Computational storage startup Eideticom has been assigned two patents: 10,996,892 for “Apparatus and Method for Controlling Data Acceleration” and 11,231,868 for “System and Method for Performing Computational Storage Utilizing a Hardware Accelerator.”
Lee Caswell.
…
Lee Caswell (Mr. HCI at VMware) has joined Nutanix as SVP for Product Marketing. He resigned from VMware as its VP for Marketing in December 2021 to begin a “new adventure.” He reports to ex-VMware guy Rajiv Ramaswami, Nutanix’ CEO, who left VMware in December 2020.
…
The latest Toshibare-organisation plan envisages a two-way split. Japan Semiconductor and Toshiba Electronic Devices and Storage would be spun-off into one entity. A second Toshiba entity would own Toshiba’s 40.6 per cent stake in NAND flash and SSD maker Kioxia, which is destined for an IPO. If the plan gains board approval it will go to a June 23 AGM for shareholder approval.
…
UK-based replicator WANdisco has adopted a four-day working week with the weekend now consisting of Friday, Saturday and Sunday. According to the Financial Times story, CEO and co-founder David Richards said that staff productivity had become higher during the COVID-19 pandemic, as a result of them working from home. Staff can choose an alternative weekday off and their salaries will not be affected by the move.
…
Tier-2 public cloud object storage provider Wasabi announced a partnership with Vultr, a cloud infrastructure vendor, to deliver an infrastructure-as-a-service (SaaS) offering claimed to be easier to use and cheaper than hyperscale cloud providers’ services. Customers can use Vultr compute with Wasabi storage to run web apps, big data analytics, media processing and other data-intensive workloads with highly predictable and simplified pricing, meaning no hidden fees. Customers can transfer data at no cost between their Wasabi storage and Vultr virtual machines and bare metal servers.
…
Should Western Digital acquire Kioxia? Objective Analysis consultant Jim Handy sees downsides in his latest blog. WD, if it acquired Kioxia, would then have to bear the cost of excess NAND chip production from the Kioxia-WD joint venture-owned foundries, and this affects its profitability.
…
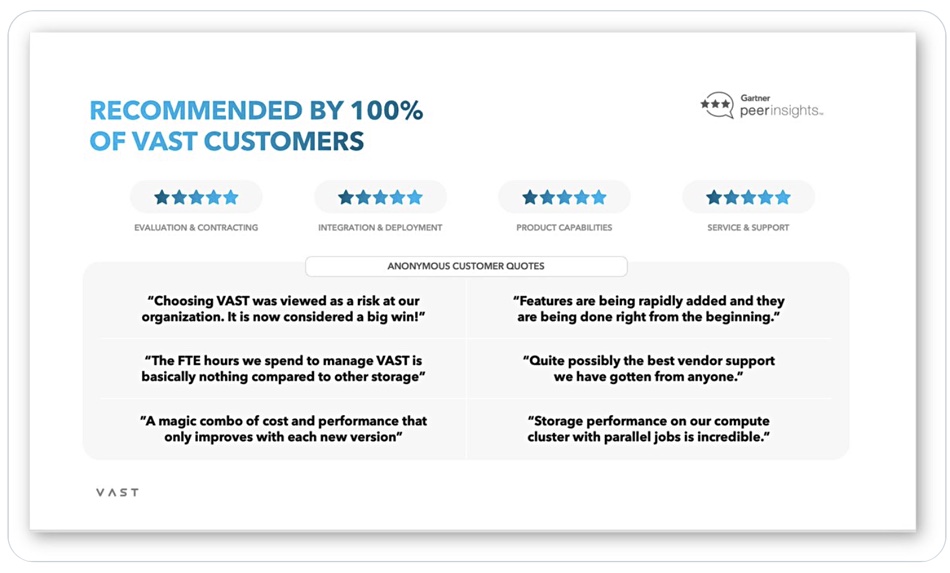
100 per cent of VAST Data‘s customers have a positive perception of VAST. This is shown by a Gartner Peer Insights report and is said to be the first time this has happened to a file and object storage supplier in such a report.
On January 4, WEKA announced Cisco was among contributors to its $73 million funding round. Now Cisco’s name is off the list – for the latest round, at least.
The original release read: “WEKA, the data platform for AI, today announced that Hitachi Ventures led its recent round raising $73 million in funding, which brings the total amount raised to $140 million. Other investors participating in this round were strategic investors, including Hewlett Packard Enterprise, Nvidia, Micron, and Cisco, and financial investors including MoreTech Ventures, Ibex Investors, and Key 1 Capital.”
