DNA-based storage platform provider Catalog Technologies claims that its tech, which uses parallelization, minimal energy, and a low physical footprint, offers an alternative to established data management systems, and has now delivered the first commercially available book encoded into DNA using its technology.
The Catalog Asimov DNA book
A traditional printed book, available from Asimov Press, includes a DNA capsule provided by Catalog, and retails for $60 as a bundle. In keeping with the spirit of science, the book features nine essays and three works of science fiction.
Catalog, founded in 2016 by MIT scientists, created around 500,000 unique DNA molecules to encode the 240 pages of the book, representing 481,280 bytes of data. After being converted into synthetic DNA, it was stored as a dry powder under inert gas to eliminate moisture and oxygen in the capsule.
Hyunjun Park
The production of the capsules involved two other companies in the process. Catalog synthesized and assembled the millions of nucleotides of DNA into thousands of individual strands in their Boston laboratories. That DNA was then shipped to France, where Imagene packaged the molecules into laser-sealed, stainless steel capsules. Finally, Plasmidsaurus “read” the DNA book at their headquarters in California and submitted the final sequence of it.
“Providing 1,000 copies of this latest Asimov book encoded into DNA is a significant milestone as we commercialize our DNA storage and computation technology,” said Hyunjun Park, co-founder and CEO of Catalog. “Our DNA platform – which uses very little energy – is quickly becoming an attractive option as emerging workloads, including AI, require unsustainable amounts of energy to process.”
While this is the first commercially available DNA book, it’s not the first DNA book. George Church’s Regenesis, which he co-authored with Ed Regis, was published in 2012. Church’s Harvard laboratory used binary code to preserve the book (including images and formatting), before converting that binary code into physical DNA.
Shortly after, a group of Cambridge scientists encoded Shakespeare’s entire collection of 154 sonnets – as well as an audio file of Martin Luther King’s “I Have A Dream” speech – into DNA.
Catalog’s DNA capsules
In 2022, Catalog encoded eight of Shakespeare’s tragedies, comprising more than 200,000 words of text, into a single test tube. It also built and tested methods to search that DNA.
Various new forms of DNA data storage technologies have been reported by Blocks & Files recently, including here, and here.
Companies built around AI data systems dominate entrants to the latest unicorn list compiled by broking comparison site BestBrokers, with Databricks and WEKA mentioned.
Unicorns are defined as privately owned companies valued at over $1 billion, and those in BestBrokers’ 2024 complete list are often valued at well over that mark.
OpenAI, the US company behind ChatGPT, recently closed a $6.6 billion funding round, nearly doubling its value from February 2024 to $157 billion. Meanwhile, Elon Musk’s SpaceX launched a tender offer in December 2024 that brought its valuation to $350 billion, overtaking Chinese tech giant and TikTok owner ByteDance as the most valuable startup in the world.
On new entrants to the unicorn list, BestBrokers said that out of 79 startups reaching the status in 2024, 36 of them, or nearly 46 percent, are AI companies. Among these is Musk’s AI startup, xAI, which he founded in 2023 to compete with OpenAI, a company he left after co-creating it. xAI is said to be worth around $50 billion after a funding round of $6 billion in December 2024.
The top ten AI unicorns with their estimated values are xAI ($50 billion), Perplexity AI ($9 billion), SandboxAQ ($5.6 billion), Safe Superintelligence ($5 billion), Sierra ($4.5 billion), Moonshot AI ($3.3 billion), Cyera ($3 billion), Poolside ($3 billion), Physical Intelligence ($2.8 billion), and Figure ($2.68 billion).
The total number of unicorns reached 1,258 in December 2024, and of the top ten, Data lakehouse supplier Databricks is ranked sixth with a $62 billion valuation. Ultra-fast file system software supplier WEKA is given a $1.6 billion valuation and is ranked 24th.
In January 2023, Blocks & Files reported there were 21 storage industry startups worth a billion dollars or more.
In BestBrokers’ list of 79 new entrants outside AI, there are six unicorns in cybersecurity (7.6 percent), ten in enterprise software (12.7 percent), and 16 in fintech and crypto (20.3 percent).
The US is home to well over half of all unicorns, with the figure standing at 683. Many were founded by immigrants or were started elsewhere but later relocated to the US. SpaceX, Databricks, and Stripe are examples.
China has 165 unicorns and India has 71. Across Europe, the UK has the largest number of unicorns, 54 in total, and Germany has 32. In addition, France has 28.
Lenovo is buying privately-owned enterprise block array storage supplier Infinidat for an undisclosed amount.
Systems supplier Lenovo’s storage line-up is centered on small and medium enterprises. It was built up by Kirk Skaugen, who was the boss of Lenovo’s Infrastructure Solutions Group from 2013 until June last year, when he was replaced by Ashley Gorakhpurwalla, who was Western Digital’s WD’s EVP and GM of its hard disk drive (HDD) business. Lenovo’s products include the ThinkSystem DG all-flash, DM hybrid, and DE SAN arrays and are mostly OEM’d from NetApp’s ONTAP storage line.
Lenovo says it has the number one revenue position in the IDC storage market price bands 1 (<$6,000) to 4 ($50,000 to $99,999). However, it doesn’t lead in bands 5 ($100,000 to $249,999) to 7 (>$500,000) and is not a major player in the enterprise storage market where Infinidat has built its business.
Greg Huff, Lenovo Infrastructure Solutions Group CTO, said in a statement: “With the acquisition of Infinidat, we are excited and well-positioned to accelerate innovation and deliver greater value for our customers. Infinidat’s expertise in high-performance, high-end data storage solutions broadens the scope of our products, and together, we will drive new opportunities for growth.”
