Graph database and analytics player Neo4j has integrated its product within the Snowflake AI Data Cloud.
A graph database is a systematic collection of data that emphasizes the relationships between different data entities. It stores nodes and relationships instead of tables or documents.
By 2025, Gartner has estimated that graph technologies will be used in 80 percent of “data and analytics innovations”, up from 10 percent in 2021.
Neo4j says its graph data science is an analytics and machine learning (ML) solution that identifies and analyzes hidden relationships across billions of data points to improve predictions and discover new insights.
Neo4j says customers include the likes of Nasa, Comcast, Adobe, Cisco and Novartis.
Neo4j graph example
The Snowflake integration enables users to instantly execute more than 65 graph algorithms, eliminating the need to move data out of their Snowflake environment, the company says.
Neo4j’s library of graph algorithms and ML modelling enables customers to answer questions like “what’s important”, “what’s unusual”, and “what’s next,” said the provider. Customers can build knowledge graphs, which capture relationships between entities, ground LLMs (large language models) in facts, and enable LLMs to reason, infer, and retrieve relevant information more accurately and effectively, it claimed.
The algorithms can be used to identify anomalies and detect fraud, optimize supply chain routes, unify data records, improve customer service, power recommendation engines, and many other use cases.
The technology potentially allows Snowflake SQL users to get more projects into production faster, accelerate time-to-value, and generate more accurate business insights for better decision-making.
The alliance empowers users to leverage graph capabilities using the SQL programming language, environment, and tooling they already know, said the partners, removing complexity and learning curves for customers seeking insights crucial for AI/ML, predictive analytics, and GenAI applications.
Customers only pay for what they need. Users create ephemeral graph data science environments seamlessly from Snowflake SQL, enabling them to pay only for Snowflake resources utilized during the algorithms’ runtime using Snowflake credits. These temporary environments are designed to match user tasks to specific needs for more efficient resource allocation and lower cost. Graph analysis results also integrate seamlessly within Snowflake, facilitating interaction with other data warehouse tables.
Sudhir Hasbe, chief product officer at Neo4j, added: “Neo4j’s graph analytics combined with Snowflake’s unmatched scalability and performance redefines how customers extract insights from connected data, while meeting users in the SQL interfaces where they are today, for unparalleled insights and decision-making agility.”
The new capabilities are available for preview and early access, with general availability “later this year” on Snowflake Marketplace, the partners said.
Earlier this year, Snowflake reported that GenAI analysis of data in its cloud data warehouses is greatly rising.
Open source data mover Airbyte announced the launch of its Snowflake Cortex connector for Snowflake users who are interested in building generative AI (GenAI) capabilities directly within their existing Snowflake accounts. With no coding required, users can create a dedicated vector store within Snowflake (compatible with OpenAI) and load data from more than 300 sources. Users can create a new Airbyte pipeline in a few minutes. The Airbyte protocol handles incremental processing automatically, ensuring that data is always up to date without manual intervention.
…
Data analyzer Amplitude announced GA of its Snowflake native offering. This allows companies to use Amplitude’s product analytics capabilities without their data ever leaving Snowflake, making it faster and easier to understand what customers are doing, build better products, and drive growth.
…
Data protector Cohesity announced that Cohesity Data Cloud now supports AMD EPYC CPU-powered all-flash and hybrid servers from Dell, HPE, and Lenovo.
…
IDC’s “China Enterprise Solid-State Drive Market Share, 2023” report reveals that DapuStor has secured the fourth position in China’s enterprise SSD market share for 2023 (PCIe/SATA included). DapuStor serves more than 500 customers, spanning telecommunications operators, cloud computing, internet, energy and power, finance, and banking sectors, covering a range of datacenters and intelligent computing centers.
…
Lakehouse supplier Databricks announced new and expanded strategic partnerships for data sharing and collaboration with industry-leading partners, including Acxiom, Atlassian, Epsilon, HealthVerity, LiveRamp, S&P Global, Shutterstock, T-Mobile, Tableau, TetraScience, and The Trade Desk. Data sharing has become critically important in the digital economy as enterprises need to easily and securely exchange data and AI assets. Collaboration on the Databricks Data Intelligence Platform is powered by Delta Sharing, an open, flexible, and secure approach for sharing live data to any recipient across clouds, platforms, and regions.
…
AI development pipeline software supplier Dataloop announced its integration with Nvidia NIM inference microservices. Users can deploy custom NIM microservices right into a pipeline up to 100 times faster with a single click, integrating them smoothly into any AI solution and workflow. Common use cases for this integration include retrieval-augmented generation (RAG), large language model (LLM) fine-tuning, chatbots, reinforcement learning from human feedback (RLHF) workflows, and more.
…
Data mover Fivetran announced an expanded partnership with Snowflake, including Iceberg Table Support and a commitment to build Native Connectors for Snowflake. Fivetran’s support of Iceberg Tables provides Snowflake customers the ability to create a lakehouse architecture with Apache Iceberg, all within the Snowflake AI Data Cloud. Fivetran will build its connectors using Snowflake’s Snowpark Container Services and they will be publicly available in the Snowflake Marketplace.
…
Data orchestrator Hammerspace said its Global Data Platform can be used to process, store, and orchestrate data in edge compute environments and the Gryf, a suitcase-sized AI supercomputer co-designed by SourceCode and GigaIO. Gryf + Hammerspace is highly relevant for use cases such as capturing large map sets and other types of geospatial data in tactical edge environments for satellite ground stations and natural disaster response. It is an effective way to transport large amounts of data quickly.
Hammerspace says it can run on a single Gryf appliance alongside other software packages like Cyber, geospatial, and Kubernetes containerized applications, and other AI analytic packages. Its standards-based parallel file system architecture combines extreme parallel processing speed with the simplicity of NFS, making it ideal for ingesting and processing the large amounts of unstructured data generated by sensors, drones, satellites, cameras, and other devices at the edge. The full benefit of Hammerspace is unlocked when multiple Gryf appliances are deployed across a distributed edge environment so that Hammerspace can join multiple locations together into a single Global Data Platform.
…
Streaming data lake company Hydrolix has launched a Splunk connector that users can deploy to ingest data into Hydrolix while retaining query tooling in Splunk. “Splunk users love its exceptional tooling and UI. It also has a reputation for its hefty price tag, especially at scale,” said David Sztykman, vice president of product management at Hydrolix. “With the average volume of log data generated by enterprises growing by 500 percent over the past three years, many enterprises were until now faced with a dilemma: they can pay a growing portion of their cloud budget in order to retain data, or they can throw away the data along with the insights it contains. Our Splunk integration eliminates this dilemma. Users can keep their Splunk clusters and continue to use their familiar dashboards and features, while sending their most valuable log data to Hydrolix. It’s simple: ingesting data into Hydrolix and querying it in Splunk. Everybody wins.” Read more about the Hydrolix Splunk implementation and check out the docs.
…
IBM has provided updated Storage Scale 6000 performance numbers: 310 GBps read bandwidth and 155 GBps write bandwidth. It tells us that Storage Scale abstraction capabilities, powered by Active File Management (AFM), can virtualize one or more storage environments into a single namespace. This system can effectively integrate unstructured data, existing dispersed storage silos, and deliver data when and where it is needed, transparent to the workload. This common namespace spans across isolated data silos in legacy third-party data stores. It provides transparent access to all data regardless of silos with scale-out POSIX access and supports multiple data access protocols such as POSIX (IBM Storage Scale client), NFS, SMB, HDFS, and Object.
AFM also serves as a caching layer that can deliver higher performance access to data deployed as a high-performance tier on top of less performant storage tiers. AFM can connect to on-prem, cloud, and edge storage deployments. A Storage Scale file system with AFM provides a consistent cache that provides a single source of truth with no stale data copies supporting multiple use cases.
…
Enterprise cloud data management supplier Informatica announced Native SQL ELT support for Snowflake Cortex AI Functions, the launch of Enterprise Data Integrator (EDI), and Cloud Data Access Management (CDAM) for Snowflake. These new offerings on the Snowflake AI Data Cloud will enable organizations to develop GenAI applications, streamline data integration, and provide centralized, policy-based access management, simplifying data governance and ensuring control over data usage.
…
Kioxia Europe announced that its PCIe 5.0 NVMe SSDs have been successfully tested for compatibility and interoperability with Xinnor RAID software and demonstrated up to 25x higher performance in data degraded mode running PostgreSQL than software RAID solutions with the same hardware configuration. This setup is being demonstrated in the Kioxia booth at Computex Taipei.
