – going into data lake/warehouse and analytics companies.
We charted the storage-related startup funding we covered during the year and saw that Databricks easily topped the rankings with its extraordinary $2.6 billion raised – nearly half of the total – distantly followed by Fivetran with $565 million, just under ten per cent of the total. Here’s the chart:
Blocks and Files data.
We subdivided the recipients into categories: analytics and warehouses, data protection, security, cloud storage, hardware-led, storage software and Kubernetes-related startups. Recognising that some startups were in two of these categories, we then totted up the amount raised in each category:
Analytics and warehouse – $4.55 billion (79.3 per cent);
Data protection – $1.0 billion (17.4 per cent);
Security – $272.4 million (4.7 per cent);
Cloud storage – $418.75 million (7.3 per cent);
Hardware-led – $418.75 (7.3 per cent);
Storage software – $137.0 million (2.4 per cent);
Kubernetes-related – $48.0 million (0.8 per cent).
The security total is heavily affected by Acronis’s $250 million raise. It was a mere $72.4 million without that. Pure-play storage security startups are not popular. Hardware-led storage startups raised $418.75 million – the same as the cloud storage startups.
The non-Kubernetes storage software startups raised $137 million, while the two Kubernetes-related startups raised $48 million – less than one per cent of the total. Storage software as a whole accounted for $185 million. Software is not yet eating the storage hardware startup market.
Storage startup funding categories.
Next, we counted the startups in each category to see how popular they were numerically:
Analytics and warehouse – 16
Data protection – 5
Security – 2
Cloud storage – 6
Hardware-led – 9
Storage software – 5
Kubernetes-related – 2
Hardware-led storage startups often have software involvement too – especially array companies like VAST Data and OpenDrives. We were surprised that there were more hardware startup funding rounds than data protection rounds, although the data protectors raised more than twice as much money.
So what does it all mean?
Our conclusion is the obvious one: massive amounts of VC funding is flowing into the analytics/data lake/data warehouse space, with data protection the next most popular category. The fact that cloud storage is getting more funding than other (on-premises) storage software companies is not unexpected – if we take out the VAST Data and OpenDrives hardware-led storage software players we are left with a derisory $34 million.
The low level of funding – $48 million – going into just two Kubernetes-storage related startups was surprising. We think that the mainstream suppliers have adopted Kubernetes quickly and effectively, and that open source development is cheap. In effect, we could say that the Kubernetes storage startup wave is over. Finished.
Essentially the bulk of storage startup funding this year has gone up-stack, away from the hardware and software boxes and into data-handling software. That is, software to protect the data, and – the big bucks golden goose area – software to store, access and manage large amounts of data for analytics.
Acronis announced that 2021 was the best year in its history. Ronan McCurtin, VP sales Europe, Israel and Turkey, said: “This has been a record-setting year in revenue growth and partner recruitment.” Over 20,000 service providers are using Acronis Cyber Protect to protect more than 750,000 customers. As of end of the third quarter in September, Acronis in Europe grew by 118 per cent in the number of workloads protected, and by 35 per cent in number of customers protected. To date, Acronis has added 408 new employees and expects to close the year at over 450 new positions globally. It has 38 datacentres across the globe, of which 18 are in Europe. Acronis has a roadmap with more products and updates to come in 2022.
…
Startup Alluxio has pulled in a $50 million C-round of funding from a16z, Seven Seas Partners, and Volcanics Venture. It will spend the cash on opening an office in Beijing, product development, go-to-market, and engineering operations. Alluxio’s open source software virtualizes data stores and enables big data analytics apps to access multiple and disparate data stores in a single way instead of using unique access routes to every storage silo.
…
Druva has rebranded its product set, calling it a Data Resiliency Cloud, a multi-tenant, cloud-native SaaS offering based on AWS, with on-demand scaling — not that its announcement admitted it was a rebrand. It claims this offers support for all data and applications with globally distributed, cross-cloud recovery capabilities. Druva says it has automatic ransomware protection, scalable orchestrated recovery, and complete operationalisation with pre-built integrations with Security Monitoring (SIEM) and Security Orchestration (SOAR) tools. The DRC can be used for for multiple use cases including backup, disaster recovery, archiving, e-discovery, data cloning, and analytics.
…
FileShadow announced that it now archives email and attachments from multiple email accounts into its cloud file vault. In addition to connecting Box, Dropbox, Google Drive, local hard drives, and more, FileShadow collects email messages and attachments from Microsoft Exchange, Office 365, Gmail, iCloud Mail, Yahoo! Mail, and generic IMAP servers into its cloud file archive. Once in the FileShadow vault, a machine learning process analyses the content to create metadata tags. Messages and attachments can be organised, searched and published, along with other files from disparate storage locations.