Spot the difference with a corrected version issued on February 5: “WEKA, the data platform for AI, today announced that Hitachi Ventures led its recent round raising $73 million in funding, which brings the total amount raised to $140 million. Other investors participating in this round were strategic investors, including Hewlett Packard Enterprise, Nvidia, Micron, and Digital Alpha, and financial investors including MoreTech Ventures, Ibex Investors, and Key 1 Capital.”
Enter Digital Alpha as a strategic investor, which now contributes a quote: “As Digital Infrastructure investors, we see Enterprise AI as a highly attractive segment,” says Rick Shrotri, managing partner at Digital Alpha, “and we are delighted to be investors in WEKA’s market-leading AI data platform.”
It describes itself on its website as a premier alternative asset manager focused on digital infrastructure and lists Cisco as a key partner.
Digital Alpha website strategy graphic.
Rick Shrotri is the founder and managing partner at Digital Alpha, and says on LinkedIn that he is the “leader of a private investment fund targeting digital infrastructure worldwide, with proprietary access to deal flow and a knowledge base backed by Cisco Systems, Inc. and other corporate partners.”
He founded Digital Alpha in Feb 2017. Before that he spent almost ten years at Cisco, finishing up as managing director and global head of business acceleration. In that role he was said to have “created and led a global initiative to bring third party equity capital to invest in attractive opportunities from Cisco’s most coveted customers.”
In a WeLink press release Digital Alpha Advisors describes itself as an investment firm focused on digital infrastructure and services required by the digital economy, with a strategic collaboration agreement with Cisco Systems. As part of this agreement, Digital Alpha has preferred access to Cisco’s “pipeline of commercial opportunities requiring equity financing.” This is not mentioned on the revised WEKA release.
In April last year, Digital Alpha announced the closing of Digital Alpha Fund II, over its initial hard cap with over $1 billion in commitments. The fund was oversubscribed.
Digital Alpha is, effectively, a Cisco investment business. That’s why it is classed as a strategic investor, not just as another contributing VC.
Fractal Index Tree – a data structure used for indexing in databases, which combines elements of traditional tree-based indexing methods like B-trees with concepts from fractal geometry to enhance performance, especially in large-scale, multidimensional databases. Here’s how it generally works:
Key Characteristics:
Fractal Nature:
The term “fractal” here refers to the self-similar structure of the tree. Each node in the tree can be seen as a smaller version of the entire tree, allowing for local decisions that mimic global behaviors. This self-similarity helps in scaling the structure efficiently across different levels of data granularity.
Adaptive Indexing:
Unlike traditional static trees where the structure is fixed once data is inserted, fractal index trees adapt dynamically. They can reorganize themselves based on data distribution, query patterns, and updates, leading to better performance over time.
Search Efficiency:
The tree structure is designed to reduce the average path length to find data, which is particularly useful in handling large datasets or high-dimensional data where traditional methods might perform poorly. The structure might involve:
Variable node sizes: Nodes can have different capacities based on the data they hold or the level in the tree they are at.
Multiple paths: Unlike a strict B-tree where each node has one parent, fractal trees might allow for multiple paths or connections between levels for quicker access.
Cache Efficiency:
Fractal trees are designed with modern hardware in mind, particularly cache hierarchies. They are structured to minimize cache misses by keeping frequently accessed data closer to the root or in more cache-friendly patterns.
Concurrency and Transactions:
These trees often include mechanisms to handle concurrent accesses better than traditional trees. They might use techniques like copy-on-write for updates, which allows for more efficient locking strategies or even lock-free operations in some scenarios.
Practical Applications:
Databases: Particularly in scenarios where data is frequently updated, or where queries span multiple dimensions or very large datasets. Systems like TokuDB (now part of Percona Server for MySQL) have implemented fractal tree indexing.
Big Data: For managing indexes in big data platforms where scalability, speed, and the ability to handle vast amounts of data are crucial.
Geospatial Indexing: Where the spatial nature of data can be better managed through fractal-like structures, enhancing query performance across spatial dimensions.
Limitations:
Complexity: The adaptive nature and complex structure mean that implementing and maintaining fractal index trees can be more challenging than simpler tree structures.
Overhead: There can be additional overhead in terms of memory usage and processing for managing the tree’s dynamic nature.
