


AI Search-as-a-Service company Nuclia claims it can index text from virtually any source and language and then search it for words or phrases in multiple languages.
It’s a cliche that 80 percent of companies’ data is unstructured and keeps on growing. Looking for text and speech needles in this data haystack is complicated by there being myriad file formats and also multiple languages used in subsidiary operations for international business. Most international companies simply cannot catalog all the unstructured data they hold – they don’t know what they have and have no practical way of finding out. Nuclia reckons it can fix that.
The two founders, CEO Eudald Camprubí and CTO Ramon Navarro, told an IT Press Tour that their software can help companies sift through complex data, because its language model technique normalizes multi-language unstructured data and makes it searchable.

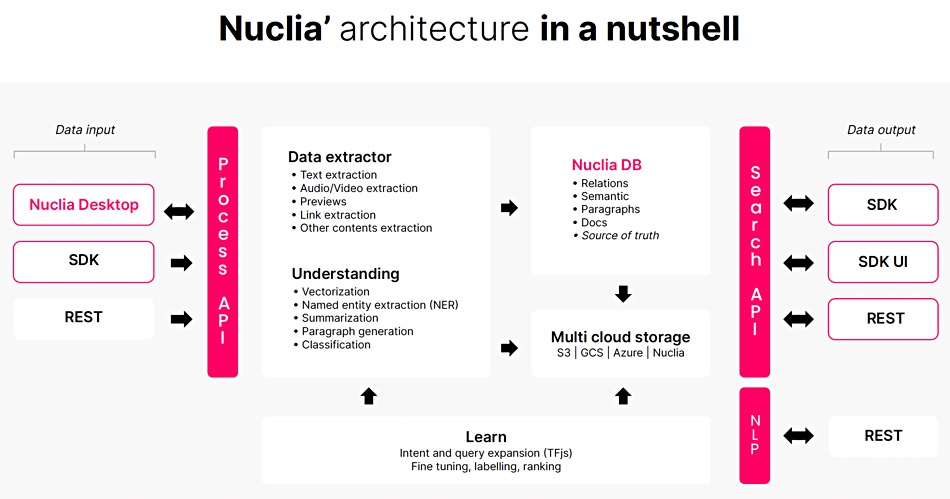
The key technology is natural language processing (NLP) and it uses language modelling to build vectors of language statements and store them in its open-source NucliaDB database. This is available in GitHub, is cloud-native and stores unstructured data and vector, text, paragraphs and relations indexing information. A vector in this sense is a set of numeric values in arbitrary dimensions – tens, hundreds or even more of them – that describe a complex data object such as a word, phrase, paragraph, object or image.
The sources from which the vectors are generated are files and objects: S3 is supported, containing text that is printed, viewed or spoken. This could be a Word document, PowerPoint slide, images which can be scanned with OCI, and audio files which can be transcribed. The text can be indexed from virtually any language which is not pictogram-based; pictograms being characters such as those found in Japanese and Chinese languages.
The index is paragraph-sensitive and search results come in multi-paragraph form, not the unparagraphed masses of text which the Otter.ai transcription service can produce.
Nuclia search is faster and broader than searching through a file:folder document structure using keywords, the company claims, as Nuclia looks into content irrespective of its format and language. A keyword search is language sensitive; a search for “Vehicle” will not return results containing the French word “voiture”, the German word “Fahrzeug“ or the Italian word “veoicolo.” A search of a Nuclia-indexed sets of PDFs, word docs, audio files and images containing text in multiple languages, will return these results.
That’s because the Nuclia search does not look for keywords but for the language models which underlie different languages and hence are common to them. When you input a search string to Nuclia it turns that into a language model and then searches for similar models in the NucliaDB repository. Searches can use sentences or paragraphs, or keywords of course.
From its point of view, files and folders are poor ways of putting a structure in place to contain and access data. It’s better to have a searchable central database indexing everything that uses text or speech. Search results point to specific text paragraphs or specific timed parts of podcasts, other audio files, or videos containing speech.
Nuclia’s software runs on the Google Cloud Platform. Applications can use it as an AI-powered search plug-in through API integration.
The company was founded in Barcelona, Spain in 2019, and picked up €5.4 million in seed funding in April from two European funds: Crane Venture Partners in the UK and Elaia in France. There are some 20 staff, mostly developers. The company earned about $100,000 in revenue this year and has commitments for next year that total $400,000 to $500,000.
Pricing is still being worked out and is influenced by the amount of source data to be indexed and the number of queries per period.
Nuclia has 20 or so customers in the healthcare, pharmaceutical, education, public administration and customer service areas. One of its customers inputs about 100,000 PDDF documents a month for indexing. This is computationally intensive; indexing a thousand of them takes about a week.
Individual users could connect their desktop drives and Dropbox folders to Nuclia and have it index them. Use cases start with basic unstructured data search and include multi-language semantic search, video and audio search, data anonymisation, GDPR compliance, data training, insight detection and customer service.
It says competing unstructured data search services include ElasticSearch and Algolia, which has a media content search and discovery feature used by customers as a recommendation engine.
Text summarization is an issue, said Camprubí: “It is not that useful today. It is difficult to define what a summary is. Do you generate text or cut-and-paste from the file?”
Nuclia’s roadmap includes a possible addition of translation services.