Phil Bullinger.
Infinidat CEO Phil Bullinger said: “Infinidat delivers award-winning high-end enterprise storage solutions providing an exceptional customer experience and guaranteed SLAs with unmatched performance, availability, cyber resilience and recovery, and petabyte-scale economics. With Lenovo’s extensive global capabilities, we look forward to expanding the comprehensive value we provide to enterprise and service provider customers across on-premises and hybrid multi-cloud environments.”
Lenovo says it will gain:
Mission critical enterprise storage for scalable, cyber-resilient data management and an in-house software R&D team.
Expanded storage systems portfolio to cover high-end enterprise storage, building on Lenovo’s existing position in the entry and mid-range enterprise storage market.
An opportunity to drive profitable growth of the Group’s storage business as Infinidat, combined with Lenovo’s existing global infrastructure business, customer relationships, and global supply chain scale, is expected to create new opportunities for high-end enterprise storage products and unlock new revenue opportunities for the Group’s storage business.
Infinidat was founded in 2010 by storage industry veteran Moshe Yanai and uses memory data cacheing in its InfiniBox systems to supply data from disk as fast if not faster than all-flash arrays. This base product line was expanded to include the InfiniBox SSA all-flash system and the InfiniGuard data protection system. These systems competed with IBM’s DS8000, Dell PowerMAX, and Hitachi Vantara’s VSP systems.
Moshe Yanai in 2018.
Eventually Infinidat’s growth sputtered somewhat and Yanai was forced out of the Chairman and CEO roles in 2020, becoming a technology evengelist and subsequently leaving. Western Digital’s SVP and GM of its disposed datacenter business unit, Phil Bullinger, became the CEO in 2021. At the time Bullinger said Infinidat was profitable, cashflow positive, and growing.
Since then Infinidat says it has grown, with a reported 40 percent year-on-year bookings growth in 2021, and double digit growth in 2022, when it was also cashflow-positive. It said it achieved record results and a 59 percent annual bookings growth rate in calendar Q1 of 2023. The company has a focus on cyber-resiliency and is also active in the AI area, with a RAG workflow deployment architecture enabling customers to run generative AI inferencing workloads on its InfiniBox on-premises.
Infinidat has raised a total of more than $370 million in funding, with the last round taking place in 2020.
UnifabriX claims its CXL-connected external MAX memory device can deliver substantial AI processing performance improvements.
The company’s MAX memory technology was described in an earlier article. UnifabriX CEO Ronen Hyatt cites an “AI and Memory Wall” research paper by Amir Gholami et al to illustrate how he sees the process. The researchers say: “The availability of unprecedented unsupervised training data, along with neural scaling laws, has resulted in an unprecedented surge in model size and compute requirements for serving/training LLMs. However, the main performance bottleneck is increasingly shifting to memory bandwidth. Over the past 20 years, peak server hardware FLOPS has been scaling at 3.0x/two years, outpacing the growth of DRAM and interconnect bandwidth, which have only scaled at 1.6 and 1.4 times every two years, respectively. This disparity has made memory, rather than compute, the primary bottleneck in AI applications, particularly in serving.”
A chart in the paper shows the effects of this:
The scaling of the bandwidth of different generations of interconnections and memory, as well as the peak FLOPS. As can be seen, the bandwidth is increasing very slowly. We are normalizing hardware peak FLOPS with the R10000 system, as it was used to measure the cost of training LeNet-5
The memory wall is the gap between memory bandwidth and peak hardware FLOPS.
The paper’s authors conclude: “To put these numbers into perspective, peak hardware FLOPS has increased by 60,000x over the past 20 years, while DRAM/interconnect bandwidth has only scaled by a factor of 100x/30x over the same time period, respectively. With these trends, memory – in particular, intra/inter-chip memory transfer – will soon become the main limiting factor in serving large AI models. As such, we need to rethink the training, deployment, and design of AI models as well as how we design AI hardware to deal with this increasingly challenging memory wall.”
Hyatt modifies the chart to add a scaling line for the PCIe bus generations plus CXL and NVLink, showing that IO fabric speeds have not increased in line with peak hardware FLOPS either:
There is a performance gap in AI infrastructure between a GPU server’s memory and flash storage, even if InfiniBand is used to connect the NAND drives. By hooking up external memory via CXL (and UALink in the future), the performance gap can be mitigated.
Hyatt says memory fabrics are better than InfiniBand networks, enabling higher performance, and that CXL and UALink are open memory fabric standards comparable to Nvidia’s proprietary NVLink.
In addition to delivering performance improvements, UnifabriX’s MAX memory can save money.
In UnifabriX’s example scenario, there are 16 servers, which include four GPU servers, with each configured with 6 TB of DRAM, providing a total capacity of 96 TB. The total memory cost is $1.6 million, and UnifabriX suggests less than 30 percent memory utilization.
By adding its MAX memory unit to the configuration, with a 30 TB memory capacity, the 16 servers can now each be configured with 2.25 TB of memory, resulting in a total of 66 TB of memory at a cost of $670,000, with a much higher utilization rate. The servers get on-demand memory capacity and bandwidth, and run their applications faster.
There is a $1 million capex saving as well as a $1.5 million TCO gain in UnifabriX’s example.
A Rubrik Zero Labs-commissioned survey reveals that 79 percent of CISOs believe the combination of compliance with the European Union’s DORA, ransomware, third-party compromise, and software supply chains has had an impact on their mental health.
The DORA (Digital Operational Resilience Act) regulation takes effect from January 17. It’s intended to improve financial institutions’ cyber resilience so they can operate during cyberattacks and other disruptive IT incidents. DORA specifies standards they need to follow for managing cybersecurity risks, incident reporting, and digital resilience.
