


Ceph, the open source integrated file, block and object storage software, can support one billion objects. But can it scale to 10 billion objects and deliver good and predictable performance?
Yes, according to Russ Fellows and Mohammad Rabin of the Evaluator Group who set up a Ceph cluster lab and, by using a huge metadata cache, scaled from zero to 10 billion 64KB objects.
In their soon-to-be published white paper commissioned by Red Hat, “Massively Scalable Cloud Storage for Cloud Native Applications”, they report that setting up Ceph was complex – without actually using that word. “We found that, because of the many Ceph configuration and deployment options, it is important to consult with an experienced Ceph architect prior to deployment.”
The authors suggest smaller organisations with smaller needs can use Ceph reference architectures. Larger organisations with larger needs better “work with Red Hat or other companies with extensive experience in architecting and administering Ceph.”
The scalability issue
Analysis of unstructured data, files and objects is required to discern patterns and gain actionable insights in a business’s operations and sales.
These patterns can be discovered through analytics and by developing and applying machine learning learning models. Very simply, the more data points in an analysis run, the better the resulting analysis or machine learning model.
It is a truism that object data scales more easily than file storage because it has a single flat address space whereas files exist in a file-folder structure. As the number of files and folders grow, the file access metadata also grows in size and complexity – and more so than object access metadata.
File storage is generally used for applications that need faster data access than object storage. Red Hat wants to demonstrate both the scalability of object storage in Ceph and its speed. The company has shown Ceph can scale to a billion objects and perform well at that level via metadata caching on NVMe SSDs.
However, Red Hat wants to go further and has commissioned the Evaluator Group to scale Ceph tenfold, to 10 billion objects, and see how it performed.
The benchmark setup
The Evaluator test set-up had six workload generating clients driving six object servers. Each pair of these accessed, in a split/shared-nothing configuration, a Seagate JBOD containing 106 x 16TB Exos nearline disk drives; 5PB of raw capacity in total spread across three storage JBODS.
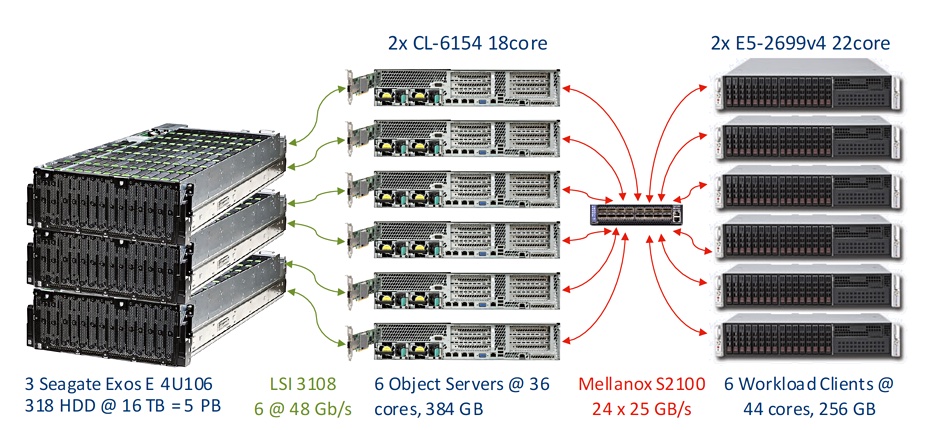
Each object server had dual Xeon 18-core CL-6154 processors, 384GB of DRAM, six Intel DC P4610 NVMe 7.6TB write-optimised NAND SSDs for metadata caching, and 384GB of DRAM.
Ceph best practice recommends not exceeding 80 per cent capacity and so the system was sized to provide 4.5PB of usable Ceph capacity. Each 64KB object required about 10KB of metadata, meaning around 95TB of metadata for the total of 10 billion objects.
Test cycles
The Evaluator Group testers ran multiple test cycles, each performing PUTS to add to the object count, then GETS and, thirdly, a mixed workload test. The performance of each successive workload was measured to show the trends as object counts and capacity both increased.
The measurements of GETs (reads) and PUTs (writes) performance showed a fairly linear pattern as the object count increased. PUT operations showed linear performance up to 8.8 billion objects; 80 per cent of the system’s usable Ceph capacity, and then dropped off slightly. GET operations showed a dip to a lower level around 5 million objects and a more pronounced decline after the 8.8 million objects level.
