A Panmnesia scheme to bulk up a GPU’s memory by adding fast CXL-accessed external memory to a unified virtual memory space has won a CES Innovation award.
Panmnesia says large-scale GenAI training jobs can be memory-bound as GPUs, limited to GBs of high-bandwidth memory (HBM), could need TBs instead. The general fix for this problem has been to add more GPUs, which gets you more memory but at the cost of redundant GPUs. Panmnesia has used its CXL (Computer eXpress Link) technology, which adds external memory to a host processor across the PCIe bus mediated by Panmnesia’s CXL 3.1 controller chip, which exhibits controller round-trip times less than 100 ns, more than 3x less than the 250 ns needed by SMT (Simultaneous Multi-Threading) and TPP (Transparent Page Placement) approaches.
A Panmnesia spokesperson stated: “Our GPU Memory Expansion Kit … has drawn significant attention from companies in the AI datacenter sector, thanks to its ability to efficiently reduce AI infrastructure costs.”
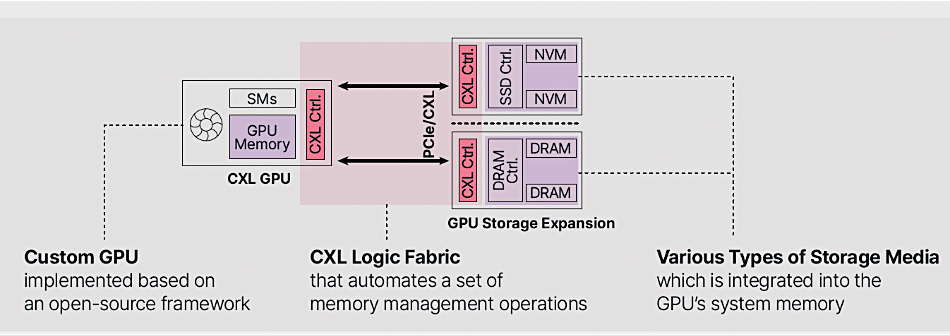
The technology was revealed last summer and shown at the OCP Global Summit in October. The company has a downloadable CXL-GPU technology brief, which says its CXL Controller has a two-digit-nanosecond latency, understood to be around 80 ns. A high-level diagram in the document shows the setup with either DRAM or NVMe SSD endpoints (EPs) hooked up to the GPU:
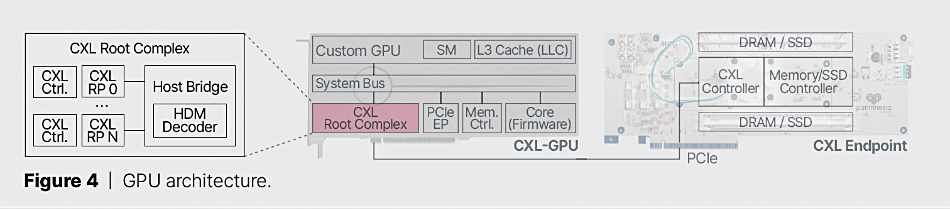
In more detail, a second Panmnesia diagram shows the GPU is linked to a CXL Root Complex or host bridge device across the PCIe bus which unifies the GPU’s high-bandwidth memory (host-managed device memory) with CXL endpoint device memory in a unified virtual memory space (UVM).
This host bridge device “connects to a system bus port on one side and several CXL root ports on the other. One of the key components of this setup is an HDM decoder, responsible for managing the address ranges of system memory, referred to as host physical address (HPA), for each root port. These root ports are designed to be flexible and capable of supporting either DRAM or SSD EPs via PCIe connections.” The GPU addresses all the memory in this unified and cacheable space with load-store instructions.
A YouTube video presents Panmnesia’s CXL-access GPU memory scheme in simplified form here.
Cohesity has added incident response partners to its Cyber Event Response Team (CERT) service to help customers diagnose and set up a recovery response to a malware attack faster.
It set up its CERT service in 2021, stating that it had partnered with the world’s leading cybersecurity incident response (IR) firms. Now it has announced a formal list of IR partners: Palo Alto Networks (Unit 42), Arctic Wolf, Sophos, Fenix24, and Semperis. CERT, available to all Cohesity customers as part of their existing subscription, can share customer-approved operational data – including logs, reports, and inventories – with these IR partners. It has developed a methodology that utilizes native platform capabilities and integrations with its Data Security Alliance to provide greater insight into data breaches.
Sanjay Poonen
Sanjay Poonen, Cohesity CEO, stated: “With ransomware, data breaches, and other cyber threats becoming an unavoidable reality, organizations need the assurance that they can bounce back faster, stronger, and smarter … We’re doubling our commitment to our customers by ensuring they have the expertise and tools to navigate and recover from cyber crises effectively. Cyber resilience is the cornerstone of modern cybersecurity, and we are committed to helping our customers achieve it.”
An example of such an incident affected the divisional manufacturing plant and R&D center of a global auto parts enterprise. The company used Cohesity backup and its FortKnox immutable isolated data copy vault. The company was hit by ransomware in late 2023, which encrypted all the VM images hosted on ESXi servers.
The manufacturer contacted CERT the morning after the attack and CERT worked in partnership with Fenix24 to contain and investigate the threat. The threat actor was identified and the IR team found that more than 100,000 files were locked up. Cohesity CERT worked with the division’s IT department and Fenix24 to bring data back from the FortKnox service, validate that the threat had been mitigated, and ensure that remediation steps were successful.
CERT is available 24×7. “Personnel from Cohesity CERT and its partners are seasoned cybersecurity experts with specialized knowledge in incident response, threat intelligence, and forensics,” we’re told.
Kerri Shafer-Page
Kerri Shafer-Page, Artic Wolf’s VP of Incident Response, said: ”Cohesity’s quick response toolkit gives us access to all kinds of data that can enable a more comprehensive investigation and quicker recovery. Partnering with Cohesity CERT adds valuable expertise in backup and recovery and helps us ensure our joint customers are resilient no matter what attackers throw at them.”
Trellix: Threat detection and response with Intelligent Virtual Execution (IVX) sandbox to analyze and inspect malware in an isolated environment.