James Hughes
James Hughes, Rubrik VP for Sales Engineering and Enterprise CTO, said: “Given the increasing threat of ransomware and third-party compromise, the implementation of regulations is required and expensive. Understanding what data is the most critical, where that data lives, who has access to it is essential to identifying, assessing, and mitigating IT risks. If good hygiene practices like these are not followed, organizations can now receive fines from the Financial Conduct Authority,” in the UK, for example.
There are 60 articles in the DORA regulations. Article 12 requires secure, physically and logically separated backup storage.
Rubrik provides backup as part of its cyber-resilience suite. Hughes said it has a DORA checklist available for customers. Other suppliers with DORA checklists include Scytale, eSentire, and UpGuard.
The key DORA regulators include:
European Banking Authority (EBA): Oversees banks, credit institutions, and payment providers.
European Securities and Markets Authority (ESMA): Regulates investment firms, trading venues, and market participants.
European Insurance and Occupational Pensions Authority (EIOPA): Supervises insurance and pension companies.
The European Central Bank (ECB) will also have a supervisory role for financial entities under its jurisdiction, such as significant banks in the Eurozone.
Each EU member state appoints its own National Competent Authority to enforce DORA at a local level.
DORA regulation concerning backup.
DORA differs from previous regulations of this kind because penalties for infringement apply to an organization’s senior personnel and not just the organization itself. This ups the stakes for CISOs concerned with DORA compliance.
A Gartner study found that 62 percent of security and IT leaders responsible for cybersecurity have experienced burnout at least once, with 44 percent reporting multiple instances.
Rubrik set up a CISO Advisory Board a few years ago, and says it aims to support CISOs in coping with these challenges in safeguarding organizational data and so contribute to their well-being and effectiveness. It also suggests that initiatives, such as its “Data Security Decoded” podcast series, provide platforms for CISOs to share experiences and strategies for managing the complexities of their roles.
Rubrik is implying that if a CISO uses Rubrik cybersecurity as part of their DORA compliance, their well-being may improve.
NetApp is selling its Spot and CloudCheckr CloudOps portfolios to FinOps business Flexera for a reported $100 million.
Spot provides ways to find and use the lowest cost public cloud instances. CloudCheckr is a public cloud cost-optimization facility. Flexera says the combination of Spot’s AI and ML-enabled technology and its own hybrid cloud expertise will provide a comprehensive FinOps offering that enhances financial accountability and efficiency in cloud operations. It also fits in FinOps’ expanding scope, “which now includes datacenters, SaaS applications, and public cloud,” plus software licensing and sustainability.
Jim Ryan
Flexera CEO and President Jim Ryan stated: “A tsunami of artificial intelligence applications is exponentially increasing organizations’ consumption of cloud resources. Yet we hear from many organizations about the difficulty in answering basic questions like ‘what technology services do we use?’ and ‘why are our cloud bills so high?’ Our acquisition of Spot is the next step in Flexera’s strategic plan to provide organizations with a full panorama of their technology spend and risk across the entire IT ecosystem. We want to make it easy for anyone to find and analyze any data related to spend and risk for any kind of technology, anywhere it lives.”
Haiyan Song, NetApp EVP for Intelligent Operations Services, said: “This decision reflects NetApp’s sharpened focus and underscores our commitment to intelligent data infrastructure and long-term growth opportunities. After a thorough evaluation, it is clear that Flexera’s established expertise and global reach provide the ideal environment for the Spot business to thrive and scale. This move not only allows the Spot team and portfolio to unlock their full potential within Flexera’s ecosystem but also reinforces our dedication to driving value creation and achieving our ambitious growth objectives.”
Haiyan Song
The Spot portfolio was not storage-focused so fell outside NetApp’s core business. Song said in a blog: “This move will enable us to further our focus on core business areas, aligning the mission of intelligent operations services (also known as CloudOps) to our primary focus on intelligent data infrastructure … Our strategy is to align our CloudOps portfolio with our core storage offerings and focus on delivering the value of intelligent operations services to our customers.”
She revealed: “Many employees currently working on the Spot portfolio are anticipated to join Flexera … We are dedicated to facilitating a smooth transition for all affected employees, providing comprehensive support, transparent communication, and transition assistance.”
Flexera says the acquired software will “provide continuous automation, optimization, and insights on an organization’s cloud infrastructure and applications. The acquisition will add new capabilities such as Kubernetes cost management and commitment management to Flexera’s industry-leading FinOps portfolio. With the acquisition, Flexera will also create a richer ecosystem of FinOps Managed Service Providers (MSPs) to serve customers’ evolving needs and bring new DevOps users into its robust customer community.”
Putting NetApp on the Spot
Financial details of the transaction were not disclosed, but Bloomberg reports that Thoma Bravo-owned Flexera is paying around $100 million for NetApp’s Spot portfolio.
NetApp bought Israeli startup Spot.io in June 2020 for an undisclosed sum. The price was said to be $450 million, according to the Calcalist, an Israeli business mag. This enabled NetApp to offer containerized app deployment services based on seeking out the lowest cost or spot compute instances.
In October 2021, NetApp acquired CloudCheckr and its cost-optimizing public cloud management CMx platform to expand its Spot by NetApp CloudOps offering. Again, financial details of the transaction were not disclosed. As CloudCheckr’s total funding was $67.4 million, it had been growing fast, and was backed by private equity, thus we expected a $200 million to $300 million acquisition cost range.
This suggests that the total acquisition cost for Spot and CloudCheckr was in the $650 million to $750 million area, far less than the $100 million Flexera is paying.
