Hammerspace is making progress selling its Global DataEnvironment file data location, management and sharing services – because it provides more functionality than either enterprise and cloud storage players, or data management and protection suppliers.
Update. Panzura disagreement with Hammerspace’s characterisation of their company added as a boot note. 12 Sep 2022.
This is part two of our look at Hammerspace’s technology positioning, market positioning and business progress. It’s laid out a radar screen-type diagram with 12 dimensions of storage infrastructure functionality and plotted out the screen occupancy of vendors in the enterprise and cloud storage, data management and protection areas.
Founder and CEO David Flynn said in a briefing: “In the world of data and storage, there are many different capabilities which matter: having the right file system protocols and semantics, being able to talk to Windows as well as Linux, being able to talk legacy.”
“There’s really important data services, like snapshots and clones, all of this stuff that has made Data ONTAP the gold standard for manageability of data, your security of making sure that you’re not vulnerable to theft, or or somebody encrypting your data, compliance to legal regulation.”
Talking about Hammerspace’s 12-dimension radar diagram, he said: “In this diagram, they all have an equal amount of real estate. But some things are more important. And I would say performance and scale and data protection are some of the bigger ones.”
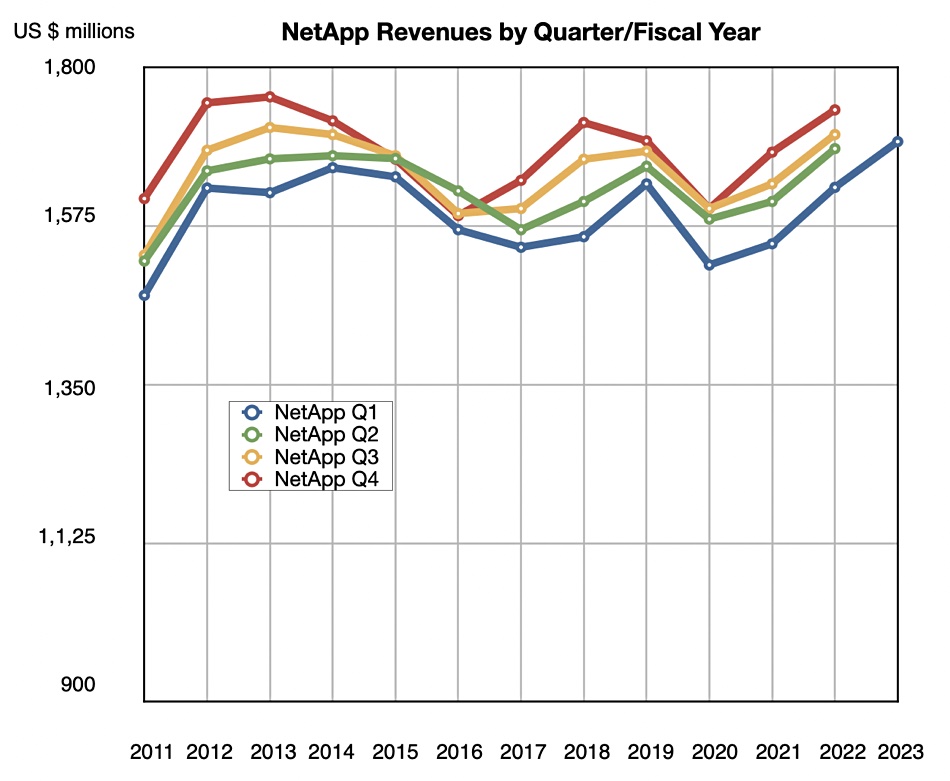
The radar screen diagram indicates a supplier’s strength on any on dimension or axis by giving it a score from 0 percent at the center out to 100 percent at the periphery. Hammerspace has plotted its view of the radar screen diagram coverage of the enterprise and cloud storage vendors, with Dell EMC (Isilon/PowerScale), NetApp, Pure Storage, Qumulo and VAST Data highlighted as example enterprise storage vendors:
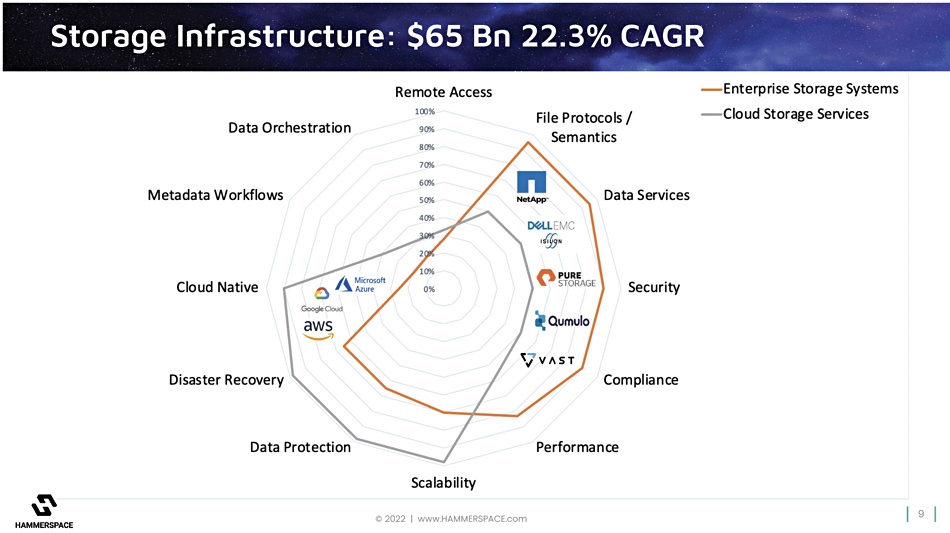
The enterprise storage suppliers (orange outline) are strongly positioned in a section of the chart from the top right round to the lower left. This area includes file protocols and semantics, data services, security, compliance and performance, and indicates they have less strong coverage in the scalability, data protection and disaster recovery areas. They have low coverage of the cloud-native, metadata workflow and remote access dimensions.
The cloud storage suppliers – AWS, Azure and Google – have strengths in the cloud-native area (unsurprisingly) and disaster recovery and scalability areas (again unsurprisingly). Hammerspace marks them down a tad in their coverage of other areas’ functionality: file semantics and protocols round to performance.
A second radar diagram looks at the data management and protection area with three groups of suppliers:
- File object gateways – CTERA, Nasuni, and Panzura are examples;
- Data Management Tools – Aspera and Komprise for example;
- Backup tools – Cohesity, Commvault and Rubrik are identified as members.
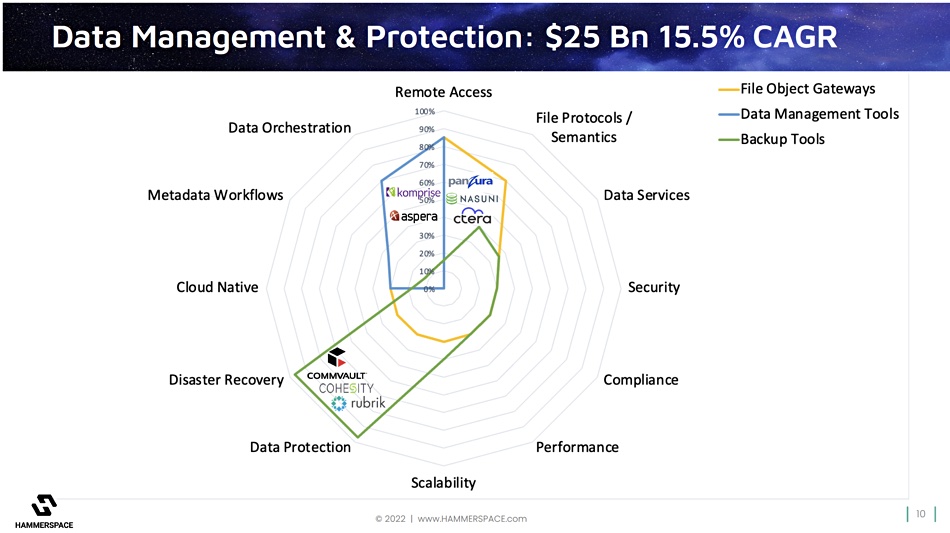
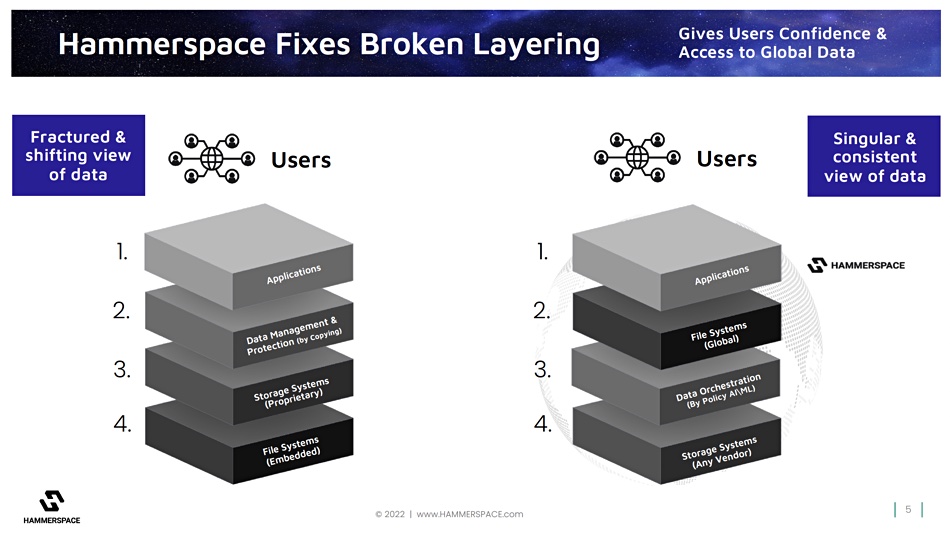
These three groups have more limited domain expertise and applicability. Hammerspace would say that, like the enterprise and cloud storage suppliers, they are all excellent at what they do. What it supplies – on top, so to speak – is additional functionality that they don’t have, because it has taken the file system layer out of the storage system layer in an application’s data access stack. We discussed its view of this in our part one story.