Rubrik has a Ransomware Response Team (RRT), a virtual team of experienced people in its global support organization. RRT is available 24x7x365 and composed of critical incident managers and senior support staff. Rubrik’s executive leadership is part of this virtual team and has visibility of every recovery RRT is involved with.
Veeam Software has integrating its data protection reporting with cybersecurity software vendor Palo Alto Networks to enable customers to respond quicker to attacks.
HighPoint Technologies, which provides PCIe NVMe storage and switching solutions, now supports Arm-based computing platforms, increasingly present in datacenters and at the edge.
HighPoint was already an established storage and connectivity provider for Intel-based systems used in high-performance environments. HighPoint’s high-density NVMe technologies support up to 32 devices per PCIe slot, addressing the growing demand for massive storage capacity.
“Integrated hardware sensors, real-time status and health monitoring, and a comprehensive storage management suite now streamline deployment and service workflows for Arm platforms,” said the provider.
The NVMe offerings can be custom-tailored with firmware, driver, and storage management tools for unique applications and easier integration with Arm platforms.
“Our expansion into Arm-based computing platforms reflects HighPoint’s commitment to driving innovation and addressing the evolving needs of datacenter and edge computing environments,” said May Hwang, VP of marketing at HighPoint Technologies. “By leveraging unparalleled NVMe storage performance, scalability, and energy efficiency with our versatile and customizable solutions, we are empowering customers to seamlessly integrate high-performance storage into their IoT servers and AI-driven applications, paving the way for next-generation computing solutions.”
HighPoint’s NVMe product lines span multiple PCIe generations, from Gen 3 to Gen 5 x16, delivering the performance and scalability increasingly required across industrial IoT server environments at the edge.
Last year, HighPoint rolled out a new line of external NVMe RAID enclosures, designed to elevate Gen 4 storage applications to “new heights.” The RocketStor 654x series promised x16 transfer performance and “nearly half a petabyte” of storage capacity, which could be integrated into any x86 platform with a free PCIe x16 slot.
As far as other storage firms integrating with Arm in the datacenter, open source object storage supplier MinIO recently tweaked its code so AI, ML, and other data-intensive apps running on Arm chipsets can achieve higher performance.
The new Cloud Data Sets feature in BMC Software’s AMI Cloud Data platform “transforms” mainframe data management by providing direct access to cloud object storage, without requiring modifications to existing JCLs or applications.
The provider claims this enhancement “empowers” ITOps teams to fully replace traditional tape storage with cloud-based solutions, “simplifying” operations and “minimizing” disruption. BMC bought Model9 in April 2023, and has rebranded its software as the AMI Cloud.
BMC maintains that within the next five years, secondary tape storage and traditional tape software will be “phased out” at most organizations. The future of mainframe data storage lies in cloud-based object storage, it says, with cloud storage “up to 12 times more affordable” than traditional virtual tape library (VTL) solutions, while eliminating the need for costly tape hardware.
South African bank Nedbank is buying into this evolution, and with the help of BMC, the company has transformed its data management. A backup that used to run for 48 hours has been reduced to 36 minutes after switching to a cloud-based solution. The switch has also allowed Nedbank to streamline its disaster recovery and backup processes, reducing complexity while enhancing security and data availability.
“This evolution allows IT operations teams to redirect their tape backups to the cloud without any operational changes, removing a major barrier to cloud adoption in mainframe environments,” says BMC. With Cloud Data Sets, AMI Cloud Data supports all major backup utilities, including EXCP. “We have seen a huge increase in the performance of our backups. One example is that the backup that used to run for an entire weekend for 48 hours, was reduced to 36 minutes when we went to a cloud-based solution,” said Ashwin Naidu, IT manager for enterprise storage and backup at Nedbank.
BMC AMI Cloud diagram
In addition to significantly shorter backup and restore times, the new version of AMI Cloud Data has been optimized for lower CPU consumption.
To deliver on such offerings, BMC says it is combining its software expertise with the data infrastructure of partners, including Hitachi, Mainline, Dell, and AWS.
Object storage supplier Cloudian is partnering unstructured data orchestrator Hammerspace by making its HyperStore object storage a repository used by Hammerspace’s Global Data Platform’s parallel NFS-based file system.
The Global Data Platform (GDP) software provides a global namespace, in which unstructured file and object data is placed, orchestrated, made available for use, and accessed as if it were local. Hammerspace uses its GDE software to manage file and object data in globally distributed locations, across SSDs, disk drives, public cloud services, and tape media. Cloudian’s HyperStore is an object storage system with effectively limitless scalability and supports Nvidia’s GPUDirect for object storage. The Hammerspace software also supports GPUDirect.
Molly Presley
Molly Presley, Hammerspace SVP of Marketing, stated: “Our partnership with Cloudian redefines how enterprises manage and leverage unstructured data. Together, we’re enabling organizations to unify their data ecosystems, eliminate silos, and unlock the full potential of their data for AI, analytics, and other transformative initiatives.”
Cloudian CMO Jon Toor paralleled this comment by saying: “Cloudian is excited to collaborate with Hammerspace to deliver an integrated solution that combines performance, scalability, and simplicity. This partnership gives enterprises the tools they need to conquer the challenges of data growth and drive their digital transformation strategies forward.”
Cloudian Hammerspace diagram
Cloudian claims its storage costs can be as low as 0.5 cents per GB per month, and provides scale-out storage for multiple use cases, such as an AI data lake, with 100x the performance of tape, and costs lower than public cloud.
There are three main features with this deal:
Jon Toor
Seamless data orchestration across tiers and locations as Hammerspace’s data platform automates data movement between Tier 0, Tier 1, and object storage within a unified global namespace, spanning sites, hybrid clouds, and multi-cloud environments.
Exabyte-scale and S3-compatible object storage with data protection and ransomware defense.
Hammerspace supports standard NFS, SMB, and S3 protocols without proprietary software or networking requirements, enabling seamless integration with Cloudian storage, and both support GPUDirect and its remote direct memory access to storage drives.
Toor told us: “The solution integrates Hammerspace as a storage virtualization layer with Cloudian HyperStore (and other storage devices) as the underlying storage infrastructure, delivering a unified, efficient, and scalable data management ecosystem.