…
Micron makes GDDR6 memory that pumps out data at 616 GBps of bandwidth to a GPU. Its GDDR7 product, sampling in this month, delivers 32 Gbps of high-performance memory, and has over 1.5 TBps of system bandwidth, which is up to 60 percent higher than GDDR6, and four independent channels to optimize workloads. GDDR7 also provides a greater than 50 percent power efficiency improvement compared to GDDR6 to improve thermals and battery life, while the new sleep mode reduces standby power by up to 70 percent.
…
Wedbush analyst Matt Bryson tells subscribers: “According to DigiTimes, Nvidia’s upcoming Rubin platform (2026) will feature gen6 HBM4, with Micron holding a competitive edge in orders into Rubin due to core features such as capacity and transmission speed (expected to be competitive with South Korean products) and US status/support. Currently, SK Hynix and Samsung are also heavily investing in HBM4.”
…
Mirantis announced a collaboration with Pure Storage, enabling customers to use Mirantis Kubernetes Engine (MKE) with Pure’s Portworx container data management platform to automate, protect, and unify modern data and applications at enterprise scale – reducing deployment time by up to 50 percent. The combination of Portworx Enterprise and MKE makes it possible for customers to deploy and manage stateful containerized applications, with the option of deploying Portworx Data Services for a fully automated database-as-a-service. MKE runs on bare metal and on-premises private clouds, as well as AWS, Azure, and Google public clouds. With the Portworx integration, containerized applications can be migrated between different MKE clusters, or between different infrastructure providers and the data storage can also move without compromising integrity.
…
MSP data protector N-able has expanded Cove Data Protection disaster recovery flexibility by introducing Standby Image to VMware ESXi. The Standby Image recovery feature also includes support for Hyper-V and Microsoft Azure, providing MSPs and IT professionals with better Disaster Recovery as a Service (DRaaS) for their end users. Standby Image is Cove’s virtualized backup and disaster recovery (BDR) capability. It works by automatically creating, storing, and maintaining an up-to-date copy of protected data and system state in a bootable virtual machine format with each backup. These images can be stored in Hyper-V, Microsoft Azure, and now also in VMware ESXi.
…
AI storage supplier PEAK:AIO has launched PEAK:ARCHIVE, a 1.4 PB per 2U all-Solidigm QLC flash, AI storage, archive, and compliance offering, with plans to double capacity in 2025. It integrates with the PEAK:AIO Data Server with automated archive, eliminating the need for additional backup servers or software. The administrator, at the click of a button, can present immutable archived data for review and instant readability without any need to restore. Learn more here.
…
William Blair analyst Jason Ader talked to Pure Storage CTO Rob Lee and tells subscribers Lee “highlighted the company’s opportunity to replace mainstream disk storage across hyperscaler datacenters, noting that it has moved into the co-design/co-engineering phase of discussions. … management spoke to three primary factors that have tipped its discussions with the largest hyperscalers, including the company’s ability to reduce TCO (power, space, cooling, and maintenance) thanks to its higher-performance AFAs, improve the reliability and longevity of hyperscalers’ storage, and decrease power consumption within data centers as power constraints become more evident in the face of AI-related activity and GPU cluster buildouts. Given these technical advantages, Pure confirmed that it still expects a hyperscaler design win by the end of this fiscal year.”
…
Seagate announced the expansion of Lyve Cloud S3-compatible object storage as a service with a second datacenter in London. It will support growing local customer needs allowing easy access to Lyve Cloud and a portfolio of edge-to-cloud solutions, including secure mass data transfer and cloud import services. Seagate has also broadened its UK Lyve Cloud channel. This is through a new distribution agreement with Climb Channel Solutions as well as a long-term collaboration with Exertis, offering a full range of advanced cloud and on-prem storage offerings.
…
SnapLogic announced new connectivity and support for Snowflake vector data types, Snowflake Cortex, and Streamlit to help companies modernize their businesses and accelerate the creation of GenAI applications. Customers can leverage SnapLogic’s ability to integrate business critical information into Snowflake’s high-performance cloud-based data warehouse to build and deploy large language model (LLM) applications at scale in hours instead of days.
…
Justin Borgman, co-founder and CEO at Starburst, tells us: “As the dust starts to settle around the Tabular and Databricks news, a lot of us are left wondering what this means for the future of Apache Iceberg. As someone who has been a part of the data ecosystem for two decades, I think it is important to remember three things:
Iceberg is a community-driven project. Top committers span from a range of companies including Apple, AWS, Alibaba and Netflix. This is in stark contrast to Delta Lake, which is effectively an open sourced Databricks project. Iceberg is not Tabular, and Tabular is not Iceberg.
The next race will be won at the engine-layer. We see Trino – and Icehouse –as the winner. Iceberg was built at Netflix to be queried by Trino. The largest organizations in the world use Trino and Iceberg together as the bedrock for analytics. There’s a reason some of the biggest Iceberg users like Netflix, Pinterest, and Apple all talked about the Trino Icehouse at the Apache Iceberg Summit just three weeks ago.
It will take time. Moving from legacy formats to Apache Iceberg is not an overnight switch and has the potential to become as much of a pipe dream as ‘data centralization’ has been. The community needs platforms that will support their entire data architecture, not just a singular format. We originally founded Starburst 7 years ago to serve this mission when the battle was between Hadoop and Teradata, and the challenges are just as real today.”
…
Enterprise data manager Syniti announced that Caldic, a global distribution solutions provider for the life and material science markets, will use Syniti’s Knowledge Platform (SKP) to help improve its data quality and build a global master data management (MDM) platform for active data governance. This will allow Caldic to work with clean data, now and in the future.
…
Synology announced new ActiveProtect appliances, a purpose-built data protection lineup that combines centralized management with a scalable architecture. ActiveProtect centralizes organization-wide data protection policies, tasks, and appliances to offer a unified management and control plane. Comprehensive coverage for endpoints, servers, hypervisors, storage systems, databases, and Microsoft 365 and Google Workspace services dramatically reduce IT blind spots and the necessity of operating multiple data protection solutions. IT teams can quickly deploy ActiveProtect appliances in minutes and create comprehensive data protection plans via global policies using a centralized console. Each ActiveProtect appliance can operate in standalone or cluster-managed modes. Storage capacity can be tiered with Synology NAS/SAN storage solutions, C2 Object Storage, and other ActiveProtect appliances in the cluster. The appliances leverage incremental backups with source-side, global, and cross-site deduplication to ensure fast backups and replication with minimal bandwidth usage. ActiveProtect will be available through Synology distributors and partners later in 2024. Check it out here.
Synology ActiveProtect appliances
…
Veeam announced the introduction of Lenovo TruScale Backup with Veeam, a cloud-like experience on-premises that helps secure workloads regardless of their location and enables customers to scale infrastructure up or down as needed. TruScale Backup with Veeam combines Lenovo ThinkSystem servers and storage, Veeam Backup & Replication, Veeam ONE, and Lenovo TruScale services to provide data protection as a service for a hassle-free on-premises or co-located deployment. TruScale Backup with Veeam is available now.
…
Veeam announced its Backup & Replication product will be available on Linux and could be available in the first half of 2025.
…
Archival software supplier Versity announced the GA release of Versity S3 Gateway, an open source S3 translation tool for inline translation between AWS S3 object commands and file-based storage systems. Download a white paper about it here.
…
Re new Western DigitalSSDs and HDD, Wedbush analyst Matt Bryson says: “We have validated that WDC is working with FADU on some new SSD products and would not be surprised if that controller vendor is supporting one or both of the new SSDs. … On the HDD front, we expect the new drives will likely include an 11th platter. We believe WDC has a near- to intermediate- term advantage around areal density (as STX works through the go-to production problems with HAMR that have led management to suggest an initial hyperscale qualification might have to wait until CQ3).”
Storage and backup cloud provider Backblaze has taken the wraps off Backblaze B2 Live Read, giving customers the ability to access, edit, and transform content while it’s still being uploaded into its B2 Cloud Storage.
The service is particularly useful for media production teams working on live events, and promises “significantly faster and more efficient workflows,” and the ability to offer new monetized content quicker.
The patent-pending technology has already been adopted by media and entertainment (M&E) production solution providers, including Telestream, Glookast, and Mimir, who are integrating the service into their production environments.
“For our customers, turnaround time is essential, and Live Read promises to speed up workflows and operations for producers across the industry,” said Richard Andes, VP, product management at Telestream. “We will offer this innovative feature to boost performance and accelerate our customers’ business engagements.”