In essence, a fractal index tree employs principles of fractals to create a more adaptive, efficient, and scalable indexing mechanism for database queries, particularly in environments where data size, dimensionality, and update frequency challenge traditional indexing approaches.
vLLM – virtual Large Language Model (LLM). The vLLM technology was developed at UC Berkeley as “an open source library for fast LLM inference and serving” and is now an open source project. According to Red Hat, it “is an inference server that speeds up the output of generative AI applications by making better use of the GPU memory.”
Red Hat says: “Essentially, vLLM works as a set of instructions that encourage the KV (KeyValue) cache to create shortcuts by continuously ‘batching’ user responses.” The KV cache is a “short-term memory of an LLM [which] shrinks and grows during throughput.”
REST – An appliacyion programming interface (API) the REST API (Representational State Transfer Application Programming Interface) is a web service that follows REST principles to enable communication between clients and servers over the internet. REST APIs allow applications to request and exchange data using standard HTTP methods.
REST API features
Stateless – Each request from a client to the server must contain all necessary information, and the server does not store client state.
Resource-Based – Resources (e.g., users, products, orders) are identified by URLs (Uniform Resource Locators).
Standard HTTP Methods:
GET – Retrieve data from the server.
POST – Create new resources.
PUT – Update existing resources.
DELETE – Remove resources.
REST APIs typically exchange data in JSON (JavaScript Object Notation) or XML (Extensible Markup Language), with JSON being the most common. They also have a uniform interface and follow consistent patterns in API design, making it easy for developers to use.
Intel made a greater than half-billion dollar loss on its Optane 3D XPoint business in 2020.
Update.Intel’s Optane head leaves and $500 million revenue number claim added; 9 Feb 2022.
Some gory financial details are laid bare in Intel’s annual 10K SEC filing for 2021, which states in the Non-Volatile Solutions Group section (page 33): “Revenue decreased $1.1 billion, driven by $712 million lower ASPs due to market softness and pricing pressure and $392 million due to the transfer of the Intel Optane memory business to DCG.”
It also says “Operating income also benefited from the transfer of the Intel Optane memory business from 2021 NSG results (a loss of $576 million in 2020).”
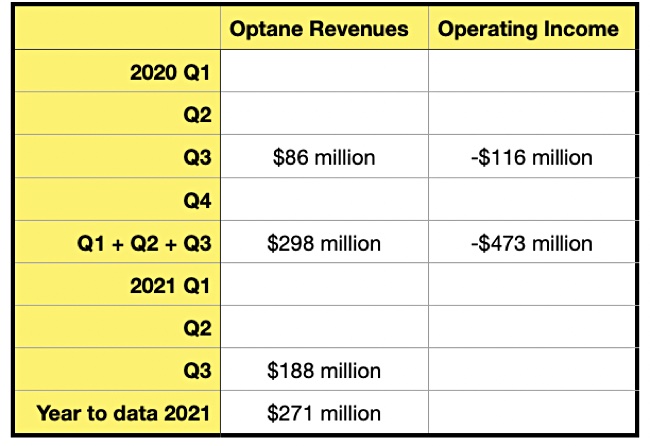
Q3 2021 Optane numbers
We were able to show this chart in November last year, based on Intel’s 10-Q SEC filing for the third 2021 quarter, and showing some Optane revenues and operating income numbers to Q3 in Intel’s fiscal 2021:
The revenues for Q3 2021 – $188 million – are considerably higher (54.3%) than the Q3 2020 revenues of $86 million.
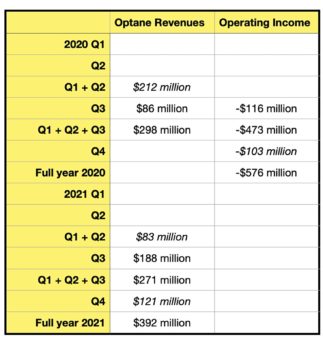
With the the recent Q4 2021 10K statement we can add Q4 revenue and full year 2020 operating income numbers, and back-calculate others (in italics in the table):
It’s still a partial picture but we can see that Intel made a $576 million operating loss on Optane products in its 2020 year. The nine-month number for 2021, $271 million, was 9.1 per cent lower than the nine-month number for 2020, $298 million, and the Q4 2021 revenue number of $121 million was sequentially down on Q3’s $188 million.
Did Intel’s Optane business make an operating loss in 2021? We don’t know, but suspect it did because the 2020 operating losses were 134.9 (Q3) to 158.7 (Q1+Q3+Q3) per cent higher than revenues. Applying the lower ratio to the $392 million full 2021 year Optane revenues we would expect a $529 million operating loss in 2021.
