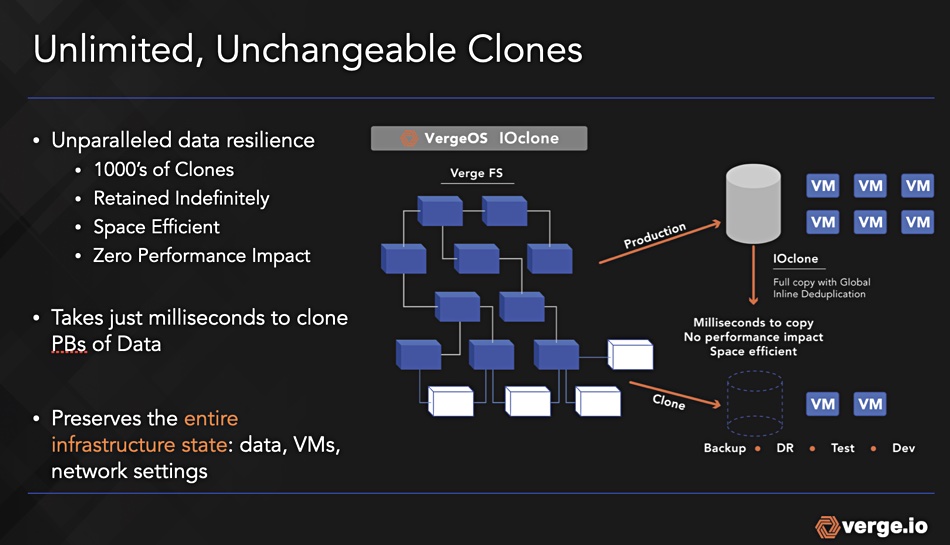
Open-source data integrator Airbyte has launched checkpointing, column selection, and schema propagation features, now available on both Airbyte Cloud and Airbyte Open Source. By creating a saved state of a data stream at regular intervals, checkpointing allows the system to resume from the most recent checkpoint in the event of a failure, avoiding data loss or redundant processing – essential for large-scale data integration tasks.
The column selection feature enables users to select specific columns from a source for replication, rather than being required to integrate the entire object or table. The schema propagation feature automatically adopts changes from the source schema to the destination schema, saving users from manually making these changes
…
Data protector Asigra has signed up with Direct 2 Channel (D2C), a North American distributor of technology for MSPs and other solution providers. Asigra is making its Tigris Data Protection cloud backup software, used by thousands of MSPs globally, available to the hundreds of channel partners in the D2C network.
…
CloudFabrix, the inventor of Robotic Data Automation Fabric (RDAF) and the “Data-centric AIOps” leader, announced the launch of Observability Data Modernization(ODM) and Composable Dashboards services for Cisco’s FSO (Full Stack Observability) platform. The FSO platform ingests, stores, and provides a unified query engine for Open Telemetry signals in a relationship-based entity model. CloudFabrix showcases the extensibility of the platform, with its patent-pending Robotic Data Automation Fabric(RDAF).
…
SaaS data protector Cobalt Iron has received a patent on its adaptive, policy-driven data cyber inspection technology. US patent 11663362, granted on May 30, introduces new policy-based approaches for effectively validating data integrity using multiple cyber inspection tools. The technology will be available as part of the company’s Compass enterprise SaaS backup platform.
…
Cloud database supplier Couchbase announced its first quarter fiscal 2024 financial results. Total revenue for the quarter was $41.0 million, an increase of 18 percent year-over-year. Subscription revenue for the quarter was $38.5 million, an increase of 21 percent year-over-year. Total ARR was $172.2 million, an increase of 23 percent year-over-year as reported and on a constant currency basis.
…
Cloud filesystem service supplier CTERA has launched a new partner program for resellers, MSP and system integrators to become trusted advisors in secure multi-cloud data management. There are three tiers: Elite, Premier and Select. More info here.
…
Ascend said it had deepened the integration of its Data Pipeline Automation platform with Databricks to further enable transparency, collaboration, and productivity. Joint customers can now take full advantage of Databricks as a cloud data compute platform in Ascend’s new second-generation remote data plane architecture, which allows users to leverage Ascend’s DataAware control plane within their Databricks lakehouse. Ascend has released a new full-featured developer tier for Databricks so that Ascend customers can take advantage of the latest Databricks capabilities.
