


Lakehouse supplier Databricks has launched the DBRX GenAI large language model (LLM).

It says DBRX lets customers build, train, and serve their own custom LLMs more cheaply, without having to rely on a small set of closed models. Closed LLMs, like ChatGPT and GPT-3.5, are based on private model weights and source code whereas open source ones such as LlaMa, Dolly, and DBRX have publicly available source code and model weights.
Developers can inspect their model architecture and training data and customize the source code, according to Databricks.
Databricks co-founder and CEO Ali Ghodsi said: “We’re excited about DBRX for three key reasons: first, it beats open source models on state-of-the-art industry benchmarks. Second, it beats GPT-3.5 on most benchmarks, which should accelerate the trend we’re seeing across our customer base as organisations replace proprietary models with open source models. Finally, DBRX uses a mixture-of-experts architecture, making the model extremely fast in terms of tokens per second, as well as being cost effective to serve.”
A Databricks chart shows DBRX delivering results faster than other open source LLMs like Llama 2 70B and Mixtral-8x7B on industry benchmarks such as language understanding, programming, maths, and logic.
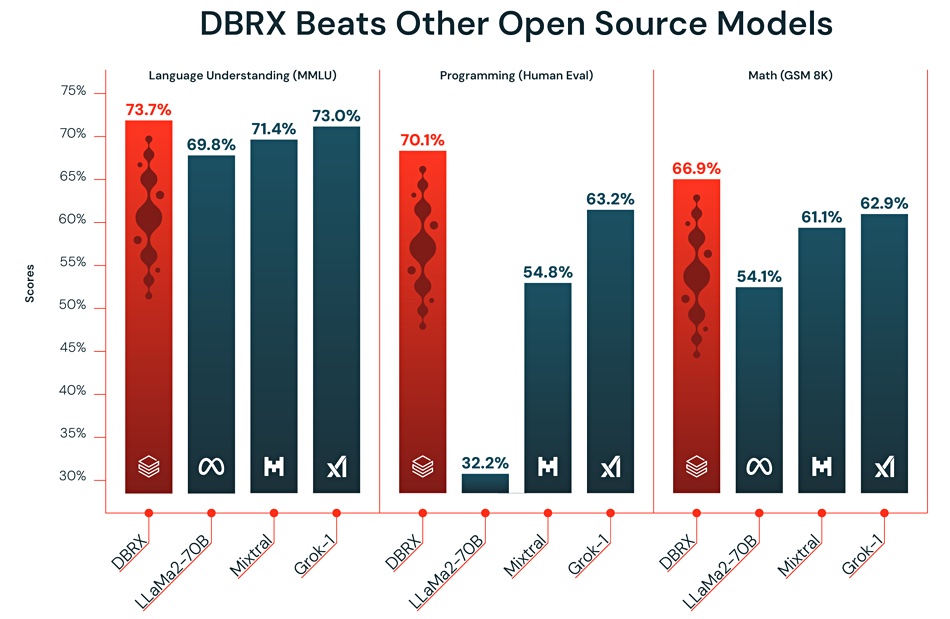
The MMLU (Massive Multitask Language Understanding) is a benchmark designed to measure knowledge acquired during pre-training by evaluating models exclusively in zero-shot (no labeled data available for new classes) and few-shot (limited number of labeled examples for each new class) settings. The benchmark covers 57 subjects across STEM, humanities, social sciences, and more. Programming (Human Eval) is a programming challenge dataset. Math GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers.
The performance differences are minor on the MMLU test, significant on the Programming (Human Eval) run, and less significant on the Match (GSM 8K) benchmark/
DBRX also goes faster than GPT-3.5, according to claims from Databricks:
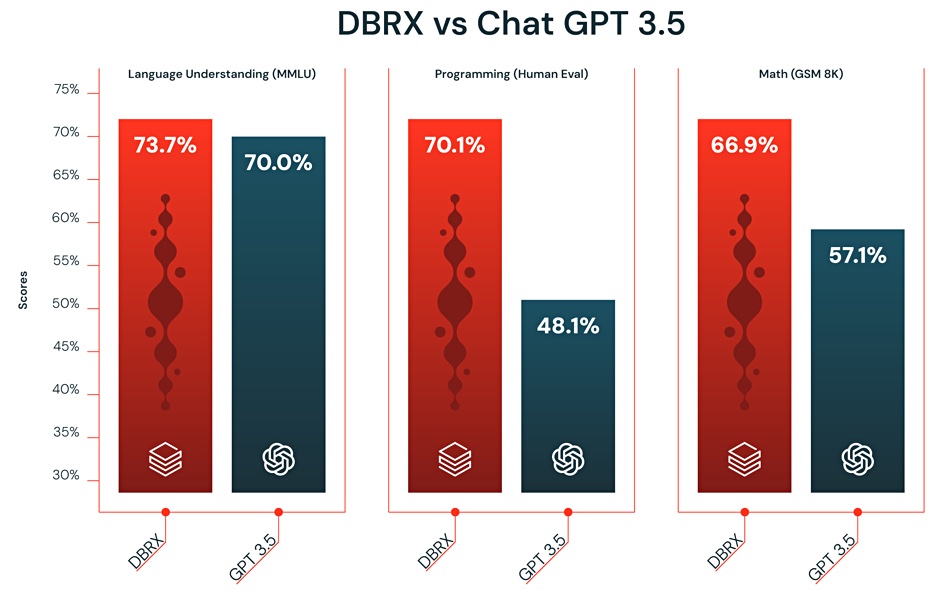
The pattern of performance differences is the same as with the open source chart above; minor on the MMLU test, significant on the Programming (Human Eval) run, and less significant on the Match (GSM 8K) benchmark.
Databricks says it has optimized DBRX for efficiency and with a mixture-of-experts (MoE) architecture, built on the MegaBlocks open source project. The MoE architecture is said to enable trillion parameter-class training with billion parameter-class compute resources. A Hugging Face blog explains the concept.
DBRX is claimed to be up to twice as compute-efficient as other available LLMs. Databricks says it can be used, when paired with Databricks’ Mosaic AI tooling, to build and deploy safe, accurate, and governed production-quality GenAI applications without customers giving up control of their data and intellectual property.
Mike O’Rourke, head of AI and Data Services at Nasdaq, said in a canned remark issued by Databricks: “Databricks is a key partner to Nasdaq on some of our most important data systems … and we are excited about the release of DBRX. The combination of strong model performance and favorable serving economics is the kind of innovation we are looking for as we grow our use of Generative AI at Nasdaq.”
DBRX is freely available on GitHub and Hugging Face for research and commercial use. Databricks is running a DBRX webinar on April 25, 1500 UTC. Check out a DBRZ article at its Mosaic AI Research blog.
Comment
Relying on a particular GenAI model’s speed at this early stage in development, on both hardware and software fronts, doesn’t appear to be a sustainable strategy unless you can afford to keep developing it at the same rate as the extremely well-heeled closed model developers.