A final thought: if Intel gains CPU performance superiority over AMD it won’t need to use Optane as a loss-leading way for Xeon servers to get a performance advantage over AMD servers. Then it could get rid of a substantial chunk of operating losses by exiting the XPoint business.
Update
CRN revealed that Alper Ilkbahar, VP and GM for Intel’s Data Centre Memory and Storage Solutions, who runs its Optane business, is resigning for personal reasons. David Tuhy takes over as Optane Group GM. A memo from Sandra Rivera, EVP and GM of Intel’s Data Centre and AI group, seen by CRN said; “Optane revenues have grown to $500 million in fewer than 3 years.”
This $500 million does not accord with intel’s 10-Q filing figure of $392 million. Intel wouldn’t comment on the Rivera memo’s $500 million number.
ACID – an acronym referring to Atomicity, Consistency, Isolation and Durabilityas applied to database transactions. ACID transactions guarantee that each read, write, or modification of a database table has the following properties:
Atomicity – each read, write, update or delete statement in a transaction is treated as a single unit and either the entire statement is executed, or none of it is. This prevents data loss and corruption from occurring if a transaction fails midway,
Consistency – transactions only make changes to tables in predefined, predictable ways so that data corruption or errors don’t create unintended consequences for the integrity of your table.
Isolation – when multiple users are reading and writing from the same table all at once, isolation of their transactions ensures that the concurrent transactions don’t interfere with or affect one another. Each request can occur as though they were occurring one by one, even though they’re actually occurring simultaneously.
Durability – ensures that changes to your data made by successfully executed transactions will be saved, even in the event of system failure.
In summary, an ACID-compliant database transaction is any operation that is treated as a single unit of work, which either completes fully or does not complete at all, and leaves the storage system in a consistent state. ACID properties ensure that a set of database operations (grouped together in a transaction) leave the database in a valid state even in the event of unexpected errors. A common example of a single transaction is the withdrawal of money from an ATM. Find out more here.
Analysis: As mainstream storage suppliers have adopted and acquired HCI, NVMeoF, and object storage technologies and others, a set of startups have found themselves in a well-funded and long-life state in which they appear to have no short-term need of an IPO or acquisition – contravening conventional financial mores.
They appear in no danger of failing and are examples of companies defying typical startup wisdom that you need to IPO or get acquired within six years or so after receiving the first venture capital investment.
According to Statista, in 2020, VC-backed companies went public approximately 5.3 years after securing their first VC investment.
Let’s look at three possible outcomes for a startup:
IPO or positive acquisition – for example Snowflake IPO and Cleversafe acquisition.
In-between state – for example Panasas and many others.
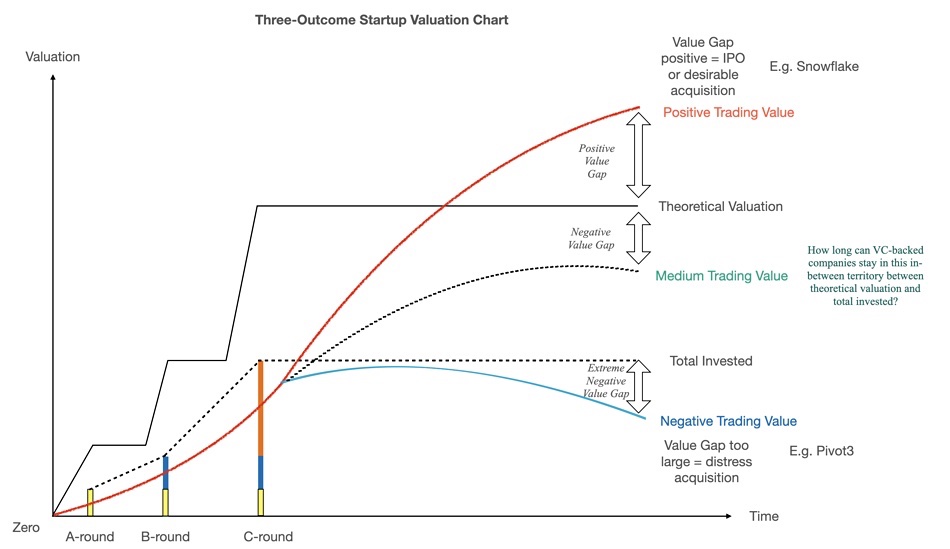
Blocks & Files chart
Above, we have devised a startup progress chart with these three possible outcomes plotted.