…
Delta Lake lakehouse supplier Databricks is buying Rubicon, a startup working on building storage systems for AI. The team behind Rubicon, including founders Akhil Gupta and Sergei Tsarev, is joining Databricks. Gupta started at Google almost two decades ago, where he was responsible for the ads infrastructure, which is one of the largest scale use cases of AI on the planet to date. Tsarev cofounded Clustrix, one of the first scale-out OLTP database systems for high value, high-transaction applications. The two met at Dropbox, where they helped build, among other things, one of the world’s largest, most efficient, and secure storage systems which served trillions of files and exabytes of data.
…
Privately-held Databricks announced its it surpassed the $1 billion annual recurring revenue milestone and its sales rose by more than 60 percent in the fiscal year ended in January. Databricks data warehouse offering, Databricks SQL generated $100 million in annualized recurring revenue in April, says Bloomberg. Databricks thinks it is the fastest-growing software company in the world. An IPO lies some time ahead but there is no rush.
…
DataStax, the real-time AI company, announced a GPT-based schema translator in its Astra Streaming cloud service that uses generative AI to transfer data between systems with different data structures within an enterprise. Astra Streaming is an advanced, fully-managed messaging and event streaming service built on Apache Pulsar. It enables companies to stream real-time data at scale, delivering applications with massive throughput, low latency, and elastic scalability from any cloud, anywhere in the world. Translator automatically generates “schema mappings” when building and maintaining event streaming pipelines.
The new GPT Translator is available immediately, for no additional cost, as part of DataStax Astra. Initially, this capability connects event data in Astra Streaming to Astra DB to simplify streaming pipelines and data integration processes, with further connections to come. Learn more about how the DataStax GPT Schema Translator helps to build and maintain streaming pipelines here.
…
DDN business unit Tintri announced BlueHat Cyber, an infrastructure and managed security services provider, implemented Tintri VMstore as the backbone of its Infrastructure as a Service (IaaS) and Disaster Recovery as a Service (DRaaS) business. Tintri technology allows BlueHat Cyber to offload tadministrative storage tasks and replicate across data centres so it can focus on providing its clients with better service.
…
HPE has been busy on the ESG front and released its annual Living Progress Report for fy2022. It claims that in just two years, HPE’s operational (Scope 1 & 2) emissions decreased 21 percent from its 2020 baseline, toward a target of 70 percent in 2030. To achieve this, it surpassed its 2025 target of sourcing 50 percent renewable electricity three years ahead of schedule. Overall Scope 3 emissions remained constant year-over-year despite a 2.6 percent increase in net revenue and HPW continues to focus on decoupling the growth of its business from emissions.
…
An IBM blog says Storage Virtualize has Inline Data Corruption Detection. This uses using Shannon Entropy here to calculate an entropy level of the data streams it’s receiving – in Shannon’s terms, deriving an ‘information level’ in the data streams. We’re told the information content, also called the surprisal or self-information, of an event E is a function which increases as the probability p ( E ) of an event decreases. When p ( E ) is close to 1, the surprisal of the event is low, but if p ( E ) is close to 0, the surprisal of the event is high.
Storage Virtualize is sampling the destage streams from the cache to determine the overall Shannon Entropy nature of that stream – which may be a signal that a ransomware or other data corruption event is taking place. The information is being streamed to IBM Storage Insights where ML and end reporting/alerting can be performed. The idea is that over time it builds a data lake of signals and use ML to understand these over time, train models that can act in near real time to then alert you the end user, or more likely your SIEM.
…
IBM says that, with Storage Scale 5.1.8.0, Storage Scale Data Management Edition and Storage Scale Erasure Code Edition entitle clients to use Storage Fusion Data Cataloging Services. These provides unified metadata management and insights for heterogeneous unstructured data, on-premises and in the cloud. Storage Scale has file system level replication by using the AFM to S3 cloud object storage. The FAQ has been updated.
…
Intelligent data management cloud supplier Informatica has bought UK-based data access control supplier Privitar. The acquisition price was not revealed. Privitar has raised over $150 million in funding since founding in 2014.