The technology can be used to create “near real-time” highlight clips for broadcasters’ news segments and sports teams’ in app replays, and can be used to promote content for on-demand sales “within minutes” of presentations at live events. On-set staff requirements can also potentially be reduced through the offering too, said Backblaze.
Live Read supports accessing parts of each growing object or growing file as it uploads, so there’s no need to wait for the full file upload to complete. This is a “major” workflow accelerator, especially when organizations are shooting for 4K to 8K resolutions and beyond, Backblaze says. When the full upload is complete, it’s accessible to customers like any other file or object in their Backblaze B2 Cloud Storage bucket, with no middleware or proprietary software needed.
“Backblaze’s Live Read is a game changer for helping organizations deliver media to their audiences dramatically faster,” said Steinar Søreide, CTO at Mimir. “Adding this offering to our platform unlocks a whole new level of impact for our user community.”
Beyond media, the Live Read API supports other demanding IT workloads. For instance, organizations maintaining large data logs or surveillance footage backups have often had to parse them into hundreds or thousands of small files each day, in order to have quick access when needed. With Live Read, said Backblaze, they can now move to far more manageable single files per day or hour, while preserving the ability to access parts “within seconds” of them having been written.
Gleb Budman
“Live Read is another example of the powerful innovation we’re delivering to support our customers and partners to do more with their data,” said Gleb Budman, Backblaze CEO.
Live Read is available in private preview now, with general availability planned “later this year”, said Backblaze
Earlier this year, Backblaze added Event Notification data change alerts to its cloud storage, so that events can be dealt with faster by triggering automated workflows.
For the year ended December 31, 2023, Backblaze revenues were $102 million, 20 percent higher than the previous year. It reported $58.9 million net loss, down from the $71.7 million net loss in 2022.
Pure Storage has taken a stake in visual AI provider LandingAI. The flash storage specialist says the investment in LandingAI’s multi-modal Large Vision Model (LVM) solutions will “help shape the future” of vision AI for the enterprise customers it serves.
Pure Storage reckons the move will reinforce its AI strategy to help customers with their training environments, enterprise inference engine or RAG environments, and upgrade all enterprise storage to enable “easier data access for AI.”
Andrew Ng
LandingAI was founded by CEO Andrew Ng in 2017 and has raised $57 million. He was co-founder of online course provider Coursera, and was founding lead of Google Brain. The Google Brain project developed massive-scale deep learning algorithms. Ng was also previously chief scientist at Chinese search engine Baidu.
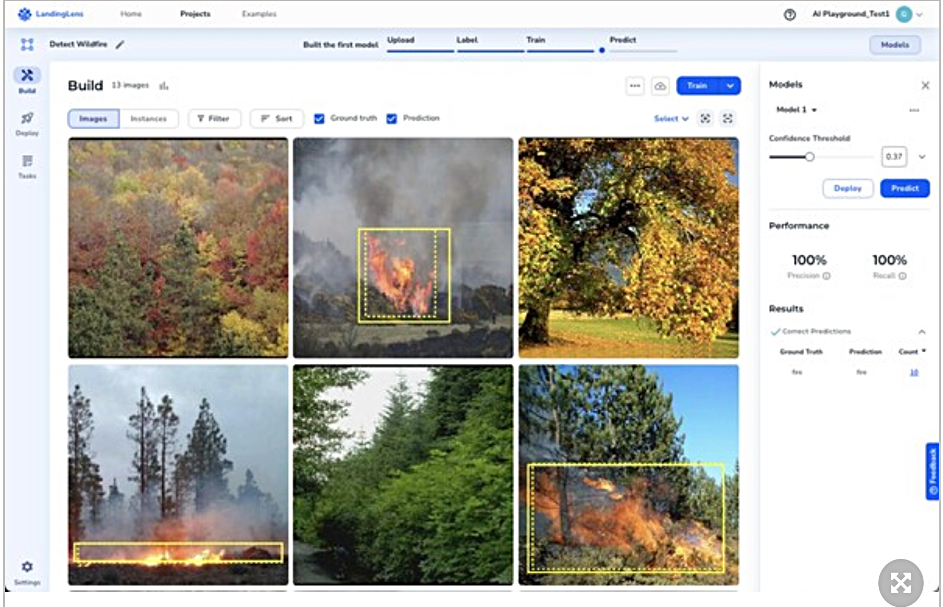
LandingAI’s flagship product, LandingLens, is a computer vision cloud platform designed to enable users to build, iterate, and deploy computer vision solutions “quickly and easily.”
With data quality key to the success of production AI systems, LandingLens promises users “optimal data accuracy and consistency.”
LandingAI bills itself as a “pioneer” in the field of domain-specific LVMs, which enhance the ability to process and understand visual data at scale. This makes sophisticated visual AI tools more accessible and efficient, we’re told.
LandingLens computer vision project. We could envisage a visual LLM being trained to detect forest fires using a stream of forest images from video cameras located in and around a forest
“Enterprises will need solutions to apply generative AI to their data, which will increasingly consist of not just text, but richer image and video data as well,” said Ng. “We are partnering with Pure Storage to meet this customer need.”
Rob Lee
Rob Lee, CTO at Pure Storage, added: “Our strategic partnership with the LandingAI team, including its pioneering leaders Andrew Ng and Dan Maloney, will lead to significant AI/ML advancements for our customers.”
The value of Pure’s LandingAI investment has not been publicly disclosed. Existing investors in LandingAI include Intel, Samsung, Insight Partners, and McRock Capital among others.
Last week, Pure reported an improved first quarter. Sales increased 20 percent year-on-year to $693.5 million for the period ended May 5. The quarterly loss was $35 million, an improvement on the $67.4 million lost a year ago.
Western Digital has defined a six-stage AI data cycle and introduced two new SSDs and a disk drive to match them.
Update. SN861 Flexible Data Placement (FDP) section added. 2 July 2024
The AI data cycle stages are (1) archives of raw data content, (2) data prep and ingest, (3) AI model training, (4) interface and prompting, (5) AI inference engine, and (6) new content generation. Stage 1 needs high-capacity disk drives. Stage 2 needs high-capacity SSDs for data lake operations. Stages 3, 4, and 5 need the same high-capacity SSDs plus high-performance compute SSDs for model training run checkpointing and caching. Stage 6 brings us back to needing high-capacity disk drives.
Rob Soderbery
Rob Soderbery, EVP and GM of Western Digital’s Flash Business Unit, said: “Data is the fuel of AI. As AI technologies become embedded across virtually every industry sector, storage has become an increasingly important and dynamic component of the AI technology stack. The new AI Data Cycle framework will equip our customers to build a storage infrastructure that impacts the performance, scalability, and the deployment of AI applications.”
Western Digital is introducing three new Ultrastar-brand storage drives:
DC SN861 SSD for fast checkpointing and caching
DC SN655 SSD for the high-capacity SSD requirement
DC HC690 HDD for the storage of raw and new content data
DC SN861 SSD
This is Western Digital’s first PCIe gen 5 SSD and suited for AI training model run checkpointing. It introduced its PCIe gen 4 SN850 drive back in 2020, but this was an M.2-format drive with limited capacity: 500 GB, 1 and 2 TB. It also had an SN840 PCIe gen 3 drive in the U.2 (2.5-inch) format with 1.6 TB to 15.36 TB capacity range in 2020.
The SN861 comes in the E1.S, E3.S, and U.2 formats with up to 16 TB capacity. E1.S is like a larger version of the M.2 gumstick format. Western Digital claims the SN861 “delivers up to 3x random read performance increase versus the previous generation with ultra-low latency and incredible responsiveness for large language model (LLM) training, inferencing and AI service deployment.”
Details are slim. We don’t know the type of NAND used, but understand it to be TLC. Nor do we know the 3D NAND generation and layer count. It’s probably BiCS 6 with 162 layers but could be the newer BiCS 8 with 218 layers.
It will come in 1 and 3 drive writes per day (DWPD) variants with a five-year warranty, and supports NVMe 2.0 and OCP 2.0. The E1.S version is sampling now. The U.2 model will be sampling in July with volume shipments set for the third quarter. There is no information about the E3.S version’s availability or the E1.S volume shipment date.
WD says the Ultrastar DC SN861 E1.S version supports Flexible Data Placement (FDP). This “allows the placement of different data in separate NAND blocks within an SSD. In a conventional SSD all data written to the drive at a similar time will be stored in the same NAND blocks. When any of that data is either invalidated by a new write or unmapped then the flash translation layer (FTL) needs to do garbage collection (GC) in order to recover physical space. In a data placement SSD data can be separated during host writes allowing for whole NAND blocks to be invalidated or unmapped at once by the host.”