“We see this as an ideal complementary solution. In many of our deployments, Cloudian is implemented alongside other, dissimilar products. With Hammerspace abstracting and virtualizing data across these disparate storage systems – including object storage, NAS, and cloud – the joint solution empowers organizations with high-performance data orchestration, enabling users to access and manage data transparently across on-premises, edge, and cloud environments.
“The power, dependability, and simplicity of this combined solution is proven in multiple Cloudian/Hammerspace deployments today.”
All-in-all, this partnership means, the two suppliers say, that customers can unify their data across edge, core, and cloud environments in a single global namespace. Through the partnership they can extend active production namespaces to provide global unified file access across them all without impacting existing high performance tiers. They get simplified management of and accessibility to unstructured data while supporting performance-intensive applications such as AI training, HPC workloads, and analytics.
The combined Cloudian-Hammerspace offering is available immediately through Hammerspace and Cloudian’s global partner networks.
Cloudian provides more AI data workflow information here. A solution brief, “End-to-End Media Workflows with Hammerspace & Cloudian,” can be accessed here.
Private equity firm Blackstone is investing $300 million in privately held DDN, valuing the company at $5 billion and aiming to help develop its AI-related storage business.
Alex Bouzari
According to DDN CEO Alex Bouzari, as referenced in a Wall Street Journal report, DDN will use the cash “to sharply expand the AI data company’s business-customer base.”
Bouzari stated: “Blackstone’s support accelerates our mission to redefine the enterprise AI infrastructure category and scale at an even faster rate. By fueling our mission to push the boundaries of data intelligence, we can empower organizations worldwide with next-level AI solutions that drive ground-breaking innovation and deliver 10x returns on their investments.”
California-headquartered DDN (DataDirect Networks) was founded in 1998 by CEO Alex Bouzari and president Paul Bloch to provide fast IO unstructured data storage arrays to high-performance computing customers, such as NASA and Nvidia. They brought two existing businesses, MegaDrive and Impact Data, together to form DDN. As enterprises operating in big data analytics, seismic processing, financial services, and life sciences adopted HPC-style IT, DDN developed its file and object product technology to support them.
It raised $9.9 million in A-round funding in 2001, but the relationship with investors soured and there was a confrontational exit from the deal in 2002, with Bouzari saying: “The VCs basically exited the company in April 2002. Somehow we managed to make payroll in April. We lost roughly $3 million in the first half of 2002 and we made roughly $3 million in the second half of 2002. In 2003, we were profitable and did roughly $25 million in revenue. By 2005, we earned $45 million in revenue and broke $100 million in revenue by 2007. Last year, we hit $188 million in revenue. Right now we are above a $200 million run rate.”
Annual revenues passed $100 million in 2008 and $200 million in 2011. DDN acquired Intel’s Lustre file system engineering team in 2018. That same year it expanded its general enterprise storage supply capabilities by acquiring the bankrupt Tintri business for $60 million in September 2018, Nexenta for an undisclosed sum in May 2019, and Western Digital’s IntelliFlash hybrid SSD/HDD storage product division in September 2019.
In 2020, DDN said annual revenues were $400 million, and it had more than 11,000 customers. Revenues reached $500 million in 2023, and were estimated to be $750 million at the end of 2024, with DDN saying it’s “highly profitable,” and: “With this groundbreaking deal, DDN is poised for historic growth in 2025 following a record-breaking 400 percent growth in AI revenue in 2024.”
The core DDN business currently produces a line of ExaScaler Lustre parallel file system storage arrays and has developed them into AI400X2 appliances for AI processing storage, supporting Nvidia’s GPUDirect storage protocol. It has a strategic partnership with Nvidia.
Paul Bloch
DDN made significant progress in the generative AI market in 2023 and 2024, relying on its strong relationship with Nvidia and securing deals such as providing storage for Elon Musk’s Colossus AI supercomputer.
DDN President Paul Bloch said: “This investment enables us to execute our strategy to bring HPC-grade AI solutions to enterprises, transforming industries and delivering measurable outcomes. Our teams are laser-focused on solving real business challenges, from accelerating LLM deployments to enhancing inferencing, so our customers can unlock their data’s potential and achieve tangible ROI faster than ever before.”
We asked DDN a few questions about this investment:
B&F: Why is the money needed? Couldn’t DDN fund necessary business development itself?
DDN: While we’ve successfully self-funded for over two decades, this investment allows us to apply what we’ve learned from working with leading AI hyperscalers and labs to meet the growing needs of Fortune 500 enterprises.
B&F: Does Blackstone get a seat on DDN’s board?
DDN: Yes, Blackstone will take a seat on our board, contributing their experience in helping companies scale effectively.
B&F: Will the cash be used for engineering, go-to-market expansion, or both or something else? Acquisitions?
DDN: The funds will support applying our proven AI expertise to enterprise customers through enhanced engineering and go-to-market efforts. We wouldn’t rule out acquisitions that align with our growth strategy.
B&F: Will it help DDN better compete with VAST Data and Pure Storage?
DDN: This investment broadens our scale and scope, enabling us to compete more effectively across the industry—not just with companies seen as our traditional competition but on a much broader scale.
B&F thinks that DDN, together with VAST Data, is one of the pre-eminent storage suppliers for AI training and large-scale inferencing work. DDN is promising a significant AI-related announcement on February 20 and we think it likely that 2025 could potentially be a billion dollar revenue year for the firm.
Blackstone is a prominent private equity investor with over $290 billion in assets under management as of 2023. Its other recent AI-related investments include GPU farm CoreWeave, datacenter operators QTS Realty Trust and AirTrunk, and cybersecurity supplier VectraAI. A Blackstone statemewnt said: “DDN’s track record for delivering cutting-edge AI and HPC platforms to thousands of customers globally is just scratching the surface of the transformative impact they’ll have on the enterprise AI market. We see DDN as the clear leader in scaling enterprise-grade solutions that drive meaningful business returns for modern AI deployments.”
As promised in December, Synology has announced its ActiveProtect backup and recovery appliance products, with integrated backup, recovery, and management software, and server and storage hardware.
Taiwan-based Synology supplies NAS filers, such as the DiskStation, RackStation and FlashStation, FS arrays, SANs, routers, video surveillance gear, and C2 public cloud services for backup, file storage, and personal (identity) security to primarily SMB buyers. It also has enterprise customers.