…
HYCU said analyst house DCIG has namedHYCU for VMware a Top Five Midsize Enterprise VMware vSphere Backup Solution. HYCU boasted that DCIG noted its ability to discover, identify and setup protections for the application each VM hosts, focus on fast backup implementations and eliminating the need and cost of introducing a physical backup server, among others. Thirty suppliers were considered by DCIG and the top five were Acronis Cyber Protect, Arcserve Unified Data Protection (UDP), HYCU for VMware, Quest NetVault Plus, and Unitrends Unified BDCDR.
…
Analytics database supplier Imply has appointed DevOps expert Eric Tschetter as its field chief technology officer (CTO). This unites the four original creators of the open source and real-time analytics database, Apache Druid, including CEO and co-founder Fangjin ‘FJ’ Yang, co-founder and CPO, Vadim Ogievetsky, and co-founder and CTO, Gian Merlino. Tschetter will be based in Imply’s Tokyo office, report to Yang, and be instrumental in driving Imply’s newly announced “Project Shapeshift” initiative forward.
…
Intevac, a supplier of thin-film processing systems, today announced the receipt of $10 million in new HDD orders. These orders consist of one 200 Lean system as well as technology upgrades, which will add to the company’s backlog at year-end 2021. The technology upgrades are expected to be installed through mid-2022 and the 200 Lean system is expected to be delivered in the second half of 2022.
…
Kioxia America has joined the STAC Benchmark Council.
…
NAKIVO has announced IT Monitoring for VMware vSphere and has improved backup protection against ransomware in a v10.5 Backup & Replication release. IT admins can monitor the memory, CPU and disk usage of their VMware vSphere infrastructure from the NAKIVO Backup & Replication unified web interface. This is useful for real-time diagnostics and strategic planning. They can project future changes in resource consumption to avoid bottlenecks, from the same interface they use to manage their backups.
…
Nutanix announced announced that Anja Hamilton will join as chief people officer (effective January 4, 2022). She will help continue, we’re told, to shape a growth-minded, aligned workforce with a focus on employee wellness and diversity and inclusion. She will be responsible for the company’s global people strategy and operations.
…
Privacera announced it has joined Snowflake’s Data Governance Accelerated Program to help customers enable secure data sharing and collaboration. Joint customers will be able to manage their cloud data and enforce data access policies with the help of Privacera’s security platform and unified data access governance offerings.
…
Scality announced its ARTESCA object storage solution is qualified as Veeam Ready Object with Immutability. With this certification, both the ARTESCA and RING products are now ransomware protection-enabled.
Block, file and object storage software supplier DataCore has bought MayaData and its Kubernetes storage business for an undisclosed sum. DataCore’s Caringo object storage software has notched up two seven-figure deals with a prominent west coast US technology supplier and a US government department.
MayaData develops and sells its MayaStore OpenEBS-based, hyper-converged, container-attached, block storage software into the Kubernetes market. It comes with a so-called Maya orchestrator. MayaData also offers Kubera as a Kubernetes management software layer that includes OpenEBS and physical storage layer management.
Dave Zabrowski.
Dave Zabrowski, CEO of Datacore, said: “With this acquisition, DataCore is proud to remain the independent software-defined storage vendor with the broadest product offering spanning block, file, object, HCI, and now container-native storage — and the deepest IP portfolio.”
He wants us to know that: “We are committed to investing in OpenEBS as an open source technology, and expanding the community of users, developers, and contributors around it, while providing a streamlined path to leveraging container storage fast, easily, and affordably. You’ll be hearing from us soon with additional solutions for this space.”
MayaData
MayaData was founded as CloudByte in 2011, relaunched as MayaData in 2018 when Evan Powell became its CEO, and has taken in $32 million in funding. In March this year Intel said: “OpenEBS MayaStor is the fastest open source storage for Kubernetes.” A CNCF 2020 Survey cited OpenEBS as the number one cloud-native storage software used in production.
MayaData’s entire San Jose, CA-based team becomes part of DataCore, which will support and invest in OpenEBS and the community around it, and accelerate product development and go- to-market activities. DataCore’s channel can now resell the MayaData software.
The MayaData acquisition deepens DataCore’s involvement with Kubernetes — its SANsymphony product already has a CSI plug-in.
Nick Connolly, technical lead for the CNCF Technical Advisory Group on Storage and DataCore’s chief scientist, said: “MayaData inside DataCore will have the technical resources to reach a wider community of enterprises, faster, while meeting the strict technical requirements of enterprise applications.”
Kiran Mova, architect and maintainer of OpenEBS, also co-founder and chief architect at MayaData, said: “OpenEBS has become the de-facto standard for enterprise workloads on Kubernetes. OpenEBS is seeing millions of pulls every month, and every survey shows it has a good lead on other storage technologies, which reflects the technical superiority of its architecture.”
Timeline
April 2008 — Venture Capital firm Insight Venture Partners and Updata Partners invest $30 million in DataCore.
April 2018 — Dave Zabrowski becomes DataCore CEO as prior CEO George Teixeira becomes chairman.
February 2020 — $26 million invested in MayaData by AME Cloud Ventures, DataCore and Insight Partners. DataCore gets minority share of MayaData, access to its technology and becomes a MayaData reseller.