DC SN655 SSD
This is a high-capacity SSD. The existing PCIe gen 4-connected DC SN655 SSD with its 15.36 TB max capacity has been expanded more than fourfold to support up to 64 TB using TLC NAND in a U.3 format. The U.3 format is equivalent to U.2 in physical size and a U.3 chassis bay supports SAS, SATA, and NVMe interfaces in the same slot.
SN655 variants are sampling now and volume shipments will start later this year, with more drive details being released then.
DC HC690 disk drive
Western Digital has tweaked its DC HC680 SMR tech to lift its capacity from 28 to 32 TB. There are few details available at present and our understanding is that this is a ten-platter drive – it might be 11 – using shingled magnetic media (SMR – partially overlapping write tracks) with OptiNAND energy-assisted PMR (ePMR), and triple-stage actuator (TSA) in a helium-filled enclosure. There is an ArmorCache write cache data safety feature.
Competitor Seagate announced 30 TB conventional Exos HAMR drives in January with a 32 TB SMR HAMR drive now available as well. Western Digital has caught up to that capacity point using microwave-assisted magnetic recording (MAMR). Toshiba demonstrated a 32 TB shingled HAMR drive and a 31 TB 11-platter MAMR drive last month. Now all three HDD manufacturers are at the 32 TB SMR drive level.
SPONSORED FEATURE: It’s easy to see why running enterprise applications in the cloud seems like a no-brainer for chief information officers (CIOs) and other C-suite executives.
Apart from the prospect of unlimited resources and platforms with predictable costs, cloud providers offer managed services for key infrastructure and applications that promise to make the lives of specific tech teams much, much easier.
When it comes to databases, for example, the burden and costs involved in deploying or creating database copies and in performing other day-to-day tasks just melt away. The organization is always working with the most up-to-date version of its chosen applications. Cloud providers may offer a variety of nontraditional database services, such as in-memory, document, or time-series options, which can help the organization squeeze the maximum value out of its data. That’s the headline version anyway.
Database administrators (DBAs) know that the reality of running a complex database infrastructure in the cloud and maintaining and evolving it into the future isn’t so straightforward.
Consider how an enterprise’s database stack will have evolved over many years, even decades, whether on-premises or in the cloud. DBAs will have carefully curated and tailored both the software and the underlying hardware, whether regionally or globally, to deliver the optimal balance of performance, cost, and resilience.
That painstaking approach to hardware doesn’t encompass only compute. It applies just as much to storage and networking infrastructure. International Data Corporation (IDC) research shows that organizations spent $6.4 billion on compute and storage infrastructure to support structured databases and data management workloads in the first half of 2023 alone, constituting the biggest single slice of enterprise information technology (IT) infrastructure spending.
As for the database itself, it’s not just a question of using the latest and greatest version of a given package. DBAs know it’s a question of using the right version for their organization’s needs, in terms of both cost and performance.
That’s why DBAs may worry that a managed service won’t offer this degree of control. It might not support the specific license or version that a company may want to put at the heart of its stack. Moreover, some DBAs might think that the underlying infrastructure powering a cloud provider’s managed database is a black box, with little or no opportunity to tune the configuration for optimal performance with their preferred software.
Many database teams – whether they’re scaling up an existing cloud database project or migrating off-prem – might decide the best option is a self-managed database running on a platform like Amazon Web Services (AWS). This gives them the option to use their preferred database version and their existing licenses. It also means they can replicate their existing infrastructure, up to a point at least, and evolve it at their own pace. All while still benefiting from the breadth of other resources that a provider like AWS can put at their disposal, including storage services like Amazon FSx for NetApp ONTAP.
Costs and control
Though the self-managed approach offers far more flexibility than a managed service, it also presents its own challenges.
As NetApp Product Evangelist, Semion Mazor explains, performance depends on many factors: “It’s storage itself, the compute instances, the networking and bandwidth throughput, or of all that together. So, this is the first challenge.” To ensure low latency from the database to the application, DBAs must consider all these factors.
DBAs still need to consider resilience and security issues in the cloud. Potential threats range from physical failures of individual components or services to an entire Region going down, plus the constant threat of cyberattacks. DBAs always focus on making sure data remains accessible so that the database is running, which means the business’ applications are running.
These challenges are complicated and are multiplied by the sheer number of environments DBAs need to account for. Production is a given, but development teams might also need discrete environments for quality assurance (QA), testing, script production, and more. Creating and maintaining those environments are complex tasks in themselves, and they all need data.
Other considerations include the cost and time investment in replicating a full set of data and the cost of the underlying instances that are powering the workloads, not to mention the cost of the storage itself.
That’s where Amazon FSx for NetApp ONTAP comes in. FSx for ONTAP is an expert storage service for many workloads on AWS. It enables DBAs to meet the performance, resilience, and accessibility needs of business-critical workloads, with a comprehensive and flexible set of storage features.
As Mazor explains, it uses the same underlying technology that has been developed over 30 years, which underpins the on-prem NetApp products and services used in the largest enterprises in the world.
The data reduction capabilities in FSx for ONTAP can deliver storage savings of 65 to 70 percent, according to AWS. Mazor says that even if DBAs can’t quite achieve this scale of compression, scaled up over the vast number of environments many enterprises need to run, the benefit becomes huge.
Another crucial feature is the NetApp ONTAP Snapshot capability, which allows the creation of point-in-time, read-only copies of volumes that consume minimal physical storage. Thin provisioning, meanwhile, allocates storage dynamically, further increasing the efficient use of storage – and potentially reducing the amount of storage that organizations must pay for.
Clones and cores
One of the biggest benefits, says Mazor, comes from the thin cloning capability of NetApp ONTAP technology. Mazor says that it gives DBAs the option to “create new database environments and refresh the database instantly with near zero cost.” These copies are fully writable, Mazor explains, meaning that the clone “acts as the full data, so you can do everything with it.”
This capability saves time in spinning up new development environments, which in turn speeds up deployment and cuts time to market. Mazor notes that, from a data point of view, “Those thin clone environments require almost zero capacity, which means almost no additional costs.”
Moving these technologies to the storage layer, rather than to the database layer, contributes to more efficient disaster recovery and backup capabilities. Amazon FSx for NetApp ONTAP also provides built-in cross-region replication and synchronization, giving DBAs another way to meet strict recovery time objective (RTO) and recovery point objective (RPO) targets.
These data reduction, snapshot creation, thin provisioning, thin cloning, and cross-region replication and synchronization features all help DBAs to decouple storage – and, crucially, storage costs – from the Amazon Elastic Compute Cloud (EC2) instances needed to run database workloads. So, storage can be scaled up or down independently of the central processing unit (CPU) capacity required for a given workload.
With fewer compute cores needed, costs and performance can be managed in a much more fine-grained way. DBAs can reduce the need for additional database licenses by optimizing the number of cores required for database workloads and environments. Of course, going the self-managed route means that enterprises can use their existing licenses.
This comprehensive set of capabilities means DBAs can more accurately match their cloud database infrastructure to real workload needs. It also means the cost of running databases in AWS can be further controlled and optimized. It can all add up to a significant reduction in total storage costs, with some customers already seeing savings of 50 percent, according to AWS.
The decision to operate in the cloud is usually a strategic, C-level one. But DBAs can take command of their off-premises database infrastructure and gain maximum control over its configuration, cost, and performance by using Amazon FSx for NetApp ONTAP.
Mature startup lakehouse supplier Databricks, with north of $4 billion in total funding, has reportedly spent a billion dollars or more on buying Tabular.
Databricks supplies an object-based lakehouse data repository combining a data warehouse and a data lake. It created its open source Delta Lake format, donated to the Linux Foundation, to enable high performance lakehouse content querying through Apache Spark with ACID (Atomicity, Consistency, Isolation, Durability) transactions, and data ingest (batch or streaming). It is a fast-growing business and faces competition from the competing, and also open source, Iceberg table format.
The Wall Street Journal reports that Databricks is spending between $1 billion and $2 billion to buy Tabular. This will be an amazing financial return for Tabular’s founders, VC investors and other stockholders.
Ali Ghodsi.
Ali Ghodsi, Co-founder and CEO at Databricks, said in a statement: “Databricks pioneered the lakehouse and over the past four years, the world has embraced the lakehouse architecture, combining the best of data warehouses and data lakes to help customers decrease TCO, embrace openness, and deliver on AI projects faster. Unfortunately, the lakehouse paradigm has been split between the two most popular formats: Delta Lake and Iceberg.”