EVP Jia-Yu Liu stated: “ActiveProtect is the culmination of two decades of experience in hardware and software engineering, shaped by our ongoing collaboration with businesses worldwide and more than half of Fortune 500 companies. With ActiveProtect, we’re setting a new standard for what businesses can expect from their data protection solutions.”
ActiveProtect features global source-side deduplication, immutable backups, air-gap capabilities, and regulatory compliance support. Synology says it delivers “comprehensive data protection” and enables customers “to implement a reliable 3-2-1-1-0 backup strategy for PCs, Macs, virtual machines, databases, file servers, and Microsoft 365 accounts.”
The 3-2-1-1-0 concept means:
3 – keep at least 3 copies of data
2 – on at least 2 different types of media
1 – with one backup copy offsite
1 – and one immutable copy
0 – ensuring zero errors with regular testing
The ActiveProtect Manager (APM) centralized console supports up to 150,000 workloads or 2,500 sites, offering scalability and “enterprise-grade data visibility and control.”
There are five products in the range, all with AMD processors:
DP320 – tabletop – protect up to 20 machines or 50 SaaS users – 2 x 8TB HDD, 2 x 400GB SSD
DP340 – tabletop – protect up to 60 machines or 150 SaaS users – 4 x 8TB HDD, 2 x 400GB SSD
DP5200 – rackmount – 1RU
DP7300 – rackmount – 2RU
DP7400 – rackmount – up to 2,500 servers & 150,000 workloads – 2RU – 10 x 20TB HDD, 2 x 38.4TB SSD
ActiveProtect appliances. From top left: DP320, DP340, DP5200, DP7300, and DP7400
All models except the DP320 use SSD caching to store backup-related metadata. Synology provides datasheets for the DP320, DP340, and DP7400, but not the DP5200 or DP7300, although it provided images of them. We understand that the DP5200 and DP7300 are future appliance products.
ActiveProtect has a one-time purchase and “once installed, ActiveProtect allows users to back up as many workloads as your storage allows. Businesses can manage up to three backup servers license-free, with optional CMS licenses available for larger, multi-appliance deployments.”
The ActiveProtect offering is available globally through Synology’s distributor and partner network. Get more information, including datasheets for the DP320, DP340 and DP7400, here.
True Base DP7400 retail pricing is, we understand, €39,999 plus €1,800 for a three-year period for each additional clustered device beyond the first three. The DP320 costs €1,996 and the DP340 is priced at €4,991.
Get an ActiveProtect buyer guide here. Get a DP7400 review here.
Interview. AI training and inferencing needs access to datasets. The dataset contents will need to be turned into vector-embedded data for GenAI large language models (LLMs) to work on them, with their semantic search capabilities finding responses from vectorized data to requests that have been vectorized as well.
In one sense, providing vectorized datasets to LLMs requires extracting the relevant data from its raw sources: files, spreadsheets, presentations, mail, objects, analytic data warehouses, and so on, turning it into vectors and then loading it into a store for LLM use, which sounds like a traditional ETL (Extract, Transform and Load) process. But Krishna Subramanian, Komprise co-founder, president, and COO, claims this is not so. The Transform part is done by the AI process itself.
Komprise provides Intelligent Data Management software to analyze, move, and manage unstructured data, including the ability to define and manage data pipelines to feed AI applications, such as LLMs. When LLMs are used to search and generate responses from distributed unstructured datasets then the data needs to be moved into a single place that the LLM can access, passing through a data pipeline.
Filtering and selecting data from data set sources, and moving it, is intrinsic to what the Komprise software does and here Subramanian discusses AI data pipeline characteristics and features.
Blocks & Files: Why are data pipelines becoming more important today for IT and data science teams?
Krishna Subramanian
Krishna Subramanian: We define data pipelines as the process of curating data from multiple sources, preparing the data for proper ingestion, and then mobilizing the data to the destination.
Unstructured data is large, diverse, and unwieldy – yet crucial for enterprise AI. IT organizations need simpler, automated ways to deliver the right datasets to the right tools. Searching across large swaths of unstructured data is tricky because the data lacks a unifying schema. Building an unstructured data pipeline with a global file index is needed to facilitate search and curation.
On the same note, data pipelines are an efficient way to find sensitive data and move it into secure storage. Most organizations have PII (Personal Identifying Information), IP and other sensitive data inadvertently stored in places where it should not live. Data pipelines can also be configured to move data based on its profile, age, query, or tag into secondary storage. Because of the nature of unstructured data, which often lives across storage silos in the enterprise, it’s important to have a plan and a process for managing this data properly for storage efficiencies, AI, and cybersecurity data protection rules. Data pipelines are an emerging solution for these needs.
Blocks & Files: What kind of new tools do you need?
Krishna Subramanian: You’ll need various capabilities, aside from indexing, many of which are part of an unstructured data management solution. For example, metadata tagging and enrichment – which can be augmented using AI tools – allows data owners to add context and structure to unstructured data so that it can be easily discovered and segmented.
Workflow management technologies automate the process of finding, classifying and moving data to the right location for analysis along with monitoring capabilities to ensure data is not lost or compromised through the workflow. Data cleansing/normalization tools and of course data security and governance capabilities track data that might be used inappropriately or against corporate or regulatory rules.
There is quite a lot to consider when setting up data pipelines; IT leaders will need to work closely with research teams, data scientists, analysts, security teams and departmental heads to create the right workflows and manage risk.
Blocks & Files: How are data pipelines evolving with GenAI and other innovations?
Krishna Subramanian: Traditionally, data pipelines have been linear, which is why ETL was the norm. These tools were designed for structured and semi-structured data sources where you extract data from different sources, transform and clean up the data, and then load it into a target data schema, data warehouse or data lake.
But GenAI is not linear; it is iterative and circular because data can be processed by different AI processes, each of which can add more context to the data. Furthermore, AI relies on unstructured data which has limited metadata and is expensive to move and load.
Since data is being generated everywhere, data processing should also be distributed; this means data pipelines must no longer require moving all the data to a central data lake first before processing. Otherwise, your costs for moving and storing massive quantities of data will be a detriment to the AI initiative. Also, many AI solutions have their own ways of generating RAG and vectorization of unstructured data.