January 2021 — DataCore buys Caringo and its Swarm object storage technology.
September 2021 — Don Williams becomes MayaData CEO with ex-CEO Evan Powell staying on the board.
November 2021 — DataCore buys MayaData.
In a briefing, Zabrowski told Blocks & Files that Pure Storage’s Portworx was less open than the community-focussed OpenEBS and that Pure Storage was hardware-led, unlike DataCore.
Dave Zabrowski
DataCore CEO Dave Zabrowski was the co-founder and CEO of Cloud Cruiser from 2010 to 2017. Before that he’d been a CEO at Neterion and a general manager at HP. Neterion was acquired by Exar in 2010. Cloud Cruiser developed SaaS application software that provided analytical insights into hybrid cloud consumption for enterprises, SIs and service providers. Its software was licensed by HPE, Cloud Cruiser’s largest customer, as part of its Flexible Capacity offering. This enabled HPE to meter and bill for usage of on-premise IT infrastructure in a pay-as-you-go, cloud economics model
Cloud Cruiser, which had raised $20.7 million in funding, was bought by HPE in January 2017 for an unrevealed amount. Cloud Cruiser became the HPE Consumption Analytics Portal, part of GreenLake Flex Capacity. Zabrowski stayed with HPE for a few months and then joined DataCore.
DataCore and Caringo deals
DataCore tells us that it has made two major, seven-figure deals for its Caringo object storage software. Neither customer was identified beyond one being a significant US technology supplier and the other a US government organisation. DataCore does not have FedRAMP (Federal Risk and Authorization Management Program) certification but some its US reselling system house partners do.
This means DataCore potentially beat Cloudian, Dell EMC ECS, Minio, NetApp StorageGRID, Scality and other competition. That causes us to uprate our idea of Caringo’s technology capabilities and see DataCore as an enterprise object storage supplier.
Zabrowski said he wants DataCore to become the largest privately owned storage software supplier. Yes, an IPO could lie ahead. However, both of Zabrowski’s two previous companies — Neterion and Cloud Cruiser — were acquired.
Comment
DataCore has expanded into the Kubernetes storage space and its storage protocol coverage for applications looks like this:
There are possibilities for MayaData to use DataCore’s file and object technology portfolio. We were surprised to learn that Caringo has won seven-figure enterprise storage deals, having thought it more of a small and medium enterprise supplier — and a niche one at that.
An examination of Zabrowski’s background, together with the Caringo deals, suggests that DataCore could well emerge to be a significant enterprise storage player — one to be considered alongside the mainstream suppliers. It has not had a relationship with Gartner that gets it entry into Magic Quadrants and Critical Capabilities reports and such like. Zabrowski said that could well change as DataCore becomes more active in its enterprise marketing.
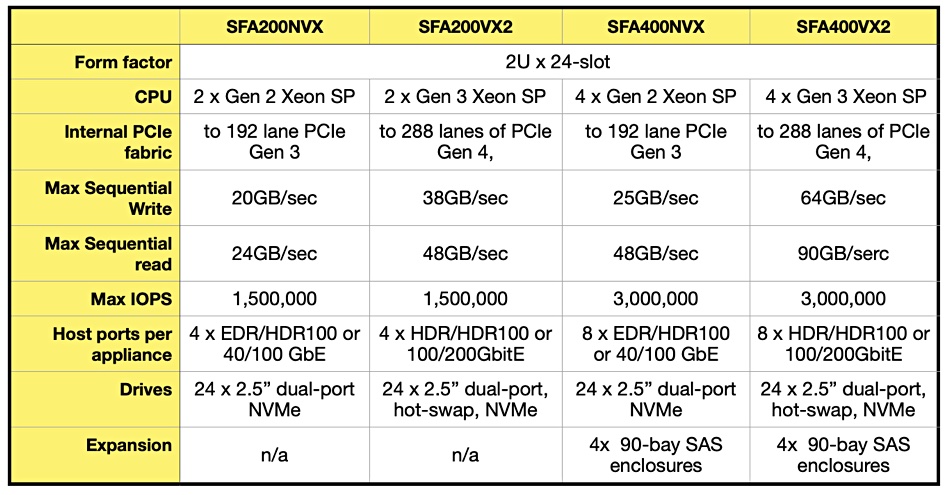
DDN has accelerated its SFA200 and SFA400 NVX arrays by up to 156 per cent by adding more and faster PCIe lanes and upgrading the controllers to Gen-3 Xeon Scalable Processors.
These two block-access arrays share a common chassis (two rack units x 24 slots) which accepts 2.5-inch NVMe SSDs. Client access links have been upgraded as well, with faster base bandwidth. These systems are the foundation of DDN’s storage portfolio and are available as EXAScaler ES400NVX2 and ES200NVX2 scale-out, parallel file storage systems, as well as the recently announced AI400X2 appliances.
SFA400VX2 front panel.