He added: “Last year, we announced Delta Lake UniForm to bring interoperability to these two formats, and we’re thrilled to bring together the foremost leaders in open data lakehouse formats to make UniForm the best way to unify your data for every workload.
Tabular was founded in 2021 by ex-Netflix people Daniel Weeks, Jason Reid, and Ryan Blue. Weeks and Blue were the original co-creators of the Apache Iceberg project when working at Netflix. Blue also serves as the Iceberg PMC Chair and Weeks is an Iceberg PMC member.
Iceberg format tables enable SQL querying of data lake contents. Spark, Trino, Flink, Presto, Hive, Impala, StarRocks, and other query engines can work on the tables simultaneously. Tabular has developed a data management software layer based on Iceberg tables. It has raised a total of $37 million in two rounds, the latest for $26 million in September last year.
Ryan Blue
Delta Lake has over 500 code contributors, and over 10,000 companies globally use Delta Lake to process 4+ exabytes of data on average each day. But Iceberg has not been dominated by Delta Lake, having many users as well. Iceberg and Delta Lake are now the two leading open-source lakehouse formats, both being based on Apache Parquet (open-source, column-oriented data storage format).
Ryan Blue, Co-Founder and CEO at Tabular, said: “It’s been amazing to see both Iceberg and Delta Lake grow massively in popularity, largely fueled by the open lakehouse becoming the industry standard.”
In 2023 Databricks introduced Delta Lake UniForm tables to provide interoperability across Delta Lake, Iceberg, and Hudi (Hadoop Upserts Deletes and Incrementals). The latter being a third open-source framework for building transactional data lakes with processes for ingesting, managing, and querying large volumes of data. Delta Lake UniForm supports the Iceberg restful catalog interface so customers can use the analytics engines and tools they are already familiar with, across all their data.
Vinoth Chandar, creator and PMC chair of the Apache Hudi project, and Onehouse founder and CEO, told us: “Users need open data architectures that give them control of their data to power all their use cases from AI to real-time analytics. We’re excited to see the increased investment in open data lakehouse projects, and this Databricks announcement may bring increased compatibility between Delta Lake and Iceberg. However, users demand more – they need a completely open architecture across table formats, data services, and data catalogs, which requires more interoperability across the stack.”
Delta Lake UniForm is only a partway step to full Iceberg-Delta Lake unification. The Tabular acquisition opens the door to that goal. Databricks says that, by bringing together the original creators of Apache Iceberg and Delta Lake, it can provide data compatibility so that customers are no longer limited by having to choose one of the formats.
Databricks (with Tabular) will work closely with the Delta Lake and Iceberg communities to develop lakehouse format compatibility. In the short term this will be provided inside Delta Lake UniForm and in the long term, it will help develop a single, open, and common standard of interoperability foir an open lakehouse.
Blue said: “With Tabular joining Databricks, we intend to build the best data management platform based on open lakehouse formats so that companies don’t have to worry about picking the ‘right’ format or getting locked into proprietary data formats.”
The huge elephant in the room here is getting unstructured data available to Gen AI’s large language models, both for training, with massive data sets being needed, and also inference. That has led to Databricks being willing to spend such a huge amount of its VC-invested cash to buy Tabular at such a high price. It will enable it to compete with more intensity against major player Snowflake.
Snowflake has just announced Polaris Catalog, a vendor-neutral, open catalog implementation for Apache Iceberg. Thus will be open-sourced and it will provide interoperability with AWS, Confluent, Dremio, Google Cloud, Microsoft Azure, Salesforce, and more.
The Tabular acquisition should close by the end of July, subject to closing conditions, and the bulk of Tabular’s 40 employees will join Databricks.
Backup and recovery provider Veeam is now providing its own Veeam Data Cloud Vault, using the Azure public cloud and offering all-in-one per TB pricing inclusive of API calls, restore and egress charges.
The Veeam Vault storage-as-a-service (STaaS) offering is integrated into Veeam’s Backup and Recover product and provides fully managed, pre-configured, immutable, encrypted and logically air-gapped storage. It complements Veeam’s various backup targets such as ExaGrid, ObjectFirst, PowerProtect, Scality and other on-premises appliance providers.
Anand Eswaran
Veeam CEO Anand Eswaran said in a statement: “Eighty-five percent of organizations that suffered a cyber-attack last year are now using cloud storage that offers immutability, according to the Veeam Ransomware Trends Report 2024. Storing a backup of your data offsite is an essential part of any backup strategy and it’s critical to rapid, clean recovery from an outage or a cyber-attack.”
Veeam Vault is based on the Azure Blob Hot LRS tier with immediate data access. The company suggests it’s used as part of a 3-2-1-1-0 backup strategy, meaning:
There should be at least 3 copies of your data, including the production copy.
At least 2 different storage media should be used; eg, tape, disk and/or cloud storage.
At least 1 of the copies should be kept off-site.
At least 1 copy should be kept offline or, if in the public cloud, be immutable.
Backups should have completed with 0 errors.
Veeam says it will add two more features to Veeam Vault this year. First it will add “colder and archive-class object storage tiers, particularly for older and/or secondary backups where slower restore performance is an acceptable trade-off for lower cost long-term retention.”
Secondly it will be “centrally managing and monitoring all aspects of Veeam Vault through tighter integration with the single UI of Veeam Data Platform.”
So Veeam is now a white label OEM for Azure cloud storage. It has a public cloud backup repository that can be used for its SaaS app protection services such as ones for Microsoft 365, Salesforce and Teams, and also possibly by Alcion, the SaaS app backup startup it’s part-funding. Existing public cloud Veeam backup targets Backblaze and Wasabi may not be best pleased by this development.
Veeam Data Cloud Vault is available now via the Azure Marketplace for a single fee per TB/month based on region: America: $60, EMEA: $74, APJ: $62, LATAM: $85 – and includes storage, write/read APIs, and egress. There’s more here.
After last quarter’s 14 percent Y/Y revenue drop, HPE reported a three percent increase in its latest quarter, driven by AI system sales, and outperforming last quarter’s outlook by some measure. It raised its full year revenue expectations as a result.
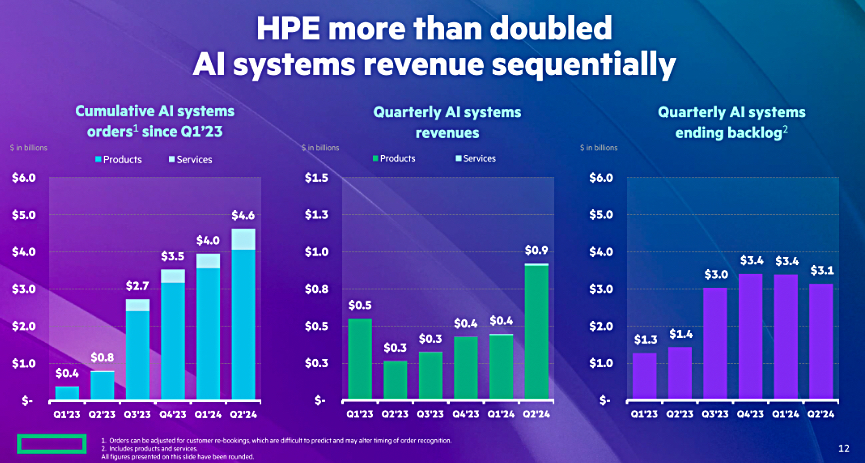
Revenues of $7.2 billion were well north of last quarter’s 6.8 billion outlook, although its profits were down to $314 million, 24.9 percent lower that the year-ago profit. The server business unit brought in $3.87 billion, up 18 percent on the year. It grew orders for trad servers both Q/Q and Y/Y and AI server revenues grew as well. In fact AI systems revenue of $900 million+ more than doubled Q/Q.
The Intelligent Edge business unit was down 19 percent annually to $1.1 billion with Hybrid Cloud bringing in $1.26 billion, down 8 percent. Although corporate investments and other earned $252 million, up 8 percent, and Financial Services $867 million, up 1 percent, the numbers were too small to swing HPE’s financial needle significantly.
Antonio Neri
President and CEO Antonio Neri’s statement said: “HPE delivered very solid results in Q2, exceeding revenue and non-GAAP EPS guidance. AI systems revenue more than doubled from the prior quarter, driven by our strong order book and better conversion from our supply chain.”