Chart explainer
The chart puts startups’ progress in a time versus valuation 2D space. The coloured bars are venture capital (VC) funding rounds and we show, as an example, A-, B- and C-rounds with the height of the bar representing total funding so far. The dashed line represents the total VC funds invested in the startup.
The solid line above this represents the company’s VC-calculated valuation at reach round. The red curve represents a theoretical startup’s progress as its trading value – what an acquirer would pay grows over time, surpasses the total invested amount and then rises further, past the theoretical valuation, putting the company in IPO territory as it approachers and passes that valuation. It has a positive trading value gap in our chart’s terminology.
At this point the VCs would get a good return on their investment if the company had an IPO or was acquired.
The blue line shows an under-performing startup whose trading value never rises above or drops below the total amount invested. There is an extreme negative value gap between the two and the VCs exit the company because it crashes – Coho Data and Tintri for example – or gets acquired as a distress purchase before bankruptcy, with Pivot3 as our cited example.
The middle, dotted, medium trading value line represents companies which don’t attain a trading value above their theoretical valuation but neither does their trading value drop below the total invested, giving the VCs hope that they will be able to achieve a good exit, eventually. We say these inbetweener companies have a negative value gap.
VC theoretical valuations
Niraj Tolia
How are VC valuations worked out? Kasten co-founder Niraj Tolia said “There is the theory that valuations should be based on discounted cash flows in the future but usually the reality is a lot more imprecise.”
Sometimes sane valuations for later stage companies will be based on “forward multiples” of, say, a multiple of the next 12 months projected revenue. Harder to do for an earlier stage company and that will then look at TAM and other market comps, founder histories, potential for exit and more.
“And, finally, there are some valuations that are simply hard to justify from the outside looking in. Might be a hot deal that got competitive and all metrics got thrown out of the window (like last year in a LOT of deals). Sometimes it’s what a founder can command based on a large vision.
“Basically, more art than science.”
Inbetweeners
Such companies can’t raise any additional funding and they either motor along in good medium trading value shape with adequate profitability, limp along with low profitability unless and until their VC backers want to exit with a closure or firesale or just cash burn themselves out of money. Perhaps a good example of this negative trading value state is Pivot3, a hyper-converged startup. It was started up in 2003 and took in a lot of money – $247 million across 12 funding events. Seventeen years after being founded it was bought by Quantum for $8.9 million, meaning a loss of $238 million for its backers.
What happened? The mainstream vendors built or acquired their HCI products and Pivot3 was not acquired. It then found that its effective addressable market shrank because the big beasts – Cisco (Springpath), Dell EMC (VxRAIL, vSAN), HPE (Nimble dHCI, Simplivity), NetApp (Elements HCI) and Nutanix – were roaming around and mopping up customers. Pivot3’s growth tailed off, faltered and stopped.
The COVID pandemic didn’t help and Pivot3’s board decided to get out of the HCI business.
Inbetweener status can be attained by any startup, whatever its funding amount. The tension between the aims of the VC backers (and most probably part-owners) meaning a good exit, and what the company’s executive leadership can deliver in terms of trading value is greatest in the well-funded in-betweeners. There is simply more VC money at risk.
