


AirMettle has reinvented object storage for the analytics and generative AI era with a parallel software storage controller architecture delivering much faster access to data.
Founded by CEO Donpaul Stephens in 2017 and incorporated in 2018, the startup has thus far eschewed venture capital, raising around $4 million from grants and angels. Stephens was one of the founders of all-flash array startup Violin Memory back in 2005. What led him to AirMettle was the realization that large objects are sent to and from storage systems – such as Cloudian, MinIO, and Scality – as single items when only small parts or sections are needed at a time by a server, either local or remote. If you could divide a large object into shards, with shards delineated from the structural concepts of accessing applications – video frames for example – and spread them across the multiple nodes in an object system, then the multiple nodes could serve them in parallel. This can speed access overall by a factor of up to 100x.
Stephens told an IT Press Tour briefing: “We bring software compute into storage but we do it correctly. Computational storage has been around for 20 years and is a failure in the market … We are computational storage, but at the system level. Not at the drive level.”
AirMettle says its “core innovation is a software-defined storage platform with integrated distributed parallel processing enabling direct queries of semi-structured content in storage. The value gained is reducing network traffic to the query result set instead of the whole data set.”
Standard object storage stores and provides access to objects. AirMettle’s software does the same but provides access to parts of objects. It understands the data formats used by accessing applications and then partitions/structures the data according to these formats, and spreads them out in erasure coded single digit MB shards across the object storage nodes. That means they can operate in parallel. These nodes are commercial-off-the-shelf (COTS) storage servers – special hardware is not needed.
Analysis and AI training data sets are steadily increasing in size, making GPU servers work harder. They need more memory, and fast networking is required to get massive data sets to the GPUs quickly enough.
AirMettle says this situation is getting worse. Analytics memory is expensive and hitting size limits as data sets grow (eg AI). Analytics compute is an expensive way to filter out irrelevant raw data, and faster networking is expensive, constrained, and adds latency. It’s better to rearchitect the data store so that smaller amounts of data are sent to the analytics processors.
AirMettle supports classic tabular data, video data, and other formats – about ten in total – covering more than 90 percent of the object data stored. Stephens explained: “We handle multi-dimensional data, ie climate and weather. We divide the data into sub-planes which facilitates parallel processing.”
AirMettle has a database to hold its own internal metadata, which adds about 0.1 percent or so to the content. Stephens said: “This metadata is not indexing. It’s record:offset – where the bytes are.” This internal metadata enables parallel in-storage analytics. The right data is fed to analytics processors without having to go through a data lake extract, transform, and load (ETL) process to populate a data warehouse, which is then used as the analytics data source. In effect the AirMettle storage system, a smart data lake, inherently carries out ETL internally and no data warehouse is needed.
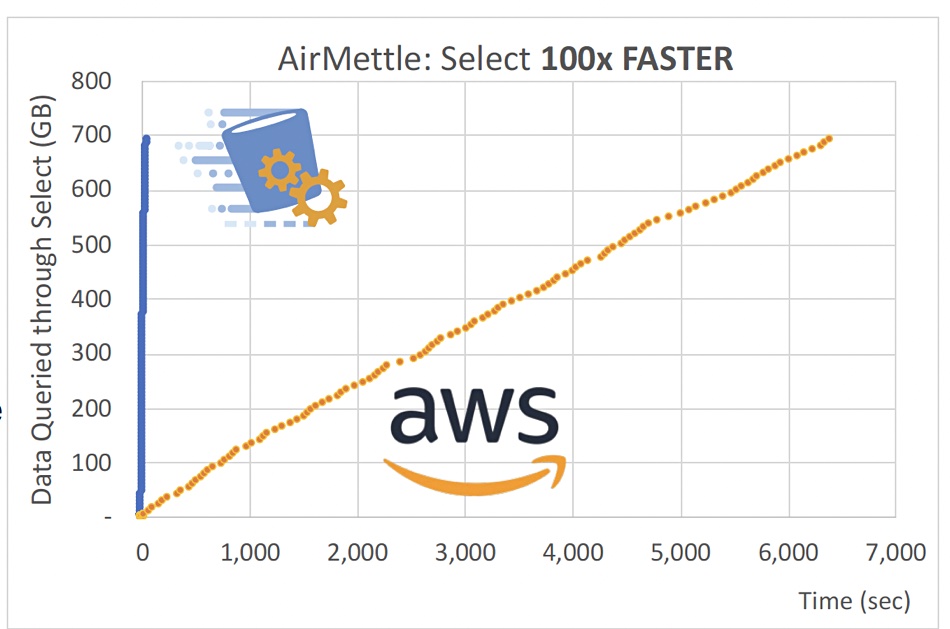
Envisage a large-scale object storage system with a thousand to ten thousand access nodes based on standard x86 servers and local drives. AirMettle’s software runs in these access node’s controllers, presenting an S3 Infrequent Access-type tier to accessing applications with an API. The system’s speed increases with scale and outperformed AWS’s S3 on the Star Schema benchmark by 100x.