Financial summary
Gross margin: 33.0 percent, down three percent year-over-year
Operating cash flow: $1.1 billion
Free cash flow: $610 million
Cash, cash equivalents, and restricted cash: $3.9 billion vs $2.8 billion last year
Diluted earnings per share: $0.24, 25 percent lower than last year
Capital returns to shareholders: $214 million in dividends and share buybacks
Neri said in the earnings call: ”I am very optimistic about where we’re headed. AI demand continues to accelerate with cumulative AI systems orders reaching $4.6 billion this quarter. We anticipate continued revenue growth driven by increased AI systems demand, continued adoption of HPE GreenLake, and ongoing improvement in the traditional infrastructure market, including servers, storage, and networking.”
The AI sector is turning into a goldmine for the company – at least during the current time period. After initial public and sovereign cloud orders: “Enterprise orders now comprise more than 15 percent of our cumulative AI systems orders, with the number of Enterprise AI customers nearly tripling year-over-year. As these engagements continue to progress from exploration and discovery phases, we anticipate additional acceleration in enterprise AI systems orders through the end of the fiscal year.”
CFO Marie Myers amplified this view: “We remain in the very early days of AI, yet it is already driving strong interest, pipeline, orders, and revenue across our portfolio from service to storage to services to financing. Our AI system revenue inflected positively in Q2. We are winning deals in the AI market now and are well positioned for additional demand from enterprises and software into the future.”
HPE’s edge over competing AI server suppliers is its Cray supercomputing business and, Neri stressed, HPE’s decades of liquid cooling experience and credentials with its more than 300 patents in the area. GPU servers will increasingly need to be liquid-cooled. The company also managed to sell its AI systems without having to compress profit margins which unfortunately affected Dell’s AI server sales results.
HPE recruited around 3,000 new customers to its GreenLake subscription service and its as-a-service total contract value went past $15 billion. The total GreenLake customer count is now 34,000. This is an annual recurring revenue bank for the future.
Storage
In storage, Neri said: “More than 1,000 new HPE Alletra MP systems have been deployed to date, which is the fastest product ramp in the history of our company.”
Myers said: “Our traditional storage business was down year-over-year. The business is managing two long-term transitions at once.” The first is the migration to the SW-focused Alletra platform. Myers said: “This is reducing current period revenue growth, [but] locking in future recurring revenue.”
The second ”is from block storage to file storage driven by AI. While early, this is also on the right trajectory. Our new file offerings, plus [a] sales force investment Antonio mentioned, tripled our pipeline of file storage deals sequentially in Q2.” That’s good news for VAST Data whose file storage SW is OEM’d by HPE.
The positive outlook could send Q4 fy2024 revenues above $8 billion
She said “Reduced revenue scale and an unfavorable mix of third-party products and traditional storage was the largest driver of the sequential change,” in the storage operating margin of “0.8 percent, which was down 300 basis points sequentially and 110 basis points year-over-year.”
Networking was dull, with Neri saying “the market remained in transition during the quarter, as customers continued to work through their current inventory.”
The Q3 outlook is for revenues of $7.6 billion+/-$200 million, an 8.5 percent rise from a year ago. The full fy2024 outlook is one to three percent in constant currency terms. It was flat to two percent before. Neri noted: “Our lead time to deliver NVIDIA H100 solutions is now between six and 12 weeks, depending on order size and complexity. We expect this will provide a lift to our revenues in the second half of the year.”
Myers added: “We expect a materially stronger second half led by AI systems, traditional servers, and storage, networking and HPE GreenLake.”
VAST Data is the first storage provider to be integrated with Cisco’s Nexus 9000 Ethernet switches in the networking giant’s Nexus HyperFabric for Ethernet AI stacks connected to Nvidia GPU farms.
Cisco has developed programmable and high-bandwidth Silicon One ASIC chips for its fastest network switches and routers. The June 2023 G200 product, for example, with 512 x 100GE Ethernet ports on one device, supports 51.2 Tbps and features advanced congestion management, packet-spraying techniques, and link failover. The Silicon One hardware is available as chips or chassis without Cisco software. Cisco has developed its Ethernet AI Fabric, using Silicon One, which is deployed at three hyperscale customers.
Renen Hallak
Nexus HyperFabric AI clusters, using Nexus switches, are designed to help enterprises build AI datacenters using Nvidia-accelerated computing, which includes Tensor Core GPUs, BlueField-3 DPUs, SuperNICs, and AI Enterprise software, through Cisco networking and the VAST Data Platform. This VAST system also supports BlueField-3 DPUs. VAST has certified Cisco Nexus Ethernet-based switches with its storage, delivering validated designs. Cisco customers can monitor and correlate storage performance and latency using VAST’s APIs, pulling both network and storage telemetry back to the Nexus HyperFabric.
Renen Hallak, CEO and co-founder of VAST Data, said: “This is the year of the enterprise for AI. Traditionally, enterprises have been slower to adopt new technologies because of the difficulty of integrating new systems into existing systems and processes. This collaboration with Cisco and Nvidia makes it simple for enterprises to implement AI as they move from proof of concept to production.”
Jonathan Davidson, Cisco EVP and GM for its networking, added: “With an ecosystem approach that now includes VAST Data and Nvidia, Cisco helps our enterprise customers tackle their most difficult and complex networking, data and security challenges to build AI infrastructures at any scale with confidence.”
Jonathan Davidson
The Cisco Nexus HyperFabric features:
Cisco cloud management capabilities to simplify IT operations across all phases of the workflow.
Cisco Nexus 9000 series switches for spine and leaf that deliver 400G and 800G Ethernet fabric performance.
Cisco Optics family of QSFP-DD modules to offer customer choice and deliver super high densities.
NVIDIA AI Enterprise software to streamline the development and deployment of production-grade generative AI workloads
NVIDIA NIM inference microservices that accelerate the deployment of foundation models while ensuring data security, and are available with NVIDIA AI Enterprise
NVIDIA Tensor Core GPUs starting with the NVIDIA H200 NVL, designed to supercharge generative AI workloads with performance and memory capabilities.
NVIDIA BlueField-3 data processing unit DPU processor and BlueField-3 SuperNIC for accelerating AI compute networking, data access and security workloads.
Enterprise reference design for AI built on NVIDIA MGX, a modular and flexible server architecture.
The VAST Data Platform, which offers unified storage, database and a data-driven function engine built for AI.
The BlueField-3 DPUs can also run security services like the Cisco Hypershield, which enables an AI-native, hyperdistributed security architecture, where security shifts closer to the workloads needing protection.
VAST and Cisco claim they are simplifying network management and operations across all infrastructure endpoints. Congestion management with flow control algorithms, and visibility with real-time telemetry are provided by the private cloud (on-premises) managed Cisco Nexus Dashboard.
Select customers can access the VAST Data Platform with Cisco and Nvidia in beta now, with general availability expected in calendar Q4 of 2024.
Comment
Cisco has developed a FlashStack AI Cisco Verified Design (CVD) with Pure Storage for AI inferencing workloads using Nvidia GPUs. A similar FlexPod AI CVD does the same for NetApp. In February, Cisco said more Nvidia-backed CVDs will be coming in the future, and it looks like the VAST Data example has just arrived.
We understand that HyperFabric will support AI training workloads. This leads us to understand that a higher-speed Silicon One chip is coming, perhaps offering 76.5 Tbps or even 102.4 Tbps.
In effect, it looks like Cisco has developed a VAST Stack AI type offering which could potentially pump data faster to Nvidia GPU farms than existing arrangements with NetApp and Pure Storage.
Data protector N2WS is enabling server backups in AWS to be restored to Azure in a cross-cloud backup and disaster recovery feature.
N2WS (Not 2 Worry Software) provides IAAS; cloud-native backup, DR and archiving facilities for larger enterprises and also MSPs. It protects RDS, Aurora, RedShift and DynamoDB databases, S3 and VPC settings in AWS. The company offers agentless, application-consistent SQL server backup and performs disaster recovery for Azure VMs and Disks in the same target region. N2WS claims users can perform disaster recovery for Azure virtual machines and disks in minutes. The N2WS service is sold through the AWS and Azure Marketplaces.
Ohad Kritz.
Ohad Kritz, CEO and co-founder of N2WS, said in as statement: “N2WS’ cloud-native backup and disaster recovery solution really makes a difference for organizations. With cyber threats on the rise, we have to keep innovating. As leaders in the industry, it’s our job to stay ahead.”
The BDR (Backup & Disater Recovery) capabilities between Amazon Web Services (AWS) and Microsoft Azure mean users are protected against an AWS cloud failure, we’re told. The BDR features allow enterprises and MSPs to back up servers in AWS and quickly recover volumes in Azure, offering cross-cloud protection and ensuring compliance with new data isolation regulations.