DDN says the new systems are designed to handle the modern data needs of AI applications, like natural language processing, financial analytics, and manufacturing automation, and production systems. In its view the new systems are needed to handle the ever-expanding amount of data these applications require, and to deliver the data fast enough for real-time processing and insight.
We have tabulated the old NVX2E and new VX2 systems using DDN datasheets to bring out the main improvements:
The sheer IOPS performance has not improved at all but the bandwidth has risen significantly, particularly with the old SFA400 putting out 25GB/sec when sequentially writing and its replacement rocketing along at 64GB/sec. There is vastly more internal PCIe bandwidth and speed with the new systems — up to 288 lanes of PCIe 4, versus 192 lanes of half-as-fast PCIe 3 in the replaced systems.
The new SFA400VX2 can be deployed in a hybrid (flash+disk) configuration and have 6.4PB of capacity in half a rack using DDN’s 90-bay drive enclosures. This uses 16 lanes x 4 ports (64 lanes) of SAS connectivity. The new systems can also have up to 64 PCIe lanes providing client connectivity.
The EXAScaler systems have so-called Hot Pools technology which optimises for both performance and low cost by transparently migrating data between flash and disk tiers.
Get a datasheet for the new systems from this DDN webpage.
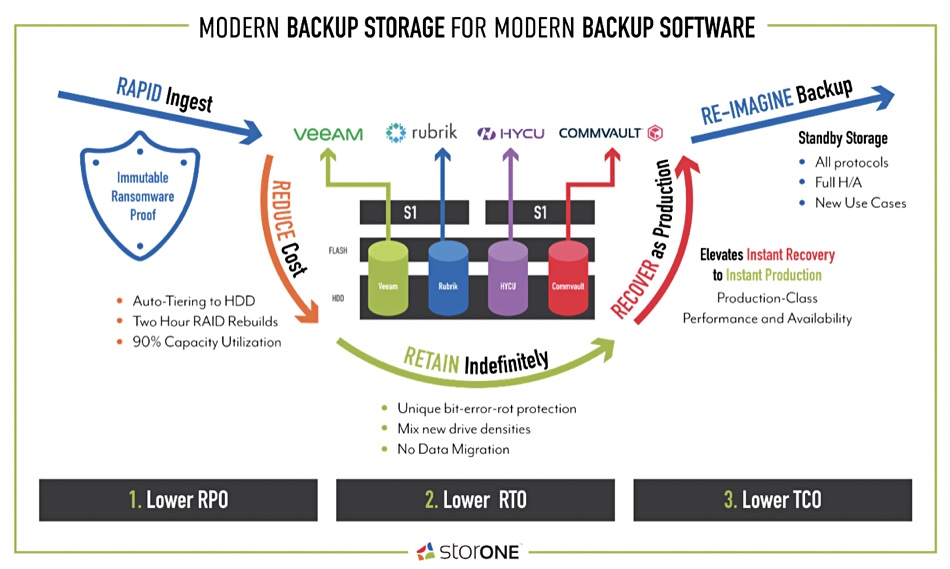
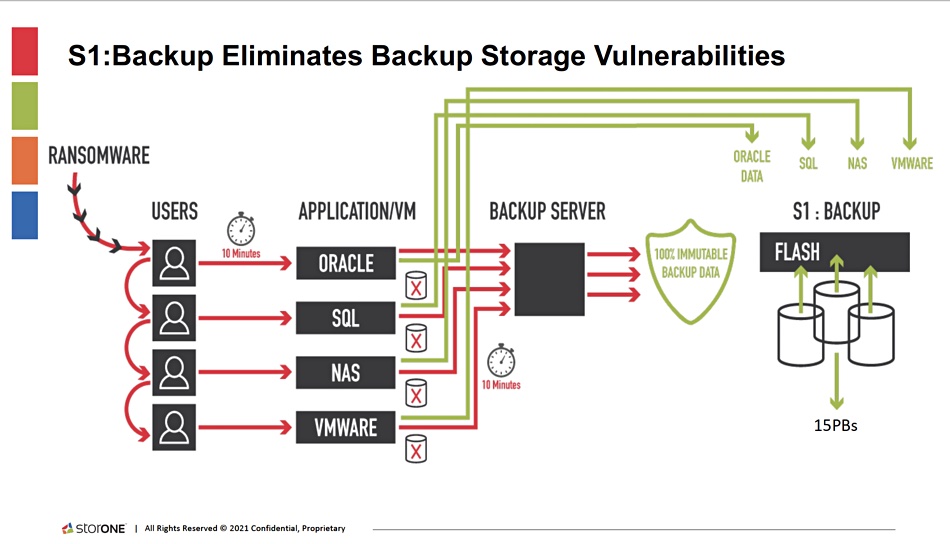
Storage startup StorONE has developed a fast-recovering, ransomware-protecting, flash-to-disk auto-tiering version of its software called S1:Backup.
