


Komprise has introduced Deep Analytics Actions (KDAA), a product which provides a systematic way to find specific data across hybrid cloud storage silos and can move a subset of data to data pipelines.
KDAA is a managed hybrid cloud service. It builds a global file index, stored in the public cloud, by indexing data in-place across file, object and cloud data storage and can thereby look into the index to search petabytes of unstructured data distributed across multiple silos and locations. It enables Komprise to compete with suppliers such as OneSync and Rubrik, with its acquired Igneous technology.
Matt Madill, senior storage administrator at Komprise customer Duquesne University, said: “Different research groups have unique requirements which users can support with tagging so that those data sets can not only be discovered easily but they can apply the appropriate data management policies to them for long-term storage. We’ll be able to give users the power to have better control of their data and let us know what to archive and when.”
The action part of this is KDAA can create a virtual data set based on a query and systematically and continuously move data from multiple file and object silos to a target location.
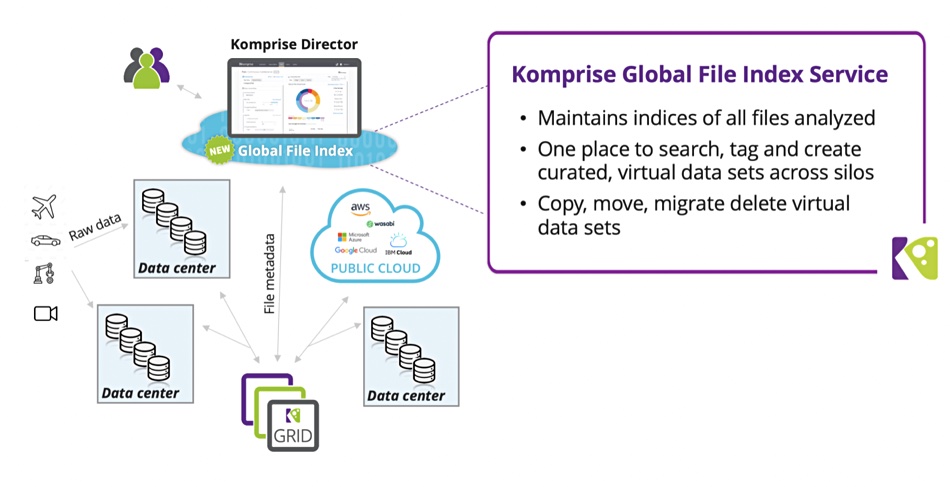
For example, researchers at a pharmaceutical company can query and extract the files related to a specific experiment generated by a set of researchers, when these files might be a small part of petabytes of research and other scattered across datacentres and clouds. They can then import this virtual data set into a data lake or data warehouse for further analysis.
Komprise says they can move smaller subsets of data than otherwise into data lakes and warehouses for analysis, which speeds data lake/warehouse load time and hopefully speeds the analytics runs as well — since there is less data to analyse.
Kumar Goswami, co-founder and CEO of Komprise, said: “With Komprise Deep Analytics Actions, departmental users can maximise the business value of their unstructured data by leveraging their domain knowledge to cull and find the right data sets to operate on across all their silos.
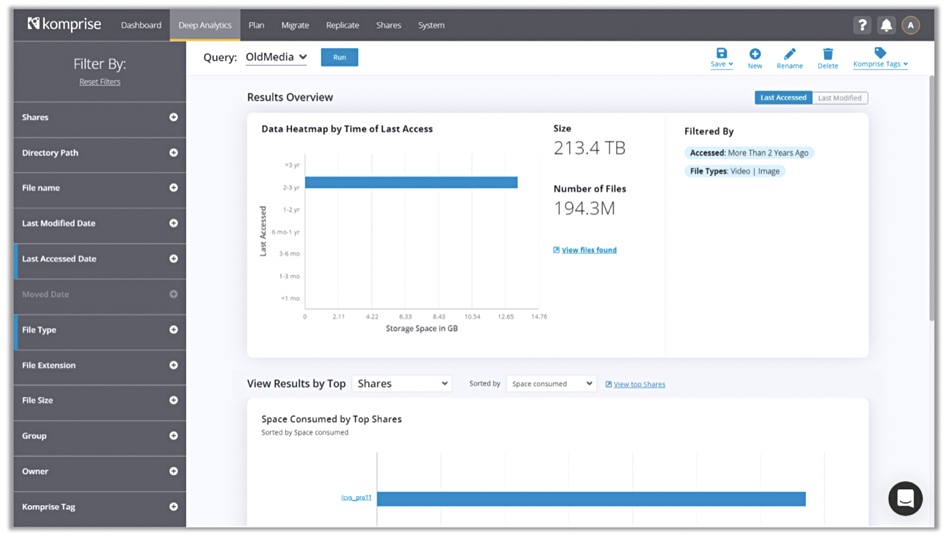
The global indexing is at file and object metadata level, not content level. That means users can create queries on file attributes and tags such as: data related to a specific tag or project name, inactive projects, file age, user/group ID’s, path, file type (aka JPEG) and specific extensions, and data with unknown owners.
Tags are what data owners and users can add as custom metadata. Unlike automatic metadata generated by a file or object system this is not necessarily systematic and certainly not automatic. It can be, as KDAA can be set up to add tags based on an unstructured data item’s characteristics.
Users could maximise the business value of unstructured data even more if they could search inside it — run a content-level search.
Check out Komprise’s KDAA web pages to learn more.
Comment
Automated content indexing requires the content indexing system to look inside a file or object and recognise words that are relevant and not articles or pronouns or other relatively content-free items. A book indexer basically looks for nouns (array) and names (Komprise) and actions (eg versioning). An automated content indexer would have to be able to recognise such words in a file or object and then list them as content metadata items for that file or object.
Such content-level indexing runs would need a huge amount of storage I/O and many processing cycles.
A content-level metadata list could be huge. A 350-page book could easily have a 550-item content index. With a million text files a content index could hold hundreds of millions of entries. An automated indexer in effect builds up a massive quasi-dictionary or key:value store in which words (keys) are listed but not explained. Instead they have references to their use in a file or object (values).
If that existed then a content-level search could be run in the same way as KDAA searches file and object metadata today.