Unlike ETL, which focuses heavily on transformation, data pipelines for unstructured data need to focus on global indexing, search, curation, and mobilization since the transformation will be done locally per AI process.
Blocks & Files: What role do real-time analytics play in optimizing data pipelines?
Krishna Subramanian: Real-time analytics is a form of data preprocessing where you can make certain decisions on the data before moving it. Data preprocessing is central in developing data pipelines for AI because it can iteratively enrich metadata before you move or analyze it. This can ensure that you are using the precise datasets needed for a project – and nothing more. Many organizations do not have distinct budgets for AI, at least not on the IT infrastructure side of the house and must carve funds out from other areas such as cloud and data center. Therefore, IT leaders should be as surgical as possible with data preparation to avoid AI waste.
Blocks & Files: How can companies leverage data pipelines to improve collaboration between data science teams, IT, and business units?
Krishna Subramanian: Data pipelines can create data workflows between these different groups. For instance, researchers who generate data can tag the data – otherwise called metadata enrichment. This adds context for data classification and helps data scientists find the right datasets. IT manages the data workflow orchestration and safe data movement to the desired location or can integrate third-party AI tools to work on datasets without moving them at all. This is a three-way collaboration on the same data facilitated by smart data workflows leveraging data pipelines.
Blocks & Files: What trends do you foresee in data pipeline architecture and how can enterprises prepare for these evolving technologies and approaches?
Krishna Subramanian: We see that data pipelines will need to evolve to address the unique requirements of unstructured data and AI. This will entail advances in data indexing, data management, data pre-processing, data mobility and data workflow technologies to handle the scale and performance requirements of moving and processing large datasets. Data pipelines of unstructured data for AI will focus heavily on search, curate and mobilization with the transformation happening within the AI process itself.
Blocks & Files: Could Komprise add its own chatbot-style interface?
Krishna Subramanian: Our customers are IT people. They know how to build a query. They know how to use our UI. What they really want is connecting their corporate data to AI. Can we reduce the risk of it? Can we improve the workflow for it? That’s a higher priority than us adding chat, which is why we have prioritized our product work more around the data workflows for AI.
Blocks & Files: Rubrik is aiming to make the data stored in its backups available for generative AI training and or inference with its Annapurna project. Rubrik is not going to supply its own vectorization facilities or its own vector database, or indeed its own large language models. It’s going to be able to say to its customers, you can select what data you could feed to these large language models. Now that’s backup data. Komprise will be able to supply real-time data. Is that a point of significant difference?
Krishna Subramanian: Yes, that’s a point of significant difference … We were at a Gartner conference last month and … Gartner did a session on what do customers want from storage and data management around AI. And … a lot of people think AI needs high performance storage. You see all this news about GPU-enabled storage and storage costs going up and all of that. And that’s not actually true. Performance is important, but only for model training. And model training is 5 percent of the use cases.
In fact, they said 50 percent of enterprises will never train a model or even engineer a prompt. You know 95 percent of the use cases is using a model. It’s inferencing.
And a second myth is AI is creating lot of data, or, hey, you’re backing up data. Can you run AI on your backup data? Yes, maybe there is some value to that, but most customers really want to have all their corporate data across all their storage available to AI, and that’s why Gartner [is] saying data management is more important than storage for AI.
We build a global file index. And this is not in the future. We already do this. You point this at all your storage and … we’re actually creating a metadata base. We’re creating a database of all the metadata of all the files and objects that we look at. And this is not backup data. It’s all your data. It’s your actual data that’s being stored.
So whether you back it up or not, we will have an index for you. With our global file index you can search across all the data. You can say, I only want to find benefits documents because I’m writing a benefits chat bot. And anytime new benefits documents show up anywhere, find those and feed those to this chat bot agent and Komprise will automatically run that workflow.
And every time new documents show up in Spain or in California or wherever, it would automatically feed that to that AI and it would have an audit trail. It will show what was spent. It will show which department asked for this. It will keep all of that so that for your data governance for AI, you have a systematic way to enable that.
Blocks & Files: Would it be fair to say that the vast majority of your customers have more than one unstructured storage, data device supplier, and building on that, those suppliers cannot provide the enterprise-wide object and file estate management capability you can?
Krishna Subramanian: Yes, that is exactly correct. Sometimes people might say, “Well, no, I don’t really have many suppliers. I might only use NetApp for my file storage.” But how much do you want to bet they’re also using AWS or Azure? So you do have two suppliers then. If you’re using hybrid cloud, by definition, you have more than one supplier, yes. I agree with your statement. And that’s what our customers are doing. That’s why this global file index is very powerful, because it’s basically adding structure to unstructured data across all storage.
And to your point, storage vendors are trying to say, look, my storage, file system can index data that’s sitting on my storage.
Blocks & Files: So you provide the ability to build an index of all the primary unstructured data there is in a data estate and regulate access to it, to detect sensitive information within it, because you build metadata tables to enable you to do that. So you could then feed data to a large language model, which would satisfy compliance and regulation needs concerning access. It would be accurate, it would be comprehensive, and you can feed it quickly to the model?
Krishna Subramanian: That’s correct. And we actually have a feature in our product called smart data workflows, where you can just build these workflows.
This is a contrived example; you know you can write a chatbot in Azure using Azure OpenAI. The basic example they have is a chat bot that has read a company’s health documents, and somebody can then go and ask it a question; What’s the difference in our company between two different health plans? And then it’ll answer that based on the data it was given, right?
So now let’s say California added some additional benefits. In the California division of this company Komprise finds those documents, feeds them into that OpenAI chatbot, and then, when the user asked the same question, it gives you a very specific answer, because the data was already fed in, right?
But really what’s more important is what’s happening behind the scenes. Azure Open AI has something called a knowledge base. It was trained with certain data, but you can actually put additional data, corporate data, in a Blob container, which it indexes regularly, to augment the process. So the RAG augmentation is happening through that container.
Komprise has indexed all the storage in our global file index. So you just build a workflow saying, find anything with benefits, that’s a Komprise is automatically doing that regularly, and that’s how this workflow is running. And the beauty of this is you don’t have to run this every time anybody could be creating a new benefits document, and it will be available to your chat bot.