S1:Backup is a backup target for Commvault, HYCU, Rubrik and Veeam’s data protection software to provide fast ingest to ransomware-proof storage based on a 4–8 SSD flash tier with automated movement of older backups to high-capacity RAID-protected disk — more than 15PB of it. StorONE also has the ability for the clustered S1 array to be a standby production system, thus offering instant recovery.
Gal Naor, StorONE’s founder and CEO, said: “When we examined the points of exposure, we discovered a gap between backup software innovations and storage hardware capabilities, which led to vulnerabilities and higher cost. Legacy backup storage is the cause of that gap.”
In his view, “S1:Backup fills it and enables companies to complete their ransomware recovery strategy and extract the full value from modern backup software by eliminating ransomware concerns and elevating backup to deliver high-availability.”
StorONE claims S1:Backup delivers 100 per cent ransomware resiliency. In general, existing ransomware-protecting systems “force customers to use S3 for immutability. S1:Backup is the industry’s only solution that delivers immutability across all its protocols, including NFS, SMB, S3, iSCSI, Fibre Channel, and NVMe-oF.”
The company claims that high-capacity disk drives can be used in its S1:Backup because its software rebuilds a failed 18TB disk drive in three hours while other suppliers’ arrays can take days or even more than a week. And that situation only gets worse as capacities rise to 30TB and beyond. Newer, higher-capacity drives can be mixed with older, lower-capacity drives in the StorONE system as well, making scale-up more straightforward.
StorONE Ransomware Protection graphic.
S1:Backup captures every backup job in an immutable state, handling hundreds of incoming incremental backup streams with 30-second snapshot intervals, and retains immutable copies indefinitely. Its software can operate at normal speed when its disks are 90 per cent full — there is no performance drop-off past the 50 per cent utilisation level.
This high-utilisation supports long-term storage. The software detects and corrects so-called bit-rot errors which can occur in long-term disk storage. Naor claims this is a future unique to StorONE. S1:Backup can also consolidate block-level incremental backups and create virtual fulls in minutes by using its 100TB+ flash tier.
StorONE also claims a pricing advantage — its pricing is openly available on its website so that customers can make comparisons with competing suppliers’ systems.
When the S1:Backup becomes a standby production system, backed-up VMs can operate in the array and use block, file and object protocols. The S1:Backup system can expand and be used for other use cases — such as archive, NAS, virtual machine storage, databases and even HPC and AI.
Comment
StorONE has close to 100 customers, Naor says. “We are growing fast from several aspects,” he told Blocks and Files, and mentioned repeat orders from existing customers as one example. “Repeat orders give us a lot of confidence.”
The alliances with Commvault, HYCU, Rubrik and Veeam, together with its S1:Backup features — such as ransomware protection, fast ingest and restore, stand-by production capability, and high disk utilisation and fast RAID rebuild capabilities — should make it an attractive alternative to other backup storage targets.
Naor thinks that the market is not yet ready for all-flash backup targets like FlashBlade because they are currently too expensive, and S1:Backup can provide similar or equivalent performance with cheaper archiving.
Commvault has appointed a new Area VP & GM of UK & Ireland: Stuart Abbott. It says he brings extensive experience to his new role, including leading both UK and Ireland accounts at Dell Technologies, and building the current Global Alliances business for EMEA at Dell Financial Services, plus previously working in partnership with multinational organisations including Capgemini and Atos.
…
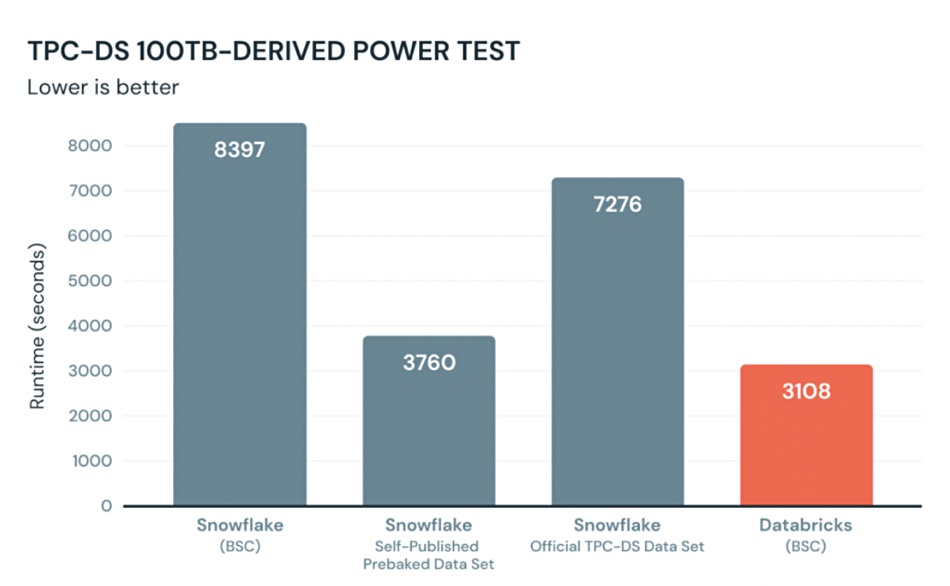
Databricks vs Snowflake wars — round 3. Databricks now claims that Snowflake’s rebuttal of Databricks performance superiority in a TPC-DS Power benchmark run over Snowflake was wrong. A blog states: “We stand by our blog post and the results: Databricks SQL provides superior performance and price performance over Snowflake, even on data warehousing workloads (TPC-DS).” The blog claims Snowflake used a different (prefaced) dataset in its testing which skewed the results in its favour. When Databricks used the official TPC-DS dataset with Snowflake’s SWsoftwarethe result was worse than Snowflake’s number:
BSC is Barcelona Supercomputer Centre test result.