Here is the radar screen diagram with all five sets of vendors shown plus Hammerspace’s view of its own positioning:
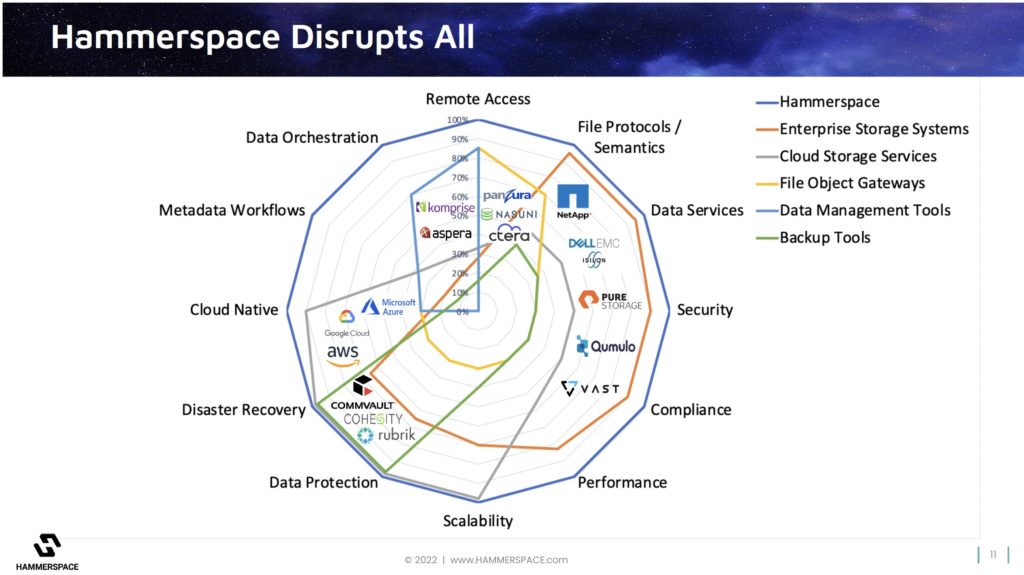
Hammerspace’s technology provides an abstraction layer of services that the other players can use. This suggests there are partnering opportunities between the other suppliers and Hammerspace. Put another way, though, this diagram suggests that customers can integrate things like data orchestration and metadata-driven workflows, provided by Hammerspace, into the other suppliers’ offerings to get a more complete file-based data services capability.
Why should they do this? Because they will find their IT operations more efficient and less expensive. We’ll discuss Hammerspace’s view of this and take a look at its business progress in the third part of this series of articles. In other words, we’ll find out if customers are responding to Hammerspace’s view of the data universe and whether operating that way is beneficial for them.
Bootnote
A Panzura spokesperson contacted us to say that they disagreed with the Hammerspace characterisation of there company. They said: “Panzura is no longer a “File object gateway”. More than three years ago, Panzura refounded and overhauled the entire company from staff to solution. It is, in fact, the exact same category “enterprise hybrid, multi-cloud data management” as Hammerspace. If you wanted to compare, it would be important to note that Hammerspace is $3 million in ARR and Panzura is 15X larger. This among other stats reflects that Panzura actually leads the enterprise hybrid, multi-cloud data management space.”
We should understand that “Since its refounding in 2020, Pazura has become the market leader in hybrid multi-cloud data management with skyrocketing rapid growth. Within three years, Panzura has achieved a record-breaking rise in annual recurring revenue of 485 percent and is growing at four times the rate of its nearest competitors. Additionally, the company has an 87 NPS score.”