Part of the problem is generative AI can become out of date because it was trained a while back. So this addresses relevancy. It addresses recency, and it also addresses data governance. Because you can tell Komprise if a source has sensitive data, don’t send it. So it can actually find sensitive data. That’s a feature we’re adding. We’ll be announcing soon.
You can tell Komprise to look for social security numbers, or you can even tell it to look for a particular keyword, a particular regular expression, because maybe in your organization, certain things are sensitive because of a certain way you label things. Komprise will find that inside the contents, not just a file name, and it will exclude that data if you if that’s what you want. So it can find personally identifiable information, the common stuff, social security numbers and so forth. But it can also find corporately sensitive information, which PII doesn’t cover.
Blocks & Files: If I’m a customer that doesn’t have Komprise, that doesn’t have any file lifecycle management capability at all, then probably my backups are my single largest cross-vendor data store. So it would make sense to use them for our AI. But as soon as that customer wheels you in, the backup store is behind the times, it’s late, and you can provide more up-to-date information.
Krishna Subramanian: Yes, that’s what we feel. And, by the way, we point to any file system. So if a backup vendor exposes their backup data in a file system, we can point to that too. It doesn’t matter to us. If a backup vendor stores its data on an object storage system? Yes, it works, because we are reading the objects. So if I happen to be a customer with object-based appliances storing all my VM backup data, we say, fine, no problem, we’ll index them – because we’re reading the objects. We don’t need to be in their proprietary file system. That’s the beauty of working through standards.
Blocks & Files: I had thought that object storage backup data and object storage were kind of invisible to you.
Krishna Subramanian: Well, it’s not invisible as long as they allow the data to be read as objects. It would be visible if they didn’t actually put the whole file as an object, if they chunked it up, and if it was proprietary to their file system, then it would be invisible, because the fact that they use object store doesn’t matter. They’re not exposing data as objects. So if they expose data as objects or files, we can access it.
As with NetApp, even though NetApp chunks the data, it exposes it via file and object protocols, and we read it as a file or an object. We don’t care how ONTAP stores it internally.
Blocks & Files: How is Komprise’s business growth doing?
Krishna Subramanian: Extremely well. New business is growing, I think, over 40 percent again this year. And the overall business is also growing rapidly. Our net dollar retention continues to be north of, I think, 110 percent. Some 30 to 40 percent of our new business comes from expansions, from existing customers.
Pure Storage has expanded its strategic collaboration with Micron to include Micron G9 QLC NAND for future DirectFlash Module (DFM) products.
Pure’s flash storage arrays use DFMs as solid-state storage devices, with up to four DFMs mounted on a blade carrier. Its latest 150 TB DFM has Micron G8 232-layer QLC NAND qualified for production. Pure also uses Kioxia flash chips in its DFMs.
Generation 9 (G9) Micron flash is claimed to be the world’s fastest TLC (3 bits/cell) NAND by Micron. It fits in an 11.5 mm x 13.5 mm package, with Micron claiming this makes it the smallest high-density NAND available. Pure is using it in QLC (4 bits/cell) format and says the Micron collaboration “enables the high-capacity and energy-efficient solutions that hyperscalers require … for future DirectFlash Module products.” It won a hyperscaler customer deal for its DFM technology in December, with its NAND technology replacing disk drive storage.
Bill Cerreta
Bill Cerreta, GM for Hyperscale at Pure, stated: “Pure Storage’s collaboration with Micron is another example of our significant momentum bringing the benefits of all-flash storage technology to hyperscale environments. With Micron’s advanced NAND technology, Pure Storage can further optimize storage scalability, performance, and energy efficiency for an industry with unparalleled requirements.”
Pure believes its partnership with Micron provides improved performance and lower latency with lower energy consumption and highly scalable systems at a reduced total cost of acquisition and ownership.
The next-generation DFM technology from Pure will provide 300 TB capacity. Micron’s G9 NAND has 19 percent more capacity per chip than 232-layer G8 NAND. A 300 TB DFM built with these chips will need a larger number of chips than a 150 TB DFM built with Micron G8 NAND.
Commercial-off-the-shelf SSDs have reached 122.88 TB in capacity with Phison’s Pascari D205V drive and 122 TB with Solidigm’s D5-P5336 product.
IBM, like Pure, makes its own NAND drives, called FlashCore Modules, and it has a 115 TB maximum effective capacity version – after onboard compression – using 176-layer TLC NAND, available in its fourth-generation FCM range. That’s two generations behind Micron’s G9 flash and we envisage IBM moving to the latest-generation NAND and QLC and at least doubling its maximum capacity later this year.
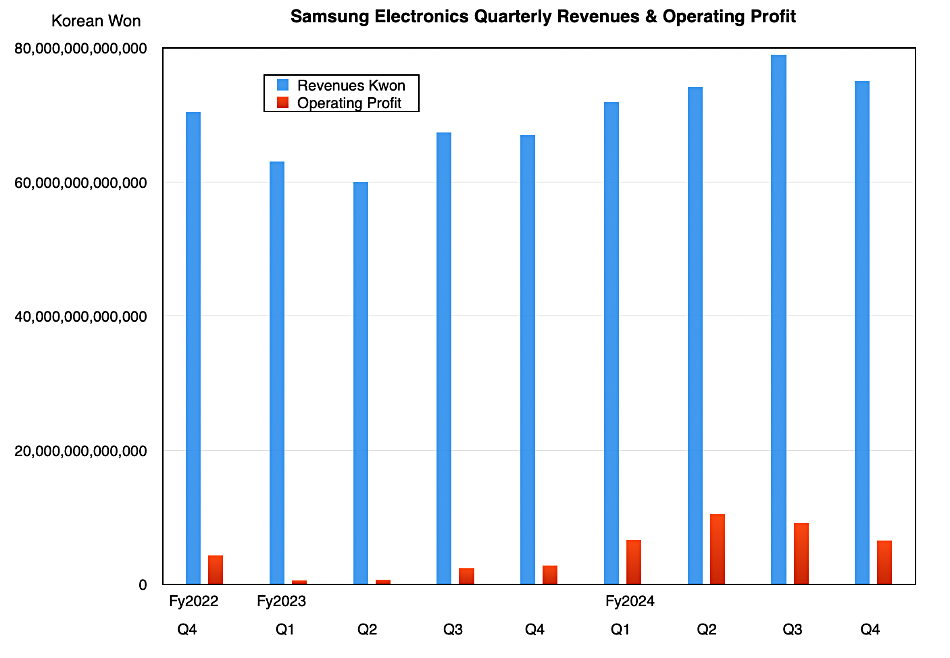
The latest quarterly results from Samsung fell short of expectations as the company tries to claw its way into the profitable high-bandwidth memory (HBM) market where SK hynix has a commanding lead, followed by Micron.