N2WS has announced a number of additional new features;
Immutable snapshots in Amazon S3 and EBS, and Azure
Consolidated reports highlighting all customer’s backup policies, a claimed game-changer for enterprises and MSPs managing extensive backup environments with hundreds of policies.
VPC Capture & Clone: ELB enhancement – users can capture and clone all meaningful networking and configurations settings, including Elastic Load Balancers, enabling organizations to restore services during a regional outage and ensure security configurations are applied across all environments.
Disaster Recovery for DynamoDB. Until now, only same-region restore was supported for DynamoDB tables. DynamoDB tables can now be copied between AWS regions and accounts. This allows for instant restoration in the event of a full-scale regional outage or malicious activity that locks users out of their AWS accounts. Additionally, it enables the migration of DynamoDB table data between regions.
NIC/IP Support during Instance Restore. Secondary IP and additional NIC can now be added during an instance restore, enabling users to modify the network settings to ensure proper communication between a restored instance and its environment.
Time-Based Retention. New time-based backup retention periods can be selected in addition to the generation-based retention periods already in place, providing flexibility in choosing. This is available for all target types and storage repositories.
Options to Customize Restore Tags. When restoring a target, users now have a comprehensive toolset to assist in editing tags. Previously, they either chose to restore tags or not. Now, they can add, modify, and delete them.
N2WS is a Clumio competitor and, with this release, aims to help its enterprise and MSP customers combat cybersecurity attacks, ensure data sovereignty, enhancing data security, and optimize costs.
Startup AirMettle has joined the STAC Benchmark Council. AirMettle’s analytical data platform is designed to accelerate exploratory analytics on big data – from records to multi-dimensional data (e.g. weather) to AI for rich media – by integrating parallel processing within a software-defined storage service deployed on-prem and in clouds.
…
Catalogic has announced the newest version of its Catalogic DPX enterprise data protection software, focusing on enhancements to the DPX vStor backup repository technology. There are significant advancements in data immutability and recovery functionalities, and vStor Snapshot Explorer feature, all designed to bolster the security and flexibility of the company’s flagship enterprise backup solution. Users can now directly access and recover files on snapshots stored in vStor, simplifying the recovery process and reducing recovery time during critical operations.
…
Cloudera has acquired Verta’s Operational AI Platform. The Verta team will join Cloudera’s machine learning group, reporting to Chief Product Officer, Dipto Chakravarty. They will draw on their collective expertise to help drive Cloudera’s AI roadmap and enable the company to effectively anticipate the needs of its global customer base. Founded on research conducted at MIT by Dr. Manasi Vartak, Verta’s former CEO, and then further developed with Dr. Conrado Miranda, Verta’s former CTO, Verta was a pioneer in model management, serving, and governance for predictive and generative AI (GenAI). It addresses one of the biggest hurdles in AI deployments by enabling organizations to effectively build, operationalize, monitor, secure, and scale models across the enterprise. Verta’s technology simplifies the process of turning datasets into custom retrieval-augmented generation applications, enabling any developer—no matter their level of machine learning expertise—to create and optimize business-ready large language models (LLMs). These features—along Verta’s genAI workbench, model catalog, and AI governance tools—will enhance Cloudera’s platform capabilities as it continues to deliver on the promise of enterprise AI for its global customer base.
…
Lakehouse supplier Dremio has confirmed support for the Apache Iceberg REST Catalog Specification. This is the foundation for metadata accessibility across Iceberg catalogs. With this new capability, Dremio is able to seamlessly read from and write to any REST-compatible Iceberg catalog, we’re told, and provide customers with the open, flexible ecosystem needed for enterprise interoperability at scale. This news follows Dremio’s recent integration of Project Nessie into Dremio Software where customers can now use a powerful Iceberg catalog everywhere they use Dremio.
…
ExaGrid, which says it’s only Tiered Backup Storage solution with Retention Time-Lock that includes a non-network-facing tier (creating a tiered air gap), delayed deletes and immutability for ransomware recovery, announced it’s achieved “Veeam Ready-Object” status, verifying that Veeam can write to ExaGrid Tiered Backup Storage as an S3 object store target, as well as the capability to support Veeam Backup for Microsoft 365 using S3 directly to ExaGrid.
Mike Snitzer.
…
Hammerspace has appointed a long-time leader in the Linux kernel community – Mike Snitzer – to its software engineering team, where he will focus on Linux kernel development for Hammerspace’s Global Data Platform and accelerating advancements in standards-based Hyperscale NAS and Data Orchestration. He joins Trond Myklebust, Hammerspace CTO, as the second Linux kernel maintainer on the Hammerspace engineering staff. Snitzer has 24 years of experience developing software for Linux and high-performance computing clusters and will focus on Linux kernel development for Hammerspace’s Global Data Platform.
…
IBM has produced a Storage Ceph Solutions Guide. The target audience for this publication is IBM Storage Ceph architects, IT specialists, and storage administrators. This edition applies to IBM Storage Ceph Version 6. Storage Ceph comes with a GUI that is called Dashboard. This dashboard can simplify deployment, management, or monitoring. The Dashboard chapter features an Introduction, and then Connecting to the cluster Dashboard, Expanding the cluster, Reducing the number of monitors to three, Configuring RADOS Gateway, Creating a RADOS Block Device, Creating an image, Creating a Ceph File System, and Monitoring.
…
We asked the LTO organisation about tape endurance and customer tape copy refresh operations (re-silvering) frequency. It replied: “Life expectancy and migration serve distinct purposes in data management. The life expectancy of LTO tape cartridges is typically around 30 years under the conditions set by the tape manufacturer, and this ensures that the quality of archived data remains intact for reliable reading and recovery. However, individual tape admins may choose to migrate their data to a new cartridge more often than this.
“Typically, migration is performed every 7 to 10 years, primarily due to evolving infrastructure technologies. When a customer’s tape drives start ageing, getting sufficient service and support can become more difficult in terms of finding parts and receiving code updates, and this is completely natural with any type of electronic goods in the market. Customers will therefore often take advantage of the highest capacities of the latest generations, so there are fewer pieces of media to manage, at the same time that slots are freed within libraries to include more cartridges and increase the library capacity without the need to buy more libraries or expansions.
“Some tape admins might decide to retain drives to read older cartridges, and only migrate opportunistically as these cartridges are required to be read. For example, LTO-3 was launched back in 2005 – nearly 20 years ago – and yet today you can still buy an LTO-5 brand new tape drive which will read all the way back to LTO-3 media, enabling customers that have kept it all this time to still read it.
“When it comes to TCO, customers will need to decide on their migration strategy in order to calculate the differences between tape and disk.”
…
AI is driving the need for a new category of connectivity devices – PCIe retimers – to scale high-speed connections between AI accelerators, GPUs, CPUs, and other components inside servers. Marvell expanded its connectivity portfolio with new PCIe Gen 6 retimers (in 8 and 16-lane) built on the company’s 5nm PAM4 technology. The Alaska P PCIe retimer product line delivers reliable communication over the physical distances required for connections inside servers. According to Marvell, the 16-lane product operates at the lowest power in the market today – it’s sampling now to customers and ecosystem partners.
…
Micron has achieved its qualification sample milestone for CZ120 memory expansion modules using Compute Express Link (CXL). Micron is the first in the industry to achieve this milestone, which accelerates the adoption of CXL solutions within the datacenter to tackle growing memory challenges stemming from existing data-intensive workloads and emerging AI and ML workloads.
The Micron CZ120 memory expansion modules, which utilize CXL, provide the building blocks to address this challenge. These modules offer 128 GB and 256 GB densities and enable up to 2 TB of added capacity at the server level. This higher capacity is complemented by a bandwidth increase of 38 GBps that stems from saturating each of the PCIe Gen5 x8 lanes. Traditional SaaS enterprise workloads such as in-memory databases, SQL Server, OLAP and data analytics see a substantial performance increase when the system memory is augmented with CZ120 memory modules, delivering up to a 1.9x TPC-H benchmark improvement. Enhanced GPU LLM inferencing is also facilitated with Micron’s CZ120 memory, leading to faster time to insights and better sustained GPU utilization.