…
France-based Kalray announced tape-out of Coolidge2, a new version of its 3rd generation Coolidge MPPA (Massively Parallel Processor Array) DPU processor. The Coolidge2 processor has been designed to deliver higher performance in the processing of artificial intelligence (AI) and data in general. It has one of the best ratios for performance/energy consumption/price in the inference and edge computing markets, with up to 10x the performance of its predecessor. Kalray is already working on its 4th generation DPU processor, Dolomites.
…
Kinetica, which supplies a real-time, vectorized, analytic database for time-series and spatial workloads, has expanded its partner ecosystem in the United States, Europe and Asia. It added strategic global systems integrators to its partner roster, including Expero, Riskfuel and Semantic AI. This comes after it announced record business momentum of 90 percent Annual Recurring Revenue (ARR) growth, Net Dollar Retention Rate (NDRR) of 163 percent and doubling of its customer base.
…
Kioxia America announced that its NVMe/PCIe and SAS SSDs have been successfully tested for compatibility and interoperability with the Microchip Technology’s Adaptec HBA 1200 Series, SmartHBA 2200 Series host bus adapters (HBAs) and SmartRAID 3200 Series RAID adapters.
…
Data orchestrator and manager Komprise says its software supports Pure’s new FlashBlade//E and Purity 4.1, complementing existing support for FlashBlade//S and FlashArray Files. It says Pure Storage already resells Komprise Elastic Data Migration to deliver unstructured data migrations into Pure FlashBlade and FlashArray environments. Komprise is used by Pure Storage Professional Services teams for data migrations. Customers can use Komprise to transparently tier from FlashBlade//S to FlashBlade//E and the cloud to tackle unstructured data growth while cutting cold data costs. Learn more here.
…