HBM stacks layers of DRAM on top of an interposer to create memory products that are connected to GPUs, providing faster bandwidth and higher capacity than the socket-connected memory used by x86 processors. HBM memory costs more than ordinary DRAM and SK hynix and Micron revenues are soaring as demand for high-bandwidth GPU memory goes up in lockstep with AI application use. In November, SK hynix added four more layers to its 12-Hi HBM3e memory chips to increase capacity from 36 to 48 GB and is set to sample this 16-Hi product this year. The faster HBM4 standard should arrive this year as well, with a stack bandwidth of around 1.5 TBps compared to HBM3e’s 1.2-plus TBps.
Samsung filed preliminary figures for the quarter ended December 31, with ₩75 trillion ($51.4 billion) in revenues, up 10.7 percent annually but below analyst estimates, and ₩6.5 trillion ($4.5 billion) operating profit, lower than the forecast ₩8.96 trillion ($6.1 billion) and 30 percent less than the prior quarter.
Management said: “Our operating profit for 4Q24 is projected to come in significantly below market expectations. This explanatory note is provided to assist in the understanding of the key factors behind the results and alleviate uncertainties prior to the release of our full results in the 4Q24 earnings call.”
“Despite sluggish demand for conventional PC and mobile-focused products, revenue in the Memory business reached a new all-time high for the fourth quarter, driven by strong sales of high-density products. However, Memory operating profit declined, weighed on by increased R&D expenses aimed at securing future technology leadership and the initial ramp-up costs tied to expanding production capacity for advanced technologies.”
TrendForce analyst Eden Chung told AFP he believes that Samsung Foundry faces multiple challenges, including “order losses from key customers in advanced processes, the gradual end-of-life of certain products, and a slow recovery in mature process segments.”
Manufacturing HBM chips is more profitable than traditional DRAM. Once GPU market leader Nvidia qualifies a manufacturer’s HBM product, sales take off. Samsung has fallen behind SK hynix and Micron in getting its latest HBM chips qualified by Nvidia. The company replaced its semiconductor unit’s leadership in November as it responded to slow memory chip sales, the second such exec reshuffle that year. A month earlier, the company had acknowledged it was in crisis and there were concerns about its technology’s competitiveness.
Mobile phone memory demand is relatively weak and domestic DRAM suppliers in China are taking a larger proportion of memory sales there.
According to Reuters, Nvidia CEO Jensen Huang told reporters at CES that Samsung is working on a new HBM chip design and he was confident that Samsung could succeed in this project.
COMMISSIONED: Retrieval-augmented generation (RAG) has become the gold standard for helping businesses refine their large language model (LLM) results with corporate data.
Whereas LLMs are typically trained with public information, RAG enables businesses to augment their LLMs with context or domain specific knowledge from corporate documents about products, processes or policies.
RAG’s demonstrated ability to augment results for corporate generative AI services improves employee and customer satisfaction, thus improving overall performance, according to McKinsey.
Less clear is how to scale RAG across an enterprise, which would enable organizations to turbocharge their GenAI use cases. Early efforts to codify repeatable processes to help spin up new GenAI products and services with RAG have run into limitations that impact performance and relevancy.
Fortunately, near term and medium-term solutions offer possible paths to ensuring that RAG can scale in 2025 and beyond.
RAGOps rising
LLMs that incorporate RAG require access to high-quality training data. However, ensuring the quality and availability of relevant data tends to be challenging because the data is scattered across different departments, systems and formats.
To maximize their effectiveness, LLMs that use RAG also need to be connected to sources from which departments wish to pull data – think customer service platforms, content management systems and HR systems, etc. Such integrations require significant technical expertise, including experience with mapping data and managing APIs.
Also, as RAG models are deployed at scale they can consume significant computational resources and generate large amounts of data. This requires the right infrastructure as well as the experience to deploy it, as well as the ability to manage data it supports across large organizations.
One approach to mainstreaming RAG that has AI experts buzzing is RAGOps, a methodology that helps automate RAG workflows, models and interfaces in a way that ensures consistency while reducing complexity.
RAGOps enables data scientists and engineers to automate data ingestion and model training, as well as inferencing. It also addresses the scalability stumbling block by providing mechanisms for load balancing and distributed computing across the infrastructure stack. Monitoring and analytics are executed throughout every stage of RAG pipelines to help continuously refine and improve models and operations.
McKinsey, for instance, uses RAGOps to help its Lilli GenAI platform sift through 100,000 curated documents. Lilli has answered more than 8 million prompts logged by roughly three-quarters of McKinsey employees searching for tailored insights into operations.
The coming age of agentic RAG
As an operating model for organizations seeking to harness more value from their GenAI implementations, RAGOps promises to land well in organizations that have already exercised other operating frameworks, such as DevOps or MLOps.
Yet some organizations may take a more novel approach that follows the direction the GenAI industry is headed: marrying RAG with agentic AI, which would enable LLMs to adapt to changing contexts and business requirements.
Agents designed to execute digital tasks with minimal human intervention are drawing interest from businesses seeking to delegate more digital operations to software. Some 25 percent of organizations will implement enterprise agents by 2025, growing to 50 percent by 2027, according to Deloitte research.
Agentic AI with RAG will include many approaches and solutions, but many scenarios are likely to share some common traits.
For instance, individual agents will assess and summarize answers to prompts from a single document or even compare answers across multiple documents. Meta agents will orchestrate the process, managing individual agents and integrating outputs to deliver coherent responses.
Ultimately, agents will work within the RAG framework to analyze, plan and reason in multiple steps, learning as they execute tasks and altering their strategies based on new inputs. This will help LLMs better respond to more nuanced prompts over time.
In theory, at least.
The bottom line
The future looks bright for GenAI technologies, which will flow from research labs to corporate AI factories, part of a burgeoning enterprise AI sector.