Identifying inbetweeners
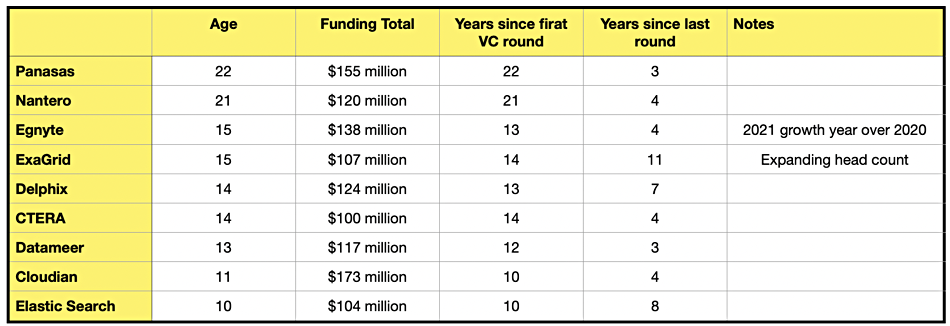
How might we identify long-life, well-funded inbetweener storage companies? Try this: we’ll look for VC-backed, $100 million-plus funded, post-startup suppliers, meaning more than five years since being funded, who have not significantly pivoted in the last few years. Here’s a starting list of $100 million-plus funded, “inbetweener” suppliers:
Databricks – $3.6 billion
Fivetran – $730 million
Cohesity – $600 million (IPO filed)
Rubrik – $552 million plus
OwnBackup – $507 million
Druva – $475 million
Dremio – $410 million
Qumulo – $351 million
Redis Labs – $347 million
Infinidat – $325 million
Silk – $313 million
Pensando – $313 million
Fungible – $311 million
Wasabi – $284 million
Firebolt – $269 million
SingleStore – $264 million
VAST Data – $263 million
Yellowbrick Data – $248 million
Clumio – $186 million
Cloudian – $173 million
Scality – $172 million
Nasuni – $167 million
Spin Memory – $166 million
Virtana – $165 million
Panasas – $155 Million
Liqid – $150 million
WEKA – $140 million
Egnyte – $138 million
MinIO – $126 million
Delphix – $124 million
Kyligence – $118 million
Datameer – $117 million
Pliops – $115 million
Pavilion Data Systems – $107 million
ExaGrid – $107 million
Scale Computing – $104 million
Elastic Search – $104 million
GoodData – $101 million
CTERA – $100 million
Now we’ll separate out those that are seven years old or older, classifying them as startups still:
Databricks – $3.6 billion and in 9th year
Fivetran – $730 million and in 10th year
Cohesity – $600 million and in 9th year (IPO filed)
Rubrik – $552 million+ and in 8th year
OwnBackup – $507 million and in 10th year
Druva – $475 million and in 14th year
Qumulo – $351 million and in 10th year
Redis Labs – $347 million and in 11th year
Infinidat – $325 million and in 12th year
Silk – $313 million and in 14th year (including Kaminario period)
SingleStore – $264 million and in 11th year
Yellowbrick Data – $248 million and in eighth year
Cloudian – $173 million and in 11th year
Scality – $172 million and in 13th year
Nasuni – $167 million and in 14th year
Spin Memory – $166 million and in 15th year
Virtana – $165 million and in 14th year (including Virtual Instruments period)
Panasas – $155 million and in 22nd year
WEKA – $140 million and in 9th year
Egnyte – $138 million and in 15th year
MinIO – $126 million and in 8th year
Delphix – $124 million and in 14th year
Nantero – $120 million and in 10th year
Datameer – $117 million and in 13th year
Pavilion Data Systems – $107 million and in 8th year
ExaGrid – $107 million and in 15th year
Scale Computing – $104 million and in 15th year
Elastic Search – $104 million and in 10th year
GoodData – $101 million and in 15th year
CTERA – $100 million and in 14th year
This gives 30 inbetweeener companies. Let’s find out the longest-lived and best-funded ones by putting them in age order, add in the time since the last funding event, and strike out companies less than ten years old, or with two years or less since their last round.
Extreme inbetweeners
We now have nine extreme “inbetweener” companies who are ten years or more old, have $100 million or more in funding, it is ten years or more since their first VC round, and their last funding round was three or more years ago. If asked, all would say they are growing and in good shape. None of them are closing offices or laying off staff. They exhibit no signs of financial stress as far as we can see. Indeed some are visibly and publicly growing, such as Egnyte and ExaGrid.
The current storage market supports – indeed seems to welcome – these players, as they continue to develop and grow their businesses. Long may it continue and let’s hope that their VC backers find some way to crystallise their investments without the company getting into dire straits. There needs to be, we might say, some way for the holdings of the relatively short-termist VC investors to be turned into the holdings of more, benevolent and long-term investors.
Perhaps a long-term view private equity acquisition, meaning not a slash-and-burn reorganising one, is one possible good outcome.
Wikipedia public domain image: https://commons.wikimedia.org/wiki/File:C_Merculiano_-_Cephalopoda_1.jpg
Big Blue’s big Red Hat open source business unit is adding Ceph-based persistent storage services to its OpenShift containerised app software services.
OpenShift Data Foundation offers cloud-native persistent storage, data management and data protection. It is based on Ceph, Noobaa and Rook software components. Ceph provides object, block and file storage. Noobaa, acquired by Red Hat in 2018, is an abstraction layer over a storage infrastructure and provides data storage service management across hybrid multi-cloud environments. Rook, which can be used to set up a Ceph cluster, orchestrates multiple storage services, each with a Kubernetes operator.