Spot and CloudCheckr were part of NetApp’s public cloud business, which accounted for 10 percent of its overall revenues in its latest quarter:
By selling the Spot and CloudCheckr parts of it CloudOps business for $100 million, NetApp will forego their revenues in future and could take a revenue hit in its public cloud business in the next quarter or two.
Wedbush analyst Matt Bryson tells subscribers: “While at one point NetApp had larger ambitions around its cloud overlay offerings with NetApp acquiring numerous companies to form what looked like a full stack of cloud management tools, the past couple of years have seen NetApp reduce its focus on non-storage related cloud businesses. Net, we see the divestment of these non-core businesses as in line with this strategic shift.”
He added: “We believe NTAP’s revised strategy is serving the company well as our conversations suggest it continues to compete effectively vs peers with its core array offerings including making inroads into the block market (in line with results the past few quarters); though we do see some risk of margin compression this quarter and next as favorable eSSD pricing dissipates.”
This Flexera-NetApp transaction is subject to customary closing conditions, including the receipt of required regulatory approvals.
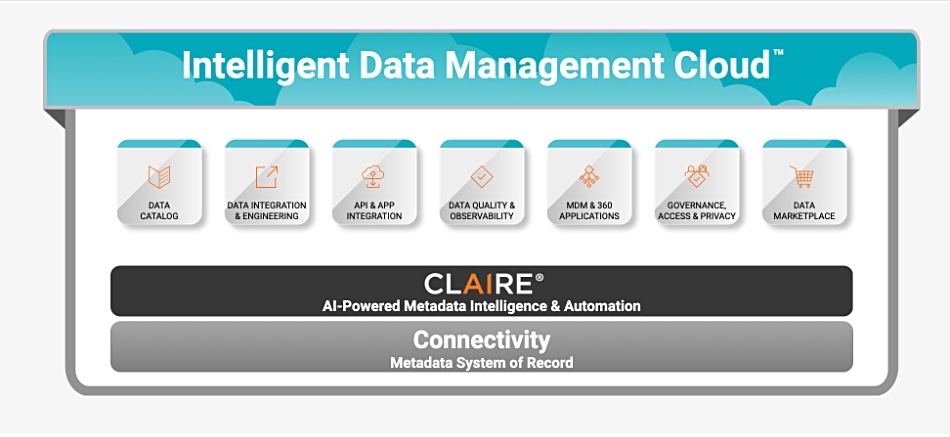
Data integration and management supplier Informatica has strengthened the integration of its Intelligent Data Management Cloud (IDMC) with Databricks’ Data Intelligence Platform, including support for AI Functions.
Databricks supplies an intelligent data warehouse and is growing its business at a furious rate as the generative AI boom pulls in more and more data to be processed. It raised $10 billion in funding late last year and has just augmented that with another $5 billion in debt financing loans, bringing its total funding to $19 billion. Informatica’s Extract, Transform and Load (ETL) and data management and governance offerings help get high-quality data ingested into Databricks for AI training and inference.
Amit Walia
Informatica CEO Amit Walia stated: “We are seeing phenomenal success with our Databricks-related business, with rapid growth and delivering impactful business outcomes for customers such as Takeda, KPMG, and Point72 to name just a few.”
He said: “One of our key priorities while partnering with Databricks is empowering customers to build enterprise-grade GenAI applications. These applications leverage high-quality, trusted enterprise data to provide high-impact GenAI applications with rich business context and deep industry semantic understanding while adhering to enterprise data governance policies.”
Adam Conway, Databricks SVP of Products, added: “As a leader in cloud-native, AI-powered data management, Informatica is a key partner of ours, supporting everything from data integration and transformation to data quality, governance, and protection.”
Databricks AI Functions are built-in SQL operations that allow customers to apply AI directly to their data. Informatica’s Native SQL ELT supports Databricks AI Functions through no-code data pipelines, opening Databricks GenAI capabilities to no-code users. Databricks’ AI Functions enable customers to use GenAI capabilities, including sentiment analysis, similarity matching, summary generation, translation and grammar correction on customer data directly from SQL.
The new Informatica Native SQL ELT for Databricks makes it possible to “push down” data pipelines with 50-plus out-of-the-box transformations and support for more than 250 native Databricks SQL functions.
In June last year, Informatica integrated its AI-powered IDMC into the Databricks Data Intelligence Platform. Informatica’s GenAI Solution Blueprint for Databricks DBRX provided a roadmap for customers to develop retrieval-augmented generation (RAG) GenAI applications using Databricks DBRX. Native Databricks SQL ELT enables joint customers to perform in-database transformations with full push-down capabilities on Databricks SQL.
Informatica’s CDI-Free offering on Databricks Partner Connect gives customers access to Informatica’s cloud data ingestion and transformation capabilities. Its IDMC platform was validated with the Databricks Unity Catalog.
Altogether, the Informatica IDMC platform includes multiple Databricks-optimized features, such as 300-plus data connectors, the ability to create low-code/no-code data pipelines, data ingestion and replication, and GenAI-driven automation via Informatica’s CLAIRE GPT and CLAIRE copilot offerings.
In Informatica’s third fiscal quarter of 2025, revenues increased 3.4 percent year-over-year to $422.5 million. It surpassed 101 trillion processed cloud transactions per month, with Walia saying: “This accomplishment reflects our commitment to product innovation, customer-centricity, and our goal of being the Switzerland of data and AI. We see great momentum in AI-powered data management use cases.”
Analysis: Having erected a substantial AI-focused stack of software components in 2024, announced a partnership with Cisco, and delivered software upgrades, how is VAST Data positioned at the start of 2025?