Databricks’ blogger writes: “We agree with Snowflake that benchmarks can quickly devolve into industry players ‘adding configuration knobs, special settings, and very specific optimizations that would improve a benchmark’. Everyone looks really good in their own benchmarks. So instead of taking any one vendor’s word on how good they are, we challenge Snowflake to participate in the official TPC benchmark.” Well … yes.
…
Datacentre composability supplier Liqid released a white paper with industry analyst firm Enterprise Strategy Group (ESG) to highlight the potential of technologies like its Matrix composable software as part of a sustainable ecosystem for next-generation applications such as artificial intelligence and machine learning (AI+ML), high-performance computing (HPC), cloud and edge computing environments to drive intelligent global infrastructure expansion.
…
Nebulon announced its smartIaaS infrastructure-as-a-service offering, designed to help cloud providers deliver new services at lower cost across both hosted and customer-owned datacentres. It also announced that UK-based service provider Inca Cloud has chosen smartIaaS with Supermicro as a part of its new cloud service: WSO by Inca. The service will be built for both hosted and private cloud deployments and will provide enterprises with a multi-cloud solution as an alternative to standalone Google Cloud, AWS and Microsoft Azure. As a reminder, Nebulon’s technology can streamline the costs of a CSP’s existing services by offloading all data services from the server CPU, memory, and network to Nebulon’s SPU (services processing unit) IO controller in each server.
…
Fox Sports is using OpenDrives’ scalable NAS systems for NASCAR and NFL, and will be deploying it for Qatar 2022, the FIFA World Cup event. The two say OpenDrives provides a modular, portable system with a turnkey installation to dramatically reduce complexity, physical footprint and set-up time. A traditional architecture takes days or weeks to set-up while OpenDrives’ solution can be up and running in less than an hour. Using IP-based standard open protocols, OpenDrives integrates with best-in-class broadcast technology and data solution providers, including CMSI, EVS, Western Digital, Signiant, Google, Aspera and Arista, to serve as the centralised hub powering seamless onsite connections and real-time access to content.
.…
There will be a SmartNICs Summit event at the San Jose DoubleTree Hotel from April 26–28, 2022. It will focus on network adapters that can process data and protocols faster. SmartNICs promise better networks with little extra cost or complexity. The Summit will feature vendor keynotes, expert tables and technology and market updates. It will also offer sessions on architectures, development methods and applications. And it will include panels on choosing the right adapter and long-term trends. Chuck Sobey, Summit chairperson, said: “The event will educate designers, present the state of the art and describe standards and open source projects.”
…
Big Data analytics supplier Vertica is partnering with NetApp to use its StorageGRID object system as an on-premises data source for its cloud-native analytics software. Vertica with NetApp StorageGRID has a fast multi-site, active-active architecture and can perform queries 10–25 times faster than conventional databases. Customers experience improved node recovery, superior workload balancing, and more rapid compute provisioning. Vertica says the separation of compute and storage architecture of Vertica in Eon Mode allows administrators to use NetApp StorageGRID as the main data warehouse repository or as a data lake.
…
Western Digital is shipping 20TB capacity Ultrastar DC HC560 and WD Gold disk drives with its OptiNAND technology. They use a 9-disk platform (2.2TB/platter) with a CMR (Conventional Magnetic Recording) recording format — these are not shingled drives. Both drives have a SATA interface and spin at 7,200rpm. The Gold is “for use in enterprise-class datacentres and storage systems” while the DC HC560 is for “hyperscale cloud, CSPs, enterprises, smart video surveillance partners, NAS suppliers and more”. They overlap, in other words.