…
William Blair analyst Jason Ader tells subscribers that MSP backup services supplier N-able is exploring a potential sale after attracting interest from private equity. While the news is yet to be confirmed, N-able is reportedly in talks with peers in the software sector and private equity firms, with specific mention of Barracuda Networks, a cybersecurity company owned by KKR. Barracuda, which specializes in network security, was acquired by KKR in 2022 from Thoma Bravo for $4 billion. Similarly, N-able was spun out of SolarWinds in 2021, which was acquired by Silver Lake and Thoma Bravo for $4.5 billion in 2016, resulting in the two firms each owning about a third of N-able today.
…
Nvidia announced the world’s 28 million developers can download NVIDIA NIM inference microservices that provide models as optimized containers to deploy on clouds, data centers or workstations, giving them the ability to build generative AI applications for copilots, chatbots and more, in minutes rather than weeks. Nearly 200 technology partners — including Cadence, Cloudera, Cohesity, DataStax, NetApp, Scale AI and Synopsys — are integrating NIM into their platforms to speed generative AI deployments for domain-specific applications, such as copilots, code assistants and digital human avatars. Hugging Face is now offering NIM — starting with Meta Llama 3. Over 40 NVIDIA and community models are available to experience as NIM endpoints on ai.nvidia.com, including Databricks DBRX, Google’s open model Gemma, Meta Llama 3, Microsoft Phi-3, Mistral Large, Mixtral 8x22B and Snowflake Arctic.
…
Veeam backup target appliance Object First has announced expanded capacity of 192 TB for its Ootbi disk-based appliance. This means up to 768 TB of usable immutable backup storage per cluster. Ootbi version 1.5 is generally available today. General availability of the Ootbi 192 TB appliance is expected worldwide from August 2024. There are now three Ootbi models:
Ootbi 64 TB model: 10 x 8 TB SAS HDDs configured in RAID 6
Ootbi 128 TB model: 10 x 16 TB SAS HDDs configured in RAID 6
Ootbi 192 TB model: 10 x 24 TB SAS HDDs configured in RAID 6
…
On June 4, RelationalAI, creators of the industry’s first knowledge graph coprocessor for the data cloud, will be presenting alongside customers AT&T, Cash App, and Blue Yonder at the Snowflake Data Cloud Summit. Its knowledge graph coprocessor is available as a Snowflake Native App on the Snowflake Marketplace. Backed by Snowflake founder and former CEO, Bob Muglia, RelationalAI has taken $122 million in total funding.
…
Enterprise scale-out file system supplier Qumulo is the first networked storage supplier to join the Ultra Ethernet Consortium (UEC). It is collaborating with Intel and Arista Networks to advance the state of the art in IT infrastructure at the intersection of networking, storage, and data management. These technologies enhance the performance and operations of Qumulo’s Scale Anywhere Data Management platform. Qumulo has deployed over an exabyte of storage across hundreds of customers jointly with Arista Networks EOS-based switching and routing systems. Ed Chapman, vice president of business development and strategic alliances at Arista Networks, said: “Qumulo joining the UEC is further validation that Ethernet and IP are the right foundation for the next generation of general purpose, cloud, and AI computing and storage.”
…
AI startup SambaNova has broken a record in GenAI LLM speed, with Samba-1 Turbo reaching a record 1,084 tokens per second on Meta’s Llama 3 Instruct (8B), according to Artificial Analysis, a provider of objective benchmarks & information about AI models. This speed is more than eight times faster than the median across other providers. SambaNova has now leapfrogged Groq, with the latter announcing 800 tokens per second in April. For reference, OpenAI’s GPT-4o can only generate 100 tokens per second and averages 50-60 tokens per second in real-world use.
…
The Samsung Electronics Union is planning to strike on June 7. TrendForce reports that this strike will not impact DRAM and NAND flash production, nor will it cause any shipment shortages. Additionally, the spot prices for DRAM and NAND had been declining prior to the strike announcement, and there has been no change in this downtrend since.
…
The SNIA’s Storage Management Initiative (SMI) has made the SNIA Swordfish v1.2.7 Working Draft available for public review. SNIA Swordfish provides a standardized approach to manage storage and servers in hyperscale and cloud infrastructure environments, making it easier for IT administrators to integrate scalable solutions into their datacenters. Swordfish v1.2.7 has been released in preparation for DMTF’s Redfish version 2024.2, enabling DMTF and SNIA to jointly deliver new functionality. The release also contains expanded functionality for Configuration Locking.
…
Data warehouser and wannabee data lake supplier Snowflake announced Polaris Catalog, a vendor-neutral, open catalog implementation for Apache Iceberg — the open standard of choice for implementing data lakehouses, data lakes, and other modern architectures.Polaris Catalog will be open sourced in the next 90 days to provide enterprises and the entire Iceberg community with new levels of choice, flexibility, and control over their data, with full enterprise security and Apache Iceberg interoperability with Amazon Web Services (AWS), Confluent, Dremio, Google Cloud, Microsoft Azure, Salesforce, and more.
…
Snowflake has adopted NVIDIA AI Enterprise software to integrate NeMo Retriever microservices into Snowflake Cortex AI, Snowflake’s fully managed large language model (LLM) and vector search service. This will enable organizations to seamlessly connect custom models to diverse business data and deliver highly accurate responses. In addition, Snowflake Arctic, the open, enterprise-grade LLM, is now fully supported with NVIDIA TensorRT-LLM software, providing users with highly optimized performance. Arctic is also now available as an NVIDIA NIM inference microservice, allowing more developers to access Arctic’s efficient intelligence. NVIDIA AI Enterprise software capabilities to be offered in Cortex AI include NeMo Retriever (info retrieval with high accuracy and powerful performance for RAG GenAi within Cortex AI) and Triton Inference Server withthe ability to deploy, run, and scale AI inference for any application on any platform. NVIDIA NIM inference microservices – a set of pre-built AI containers and part of NVIDIA AI Enterprise – can be deployed right within Snowflake as a native app powered by Snowpark Container Services. The app enables organizations to easily deploy a series of foundation models right within Snowflake.
…
StorONE will be showcased at VeeamON from June 3-5 in Fort Lauderdale, FL. StorONE seamlessly transforms into a backup target, integrating flawlessly with Veeam. The platform brings three distinct advantages to the backup and archival use case specific to Veeam:
Maximized Drive Utilization: More data can be stored on fewer drives without the performance penalty of de-duplication.
Built-In Security: From immutable snapshots to multi-admin approval, data security is managed at the storage layer for rapid recovery.
Fast Restores and Production Capability: StorONE is a fully featured array capable of fast restores and running as a production copy if required and has the necessary Flash resources.
“Veeam provides for backup data movement and cataloging along with security features, while StorONE adds an extra, complimentary layer of security, including multi-admin approval for changes,” said Gal Naor, CEO of StorONE. “StorONE also unlocks many advanced features of Veeam, as it is a fully-featured array that can be configured for backups and high-performance storage, allowing Veeam restores and data integrity features to operate efficiently yet at a dramatically less expensive price point than competing backup solutions.”
…
TrendForce reports that a reduction in supplier production has led to unmet demand for high-capacity orders since 4Q23. Combined with procurement strategies aimed at building low-cost inventory, this has driven orders and significantly boosted enterprise SSD revenue, which reached $3.758 billion in 1Q24 – a staggering 62.9 percent quarter-over-quarter increase. Demand for high capacity, driven by AI servers, has surged. North American are clients increasingly adopting high-capacity QLC SSDs to replace HDDs, leading to an estimate of more than 20 percent growth in Q2 enterprise SSD bit procurement. This has also driven up Q2 enterprise SSD contract prices by more than 20 percent, with revenue expected to grow by another 20 percent.
…
Western Digital says that on Monday, June 10, 2024, at 1:00 p.m. Pacific / 4:00 p.m. Eastern, Robert Soderbery, EVP And GM its Flash business and other senior execs will host a webcast on the “New Era of NAND.” They’ll share WD’s view of the new dynamics in the NAND market and its commitment to NAND Tech innovation. There’ll be a Q&A session and the live webcast will be accessible through WD’s Investor Relations website at investor.wdc.com with an archived replay available shortly after the conclusion of the presentation.
…
Software RAID supplier Xinnor is included in the Arm Partner Program. Xinnor’s latest solution brief, “xiRAID Superfast RAID Engine for NVMe SSD on Arm-Based BlueField3 DPU,” is now available at the Arm partner portal. “There is an insatiable amount of data being produced today, especially with advances in AI,” said Kevin Ryan, senior director of partner ecosystem marketing at Arm. “More than ever, these increasingly complex workloads require high-performance and efficient data storage solutions, and we look forward to seeing how Xinnor’s addition to the Arm Partner Program will enable greater innovation in this space.”