For example, the footprint of models will shrink even as they become more optimized to run efficiently on-premises and at the edge on AI PCs and other devices. RAG standardization, including software libraries and off-the-shelf tools, will grow.
Whether your organization is embracing RAGOps or adopting agentic AI, solutions are emerging to help organizations scale RAG implementations.
Agentic RAG on the Dell AI Factory with NVIDIA, when applied to healthcare for example, helps reconcile the challenges of utilizing structured data, such as patient schedules and profiles, alongside unstructured data, such as medical notes and imaging files, while maintaining compliance to HIPAA and other requirements.
That’s just one bright option. Many more are emerging to help light the way for organizations in the midst of their GenAI journey.
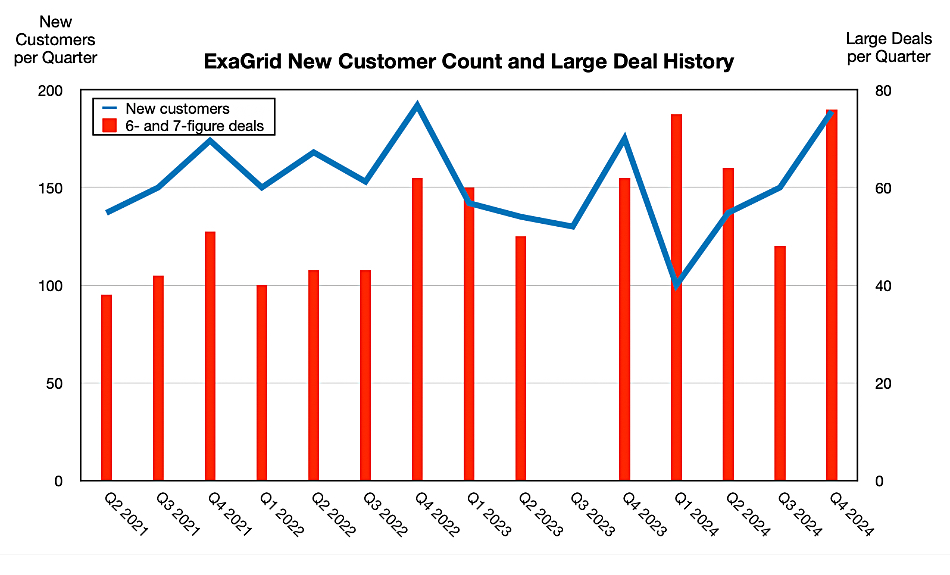
ExaGrid claims it is fielding “record bookings” and revenue – although as a privately held company it provides no comparative figures for this – for the final 2024 quarter, up 20 percent annually, and full year.
The company provides target backup appliances featuring a fast restore landing zone and deduplicated retention zone. This has a Retention Time-Lock that includes a non-network-facing tier (creating a tiered air gap), delayed deletes, and immutability for ransomware recovery. ExaGrid was founded in 2002 and last raised funds in 2011, with a $10.6 million round, taking the total raised to $107 million. It says it is debt-free.
President and CEO Bill Andrews stated:”ExaGrid is continuing to grow with healthy financials, as shown by the past 16 quarters that we have maintained positive P&L, EBITDA, and free cash flow. We have sales teams in over 30 countries worldwide, and customer installations in over 80 countries. We continue to invest in our channel partnerships and worked with more reseller partners in 2024 than ever before, and we plan to expand on our partner programs in 2025.”
Bill Andrews
He added: “As we constantly innovate our Tiered Backup Storage, we look forward to announcing new updates, integrations, and product announcements throughout 2025 and expect continued growth and success.”
ExaGrid says it recruited 189 new customers in the quarter, of which 76 were six and seven-figure deals, taking the customer count to near 4,600. Its average customer count increase has been 150 over the past 16 quarters and its competitive win rate is 75.3 percent, it says.
Andrews claims: “There are only three solutions in the market: standard primary storage disk, which does not have dedicated features for backup and becomes expensive with retention; inline deduplication appliances … that are slow for backups and restores, use a scale-up architecture, and don’t have all the security required for today’s backup environments; and ExaGrid Tiered Backup storage, which offers many features for backup storage and many deep integrations with backup applications. When customers test ExaGrid side by side, they buy ExaGrid 83 percent of the time – the product speaks for itself.”
Andrews told B&F: “We continue to replace primary storage behind the backup application from Dell, HPE, NetApp, Hitachi, IBM, etc. We continue to replace Dell Data Domain and HPE StoreOnce inline/scale-up deduplication appliances. We continue to replace [Cohesity-Veritas] NetBackup FlexScale appliances.”
Geographically, there was “great participation from the US, Canada, Latin America, Europe, the Middle East, and Africa. We have hired ten sales teams in Asia Pacific and expect the investment to start kicking in this quarter. We continue to maintain a 95 percent customer retention rating, 99 percent of customers on maintenance, and support and an NPS score of +81.”
The company will be “adding many service provider features for the large Backup as a Service MSPs” in 2025.
Last October we learned that ExaGrid reckoned it had 3 percent of the $6 billion backup storage market, implying $180 million in annual revenues. While its Q4 2024 revenues increased 20 percent annually, we don’t know the quarter-on-quarter increase. Andrews claimed in October last year that the company was making solid progress toward achieving $1 billion in annual sales.
Andrews said at the time: “Our product roadmap throughout 2025 will be the most exciting we have ever had, especially in what we will announce and ship in the summer of 2025. We don’t see the competitors developing for backup storage. Our top competitors in order are Dell, HPE, NetApp, Veritas Flexscale Appliances, Pure, Hitachi, IBM, Huawei. Everyone else is a one-off sighting here and there.”
NetApp does not provide a deduping target backup appliance equivalent to Dell’s PowerProtect, HPE’s StoreOnce or Quantum’s DXi products. But NetApp BlueXP provides a backup and recovery control plane with the ability to back up NetApp ONTAP systems to NetApp StorageGRID object storage or AWS, Azure, and Google cloud object stores.
The big change in the target backup appliance and storage market in the last couple of years has been the emergence of object storage targets for backup software, such as Cloudian and startup Object First. ExaGrid supports the Amazon S3 object protocol.