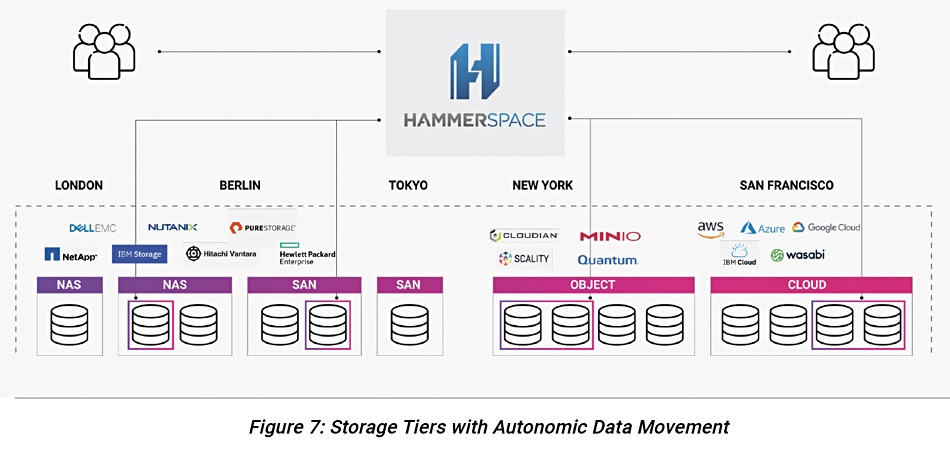
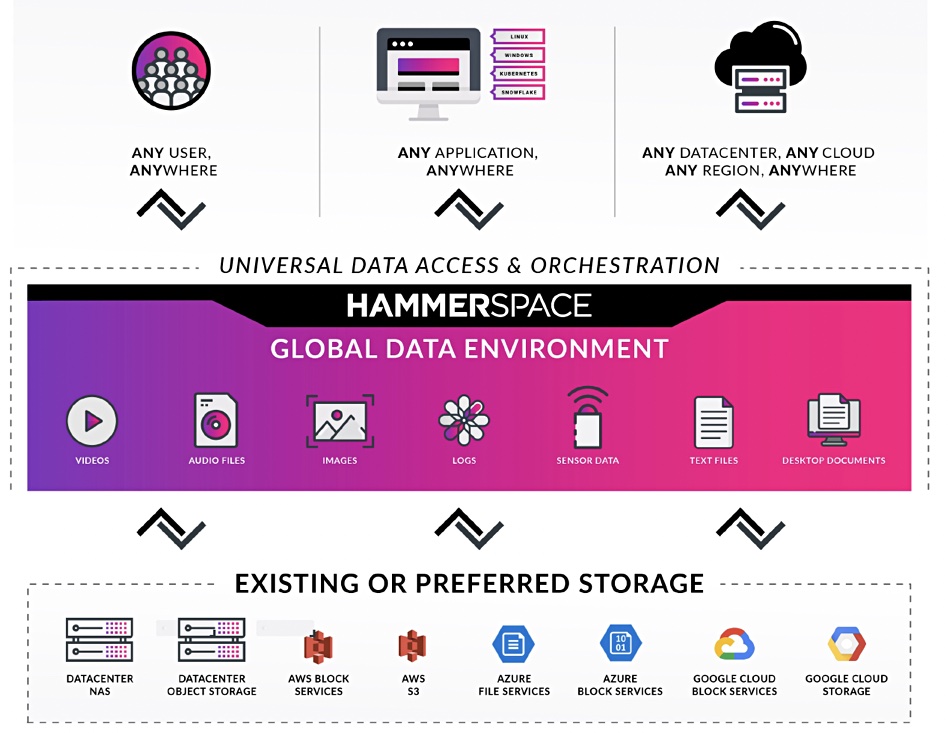
Take a deep breath. Hammerspace, the unstructured data silo-busting supplier, has raised its game to provide a Global Data Environment (GDE) across file, block and object storage on-premises and in public clouds with policy-driven automated data movement and services.
That’s quite a mouthful, and it means what it says. It builds on Hammerspace’s existing file and object metadata-based technology that unified distributed file and object silos into a single network-attached storage (NAS) resource. This can give applications on-demand access to unstructured data in on-premises private, hybrid or public clouds. The idea is to keep data access points updated with the GDE metadata so that all data is visible and can be accessed from anywhere.
CEO and founder David Flynn told Blocks and Files: “Data Gravity is central to the story. In effect, what we’re doing is elevating data to exist in an antigravity field able to access any infrastructure.”
Molly Presley, SVP marketing, said: “For years, I have spoken to customers in Media & Entertainment, Life Sciences, Research Computing and Enterprise IT that constantly struggled with sharing their file data with distributed users. They have tried to build their own solutions, they have tried to integrate multiple data movers, storage solutions, and metadata management solutions and never been satisfied with the results. Hammerspace took on this really tough innovation challenge and created an elegant, efficient, integrated solution.”
Global DataEnvironment
Hammerspace’s GDE can use existing storage resources, assimilating them, taking them over in effect.
An organisation’s stored data is then accessed, as it were, through a logical Hammerspace front end or gateway.
It’s this concept that lay behind its notion of storageless storage, espoused in December last year. Data, Flynn believes, should be free to move between block, file and object silos, wherever they are. We note that GDE is based on file metadata technology and how it interacts with block storage and volumes will be interesting to find out. For example, if files or objects are moved to block storage, do they become one volume or several? We can ask a similar question about block to file or object conversion.
Setting that aside, GDE supports persistent data in Kubernetes environments and treats clouds as regions, with cross-region access supported.