It’s entering the year with the latest v5.2 Data Platform software release, which features its EBox functionality, first previewed in March 2024. VAST’s basic DASE (Disaggregated Shared Everything) software has a cluster architecture “that eliminates any communication or interdependencies between the machines that run the logic of the system.” It features compute (CNodes) liaising with data box storage enclosures (DNodes) across an internal NVMe fabric.
The DNodes are just boxes of flash (JBOFs) housing NVMe SSDs. These highly available DNodes store the DASE Cluster system state. VAST says: CNodes “run all the software and DBoxes … hold all the storage media, and system state. This enables the cluster compute resources to be scaled independently from storage capacity across a commodity datacenter network.”
Howard Marks
The EBox idea colocates a CNode and DNode in one server box, thus preventing the independent scaling of compute and storage. This is justified because, as VAST Technologist blogger Howard Marks says: “The EBox architecture lets us run the VAST Data Platform in environments that, until now, didn’t want, or couldn’t use, highly available DBoxes. These include hyperscalers that have thousands of a very specific server configuration and cloud providers that only offer virtual machine instances. It also allows us to work with companies like Supermicro and Cisco to deliver the VAST Data Platform to customers using servers from those vendors.”
A separate VAST blog states: “The EBox is designed to address the growing needs of hyperscalers and CSPs that require infrastructure capable of handling massive data volumes and complex workloads. By combining the best features of its predecessors into a more compact form factor, the EBox not only saves valuable rack space but also enhances the overall performance and resilience of the datacenter.”
EBox hardware features a single AMD Genoa 48-core processor, 384 GB of DRAM, 3 x storage-class memory (SCM) drives, and 9 x 30 TB NVMe SSDs (270 TB), plus two PCIe slots for front-end cards. There is a minimum cluster size of 11 nodes and metadata triplication “ensuring every read or write operation is replicated across three EBoxes within the cluster.” So the system withstands substantial hardware failure, keeping data secure and ensuring “sustained performance and rapid recovery, even during failures.”
Marks says: “Each x86 EBox runs a CNode container that serves user requests and manages data just like a dedicated CNode would, and DNode containers that connect the EBox’s SSDs to the cluster’s NVMe fabric. Just like in a VAST cluster with CBoxes and DBoxes, every CNode in the cluster mounts every SSD in the cluster.”
v5.2 also includes a global SMB namespace, Write Buffer Spillover, VAST native table support in async replication, S3 event publishing, and S3 Sync Replication, all of which “can streamline complex workloads for enterprise, AI, and high-performance computing environments.” It also has improved write performance, with Marks saying: “We’re taking advantage of the fact that there are many more capacity (QLC) SSDs than SCM SSDs by directing large bursts of writes, like AI models’ dumping checkpoints, to a section of QLC. Writing to the SCM and QLC in parallel approximately doubles write performance” over the previous v5.1 software release. Since we’re only sending bursts of large writes to a small percentage of the QLC in a cluster, the flash wear impact is insignificant.”
He adds: “We’re also bringing the EBox architecture to the public cloud in 5.2, with fully functional VAST Clusters on the Google Cloud Platform,” which we expect to be announced later this year.
The S3 event publishing is configured on one or more buckets in the system and provides event-driven workflows triggering functions. When data changes in such a bucket, the VAST cluster will send an entry to a specified Apache Kafka (distributed streaming platform) topic. Specifically, v5.2 VAST software requires the topic to be on an external Kafka cluster and the functions must subscribe to the Kafka topic.
More is coming this year, with Marks writing: “Over the next few quarterly releases, the VAST DataEngine will add a Kafka API-compatible event broker and the functionality to process data,” ending the external Kafka cluster limitation.
Camberly Bates
Futurum analyst Camberly Bates writes: “VAST’s EBox integration with the Google Cloud Platform is likely to drive further adoption in public cloud environments.” This hints at Azure and AWS support for the EBox concept coming later this year.
We would expect the EBox architecture to support much higher capacity SSDs later this year, with 62 TB drives now available from Micron, Phison, Samsung, and SK hynix, and 122 TB-class SSDs announced by Phison and Solidigm recently.
Bates also suggests, referring to the v5.2 software: “Rivals may introduce similar advancements in replication, namespace management, and performance to remain competitive.”
Suppliers like DDN, HPE, Hitachi Vantara, IBM, NetApp, Pure Storage, and WEKA are likely going to face continued strong competition from VAST in 2025.
Israel-based UnifabriX, founded in 2020 by Ronen Hyatt (CEO and chief architect), Danny Volkind (CTO), and Micha Rosling (chief business officer), has taken in $11 million in seed funding to develop Smart Memory Fabric systems based around CXL external memory sharing and pooling technology. The intention is to sidestep the memory capacity limitations of individual CPU and GPU server systems by connecting external memory pools using the CXL (Computer Express Link) scheme, which is based on the PCIe cabling standard.
UnifabriX and Panmnesia are two of the most active CXL-focused startups. We looked at Panmnesia yesterday and now turn our attention to UnifabriX.
It had developed a Smart Memory Node with 32 TB of DDR5 DRAM in a 2RU chassis by April 2023, and now has its MAX (Memory Accelerator) composable memory device based on UnifabriX software and semiconductor IP.
MAX provides a software-defined memory fabric pool, featuring adaptive memory sharing, and using CXL and UALink cabling and concepts, several of which are mentioned in the slide above. We’ll look at the system-level architecture and then try to make sense of the cabling spaghetti.