According to Reuters, Micron, being harassed by the Chinese state cyberspace regulator for potentially putting China’s security at risk and revented from selling product in China, has said it’s committed to China and would invest 4.3 billion yuan ($603 million) over the next few years in its chip packaging facility in the Chinese city of Xian. Perhaps this will sweeten the Chinese regulator. Around half of its sales to China-headquartered clients may be affected by the cybersecurity probe, affecting 10-15 percent of its global revenue.
…
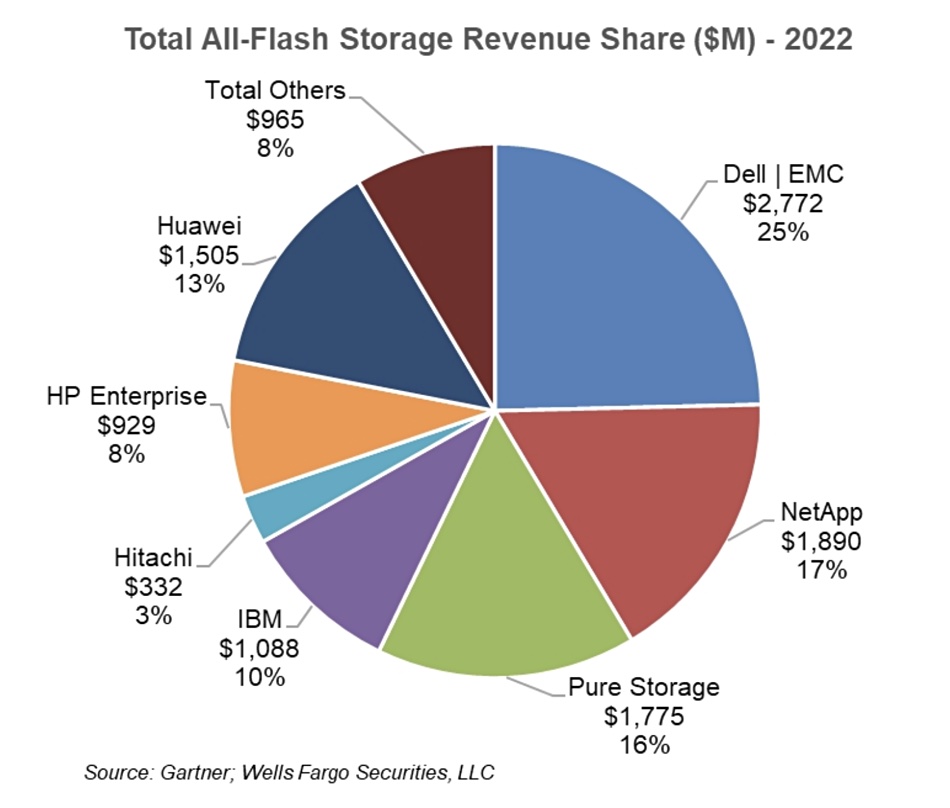
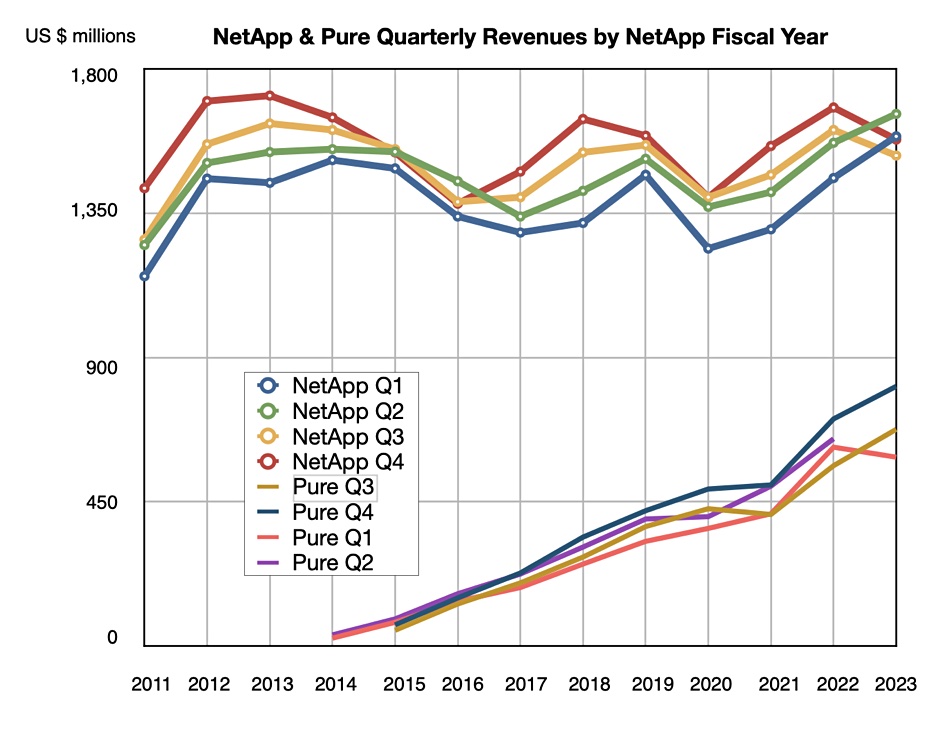
NetApp released its annual 2023 State of CloudOps report, which found that only 33% of executives are “very confident” in their ability to operate in a public cloud environment, an increase from 2022 when only 21 percent reported feeling very confident. 64 percent of IT decision makers continue to see security and compliance as the top cloud operations challenge, followed by cost management, which was cited as the top challenge by 60 percent of respondents. The biggest areas of focus for improving cloud operations continue to be cost management and security, according to 66 percent of technology executives. Spot by NetApp has offerings to help.
…
Data management supplier Nodeum announced a distribution agreement with VAD Climb Channel Solutions. Nodeum’s software automates data movement and abstracts different hybrid storage tiers: NAS, Cloud, Object & Tape Storage.
…
Oracle reported good fyQ4 results, ahead of estimates, with total fy revenue of $50.0 billion, an all-time high, up 18 percent, and Q4 revenue of $13.8 billion, up 17 percent. Q4 profit was $3.32 and fy23 profit was $8.5 billion. Cloud Revenue (IaaS plus SaaS) was $4.4 billion, up 54 percent. Cloud license and on-premise license revenues were down 15 percent. “Oracle’s Gen2 Cloud has quickly become the number 1 choice for running Generative AI workloads,” said Oracle chairman and CTO, Larry Ellison. “Why? Because Oracle has the highest performance, lowest cost GPU cluster technology in the world. NVIDIA themselves are using our clusters, including one with more than 4,000 GPUs, for their AI infrastructure.”