A layer of file-granular data services exists above the storage silo abstraction layer and includes snapshots, replication, file versioning, tiering with policy-driven data movement, deduplication, compression, encryption, WORM, delete and undelete. Policies can be created for any metadata attribute including entity type, name, creation and modification date/time, and owner. Snapshots can be recovered at file level and also at the fileshare level
Hammerspace will dedupe and compress when replicating or moving data over the WAN when data is stored on object storage. The Hammerspace software can run on bare metal servers, in virtual machines (ESX, Hyper-V. KVM and Nutanix AHV) and in the three main public clouds.
Gradually more and more single store-type environments are emerging. Ceph covers block, file and object. Unified block and filesystems get object support through S3. Suppliers, led by pioneering NetApp, are erecting data fabric structures covering the on-premises and public cloud environments. Public cloud suppliers are establishing on on-premises beachheads, such as Amazon’s Outposts and Azure Stack.
Komprise and others are building multi-vendor, multi-site file lifecycle management systems. And now Hammerspace emerges with its comprehensive offering. As Flynn says: “We are talking about universal access to the data.”
David Flynn.
He asks: “How can you have [data] local to this user, local to this application, local to this datacentre? To each and every one of them simultaneously, without ever copying the data, without it being a copy of the data? It’s a different instance of the same piece of data. And that’s in essence what we are doing by by empowering metadata to be the manager of the data.”
Flynn aims to change the relationship between data and infrastructure: “Changing the relationship is done through intent-based orchestration, through granular orchestration, through live data orchestration. And nobody else does that, where you can have statements of objective, and have the system pre-position the data where you’re going to need it.”
Access has to be fast. “Your system has to be able to serve data, once it is positioned onto a specific locale. It has to be able to serve it in parallel, in the highest performance fashion.”
Flynn does not like the notion of an actual central data store. “If you look at other attempts to address globalising data and its access, invariably, all of them use the notion of a central silo — a big central object store. Then you stretch and put file access to where you use a central file or you stretch and you put caches on front of it. It almost makes [things] worse now, because you’re not only dependent on a centralised [store] but now each of your decentralised points become critical points of failure as well.”
Spinning up Hammerspace GDE
Flynn told us: “Hammerspace can be spun up at the click of a mouse through APIs. As matter of fact, we have one of the major cloud vendors — actually, they did the work to automate the spin-up of Hammerspace. And have been positioning Hammerspace as the way to do multi-region, even within their cloud.” He wouldn’t say which public cloud this was.
”This, the ability to simply turn on Hammerspace, and have it stretch your data from on-prem into the cloud, or from one region to the cloud to another, through an API and in a matter of mere minutes, is extremely powerful.
“So this ends up being super simple to spin up through … scripting, a presence of your data, and you don’t even have to wait for the data to get there. Because the system replicates metadata, and the data comes granularly. And based on policy, so you’re not waiting for whole datasets to come.”
Customers
We suggested Hammerspace was asking a lot of its customers to trust Hammerspace with their data crown jewels.
Flynn agreed. “Yes, we are asking our clients to trust us to be their data layer. So in the end, they are subjugating all of the storage infrastructure to Hammerspace. And using that to automate, arguably, one of the most manual processes in the IT world — the placement and movement of data across different storage infrastructure. It’s kind of a sin. There’s nothing more digital than data. And yet, something in the most desperate need of digital automation is the, how we manage the mapping of data to the infrastructure.
Customers have responded. “This is something where the company has made major strides in the past year [with] some very large organisations that have gone into production. And even in the seven figure deals, million dollar-plus range. And even at that, it’s still just a fraction of how far they want to grow. So we have three of the world’s largest telcos, some of the largest online game manufacturers, media and entertainment companies.”
How did Flynn know this was the right time to make a big push into the market?
“When we had one of these telcos I was talking about in production for nine months, continuous operation, zero downtime, running mission-critical applications, 24/7, 365 days a year, over 3,000 metadata ops per second. So you look [at that] as a as a startup guy, you’re looking for signs, and how do you know when you’re ready? It’s hard, right? Because if you go too soon, you can stub your toe. If you go too late you miss opportunity.
“As soon as I had not just that, but other proof points similar to it, we were there. … The first thing that we decided that we want to go after [is] the enterprise NAS world, and the need to move enterprise NAS workloads to the cloud.”
Partners and execs
So the software is ready, customers are interested and the timber is ripe for launch. What next? Hammerspace is ramping up its go-to-market operation, having recently hired:
Jim Choumas VP channel sales;
Chris Bowen as SVP global sales;
Molly Presley as SVP marketing.
There’s a mass of related activity. Sales teams have been hired for the southern California media and entertainment market, high tech companies in northern California, and life sciences in the Boston area.
It’s set up a new partner program, Partnerspace, which integrates with the channel for 100 per cent of its customer engagements.
DataCore sells Hammerspace software as its vFilo product. We expect many more channel partners will be recruited.













 in Chichén Itzá")