Hyatt talked about this slide: “On top of our FabriX Memory OS, which is a hardened Linux … we have a stream processor that can manipulate the stream of data and the stream of protocols as they come into the memory pool. And this is programmable hardware. You can think of it like the P4 concept that grew in switches and internet switches where you can parse the data as it goes on the fly and edit the protocol messages as they go in and out.
Ronen Hyatt
“So you see here the frontend ports, the six frontend ports go to the host. Today there are CXL 1.1 and 2.0. We have deck and fabric ports and we accelerated the link there to 112G, much faster than CXL supports today. This is NVLink 4-equivalent in terms of speed and we are working on prototyping 224G, which is the equivalent of NVLink 5. Yes, it’s the bandwidth. We wanted to get the highest bandwidth possible on the backend side, on the fabric, when you connect multiple MAX appliances, one to each other.”
CXL cabling situation
The PCIe, CXL, and UALink situation is complex. We should note that there are five CXL standard generations between CXL 1 and CXL 3.1, with also a sixth, CXL 3.2, now available. This adds optimized memory device monitoring and management, extended security, performance monitoring, and is backwards-compatible with prior CXL specifications.
Hyatt tells us: “PCIe was originally built to live inside a platform, serving as a short-distance interconnect superseding PCI, between a CPU and peripheral devices, therefore it does not have a developed ecosystem of cabling. Larger-scale use cases of PCIe emerged only later, with ‘PCIe Fabrics’ that pooled and disaggregated devices such as NVMe storage, NICs, and GPUs.
“Those use cases did not require a lot of bandwidth, and therefore were comfortable with utilizing narrow x4 switch ports and x4 SFF-8644 (mini-SAS) cabling. A few examples here and here.
“The emergence of CXL over PCIe Gen 5 created a new demand for high-performance PCIe cabling that is capable of delivering much higher bandwidth for memory transactions. Since PCIe did not have such solutions ready, the market found interim solutions by utilizing cabling systems from the Ethernet domain, such as:
QSFP-DD MSA (x8) – a denser form factor of QSFP, originally created for Ethernet, Fibre Channel, InfiniBand and SONET/SDH. Some people used it (and still use it today) for PCIe x8 connections. See here.
CDFP MSA (x16) – originally developed for 400G Ethernet (16 x 25G lanes), but later certified de-facto for PCIe Gen 5. See here and here.
“Today, the PCIe ecosystem is aligning around the OSFP MSA cabling system, with OSFP (x8) and its denser variant OSFP-XD (x16) that both support the latest signaling rate of 224G PAM4 per lane (for example, 8 x 200G = 1.6 Tbps Ethernet), and are therefore also compatible with PCIe Gen 5/CXL 1.1, 2.0 (32G NRZ), PCIe Gen 6/CXL 3.x (64G PAM4), and PCIe Gen 7/CXL 4.x (128G PAM4). i.e. this OSFP cabling system is future-proof for at least two generations ahead in the PCIe domain. It is also ready for UALink that reuses Ethernet IO at the electrical level. One cable to rule them all.”
Nvidia showed a way forward here, with Hyatt explaining: “It takes a lot of market education to bring memory fabrics into the datacenter. Nvidia jumped in to help when it introduced the DGX GH200 system with its NVLink memory fabric, creating a large, disaggregated 144 TB pool of memory. CXL and UALink are the open comparables of NVLink. They all support native load/store memory semantics.
“Nvidia taught the world that memory fabrics (by NVLink) are superior to networks (by InfiniBand). We tend to agree.”
He said: “UnifabriX developed a Fabric Manager (FM) compliant with CXL 3.2 FM APIs including support for DCD (Dynamic Capacity Device), i.e. it is capable of provisioning and de-provisioning memory dynamically, on-demand, using standard, open, CXL APIs. I haven’t seen another DCD Fabric Manager out there, so this may be one of the first FMs that you would encounter that actually does the work.”
There are a couple of other points. Hyatt said: “We are able to mix and match CXL ports and UALink ports, meaning we can provide memory on demand to both CPUs and to GPUs. The UALink connector is based on Ethernet IO, so the same connector, the same OSFP and OSFP XD, is going to be used for both CXL and UALink. You just change the personality of the port.”
Working silicon
The company demonstrated its memory pool dynamically altering in size and composed out to host processors on demand and then returned to the pool. UnifabriX is already earning revenue, with deployments in the data analytics, high-performance computing, public and private cloud areas.
UnifabriX slide
Hyatt said: “We have a few hyperscaler customers [where] the system is there running with the real workloads currently on Emerald Rapids platform and shifting soon towards Granite Rapids and Turin systems with AMD.”
“We have quite a few new customers in different segments of the market, not just the hyperscalers and the national labs. We have drug discovery companies, DNA sequencing. Turns out there are a lot of use cases that sit under the HPC umbrella where people need a lot of memory. Sometimes they need bandwidth, sometimes they need capacity. But having the ability to grow memory on demand and doing it dynamically brings a lot of value, not just on the TCO side.”
He explained: “You see the cloud, the public cloud, national labs. We started with the national labs and animation studios. There’s a lot of digital assets and you need to do rendering and processing, and they’re all working with fast storage systems these days, but they’re not fast enough for what they need. So having a memory pool in between helps to accelerate the whole process.”
Processing in memory
Hyatt talked about MAX being able to do some processing: “It has processing capabilities, which we found very useful for HPC. So we have processing-in-memory or near-memory capabilities. This works great for sparse memory models, for instance, in HPC where you have very large models that fit into petabytes and you need to abstract the memory address space. So you actually expose a huge address space externally.