Joe Fernandes, Red Hat’s cloud platforms VP and GM, provided the standard announcement quote: “Red Hat OpenShift Platform Plus provides the innovation of Kubernetes tailored for enterprise needs, along with a broad set of additional capabilities like management, enhanced security features and now storage out of the box, answering common production requirements that basic Kubernetes services cannot address.”
Red Hat OpenShift is now a more complete Kubernetes app development, deployment and secure software stack. This comes from adding the OpenShift Data Foundation product to a Red Hat OpenShift Platform Plus bundle, now made up of:
OpenShift;
Advanced Cluster Management for Kubernetes;
Advanced Cluster Security for Kubernetes;
Quay (Central registry);
OpenShift Data Foundation (previously called Container Services).
The latest version of OpenShift Data Foundation, 4.9, includes multi-cloud object gateway namespace buckets. These enable data to reside in a single location while also being made available on alternative locations where applications need access, without having to copy data over to the alternative location.
It also has persistent volume encryption in which users can bring their own key, and manage and hold encryption keys separate from their cluster.
Red Hat OpenShift Platform Plus is available now and the Data Foundation offering is added it in two ways. Red Hat customers who have an active Red Hat OpenShift Platform Plus subscription receive OpenShift Data Foundation Essentials as part of their existing subscription at no extra cost.
A Red Hat OpenShift Platform Plus with Red Hat OpenShift Data Foundation Advanced bundle, adds security features, multi-cluster workload support, disaster recovery, and standalone and mixed use storage support to the Essentials offering.
Cloud file sync-and-sharer Panzura has upped its game three ways: cloud outage failover, shared NFS and SMB access, and Hyper-V support.
This so-called Data Flex release means Panzura’s CloudFS customers need no longer suffer an outage when their cloud goes down, can have SMB and NFS users access the same files at the same time, and Hyper-V hypervisor users as well as VMware vSphere users get access to Panzura’s facilities.
The announcement quote came from Panzura’s chief innovation officer, Edward M.L. Peters: “Our customers operate in an environment that can span virtualizations and cloud providers. It only makes sense that they want a simplified way to access, share and collaborate on files no matter what multi-hypervisor or multi-cloud configuration they use.”
Cloud outage failover is provided through a cloud mirroring feature and it enables, Panzura says, enterprise-grade high availability, built-in multi-cloud orchestration, and automation. CloudFS simultaneously places the same set of data in two separate object stores in real time, providing multi-cloud redundancy. If there is a primary cloud outage or security issue with one cloud provider CloudFS can immediately failover data, applications and workloads to a secondary cloud provider, an organisation’s private cloud, or both.
Users can seamlessly continue work with no loss of data while the primary object store remains offline. Cloud FS re-syncs the impacted storage volumes when they come back online. Panzura customers get more uptime and can also remain in compliance with strict SLAs for regulatory and contractual uptime mandates.
Peters said “When you lose access to crucial data, financial losses mount with every minute that passes – and the reputational damage can be crippling. With the new failover capabilities of Panzura CloudFS, you will continue working as if an outage never happened.”
The mixed NFS-SMB mode allows users with file shares and storage via both NFS and SMB connections to access, share and update the same data, eliminating redundant workflows and data silos.
Panzura’s Hyper-V support enables IT departments to consolidate data and native applications for Microsoft SQL Server, Microsoft Exchange and Microsoft SharePoint that require low latency and high-performance access, backup and storage, onto Cloud FS. This, together with shared NFS-SMB access and cloud high availability, ups Panzura’s enterprise credentials considerably.
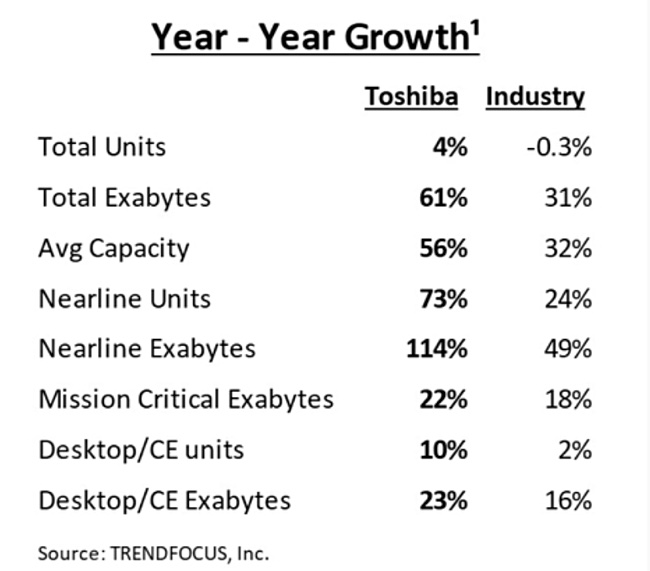
Toshiba was the only one of the big three disk drive manufacturers to increase its unit shipments in 2021, with exabytes shipped rising faster than the market average as well.