…
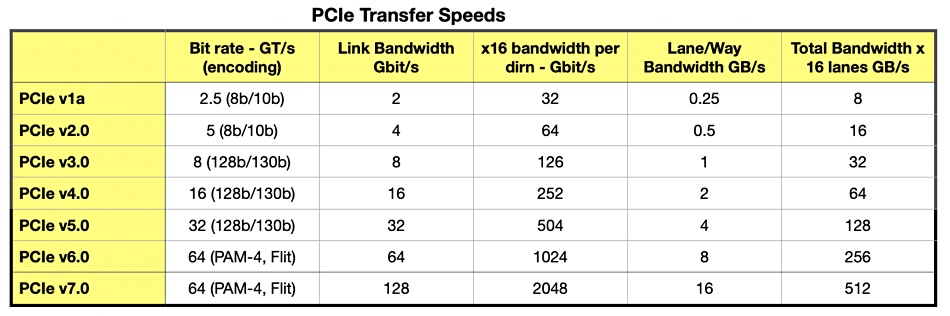
The PCI-SIG standards group, is announcing at its yearly DevCon that it will be making available the initial specification of the latest update: PCIe gen 7.0. Every version of PCIe is designed to be backwards compatible. Gen 7 has a 2x transfer rate increase over PCIe 6.0 with 128 gigatransfers per second. There is the same PAM4 signaling and FLIT mode encoding as PCIe gen 6.

…
Rubrik has appointed Andres Botero as its chief marketing officer. He comes from BlackLine, a Nasdaq-listed SaaS modern accounting supplier, where he was responsible for driving BlackLine’s strategy and global marketing. During his tenure, BlackLine more than doubled its ARR. Prior to BlackLine, Andres was the CMO of CallidusCloud (acquired by SAP) and Aria Systems. Previously, Botero held leadership roles at SAP and Siebel Systems (acquired by Oracle). He also sits on the Board of Advisors at Sendoso.
…
Seagate has released a fancy gaming disk drives: the Starfield Special Edition Game Drive and Game Hub for Xbox. The 2TB or 5TB Game Drive and 8TB Game Hub display a design that feels pulled directly from the Settled Systems of Starfield with customizable RGB LED lighting. They use USB 3.2 GEn 1. The Starfield Special Edition Game Drive for Xbox is available in capacities of 2TB ($109.99) and 5TB ($169.99) and the Seagate Starfield Special Edition Game Hub for Xbox is available in an 8TB ($239.99) capacity.

…
SSD controller supplier Silicon Motion Technology is an NXP Registered Partner. The two combine Silicon Motion’s Ferri embedded SSD tech and SM768 graphics display SoC with NXP’s offerings in automotive electronics to meet the requirements of the automotive and industrial markets.
…
Application high availability (HA) and disaster recovery (DR) supplier SIOS Technology has partnered with Zepto Consulting, which will resell SIOS DataKeeper and SIOS LifeKeeper products across Southeast Asia to help customers achieve high availability for applications, databases, and file storage both on-premises data centers and in the cloud.
…
SpectraLogic has partnered with Titan, a specialist distributor offering end-to-end data management solutions and cybersecurity services. The relationship spans the EMEA region. Titan will distribute the entire Spectra product portfolio, including object storage and NAS with the BlackPearl Platform, StorCycle enterprise software for digital archive, and the company’s full range of tape libraries to its resellers, targeting horizontal and vertical markets such as media and entertainment, life sciences, and HPC.
…
Europe backup supplier StorWare is partnering DataCore so its Backup and Recovery product can write to DataCore SWARM object storage to provide faster backup and recovery times. Storware Backup and Recovery provides a unified console for managing backup jobs, while DataCore Swarm provides a single view of data across multiple locations and storage types.
…
Storware has joined the OpenInfra Foundation as a Silver Member. It wants to play a pivotal role in advancing the success of OpenStack, the flagship open source cloud computing platform supported and sponsored by the OpenInfra Foundation.
…
Taiwan-based memory provider TEAMGROUP launched the PRO+ MicroSDXC UHS-I U3 A2 V30 Memory Card. It meets the Application Performance Class A2, UHS Speed Class 3, and Video Speed Class V30 standards and has read and write speeds of up to 160 MB/s and 110 MB/s, respectively. It’s compatible with a wide range of mobile devices and cameras, and allows consumers to experience high-definition 4K videos and photos.