“But internally you do the mapping. And this is part of the memory processing that we do here. And this is one example. We have an APU, which is an application processing unit which is exposed to the customer, where the customer can run their own code over containers. So if they want to do something on the memory, like, for instance, checking for malicious code, checking for some abnormal patterns within the memory, this is something that they can run internally. We provide that capability.”
Go to market
How does UnifabriX go to market? Hyatt said: “Currently, we work directly with end customers. And the reason we do it is because this is part of the product definition, like getting the feedback of what customers need. So you don’t want the channel in between because then you lose a lot of the feedback.
“But we are already engaged with partners. Some of them are platform OEMs that want to have a memory pool as part of their product portfolio. So think about all the big guys that have storage systems and think of a memory pool as a storage server, but it works on memory. So most of the paradigms and the semantics that go with storage would be replicated to the memory world and we are working with them.
“And on top of that we have several channels, some are specialized for HPC. There are OEM vendors that build unique servers and unique appliances for the HPC market. And HPC is really interested in having the memory bandwidth that CXL provides. There are several system integrators that build the whole racks and ship systems with GPUs and with a lot of compute power. And they actually pack together GPUs, servers, storage, and memory together, and ship it as a rack.”
UnifabriX is planning a new funding round in the second half of 2025.
The fab process side is developing, with Hyatt saying: “Currently, our silicon is seven nanometer and we plan to have a five nanometer TSMC silicon later, in 2026, early 2027.” This aligns with PCIe Gen 6, as Hyatt pointed out: “CXL itself is moving from PCIe Gen 5 to Gen 6, so we have to upgrade the process. Gen 6 comes with mixed signals … that needs five nanometer to be efficient on power.”
We’ll follow up with an article looking at UnifabriX’s MAX device.
Bootnote
QSFP – Quad Small Form-factor Pluggable standard referring to transceivers for optical fiber or copper cabling, and providing speeds four times their corresponding SFP (Small Form-factor Pluggable) standard. The QSFP28 variant was published in 2014 and allowed speeds up to 100 Gbps while the QSFP56 variant was standardized in 2019, doubling the top speeds to 200 Gbps. A larger variant Octal Small Format Pluggable (OSFP) had products released in 2022 capable of 800 Gbps links between network equipment.
OSFP MSA – Octal Small Form Factor Pluggable (OSFP) Multi Source Agreement (MSA). The OSFP (x8) and its denser OSFP-XD (x16) variants both support the latest signaling rate of 224G PAM4 per lane (for example 8 x 200G = 1.6 Tbps Ethernet). They are compatible with PCIe Gen5 / CXL 1.1, 2.0 (32G NRZ), PCIe Gen6 / CXL 3.x (64G PAM4) and PCIe Gen7 / CXL 4.x (128G PAM4). This OSFP cabling system is future-proof for 2 generations ahead in the PCIe domain. It is also ready for UALink that reuses Ethernet IO at the electrical level.
CDFP – CDFP is short for 400 (CD in Roman numerals) Form-factor Pluggable, and designed to provide a low cost, high density 400 Gigabit Ethernet connection.
The Commvault Cloud Platform (formerly known as Metallic) is now automating protection for Active Directory at forest level.
Active Directory (AD) is a user authentication service in the Microsoft Windows environment. It lists users and resources such as devices, along with the permissions they have or require. AD Domain Services are run on a server and a domain is a central admin unit for management and security. An organization can have more than one domain, and cross-domain access is prohibited unless authorized. Domains are managed in a tree-like structure with a top-level forest managing a set of domains that share a common schema, configuration, and global catalog, and include users, groups, permissions, and domain controllers across the organization.
Pranay Ahlawat
Commvault CTO and AI Officer Pranay Ahlawat stated: “Recovering Active Directory is foundational to maintaining continuous business after a cyberattack, yet traditional methods are too complex and prone to error. With automated Active Directory forest recovery, we are giving customers game-changing recovery capabilities, and by integrating this into our unique cyber resilience platform with broad workload support, we’re bringing a new era of continuous business to our customers that nobody can match.”
Malware attackers commonly target AD as it is essential in Windows environments, used to authenticate more than 610 million users worldwide. Commvault says: “When disaster strikes, recovering AD is vital, yet traditionally has been very hard to do, requiring intricate, time-consuming, manual processes, as described by Microsoft’s Forest Recovery Guide.” This can take “days or even weeks to complete.”
To use its full name, Commvault Cloud Backup & Recovery for Active Directory Enterprise Edition (CCBRADEE) now enables automated “rapid recovery” of such an AD forest by using automated runbooks. These include “tasks like transferring key roles from an unavailable domain controller to a functioning one, which is essential for a clean recovery.”
Comvault slide.
CCBRADEE has visual topology views of an organization’s Active Directory environment to give admins simple and quick identification of which domain controllers to restore first and how they should be recovered to accelerate availability of AD services. It “integrates AD forest recovery with granular recovery of both Active Directory and Entra ID, the cloud-based identity service, providing comprehensive protection.”
Cohesity and its acquired Veritas business can also safeguard AD forest environments via integrations with Semperis Active Directory Forest Recovery (ADFR) and other tools. More data protection suppliers protect AD at the forest level, including Dell with Recovery Manager for Active Directory Forest Edition, Rubrik with its Security Cloud (RSC), and Veeam.
Commvault Cloud Backup & Recovery for Active Directory Enterprise Edition is targeted for general availability within the first half of 2025 and priced per user. Explore AD protection on Commvault’s website here.
COMMISSIONED: As with any emerging technology, implementing generative AI large language models (LLMs) isn’t easy and it’s totally fair to look side-eyed at anyone who suggests otherwise.
From issues identifying use cases that maximize business value to striking the right balance between hard-charging innovation and sound governance, companies face their fair share of GenAI struggles.
