


The basic idea behind Hammerspace’s technology is that the file system should sit above data orchestration and storage layers in the application data access stack and not be the bottom layer.
This leads to cross-vendor and cross-cloud data orchestration and access. Hammerspace CEO and founder David Flynn briefed us on what the ramifications of this repositioning were as well as discussing Hammerspace’s business progress and recent revenue growth. We’ll look at the filesystem layer re-positioning here, and move on to the follow-on features, and advantages, with reference to a radar diagram, and business progress in later, part 2 and part 3 articles.
Here’s a Hammerspace briefing deck slide to show David Flynn’s layering views:
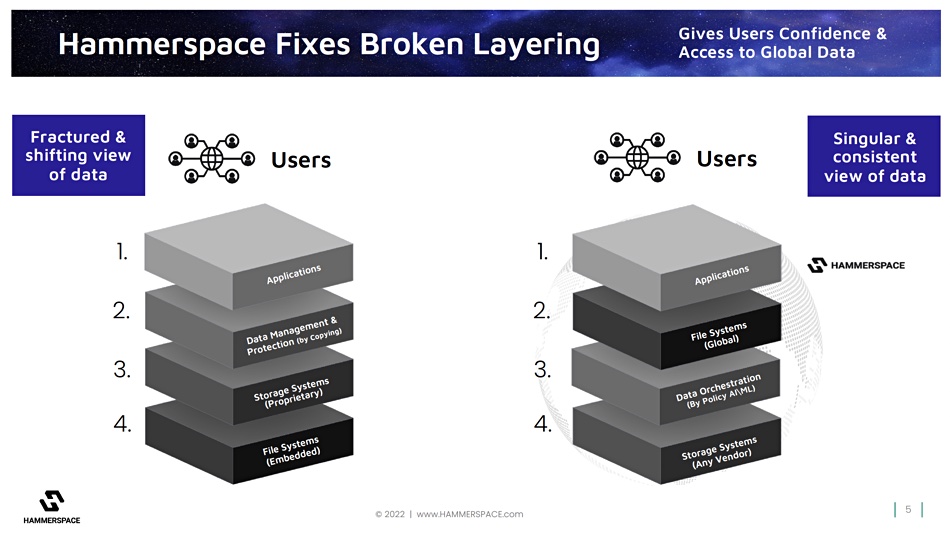
The left-hand stack is today’s stack with file systems embedded in a storage system layer with a data management and protection layer above that. These three layers sit below the application. The right-hand stack has the storage system at the bottom with the file system layer sitting directly beneath the application. The application talks to the file system layer and it then talks to the data orchestration layer, not a data management and protection layer, which, in turn, operates on the storage layer.
New layer cake

In Flynn’s view: “File systems have been embedded within the storage system or service. If I use EFS, that’s inside of Amazon and a specific region. If I use a NeTapp that’s in a specific data centre in a specific locality, and data management has always been done between these. This leads to a fractured and shifting view of data, because the act of managing data is actually creating different data, because you’re copying from one file system to another in a different thing.”
“And that leads to, I would call data schizophrenia. Where’s my data? I have no control of my data. Either I imprison it in a silo, or I manage it by copy.”
Flynn said: “Data management disappears as a separate thing and it becomes data orchestration, behind the facade of the file system.”
“What we are proposing is radical in that it’s a reordering of the very layering, that whole industries have been built around. Data management and storage infrastructure have assumed this broken ordering and layering. And so what we’re saying is, look, pull the file system out. The file system should be adjacent to the applications and the users. It should transcend any of the infrastructure, and that allows data management to disappear as a separate thing and become data orchestration behind the file system.”
This re-layering provides a single view of data: “It gives you a singular consistent view of data, data that you have minute and powerful control of, because, through the file system, you’re expressing how the data should be rendered, how it should exist across your highly decentralised and highly diverse infrastructure.”
This requires a new kind of file system.
File system development history
Flynn sees a progression of file system development over time: “Going back to the beginning, file systems have always been the heart of the problem, file system and have always been the most challenging part of the operating environment, whether it was operating systems before or cloud operating environments. The file system has been the most difficult thing.”