Stephens said AI training uses files sent via GPUDirect to GPUs. In effect it could provide the equivalent of GPUDirect for objects.
There are about 20 employees in the biz, with nobody yet full time on sales or marketing. Chief product officer Troy Trenchard was hired in July last year to lead product strategy, marketing, and business development. He discussed three public cloud product ideas:
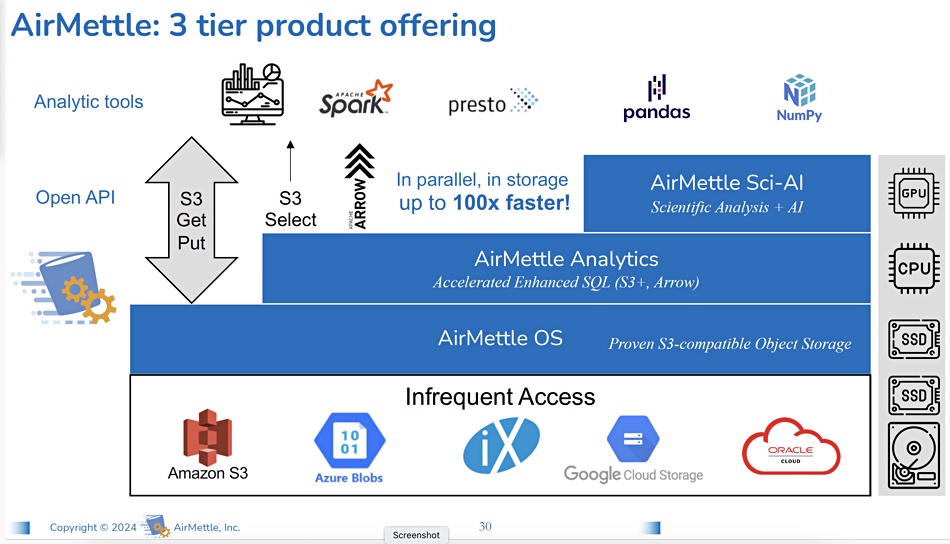
- AirMettle OS as a layer on top of public cloud object stores. 5x acceleration possibility, S3 get/put operations. Object storage would compete with Cloudian etc. at this level. It would need meed mid-market channel players.
- AirMettle Analytics on top. S3 Select, Arrow 100x accelerated enhanced SQL (S3+, Arrow). This implies a more enterprise option of AirMettle OS and Analytics. Growth over time.
- AirMettle Sci-AI. Scientific analysis + AI – plug-in support for add-ins and modules – GPU. For high-end customers in near term.
AirMettle has been awarded a patent and there are more in the pipeline.
The startup has not publicly launched its product technology, but has paying customers – such as Los Alamos Labs, its first such customer, with Gary Grider, HPC division leader, lauding the software. Stephens told us: “You get more value out of supercomputers if our software runs on the COTS storage servers feeding them data.” It’s also working with the National Oceanic and Atmospheric Administration in the US.
Stephens said: “We are talking to the CSPs on infrequent access tiers – all of the big three.” Potential use cases include accelerated in-storage data mining of video light sources, processing of video data, accelerated video analytics, and the selection and rescaling of weather data.
This is a young business that has bypassed the traditional startup funding development process. It has unique and promising technology, and we can expect to hear more from it in 2024 as its product strategy solidifies and its route to market becomes defined.