Now it seems even those LLMs could use some help. If AI experts have it right, LLMs may be running out of fresh training data, which has the AI sector looking to a possible stopgap: synthetic data.
In the context of LLMs, synthetic data is artificially manufactured using the statistical properties of real-world data without using real information about companies or people and other entities. Using synthetic data helps organizations model outcomes without exposing themselves to security or privacy risks.
Some experts believe that by conjuring new data with which to populate outputs synthetic data can help LLMs clear the so-called data wall. To better understand the value of synthetic data, it helps to grasp the pending limitations posed by real-world data.
The data wall
Academics and AI luminaries alike have noted the probability for LLMs to hit a limit to the amount of human-generated text with which they’re trained – possibly as soon as 2026.
The data shortfall presents a problem because as the volume of training data declines, models can struggle to generalize. This can lead to overfitting, a phenomenon in which a model masters its training data so much that it performs poorly on new data, resulting in less coherent outputs.
And while experts began publicizing the problem shortly after OpenAI’s kicked off the GenAI race by launching ChatGPT two years ago, VCs powerful enough to pull the financial levers of this market have lent their voices to the issue.
“The big models are trained by scraping the internet and pulling in all human-generated training data, all-human generated text and increasingly video and audio and everything else, and there’s just literally only so much of that,” said Marc Andreessen, co-founder of Andreessen Horowitz.
The problem is serious enough that AI companies have gone analog, hiring human domain experts such as doctors and lawyers to handwrite prompts for LLMs.
Barring any breakthroughs in model techniques or other innovations that help GenAI hurdle the coming data wall, synthetic data may be the best available option.
Big brands swear by synthetic data
Synthetic data is particularly useful for helping organizations simulate real-world scenarios, including everything from what merchandise customers may purchase next to modeling financial services scenarios without the risk of exposing protected data.
Walmart, for one, synthesizes user behavior sequences for its sports and electronics categories to predict next purchases. Walmart employees vet the data throughout the process to ensure integrity between the user behavior sequence and the prediction.
The human-in-the-loop factor may be key to harnessing synthetic data to improve outcomes. For example, combining proprietary data owned by enterprises with reasoning from human employees can create a new class of data that corporations can use to create value.
This “hybrid human AI data approach” to creating synthetic data is something that organizations such as JPMorgan are exploring, according to Alex Wang, a senior research associate with the financial services company, who noted that JPMorgan has 150 petabytes of data at its disposal compared to 1 petabyte OpenAI has indexed for GPT 4.
In fact, OpenAI itself has used its Strawberry reasoning model to create data for its Orion LLM. You read that right – OpenAI is using its AI models to train its AI models.
The bottom line
Synthethic data has its limitations. For example, it often fails to capture the complexity and nuances – think sarcasm or turns of phrase – which makes real-world data so rich. This can reduce the relevancy of results, thus limiting the value of scenarios synthetic data is meant to model.
As with real-world data, algorithms used to generate synthetic data can include or amplify existing biases, which can lead to biased outputs. Moreover, ensuring the model trained on synthetic data performs well may require using supplementary real-world data, which can make fine-tuning challenging. Similarly, inaccuracies hallucinations remain an issue in synthetic data.
The challenges that come with using synthetic data require the same sound data governance practices organizations are leveraging with LLMs that train on real-world data. As such, many data engineers view the use of synthetic data to populate models as complementary.
Even so, an existential data crisis isn’t required to capitalize on the benefits of using synthetic data. And your organization needn’t be Walmart of JPMorgan’s scale to take advantage of the opportunities synthetic data has to offer.
Knowing how to effectively leverage synthetic data may be challenging for organizations who haven’t leveraged such techniques to manage and manipulate their data.
Dell Technologies offers access to professional services, as well as a broad open ecosystem of vendors, that can help you embark on your synthetic data creation journey.
XenData has taken the wraps off its new X10 Media Archive Appliance, which connects to one or two external LTO drives and can manage an “unlimited number” of offline LTO cartridges.
It has both a file-folder interface and a web interface, which provides previews of video and image files. “The X10 is a very cost-effective way to manage a highly scalable media archive,” the company says.
XenData X10 Media Archive Appliance
The web interface can be securely accessed by on-premises and remote users. They can search and browse for archived files and then play video previews and view low-res versions of image files for all the content held in the archive, including files stored on offline LTO cartridges. The web interface uses HTTPS, and it supports Chrome, Microsoft Edge, and Safari browsers.
The X10 appliance runs a Windows 11 Pro operating system and can be used standalone or connected to a local network. Although optimized for media files, the X10 will archive all file types and file names supported by Windows. It includes a mirrored 4 TB cache volume, “enhancing write and read performance,” said XenData, while being used to store the media file previews.
The archive file system can be accessed as a standard network share that adheres to the standard Microsoft security model based on Active Directory, and can be easily added to a Windows Domain or Workgroup.
Advanced functionality includes automatic LTO cartridge replication, end-to-end logical block protection, and the creation of LTO cartridge contents reports and the issuance of email alerts. It can also be configured to write to rewritable LTO cartridges using the LTFS interchange format, and can support writing to unalterable LTO WORM cartridges.
Phil Storey
“The X10 can manage hundreds of LTO cartridges stored ‘on the shelf’, and allows users to easily find the content they want and bring it back online, even for a very large archive,” said Phil Storey, XenData CEO.
The X10 appliance will be available at the end of this month, priced from $6,950.
XenData introduced its Media Portal viewer to its on-prem and public cloud tape archive library last May so users can see previews of archived image and video files to select content for restoration.