“DOS was named after a disk operating system, right? The old fat 16 Fat 32. And it’s what made Microsoft after they pulled that file system out of the mainframe and put it into the individual OS, and allowed a commoditization away from mainframes.
“NetApp took that file system and embedded it in an appliance. Remember, they took the file system and put it into the array. And that was the defining difference between a RAID array or a Fibre Channel, SAN, and NAS. And what made NAS so sticky is it had a file system embedded in it, which gives you a shared view of data. It improved the scope and enabled the data to be more global than it was before. And there was no going back from that.”
“We went forward with Isilon, where you now were able to scale out across multiple nodes. And so they improve the scalability. And by the way, they didn’t take market share from NetApp, they create a new market by taking it to a new scale, where where file systems had not gone before.”
The public cloud vendors wanted more scale and prioritized that over file system performance: “Along comes folks who want to build the cloud. They want a utility model of computing, they want to host multiple tenants in the hundreds and 1000s in their data centre scale mainframe. And building a file system is massively difficult. So what do they do?
“They throw out the baby with the bathwater, and they say, let’s invent super simple storage. Let’s have it do nothing but data retention, not have any performance. Accessing OSes, don’t know how to talk to it naturally, you’d have to rewrite your application. You don’t have random read and write. The OS can’t just page it in. Right. So they basically said, let’s throw out everything that’s hard and everything that’s useful out of a file system.”
He backs this up by saying Amazon’s EFS “doesn’t support Windows and doesn’t have snapshots and clones.”
He asks: “And why has NetApp and Isilon survived with the onslaught of cloud? It’s because their file system, the WAFL file system, and OneFS , they’re really the only games out there when it comes to a true enterprise grade capable file system. And the file systems in the cloud are very poor approximations of that.”
In his thinking Hammerspace’s Global Data Environment platform is what comes next: “What I’m telling you is we are the logical successor here.”
Hammerspace is: “building a file system that is now fully spanning of all infrastructure, including across whole data centres, that has never existed before. And we did that by using parallel file system architecture. And pushing open standards to have that parallel file system plumbing.”
Flyyn says: “The NFS 4.2 open source implementation came from my team; the standard, the open source, and we put windows SMB, and old NFS, v3, in. We bridge them on top. So now they get the benefit of scalability of parallel file system. But you can still serve all the legacy protocols. It’s the best of both worlds parallel file system scalability, with legacy protocol in front of it.”
He said: “In the supercomputing world, in HPC, they’ve used parallel file system architecture to scale performance. It just turns out, not surprisingly, that that same architecture lets you scale, across third party infrastructure, across data centres, and to support many, many different clients, because now you can instantiate this on behalf of each client on each customer. But it’s a new breed of file system. It’s a file system that operates by reference, instead of a file system that’s operating by being in the storage infrastructure.”
Therefore: “At the end of the day, what this means is that you have a unified, unified metadata. And you have a single consistent view of data, regardless of location, and regardless of the location, you’re using the data or the location where the data is originally housed. And through AI and machine learning, we can orchestrate data to be where you need it when you need it.”
Management
He says: “We’re in desperate need of digital automation, to automate the management of data.” And it can’t be done with old-style layering.
Flynn asserts that: “If the management is outside of the file system then, by copying between file systems, you’re fracturing the view of the data. It’s different data. You have to put the management behind the file system before you can automate it.”
In his view: “You have to fix the layering and the entire industry, these industries worth 10s of billions of dollars, have been operating under that broken assumption of management is outside of the file system.”
Once data management, as a separate upper stack layer, is replaced by a data orchestration layer below the file system, then you can automate data management; it becomes a set of orchestration functions.
Up-down flow in Hammerspace layers
Flynn says current file data sharing, between dispersed entity components in a film studio’s video production supply chain for example, work on the basis of file copying.
He says that: “What Hammerspace represents for the first time is the ability to share data by reference by having people in the same file system across different organisations. … the point is that you’re sharing data by reference within the file system instead of sharing data by copy.”
If we say the dispersed people in this data supply chain operate in the same file system namespace then that might make things clearer. The filesystem moves files to where they are needed instead of the application or users making and sending copies around this ecosystem, from silo to silo. How does Hammerspace achieve this?
It uses metadata tagging. It has an integration with Autodesk ShotGrid, the production management and review toolset for VFX, TV, movie production, animation and games teams.
Flynn said: “So ShotGrid, just by saying I want to do this rendering job over in this data centre, will label the metadata in the file system and that will cause the data to be pre-orchestrated [moved] into the other data centre, just the stuff that’s actually needed for that job.”
Here, the application, ShotGrid, gives its intent to the filesystem. It needs a file or files to be made available to to users at a distant data centre and inputs that intent as a metadata item. The file system picks this up and orchestrates the data movement from the source storage system to the destination storage system – showing the up-down interaction between the layers in Hammerspace’s re-organised application data stack. ShotGrid is not concerned with the underlying storage systems at all here.
****
Part two of this examination of Hammerspace will look at its radar positioning diagram and then we’ll have a check on its business progress in a part three.