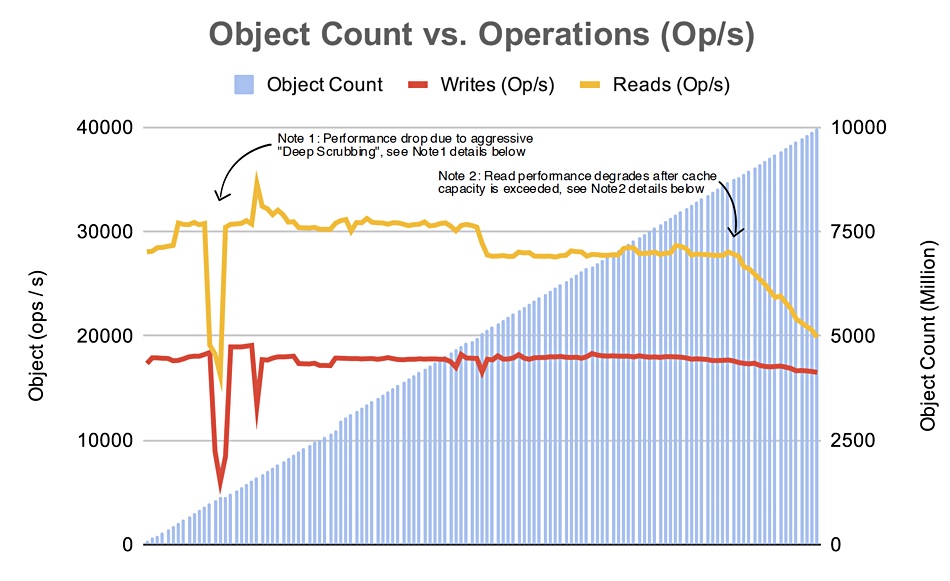
GET performance declined once the metadata cache capacity was exceeded (yellow line on chart) and the cluster’s usable capacity surpassed 80 pr cent of actual capacity. Once the cache’s capacity was surpassed the excess metadata had to be stored on disk drives, and accesses were consequently much slower.
Performance linearity at this level would requite a larger metadata cache.
The “deep scrubbing” dip on the chart occurred because a Ceph parameter set for deep scrubbing, to help with data consistency, came into operation at 500 million objects. Ceph was reconfigured to stop this.
The system exhibited nearly 2GB/s of sustained read throughput and more than 1GB/sec of sustained write throughput.
Larger objects
The Evaluator Group also tested how Ceph performed with up to 20 million 128MB objects. In this test the metadata cache capacity was not exceeded and performance was linear for reads and near-linear for writes as the object count increased;
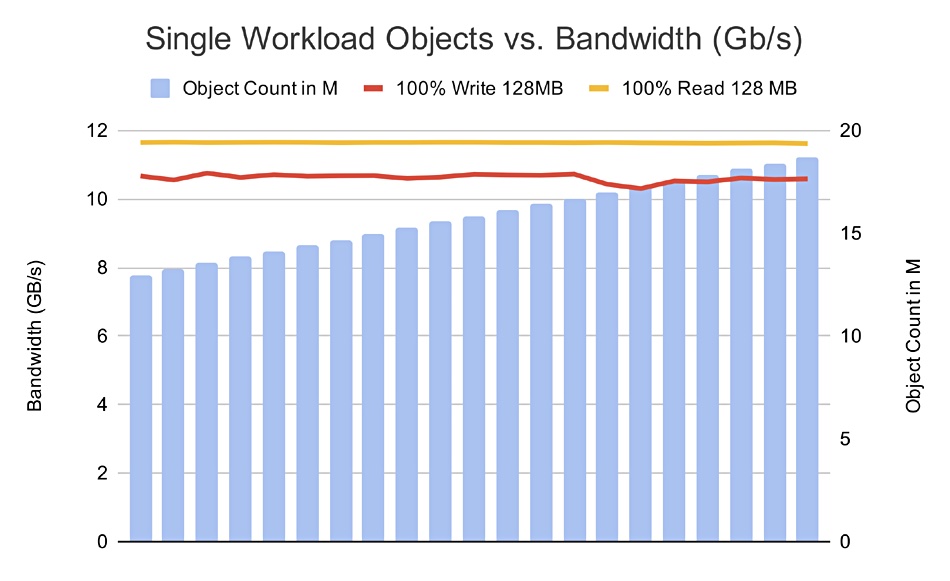
There is less metadata with the smaller number of objects, meaning no spill over of metadata to disk. The GET and PUT performance lines are both linearish – ‘deterministic’ is the Evaluator Group’s term, with performance of 10GB/sec for both operation types.
Comment
Suppliers like Iguazio talk about operating at the trillion-plus file level. That’s extreme but today’s extremity is tomorrow’s normality in this time of massive data growth That suggests Red Hat will have keep going further to establish and then re-establish Ceph’s scalability credentials.
Next year we might see a 100 billion object test and, who knows, a trillion object test could follow some day.