Disk unit shipments have been declining for several years as faster SSDs take over from slower, albeit cheaper, disk drives in notebook and desktop computers as well as performance-critical storage arrays. However, within the overall market, the 3.5-inch 7,200rpm (nearline) disk segment has been growing both unit numbers and exabytes shipped – so much so that overall disk capacity shipments have continued to rise while disk unit shipments decline.
US research house TrendFocus tracks the HDD market and its VP John Chen said “Toshiba’s leading year-over-year growth percentages in so many categories are the result of the company’s execution under challenging market conditions. … As some of the ongoing pandemic-related constraints begin to ease, Toshiba has positive momentum to post more milestones in 2022.”
Kyle Yamamoto, VP of Toshiba America Electronic Components’ (TAEC) HDD Business Unit, said “Our new technologies such as FC-MAMR (Flux-Controlled Microwave-Assisted Magnetic Recording) and MAS-MAMR (Microwave Assisted Switching Microwave-Assisted Magnetic Recording) are excellent examples of the effort that will propel the next generation of products forward.”
Toshiba shipped 54.68 million units equaling 187.24 exabytes for the year. It ships product into four products into four market sectors:
AL series – mission-critical enterprise performance segment;
MG series – nearline enterprise capacity and datacentre drives;
MQ series – mobile client HDDs;
DT series – surveillance and traditional desktop drives (3.5-inch).
TrendForce’s latest report shows that Toshiba grew unit and capacity shipments more than the market average in overall totals, nearline drives (MG series), mission-critical (2.5-inch and 10,000rpm) drives (AL series) and the desktop/consumer electronics (DT series) sectors.
That means competitors Seagate and Western Digital collectively lost share in these market sectors. We envisage that Toshiba was able to better manage its supply chain than the other two suppliers, who both alluded to supply chain issues in their results statements – here’s Western Digital and here’s Seagate.
Toshiba’s 2021 nearline exabytes shipped growth of 114 per cent more than in 2020 looks extraordinary against the industry average of, impressive as it is, 49 per cent.
In the final 2021 quarter Toshiba had a near-20 per cent unit ship share, Western Digital near-37 per cent and Seagate near-43-percent. Toshiba will have to keep growing its share for some time if it wants to get past Western Digital.
All-flash array vendor Pure Storage is partnering with IBM infrastructure services spin-off Kyndryl in a global alliance.
Kyndryl says it will become a key delivery partner for Pure and deliver jointly-optimised software and hardware to its enterprise customers, of which it has more than 4,000 – including 75 per cent of the Fortune 500. The company will increase its existing Pure skills and capabilities.
Stephen Leonard.
Stephen Leonard, Kyndryl’s global alliances & partnerships leader, provided a good formulaic announcement quote: “Our alliance with Pure Storage can help customers identify and take advantage of new ways to manage, secure, and analyse their mission-critical multi-cloud business data.”
Wendy Stusrud, VP, global partner sales at Pure Storage, matched it: “We’ve fostered a true collaboration with Kyndryl that will address our shared customers’ business challenges and drive the transformation and modernisation they are undertaking.”
Pure and Kyndryl say they will deliver systems related to application and infrastructure modernisation, automation, multi-cloud management, containerisation, and more. They will provide cyber resiliency elements natively at the storage layer to enable cloud-based applications coupled with data portability in the cloud or on-premises.
It’s good news for Pure, with Kyndryl recognising its enterprise credentials as a storage supplier.
Pure is joining august company. Kyndryl also partners with AWS, Cisco, Google Cloud, IBM, Lenovo, NetApp, Red Hat, SAP and VMware. And, in November 2021, Microsoft became Kyndryl’s only Premier Global Alliance Partner increasing Microsoft’s access to the $500 billion managed services market which Kyndryl leads and enhancing prospects for Azure’s use.
That means Dell Technologies and HPE are not in Kyndryl’s partner list. Yet.